







软件包管理器 yum
编辑器 vim
编译器 gcc
调试器 gdb
工程管理工具 make/Makefile
包管理器: yum 命令行版本的应用商店
对应的服务器叫做软件源
管理员才能安装软件
linux 下软件安装方式:
源码安装: 手动安装一个个依赖关系库 --- 极其复杂
工具安装:自动检测解决依赖关系库的安装 yum
查看能够安装那些软件包
yum list|grep package_name
查看已经安装哪些软件包
yum list installed|grep package_name
安装软件包
yum install package_name
yum install vim --- 文本编辑工具
yum install gcc ---程序编译工具
yum install gdb ---程序调试工具
yum install git ---版本控制工具
yum install lrzsz---文件传输工具
移除已安装软件包
yum remove package_name
yum 只能安装一些知名的常见软件
lrzse的使用
rz 从主机传输文件到服务器/虚拟机
sz filename 从虚拟机/服务器传输指定文件到主机
编辑器:vim
vim 史上最强大文本编译器之一
1、支持非常丰富的快捷键(操作效率高、学习成本高)
2、 支持非常强大的扩展能力(插件机制),背后依赖一个编程语言(VimL)
vim 共用12种模式,但是最常用的有三种:
普通模式:完成编辑一个文件最常见的操作 光标移动、 复制、黏贴、剪切、撤销、恢复
插入模式:插入数据
底行模式:保存、退出、 vim设置
替换模式: R 进入替换模式
可视模式: v 进入可视模式,可以进行先择
普通 —>插入:
i 从光标所在位置开始插入
I 从行首开始插入
a 从光标后的一个字符,开始插入
A 光标移动到行尾开始插入
小写0 向光标所在行下方添加新行,开始插入
大写O 向光标所在行上方添加新行,开始插入
插入 —>普通:
Esc
普通—> 底行:
:
底行—> 普通
Esc
光标移动 —普通模式下
H J K L 左下上右
w 向左移动一个单词
B 向右移动一个单词
e 下一单词末尾
ctrl+f/b 向下/上翻页
gg/G 文档首行/尾行
f [字符] 行内移动光标到指定位置 只能向后移
复制
yy 复制光标所在行
nyy 从光标所在行为止向下方复制n行
粘贴
P 向光标所在行下方黏贴新行
p 向光标所在行上方黏贴新行
剪切/删除 —普通模式
x 删除光标所在字符
X 往前删除一个字符,如果当前光标的前面没有字符,那就不删除了
nx :删除当前行的从光标开始计算,删除n个字符,不会影响其他行
dw 从当前位置开始删除到下一个单词开始
de 从当前位置删除到单词末
dd 删除光标所在行// 剪切
d$ 从当前位置删除到行末
ndd 从光标所在行开始向下删除n行
s [字符] s 删除光标字符 ,插入一个[字符];
快速交换两个字符的位置: 光标放到前一个字符上 , x p
r+(x) 用x替换光标位置类容
撤销
「u」:如果您误执行一个命令,可以马上按下「u」,回到上一个操作。
按多次“u”可以执行多次回复。
恢复
「ctrl + r」: 撤销的恢复 redo 反撤销
gg=G : 全文对齐
vim末行模式命令集
:q 退出
:q! 强制退出 (退出不保存)
:w 保存
:wq 保存并退出
:!command 临时执行command命令
/string进行字符串查找,
?string
ctrl +z 切换程序到后台
fg+ Enter 切换回刚才的程序
p 黏贴剪切板中的内容
c 修改命令 删除内容同时进入插入模式
ctrl + g 显示文件信息
% 能查找到匹配的()
:s/old/new 将old替换成new(查找替换 只进行一次)
:s/old/new/g
要替换两行之间出现的每个匹配串,请
输入 :#,#s/old/new/g 其中 #,# 代表的是替换操作的若干行中首尾两行的行号。
