




1、初识 Node.js 与内置模块
1.1、Node.js
Node.js 的官网地址: https://nodejs.org/zh-cn/
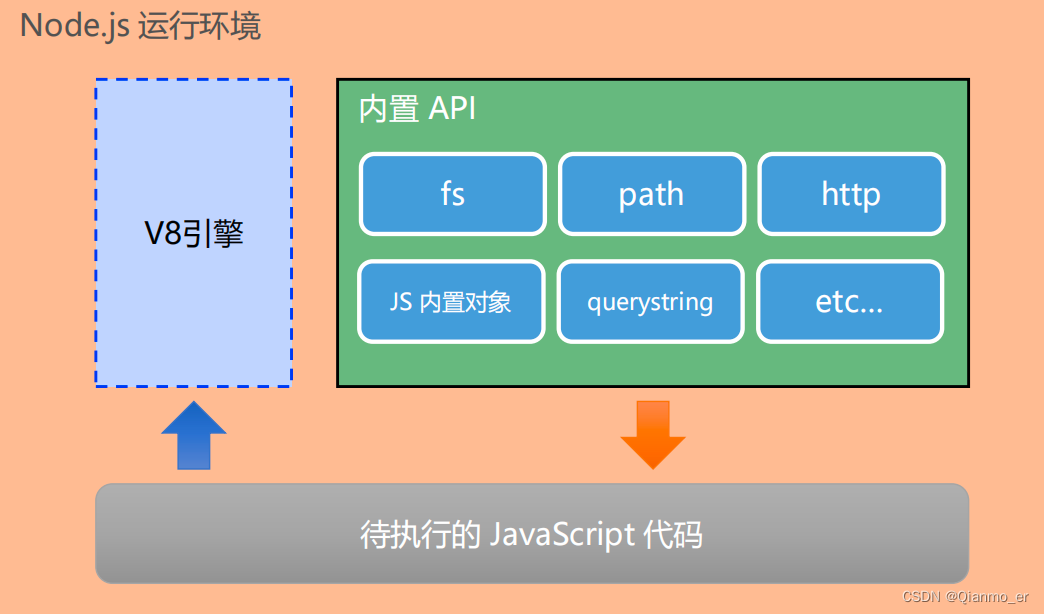
Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行环境。
Node.js 中的 JavaScript 运行环境
注意
① 浏览器是 JavaScript 的前端运行环境。
② Node.js 是 JavaScript 的后端运行环境。
③ Node.js 中无法调用 DOM 和 BOM 等浏览器内置 API。
Node.js 作为一个 JavaScript 的运行环境,仅仅提供了基础的功能和 API。然而,基于 Node.js 提供的这些基础能,很多强大
的工具和框架如雨后春笋,层出不穷,所以学会了 Node.js ,可以让前端程序员胜任更多的工作和岗位:
① 基于 Express 框架(http://www.expressjs.com.cn/),可以快速构建 Web 应用
② 基于 Electron 框架(https://electronjs.org/),可以构建跨平台的桌面应用
③ 基于 restify 框架(http://restify.com/),可以快速构建 API 接口项目
④ 读写和操作数据库、创建实用的命令行工具辅助前端开发、etc…
安装:
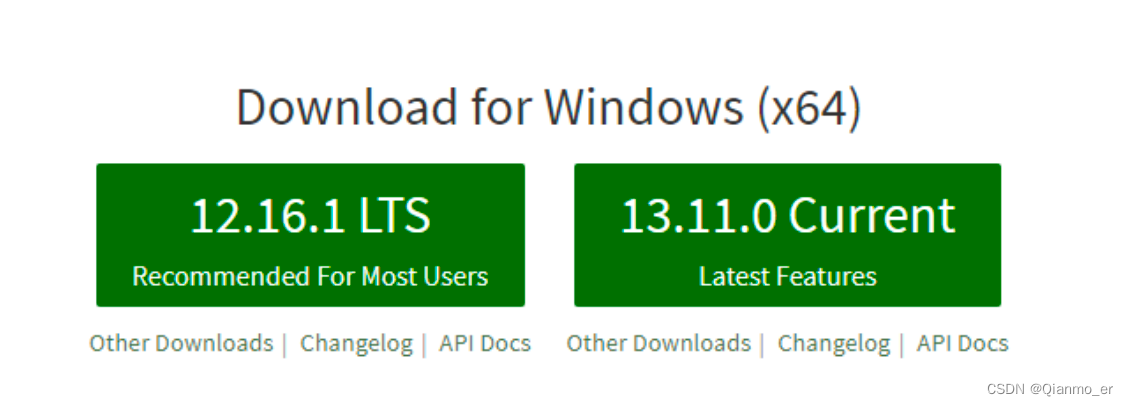
安装包可以从 Node.js 的官网首页直接下载,进入到 Node.js 的官网首页(https://nodejs.org/en/),点击绿色的按钮,下载所需的版本后,双击直接安装即可。
-
区分 LTS 版本和 Current 版本的不同
① LTS 为长期稳定版,对于追求稳定性的企业级项目来说,推荐安装 LTS 版本的 Node.js。
② Current 为新特性尝鲜版,对热衷于尝试新特性的用户来说,推荐安装 Current 版本的 Node.js。但是,Current 版本中可能存在隐藏的 Bug 或安全性漏洞,因此不推荐在企业级项目中使用 Current 版本的 Node.js。 -
查看已安装的 Node.js 的版本号
打开终端,在终端输入命令node –v后,按下回车键,即可查看已安装的Node.js的版本号。
Windows 系统快速打开终端的方式:
使用快捷键(Windows徽标键 + R)打开运行面板,输入cmd后直接回车,即可打开终端。
1.2、fs 文件系统模块
fs 模块是 Node.js 官方提供的、用来操作文件的模块。它提供了一系列的方法和属性,用来满足用户对文件的操作需求。
例如:
⚫ fs.readFile() 方法,用来读取指定文件中的内容
⚫ fs.writeFile() 方法,用来向指定的文件中写入内容
如果要在 JavaScript 代码中,使用 fs 模块来操作文件,则需要使用如下的方式先导入它:
const fs = require('fs')
1.2.1、读取指定文件中的内容
- fs.readFile() 方法,可以读取指定文件中的内容,语法格式如下:
fs.readFile(path[,options],callback)
参数解读:

- fs.readFile() 的示例代码
以 utf8 的编码格式,读取指定文件的内容,并打印 err 和 dataStr 的值:
const fs = require('fs')
fs.readFile('./files/11.txt','utf8'.function(err,dataStr){
console.log(err)
console.log('-----')
console.log(dataStr)
})
- 判断指定文件中的内容
可以判断 err 对象是否为 null,从而知晓文件读取的结果:
const fs = require('fs')
fs.readFile('./files/1.txt','utf8',function(err,result){
if(err){
return console.log('文件读取失败!' + err.message)
}
console.log('文件读取成功!内容是:' + result)
})
1.2.2、向指定的文件中写入内容
- fs.writeFile() 的语法格式
使用 fs.writeFile() 方法,可以向指定的文件中写入内容,语法格式如下:
fs.writeFile(file,data[,options],callback)
参数解读:

- fs.writeFile() 的示例代码
向指定的文件路径中,写入文件内容:
const fs = require('fs')
fs.writeFile('./files/2.txt','hello Node.js!',function(err){
console.log(err)
})
- 判断文件是否写入成功
可以判断 err 对象是否为 null,从而知晓文件写入的结果:
const fs = require('fs')
fs.writeFile('F:/files/2.txt','Hello Node.js!',function(err){
if(err){
return console.log('文件写入失败!' + err.message)
}
console.log('文件写入成功!')
})
1.2.3、练习 - 考试成绩整理
使用 fs 文件系统模块,将素材目录下成绩.txt文件中的考试数据,整理到成绩-ok.txt文件中。
整理前,成绩.txt文件中的数据格式如下:
小红=99 小白=100 小黄=70 小黑=66 小绿=88
整理完成之后,希望得到的成绩-ok.txt文件中的数据格式如下:
小红:99
小白:100
小黄:70
小黑:66
小绿:88
核心实现步骤
① 导入需要的 fs 文件系统模块
② 使用 fs.readFile() 方法,读取素材目录下的 成绩.txt 文件
③ 判断文件是否读取失败
④ 文件读取成功后,处理成绩数据
⑤ 将处理完成的成绩数据,调用 fs.writeFile() 方法,写入到新文件 成绩-ok.txt 中
1.2.4、fs 模块 - 路径动态拼接的问题
在使用 fs 模块操作文件时,如果提供的操作路径是以 ./ 或 …/ 开头的相对路径时,很容易出现路径动态拼接错误的问题。
原因:代码在运行的时候,会以执行 node 命令时所处的目录,动态拼接出被操作文件的完整路径。
解决方案:在使用 fs 模块操作文件时,直接提供完整的路径,不要提供 ./ 或 …/ 开头的相对路径,从而防止路径动态拼接的问题。
// 不要使用 ./ 或 ../ 相对路径
fs.readFile('./files/1.txt','utf8',function(err,dataStr){
if(err) return console.log('读取文件失败!' + err.message)
console.log(dataStr)
})
// __dirname 表示当前文件所处的目录
fs.readFile( __dirname + '/files/1.txt','utf8',function(err,dataStr){
if(err) return console.log('读取文件失败!' + err.message)
console.log(dataStr)
})
1.3、path 路径模块
path 模块是 Node.js 官方提供的、用来处理路径的模块。它提供了一系列的方法和属性,用来满足用户对路径的处理需求。
例如:
⚫ path.join() 方法,用来将多个路径片段拼接成一个完整的路径字符串
⚫ path.basename() 方法,用来从路径字符串中,将文件名解析出来
如果要在 JavaScript 代码中,使用 path 模块来处理路径,则需要使用如下的方式先导入它:
const path = require('path')
1.3.1、路径拼接
path.join()的语法格式
使用 path.join() 方法,可以把多个路径片段拼接为完整的路径字符串,语法格式如下:
path.join([...paths])
参数解读:
...path <string>路径片段的序列- 返回值:
<string>
- 代码示例
使用path.join()方法,可以把多个路径片段拼接为完整的路径字符串:
const pathStr = path.join('/a','/b/c','../','./d','e')
console.log(pathStr) // 输出 \a\b\c\d\e
const pathStr2 = path.join(__dirname,'./files/1.txt')
console.log(pathStr2) // 输出 当前文件所处目录 \files\1.txt
注意:今后凡是涉及到路径拼接的操作,都要使用path.join() 方法进行处理。不要直接使用 + 进行字符串的拼接
1.3.2、获取路径中的文件名
path.basename()的语法格式
使用path.basename()方法,可以获取路径中的最后一部分,经常通过这个方法获取路径中的文件名,语法格式如下:
path.basename(path[,ext])
参数解读:
⚫ path <string> 必选参数,表示一个路径的字符串
⚫ ext <string> 可选参数,表示文件扩展名
⚫ 返回: <string> 表示路径中的最后一部分
- 代码示例
使用 path.basename() 方法,可以从一个文件路径中,获取到文件的名称部分:
const fpath = '/a/b/c/index.html' // 文件的存放路径
var fullName = path.basename(fpath)
console.log(fullName) // 输出 index.html
var nameWithoutExt = path.basename(fpath,'.html')
console.log(nameWithoutExt) // 输出 index
1.3.3、获取路径中的文件扩展名
path.extname()的语法格式
使用path.extname()方法,可以获取路径中的扩展名部分,语法格式如下:
path.extname(path)
参数解读:
⚫ path <string>必选参数,表示一个路径的字符串
⚫ 返回: <string> 返回得到的扩展名字符串
- 代码示例
使用path.extname()方法,可以获取路径中的扩展名部分:
const fpath = '/a/b/c/index.html'
const fext = path.extname(fpath)
console.log(fext) // 输出 .html
1.3.4、综合示例 - 时钟
- 案例要实现的功能
将素材目录下的 index.html 页面,
拆分成三个文件,分别是:
- index.css
- index.js
- index.html
并且将拆分出来的 3 个文件,存放到 clock 目录中。
-
案例的实现步骤
① 创建两个正则表达式,分别用来匹配<style>和<script>标签
② 使用fs 模块,读取需要被处理的HTML文件
③ 自定义resolveCSS方法,来写入index.css样式文件
④ 自定义resolveJS方法,来写入index.js脚本文件
⑤ 自定义resolveHTML方法,来写入index.html文件 -
步骤
步骤1 - 导入需要的模块并创建正则表达式
// 1.1 导入 fs 文件系统模块
const fs = require('fs')
// 1.2 导入 path 路径处理模块
const path = require('path')
// 1.3 匹配 <style></style> 标签的正则
// \s 表示空白字符;\S 表示非空白字符;* 表示匹配任意字符
const regStyle = /<style>[\s\S]*<\/style>/
// 1.4 匹配 <script></script> 标签
const regScript = /<script>[\s\S]*<\/script>/
步骤2 - 使用 fs 模块读取需要被处理的 html 文件
// 2.1 读取需要被处理的 html 文件
fs.readFile(path.join(__dirname,'../素材/index.html'),'utf8',(err,dataStr)=>{
// 2.2 读取 HTML 文件失败
if(err) return console.log('读取 HTML 文件失败!' + err.message)
// 2.3 读取 HTML 文件成功,调用对应的方法,解析 css.js 和 html 文件
resolveCSS(dataStr)
resolveJS(dataStr)
resolveHTML(dataStr)
})
步骤3 – 自定义 resolveCSS 方法
// 3.1 处理 css 样式
function.resolveCSS(htmlStr){
// 3.2 使用正则提取页面中的 <style></style> 标签
const r1 = regStyle.exec(htmlStr)
// 3.3 将提取出来的样式字符串,做进一步的处理
const newCSS = r1[0].replace('<style>','').replace('</style>','')
// 3.4 将提取出来的 css 样式,写入到 index.css 文件中
fs.writeFile(path.join(__dirname,'./clock/index.css'),newCSS,err=>{
if(err) return console.log('写入 CSS 样式失败!' + err.message)
console.log('写入 CSS 样式成功!')
})
}
步骤4 – 自定义 resolveJS 方法
// 4.1 处理 js 脚本
function.resolveJS(htmlStr){
// 4.2 使用正则提取页面中的 <script></script> 标签
const r2 = regScript.exec(htmlStr)
// 4.3 将提取出来的样式字符串,做进一步的处理
const newJS = r2[0].replace('<script>','').replace('</script>','')
// 4.4 将提取出来的 js 脚本,写入到 index.js 文件中
fs.writeFile(path.join(__dirname,'./clock/index.js'),newJS,err=>{
if(err) return console.log('写入 JavaScript 脚本失败!' + err.message)
console.log('写入 JavaScript 脚本成功!')
})
}
步骤5 – 自定义 resolveHTML 方法
// 5.1 处理 html 文件
function.resolveHTML(htmlStr){
// 5.2 使用字符串的 replace 方法,把内嵌的 <style> 和 <Script> 标签,替换为外联的 <link> 和 <script> 标签
const newHTML = htmlStr
.replace(regStyle,'<link rel="stylesheet" href="./index.css" />')
.replace(regScript,'<script src="./index.js"></script>')
// 5.3 将替换完成之后的 html 代码,写入到 index.html 文件中
fs.writeFile(path.join(__dirname,'./clock/index.html'),newHTML,err=>{
if(err) return console.log('写入 html 文件失败!' + err.message)
console.log('写入 html 文件成功!')
})
}
注意:
① fs.writeFile() 方法只能用来创建文件,不能用来创建路径
② 重复调用 fs.writeFile() 写入同一个文件,新写入的内容会覆盖之前的旧内容
1.4、http 模块
http 模块是 Node.js 官方提供的、用来创建 web 服务器的模块。通过 http 模块提供的 http.createServer() 方法,就能方便的把一台普通的电脑,变成一台 Web 服务器,从而对外提供 Web 资源服务。
如果要希望使用 http 模块创建 Web 服务器,则需要先导入它
const http = require('http')
1.4.1、创建最基本的 web 服务器
-
创建 web 服务器的基本步骤
① 导入 http 模块
② 创建 web 服务器实例
③ 为服务器实例绑定 request 事件,监听客户端的请求
④ 启动服务器 -
步骤
// 步骤1 - 导入 http:
const http = require('http')
// 步骤2 - 创建 web 服务器实例
const server = http.createServer()
//步骤3 - 为服务器实例绑定 request 事件
// 使用服务器实例的 .on() 方法,为服务器绑定一个 requrst 事件
server.on('request',(req,res)=>{
// 客户端请求服务器,触发 request 事件
console.log("Someone visit web server")
})
// 步骤4 - 启动服务器
// 调用服务器实例的 server.listen(端口号,cb回调) 方法,即可启动当前 web 服务器
server.listen(80,()=>{
console.log("http server running at http://127.0.0.1")
})
req请求对象
只要服务器接收到了客户端的请求,就会调用通过server.on()为服务器绑定的 request 事件处理函数。
如果想在事件处理函数中,访问与客户端相关的数据或属性,可以使用如下的方式
server.on('request',(req)=>{
// req 是请求对象,包含了与客户端相关的数据和属性
// req.url 是客户端请求的 URL 地址
// req.method 是客户端的 method 请求类型
const str = `Your request url is ${req.url},and request method is ${req.method}`
console.log(str)
})
res相应对象
在服务器的 request 事件处理函数中,如果想访问与服务器相关的数据或属性,可以使用如下的方式
server.on('request',(req,res)=>{
// res 是响应对象,包含了与客户端相关的数据和属性
// 要发送客户端的字符串
const str = `Your request url is ${req.url},and request method is ${req.method}`
// res.end() 方法的作用
// 向客户端发送指定的内容,并结束这次请求的处理过程
res.end(str)
})
- 解决中文乱码问题
当调用 res.end() 方法,向客户端发送中文内容的时候,会出现乱码问题,此时,需要手动设置内容的编码格式:
server.on('request',(req,res)=>{
// 发送的内容包含中文
const str = `您请求的 url 地址是 ${req.url},请求的 method 类型是 ${req.method}`
// 为了防止中文显示乱码的问题,需要设置相应头 Content-Type 的值为 text/html;charset=utf-8
res.setHeader('Content-Type','text/html;charset=utf-8')
// 把包含的中文内容,响应给客户端
res.end(str)
})
1.4.2、根据不同的 url 响应不同的 html 内容
-
核心实现步骤
① 获取请求的 url 地址
② 设置默认的响应内容为 404 Not found
③ 判断用户请求的是否为/或/index.html首页
④ 判断用户请求的是否为/about.html关于页面
⑤ 设置Content-Type 响应头,防止中文乱码
⑥ 使用res.end()把内容响应给客户端 -
动态响应内容
server.on('request',function(req,res)=>{
// 1. 获取请求的 url 地址
const url = req.url
// 2. 设置默认的内容为 404 Not Found
let content = '<h1>404 Not Found</h1>'
if(url === '/' || url ==='.index.html'){
// 3. 用户请求的是首页
conent = '<h1>首页</h1>'
}else if(url === '/about.html'){
// 4. 用户请求的是关于页面
content = '<h1>关于页面</h1>'
}
// 5. 设置 Content-Type 响应头,防止中文乱码
res.setHeader('Content-Type','text/html;charset=utf-8')
// 6. 把内容发送给客户端
res.end(content)
})
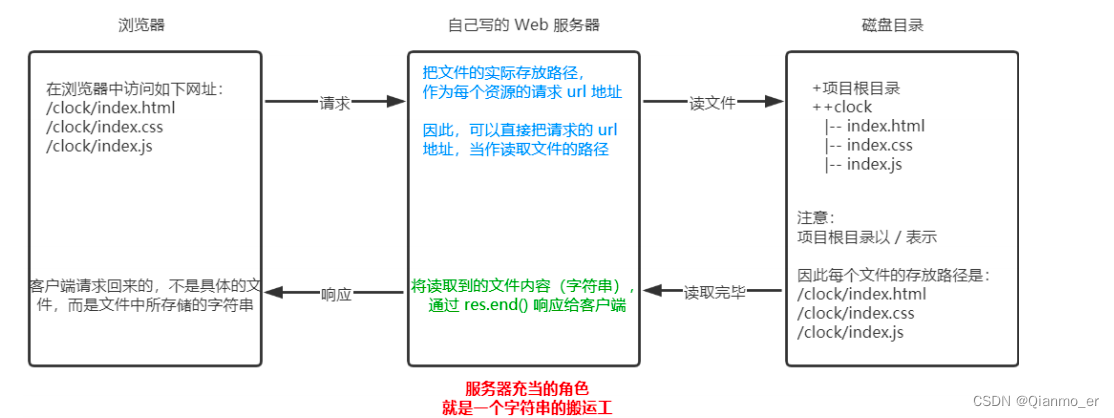
1.4.3、案例 - 实现 clock 时钟的 web 服务器
-
核心思路
把文件的实际存放路径,作为每个资源的请求 url 地址
-
实现步骤
① 导入需要的模块
② 创建基本的 web 服务器
③ 将资源的请求 url 地址映射为文件的存放路径
④ 读取文件内容并响应给客户端
⑤ 优化资源的请求路径 -
代码步骤
// 步骤1 - 导入需要的模块
// 1.1 导入 http 模块
const http = require('http')
// 1.2 导入 fs 文件系统模块
const fs = require('fs')
// 1.3 导入 path 路径处理模块
const path = require('path')
// 步骤2 - 创建基本的 web 服务器
// 2.1 创建 web 服务器
const server = http.createServer()
// 2.2 舰艇 web 服务器的 request 事件
server.on('request',function(req,res){
// 步骤3 - 将资源的请求 url 地址映射为文件的存放路径
// 3.1 获取到客户端请求的 url 地址
const url = req.url
// 3.2 把请求的 url 地址,映射为本地的存放路径
//const fpath = path.join(__dirname,url)
// 优化资源的请求路径
// 预定义空白文件存放路径
let fpath = ''
if(url === '/'){
// 如果请求的路径是否为 /,则手动置顶文件的存放路径
fpath = path.join(__dirname,'./clock/index.html')
}else{
// 如果请求的路径不为 /,则动态拼接文件的存放路径
fpath = path.join(__dirname,'./clock',url)
}
// 步骤4 - 读取文件的内容并响应给客户端
// 4.1 根据映射”过来的文件路径读取文件
fs.readFile(fpath,'utf8',(err,dataStr)=>{
// 4.2 读取文件失败后
if(err) return res.end('404 Not Found')
// 4.3 读取文件成功后
res.end(dataStr)
})
})
// 2.3 启动 web 服务器
server.listen(80,function(){
console.log('server listen at http://127.0.0.1')
})
2、模块化
模块化是指解决一个复杂问题时,自顶向下逐层把系统划分成若干模块的过程。
对于整个系统来说,模块是可组合、分解和更换的单元。
编程领域中的模块化,就是遵守固定的规则,把一个大文件拆成独立并互相依赖的多个小模块。
把代码进行模块化拆分的好处:
① 提高了代码的复用性
② 提高了代码的可维护性
③ 可以实现按需加载
==模块化规范:==对代码进行模块化的拆分与组合时,需要遵守的那些规则。
好处:都遵守同样的模块化规范写代码,降低了沟通的成本,极大方便了各个模块之间的相互调用。
2.1、Node.js中的模块化
2.1.1、模块的分类
内置模块(内置模块是由 Node.js 官方提供的,例如 fs、path、http 等)自定义模块(用户创建的每个 .js 文件,都是自定义模块)第三方模块(由第三方开发出来的模块,并非官方提供的内置模块,也不是用户创建的自定义模块,使用前需要先下载)
2.1.2、加载模块
使用强大的 require() 方法,可以加载需要的内置模块、用户自定义模块、第三方模块进行使用。例如:
// 1.加载内置的 fs 模块
const fs = require('fs')
// 2.加载用户的自定义模块
const custom = require('./custom.js')
// 3.加载第三方模块
const moment = require('moment')
注意:使用 require() 方法加载其它模块时,会执行被加载模块中的代码
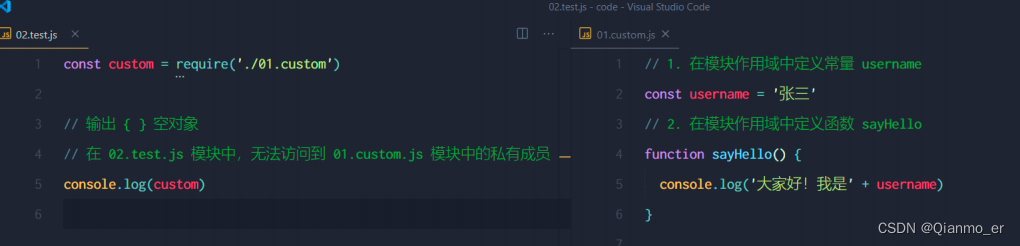
2.1.3、模块中的作用域
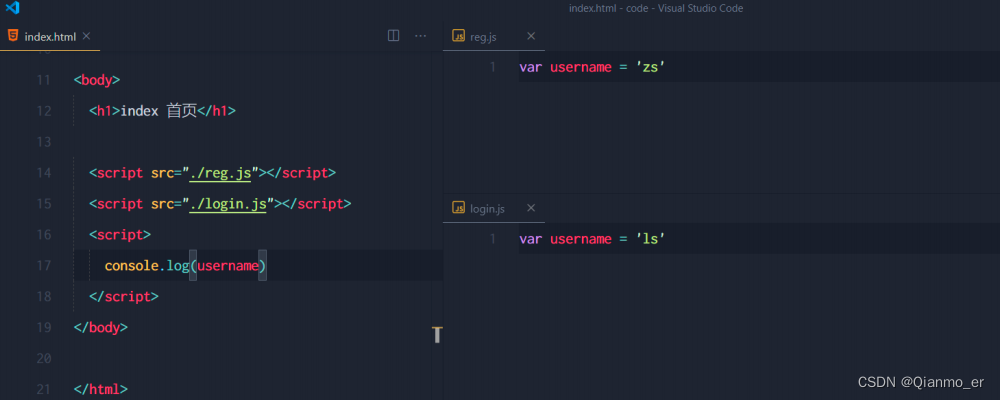
和函数作用域类似,在自定义模块中定义的变量、方法等成员,只能在当前模块内被访问,这种模块级别的访问限制,叫做模块作用域。
模块作用域的好处:
防止了全局变量污染的问题
2.1.4、向外共享模块作用域中的成员
-
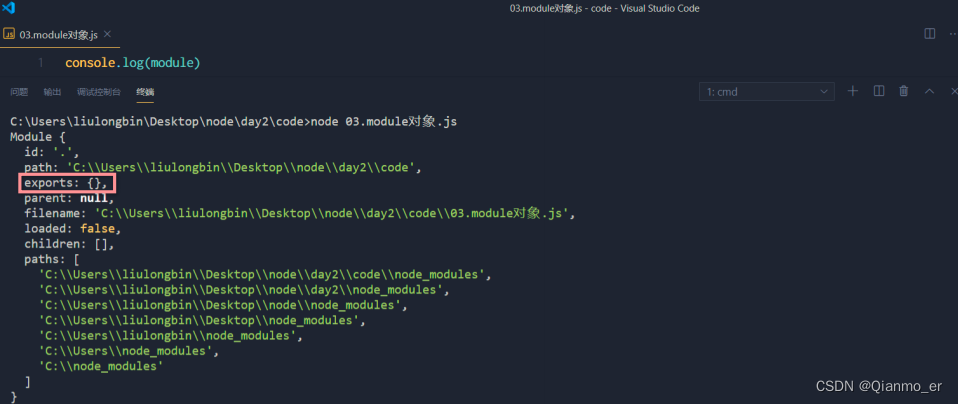
module对象
在每个 .js 自定义模块中都有一个module对象,它里面存储了和当前模块有关的信息,打印如下:
-
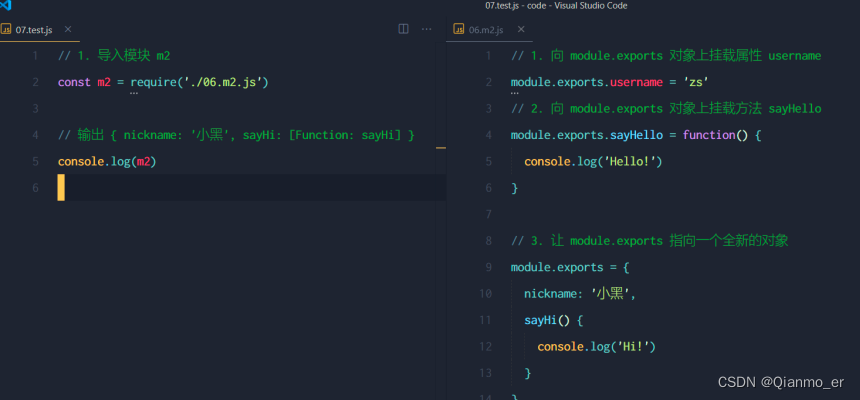
module.exports对象
在自定义模块中,可以使用module.exports对象,将模块内的成员共享出去,供外界使用。
外界用require()方法导入自定义模块时,得到的就是module.exports所指向的对象。 -
共享成员时的注意点
使用require()方法导入模块时,导入的结果,永远以module.exports指向的对象为准
-
exports对象
由于 module.exports 单词写起来比较复杂,为了简化向外共享成员的代码,Node 提供了 exports 对象。默认情况下,exports和module.exports指向同一个对象。
最终共享的结果,还是以 module.exports 指向的对象为准。
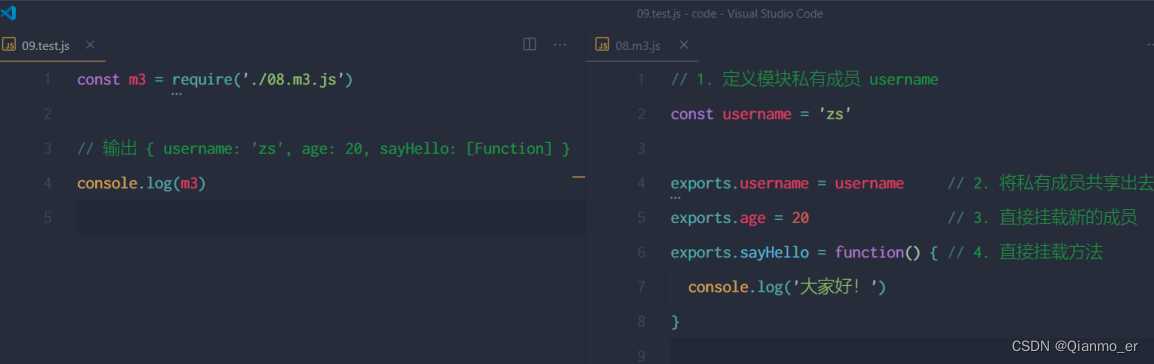
-
exports和module.exports的使用误区
require() 模块时,得到的永远是module.exports指向的对象:

