







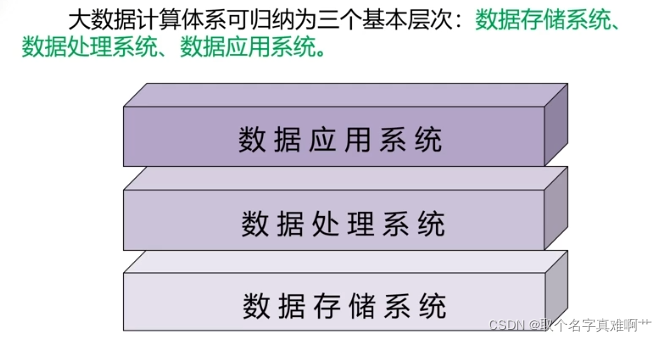
大数据计算系统
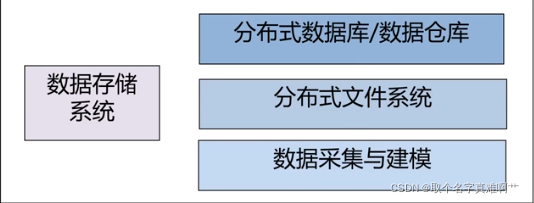
数据存储系统
- 包括数据采集层(系统日志、网络爬虫、无线传感器网络、物联网、以及各种数据源) ;
- 数据清洗、抽取与建模(将各种类型的结构化、非结构化、异构数据转化为标准存储格式数据,并定义数据属性及值域) ;
- 数据存储架构(集中式/分布式文件系统、关系型数据库/分布式数据库、行存储数据结构/列存储数据结构,键值对结构,哈希表(Hash Table)检索) ;
- 数据统一接口等。
数据存储系统提供:
- 数据清洗、抽取与建模(将各种类型的结构化、非结构化、异构数据转化为标准存储格式,键值对结构,哈希表(Hash Table)检索)数据,并定义数据属性及值域)
- 数据存储架构(集中式/分布式文件系统、关系型数据库/分布式数据库、行存储数据结构/列存储数据结构
- 数据仓库与数据服务
- 统一数据接口(Unified Data Access Interface)
数据建模
数据模型定义为三个层次:概念模型(conceptual model),逻辑模型(logicmodel),物理模型(physical model)。
●概念模型主要基于用户的数据功能需求产生,通过与客户的交流获得对客户业务要素、功能和关联关系的理解,从而定义出该业务领域内对应于.上述业务要素和功能的实体类(entity class) 。
●逻辑模型则给出更多的数据实体细节,包括主键、外键、属性、索引关系、约束、甚至是视图,以数据表、数据列、值域、面向对象类(object-oriented class)、XML标签等形式来描述。
●物理模型(有时又称为存储模型)则是考虑数据的存储实现方式,包括数据拆分(partition)、数据表空间、数据集成。
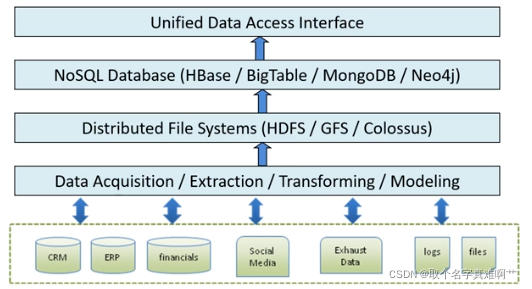
数据存储
在存储结构中:数据库提供了数据的逻辑存储结构;分布式文件系统提供了数据的物理存储结构。
逻辑存储结构
也称为数据的逻辑结构。数据存储的逻辑模型(抽象模型),即纸面上人们设计的存储模式或数据结构,比如矩阵(matrix) 、树(tree) 、数据库表单(form)等。主要用于表达数据属性及数据元素相互间的管联关系。
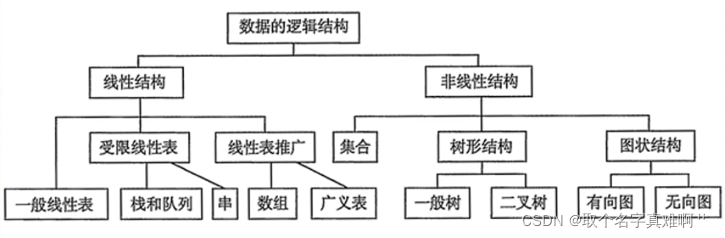
物理存储结构
也称为数据的存储结构。数据存储的物理模型,即在物理存储介质(如磁盘)上数据实际的排列方式。数据的存储结构主要有:顺序存储、链式存储、索引存储和散列存储。.
