




 本文详细介绍使用KNN算法预测年收入是否超过50K美元的过程,包括数据预处理、特征量化、模型训练、性能评估及调优策略,如参数调整、数据归一化、标准化和正则化。
本文详细介绍使用KNN算法预测年收入是否超过50K美元的过程,包括数据预处理、特征量化、模型训练、性能评估及调优策略,如参数调整、数据归一化、标准化和正则化。
练习 2 预测年收入是否大于50K美元
读取adult.txt文件,最后一列是年收入,并使用KNN算法训练模型,然后使用模型预测一个人的年收入是否大于50
1. 读取文件,查看相应的信息
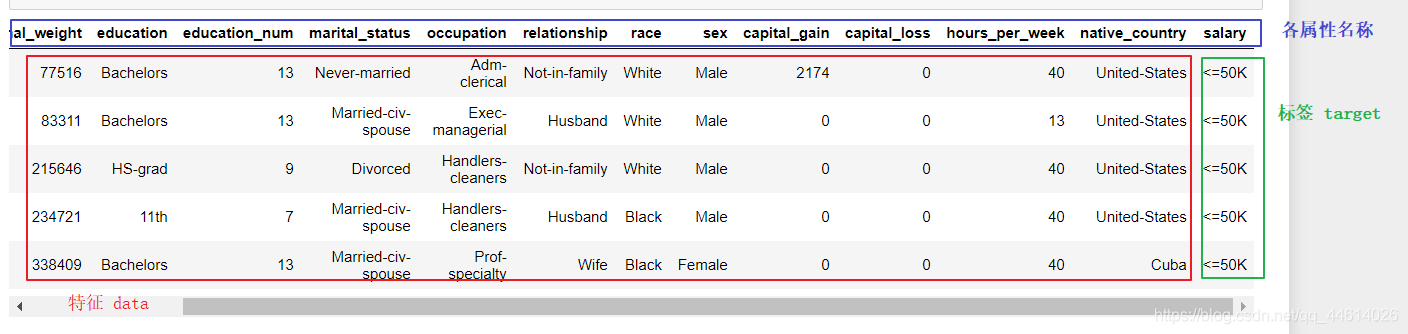
2. 将特征和标签分离
取特征 : 用切片方式获取 对于DataFrame,不能用属性切片,只能用索引切片 第0个维度不变,第1个从开头切到最后一个(前闭后开)
取标签 : 取 salary
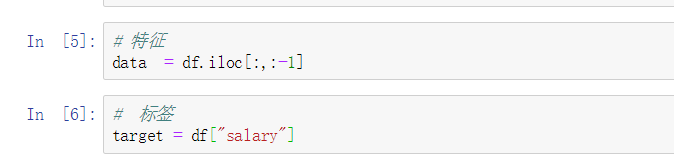
查看一下 特征data 和 标签target
data总共有32561条数据,每条数据14个特征
target 只有 <=50k 和 >50k
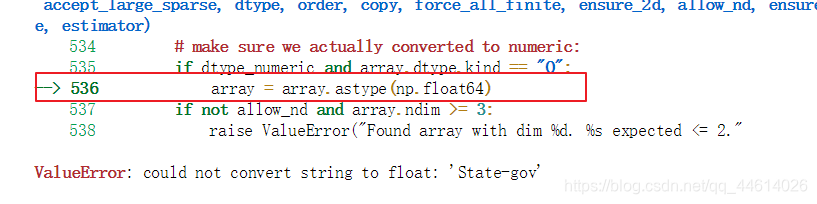
那现在是不是就可以用knn算法去训练了呢?
哦豁!报错了
错误是没有办法把string类型转换成float类型
sklearn中,和数学运算有关算法,不能传字符串的
但是这些特征data中,含有大量的字符串,怎么解决这个问题?