注意:为了防止混乱,建议大家不要在同一个模块中同时使用exports和module.exports
2.1.5、模块化规范
Node.js 遵循了 CommonJS 模块化规范,CommonJS 规定了模块的特性和各模块之间如何相互依赖。
CommonJS 规定:
- 每个模块内部,
module变量代表当前模块。 - module 变量是一个对象,它的 exports 属性(即
module.exports)是对外的接口。 - 加载某个模块,其实是加载该模块的 module.exports 属性。
require()方法用于加载模块
2.2、npm 与包
Node.js 中的第三方模块又叫做包。包是由第三方个人或团队开发出来的,免费供所有人使用。
注意:Node.js 中的包都是免费且开源的,不需要付费即可免费下载使用。
- 由于 Node.js 的内置模块仅提供了一些底层的 API,导致在基于内置模块进行项目开发的时,效率很低。
- 包是基于内置模块封装出来的,提供了更高级、更方便的 API,极大的提高了开发效率。
- 包和内置模块之间的关系,类似于 jQuery 和 浏览器内置 API 之间的关系。
国外有一家 IT 公司,叫做 npm, Inc. 这家公司旗下有一个非常著名的网站:https://www.npmjs.com/ ,它是全球最大的包共享平台,你可以从这个网站上搜索到任何你需要的包,只要你有足够的耐心!
到目前位置,全球约 1100 多万的开发人员,通过这个包共享平台,开发并共享了超过 120 多万个包 供我们使用。
npm, Inc. 公司提供了一个地址为 https://registry.npmjs.org/ 的服务器,来对外共享所有的包,我们可以从这个服务器上下载自己所需要的包。
注意:
- 从 https://www.npmjs.com/ 网站上搜索自己所需要的包
- 从 https://registry.npmjs.org/ 服务器上下载自己需要的包
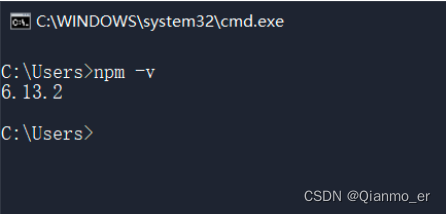
这个包管理工具的名字叫做 Node Package Manager(简称 npm 包管理工具),这个包管理工具随着 Node.js 的安装包一起被安装到了用户的电脑上。
可以在终端中执行 npm -v 命令,来查看自己电脑上所安装的 npm 包管理工具的版本号:
2.2.1、npm 初体验
- 格式化时间的传统做法
① 创建格式化时间的自定义模块
② 定义格式化时间的方法
③ 创建补零函数
④ 从自定义模块中导出格式化时间的函数
⑤ 导入格式化时间的自定义模块
⑥ 调用格式化时间的函数
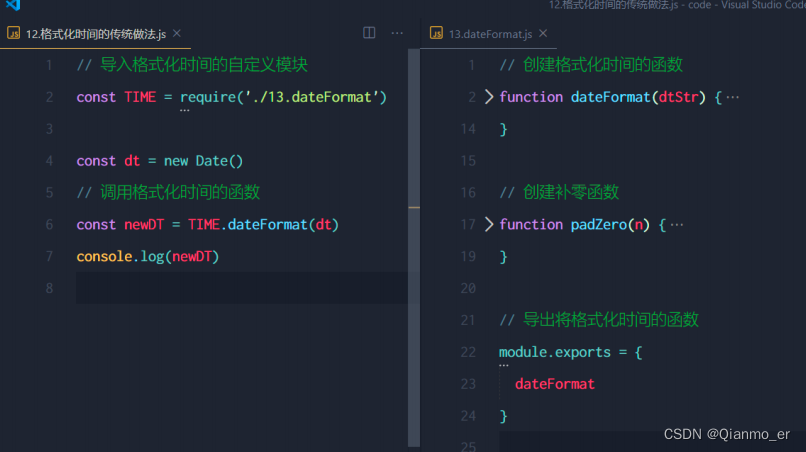
- 格式化时间的高级做法
① 使用 npm 包管理工具,在项目中安装格式化时间的包 moment
② 使用 require() 导入格式化时间的包
③ 参考 moment 的官方 API 文档对时间进行格式化
// 1. 导入 moment 包
const moment = require('moment')
// 2. 参考 moment 官方 api 文档,可调用对应的方法,对时间进行格式化
// 2.1 调用 moment() 方法,得到当前的时间
// 2.2 针对当前的时间,调用 format() 方法,按指定的格式进行时间格式化
const dt = moment().format('YYYY-MM-DD HH:mm:ss')
console.log(dt) // 输出 当前系统时间
- 在项目中安装包的命令
如果想在项目中安装指定名称的包,需要运行如下的命令:
npm install 包的完整名称
上述的装包命令,可以简写成如下格式:
npm i 包的完整名称
- 初次装包后多了哪些文件
初次装包完成后,在项目文件夹下多一个叫做 node_modules 的文件夹和 package-lock.json 的配置文件。
其中:
node_modules文件夹用来存放所有已安装到项目中的包。require()导入第三方包时,就是从这个目录中查找并加载包。package-lock.json配置文件用来记录node_modules目录下的每一个包的下载信息,例如包的名字、版本号、下载地址等。
注意:不要手动修改 node_modules 或 package-lock.json 文件中的任何代码,npm 包管理工具会自动维护它们。
- 安装指定版本的包
默认情况下,使用 npm install 命令安装包的时候,会自动安装最新版本的包。如果需要安装指定版本的包,可以在包名之后,通过 @ 符号指定具体的版本,例如:
npm i moment@2.22.2
- 包的语义化版本规范
包的版本号是以“点分十进制”形式进行定义的,总共有三位数字,例如 2.24.0
其中每一位数字所代表的的含义如下:
- 第1位数字:大版本
- 第2位数字:功能版本
- 第3位数字:Bug修复版本
版本号提升的规则:只要前面的版本号增长了,则后面的版本号归零。
2.2.2、包管理配置文件
npm 规定,在项目根目录中,必须提供一个叫做 package.json 的包管理配置文件。用来记录与项目有关的一些配置信息。例如:
- 项目的名称、版本号、描述等
- 项目中都用到了哪些包
- 哪些包只在
开发期间会用到 - 那些包在
开发和部署时都需要用到
- 如何记录项目中安装了哪些包
在项目根目录中,创建一个叫做 package.json 的配置文件,即可用来记录项目中安装了哪些包。从而方便剔除node_modules 目录之后,在团队成员之间共享项目的源代码。
注意:今后在项目开发中,一定要把 node_modules 文件夹,添加到 .gitignore 忽略文件中。
- 快速创建 package.json
npm 包管理工具提供了一个快捷命令,可以在执行命令时所处的目录中,快速创建 package.json 这个包管理配置文件:
// 作用:在执行命令所处的目录中,快速新建 package.json 文件
npm init -y
注意:
-上述命令只能在英文的目录下成功运行!所以,项目文件夹的名称一定要使用英文命名,不要使用中文,不能出现空格。
- 运行 npm install 命令安装包的时候,npm 包管理工具会自动把
包的名称和版本号,记录到 package.json 中。
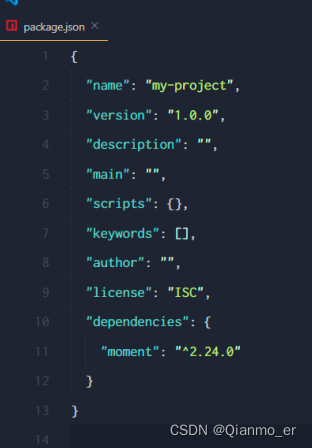
dependencies节点
package.json 文件中,有一个 dependencies 节点,专门用来记录您使用 npm install 命令安装了哪些包。
- 一次性安装所有的包
当我们拿到一个剔除了 node_modules 的项目之后,需要先把所有的包下载到项目中,才能将项目运行起来。否则会报类似于下面的错误:

可以运行 npm install 命令(或 npm i)一次性安装所有的依赖包:

- 卸载包
可以运行 npm uninstall 命令,来卸载指定的包:
npm uninstall moment
注意:
npm uninstall 命令执行成功后,会把卸载的包,自动从 package.json 的 dependencies 中移除掉
devDependencies节点
如果某些包只在项目开发阶段会用到,在项目上线之后不会用到,则建议把这些包记录到 devDependencies 节点中。
与之对应的,如果某些包在开发和项目上线之后都需要用到,则建议把这些包记录到 dependencies 节点中。
您可以使用如下的命令,将包记录到 devDependencies 节点中:
// 安装指定的包,并记录到 devDependencies 节点中
npm i 包名 -D
// 完整写法
npm install 包名 --save-dev
2.2.3、解决下包速度慢的问题
- 为什么下包速度慢
在使用 npm 下包的时候,默认从国外的 https://registry.npmjs.org/ 服务器进行下载,此时,网络数据的传输需要经过漫长的海底光缆,因此下包速度会很慢。
扩展阅读 - 海底光缆:
- https://baike.baidu.com/item/%E6%B5%B7%E5%BA%95%E5%85%89%E7%BC%86/4107830
- https://baike.baidu.com/item/%E4%B8%AD%E7%BE%8E%E6%B5%B7%E5%BA%95%E5%85%89%E7%BC%86/10520363
- https://baike.baidu.com/item/APG/23647721?fr=aladdin
- 淘宝 NPM 镜像服务器
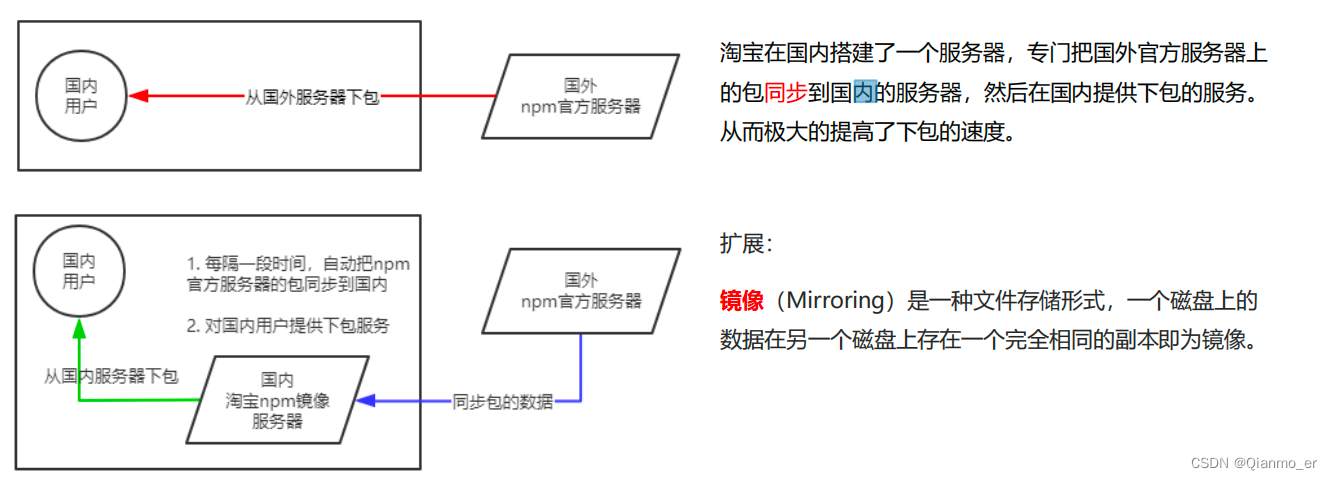
- 切换 npm 的下包镜像源
下包的镜像源,指的就是下包的服务器地址。
# 查看当前的下包镜像源
npm config get registry
# 将下包的镜像源切换为淘宝镜像源
npm config set registry=https://registry.npm.taobao.org/
# 检查镜像源是否下载成功
npm config get registry
- nrm
为了更方便的切换下包的镜像源,我们可以安装 nrm 这个小工具,利用 nrm 提供的终端命令,可以快速查看和切换下包的镜像源。
# 通过 npm 包管理器,将 nrm 安装为全局可用的工具
npm i nrm -g
# 查看所有可用的镜像源
nrm ls
# 将下包的镜像源切换为 taobao 镜像
nrm use taobao
2.2.4、包的分类
使用 npm 包管理工具下载的包,共分为两大类,分别是:
- 项目包
- 全局包
- 项目包
那些被安装到项目的node_modules目录中的包,都是项目包。
项目包又分为两类,分别是:
- 开发依赖包(被记录到
devDependencies节点中的包,只在开发期间会用到) - 核心依赖包(被记录到
dependencies节点中的包,在开发期间和项目上线之后都会用到)
npm i 包名 -D # 开发依赖包(被记录到 devDependencies 节点中)
npm i 包名 # 核心依赖包(被记录到 dependencies 节点中)
- 全局包
在执行 npm install 命令时,如果提供了 -g 参数,则会把包安装为全局包。
全局包会被安装到 C:\Users\用户目录\AppData\Roaming\npm\node_modules 目录下
npm i 包名 -g # 全局安装指定的包
npm uninstakl 包名 -g # 卸载全局安装的包
注意:
① 只有工具性质的包,才有全局安装的必要性。因为它们提供了好用的终端命令。
② 判断某个包是否需要全局安装后才能使用,可以参考官方提供的使用说明即可。
- i5ting_toc
i5ting_toc 是一个可以把 md 文档转为 html 页面的小工具,使用步骤如下:
# 将 i5ting_toc 安装为全局包
npm install -g i5ting_toc
# 调用 i5ting_toc ,轻松实现 md 转 html 功能
i5ting_toc -f 要转换的md文件路径 -o
2.2.5、规范的包结构
在清楚了包的概念、以及如何下载和使用包之后,接下来,我们深入了解一下包的内部结构。
一个规范的包,它的组成结构,必须符合以下 3 点要求:
① 包必须以单独的目录而存在
② 包的顶级目录下要必须包含 package.json 这个包管理配置文件
③ package.json 中必须包含 name,version,main 这三个属性,分别代表包的名字、版本号、包的入口。
注意:以上 3 点要求是一个规范的包结构必须遵守的格式,关于更多的约束,可以参考如下网址:https://yarnpkg.com/zh-Hans/docs/package-json
2.2.6、开发属于自己的包
- 需要实现的功能
① 格式化日期
// 1.导入自己的包
const it = require('it-utils')
// 功能1:格式化日期
const dt = it.dataFormat(new Date())
// 输出 系统时间
console.log(dt)
② 转义 HTML 中的特殊字符
// 1.导入自己的包
const it = require('it-utils')
// 功能2:转义 HTML 中的特殊字符
const htmlStr = '<h1 style="color:red;">你好!©<span>小黄!</span></h1>'
const str = it.htmlEscape(htmlStr)
// 输出
console.log(str)
③ 还原 HTML 中的特殊字符
// 1.导入自己的包
const it = require('it-utils')
// 功能3:还原 HTML 中的特殊字符
const rawHTML = it.htmlUnEscape(str)
// 输出
console.log(rawHTML)
- 初始化包的基本结构
- 新建 it-tools 文件夹,作为包的根目录
- 在
it-tools文件夹中,新建如下三个文件:package.json(包管理配置文件)index.js(包的入口文件)README.md(包的说明文档)
-
初始化 package.json
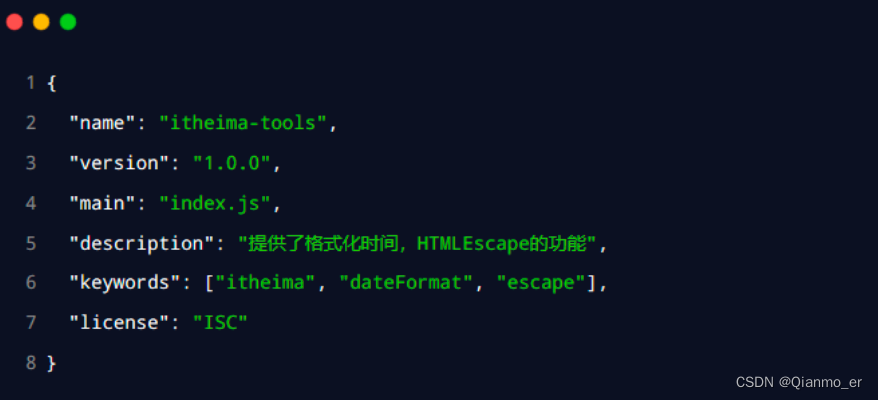
关于更多 license 许可协议相关的内容,可参考 https://www.jianshu.com/p/86251523e898 -
在 index.js 中定义格式化时间的方法
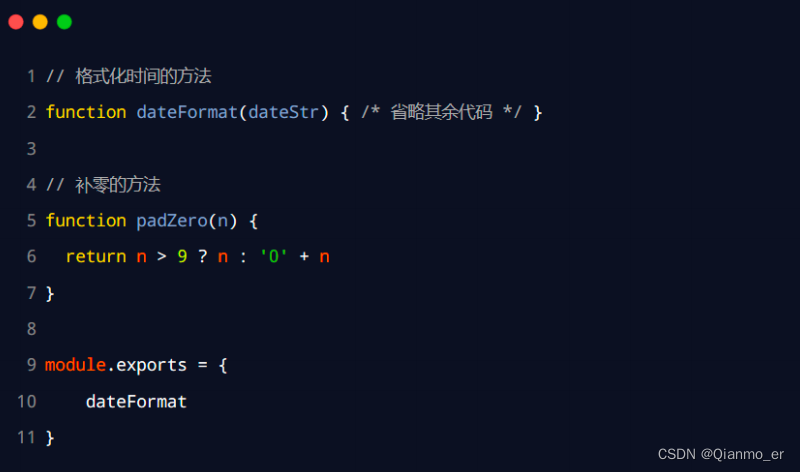
-
在 index.js 中定义转义 HTML 的方法
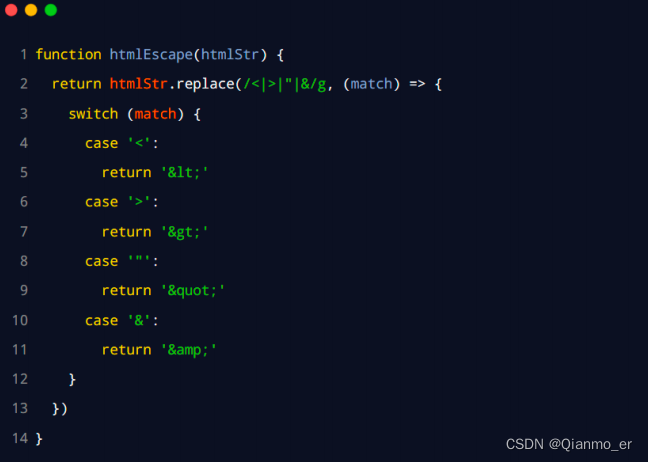
6. 在 index.js 中定义还原 HTML 的方法
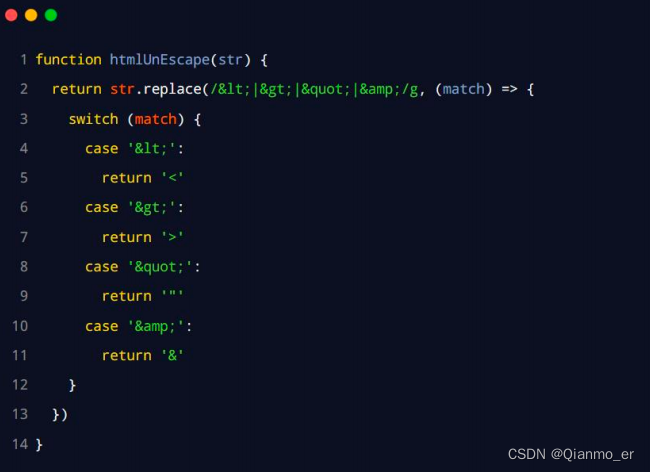
- 将不同的功能进行模块化拆分
① 将格式化时间的功能,拆分到 src -> dateFormat.js 中
② 将处理 HTML 字符串的功能,拆分到 src -> htmlEscape.js 中
③ 在 index.js 中,导入两个模块,得到需要向外共享的方法
④ 在 index.js 中,使用 module.exports 把对应的方法共享出去
- 编写包的说明文档
包根目录中的README.md文件,是包的使用说明文档。通过它,我们可以事先把包的使用说明,以 markdown 的格式写出来,方便用户参考。
README 文件中具体写什么内容,没有强制性的要求;只要能够清晰地把包的作用、用法、注意事项等描述清楚即可。
所创建的这个包的 README.md 文档中,会包含以下 6 项内容:
安装方式、导入方式、格式化时间、转义 HTML 中的特殊字符、还原 HTML 中的特殊字符、开源协议。
2.2.7、发布包
- 注册 npm 账号
① 访问 https://www.npmjs.com/ 网站,点击 sign up 按钮,进入注册用户界面
② 填写账号相关的信息:Full Name、Public Email、Username、Password
③ 点击 Create an Account 按钮,注册账号
④ 登录邮箱,点击验证链接,进行账号的验证
-
登录 npm 账号
npm 账号注册完成后,可以在终端中执行npm login命令,依次输入用户名、密码、邮箱后,即可登录成功。
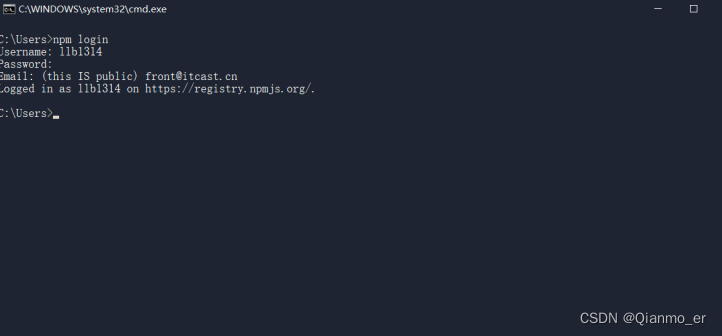
注意:在运行npm login命令之前,必须先把下包的服务器地址切换为 npm 的官方服务器。否则会导致发布包失败 -
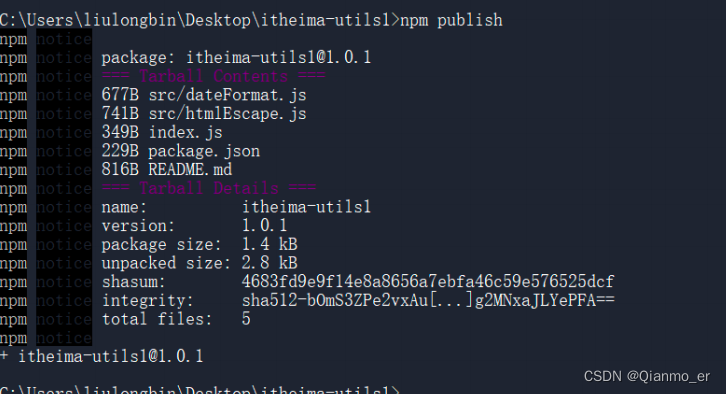
把包发布到 npm 上
将终端切换到包的根目录之后,运行 npm publish 命令,即可将包发布到 npm 上(注意:包名不能雷同)。
- 删除已发布的包
运行 npm unpublish 包名 --force 命令,即可从 npm 删除已发布的包。

