







决策数
决策数的核心类容
1:如何确定最佳节点和最佳分支
2:决策数什么时候停止生长(防止过拟合)
sklearn中的决策树
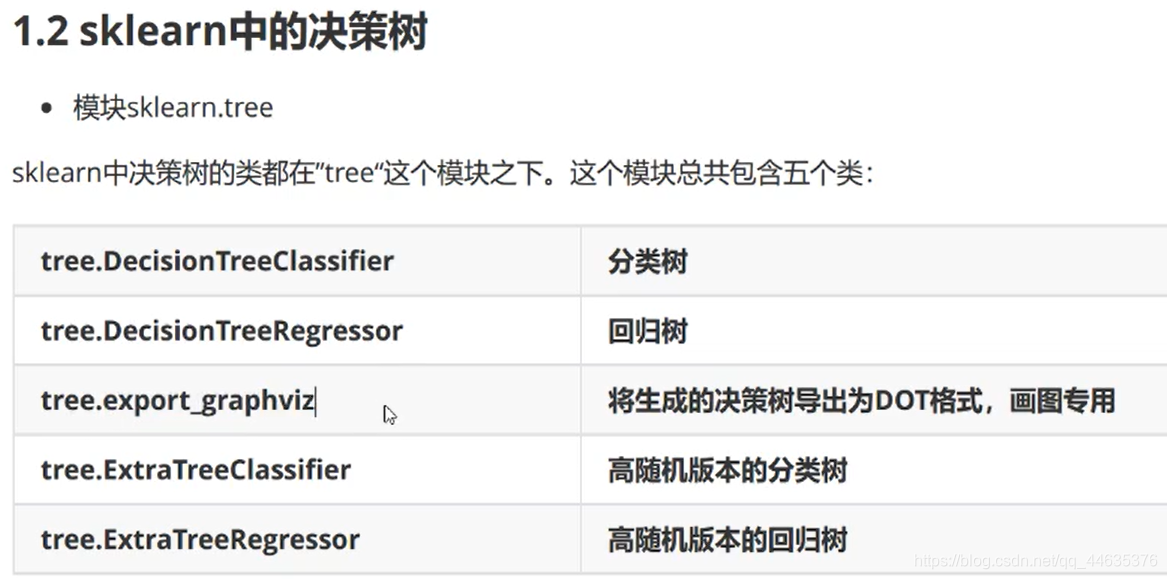
sklearn训练流程
from sklearn import tree #导入需要的模块
clf = tree.DecisionTreeClassifier() #实例化
clf = clf.fit(x_train,y_train) #训练集数据训练模型
result = clf.score(x_train,y_train) #导入测试积,获取需要的信息
决策树分类器DecisionTreeClassifier
重要参数
class sklearn.tree.DecisionTreeClassifier (criterion=’gini’, splitter=’best’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, class_weight=None, presort=False)
# 重要参数
criterion //标准:用来决定“不纯度”的计算方式
1)entropy(信息熵):更加敏感,欠拟合的时候用信息熵
2)gini(基尼系数):适用于高维数据和噪音很多的数据
**********不纯度:衡量最佳节点和最佳分支的标准,不纯度越低越好,子节点不纯度一定小于父节点。
======================随机参数=======================
random_state //消除随机性
1)随便指定一个数
splitter //消除随机性,同时调整过拟合
