




 本文介绍了一种基于机器学习的手写数字识别方法,包括图片预处理、数据集划分、模型训练及参数调优过程。通过将图片转换为784维特征向量,利用sklearn算法实现数字识别,并通过网格搜索提升模型精度。
本文介绍了一种基于机器学习的手写数字识别方法,包括图片预处理、数据集划分、模型训练及参数调优过程。通过将图片转换为784维特征向量,利用sklearn算法实现数字识别,并通过网格搜索提升模型精度。
手写体数字识别
与ipynb文件夹同级的data文件夹下有10个文件,
每个文件中都是手写体数字的图片
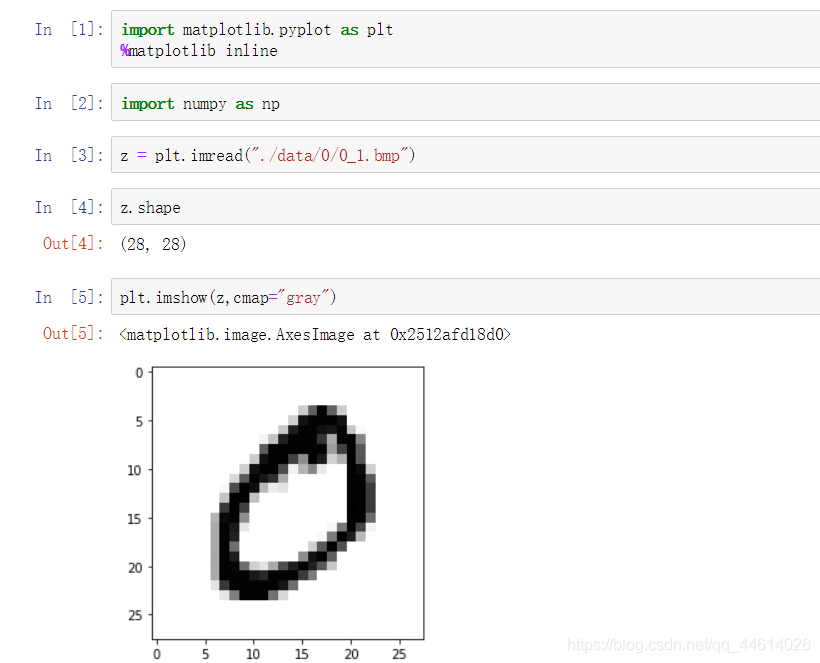
1. 导入绘图模块,查看图片
先读取一张图片,图片为28x28像素
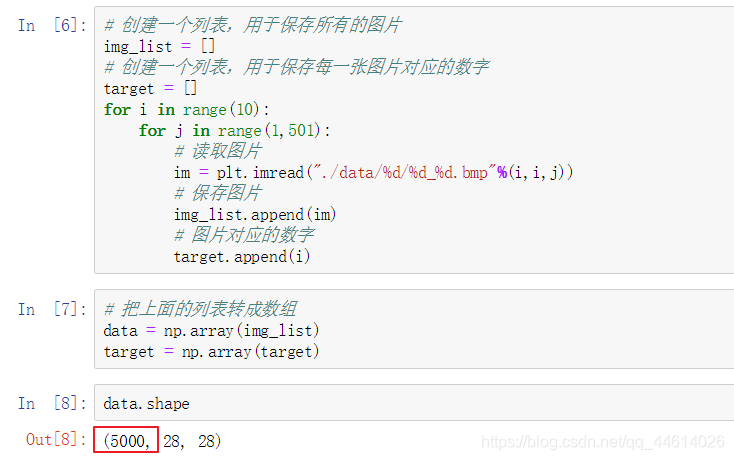
2. 读取文件所有的手写体数字图片
这是一个三维数组,总共有5000张图片
3. 模型训练
3.1 sklearn的算法只接受二维以下的数组
所以不能直接训练
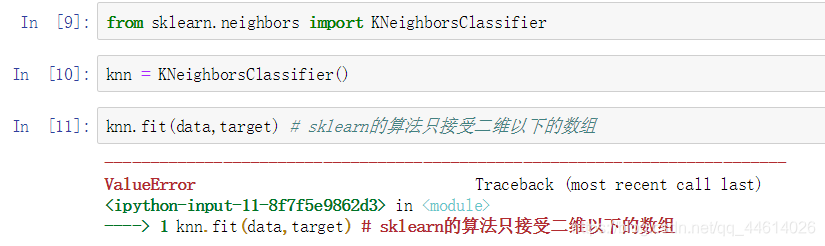
3.2 使用reshape()函数将数组由三维变成二维
data是一个5000x28x28的三维数组,5000代表有5000张图片,属于数据的样本量,28x28代表每一个样本,样本比价特别,是图片,样本的特征就是图片的每一个像素,这些像素现在排列成了一个28x28的方阵,我们可以把这方阵改成一个784的行向量
