







一、裁剪任务概述
数据描述 :
- 提供全国基础地理数据 23 个图层
处理要求 :
- 分别提取每一个省份的所有图层,并将同一个省份的所有数据放在同一数据集合中
- 分别提取所有省份的每个地级市图层,并将同一个地级市的所有数据放在同一集合中
处理思路:
- 利用模型构建器实现批量裁剪
- 利用Python脚本实现批量裁剪
数据准备:
- 将数据源数据存放于文件地理数据库中的要数数据集中,这样就可以批量的打开数据,方便进行数据的管理与处理
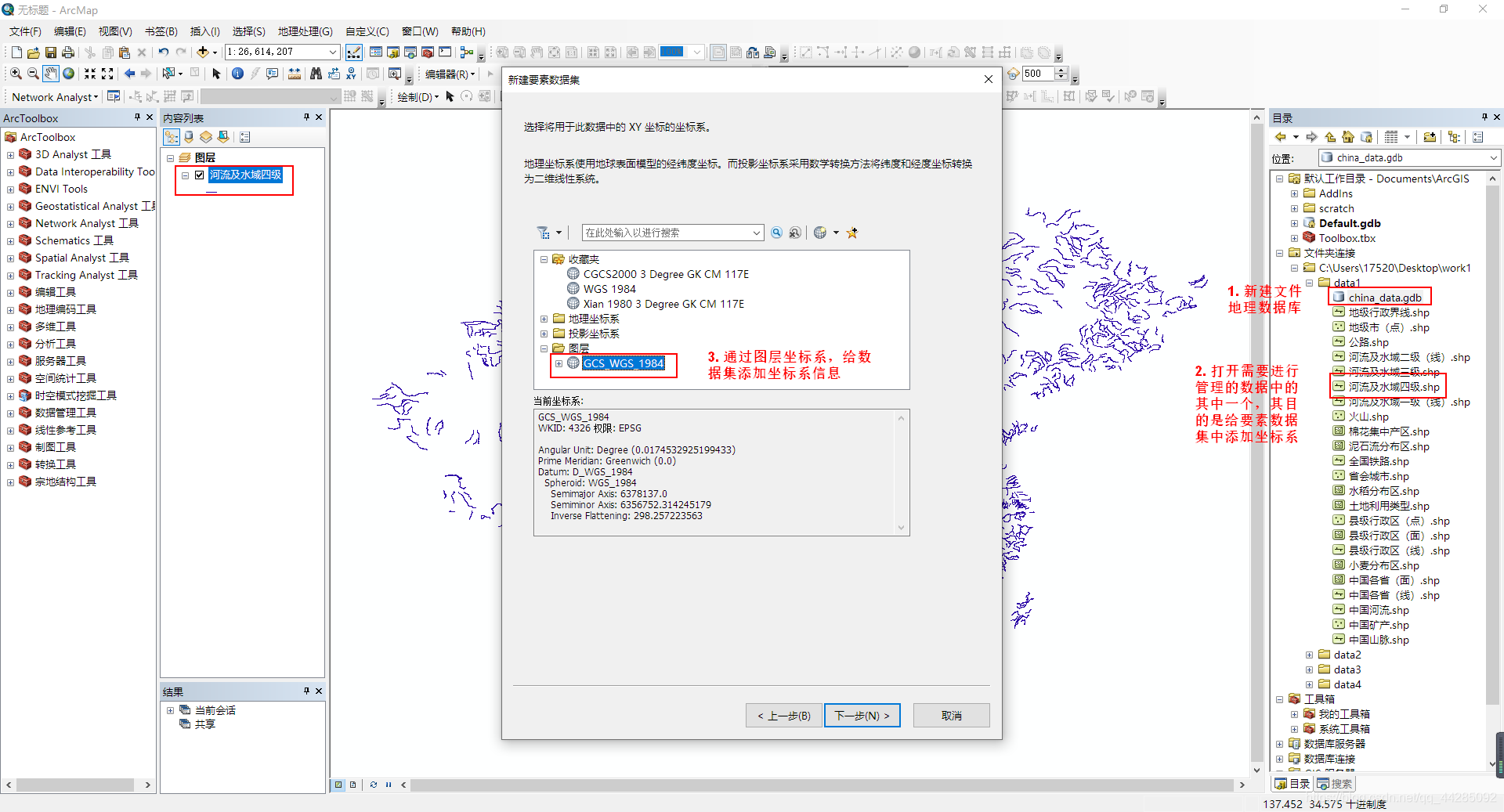
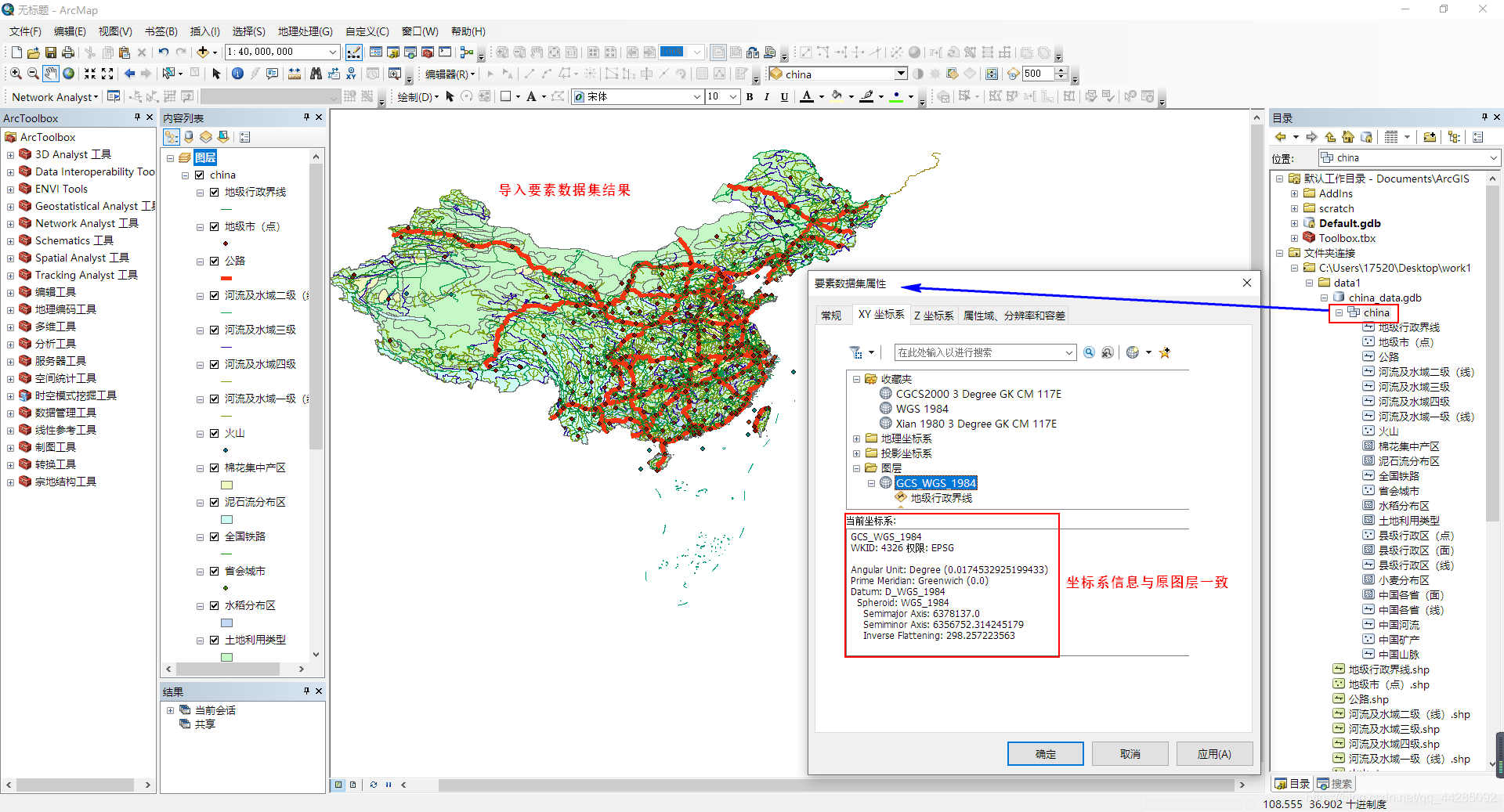
二、利用GIS自带裁剪工具进行裁剪
2.1 单个数据的裁剪
1 通过属性选择选取作为裁剪的依据,即按什么裁剪