对字符串属性进行量化,量化成数字

3. 对字符串属性进行量化
- 查看一下都有哪些字符串

- 将这些字符串用数字取代
用序号(下标)去取代
需要用到映射
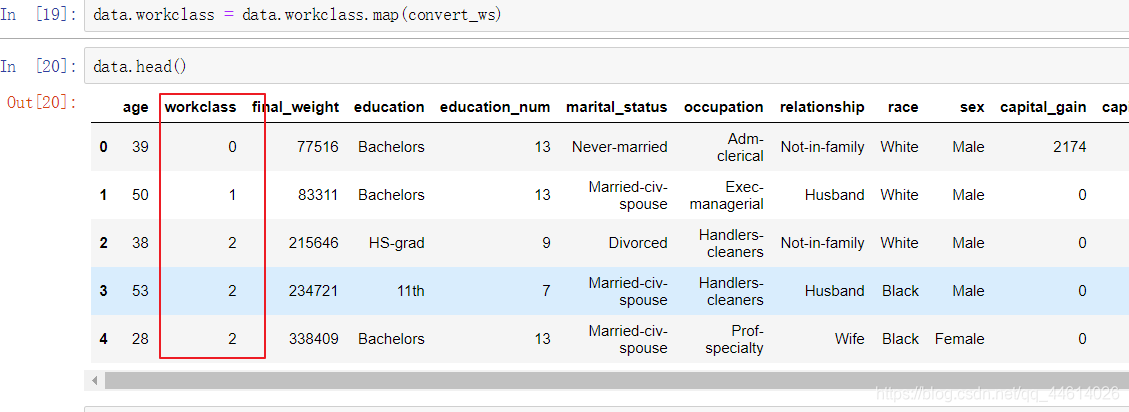
定义一个函数,传入字符串,返回序号
使用map()函数进行映射
可以看到workclass这一列的字符串就用相应的数字取代了


- 将其他需要量化的字符串进行量化
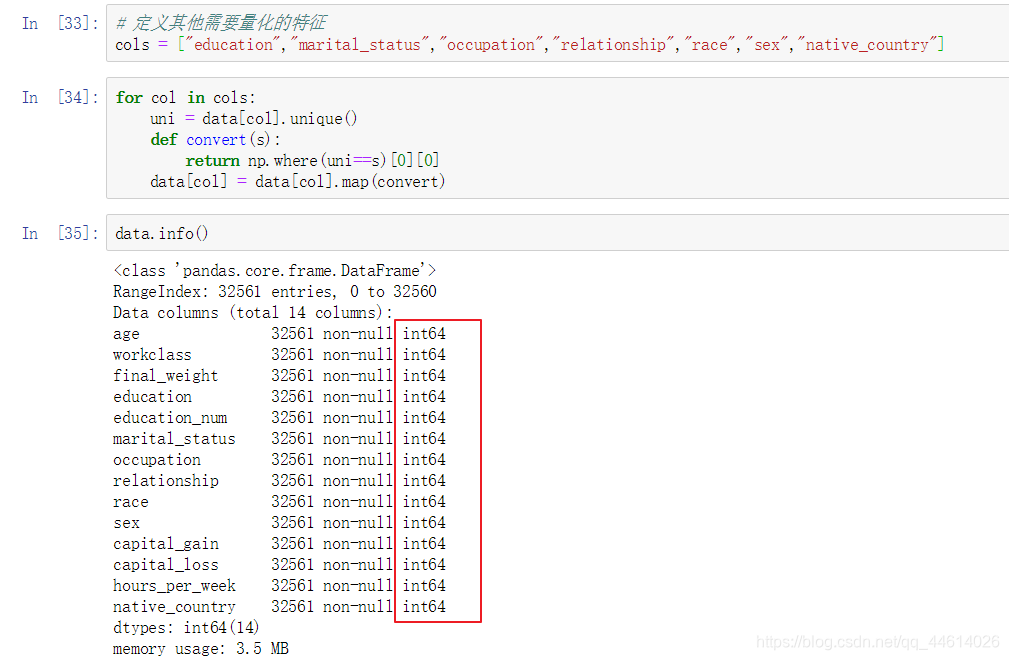
定义其他需要量化的特征,使用同样的方法
可以看到,都变成了数字类型,可以参与到运算中了
4. 分离测试集与训练集

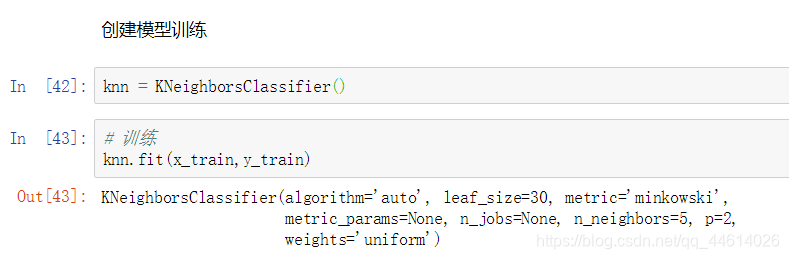
5. 创建模型训练
6. 性能评测

经验性能和泛化性能都不怎么好
这里引进一个概念
【性能检测指标】
案例:
真正的标签: 1 0 0 1 1 1 1 1 1 1 0 1
预测的标签: 1 0 1 1 1 1 1 1 0 1 0 1
1、准确率:预测正确的数据占总数据的比例 ,上例中准确率 10/12 = 5/6
