






 本文介绍了如何在Android中使用Jsoup库抓取网页内容,包括添加依赖、建立网络连接、解析HTML以及遇到的问题。作者通过分析网页结构,创建数据模型,并展示了使用RxJava进行线程切换以避免UI阻塞。在实践中遇到了网络请求、数据解析、布局问题,通过不断调试和学习,逐步解决了这些问题,但还存在一些未解决的挑战,如反扒机制和数据拼接。
本文介绍了如何在Android中使用Jsoup库抓取网页内容,包括添加依赖、建立网络连接、解析HTML以及遇到的问题。作者通过分析网页结构,创建数据模型,并展示了使用RxJava进行线程切换以避免UI阻塞。在实践中遇到了网络请求、数据解析、布局问题,通过不断调试和学习,逐步解决了这些问题,但还存在一些未解决的挑战,如反扒机制和数据拼接。
https://blog.youkuaiyun.com/qq_21154101/article/details/100068269
https://www.cnblogs.com/scetopcsa/p/4161214.html
https://www.open-open.com/jsoup/attributes-text-html.htm
程序需要联网 记得在AndroidMainFest中加入联网许可:
<uses-permission android:name="android.permission.INTERNET"></uses-permission>得将Jsoup包放入
libs中
地址http://jsoup.org/download
然后记得add as library
这样就不需要在build.gradle中的dependencies手动导入Jsoup,
程序会自动加入
implementation files(‘libs/jsoup-1.13.1.jar’)
还要在程序的build.gradle中的dependencies导入Jsoup
implementation 'org.jsoup:jsoup:1.12.1'不能把网络请求放在UI线程中,应该把网络请求等耗时操作放在非UI线程。所以jsoup和网络的连接不能放在UI线程中,为了让问题更加简单,我们可以导入RxJava和RxAndroid,实现线程切换。
implementation "io.reactivex.rxjava2:rxjava:2.2.8"
implementation 'io.reactivex.rxjava2:rxandroid:2.1.1'因为我们需要加载图片,还需要导入Glide:
implementation 'com.github.bumptech.glide:glide:4.9.0'
annotationProcessor 'com.github.bumptech.glide:compiler:4.9.0'因为还需要实现列表的RecyclerView,所以需要导入design库:
implementation 'com.android.support:design:28.0.0'改动之后,要点上方sync now(立即同步)

记住在程序中导入相应的包!
第一步:建立连接
Document doc=null;
String url="https://open.163.com/special/ted10collection/";
try{
doc=Jsoup.connect(url).get();}catch (IOException e){
e.printStackTrace();
}第二步:分析Html

点击检查,发现网页已经自动标出头部和尾部了,内容在<div class="g-doc">中,

点卡发现里面有很多div,里面的class和id都是一样的,猜测这是封面和每一组的内容合集。
这里有不同主题的演讲,和一系列的图片
检查一下大图片和小图片


再点一个

发现大图片都是在“log f-fl”的class中,小图片都是在class为“f-cb”的ul中,对应的li中,每个li的class为“lik10 show”,li中的title和img都是我们要获取的。
同时我们还需要获取小图片对应的小标题。