注意:
npm unpublish命令只能删除 72 小时以内发布的包npm unpublish删除的包,在 24 小时内不允许重复发布- 发布包的时候要慎重,尽量不要往 npm 上发布没有意义的包!
2.3、模块的家在机制
2.3.1、优先从缓存中加载
模块在第一次加载后会被缓存。 这也意味着多次调用 require() 不会导致模块的代码被执行多次。
注意:不论是内置模块、用户自定义模块、还是第三方模块,它们都会优先从缓存中加载,从而提高模块的加载效率。
2.3.2、内置模块的加载机制
内置模块是由 Node.js 官方提供的模块,内置模块的加载优先级最高。
例如,require(‘fs’) 始终返回内置的 fs 模块,即使在 node_modules 目录下有名字相同的包也叫做 fs。
2.3.3、自定义模块的加载机制
使用 require() 加载自定义模块时,必须指定以 ./ 或 ../ 开头的路径标识符。在加载自定义模块时,如果没有指定 ./ 或 ../ ,这样的路径标识符,则 node 会把它当作内置模块或第三方模块进行加载。
同时,在使用 require() 导入自定义模块时,如果省略了文件的扩展名,则 Node.js 会按顺序分别尝试加载以下的文件:
- 按照
确切的文件名进行加载 - 补全
.js扩展名进行加载 - 补全
.json扩展名进行加载 - 补全
.node扩展名进行加载 - 加载失败,终端报错
2.3.4、第三方模块的加载机制
如果传递给 require() 的模块标识符不是一个内置模块,也没有以 ‘./’ 或 ‘…/’ 开头,则 Node.js 会从当前模块的父目录开始,尝试从 /node_modules 文件夹中加载第三方模块。
如果没有找到对应的第三方模块,则移动到再上一层父目录中,进行加载,直到文件系统的根目录。
例如,假设在 ‘C:\Users\itheima\project\foo.js’ 文件里调用了 require('tools'),则 Node.js 会按以下顺序查找:
① C:\Users\itheima\project`node_modules\tools ② C:\Users\itheima\node_modules\tools ③ C:\Users\node_modules\tools ④ C:\node_modules`\tools
2.3.5、目录作为模块
当把目录作为模块标识符,传递给 require() 进行加载的时候,有三种加载方式:
- 在被加载的目录下查找一个叫做 package.json 的文件,并寻找 main 属性,作为 require() 加载的入口
- 如果目录里没有 package.json 文件,或者 main 入口不存在或无法解析,则 Node.js 将会试图加载目录下的
index.js文件。 - 如果以上两步都失败了,则 Node.js 会在终端打印错误消息,报告模块的缺失:Error: Cannot find module ‘xxx’
3、框架
3.1、Express
Express 的中文官网: http://www.expressjs.com.cn/
Express 是基于 Node.js 平台,快速、开放、极简的 Web 开发框架
Express 的本质:就是一个 npm 上的第三方包,提供了快速创建 Web 服务器的便捷方法。
- Web 网站服务器:专门对外提供
Web 网页资源的服务器。 - API 接口服务器:专门对外提供
API 接口的服务器。
使用 Express,我们可以方便、快速的创建 Web 网站的服务器或 API 接口的服务器。
3.1.1、Express 基本使用
3.1.1.1 使用
- 安装
在项目所处的目录中,运行如下的终端命令,即可将 express 安装到项目中使用:
npm i express
- 创建基本的 Web 服务器
// 1. 导入 express
const express = require('express')
// 2. 创建 web 服务器
const app = express()
// 3. 调用 app.listen(端口号,启动成功后的回调函数),启动服务器
app.listen(80,()=>{
console.log("express server running at http://127.0.0.1")
})
- 监听
GET 请求
通过 app.get() 方法,可以监听客户端的 GET 请求,具体的语法格式如下:
/**
* 参数1:客户端请求的 URL 地址
* 参数2:请求对应的处理函数
* req:请求对象(包含了请求相关的属性与方法)
* res:响应对象(包含了响应相关的属性与方法)
*/
app.get('请求的URL', function(req,res){
// 处理的函数
})
- 监听
POST 请求
通过app.post()方法,可以监听客户端的 POST 请求,具体的语法格式如下:
/**
* 参数1:客户端请求的 URL 地址
* 参数2:请求对应的处理函数
* req:请求对象(包含了请求相关的属性与方法)
* res:响应对象(包含了响应相关的属性与方法)
*/
app.get('请求的URL', function(req,res){
// 处理的函数
})
- 把内容响应给客户端
通过res.send()方法,可以把处理好的内容,发送给客户端:
app.get('/user',(req,res) => {
// 向客户端发送 json 对象
res.send({name:'zs',age:20,gender:'男'})
})
app.post('/user',(req,res) => {
// 向客户端发送文本内容
res.send('请求成功!')
})
- 获取 URL 中携带的查询参数
通过req.query对象,可以访问到客户端通过查询字符串的形式,发送到服务器的参数:
app.get('/',(req,res) => {
// req.query 默认是一个空对象
// 客户端使用 ?name=zs&age=20 这种查询字符串形式,发送到服务器的参数
// 可以通过 req.query 对象访问到,如:
// req.query.name req.query.age
console.log(req.query)
})
- 获取 URL 中的动态参数
通过req.params对象,可以访问到 URL 中,通过:匹配到的动态参数:
// URL 地址中,可以通过 :参数名 的形式,动态匹配参数值
app.get('/user/:id',(req,res) => {
// req.params 默认是一个空对象
// 里面存放着通过 : 动态匹配的参数值
console.log(req.params)
})
3.1.1.2 托管静态资源
express.static()
express 提供了一个非常好用的函数,叫做 express.static(),通过它,我们可以非常方便地创建一个静态资源服务器
例如,通过如下代码就可以将 public 目录下的图片、CSS 文件、JavaScript 文件对外开放访问了
app.use(express.static('public'))
现在,就可以访问 public 目录中的所有文件了:
http://localhost:3000/images/bg.jpg
http://localhost:3000/css/style.css
http://localhost:3000/js/login.js
注意:Express 在指定的静态目录中查找文件,并对外提供资源的访问路径。因此,存放静态文件的目录名不会出现在 URL 中
- 托管多个静态资源目录
如果要托管多个静态资源目录,请多次调用 express.static() 函数:
app.use(express.static('public'))
app.use(express.static('files'))
访问静态资源文件时,express.static() 函数会根据目录的添加顺序查找所需的文件。
- 挂载路径前缀
如果希望在托管的静态资源访问路径之前,挂载路径前缀,则可以使用如下的方式:
app.use('/public',express.static('public'))
现在,就可以通过带有 /public 前缀地址来访问 public 目录中的文件了:
http://localhost:3000/public/images/kitten.jpg
http://localhost:3000/public/css/style.css
http://localhost:3000/public/js/app.js
3.1.1.3 nodemon
在编写调试 Node.js 项目的时候,如果修改了项目的代码,则需要频繁的手动 close 掉,然后再重新启动,非常繁琐。
现在,我们可以使用 nodemon(https://www.npmjs.com/package/nodemon) 这个工具,它能够监听项目文件的变动,当代码被修改后,nodemon 会自动帮我们重启项目,极大方便了开发和调试。
- 安装 nodemon
在终端中,运行如下命令,即可将 nodemon 安装为全局可用的工具
npm install -g nodemon
- 使用 nodemon
当基于 Node.js 编写了一个网站应用的时候,传统的方式,是运行node app.js命令,来启动项目。
这样做的坏处是:代码被修改之后,需要手动重启项目。
现在,可以将 node 命令替换为 nodemon 命令,使用 nodemon app.js 来启动项目。这样做的好处是:代码被修改之后,会被 nodemon 监听到,从而实现自动重启项目的效果
3.1.2、Express 路由
路由就是映射关系
在 Express 中,路由指的是客户端的请求与服务器处理函数之间的映射关系。
Express 中的路由分 3 部分组成,分别是请求的类型、请求的 URL 地址、处理函数,格式如下:
app.METHOD(PATH,HANDLER)
Express 中的路由的例子:
// 匹配 GET 请求,且开启功能球 URL 为 /
app.get('/',function(req,res){
res.send("Hello World!")
})
// 匹配 POST 请求,且请求 URL 为 /
app.post('/',function(req,res){
res.send('Got a POST request')
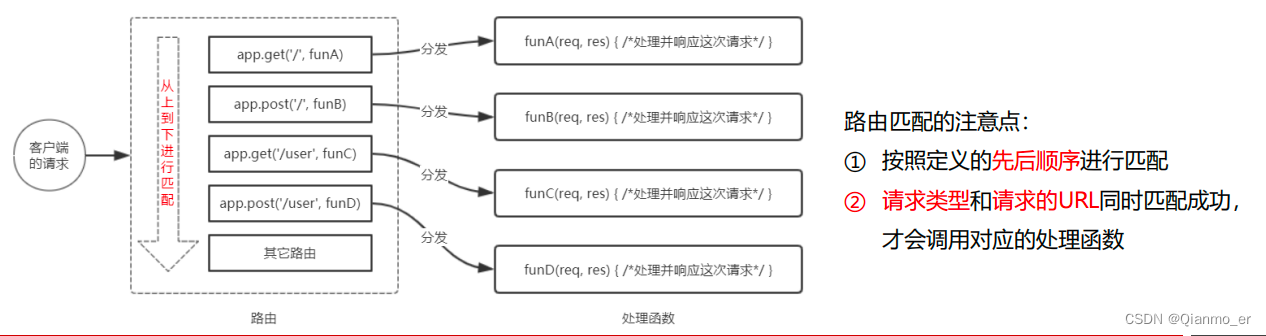
})
每当一个请求到达服务器之后,需要先经过路由的匹配,只有匹配成功之后,才会调用对应的处理函数。
在匹配时,会按照路由的顺序进行匹配,如请求类型和请求的 URL 同时匹配成功,则 Express 会将这次请求,转交给对应的 function 函数进行处理。
3.1.2.1 路由的使用
- 最简单的用法
在 Express 中使用路由最简单的方式,就是把路由挂载到 app 上,示例代码如下:
const express = require('express')
// 创建 Web 服务器,命名为 app
const app = express()
// 挂载路由
app.get('/',(req,res) => {
res.send('Hello World!')
})
app.post('/',(req,res) => {
res.send('Post Request')
})
// 启动 Web 服务器
app.listen(80,() => {
console.log('server running at http:127.0.0.1')
})
- 模块化路由
为了方便对路由进行模块化的管理,Express 不建议将路由直接挂载到 app 上,而是推荐将路由抽离为单独的模块。
将路由抽离为单独模块的步骤如下:
① 创建路由模块对应的 .js 文件
② 调用 express.Router() 函数创建路由对象
③ 向路由对象上挂载具体的路由
④ 使用 module.exports 向外共享路由对象
⑤ 使用 app.use() 函数注册路由模块
- 创建路由模块
// 1. 导入 express
var express = require('express')
// 2. 创建路由对象
var router = express.Router()
// 3. 挂载获取用户列表的路由
router.get('/user/list',function(req,res){
res.send('Get user list.')
})
// 4. 挂载添加用户的路由
router.post('/user/add',function(req,res){
res.send('Add new user.')
})
// 5. 向外到处路由对象
module.exports = router
- 注册路由模块
// 1. 导入路由模块
const userRouter = require('./router/user.js')
// 2. 使用 app.use() 注册路由模块
app.use(userRouter)
- 为路由模块添加前缀
类似于托管静态资源时,为静态资源统一挂载访问前缀一样,路由模块添加前缀的方式也非常简单:
// 1. 导入路由模块
const userRouter = require('./router/user.js')
// 2. 使用 app.use() 注册路由模块,并添加统一的访问前缀 /api
app.use('/api',userRouter)
3.1.3、Express 中间件
中间件(Middleware ),特指业务流程的中间处理环节。
Express 中间件的调用流程:
当一个请求到达 Express 的服务器之后,可以连续调用多个中间件,从而对这次请求进行预处理。
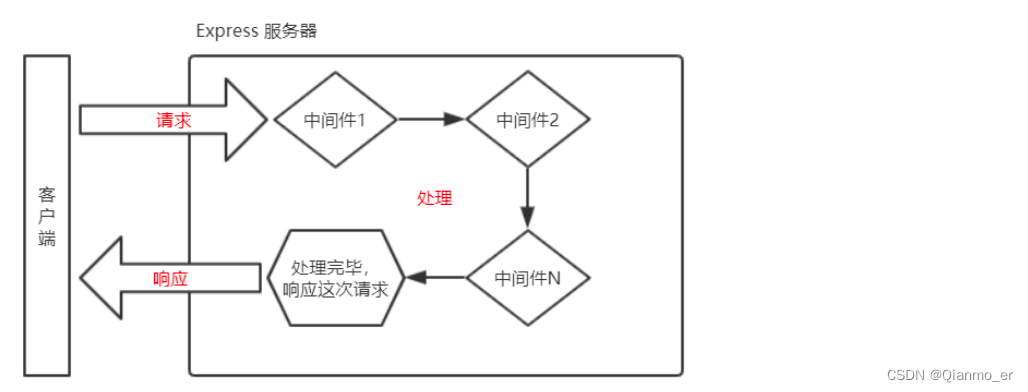
Express 中间件的格式:
Express 的中间件,本质上就是一个 function 处理函数,Express 中间件的格式如下:

next 函数的作用
next 函数是实现多个中间件连续调用的关键,它表示把流转关系转交给下一个中间件或路由
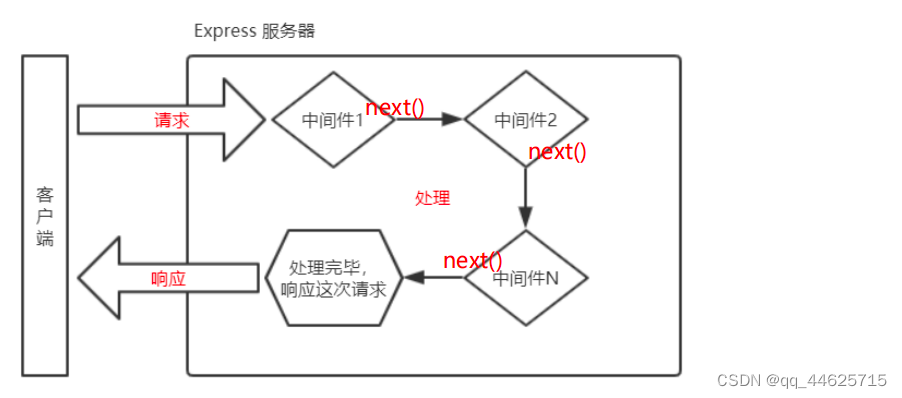
3.1.3.1 使用
- 定义中间件函数
可以通过如下的方式,定义一个最简单的中间件函数:
// 常量 mw 所指向的,就是一个中间件函数
const mw = function(req,res,next){
console.log('这是一个最简单的中间件函数')
// 注意:在当前中间件的业务处理完毕前,必须调用 next() 函数
next()
}
- 全局生效的中间件
客户端发起的任何请求,到达服务器之后,都会触发的中间件,叫做全局生效的中间件。
通过调用app.use(中间件函数),即可定义一个全局生效的中间件,示例代码如下:
// 常量 mw 所指向的,就是一个中间件函数
const mw = function(req,res,next){
console.log('这是一个最简单的中间件函数')
next()
}
// 全局生效的中间件
app.use(mw)
- 定义
全局中间件的简化形式
// 全局生效的中间件
app.use(function(req,res,next){
console.log('这是一个最简单的中间件函数')
next()
})
- 中间件的作用
多个中间件之间,共享同一份 req 和 res。基于这样的特性,我们可以在上游的中间件中,统一为 req 或 res 对象添加自定义的属性或方法,供下游的中间件或路由进行使用
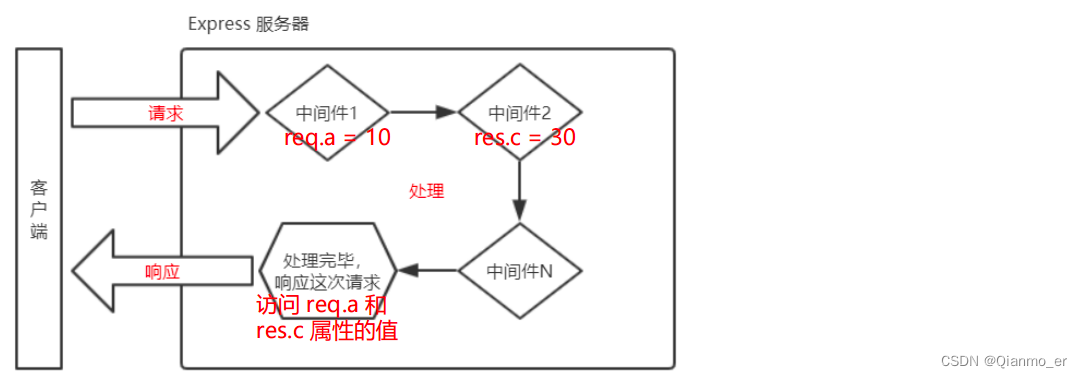
- 定义多个全局中间件
可以使用 app.use() 连续定义多个全局中间件。客户端请求到达服务器之后,会按照中间件定义的先后顺序依次进行调用,示例代码如下
// 第一个全局中间件
app.use(function(req,res,next){
console.log('调用了第一个全局中间价')
next()
})
// 第二个全局中间件
app.use(function(req,res,next){
console.log('调用了第二个全局中间价')
next()
})
// 请求这个路由,依次触发全局中间件
app.get('/user',(req,res) => {
res.send('Home page.')
})
- 局部生效的中间件
不使用app.use()定义的中间件,叫做局部生效的中间件,示例代码如下:
// 定义中间件函数 mw1
const mw1 = function(req,res,next){
console.log('这是中间件函数')
next()
}
// mw1 这个中间件只在“当前路由中生效”,这种用法属于“局部生效的中间件”
app.get('/',mw1,function(req,res){
res.send('Home page.')
})
// mw1 这个中间件不会影响下面这个路由
app.get('user',function(req,res){
rees.send('User page.')
})
- 定义多个局部中间件
可以在路由中,通过如下两种等价的方式,使用多个局部中间件:
// 以下两种写法是“完全等价”
app.get('/',mw1,mw2,(req,res) => {
res.send('Home Page.')
})
app.get('/',[mw1,mw2],(req,res) => {
res.send('Home Page.')
})
- 了解中间件的5个使用注意事项
① 一定要在路由之前注册中间件
② 客户端发送过来的请求,可以连续调用多个中间件进行处理
③ 执行完中间件的业务代码之后,不要忘记调用 next() 函数
④ 为了防止代码逻辑混乱,调用 next() 函数后不要再写额外的代码
⑤ 连续调用多个中间件时,多个中间件之间,共享req 和 res 对象
3.1.3.2 中间件的分类
Express 官方把常见的中间件用法,分成了 5 大类,分别是:
① 应用级别的中间件
② 路由级别的中间件
③ 错误级别的中间件
④ Express 内置的中间件
⑤ 第三方的中间件
- 应用级别的中间件
通过app.use()或app.get()或app.post(),绑定到 app 实例上的中间件,叫做应用级别的中间件,代码示例如下:
// 应用级别的中间件(全局中间件)
app.use((req,res,next) => {
next()
})
// 应用级别的中间件(局部中间件)
app.get('/',mw1,(req,res) => {
res.send('Home page.')
})
- 路由级别的中间件
绑定到express.Router()实例上的中间件,叫做路由级别的中间件。它的用法和应用级别中间件没有任何区别。
只不过,应用级别中间件是绑定到 app 实例上,路由级别中间件绑定到 router 实例上,代码示例如下:
var app = express()
var router = express.Router()
// 路由级别的中间件
router.use(function(req,res,next){
console.log('Time',Date.now())
next()
})
app.use('/',router)
- 错误级别的中间件
错误级别中间件的作用:专门用来捕获整个项目中发生的异常错误,从而防止项目异常崩溃的问题。
格式:
错误级别中间件的 function 处理函数中,必须有 4 个形参,形参顺序从前到后,分别是 (err, req, res, next)。
// 1.路由
app.get('/',function(req,res){
// 1.1 抛出一个自定义的错误
throw new Error('服务器内部发生了错误!')
res.send('Home Page.')
})
// 2. 错误级别的中间件
app.use(function(err,req,res,next){
// 2.1 在服务器打印错误消息
cosnole.log('发生了错误:' + err.message)
// 2.2 向客户端响应错误相关的内容
res.send('Error!' + err.message)
})
注意:错误级别的中间件,必须注册在所有路由之后!
错误级别中间件的 function 处理函数中,必须有 4 个形参,形参顺序从前到后,分别是 (err, req, res, next)。
- Express内置的中间件
自 Express 4.16.0 版本开始,Express 内置了 3 个常用的中间件,极大的提高了 Express 项目的开发效率和体验:
express.static快速托管静态资源的内置中间件,例如: HTML 文件、图片、CSS 样式等(无兼容性)express.json解析 JSON 格式的请求体数据(有兼容性,仅在 4.16.0+ 版本中可用)express.urlencoded解析 URL-encoded 格式的请求体数据(有兼容性,仅在 4.16.0+ 版本中可用)
// 配置解析 application/json 格式数据的内置中间件
app.use(express.json())
// 配置解析 application/x-www-form-urlencoded 格式数据的内置中间件
app.use(express.urlencoded({ extended:false }))
- 第三方的中间件
非 Express 官方内置的,而是由第三方开发出来的中间件,叫做第三方中间件。在项目中,大家可以按需下载并配置第三方中间件,从而提高项目的开发效率。
例如:在 express@4.16.0 之前的版本中,经常使用 body-parser 这个第三方中间件,来解析请求体数据。使用步骤如下:
① 运行 npm install body-parser 安装中间件
② 使用 require 导入中间件
③ 调用 app.use() 注册并使用中间件
注意:Express 内置的 express.urlencoded 中间件,就是基于 body-parser 这个第三方中间件进一步封装出来的
3.1.3.3 自定义中间件
-
需求描述与实现步骤
自己手动模拟一个类似于express.urlencoded这样的中间件,来解析 POST 提交到服务器的表单数据。
实现步骤:
① 定义中间件
② 监听 req 的 data 事件
③ 监听 req 的 end 事件
④ 使用 querystring 模块解析请求体数据
⑤ 将解析出来的数据对象挂载为 req.body
⑥ 将自定义中间件封装为模块 -
定义中间件
使用 app.use() 来定义全局生效的中间件,代码如下:
// 1. 定义中间件:使用 app.use() 来定义全局生效的中间件
app.use(function(req.res.next){
// 中间件的业务逻辑
})
- 监听 req 的 ==data ==事件
在中间件中,需要监听 req 对象的 data 事件,来获取客户端发送到服务器的数据。
如果数据量比较大,无法一次性发送完毕,则客户端会把数据切割后,分批发送到服务器。所以 data 事件可能会触发多次,每一次触发 data 事件时,获取到数据只是完整数据的一部分,需要手动对接收到的数据进行拼接
// 定义变量,用来存储客户端发送过来的请求数据
let str = ''
// 监听 req 对象的 data 事件(客户端发送过来的请求数据)
req.on('data',(chunk) => {
// 拼接请求体数据,隐式转换字符串
str += chunk
})
- 监听 req 的 end事件
当请求体数据接收完毕之后,会自动触发 req 的 end 事件。
因此,我们可以在 req 的 end 事件中,拿到并处理完整的请求体数据。示例代码如下:
// 监听 req 对象的 end 事件(请求体发送完毕后自动触发)
req.on('end',() => {
// 打印完整的请求体数据
console.log(str)
// TODO:吧字符串格式的请求体数据,解析成对象格式
})
- 使用 querystring 模块解析请求体数据
Node.js 内置了一个querystring模块,专门用来处理查询字符串。通过这个模块提供的parse()函数,可以轻松把查询字符串,解析成对象的格式。示例代码如下:
// 导入处理 querystring 的 Node.js 内置模块
const qs = require('querystring')
// 调用 qs.parse() 方法,把查询字符串解析为对象
const body = qs.parse(str)
- 将解析出来的数据对象挂载为
req.body
上游的中间件和下游的中间件及路由之间,共享同一份 req 和 res。因此,我们可以将解析出来的数据,挂载为 req 的自定义属性,命名为req.body,供下游使用。示例代码如下:
req.on('end'() => {
// 调用 qs.parse() 方法,把查询字符串解析为对象
const body = qs.parse(str)
// 将解析出来的请求对象,挂载为 req.body 属性
req.body = body
// 一定要调用 next() 函数,执行后续的业务逻辑
next()
})
- 将自定义中间件封装为模块
为了优化代码的结构,我们可以把自定义的中间件函数,封装为独立的模块,示例代码如下:
// custom-body-parse.js 模块中的代码
const qs = require('querystring')
function bodyParse(req,res,next){}
// 向外导出解析请求数据的中间函数
module.exports = bodyParse
// 1. 导入自定义的中间件
const myBodyParse = requery('custom-body-parse.js')
// 2. 注册自定义的中间件模块
app.use(myBodyParse)
完整代码:
// 导入处理 querystring 的 Node.js 内置模块
const qs = require('querystring')
// 调用 qs.parse() 方法,把查询字符串解析为对象
const body = qs.parse(str)
// 1. 定义中间件:使用 app.use() 来定义全局生效的中间件
app.use(function(req.res.next){
// 定义变量,用来存储客户端发送过来的请求数据
let str = ''
// 监听 req 对象的 data 事件(客户端发送过来的请求数据)
req.on('data',(chunk) => {
// 拼接请求体数据,隐式转换字符串
str += chunk
})
// 监听 req 对象的 end 事件(请求体发送完毕后自动触发)
req.on('end',() => {
// 打印完整的请求体数据
console.log(str)
// TODO:吧字符串格式的请求体数据,解析成对象格式
})
// 将解析出来的数据对象挂载为 req.body
req.on('end'() => {
// 调用 qs.parse() 方法,把查询字符串解析为对象
const body = qs.parse(str)
// 将解析出来的请求对象,挂载为 req.body 属性
req.body = body
// 一定要调用 next() 函数,执行后续的业务逻辑
next()
})
})
3.1.4、使用 Express 写接口
3.1.4.1 创建基本的服务器
// 导入 express 模块
const express = require('express')
// 创建 express 的服务器实例
const app = express()
// 这里写你的代码...
// 调用 app.listen 方法,指定端口号并启动Web服务器
app.listen(80,function(){
console.log('Express server running at http://127.0.0.1')
})
3.1.4.2 创建 API 路由模块
apiRouter.js【路由模块】
const express = require('express')
const apiRouter = express.Router()
// 这里可以写其他路由...
module.exports = apiRouter
app.js 【导入并注册路由模块】
const apiRouter = require('./apiRouter.js')
app.use('/api',apiRouter)
3.1.4.3 编写 GET 接口
apiRouter.get('/get',(req,res) => {
// 1. 获取到客户端通过查询字符串,发送到服务器的数据
const query = req.query
// 2. 调用 res.send() 方法,把数据响应给客户端
res.send({
status:0, // 状态,0 表示成功,1表示失败
msg:'GET请求成功!' // 状态描述
data:query // 需要响应给客户端的具体数据
})
})
3.1.4.4 编写 POST 接口
apiRouter.post('/post',(req,res) => {
// 1. 获取客户端通过请求体,发送到服务器的 URL-encoded 数据
const body = req.body
// 2. 调用 res.send() 方法,把数据响应改客户端
res.send({
status:0,
meg:'POST请求成功!',
data:body
})
})
3.1.4.5 CORS 跨域资源共享
- 接口的跨域问题
刚才编写的 GET 和 POST接口,存在一个很严重的问题:不支持跨域请求。
解决接口跨域问题的方案主要有两种:
① CORS(主流的解决方案,推荐使用)
② JSONP(有缺陷的解决方案:只支持 GET 请求)
-
使用 cors 中间件解决跨域问题
cors 是 Express 的一个第三方中间件。通过安装和配置 cors 中间件,可以很方便地解决跨域问题。
使用步骤分为如下 3 步:
① 运行npm install cors安装中间件
② 使用const cors = require('cors')导入中间件
③ 在路由之前调用app.use(cors())配置中间件 -
什么是 CORS
CORS (Cross-Origin Resource Sharing,跨域资源共享)由一系列 HTTP 响应头组成,这些 HTTP 响应头决定浏览器是否阻止前端 JS 代码跨域获取资源。
浏览器的同源安全策略默认会阻止网页“跨域”获取资源。但如果接口服务器配置了 CORS 相关的 HTTP 响应头,就可以解除浏览器端的跨域访问限制。
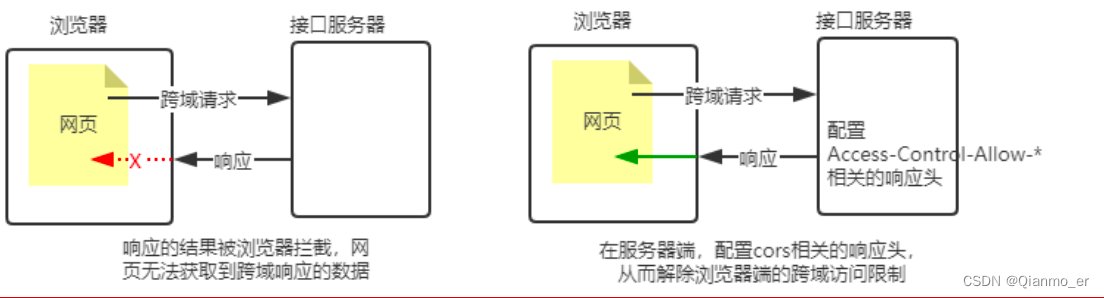
4. CORS 的注意事项
① CORS 主要在服务器端进行配置。客户端浏览器无须做任何额外的配置,即可请求开启了 CORS 的接口。
② CORS 在浏览器中有兼容性。只有支持 XMLHttpRequest Level2 的浏览器,才能正常访问开启了 CORS 的服务端接口(例如:IE10+、Chrome4+、FireFox3.5+)。
- CORS 响应头部 - Access-Control-Allow-Origin
响应头部中可以携带一个Access-Control-Allow-Origin字段,其语法如下:

其中,origin 参数的值指定了允许访问该资源的外域 URL。
例如,下面的字段值将只允许来自 http://itcast.cn 的请求:
res.setHeader('Access-Control-Allow-Origin','http://itcast.cn')
如果指定了 Access-Control-Allow-Origin 字段的值为通配符 *,表示允许来自任何域的请求,示例代码如下:
res.setHeader('Access-Control-Allow-Origin','*')
- CORS 响应头部 - Access-Control-Allow-Headers
默认情况下,CORS 仅支持客户端向服务器发送如下的 9 个请求头:
Accept、Accept-Language、Content-Language、DPR、Downlink、Save-Data、Viewport-Width、Width 、Content-Type (值仅限于 text/plain、multipart/form-data、application/x-www-form-urlencoded 三者之一)
如果客户端向服务器发送了额外的请求头信息,则需要在服务器端,通过 Access-Control-Allow-Headers 对额外的请求头进行声明,否则这次请求会失败!
// 允许客户端额外向服务器发送 Content-Type 请求头和 x-Custom-Header 请求头
// 多个请求头之间使用英文逗号进行分割
res.setHeader('Access-Control-Allow-Headers','Content-Type','x-Custom-Header')
- CORS 响应头部 - Access-Control-Allow-Methods
默认情况下,CORS 仅支持客户端发起 GET、POST、HEAD 请求。
如果客户端希望通过PUT、DELETE等方式请求服务器的资源,则需要在服务器端,通过 Access-Control-Alow-Methods来指明实际请求所允许使用的 HTTP 方法。
示例代码如下:
// 只允许 POST、GET、DELETE、HEAD 请求方法
res.setHeader('Access-Control-Allow-Headers','POST,GET,DELETE,HEAD')
// 只允许所有的 HTTP 请求方法
res.setHeader('Access-Control-Allow-Method','*')
- CORS请求的分类
客户端在请求 CORS 接口时,根据请求方式和请求头的不同,可以将 CORS 的请求分为两大类,分别是:
-
简单请求
同时满足以下两大条件的请求,就属于简单请求:
- 请求方式:GET、POST、HEAD 三者之一
- HTTP 头部信息不超过以下几种字段:无自定义头部字段、Accept、Accept-Language、Content-Language、DPR、
Downlink、Save-Data、Viewport-Width、Width 、Content-Type(只有三个值application/x-www-formurlencoded、multipart/form-data、text/plain) -
预检请求
只要符合以下任何一个条件的请求,都需要进行预检请求:
- 请求方式为 GET、POST、HEAD 之外的请求 Method 类型
- 请求头中包含自定义头部字段
- 向服务器发送了 application/json 格式的数据
在浏览器与服务器正式通信之前,浏览器会先发送 OPTION 请求进行预检,以获知服务器是否允许该实际请求,所以这一次的 OPTION 请求称为“预检请求”。
服务器成功响应预检请求后,才会发送真正的请求,并且携带真实数据。
- 简单请求和预检请求的区别
简单请求的特点:客户端与服务器之间只会发生一次请求。
预检请求的特点:客户端与服务器之间会发生两次请求,OPTION 预检请求成功之后,才会发起真正的请求
3.1.4.6 JSONP 接口
概念:浏览器端通过
- 创建 JSONP 接口的注意事项
如果项目中==已经配置了 CORS ==跨域资源共享,为了防止冲突,必须在配置 CORS 中间件之前声明 JSONP 的接口。
否则JSONP 接口会被处理成开启了 CORS 的接口。示例代码如下:
// 优化创建 JSONP 接口【这个接口不会被处理成 CORS 接口】
app.get('/api/jsonp',(req,res) => {})
// 在配置 CORS 中间件【后续的所有接口,都会被处理成 CORS 接口】
app.use(cors())
// 这是一个开启了 CORS 的接口
app.get('/api/get',(req,res) => {})
-
实现 JSONP 接口的步骤
① 获取客户端发送过来的回调函数的名字
② 得到要通过 JSONP 形式发送给客户端的数据
③ 根据前两步得到的数据,拼接出一个函数调用的字符串
④ 把上一步拼接得到的字符串,响应给客户端的<script>标签进行解析执行 -
实现 JSONP 接口的具体代码
app.get('/api/jsonp',(req,res) => {
// 1. 获取客户端发送过来的回调函数的名字
const funcName = req.query.callback
// 2. 得到要通过 JSONP 形式发送给客户端的数据
const data = { name:'zs',age:22 }
// 3. 根据前两步得到的数据,并拼接一个函数调用的字符串
const scriptStr = `${funcName}(${JSON.stringify(data)})`
// 4. 把上一步拼接得到的字符串,响应给客户端的 <script> 标签进行解析执行
res.send(scriptStr)
})
- 在网页中使用 jQuery 发起 JSONP 请求
调用$.ajax()函数,提供 JSONP 的配置选项,从而发起 JSONP 请求,示例代码如下:
$('#btnJSONP').on('click',function(){
$.ajax({
method:'GET',
url:'http://127.0.0.1/api/jsonp',
dataType:'jsonp', // 表示要发起 jsonp 请求
success:function(res){
console.log(res)
}
})
})
3.2、Koa2
官网:https://koa.bootcss.com/#application
3.2.1、开始工作
3.2.1.1 项目初始化
执行 npm init -y, 生成package.json
npm init -y
3.2.1.2 安装Koa
npm i koa
3.2.1.3 编写服务程序
编写src/01_quickstart.js
- 导入koa包
- 实例化app对象
- 编写中间件
- 启动服务, 监听3000端口
// 一. 导入koa
const Koa = require('koa')
// 二. 实例化对象
const app = new Koa()
// 三. 编写中间件
app.use((ctx) => {
ctx.body = 'hello Koa2'
})
// 四. 启动服务
app.listen(3000, () => {
console.log('server is running on http://localhost:3000')
})
注意:
如果没有通过ctx.body返回给客户端, 最终会得到Not Found
3.2.2、中间件
3.2.2.1 基本概念
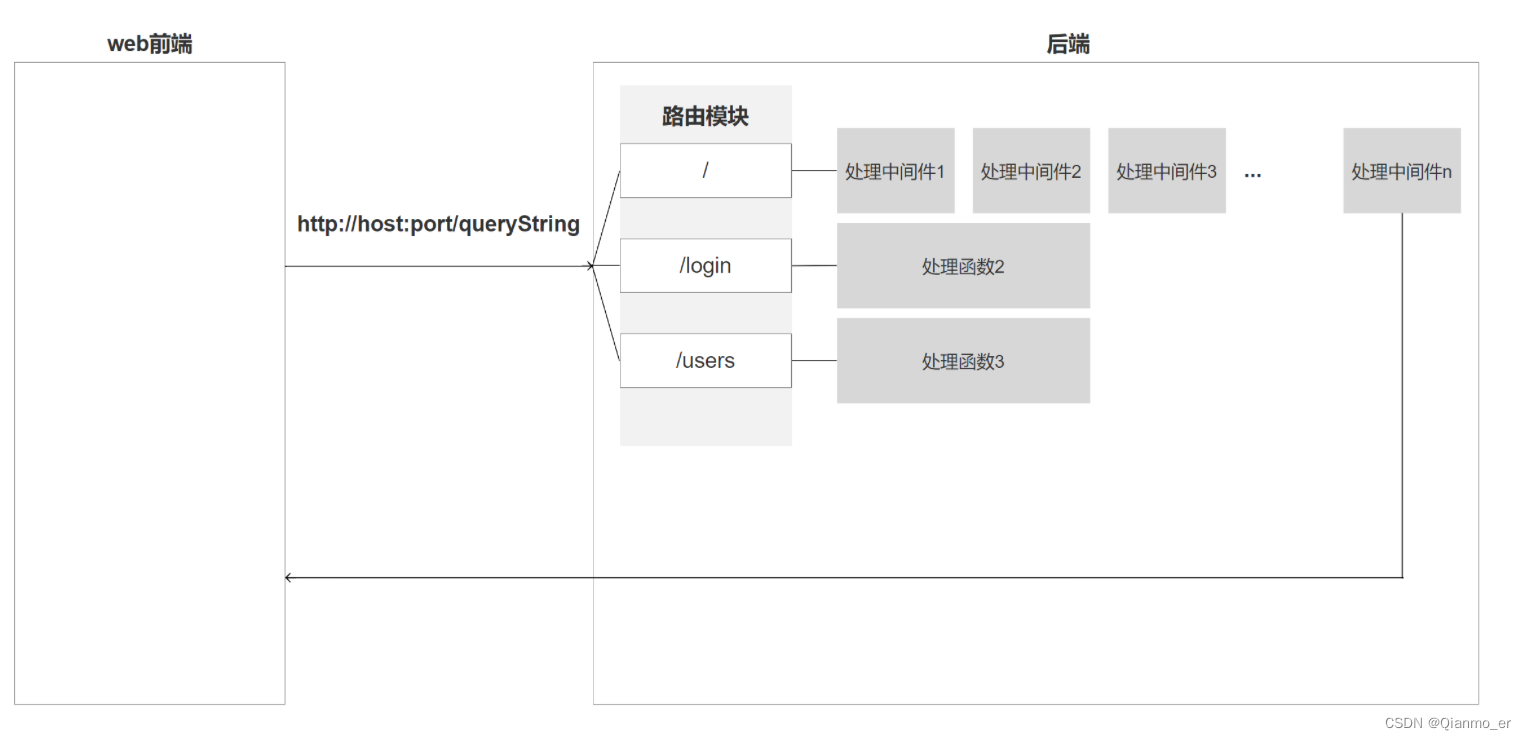
- 什么叫中间件
它在请求和响应中间的处理程序
从请求到响应的业务比较复杂, 将这些复杂的业务拆开成一个个功能独立的函数, 就是中间件。
中间件函数,帮助拆解主程序的业务逻辑,
并且每一个的中间件函数处理的结果都会传递给下一个中间件函数。
就好比工厂里流水线工人清洗一个箱子:
第一个人清洗侧面,第二个人清洗底面,第三个人清洗顶面,。。。
这条流水线结束后,箱子也就清洗干净了
各做各的,不相互影响,又彼此协作
- 基本使用
编写src/02_middleware.js
// 一. 导入koa
const Koa = require('koa')
// 二. 实例化对象
const app = new Koa()
// 三. 编写中间件
app.use((ctx, next) => {
console.log('我来组成身体')
next()
})
app.use((ctx, next) => {
console.log('我来组成头部')
next()
})
app.use((ctx) => {
console.log('---------')
ctx.body = '组装完成'
})
// 四. 启动服务
app.listen(3000, () => {
console.log('server is running on http://localhost:3000')
})
输出结果
我来组成身体
我来组成头部
- 链式调用
app.use实际上会返回this
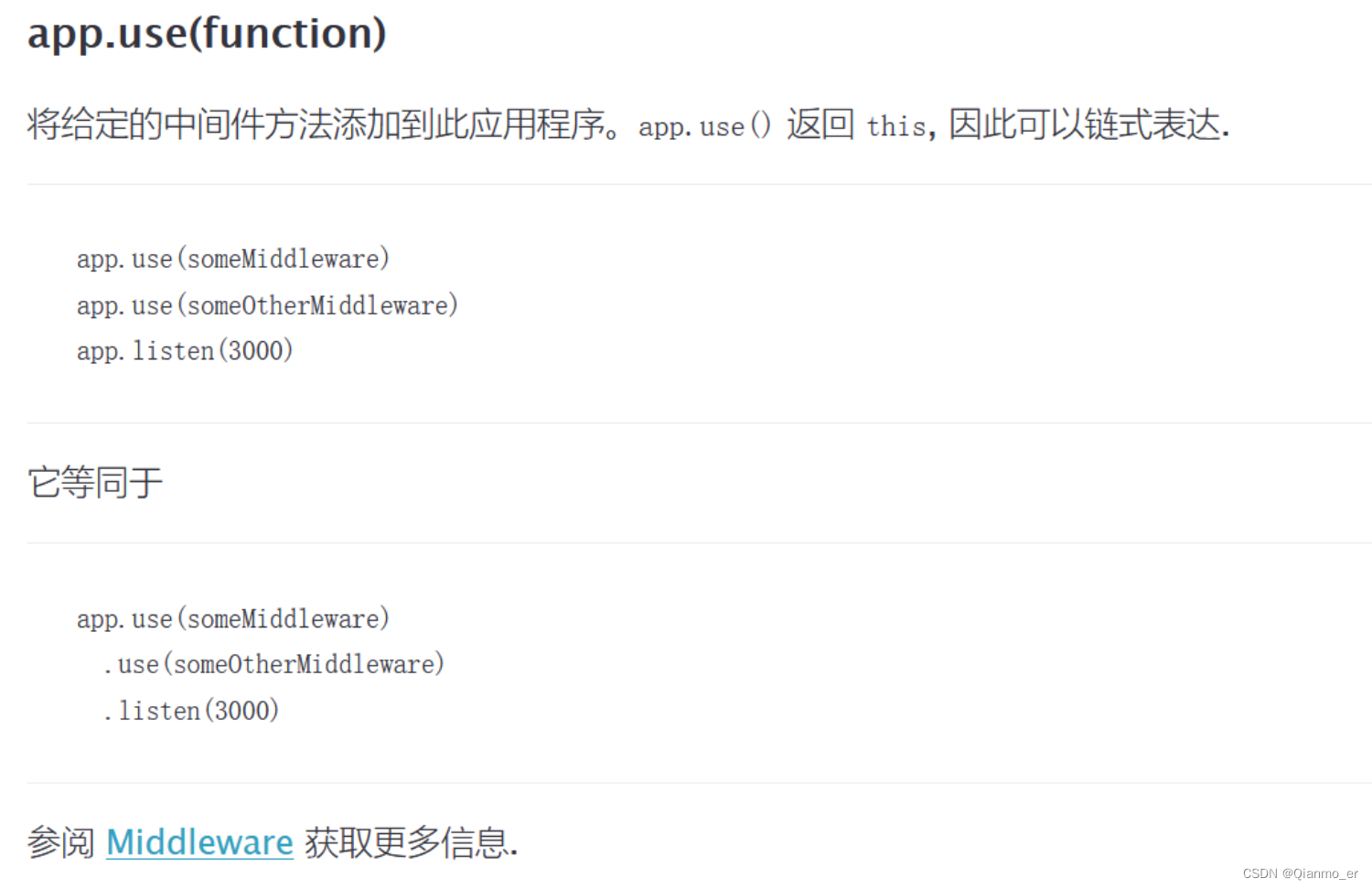
上述代码可以写成:
// 一. 导入koa
const Koa = require('koa')
// 二. 实例化对象
const app = new Koa()
// 三. 编写中间件
app
.use((ctx, next) => {
console.log('我来组成身体')
next()
})
.use((ctx, next) => {
console.log('我来组成头部')
next()
})
.use((ctx) => {
console.log('---------')
ctx.body = '组装完成'
})
// 四. 启动服务
app.listen(3000, () => {
console.log('server is running on http://localhost:3000')
})
注意:
在use中, 一次只能接受一个函数做为参数
3.2.2.2 洋葱圈模型