输入 :%s/old/new/g 则是替换整个文件中的每个匹配串。
输入 :%s/old/new/gc 会找到整个文件中的每个匹配串,并且对每个匹配串提示是否进行替换。
%s :全文替换
g :如果命令行中有g , 则代表替换
:! 这是再vim 外部执行一条指令
v 进入可视模式,选中
y 复制选中内容
p 黏贴
:set number 设置行号
:set 设置一些选项
ctrl + s :xshell 冻结当前界面
ctrl +q : 解冻
vim 批量注释代码
1、ctrl + v 进入可视列 模式
2、 拖动光标,把要注释的代码的第一列都选中
3、按I 进入插入模式
4、输入//
5、Esc
底行模式
:table [filename] 以标签页的方式来打开文件
gt 切换到下一个标签页
gT 切换到上一个标签页
:q 关闭当前标签页
:qa 关闭全部
:set mouse = a 就可以使用鼠标
:set mouse -= a 就可以关闭鼠标
编译器 gcc
将高级语言编译成为机器可执行的指令代码
编译过程:
预处理:去掉注释,展开代码
编译:语法、语法纠错、将代码解释成为汇编代码
汇编:将汇编代码解释成为机器指令代码
链接:链接代码库以及所以所有的目标文件,生成可执行代码库文件;
gcc的链接方式: 动态链接
静态链接:链接时,将库中代码写入到可执行程序中,优点:运行时,不依赖库的存在,但是占用的资源较大,并且如果大量 程序静态链接,会在内存中造成代码冗余
动态链接:链接时,只记录接口位置符号信息,并不拷贝代码;优点:占用资源少,在内存中大量程序可以共享使用(共享库),缺点:运行时依赖库的存在(运行时库)
编译 gcc test.c
-g 编译的时候保留调试信息 (debug)
-O 优化
优化级别越高,程序的实际执行顺序就和原始的执行顺序差别越大,必须要关闭优化才能进行调试
-O0 // 调试就用-O0
-O1 //默认
-O2
-O3
编译:gcc -g test.c -o test
执行: ./test
调试器 gdb
调试一个程序的前提是什么?
生成一个debug版本的程序,向程序中添加调试符号信息
linux gcc默认生成release版本程序
需要加上 -g 选项 , 生成debug版本程序
gcc -g main.c -0 main
gdb加载程序:
方式一: gdb ./main
方式二: gdb 敲回车 file ./main.c
获取运行参数,并运行程序
r -a -l -s -t
最常见的调试有哪些?
逐步调试:
start 开始单步调试
l (list) 查看调试行附近代码
l file(文件名): line(行号)
n (next) 下一步: 不进入函数
until 直接运行到指定行
until file:line
s (step) 下一步: 进入函数
打断点:
b(break) :打断点
b file:line
b 行号
b function_name 通过函数名给函数打断点
i(info):查看调试信息
i b 查看断点信息
d(delete) 删除断点
d b_id(断点编号)
disable b[断点序号]
enable b[断点序号]
watch 变量监控
watch var_name
c(continue) 继续开始运行
打印内容:
p(print) 打印变量内容
p var_name
查看函数调用栈信息 :
bt(back trace ) 快速定位程序崩溃位置
frame/f[栈帧标号] : 切换到某个指定栈帧 ---
在代码调试过程中,在当前栈帧下只能查看当前栈帧的内容,如果想查看别的栈帧的变量或内容, 就要使用到frame , 实际当前栈帧不变
工程管理工具 make/Makefile
工程管理工具 :
解决大型项目中的模块之间的依赖问题
[target] : [dependent]
[command]
test:test.c
gcc -g test.c -o test
如果test.c没变化,就不需要重写生成test
如果test.c变化,需要重写生成test
如何判断是否发生变化?
