







出现原因:agent和环境互动,但是获取不到reward。【模糊】
解决方案:收集专家做的示范。【假设不知道该怎么定义奖励,可以收集到一些很厉害的智能体(比如人)跟环境实际上的互动的话,就可以考虑模仿学习这个技术。】
在自动驾驶汽车里面,虽然没有办法给出自动驾驶汽车的奖励,但可以收集很多人类开车的纪录。
behavior cloning 行为克隆
类比 【监督学习:收集很多人在具体state的时候采取什么action,得到训练数据,学习一个网络NN,就是一个actor,在输入相同state的时候希望输出相同action】
存在问题:1.收集观测有限 2.行为完全克隆会包含无用action 3.训练数据和测试数据不匹配
数据集聚合(dataset aggregation,DAgger)
会希望收集更多样性的数据,而不是只收集专家所看到的观测。会希望能够收集专家在各种极端的情况下,它会采取什么样的行为。
逆强化学习
提出原因:机器和环境互动,得不到奖励,但我们会有一堆专家示范的数据(人开车数据)
解决方案:由专家示范数据反推出奖励函数,先找出奖励函数,找出奖励函数以后,再去用强化学习找出最优演员。
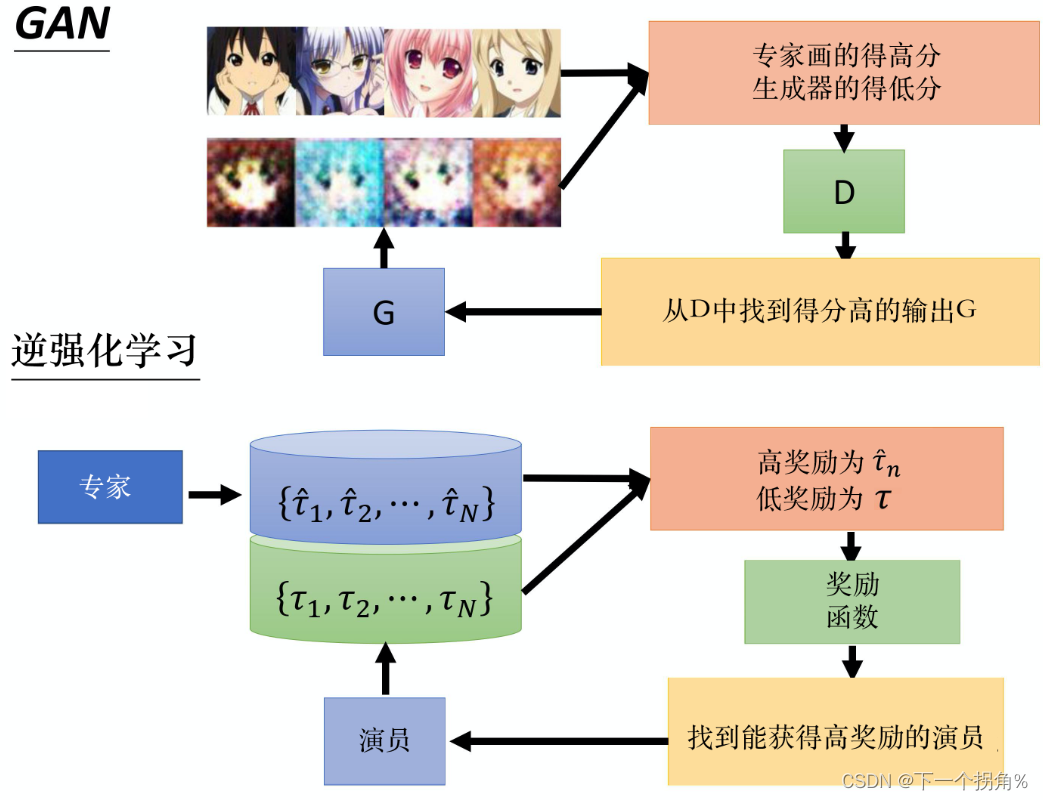
具体操作:
首先,有一个专家π^,这个专家去跟环境互动,给我们很多轨迹:{τ1^,τ2^,N^}。有一个演员π,一开始演员很烂,这个演员也去跟环境互动。
然后,用专家轨迹要反推出奖励函数。这个奖励函数的原则就是专家得到的分数要比演员得到的分数高(先射箭,再画靶)。
然后reward function的更新,使得actor得得分越来越高,但是不超过expert的得分。
最终的reward function应该让expert和actor对应的reward function都达到比较高的分数,并且从最终的reward function中无法分辨出谁应该得到比较高的分数。
以上只是先了解一下思想

















 571
571

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