检查,

发现标题都在class为“m-list f-cb”的div中,每个标题对应class为“f-fl”的ul中的一个li。我们需要获取class为“f-fl cou f-thide”的p标签。
第三步:建立Model类
我们需要每一个视频的标题,主讲人,图片和播放地址。
public class TED {
private String title;
private String img;
private String content;
private String href;
public String getHref() {
return href;
}
public void setHref(String href) {
this.href = href;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getImg() {
return img;
}
public void setImg(String img) {
this.img = img;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}
第四部:解析html
一开始解析时是直接用url连接的,但是怎么样都解析不了,
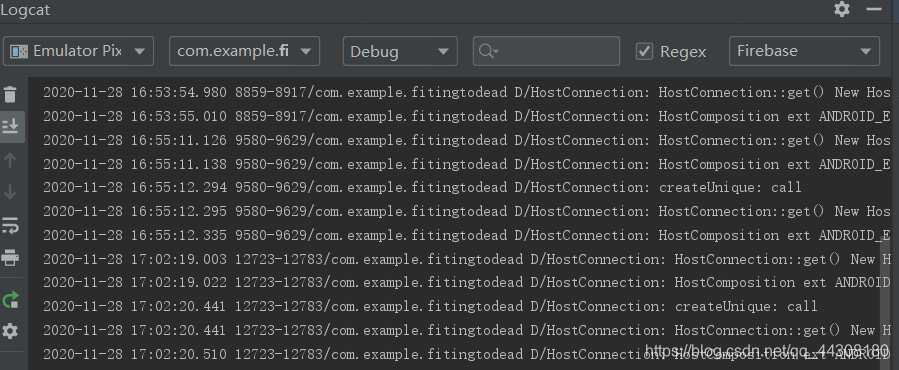
我只找到了这个,猜测是提取的表达式的问题,于是我把网页的相应源代码直接放到Eclipse中,使用Jsoup解析,最终可以提取到相应代码了,但是代码还是有些问题。
然后我把代码移植到AndroidStudio中运行,依旧不行啊,还是显示如上的报错。
我就崩溃了,然后又想起这个星期软件工程老师讲的一种调试方法——直接把确定的值输入,而不是靠循环中的取值,果然让我找到错误了——ClassNotFoundException:android.support.constraint.ConstraintLayout,
然后我又去改了,卧槽,design中出现布局了,长记性了,如果design中看到的是黑框,
或者显示不正常,那么这个布局就是有问题的。
因为我是参考一位爬取简书前辈的代码,而他的代码又有一定时间了,这段时间Android迁移到AndroidX中了,所以显示要到AndroidX版本的包都得去找相应的X版本。
而上面的布局也是这个原因,之前的错也差不多都是这个原因。
这下终于找到原因了,但是还是有问题的:
1.无法做到解析url,而只能通过部分本地源代码解析。感觉可能是因为源代码太长了,或者是因为网站有反扒机制,这点我们暂且放一放。
2.我们需要爬取的有网站连接,人物姓名等等,网站的资源是一排一排的,而我的代码奇数行的内容是完整的,而偶数行的时候图片和姓名,竟然没有?
但是用recycview的话,是每次传过去一个对象,如果有空值的话,会显示
RecyclerView: No adapter attached; skipping layout
ted.setImg(pic);
ted.setContent(href);
ted.setName(name);
ted.setTitle(title);
if (title =="" || name=="" || pic=="" || href==""){
continue;}
tedList.add(ted);
emitter.onNext(tedList);所以我想到如果是空值,直接跳过,机智如我。
3.我想按照资源的数量进行循环,但是如果
Elements input = document.getElementsByClass(“m-ttopic f-cb”).select(“li”);
for (int i = 0; i<input.size; i++) {
竟然没有屏幕又没有显示了,
但是我输出的
System.out.println(input.size());
System.out.println(input1.size());
在控制台
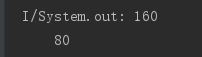
哦,怪不得有的地方没有数据呢,数据可能被分成了不同的class,所以一个class只能爬取一半,可是如果我再爬另一半怎么拼接呢?所以这个问题也跳过吧。
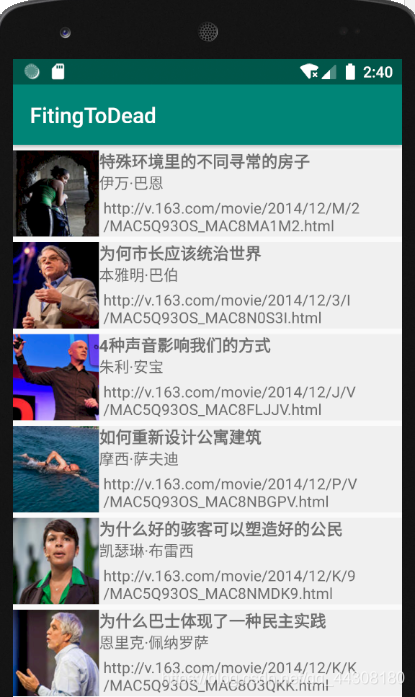
手动输入i的值(i=80),可以运行。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