- 顺序存储:把逻辑上相邻的元素存储在物理位置上也相邻的存储单元里,元素之间的关系由存储单元的邻接关系来体现。
- 链接存储: 不要求逻辑上相邻的元素在物理位置上也相邻,借助指示元素存储地址的指针表示元素之间的逻辑关系。
- 索引存储: 在存储元素信息的同时,还建立附加的索引表。索弓|表中的每- -项称为索引项,索引项的一般形式是: (关键字, 地址)
- 散列存储: 根据元素的关键字直接计算出该元素的存储地址,又称为Hash存储。
分布式文件系统
提供数据的物理存储架构
主要的分布式文件系统技术和产品
- HDFS(Hadoop distribute file system)
- GFS(Google file system)
都使用了master/slave(主从结构)架构:包括一个主节点和一组从节点
在存储时,会将一个大的数据文件分成小的数据块(data block),数据块有着固定的尺寸和大小,对划分出来的每一个数据块,产生多个备份,把数据块的原版和多个备份一起存入分布式文件系统中。
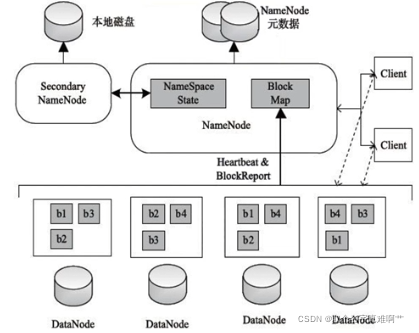
namenode:主节点
datanode:从节点
client:上层的大数据应用
secondary namenode:主机点的备份节点(主节点一旦出现问题,立刻替代主节点进行工作)
b1、b2、b3、b4:拆分出来的数据块及其备份节点(保证了数据的容错和恢复机制)
不管是主节点还是从节点,都是一台独立的机器,有自己的本地磁盘和CPU。主节点和从节点通过高速网络连接在一起,形成一个Hadoop集群。
优势:
- 开源
- 易于开发
- 运行在廉价通用的设备上
- 非常好的扩展性
缺点:
- 数据读取速度不够
- 不适合处理小尺度文件
- 不擅长对单个数据的读取和更新
分布式数据库(NoSQL)
优势:
- 不需要提前定义数据结构
- 扩展性很强
- 运行数据划分
- 在一定时间内不用对数据库进行数据同步(关系型数据库所必须的)
NoSQL数据库的4种类型
●键值数据库(key-value store database)
●列存储数据库(column family-oriented database)
●文档数据库(document-oriented database)
●图形数据库(graph-oriented database)
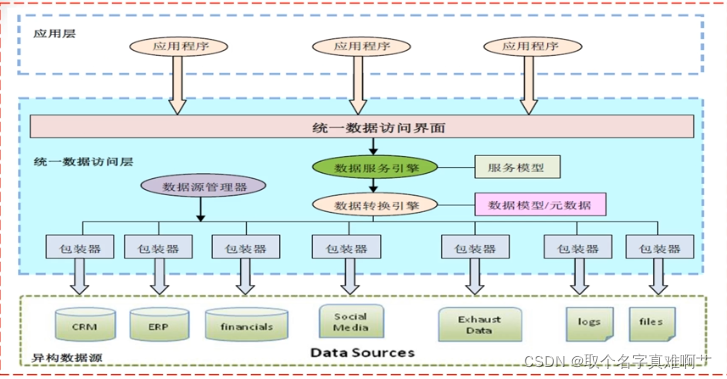
统一数据访问接口
定义:基于统一数据接口用于支持分布式环境中对跨平 台异构数据库访问的数据访问层(DAL)
功能:
➢统一的数据展示、存储和管理
➢访问接口与实现代码分离的原则,底层数据库连接的更改不影响统一数据访问接口.