// 1. 导入koa包
const Koa = require('koa')
// 2. 实例化对象
const app = new Koa()
// 3. 编写中间件
app.use((ctx, next) => {
console.log(1)
next()
console.log(2)
console.log('---------------')
ctx.body = 'hello world'
})
app.use((ctx, next) => {
console.log(3)
next()
console.log(4)
})
app.use((ctx)=>{
console.log(5)
})
// 4. 监听端口, 启动服务
app.listen(3000)
console.log('server is running on http://localhost:3000')
3.2.2.3 异步处理
如果中间件中存在一些异步的代码, Koa也提供了统一的处理方式.
首先, 我们要了解async await语法
-
async await语法
- async: 声明异步函数
- await: 后跟一个promise对象
如果要使用await, 需要在函数声明前加上async
-
示例
需求:
- 在middleware1中, 构造一个message = aa
- 在middleware2中, 同步追加bb
- 在middleware3中, 异步追加cc
- 最终在middleware1中, 通过body返回数据
app.use(async (ctx,next) => {
ctx.message = 'aa'
await next()
ctx.body = ctx.message
})
app.use(async (ctx,next) => {
ctx.message += 'bb'
await next()
})
app.use(async (ctx) => {
// 返回一个Promise对象,状态 fulfilled ,结果cc
const res =awit Promise.resolve('cc')
ctx.message += res
})
3.2.3、路由
3.2.3.1 概念
- 建立URL和处理函数之间的对应关系
- 主要作用: 根据不同的
Method和URL返回不同的内容
需求
根据不同的Method+URL, 返回不同的内容
- Get 请求/, 返回’这是主页’
- Get 请求/users, 返回’这是用户页’
- Post请求/users, 返回’创建用户’
// 一. 导入koa
const Koa = require('koa')
// 二. 实例化对象
const app = new Koa()
// 三. 编写中间件
app.use((ctx) => {
if (ctx.url == '/') {
ctx.body = '这是主页'
} else if (ctx.url == '/users') {
if (ctx.method == 'GET') {
ctx.body = '这是用户列表页'
} else if (ctx.method == 'POST') {
ctx.body = '创建用户'
} else {
ctx.status = 405 // 不支持的请求方法
}
} else {
ctx.status = 404
}
})
// 四. 启动服务
app.listen(3000, () => {
console.log('server is running on http://localhost:3000')
})
3.2.3.2 使用 koa-router
- 安装
npm i koa-router
- 使用
在koa的基础上
- 导入
koa-router包 - 实例化
router对象 - 使用
router处理路由 - 注册中间件
// 一. 导入koa
const Koa = require('koa')
// 二. 实例化对象
const app = new Koa()
// 三. 导入koa-router, 实例化路由对象
const Router = require('koa-router')
const router = new Router()
router.get('/', (ctx) => {
ctx.body = '这是主页'
})
router.get('/users', (ctx) => {
ctx.body = '这是用户页'
})
router.post('/users', (ctx) => {
ctx.body = '创建用户页'
})
// 四. 注册路由中间件
app.use(router.routes())
app.use(router.allowedMethods())
// 五. 启动服务
app.listen(3000, () => {
console.log('server is running on http://localhost:3000')
})
- 优化
最好将一个模块放到一个单独的文件中. 分离出一个router路由层创建src/router/user.route.js
// 导入koa-router, 实例化路由对象
const Router = require('koa-router')
const router = new Router()
router.get('/users', (ctx) => {
ctx.body = '这是用户页'
})
router.post('/users', (ctx) => {
ctx.body = '创建用户页'
})
module.exports = router
再导入
// 一. 导入koa
const Koa = require('koa')
// 二. 实例化对象
const app = new Koa()
const userRouter = require('./router/user.route')
// 四. 注册路由中间件
app.use(userRouter.routes()).use(userRouter.allowedMethods())
// 五. 启动服务
app.listen(3000, () => {
console.log('server is running on http://localhost:3000')
})
可以进一步优化, 使代码更加简洁
给路由设置一个统一的前缀
// 导入koa-router, 实例化路由对象
const Router = require('koa-router')
const router = new Router({ prefix: '/users' })
router.get('/', (ctx) => {
ctx.body = '这是用户页'
})
router.post('/', (ctx) => {
ctx.body = '创建用户页'
})
module.exports = router
3.2.4、请求参数解析
3.2.4.1 为什么要请求参数解析
在很多场景中, 后端都需要解析请求的参数, 做为数据库操作的条件
场景一
前端希望通过请求, 获取id=1的用户信息

接口设计
GET /users/:id
场景二
前端希望查询年龄在18到20的用户信息
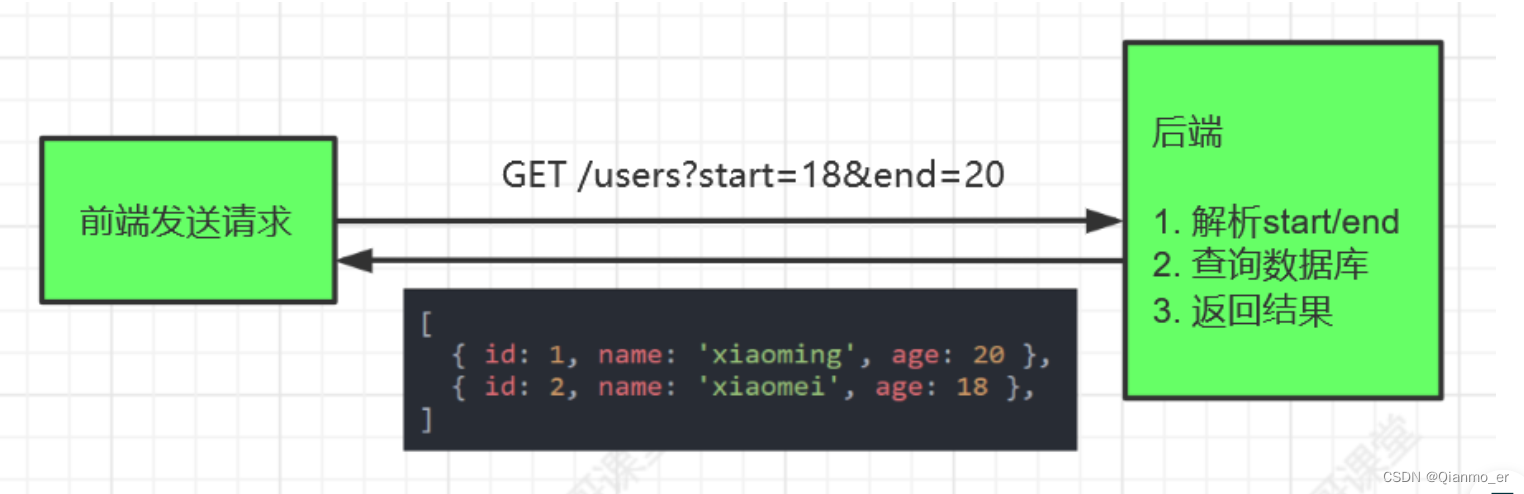
前端希望查询1月到3月的账单信息

接口设计
GET /bills?start=1&end=3
场景三
前端注册, 填写了用户名, 年龄, 传递给后端, 后端需要解析这些数据, 保存到数据库

对于不同的Http请求, 需要使用不同的方式携带参数
GET请求: 在URL中以键值对传递POST/PUT/PATCH/DELET请求: 在请求体中传递
3.2.4.2 处理URL参数
query
在GET请求中, 如果以键值对的形式传参, 可以通过query得到
// GET /users?start=18&end=20 ---- 获取所有的用户信息, 返回一个数组
router.get('/', (ctx) => {
// 通过 ctx.query 是ctx.request.query的代理 解析键值对参数
const { start = 0, end = 0 } = ctx.query
const res = db.filter((item) => item.age >= start && item.age <= end)
// 解析键值对
res.length == 0 ? ctx.throw(404) : (ctx.body = res)
})
params
在GET请求中, 有些参数可以通过路由传参, 可以通过params得到
// GET /users/:id ---- 根据id获取单个用户的信息, 返回一个对象
router.get('/:id', (ctx) => {
// 解析id参数
const id = ctx.params.id
const res = db.filter((item) => item.id == id)
if (!res[0]) ctx.throw(404)
ctx.body = res[0]
})
3.2.4.3 处理body参数
Koa原生支持body参数解析, 通常借助社区的中间件实现. 官方推荐的有
koa-bodyparserkoa-body
- 安装koa-body
npm install koa-body
- 注册
// 注册KoaBody中间件, 解析请求体中的参数, 挂载到ctx.request.body
const KoaBody = require('koa-body')
app.use(KoaBody())
- 使用
通过ctx.request.body获取请求体中的数据
//router.post('/',(ctx) => {
// console.log(ctx.request.body)
//})
const Koa = require('koa');
const koaBody = require('koa-body');
const app new Koa();
app.use(KoaBody());
app.use(ctx => {
ctx.body = `Request Body: ${JSON.strinfify(ctx.request.body)}`;
});
app.listen(3000);
3.2.5、错误处理
对于接口编程, 错误处理是非常重要的环节, 通过提供更友好的提示
- 提高错误定位的效率
- 提高代码的稳定性和可靠性
- 原生的错误处理
一般Koa中的错误分为三类
404: 当请求的资源找不到, 或者没有通过ctx.body返回时, 由koa自动返回
手动抛出: 通过ctx.throw手动抛出500: 运行时错误
Koa类是继承Emitter类, 因此可以
- 通过
emit提交一个错误 - 通过
on进行统一错误处理
app.on('error', (err, ctx) => {
console.error(err)
ctx.body = err
})
- 使用中间件
- 安装
npm i koa-json-error
- 使用
基本使用
const error = require('koa-json-error')
app.use(error())
高级使用
const error = require('koa-json-error')
app.use(
error({
format: (err) => {
return { code: err.status, message: err.message, result: err.stack }
},
postFormat: (err, obj) => {
const { result, ...rest } = obj
return process.env.NODE_ENV == 'production' ? rest : obj
},
})
)
3.3、Egg
官网:https://www.eggjs.org/zh-CN/
3.3.1、介绍
Eggjs是一个基于Koajs的框架,所以它应当属于框架之上的框架,它继承了Koa的高性能优点,同时又加入了一些约束与开发规范,来规避Koajs框架本身的开发自由度太高的问题。
Koajs是一个nodejs中比较基层的框架,它本身没有太多约束与规范,自由度非常高。而egg为了适应企业开发,加了一些开发时的规范与约束,从而解决Koajs这种自由度过高而导致不适合企业内使用的缺点。
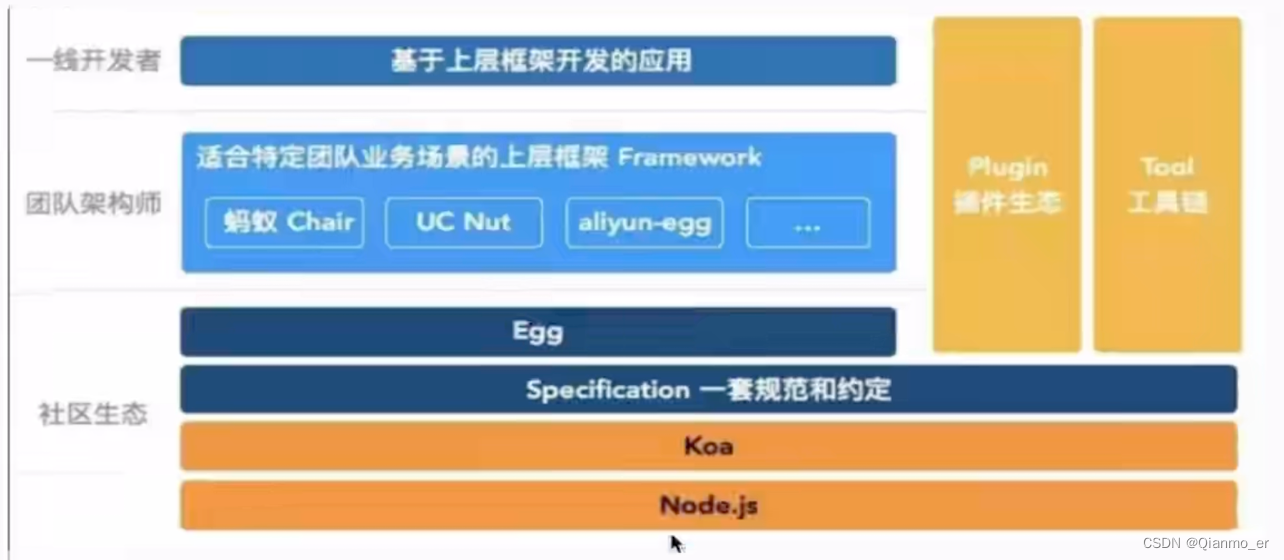
Egg是由阿里巴巴团队开源出来的一个“蛋”,像阿里内部不同的部门之间都孵化出了合适自己的egg框架,如蚂蚁的chair,UC的Nut,阿里云的aliyun-egg等,可以看下面这张图。
3.3.1.1、特性
- 提供基于 Egg 定制上层框架的能力
- 高度可扩展的插件机制
- 内置多进程管理
- 基于 Koa 开发,性能优异
- 框架稳定,测试覆盖率高
- 渐进式开发
- 约定大于配置
3.3.2、环境的搭建、创建、运行
npm init egg --type=simple
npm i
启动项目
npm run dev
gooopen http://localhost:7001
目录结构