2 利用cq这个图层裁剪公路图层

3 裁剪结果

2.2 多个数据的批量裁剪
1 批量裁剪工具位置

2 利用cq这个图层同时去裁剪公路、河流和水稻分布区

3 裁剪结果

2.3 小结
可以看到如果数据量比较小,用此方法来进行裁剪更为方便。如果数据量很多,需要不断的重复进行裁剪工作, 利用此方法则就行不通了,因此我们需要借助于ArcMap里面的模型构建器或者Python来实现多数据,进行繁杂的裁剪工作。
三、利用模型构建器实现裁剪
3.1 单个省数据裁剪(以重庆为例)
1 构建裁剪的模型构建器

2 裁剪结果

3.2 各省数据的裁剪
裁剪思路
- 提取各个省市的面要素作为裁剪要素
- 在将全国的所有图层数据进行裁剪
- 由于需要迭代提取两次,第一次是通过用迭代器中的要素选择来获取裁剪要素;第二次则是通过迭代器中的要素类来获取数据库中的各个图层数据作为裁剪输入要素。由于一个模型构建器中只能出现一次迭代,因此我们需要另想办法,通过新建一个模型,然后将整个模式作为一个工具拖入至主模型中即可。
迭代器中的要素类与要素选择的区别
- 迭代器中要素类指的是数据库中有多个要素图层,将各个要素图层进行迭代;迭代器中要素选择则是从同一图层中提取每一个要素进行迭代
3.2.1 具体步骤
1 根据每个省市的名称创建文件地理数据库






2 创建裁剪输入要素(新建一个模型)




3 创建裁剪要素并连接输入要数的模型(前面创建文件地理数据库已经获取到了裁剪要素,因此直接连接模型设为裁剪要素即可)

4 运行模型与结果


四、利用Python进行裁剪
4.1 单个省数据裁剪(以重庆为例)
以公路这一个图层裁剪作为示例
import arcpy
arcpy.Clip_analysis('公路',"cq","cq_road")

通过一个列表或者元组等,将各个图层的名称存下来,然后通过for循环实现重庆市各图层数据的裁剪
import arcpy
import arcpy.mapping as mp
mxd = mp.MapDocument("CURRENT")
lyrs = mp.ListLayers(mxd)
for lyr in lyrs:
裁剪输入要素的图层名 = lyr.name
arcpy.Clip_analysis(裁剪输入要素的图层名,裁剪要素名,保存的名)


4.2 各省数据的裁剪
1 批量导出所需要进行裁剪要素的各省市数据
import arcpy
input_shp = 输入的shp文件,即需要进行批量导出的文件
arcpy.env.overwriteoutput = True # 如果写入环境中已存在则覆盖该文件
# 以"NAME"字段进行分割,实现同一"NAME"字段得到数据批量导出
arcpy.Split_analysis(input_shp,input_shp,"NAME",保存的位置)


2 分别对第1布的结果与中国的所有图层数据都保存为地图文档文件,即.mxd文件

3 实现全国各省市数据的裁剪
import arcpy
import arcpy.mapping as mp
mxd_china = mp.MapDocument(r'C:\Users\17520\Desktop\work1\data1\china.mxd')
mxd_china_split = mp.MapDocument(r'C:\Users\17520\Desktop\work1\data1\china_split.mxd')
# 创建文件夹
arcpy.CreateFolder_management(r'C:\Users\17520\Desktop\work1\data1',"Python_gdb")
# 获取地图文档中图层信息
lyrs_mxd_china = mp.ListLayers(mxd_china)
lyrs_mxd_china_split = mp.ListLayers(mxd_china_split)
# 按照省市名创建文件地理数据库
for i in lyrs_mxd_china_split:
arcpy.CreateFileGDB_management(r'C:\Users\17520\Desktop\work1\data1\Python_gdb',i.name)
# 裁剪
for i in lyrs_mxd_china_split:
for j in lyrs_mxd_china:
# 设置保存的文件数据库位置
arcpy.env.workspace = 'C:\\Users\\17520\\Desktop\\work1\\data1\\Python_gdb\\' + i.name + '.gdb'
in_features = 'C:\\Users\\17520\\Desktop\\work1\\data1\\china_data.gdb\\china\\' + j.name
clip_features = 'C:\\Users\\17520\\Desktop\\work1\\data1\\CCC.gdb\\' + i.name
# 裁剪
arcpy.Clip_analysis(in_features,clip_features,i.name + "_" + j.name)



导出时间比较久,这里总结下思路,首先通过将各个数据先分别保存为地图文档,然后在通过地图文档得到每个图层的名称(我想这里直接从文件数据库中获取到要素信息也是可行的,目前我还不清楚怎么直接从数据库中提取各图层名称,这里也希望各位大佬能告知一下,感激不尽);然后就是通过两次for循环将裁剪任务完成的,第一次for循环是裁剪要素,第二次for循环是裁剪输入要素;接着就是通过根据裁剪要素来动态的选取保存的数据库,以此作为新的工作空间;最后就是裁剪啦。
太慢啦~等着难受,就该少用一点数据的。有没有什么能够加速运行的,指点一下。从8:32一直运行到9:14,太慢啦。。。不过结果是正确的,还算不错,哈哈哈
五、总结
用模型构建器和Python脚本来实现批量裁剪,数据量大时花费时间都比较久。总体而言,模型构建器逻辑比较清晰,实现起来也更加容易;Python脚本需要有一定的基础,编程时需要思路清晰,多大胆的尝试,但是熟练后比模型构建起用起来更快,适用范围更广。


















 1667
1667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