➢屏蔽了数据源的差异和数据库操作细节,使得应用层专注于数据应用
➢提供一个统一的访问界面和一种统一的查询语言
传统的数据库接口软件
1.ODBC接口(c/c++)
定义:是一组数据库访问API (应用程序编程接口),由一组函数调用组成,核心是SQL语句
特性:
- 用户直接将SQL语句传送给ODBC
- ODBC对数据库的操作不依赖任何DBMS,不直接与DBMS打交道,所有的数据库操作由对应的ODBC驱动程序完成
2.JDBC接口(Java)
定义:是一个面向对象的数据库的接口规范,定义了一个支持标准SQL查询的通用程序编程接口(API)
特性:
- 由Java 语言编写的类和接口组成
- 用于支持Java应用程序对各类数据库的访问
- 支持同时建立多个数据库连接
- 可以用SQL语句同时访问多个异构数据库
- 具有对硬件平台和操作系统的跨平台支持。
统一数据读写接口DAL
定义:基于统一数据接口用于支持分布式环境中对跨平台异构数据库访问的数据访问层(DAL)
功能:
- 统一的数据展示、存储和管理
- 访问接口与实现代码分离的原则,底层数据库连接的更改不影响统一数据访问接口
- 屏蔽了数据源的差异和数据库操作细节,使得应用层专注于数据应用
- 提供一个统- -的访问界面和一种统一的查询语言
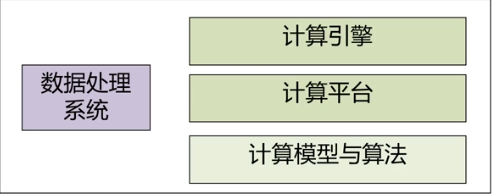
数据处理系统
包括针对不同类型数据的计算模型,如
- 针对海量数据的MapReduce批处理模型
- 针对动态数据流的流计算(Stream Computing)模型
- 针对结构化数据的大规模并发处理(MPP)模型
- 基于物理大内存的内存计算(In-memory Computing)模型;
- 针对机器学习算法的数据流图(Data Flow Graph)模型;
- 各类分析算法实现(回归分析、聚合算法、关联规则算法、决策树算法、贝叶斯分析等)
- 提供各种开发工具包和运行环境的计算平台,如Hadoop, Spark, Storm等。
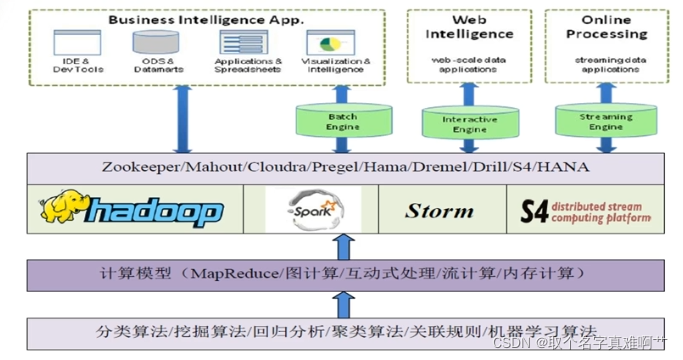
大数据计算模式
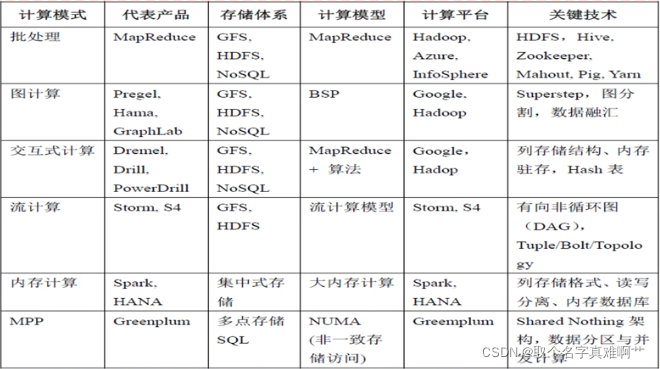

大数据计算架构
●
数据存储系统
HDFS分布式文件系统、Hadoop平台、 NoSQL数据库、列存储格式与检索
●
计算处理模型
MapReduce计算模型、Hama图并行处理框架、流计算、交互式计算模型、
TensorFlow数据流图
●
计算关键技术