1)best 默认
2)random 随机,更加敏感
===================================================
=====================剪枝参数=========================
max_depth //设置最大层数
min_samples_leaf //任意子节点得最小样本量
min_samples_split //任意父节点得最小样本量
max_features //设置最多使用的特征数
min_impurity_decrease //设置信息增益的大小,当信息增益小于这个限定值时,停止分支
信息增益:父节点信息熵-子节点信息熵
====================================================
=======================标签权重参数:对样本标签进行均衡==============
class_weight
class_weight_fraction_leaf
重要接口
clf.fit() //训练接口
clf.score() //评价接口,返回准确度accuracy
clf.apply()
clf.predict() //预测接口
回归树
重要参数(和决策数一样,不一样的在线面说明)
criterion //标准。MSE或者MAE。
重要接口
fit() //返回R^2 不是MSE
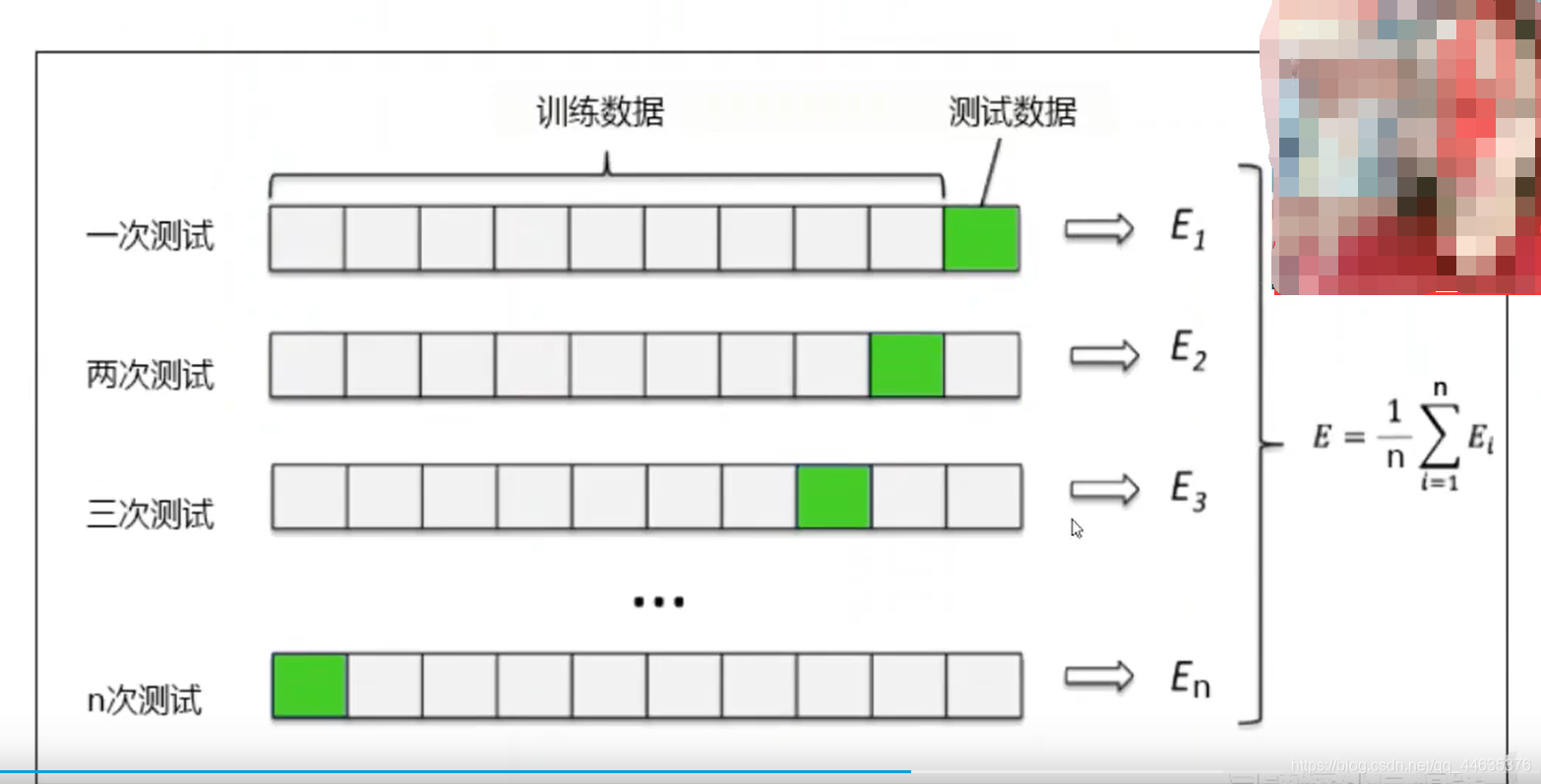
交叉验证


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