2、精确率(查正率):表示每一个类别预测准确的标签数占预测为该类别的标签数的比例
上例中: 类别“1”,预测为1的有9个,其中正确的有8个 类别“1”的查正率为:8/9
类别“0”,预测为0的有3个,其中正确的有2个,类别“0”的查正率为:2/3
3、召回率(查全率):表示每一个类别预测正确的标签数占真正为该标签的数量的比例
上例中:类别“1”,真实为1的有9个,预测为1且正确的有8个,类别“1”的查全率为:8/9
类别“0”,真实为0的有3,预测为0缺正确的有2个,0个查全率为:2/3
4、F1值:查正率和查全率的调和平均数
F1_0 = 1/(1/0的查正率 + 1/0的查全率) = 1/(3/2 + 3/2) = 1/3
所以,如果一个模型,查正率和查全率差别比较大的话,说明这个模型并不怎么好
7. 预测
由于数据太多,不好对比
sklearn中 有一个专门针对查正率和查全率等一系列的指标的模型
导入相关函数
from sklearn.metrics import classification_report
classification_report的英文意思是分类模型的检测报告
需要传两个参数
y_pred=y_ 预测的y值
y_true=y_test 真实的y值
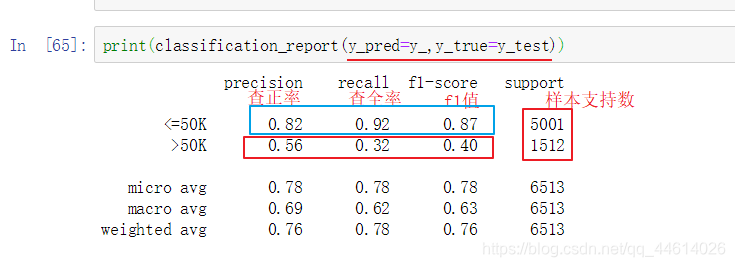
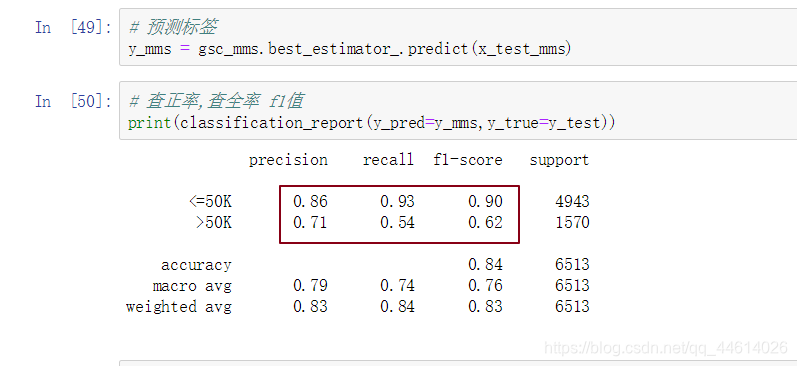
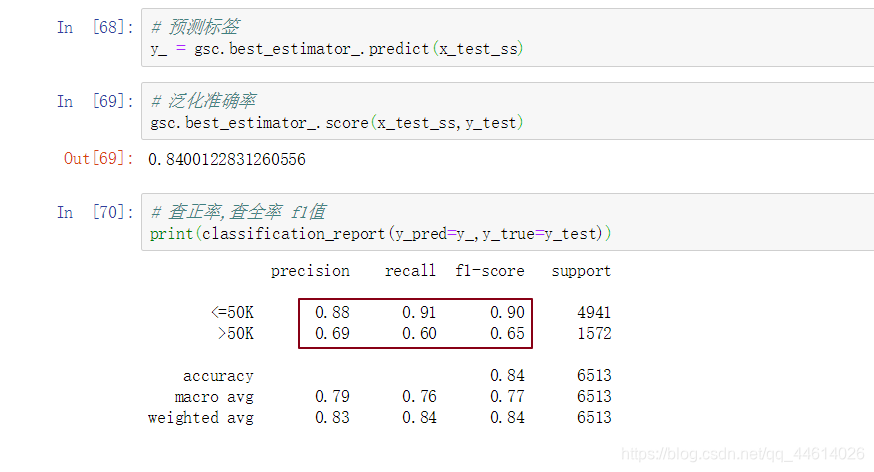
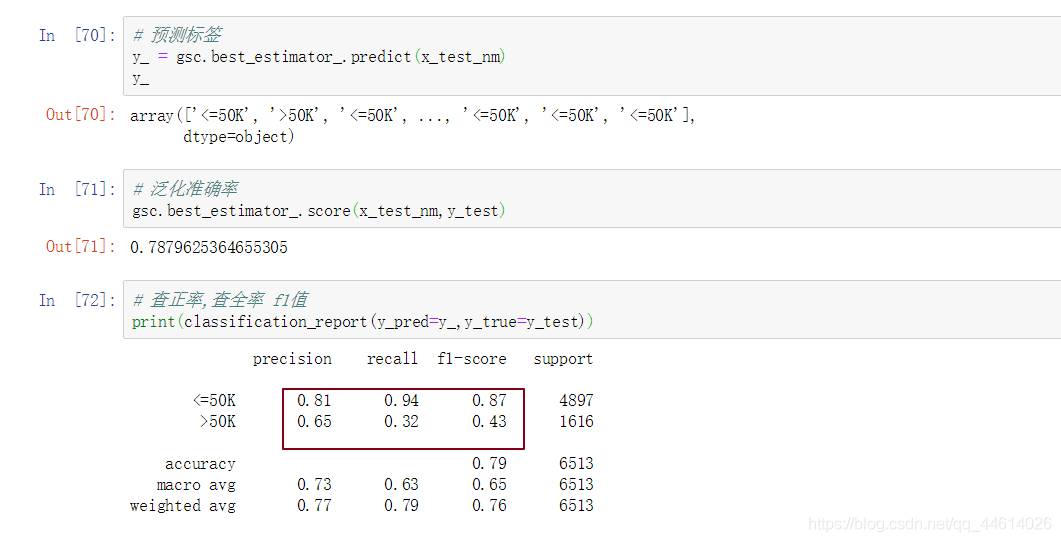
查看打印的内容,<=50k的整体性能还好,但是>50k的性能就很低了,
这是因为<=50k的和>50k的样本支持率差距太大,一个5001,一个1512,
所以这个模型性能不行,就需要进行模型的调优
8. 模型调优
8.1、从算法方面来调优
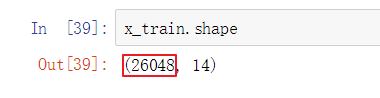
- 求出k的取值范围
x_train有26048条数据
开平方求出k的取值范围

- 用网格搜索进行参数的调优