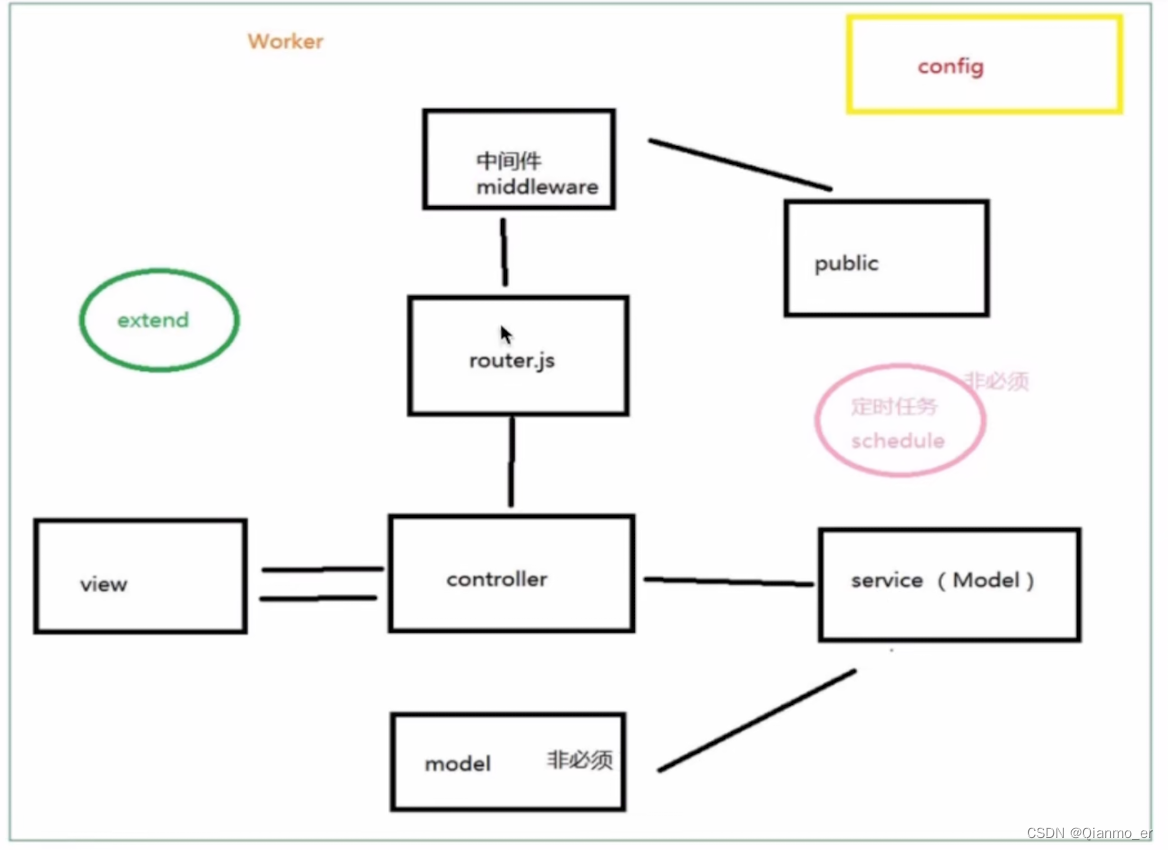
3.3.3、MVC
egg的设计完全符合比较好的mvc的设计模式
- Model(模型) - 模型代表一个存取数据的对象。它也可以带有逻辑,在数据变化时更新控制器。
- View(视图) - 视图代表模型包含的数据的可视化。
- Controller(控制器) - 控制器作用于模型和视图上。它控制数据流向模型对象,并在数据变化时更新视图。它使视图与模型分离开。
vscode 下载插件:eggjs
控制器(controller)
app/controller目录下面实现Controller
'use strict';
const Controller = require('egg').Controller;
class HomeController extends Controller {
async index() {
const { ctx } = this;
ctx.body = 'hi, egg';
}
}
module.exports = HomeController;
服务(service)
'use strict';
const Service = require('egg').Service;
class HomeService extends Service {
async index() {
return {ok:1}
}
}
module.exports = HomeService;
修改controller/home.js
'use strict';
const Controller = require('egg').Controller;
class HomeController extends Controller {
async index() {
const {
ctx,
service
} = this;
const res = await service.home.index();
ctx.body = res
}
}
module.exports = HomeController;
路由器(routes)
'use strict';
/**
* @param {Egg.Application} app - egg application
*/
module.exports = app => {
const { router, controller } = app;
router.get('/', controller.home.index);
};
访问:http://locoalhost:7001
3.3.4、项目实战
针对用户表的增删改查操作,案例基于mongoose非关系型数据库
使用egg-mongoose链接数据库
下载
npm i egg-mongoose -S
配置
config/plugin.js
exports.mongoose = {
enable: true,
package: 'egg-mongoose',
};
config/config.default.js
module.exports = appInfo => {
const config = exports = {};
// 为了解决安全跨站请求伪造,默认是 开启
config.security = {
csrf.security = {
enable:false
}
}
}
config.mongoose = {
url: "mongodb://127.0.0.1:27017/egg-test",
options:{
useUnifiedTopology: true,
useCreateIndex:true
}
}
创建用户模型
model/user.js
module.exports = app => {
const mongoose = app.mongoose;
const UserSchema = new mongoose.Schema({
username: {
type: String,
required: true
},
password: {
type: String,
required: true
},
avatar: {
type: String,
default: 'https://1.gravatar.com/avatar/a3e54af3cb6e157e496ae430aed4f4a3?s=96&d=mm'
},
createdAt: {
type: Date,
default: Date.now
}
})
return mongoose.model('User', UserSchema);
}
创建用户
router.js
// 用户创建
router.post('/api/user',controller.user.create);
controller/user.js
//创建用户
async create() {
const {
ctx,
service
} = this;
const payLoad = ctx.request.body || {};
const res = await service.user.create(payLoad);
ctx.body = {
code:200,
data:"创建成功!"
};
}
service/user.js
async create(payload) {
// 操作数据库
const {
ctx
} = this;
return ctx.model.User.create(payload);
}
获取所有用户
router.js
router.get('/api/user',controller.user.index);
controller/user.js
// 获取所有用户
async index() {
const {
ctx,
service
} = this;
const res = await service.user.index();
ctx.body = {
code:200,
data:res
};
}
service/user.js
async index() {
const {
ctx
} = this;
return ctx.model.User.find();
}
根据id获取用户详情
router.js
// 根据id获取用户详情
router.get('/api/user/:id',controller.user.detail);
controller/user.js
async detail() {
const id = this.ctx.params.id;
const res = await this.service.user.detail(id);
ctx.body = {
code:200,
data:res
};
}
service/user.js
async detail(id){
return this.ctx.model.User.findById({_id:id})
}
更新用户
router.js
// 更新用户
router.put('/api/user/:id',controller.user.update);
controller/user.js
async update() {
const id = this.ctx.params.id;
const payLoad = this.ctx.request.body;
// 调用 Service 进行业务处理
await this.service.user.update(id, payLoad);
// 设置响应内容和响应状态码
ctx.body = {msg:'更新用户成功'};
}
service/user.js
async update(_id, payLoad) {
return this.ctx.model.User.findByIdAndUpdate(_id,payLoad);
}
删除用户
router.js
// 删除用户
router.delete('/api/user/:id',controller.user.delete);
controller/user.js
async delete() {
const id = this.ctx.params.id;
// 调用 Service 进行业务处理
await this.service.user.delete(id);
// 设置响应内容和响应状态码
ctx.body = {msg:"删除用户成功"};
}
service/user.js
async delete(_id){
return this.ctx.model.User.findByIdAndDelete(_id);
}
3.3.5、中间件
配置
一般来说中间件也会有自己的配置。在框架中,一个完整的中间件是包含了配置处理的。我们约定一个中间件是一个放置在 app/middleware 目录下的单独文件,它需要 exports 一个普通的 function,接受两个参数:
options: 中间件的配置项,框架会将app.config[${middlewareName}]传递进来。app: 当前应用 Application 的实例。
app/middleware/error_handler.js
module.exports = (option, app) => {
return async function (ctx, next) {
try {
await next();
} catch (err) {
// 所有的异常都在app上触发一个error事件,框架会记录一条错误日志
app.emit('error', err, this);
const status = err.status || 500;
// 生成环境下 500 错误的详细错误内容不返回给客户端,因为可能包含敏感信息
const error = status === 500 && app.config.env === 'prod' ? 'Internal Server Error' : err.message
// 从error对象上读出各个属性,设置到响应中
ctx.body = {
code: status, // 服务端自身的处理逻辑错误(包含框架错误500 及 自定义业务逻辑错误533开始 ) 客户端请求参数导致的错误(4xx开始),设置不同的状态码
error:error
}
if(status === 422){
ctx.body.detail = err.errors;
}
ctx.status = 200
}
}
}
使用中间件
- 中间件编写完成后,我们还需要手动挂载,支持以下方式:
- 在应用中,可以完全通过配置来加载自定义的中间件,并决定它们的顺序。
- 如果需要加载上面的
error_handler中间件,在config.default.js中加入下面的配置就完成了中间件的开启和配置:
// add your middleware config here
config.middleware = ['errorHandler'];
登录认证
3.3.6、插件
插件机制是框架的一大特色。它不但可以保证框架核心的足够精简、稳定、高效,还可以促进业务逻辑的复用,生态圈的形成。
为什么要使用插件
在使用 Koa 中间件过程中发现了下面一些问题:
- 中间件加载其实是有先后顺序的,但是中间件自身却无法管理这种顺序,只能交给使用者。这样其实非常不友好,一旦顺序不对,结果可能有天壤之别。
- 中间件的定位是拦截用户请求,并在它前后做一些事情,例如:鉴权、安全检查、访问日志等等。但实际情况是,有些功能是和请求无关的,例如:定时任务、消息订阅、后台逻辑等等。
- 有些功能包含非常复杂的初始化逻辑,需要在应用启动的时候完成。这显然也不适合放到中间件中去实现。
综上所述,我们需要一套更加强大的机制,来管理、编排那些相对独立的业务逻辑。
中间件、插件、应用的关系
一个插件其实就是一个『迷你的应用』,和应用(app)几乎一样:
- 它包含了
Service、中间件、配置、框架扩展等等。 - 它没有独立的
Router和Controller。 - 它没有
plugin.js,只能声明跟其他插件的依赖,而不能决定其他插件的开启与否。
他们的关系是:
- 应用可以直接引入 Koa 的中间件。
- 当遇到定时任务、消息订阅、后台逻辑这些场景时,则应用需引入插件。
- 插件本身可以包含中间件。
- 多个插件可以包装为一个上层框架。
使用插件
上面我们使用的egg-mongoose就是一个插件。
插件一般通过 npm 模块的方式进行复用:
npm i egg-validate -S
然后需要在应用或框架的 config/plugin.js 中声明:
exports.validate = {
enable: true,
package: 'egg-validate',
};
就可以直接使用插件提供的功能:
controller/user.js
'use strict';
const Controller = require('egg').Controller;
class UserController extends Controller {
constructor(props) {
super(props);
this.UserCreateRule = {
username: {
type: 'string',
required: true,
allowEmpty: false,
// 用户名必须是3-10位之间的字母、下划线、@、. 并且不能以数字开头
format: /^[A-Za-z_@.]{3,10}/
},
password: {
type: 'password',
require: true,
allowEmpty: false,
min: 6
}
}
}
async create() {
const {
ctx,
service
} = this;
// 校验参数
ctx.validate(this.UserCreateRule)
const payLoad = ctx.request.body || {};
const res = await service.user.create(payLoad);
this.ctx.helper.success({
ctx: this.ctx,
res
});
}
}
module.exports = UserController;
3.3.7 框架扩展
Helper 函数用来提供一些实用的 utility 函数。
-
它的作用在于我们可以将一些常用的动作抽离在
helper.js里面成为一个独立的函数,这样可以用 JavaScript 来写复杂的逻辑,避免逻辑分散各处。另外还有一个好处是Helper这样一个简单的函数,可以让我们更容易编写测试用例。 -
框架内置了一些常用的 Helper 函数。我们也可以编写自定义的 Helper 函数。
-
框架会把
app/extend/helper.js中定义的对象与内置helper的prototype对象进行合并,在处理请求时会基于扩展后的prototype生成helper对象。
例如,增加一个 helper.success() 方法:
extend/helper.js
module.exports = {
success:function({res=null,msg='请求成功'}) {
// this是helper对象,在其中可以调用其他的helper方法
// this.ctx =>context对象
// this.app =>application对象
this.ctx.body = {
code:200,
data:res,
msg
}
this.ctx.status = 200;
}
}
controller/user.js
async index() {
const res = await this.service.user.index();
this.ctx.helper.success({
res
});
}
定时任务
虽然通过框架开发的 HTTP Server 是请求响应模型的,但是仍然还会有许多场景需要执行一些定时任务,例如:
- 定时上报应用状态。(订单超时反馈,订单详情处理等)
- 定时从远程接口更新本地缓存。
- 定时进行文件切割、临时文件删除。
框架提供了一套机制来让定时任务的编写和维护更加优雅
编写定时任务
所有的定时任务都统一存放在 app/schedule 目录下,每一个文件都是一个独立的定时任务,可以配置定时任务的属性和要执行的方法。
一个简单的例子,定义一个更新远程数据到内存缓存的定时任务,就可以在 app/schedule 目录下创建一个 update_cache.js 文件
const Subscription = require('egg').Subscription;
class UpdateCache extends Subscription {
// 通过 schedule 属性来设置定时任务的执行间隔等配置
static get schedule() {
return {
interval: '5s', // 1 分钟间隔
type: 'all', // 指定所有的 worker 都需要执行
};
}
// subscribe是真正定时任务执行时被运行的函数
async subscribe() {
console.log("任务执行 : " + new Date().toString());
// const res = await this.ctx.curl('https://free-api.heweather.net/s6/weather/now?location=beijing&key=4693ff5ea653469f8bb0c29638035976', {
// dataType: 'json',
// })
// this.ctx.app.cache = res.data;
}
}
module.exports = UpdateCache;
可以简写
module.exports = {
schedule: {
interval: '1m', // 1 分钟间隔
type: 'all', // 指定所有的 worker 都需要执行
},
async task(ctx) {
const res = await ctx.curl('https://free-api.heweather.net/s6/weather/now?location=beijing&key=4693ff5ea653469f8bb0c29638035976', {
dataType: 'json',
});
ctx.app.cache = res.data;
},
};
这个定时任务会在每一个 Worker 进程上每 1 分钟执行一次,将远程数据请求回来挂载到 app.cache 上。
定时方式
定时任务可以指定 interval 或者 cron 两种不同的定时方式。
- interval:
通过schedule.interval参数来配置定时任务的执行时机,定时任务将会每间隔指定的时间执行一次。interval可以配置成
- 数字类型,单位为毫秒数,例如 5000。
- 字符类型,会通过 ms 转换成毫秒数,例如 5s。
module.exports = {
schedule: {
// 每 10 秒执行一次
interval: '10s',
},
};
- cron
通过schedule.cron参数来配置定时任务的执行时机,定时任务将会按照 cron 表达式在特定的时间点执行。cron 表达式通过cron-parser进行解析。
注意:cron-parser 支持可选的秒(linux crontab 不支持)。

module.exports = {
schedule: {
// 每三小时准点执行一次
cron: '0 0 */3 * * *',
},
};
类型
框架提供的定时任务默认支持两种类型,worker 和 all。worker 和 all 都支持上面的两种定时方式,只是当到执行时机时,会执行定时任务的 worker 不同:
- worker 类型:每台机器上只有一个 worker 会执行这个定时任务,每次执行定时任务的 worker 的选择是随机的。
- all 类型:每台机器上的每个 worker 都会执行这个定时任务。
其他参数
除了刚才介绍到的几个参数之外,定时任务还支持这些参数:
- cronOptions: 配置 cron 的时区等,参见 cron-parser 文档
- immediate:配置了该参数为 true 时,这个定时任务会在应用启动并 ready 后立刻执行一次这个定时任务。
- disable:配置该参数为 true 时,这个定时任务不会被启动。
- env:数组,仅在指定的环境下才启动该定时任务。
动态配置定时任务
config/config.default.js
config.cacheTick = {
interval: '5s', // 1 分钟间隔
type: 'all', // 指定所有的 worker 都需要执行
immediate: true, //配置了该参数为 true 时,这个定时任务会在应用启动并 ready 后立刻执行一次这个定时任务
// disable: true, //为true表示定时任务不会被启动
};
schedule/update_cache.js
module.exports = app => {
return {
schedule: app.config.cacheTick,
async task(ctx) {
console.log("任务执行 : " + new Date().toString());
},
}
};
启动项目,查看控制台输出。
4、数据库

其中,MySQL、Oracle、SQL Server 属于传统型数据库(又叫做:关系型数据库 或 SQL 数据库),这三者的设计理念相同,用法比较类似。
而 Mongodb 属于新型数据库(又叫做:非关系型数据库 或 NoSQL 数据库),它在一定程度上弥补了传统型数据库的缺陷。
4.1、MySQL
SQL(英文全称:Structured Query Language)是结构化查询语言,专门用来访问和处理数据库的编程语言。能够让我们以编程的形式,操作数据库里面的数据。
三个关键点:
① SQL 是一门数据库编程语言
② 使用 SQL 语言编写出来的代码,叫做 SQL 语句
③ SQL 语言只能在关系型数据库中使用(例如 MySQL、Oracle、SQL Server)。非关系型数据库(例如 Mongodb)不支持 SQL 语言
查询数据(select) 、插入数据(insert into) 、更新数据(update) 、删除数据(delete)
where 条件、and 和 or 运算符、order by 排序、count(*) 函数
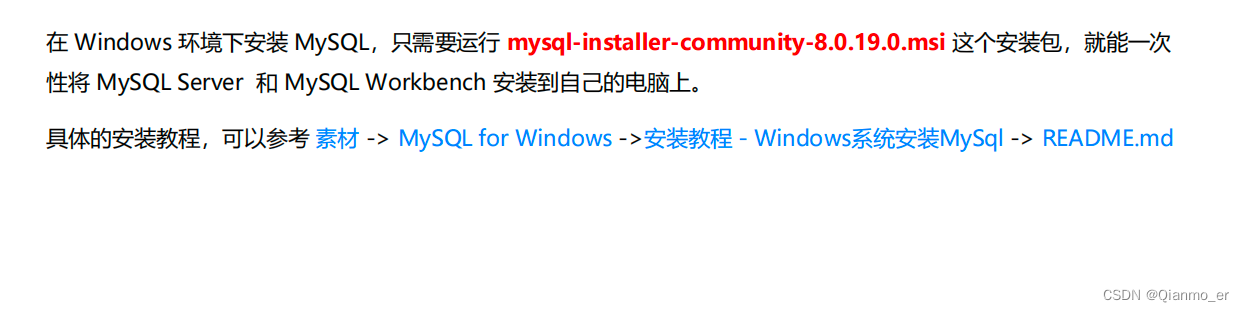
4.1.1、安装并配置 MySQL
-
MySQL 在 Mac 环境下的安装
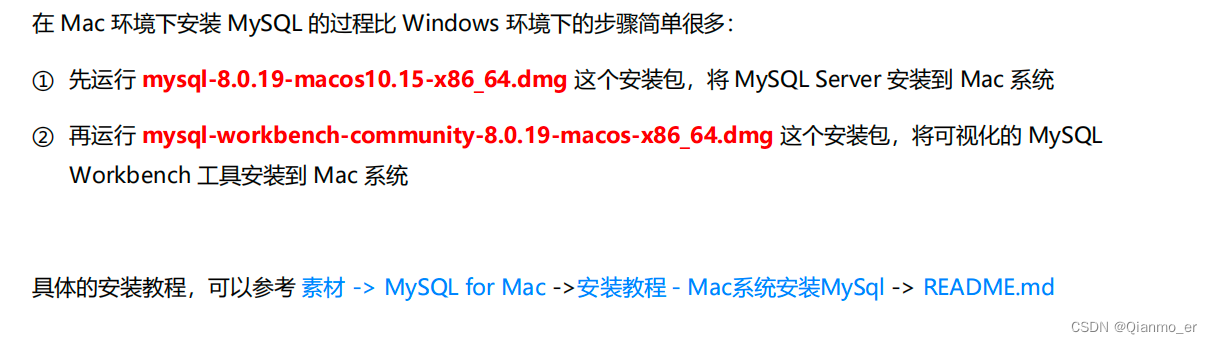
-
MySQL 在 Windows 环境下的安装
4.1.2、MySQL的基本使用
4.1.2.1 查(select)
SELECT 语句用于从表中查询数据。执行的结果被存储在一个结果表中(称为结果集)。语法格式如下:
-- 查询所有数据
select * from 表名称
-- 查询指定列名称的数据
select 列名称 from 表名称
注意:SQL 语句中的关键字对大小写不敏感。SELECT 等效于 select,FROM 等效于 from。
示例:
-- 从 users 表中选取所有的列
select * from users
-- 如需获取名为 "username" 和 "password" 的列的内容(从名为 "users" 的数据库表)
select username,password from users
4.1.2.2 增(insert into)
INSERT INTO 语句用于向数据表中插入新的数据行
-- 向指定的表中,插入如下几列数据,列的值通过 values 指定
insert into table_name(列1,列2...) values(值1,值2,...)
示例:
-- 向 users 表中,插入一条 username 为 tony stark,password 为 098123 的用户数据
insert into users(username,password) values('tony','123456')
4.1.2.3 改(update)
Update 语句用于修改表中的数据。
-- 1. 用 update 指定要更新哪个表中数据
-- 2. 用 set 指定列对应的新值
-- 3. 用 where 指定更新的条件
update 表名称 set 列名称 = 新值 where 列名称 = 某值
示例:
更新某一行中的一个列
-- 把 users 表中 id 为 7 的用户密码,更新为 888888
update users set password='888888' where id=7
更新某一行中的若干列
-- 把 users 表中 id 为 2 的用户密码和用户状态,分别更新为 admin123 和 1。
update user set password='admin123',status=1 where id=2
4.1.2.4 删(delete)
DELETE 语句用于删除表中的行
-- 从指定的表中,根据 where 条件,删除对应的数据行
delete from 表名称 where 列名称 = 值
示例:
-- 从 users 表中,删除 id 为 4 的用户
delete from users where id = 4
4.1.2.5 where 子句
where 子句用于限定选择的标准。在 selete、update、delete 语句中,皆可使用 where 子句来限定选择的标准。
-- 查询语句中的 where 条件
select 列名称 from 表名称 where 列 运算符 值
-- 更新语句中的 where 条件
update 表名称 set 列 = 新值 where 列 运算符 值
-- 删除语句中的 where 条件
delete from 表名称 where 列 运算符 值
下面的运算符可在 WHERE 子句中使用,用来限定选择的标准:
| 操作符 | 描述 |
|---|---|
= | 等于 |
<> | 不等于 |
> | 大于 |
< | 小于 |
>= | 大于等于 |
<= | 小于等于 |
between | 在某个范围内 |
like | 搜索某种模式 |
注意:在某些版本的 SQL 中,操作符 <> 可以写为 !=
示例:
通过 WHERE 子句来限定 SELECT 的查询条件
-- 查询 status 为 1 的所有用户
select * from users where status = 1
-- 查询 id 大于 2 的所有用户
select * from users where id > 2
-- 查询 username 不等于 admin 的所有用户
select * from users where username <> 'admin'
4.1.2.6 and 和 or
AND 和 OR 可在 WHERE 子语句中把两个或多个条件结合起来。
AND 表示必须同时满足多个条件,相当于 JavaScript 中的 && 运算符,例如 if (a ! == 10 && a !== 20)
OR 表示只要满足任意一个条件即可,相当于 JavaScript 中的 || 运算符,例如 if(a !== 10 || a !== 20)
and示例:
-- 使用 AND 来显示所有 status 为 0,并且 id 小于 3 的用户
select * from users where status=0 and id<3
or示例:
-- 使用 OR 来显示所有 status 为 1,或者 username 为 zs 的用户:
select * from users where status=1 or username = 'zs'
4.1.2.7 order by
ORDER BY 语句用于根据指定的列对结果集进行排序。
ORDER BY 语句默认按照升序对记录进行排序。
如果您希望按照降序对记录进行排序,可以使用 DESC 关键字。
升序排序:
-- 对 users 表中的数据,按照 status 字段进行升序排序
-- 默认进行升序排序
select * from users order by status;
-- asc为升序排序
select * from users order by status asc;
降序排序:
-- 对 users 表中的数据,按照 id 字段进行降序排序
select * from users order by id desc
多重排序:
-- 对 users 表中的数据,先按照 status 字段进行降序排序,再按照 username 的字母顺序,进行升序排序
select * from users order by status desc,usename asc
4.1.2.8 count(*) 函数
COUNT(*) 函数用于返回查询结果的总数据条数,语法格式如下:
select count(*) from 表名称
示例:
-- 查询 users 表中 status 为 0 的总数据条数:
select count(*) from users where status = 0
使用 AS 为列设置别名:
-- 给查询出来的列名称设置别名,可以使用 AS 关键字
select count(*) as total from users where staus = 0
4.1.3、实操MySQL
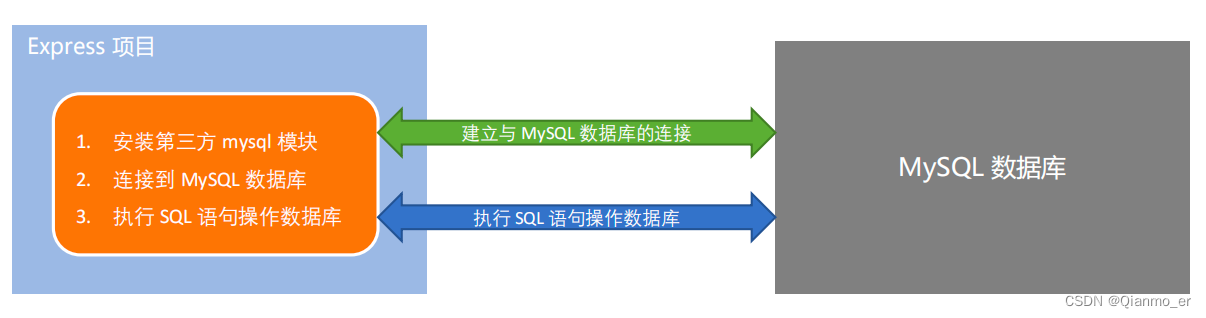
4.1.3.1 在项目中操作数据库的步骤
① 安装操作 MySQL 数据库的第三方模块(mysql)
② 通过 mysql 模块连接到 MySQL 数据库
③ 通过 mysql 模块执行 SQL 语句
4.1.3.2 安装与配置 mysql 模块
- 安装 mysql 模块
mysql 模块是托管于 npm 上的第三方模块。它提供了在 Node.js 项目中连接和操作 MySQL 数据库的能力。
想要在项目中使用它,需要先运行如下命令,将 mysql 安装为项目的依赖包:
npm install mysql
- 配置 mysql 模块
在使用 mysql 模块操作 MySQL 数据库之前,必须先对 mysql 模块进行必要的配置,主要的配置步骤如下:
// 1. 导入 mysql 模块
const mysql = require('mysql')
// 2. 建立与 MySQL 数据库的连接
const db = mysql.createPool({
host:'127.0.0.1', // 数据库的 IP 地址
user:'root', // 登录数据库的账号
password:'admin123', // 登录数据库的密码
database:'my_db' // 指定数据库
})
- 测试 mysql 模块能否正常工作
调用db.query()函数,指定要执行的 SQL 语句,通过回调函数拿到执行的结果:
// 检测 mysql 模块能否正常工作
db.query('select 1',(err,res) => {
if(err) return console.log(err.message)
// 只能打印出 [ RowDataPacket{'1':1} ],就证明数据库连接正常
console.log(res)
})
4.1.3.3 使用 mysql 模块操作 MySQL 数据库
- 查询数据
查询 users 表中所有的数据:
// 查询 users 表中所有的用户数据
db.query('select * from users',(err,res) => {
// 查询失败
if(err) return console.log(err.message)
// 查询成功
console.log(res)
})
- 插入数据
向 users 表中新增数据, 其中 username 为 Spider-Man,password 为 pcc321。示例代码如下:
// 1. 要插入到 users 表中的数据对象
const user = { username:'Spider-Man',password:'pcc321'}
// 2.待执行的 SQL 语句,其中英文的 ? 表示占位符
const sqlStr = 'insert into users(username,password) values(?,?)'
// 3.使用数组的形式,依次为 ? 占位符指定具体的值
db.query(sqlStr,[user.username,user.password],(err,res) => {
if(err) return console.log(err.message)
if(res.affectedRows === 1){
console.log('插入成功!')
}
})
- 插入数据的便捷方式
向表中新增数据时,如果数据对象的每个属性和数据表的字段一一对应,则可以通过如下方式快速插入数据:
// 1. 要插入到 users 表中的数据对象
const user = { username:'Spider-Man',password:'pcc321'}
// 2.待执行的 SQL 语句,其中英文的 ? 表示占位符
const sqlStr = 'insert into users set ?'
// 3.使用数组的形式,依次为 ? 占位符指定具体的值
db.query(sqlStr,user,(err,res) => {
if(err) return console.log(err.message)
if(res.affectedRows === 1){
console.log('插入成功!')
}
})
- 更新数据
可以通过如下方式,更新表中的数据:
// 1. 要更新的数据对象
const user = { id:7,username:'aaa',password:'000'}
// 2.待执行的 SQL 语句
const sqlStr = 'update users set username=?,password=? where id=?'
// 3.调用 db.query() 执行
db.query(sqlStr,[user.username,user.password,user.id],(err,res) => {
if(err) return console.log(err.message)
if(res.affectedRows === 1){
console.log('更新成功!')
}
})
- 更新数据的便捷方式
更新表数据时,如果数据对象的每个属性和数据表的字段一一对应,则可以通过如下方式快速更新表数据:
// 1. 要更新的数据对象
const user = { id:7,username:'aaa',password:'000'}
// 2.待执行的 SQL 语句
const sqlStr = 'update users set ? where id=?'
// 3.调用 db.query() 执行
db.query(sqlStr,[user,user.id],(err,res) => {
if(err) return console.log(err.message)
if(res.affectedRows === 1){
console.log('更新成功!')
}
})
- 删除数据
在删除数据时,推荐根据 id 这样的唯一标识,来删除对应的数据。示例如下:
// 1.要执行的 SQL 语句
const sqlStr = 'delete from users where id=?'
// 2.调用 db.query() 执行语句
db.query(sqlStr,7,(err,res) => {
if(err) return console.log(err.message)
if(res.affectedRows === 1){
console.log('删除数据成功!')
}
})
注意:
如果 SQL 语句中有多个占位符,则必须使用数组为每个占位符指定的具体的值
如果 SQL 语句中只有一个占位符,则可以省略
- 标记删除
- 使用
delete语句,会把真正的把数据从表中删除掉。 - 为了保险起见,推荐使用标记删除的形式,来模拟删除的动作。
- 所谓的标记删除,就是在表中设置类似于 status 这样的状态字段,来标记当前这条数据是否被删除。
- 当用户执行了删除的动作时,我们并没有执行
delete语句把数据删除掉,而是执行了update语句,将这条数据对应的status字段标记为删除即可
db.query('update users set status=1 where id=?',6,(err,res) => {
if(err) return console.log(err.message)
if(res.affectedRows === 1){
console.log('删除数据成功!')
}
})
4.1.4、前后端的身份认证
4.1.4.1 Web 开发模式
目前主流的 Web 开发模式有两种,分别是:
① 基于服务端渲染的传统 Web 开发模式
② 基于前后端分离的新型 Web 开发模式
- 服务端渲染的 Web 开发模式
服务端渲染的概念:服务器发送给客户端的HTML页面,是在服务器通过字符串的拼接,动态生成的。因此,客户端不
需要使用Ajax这样的技术额外请求页面的数据。代码示例如下:
app.get('/index.html',(req,res) => {
// 1. 要渲染的数据
const user = { name:'zs',age:20 }
// 2.服务器通过字符串的拼接,动态生成 HTML 内容
const html = `<h1>姓名:${user.name},年龄:${user.age}</h1>`
// 3.把生成的页面内容响应给客户端,
res.send(html)
})
服务端渲染的优缺点:
优点:
- ①
前端耗时少。因为服务器端负责动态生成 HTML 内容,浏览器只需要直接渲染页面即可。尤其是移动端,更省电。 - ②
有利于SEO。因为服务器端响应的是完整的 HTML 页面内容,所以爬虫更容易爬取获得信息,更有利于 SEO。
缺点:
- ①
占用服务器端资源。即服务器端完成 HTML 页面内容的拼接,如果请求较多,会对服务器造成一定的访问压力。 - ②
不利于前后端分离,开发效率低。使用服务器端渲染,则无法进行分工合作,尤其对于前端复杂度高的项目,不利于项目高效开发。
- 前后端分离的 Web 开发模式
前后端分离的开发模式,依赖于 Ajax 技术的广泛应用。简而言之,前后端分离的 Web 开发模式,就是后端只负责提供 API 接口,前端使用 Ajax 调用接口的开发模式
前后端分离的优缺点
优点:
- ①
开发体验好。前端专注于 UI 页面的开发,后端专注于api 的开发,且前端有更多的选择性。 - ②
用户体验好。Ajax 技术的广泛应用,极大的提高了用户的体验,可以轻松实现页面的局部刷新。 - ③
减轻了服务器端的渲染压力。因为页面最终是在每个用户的浏览器中生成的。
缺点:
不利于 SEO。因为完整的 HTML 页面需要在客户端动态拼接完成,所以爬虫对无法爬取页面的有效信息。(解决方案:利用 Vue、React 等前端框架的 SSR (server side render)技术能够很好的解决 SEO 问题!)
- 如何选择 Web 开发模式
不谈业务场景而盲目选择使用何种开发模式都是耍流氓。
- 比如企业级网站,主要功能是展示而没有复杂的交互,并且需要良好的 SEO,则这时我们就需要使用服务器端渲染;
- 而类似后台管理项目,交互性比较强,不需要考虑 SEO,那么就可以使用前后端分离的开发模式。
另外,具体使用何种开发模式并不是绝对的,为了同时兼顾了首页的渲染速度和前后端分离的开发效率,一些网站采用了首屏服务器端渲染 + 其他页面前后端分离的开发模式。
4.1.4.2 身份认证
身份认证(Authentication)又称“身份验证”、“鉴权”,是指通过一定的手段,完成对用户身份的确认。
- 日常生活中的身份认证随处可见,例如:高铁的验票乘车,手机的密码或指纹解锁,支付宝或微信的支付密码等。
- 在 Web 开发中,也涉及到用户身份的认证,例如:各大网站的手机验证码登录、邮箱密码登录、二维码登录等。
身份认证的目的:是为了确认当前所声称为某种身份的用户,确实是所声称的用户。例如,你去找快递员取快递,你要怎么证明这份快递是你的。
在互联网项目开发中,如何对用户的身份进行认证,是一个值得深入探讨的问题。
不同开发模式下的身份认证
对于服务端渲染和前后端分离这两种开发模式来说,分别有着不同的身份认证方案:
① 服务端渲染推荐使用 Session 认证机制
② 前后端分离推荐使用 JWT 认证机制
4.1.4.3 Session 认证机制
- HTTP 协议的无状态性
了解 HTTP 协议的无状态性是进一步学习 Session 认证机制的必要前提。
HTTP 协议的无状态性,指的是客户端的每次 HTTP 请求都是独立的,连续多个请求之间没有直接的关系,服务器不会主动保留每次 HTTP 请求的状态。
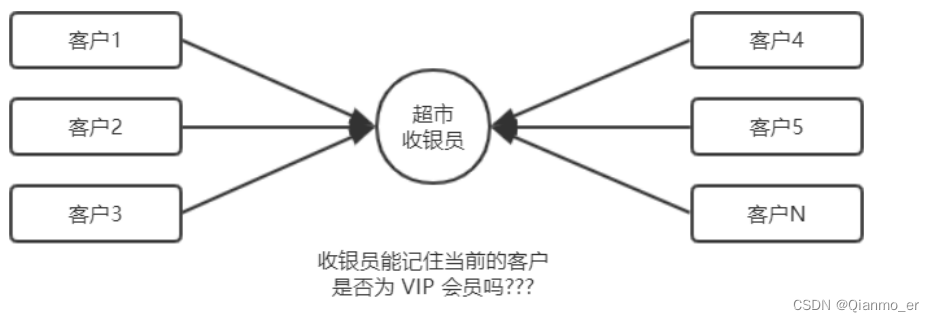
- 如何突破 HTTP 无状态的限制
对于超市来说,为了方便收银员在进行结算时给 VIP 用户打折,超市可以为每个 VIP 用户发放会员卡。
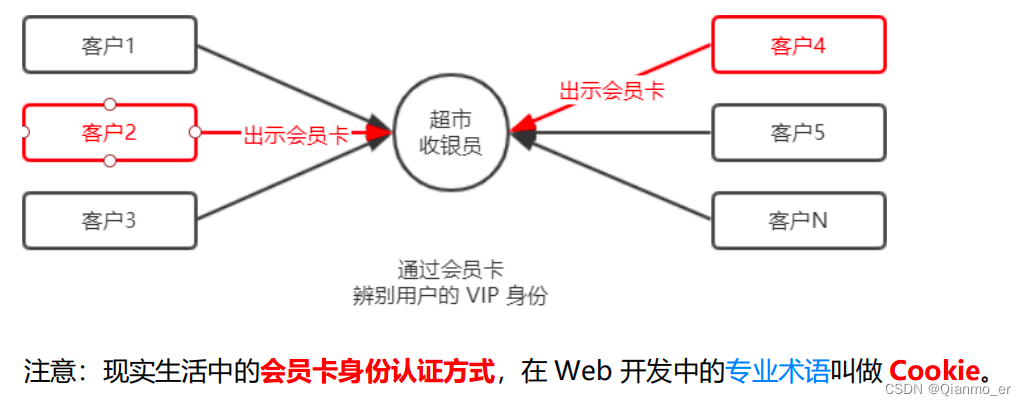
- 什么是 Cookie
Cookie 是存储在用户浏览器中的一段不超过 4 KB 的字符串。它由一个名称(Name)、一个值(Value)和其它几个用于控制 Cookie 有效期、安全性、使用范围的可选属性组成。
不同域名下的 Cookie 各自独立,每当客户端发起请求时,会自动把当前域名下所有未过期的 Cookie 一同发送到服务器。
Cookie的几大特性:
① 自动发送
② 域名独立
③ 过期时限
④ 4KB 限制
- Cookie 在身份认证中的作用
- 客户端第一次请求服务器的时候,服务器通过响应头的形式,向客户端发送一个身份认证的 Cookie,客户端会自动
将 Cookie 保存在浏览器中。 - 随后,当客户端浏览器每次请求服务器的时候,浏览器会自动将身份认证相关的 Cookie,通过请求头的形式发送给服务器,服务器即可验明客户端的身份。