通过对比[target] 和 [dependent]的最后一次修改时间
增量编译 <===> 全量编译
[target] : 目标 --- 生成内容
[dependent]:依赖---通过什么生成
[command]: 命令 --- 怎么生成
test:test.c
gcc -g test.c -o test
make 命令的执行过程
1、现在当前目标中查找 Makefile/makefile文件
2、找到要生成的目标
3、检查依赖的文件是否都存在
4、执行生成动作的命令
vim 打开文件的同时会创建一个swap文件。异常退出swap存在,
一个Makefile 中可以存在多个目标,
有的目标并不是为了要生成个文件
而仅仅是为了执行一些特定的动作
最典型的就是 clean 方式(清空之前生成的目标)
make 指令后可以带上参数(要去生成的目标)
如果 Makefile 中包含了多个目标 直接敲 make 默认生成第一个目标
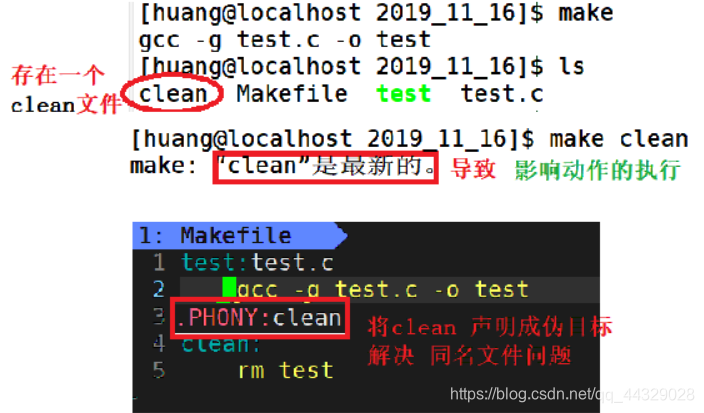
clean 这样的目标,只是为了执行一个动作,而不是为了生成一个文件,
如果此时在目录中,碰巧已有一个叫 clean 的文件,就会影响到 动作的执行
就可以使用 .PHONY 把 clean 申明成一个"伪目标"
在多文件编译时
app:main.c add.c sum.c mul.c
gcc main.c add.c sum.c mul.c -o app
此时若修改其中一个文件,重新make 其他的文件也都会被重新编译一遍
若存在大量文件时,极其影响效率
解决方法,在修改一个文件时,只需要重新编译对应的文件即可
app:main.o add.o sum.o mul.o
gcc main.o add.o sum.o mul.o -o app
main.o:main.c
gcc -c main.c
add.o:add.c
gcc -c main.c
sum.o:sum.c
gcc -c add.c
mul.o:mul.c
gcc -c mul.c
从下往上执行命令,最终生成终极目标
此时就可以每一个文件分开进行编译
Makefile的工作原理:
通过内部更新机制,文件修改了,对比时间 , 就会被重新编译
app:main.o add.o sum.o mul.o
gcc main.o add.o sum.o mul.o -o app
main.o:main.c
gcc -c main.c
add.o:add.c
gcc -c main.c
sum.o:sum.c
gcc -c add.c
mul.o:mul.c
gcc -c mul.c
该Makefile尽管可以分开编译,但是却存在大量的冗余
如何修改可以避免呢?
定义变量 --- Makefile中的变量是不需要定义类型的
obj = main.o add.o sum.o mul.o // 将其赋值给 obj变量
target = app
$(target):$(obj) //$ 打印路径对应的内容 , &(变量名) 取变量对应的值
gcc $(obj) -o $(target)
%.o:%.c // % 模式匹配
gcc -c $^ -o $@ // %^ 目标 $@ 所有依赖
%.o:%.c --->会根据终极目标的依赖模式匹配,生成对应的 目标:依赖
1、main.o:main.c
2、add.o:add.c
3、sum.o:sum.c
4、mul.o:mul.c
终极方案 函数
Makefile 提供函数,并且所有的函数都有返回值
wildcard 文件路径/文件名 获取该目录下所有该文件返回
patsubst 文件路径/文件类型1,文件路径/文件类型2, 文件类型1源 替换
target=app
src=$(wildcard ./*.c) //获取当前目录下所有.c文件并返回,通过$取函数返回的内容,并赋值给src
obj=$(patsubst ./%.c, ./%.o, $(src)) // 或取src中.c文件,并把.c替换成.o
$(target):$(obj)
$(CC) $(obj) -o $(target)
%.o:%.c
$(CC) -c $^ -o $@
命令前面加上 - 则表示,若该命令执行失败,则继续往下执行
自动化生成工具:
CMake :开源世界中广泛使用的构建工具
Blaze(火焰刀) :比较重量级的构建工具
缓冲区buffer:
1、 缓冲区去如果满了,就会正真写入到 显示器上
2、 如果遇到 \n 也会到显示器上。如果是把数据写到文件中,此时\n就不能刷新缓冲区
3、 程序结束时也可能回刷新
fflush(stdout);// 刷新缓冲区
sleep(1); // 秒
usleep(500 * 1000)//微秒 -- 500毫秒 0.5秒


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