由于当前计算条件有限制我无法对161个参数全部调优,从161中随机取出20个来调(实际工作中建议全调)
对上面的knn算法模型进行调优,训练的过程中耗时可能会有点长,因为数据很多,计算量大
如果全调,修改这一步即可,n_jobs=-1表示有多少给就调优多少个(取到最后一个)
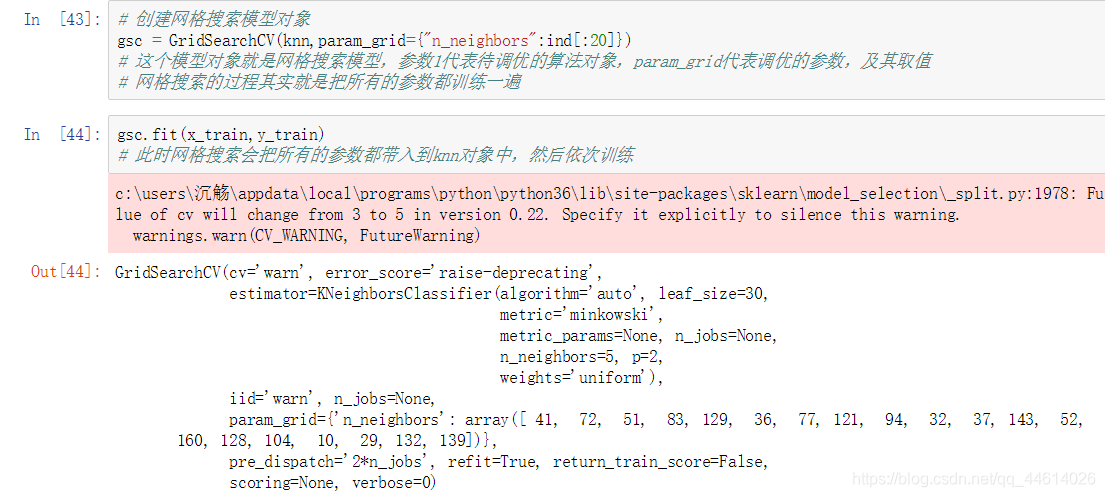

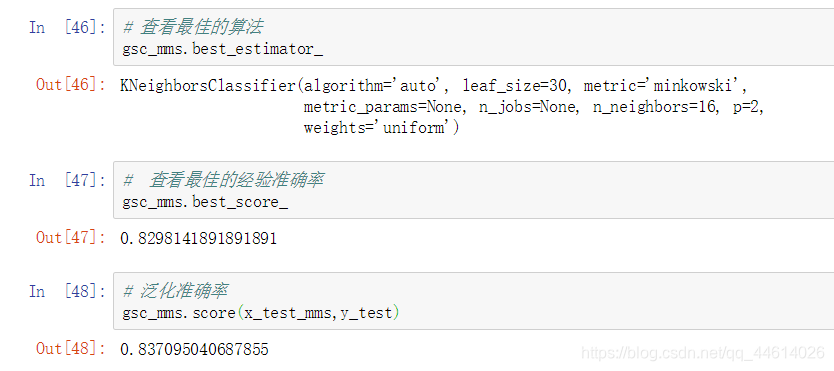
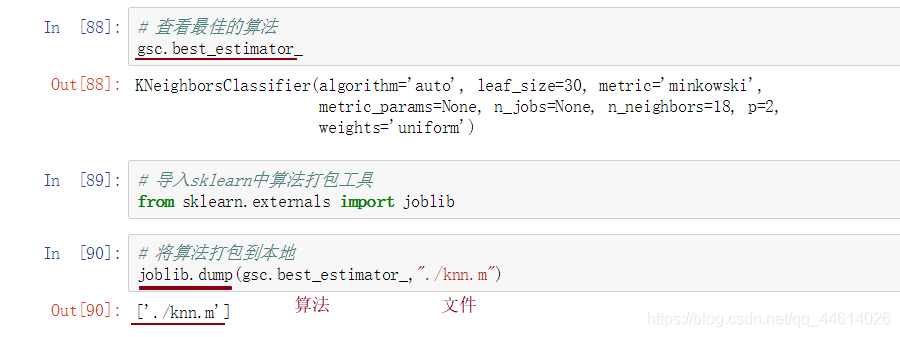
- 查看最佳算法的信息
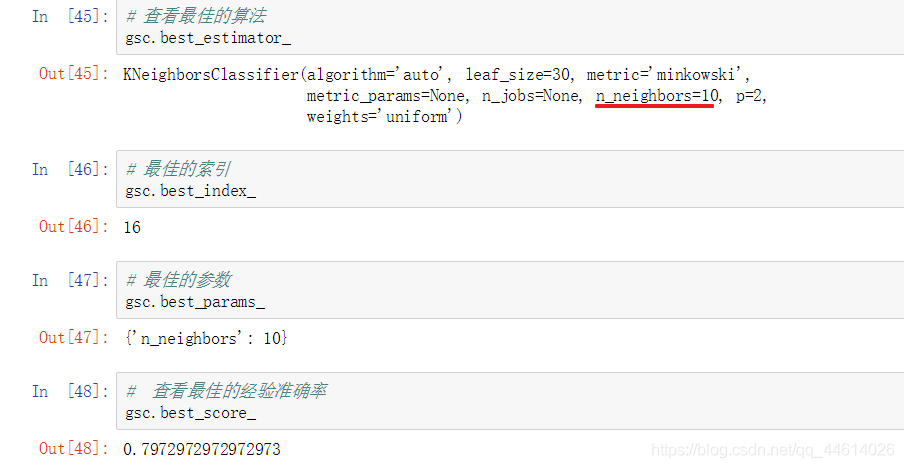
- 评测最优算法在测试集上的泛化能力
可以发现,泛化能力对比以前的有所增强,虽然不是很多
8.2、从数据方面来调优
通过观察数据集,我们发现某些属性的值特别大,而某些属性的值非常小,这样的话,比较小的那些属性对于整个模型训练起到的作用微乎其微,而数据特别大的那些属性反倒会主导整个预测结果,容易造成模型的泛化能力不足,从而造成欠拟合现象