智能算法、列存储结构(Columnar Storage Structure)与检索、内存驻存技术
(Memory in-site)、交互式计算、数据可视化
●
技术解决方案
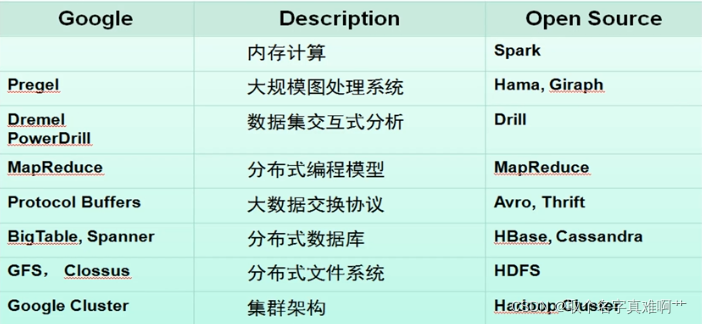
商业产品技术方案: Colossus/Spanner/Pregel/PowerDrill
开源技术解决方案: HDFS/Hbase/MapReduce/Hama/Spark/TensorFlow
两条技术主线
计算模型与计算架构
计算模型:抽象结构+计算范式+算法
计算模型针对领域问题提出技术解决方案的基础模型、数据结构及算法。
例如:
- MapReduce批处理
- 图并行计算
- 交互式处理
- 流计算
- 内存计算
- 数据流图模型(Tensorflow)
计算架构:系统架构+软件设计+实现方法
计算架构提出基于上述模型、在特定计算平台上实现的技术方案框架(系统架构、软件架构与模块、数据流与数据接口、实现原理及方法等)。
例如:
- Hadoop/HDFS/MapReduce
- 基于BSP模型的Pregel, HAMA
- Dremel/PowerDrill, Apache Drill
- Storm, Spark Stream
- Spark内存计算,MemCloud
- Tensorflow
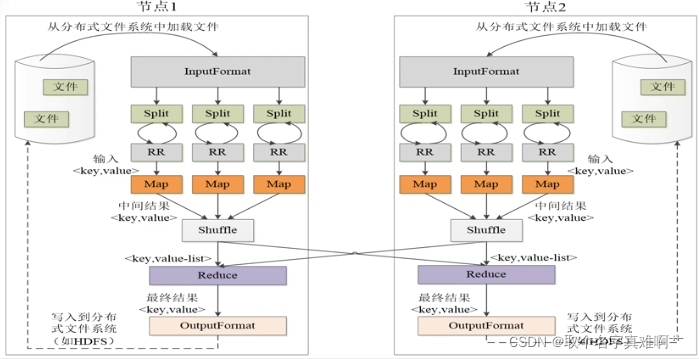
简单描述MapReduce计算模型
基本思想——分治法
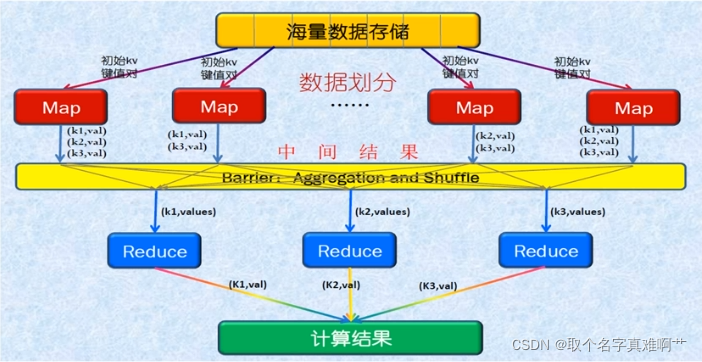
MapReduce为什么慢——不得不把计算产生的中间数据放在外部磁盘空间,而不能放在内存中
举例:
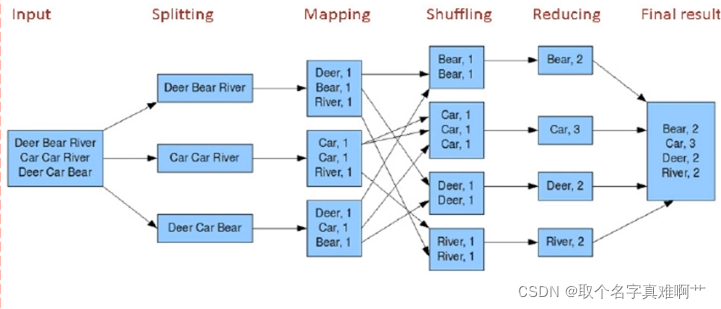
◆计算流程
Split (数据划分)
Map (映射)
Collect&Sort (聚合排序,也称Shuffle)
Reduce (简化)
Store (数据存储)
◆特点:分治策略
◆缺点:硬盘数据读取频繁,处理时效性较差
数据应用系统
基于上述计算架构和处理平台提供各行业各领域的大数据应用技术解决方案。目前,互联网、电子商务、电子政务、金融、电信、医疗卫生等行业是大数据应用最热门的领域,而制造业、教育、能源、环保、智慧交通则是大数据技术即将或已经开始拓展的行业。


















 3710
3710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