- Cookie 不具有安全性
由于 Cookie 是存储在浏览器中的,而且浏览器也提供了读写 Cookie 的 API,因此 Cookie 很容易被伪造,不具有安全
性。因此不建议服务器将重要的隐私数据,通过 Cookie 的形式发送给浏览器。
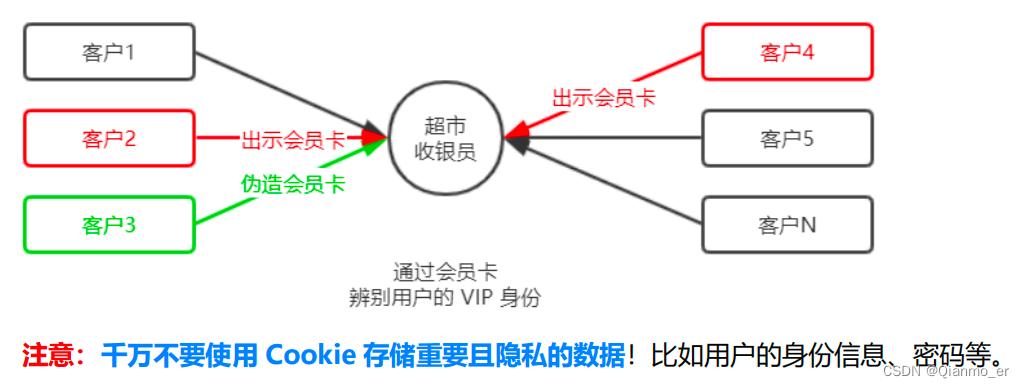
- 提高身份认证的安全性
为了防止客户伪造会员卡,收银员在拿到客户出示的会员卡之后,可以在收银机上进行刷卡认证。只有收银机确认存在的会员卡,才能被正常使用。
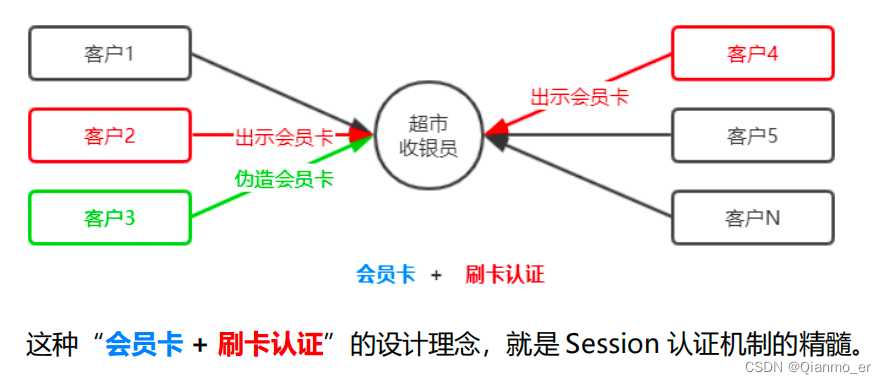
- Session 的工作原理
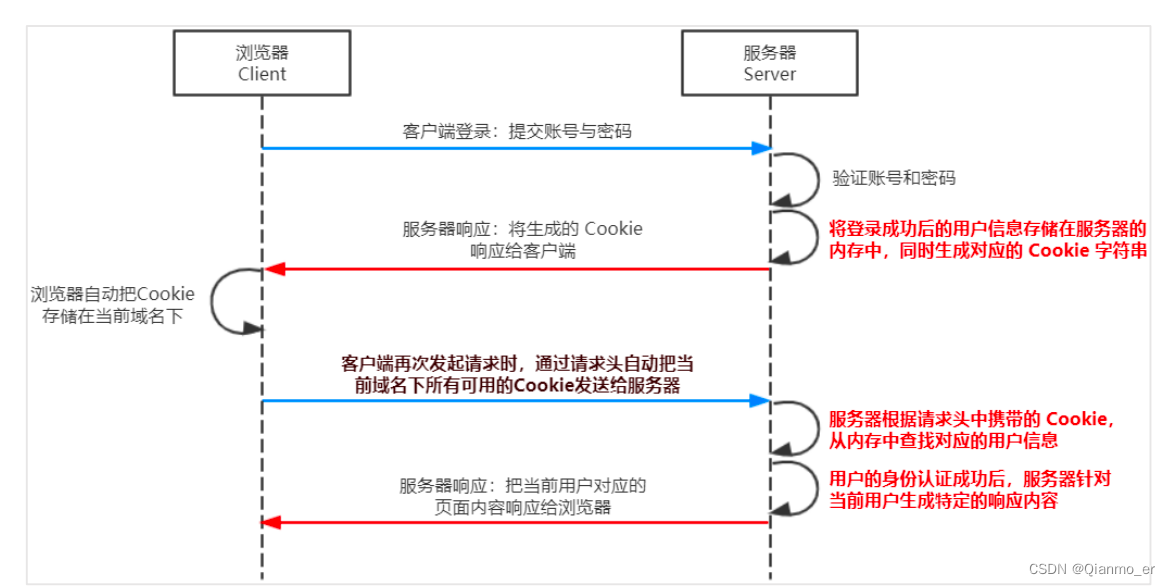
4.1.4.4 在 Express 中使用 Session 认证
- 安装
express-session中间件
在 Express 项目中,只需要安装express-session中间件,即可在项目中使用 Session 认证:
npm install express-session
- 配置 express-session 中间件
express-session 中间件安装成功后,需要通过app.use()来注册 session 中间件,示例代码如下:
// 1.导入 session 中间件
var session = require('express-session')
// 2. 配置 session 中间件
app.use(session({
secret:'keyboard cat', // secret 属性的值可以为任意字符
resave:false, // 固定写法
saveUninitialiaed:true, // 固定写法
}))
- 向 session 中存数据
当 express-session 中间件配置成功后,即可通过req.session来访问和使用 session 对象,从而存储用户的关键信息:
app.post('/api/login',(req,res) => {
// 判断用户提交的登录信息是否正确
if(req.body.username !== 'admin' || req.body.password !== '000000'){
return res.send({ status:1,msg:'登录失败' })
}
// 将用户的信息,存储到 Session 中
req.session.user = req.body
// 将用户的登录状态,存储到 Session 中
req.session.islogin = true
res.send({ status:0,msg:'登录成功' })
})
- 从 session 中取数据
可以直接从req.session对象上获取之前存储的数据,示例代码如下:
// 获取用户姓名的接口
app.get('/api/username'.(req,res) => {
// 判断用户是否登录
if(!req.session.islogin){
return res,send({ status:1,meg:'登录失败!' })
}
res.send({ status:0,mes:'登录成功!',username:req.session.user.username })
})
- 清空 session
调用req.session.destroy()函数,即可清空服务器保存的 session 信息。
// 退出登录的接口
app.post('/api/logout',(req,res) => {
// 清空当前客户端对应的 session 信息
req.session.destroy()
res.send({
status:0,
msg:'退出登录成功'
})
})
4.1.4.5 JWT 认证机制
- 了解 Session 认证的局限性
Session 认证机制需要配合 Cookie 才能实现。由于 Cookie 默认不支持跨域访问,所以,当涉及到前端跨域请求后端接口的时候,需要做很多额外的配置,才能实现跨域 Session 认证。
注意:
- 当前端请求后端接口不存在跨域问题的时候,推荐使用 Session 身份认证机制。
- 当前端需要跨域请求后端接口的时候,不推荐使用 Session 身份认证机制,推荐使用 JWT 认证机制。
-
什么是 JWT
JWT(英文全称:JSON Web Token)是目前最流行的跨域认证解决方案。 -
JWT 的工作原理
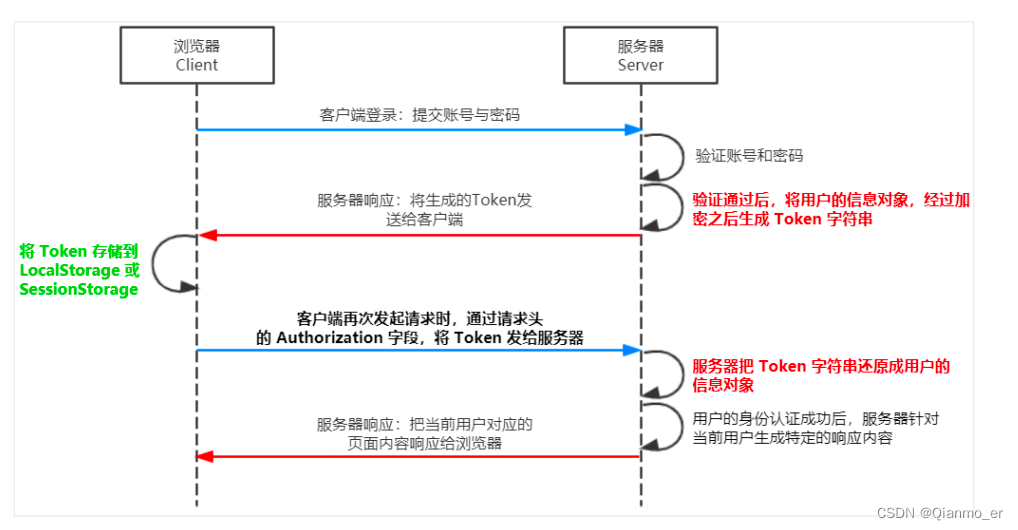
总结:用户的信息通过 Token 字符串的形式,保存在客户端浏览器中。服务器通过还原 Token 字符串的形式来认证用户的身份 -
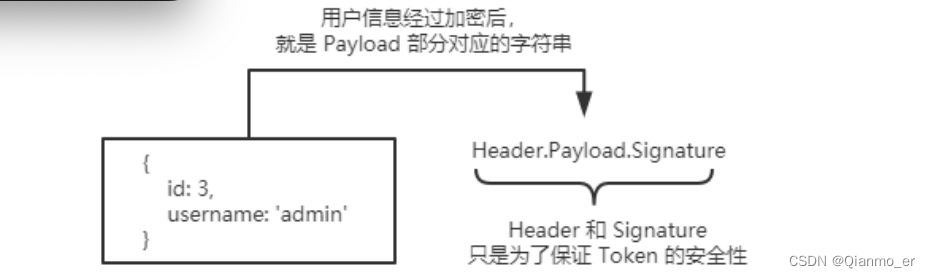
JWT 的组成部分
JWT 通常由三部分组成,分别是 Header(头部)、Payload(有效荷载)、Signature(签名)。三者之间使用英文的“.”分隔,格式如下

下面是 JWT 字符串的示例:

-
JWT 的三个部分各自代表的含义
JWT 的三个组成部分,从前到后分别是 Header、Payload、Signature。
Payload部分才是真正的用户信息,它是用户信息经过加密之后生成的字符串。Header和Signature是安全性相关的部分,只是为了保证 Token 的安全性
- JWT 的使用方式
客户端收到服务器返回的 JWT 之后,通常会将它储存在localStorage或sessionStorage中。
此后,客户端每次与服务器通信,都要带上这个 JWT 的字符串,从而进行身份认证。推荐的做法是把 JWT 放在 HTTP 请求头的 Authorization 字段中,格式如下:

4.1.4.6 在 Express 中使用 JWT
- 安装 JWT 相关的包
运行如下命令,安装如下两个 JWT 相关的包:
npm install jsonwebtoken express-jwt
其中:
jsonwebtoken用于生成 JWT 字符串express-jwt用于将 JWT 字符串解析还原成 JSON 对象
- 导入 JWT 相关的包
使用require()函数,分别导入 JWT 相关的两个包:
// 1. 导入用于生成 JWT 字符串的包
const jwt = require('jsonwebtoken')
// 2. 导入用于将客户发送过来的 JWT 字符串,解析还原成 JSON 对象的包
const expressJWT = require('express-jwt')
- 定义 secret 密钥
为了保证 JWT 字符串的安全性,防止 JWT 字符串在网络传输过程中被别人破解,我们需要专门定义一个用于加密和解密的 secret 密钥:
① 当生成 JWT 字符串的时候,需要使用 secret 密钥对用户的信息进行加密,最终得到加密好的 JWT 字符串
② 当把 JWT 字符串解析还原成 JSON 对象的时候,需要使用 secret 密钥进行解密
// 3. secret 密钥的本质:就是一个字符串
const secretKey = 'itNo1'
- 在登录成功后生成 JWT 字符串
调用jsonwebtoken包提供的sign()方法,将用户的信息加密成 JWT 字符串,响应给客户端:
// 登录接口
app.post('/api/login',function(req,res){
// 用户登录成功后,生成 JWT 字符串,通过 token 属性响应给客户端
res.send({
status:200,
message:'登录成功!',
// 调用 jwt.sign() 生成 JWT 字符串,三个参数分别是:用户信息对象、加密密钥、配置对象
token:jwt.sign({ username:userinfo.username },secretKey,{ expiresIn:'30s' })
})
})
- 将 JWT 字符串还原为 JSON 对象
客户端每次在访问那些有权限接口的时候,都需要主动通过请求头中的Authorization字段,将 Token 字符串发送到服务器进行身份认证。
此时,服务器可以通过 express-jwt 这个中间件,自动将客户端发送过来的 Token 解析还原成 JSON 对象
// 使用 app.use() 来注册中间件
// expressJWT({ sercret:sercretKey }) 就是用来解析 Token 的中间件
// .unless({ path:[/^\/api\//]}) 用来指定哪些接口不需要的访问权限
app.use(expressJWT({ sercret:secretKey }).unless({ path:[/^\/api\//] }))
- 使用 req.user 获取用户信息
当express-jwt这个中间件配置成功之后,即可在那些有权限的接口中,使用req.user对象,来访问从 JWT 字符串中解析出来的用户信息了,示例代码如下:
// 这是一个有权限的接口
app.use('/admin/getinfo',function(req,res) => {
cosole.log(req.user)
res.send({
status:200,
message:'获取用户信息成功!',
data:req.user
})
})
- 捕获解析 JWT 失败后产生的错误
当使用express-jwt解析 Token 字符串时,如果客户端发送过来的 Token 字符串过期或不合法,会产生一个解析失败的错误,影响项目的正常运行。
可以通过 Express 的错误中间件,捕获这个错误并进行相关的处理,示例代码如下:
app.use((err,req,res,next) => {
// token 解析失败导致的过程
if(err.name == 'Unauthorizederror'){
return res.send({ status:401,message:'无效的token' })
}
// 其他原因导致的错误
res.send({ status:500,message:'未知错误!' })
})
4.2、MongoDB
4.2.1、基础知识
4.2.1.1 数据库(Database)
数据库是按照数据结构来组织、存储和管理数据的仓库。
• 我们的程序都是在内存中运行的,一旦程序运行结束或者计算机断电,程序运行中的数据都会丢失。
• 那就需要将一些程序运行的数据持久化到硬盘之中,以确保数据的安全性。而数据库就是数据持久化的最佳选择。
• 数据库就是存储数据的仓库。
4.2.1.2 数据库分类
- 关系型数据库
- MySQL、Oracle、DB2、SQL Server ……
- 关系数据库中全都是表
- 非关系型数据库
- MongoDB、Redis ……
- 键值对数据库
- 文档数据库MongoDB
4.2.1.3 MongoDB
• MongoDB是为快速开发互联网Web应用而设计的数据库系统。
• MongoDB的设计目标是极简、灵活、作为Web应用栈的一部分。
• MongoDB的数据模型是面向文档的,所谓文档是一种类似于JSON的结构,简单理解MongoDB这个数据库中存的是各种各样的JSON。(BSON)
- 下载地址:https://www.mongodb.org/dl/win32/
- MongoDB的版本偶数版本为稳定版,奇数版本为开发版。
- MongoDB对于32位系统支持不佳,所以
3.2版本以后没有再对32位系统的支持。
Docker安装:
常用命令:
4.2.1.4 基本概念
- 数据库(database) – 数据库是一个仓库,在仓库中可以存放集合。
- 集合(collection) – 集合类似于数组,在集合中可以存放文档。
- 文档(document) – 文档数据库中的最小单位,我们存储和操作的内容都是文档,类似于JS中的对象,在MongoDB中每一条数据都是一个文档
- 多个文档组成集合,多个集合组成数据库
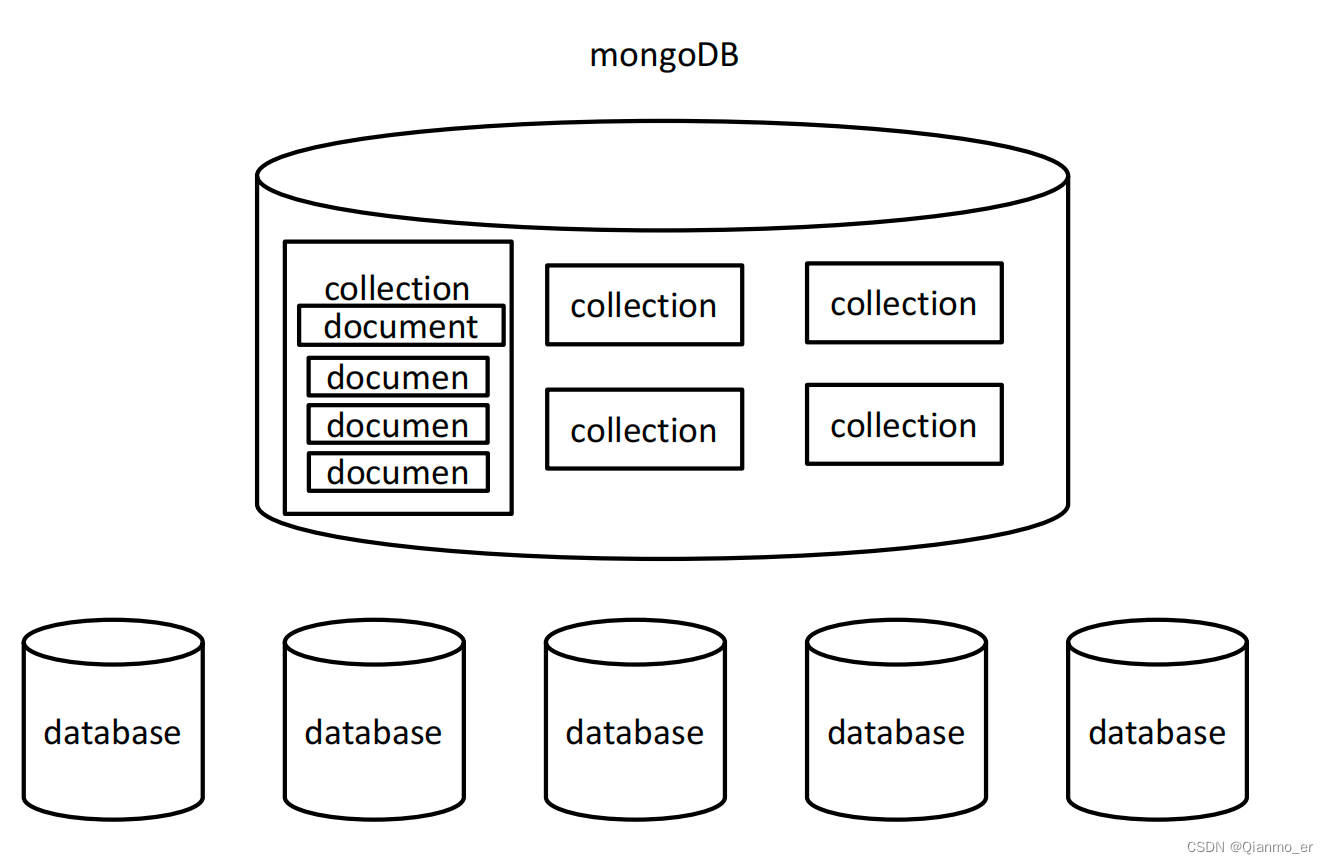
4.2.1.5 创建数据库
- 使用use时,如果数据库存在则会进入到相应的数
据库,如果不存在则会自动创建 - 一旦进入数据库,则可以使用db来引用当前库
use 数据库名
- 向集合中插入文档,如果集合不存在则创建
db.collection.insert(文档)
- 创建一个新的集合
db.createCollection()
- 删除集合
db.collection.drop()
4.2.1.6 文档的增删改查
- 插入文档
-- 向数据库插入文档
db.collection.insert()
-- 插入一个文档对象
db.collection.insertOne()
-- 插入多个文档对象
db.collection.insertMany()
db.stus.insert({ name:'zs',age:28,gender:'男'})
db.stus.find()
insert()可以用于向集合中添加一个或多个文档,可以传递一个对象,或一个数组。
- 可以将对象或数组中的对象添加进集合中
- 添加时如果集合或数据库不存在,会自动创建
- 插入的文档对象会默认添加
_id属性,这个属性
对应一个唯一的id,是文档的唯一标识
db.stus.insert([
{name:'zs',age:28,gender:'男'},
{name:'ls',age:38,gender:'男'},
{name:'ww',age:58,gender:'女'},
])
db.stus.find()
- 查询文档
- 查询条件
• l t 、 lt、 lt、lte、 g t 、 gt、 gt、gte、 n e 、 ne、 ne、or、 i n 、 in、 in、nin、 n o t 、 not、 not、exists、$and
find() 用来查询集合中所有符合条件的文档
find() 可以接收一个对象作为条件参数
{属性 : 值} 查询属性是指定值的文档
-- 查询集合中所有符合条件的文档
db.collection.find()
-- 查询集合中符合条件的第一文档
db.collection.findOne()
-- 查询所有结果的数量
db.collection.find({}).count()
db.stus.find( {_id:'12'} );
db.stus.find({age:23,name:'zs'});
db.stus.findOne({age:38});
db.stus.find({}).count()
-
修改文档
update()默认情况下会使用新对象来替换旧对象
如果需要修改指定的属性,而不是替换,需要使用“修改操作符$set”来完成修改$set修改文档的指定属性$unset删除文档的额指定属性
-- 修改文档,update() 只会修改一个
db.collection.update()
-- 同时修改多个符合条件的文档
db.collection.updateMany()
-- 修改一个符合条件的文档
db.collection.updateOne()
db.stus.update({name:'zs'},{age:23})
db.stus.update(
{"_id":ObjectId("12345678")},
{$set:{
name:'zs',
gender:'女'
}}
)
db.stus.update(
{"_id":ObjectId("12345678")},
{$unset:{
gender:'女'
}}
)
db.stus.update(
{"name":'zs'},
{$set:{
address:'beijing'
}}
)
- 删除文档
remove() 可以根据条件来删除文档,传递的条件的方式和find()一样
-- 删除符合条件的所有文档
-- 如果 remove() 第二个参数传递一个 true ,则只会删除一个
-- 如果传递一个空对象作为参数,则会删除所有的
db.collection.remove()
db.collection.deleteOne()
db.collection.deleteMany()
-- 删除集合
db.collection.drop();
-- 删除数据库
db.dropDatabase();
db.stus.remove({ _id:"2323213" });
db.stus.remove({age:28})
db.stus.insert({
{age:28},
{age:18},
});
db.stus.remove({})
练习:
//1.进入my_test数据库
use my_test
//2.向数据库的user集合中插入一个文档
db.users.insert({
username:"xunwukong"
});
//3.查询user集合中的文档
db.users.find();
//4.向数据库的user集合中插入一个文档
db.users.insert({
username:"zhubajie"
});
//5.查询数据库user集合中的文档
db.users.find();
//6.统计数据库user集合中的文档数量
db.user.find().count();
//7.查询数据库user集合中username为sunwukong的文档
db.users.find({username:"sunwukong"});
//8.向数据库user集合中的username为sunwukong的文档,添加一个address属性,属性值为huaguoshan
db.users.update({username:"sunwukong"},{$set:{address:"huaguoshan"}});
//9.使用{username:"tangseng"} 替换 username 为 zhubajie的文档
db.users.replaceOne({username:"zhubajie"},{username:"tangsneg"});
//10.删除username为sunwukong的文档的address属性
db.users.update({username:"sunwukong"},{#unset:{address:1}});
//11.向username为sunwukong的文档中,添加一个hobby:{cities:["beijing","shanghai","shenzhen"] , movies:["sanguo","hero"]}
db.users.update({username:"sunwukong",{$set:{hobby:{cities:["beijing","shanghai","shenzhen"], movies:["sanguo","hero"]}}}});
db.users.find();
//12.向username为tangseng的文档中,添加一个hobby:{movies:["A Chinese Odyssey","King of comedy"]}
db.users.update({username:"tangsneg"},{$set:{hobby:{movies:["A Chinese Odyssey","King of comedy"]}}});
db.users.find();
//13.查询喜欢电影hero的文档
db.users.find({"hobby.movies":"hero"});
//14.向tangseng中添加一个新的电影Interstellar
// $push 用于向数组中添加一个新的元素
// $addToSet 向数组中添加一个新元素,如果数组中已经存在了该元素,则不会添加
db.users.update({username:"tangseng"},{$push:{"hobby.movies":"Interstellar"}});
db.users.update({username:"tangseng"},{$addToSet:{"hobby.movies":"Interstellar"}});
db.users.find();
//15.删除喜欢beijing的用户
db.users.remove({"hobby.cities":"beijing"});
//16.删除user集合
db.users.remove({});
db.users.drop();
show dbs;
//17.向numbers中插入20000条数据
for(var i=1;i<=20000;i++){
db.bumbers.insert(num:i)
}
db.numbers.find();
db.numbers.remove({});
// 优化后:
var arr = [];
for(var i=1;i<=20000;i++){
arr.push({num:i});
}
db.numbers.insert(arr);
//18.查询numbers中num为500的文档
db.numbers.find({num:500});
//19.查询numbers中num大于5000的文档
db.numbers.find({num:{$gt:500}});
db.numbers.find({num:{$eq:500}});
//20.查询numbers中num小于30的文档
db.numbers.find({num:{$lt:30}});
//21.查询numbers中num大于40小于50的文档
db.numbers.find({num:{$gt:40,$lt:50}});
//22.查询numbers中num大于19996的文档
db.numbers.find({num:{$gt:19996}});
//23.查看numbers集合中的前10条数据
db.numbers.find({num:{$lte:20}});
// limit() 设置显示数组的上限
db.numbres.find().limit(10);
// 在开发时,绝不会执行不带条件的查询
db.numbers.find();
//24.查看numbers集合中的第11条到20条数据
db.numbers.find().skip(10).limit(10);
//25.查看numbers集合中的第21条到30条数据
db.numbers.find().skip(20).limit(10);
4.2.1.7 文档之间的关系
- 一对一
db.wifeAndHusband.insert({
{
name:'zhangsan',
husband:{
name:"lisi"
}
}
})
- 一对多 / 多对一
db.users.insert([
{username:'zhangsan'},
{username:'lisi'},
])
db.order.insert({
list:["苹果","香蕉","橘子"],
user_id:ObjectId("32312312fdf3")
});
// 查找用户 swk 的订单
var user_id = db.users.findOne({username:'swk'})._id;
db.order.find({user_id:user_id})
- 多对多
db.teachers.insert([
{name:'zhangsan'},
{name:'lisi'},
{name:'wangwu'},
]);
db.stus.insert([
{
name:'laoliu',
tech_ids:[
ObjectId("we2343g45")
]
},{
name:'xiaohong',
tech_ids:[
ObjectId("we2343g45erer")
]
}
])
修改器:
- 使用update会将整个文档替换,但是大部
分情况下我们是不需要这么做的 - 如果只需要对文档中的一部分进行更新时,
可以使用更新修改器来进行。 - 学习以下几个修改器
-$set、 $unset 、$inc、$push、$addToSet
$set、$unset
- $set用来指定一个字段的值,如果这个字段不存在,则创建它。
- 语法:
db.test_coll.update(查询对象, {$set:更新对象});- $unset可以用来删除文档中一个不需要的字段,用法和
set类似。
$inc
$inc用来增加已有键的值,或者该键不存在那就创建一个$inc只能用于Number类型的值
4.2.1.8 sort 和 投影
sort() 可以用来指定文档的排序的规则,需要传递一个对象来指定排序规则
limit,skip,sort 可以任意的顺序进行调用
-- 查询文档时,默认情况是按照 _id 的值进行排列(升序)
db.emp.find({}).sort();
-- 1 表示升序,-1 表示将序
db.emp.find({}).sort({sal:1,empbo:-1});
// 在查询时,可以在第二个参数的位置设置查询结果的 投影
db.emp.find({},{ename:1,_id:0,sal:1})
练习:
//1.将dept和emp集合导入到数据库中
db.dept.find()
db.emp.find()
//2.查询工资小于2000的员工
db.emp.find({sal:{$lt:2000}});
//3.查询工资在1000-2000之间的员工
db.emp.find({sal:{$lt:2000,$gt:1000}});
//4.查询工资小于1000或大于2500的员工
db.emp.find({$or:[{sal:{$lt:1000}},{}]});
//5.查询财务部的所有员工
db.dept.findOne({dname:"财务部"}).deptno;
//6.查询销售部的所有员工
var depno = db.dept.findOne({dname:"财务部"}).deptno;
db.emp.find({depno:depno});
//7.查询所有mgr为7698的所有员工
db.emp.find({mgr:7698});
//8.为所有薪资低于1000的员工增加工资400元
db.emp.updateMany({sql:{$lte:1000}},{$inc:{sql:400}});
db.emp.find();
4.2.2、Mongoose
- Mongoose就是一个让我们可以通过Node来操作
MongoDB的模块。 Mongoose是一个对象文档模型(ODM)库,它对Node原生的MongoDB模块进行了进一步的优化封装,并提供了更多的功能。- 在大多数情况下,它被用来把结构化的模式应用到一个MongoDB
集合,并提供了验证和类型转换等好处。
4.2.2.1 mongoose的好处
- 可以为文档创建一个模式结构(Schema)
- 可以对模型中的对象/文档进行验证
- 数据可以通过类型转换转换为对象模型
- 可以使用中间件来应用业务逻辑挂钩
- 比Node原生的MongoDB驱动更容易
4.2.2.2 新的对象
- Schema(模式对象)
Schema对象定义约束了数据库中的文档结构
- Model
- Model对象作为集合中的所有文档的表示,相当于MongoDB数据库中的集合
collection
- Model对象作为集合中的所有文档的表示,相当于MongoDB数据库中的集合
- Document
- Document表示集合中的具体文档,相当于集合中的一个具体的文档
4.2.2.3 通过mongoose连接MongoDB
- 安装mongoose包
npm install mongoose
- 引入并加载Mongoose
const mongoose = require("mongoose")
- 连接数据库
如果端口号是默认端口(27017),则可以省略不写
mongoose.connect("mongodb://地址")
地址例子:mongodb://127.0.0.1/mg_test
- 断开连接(一般不需要调用)
mongoose.disconnect()
- 监听MongoDB数据库的连接状态
在mongoose对象中,有一个属性叫做connection,该对象表示的就是数据库连接,通过件事对象的状态,来舰艇数据库的连接与断开
// 数据库连接成功的事件
mongoose.connection.once("open",function(){});
// 数据库断开的事件
mongoose.connection.once("close",function(){});
完整代码:
// 引入mongoose
var mongoose = require('mongoose')
// 连接数据库
mongoose.connect("mongodb://127.0.0.1/mongoose_test",{ useMongoClient:true });
mongoose.connection.once("open",function(){
console.log("数据库连接成功~~~")
})
// 断开数据库连接
mongoose.disconnect();
- 一旦连接了MongoDB数据库,底层的Connection对象就可以通过
mongoose模块的conection属性来访问。 connection对象是对数据库连接的抽象,它
提供了对象连接、底层的Db对象和表示结合
的Model对象的访问。- 并且可以对
connection对象上的一些事件进行监听,来获悉数据库连接的开始与端开。 - 比如,可以通过
open和close事件来监控连接
的打开和关闭
4.2.2.4 Schema模式对象
- 使用Mongoose你必须经常定义模式。
- 模式为集合中的文档定义字段和字段类型。
- 如果你的数据是被结构化成支持模式的,这是非常有用的。
- 简单来说,模式就是对文档的约束,有了模式,文档中的字段必须符合模式的规定。否则将不能正常操作。
- 对于在模式中的每个字段,你都需要定一个特定的值类型。受支持的类型如下:
String、Number、Boolean、Array、Buffer、Date、ObjectId或Oid、Mixed
模式需要通过mongoose的Schema属性来创建,这个属性是一个构造函数。
new Schema(definition,option)
• definition(描述模式)
• options 配置对象,定义与数据库中集合的交互

// 引入mongoose
var mongoose = require('mongoose')
// 连接数据库
mongoose.connect("mongodb://127.0.0.1/mongoose_test",{ useMongoClient:true });
mongoose.connection.once("open",function(){
console.log("数据库连接成功~~~")
})
// 将 mongoose.Schema 赋值给一个变量
var Schema = mongoose.Schema;
// 创建 Schema (模式) 对象
var stuSchema = new Schema({
name:String,
age:Number,
gender:{
type:String,
default:"female"
},
address:String
});
/**
* 通过 Schema 来创建 Model
* Model 代表的是 数据库中的集合,通过 Model 才能对数据库进行操作
* mongoose.model(modelName,schema)
* modelName 就是要映射的集合名 mongoose 会自动将集合变成复数
*/
var StuModel = mongoose.model("students",stuSchema);
// 向数据库中插入一个文档
// StuModel.create(doc,function(){})
StuModel.create({
name:"张三",
age:18,
gender:"male",
address:"北京"
},function(err){
if(!err){
console.log("插入成功~~~")
}
});
options常用选项
| 属性 | 说明 |
|---|---|
| autoIndex | 布尔值,开启自动索引,默认true |
| bufferCommands | 布尔值,缓存由于连接问题无法执行的语句,默认true |
| capped | 集合中最大文档数量 |
| collection | 指定应用Schema的集合名称 |
| id | 布尔值,是否有应用于_id的id处理器,默认true |
| _id | 布尔值,是否自动分配id字段,默认true |
| strict | 布尔值,不符合Schema的对象不会被插入进数据库,默认true |
4.2.2.5 Model模型对象
-
一旦定义好了Schema对象,就需要通过该Schema对象来创建Model对象。
-
一旦创建好了Model对象,就会自动和数据库中对应的集合建立连接,以确保在应用更改时,集合已经创建并具有适当的索引,且设置了必须性和唯一性。
-
Model对象就相当于数据库中的集合,通过Model可以完成对集合的CRUD操作。
-
创建模型对象需要使用mongoose的model()方法,语法如下:
model(name, [schema], [collection] , [skipInit])
- name参数相当于模型的名字,以后可以同过name找到模型。
- schema是创建好的模式对象。
- collection是要连接的集合名。
- skipInit是否跳过初始化,默认是false。
- 一旦把一个Schema对象编译成一个Model对象,你就完全准备好开始在模型中访问、添加、删除、更新和删除文档了。也就是说有了模型以后我们就可以操作数据库了。
- 添加
有了Model,就可以对数据库进行增删改查操作
Model.create(doc(s),[callback]) // 用来创建一个或多个文档并添加到数据库
参数:
doc(s) 可以是一个文档对象,也可以是一个文档对象的数组
callback 当操作完成后调用的回调函数
StuModel.create([
{
name:"zhangsan",
age:28,
gender:'male',
address:'beijing'
},{
name:"lisi",
age:16,
gender:'male',
address:'jiangxi'
},
],function(err){
if(!err){
console.log("插入成功~~~")
}
})
- 查询
- 查询所有符合条件的文档
Model.find(conditions,[projection],[options],[callback])
- 根据文档的
id属性查询文档
Model.findById(id,[projection],[options],[callback])
- 查询符合条件的第一个文档,综合返回一个具体的文档
Model.findOne([conditions],[projection],[options],[callback])
conditions查询的条件projection投影options查询选项(skip limit)callback回调函数,查询结果会通过回调函数返回
StuModel.find({},"name age -_id",function(err,docs){
if(!err){
console.log(docs);
}
})
StuModel.findOne({},function(err,docs){
if(!err){
console.log(docs);
}
})
StuModel.findById("sds3wewewesdsd343434",function(err,docs){
if(!err){
console.log(docs);
// 通过 find() 查询的结果
}
})
- 修改
- 修改所有符合条件的文档
Model.update(conditions,doc,[options],[callback])
- 修改多个符合条件的文档
Model.findByMany(conditions,doc,[options],[callback])
- 修改一个符合条件的文档
Model.findOne(conditions,doc,[options],[callback])
conditions查询的条件doc修改后的对象options配置参数callback回调函数,查询结果会通过回调函数返回
// 修改张三的年龄为20
StuModel.updateOne({name:"张三"},{$set:{age:20}},function(err){
if(!err){
console.log(docs);
// 通过 find() 查询的结果
}
})
- 删除
Model.remove(conditions,[callback])
Model.deleteOne(conditions,[callback])
Model.deleteMany(conditions,[callback])
StuModel.remove({name:"zhangsan"},function(err){
if(!err){
console.log("删除成功~~~")
}
});
统计文档的数量
Model.count(conditions,[callback])
StuModel.count({},function(err,count){
if(!err){
console.log(count)
}
});
4.2.2.6 Document文档对象
- 通过Model对数据库进行查询时,会返回Document对象或Document对象数组。
- Document继承自Model,代表一个集合中的文档。
- Document对象也可以和数据库进行交互操作。
- Document对象的方法:
| 方法 |
|---|
| equals(doc) |
| id |
| get(path,[type]) |
| set(path,value,[type]) |
| update(update,[options],[callback]) |
| save([callback]) |
| remove([callback]) |
| isNew |
| isInit(path) |
| toJSON() |
| toObject() |
// 创建一个 Document
var stu = new StuModel({
name:'章三',
age:23,
gender:'male'
address:"北京"
});
console.log(stu)
stu.save(function(err){
if(!err){
console.log("保存成功~~~");
}
})
StuModel.findOne({},function(err,doc){
if(!err){
console.log(doc);
doc.update({$set:{age:18}},function(err){
if(!err){
console.log("修改成功~~~");
}
});
doc.age = 19;
doc.save();
doc.remove(function(err){
if(!err){
console.log("删除成功~~~");
}
})
}
})
优化:
- 定义一个模块
conn_mongo.js,用来连接 MongoDB 数据库
var mongoose = require('mongoose');
mongoose.connect("mongodb://127.0.0.1/mongoose_test",{useMongoClient:true})
mongoose.connection.once("open",function(){
console.log("数据库连接成功~~~")
})
- 定义模型
// 定义 Student 的模型
var mongoose = require("mongoose");
var Schema = mongoose.Schema;
var stuSchema = new Schema({
name:String.
age:Number,
gender:{
type:String,
default:"female"
},
address:String
});
// 定义模型
var StuModel = mongoose.model("student",stuSchema);
module.exports = StuModel;
- 在
index.js引用:
require("./tools/conn_mongo")
var Student = require("./models/student");
console.log(Student)
// 查询
Student.find({},function(err,docs){
if(!err){
console.log(docs);
}
})



















 1045
1045

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