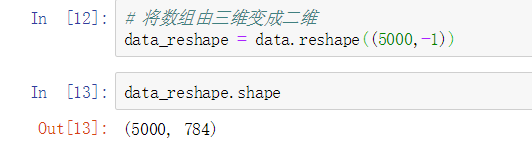
3.3 切分训练集合测试集
4. 算法参数调优
4.1 用网格搜索进行参数的调优
由于计算机性能有限,没办法对参数进行全调,将64参数个随机打乱,取随机打乱的前20个参数随机调优
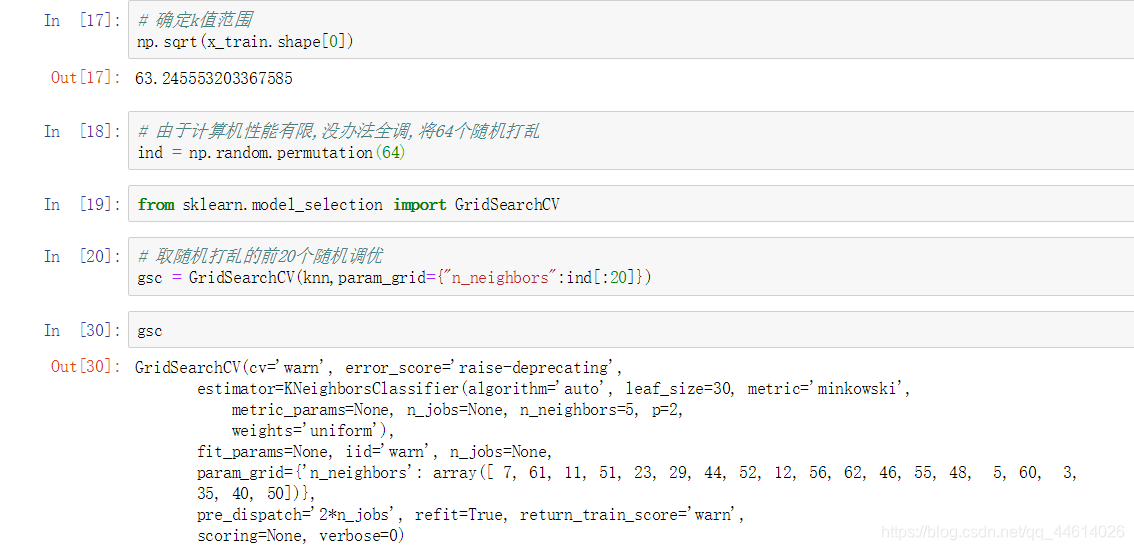
4.2 训练调优
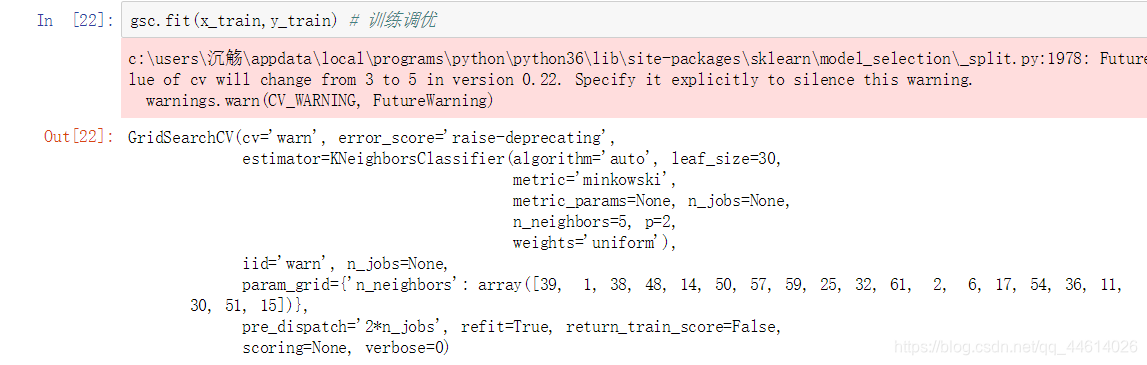
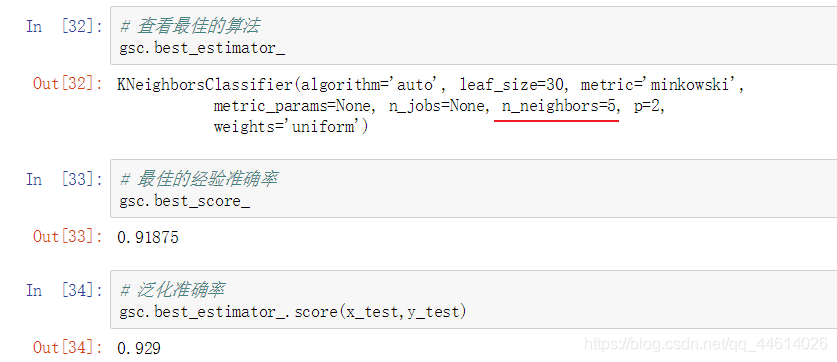
4.3 查看相关信息
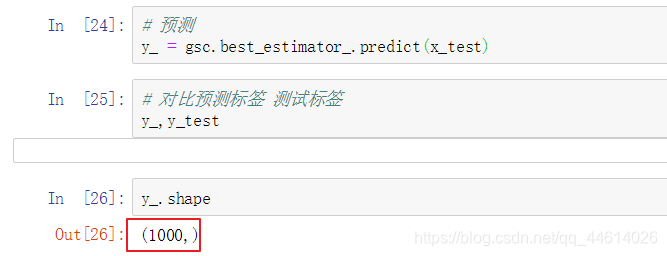
4.4 预测
预测标签,可以看到预测标签有1000条数据,简单对比一些测试标签和预测标签,数据太多,不一一查看
5. 算法打包
6. 用图像来画出x_test其中前100条数据的图像,以及其预测情况和真实情况

查看预测和真实情况

还是有数据会识别出错的,这是必然的

















 1036
1036

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