为了避免这种情况,我们要尽量的是所有的特征的数据控制在一个合理的大致相同范围之内,这就是数据优化
数据优化的方式:归一化、正则化、标准化
8.2.1 归一化:将数据转化成(0-1)之间的值
公式:(data-min(data))/(max(data)-min(data))
1)创建归一化算法模型

2) 对数据进行归一化处理
3) 对归一化以后的数据进行网格搜索
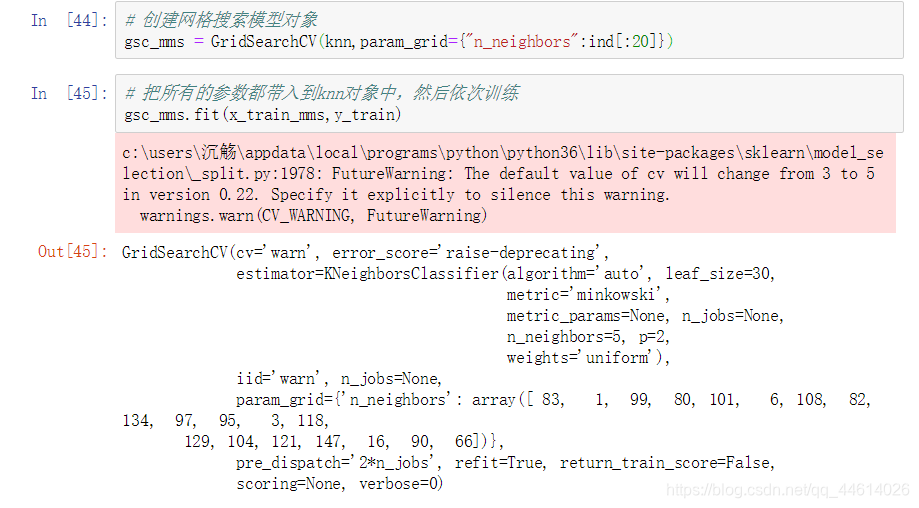
- 查看相关信息
8.2.2 标准化
公式:(data-std(data))/std(data)
1)创建标准化算法模型

2) 对数据进行标准化处理
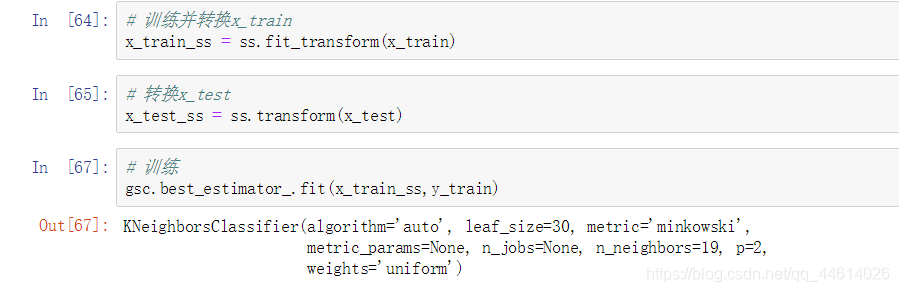
- 查看相关信息
8.2.3 正则化
正则化有两种,l1正则化和l2正则化
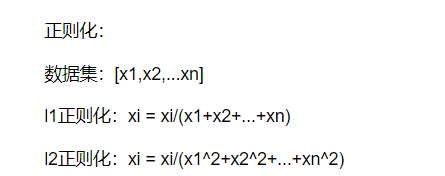
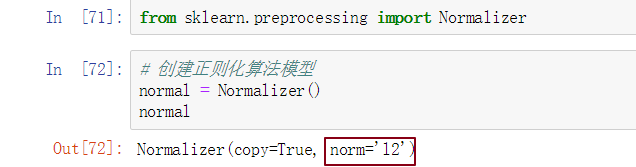
- 创建正则化算法模型
默认是l2正则化模型
2) 对数据进行正则化处理
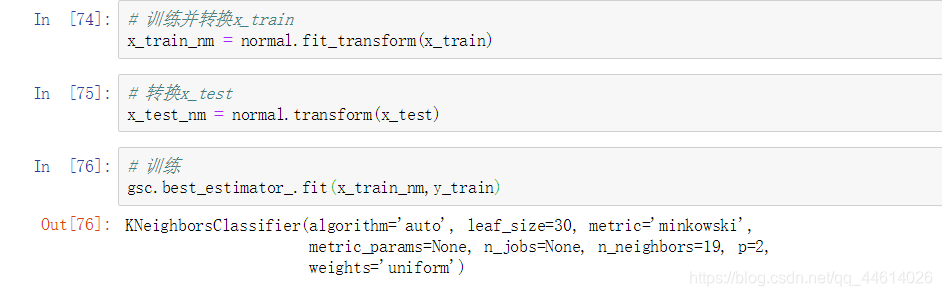
- 查看相关信息
9. 打包算法
当一个算法经过调优以后,如果达到了理想情况我们需要将这个算法进行打包,以供系统人员使用
- 打包
使用joblib.dump()函数打包
查看打包的文件
算法使用说明文档:
1)knn.m这个文件是算法的核心文件,里面封装了整个算法的流程
2)使用这个算法首先要安装numpy、pandas、sklearn等框架
3)使用该算法之前,首先要导入sklearn中的joblib模块,具体代码:from sklearn.externals import joblib
4)用joblib把本地的算法的.m文件导入(joblib.load(“路径”))
5)在使用这个算法预测之前首先要把数据进行归一化,具体操作(附代码)
6)使用我们导入的文件调用predict方法把归一化的数据传入就可以得到预测结果
- 算法的使用


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









