






一、空间与地址分配
链接器在连接过程中的工作就是把多个输入的目标文件加工合并成一个输出文件。有几种不同的方案:
按序叠加
按序叠加可以说是最简单的一个方案,就是将输入的目标文件按照次序叠加起来。
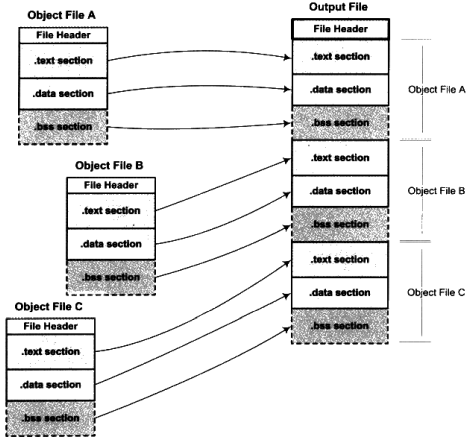
从图中可以看到,在有很多输入文件的情况下,输出文件将有很多零散的段。因为每个段都要遵循空间对齐,所以这样会占用大量空间。比如,一个段长度只有1字节,但是按照空间对齐,其在内存也要占用4096个字节。
相似段合并
为了解决按需叠加所带来的问题,引入了相似段合并这个概念,就是把相同性质的段合并到一起。.bss段其实在目标文件和可执行文件中并不占用文件的空间(不占用磁盘空间),但是在装载时是要占用地址空间的。
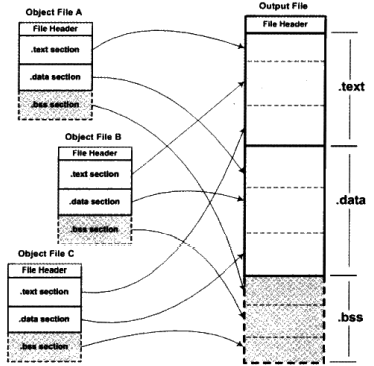
很多书中提到的“链接器为目标文件分配地址和空间”,这一句话其实是有两个含义的。对于.text和.data这样有实际数据的段,链接器在文件中和虚拟地址中都要分配空间。但是对于.bss这样的段,在文件中就不必分配空间,目的是节约磁盘空间。
目前的链接器都不采用按序叠加的方法,而是采用相似段合并的方法。
链接器采用的是相似段合并的方法,使用这种方法的链接器一般都采用两步链接的方法。
第一步 空间与地址分配:链接器获取所有目标文件的段长度,将他们合并,计算出输出文件中各个段合并后的长度与位置,建立映射关系。
第二步 符号解析与重定位:使用上一步所收集到的信息,读取输入文件中段的数据、重定位信息、进行符号解析和重定位、调解代码中的地址。
链接器前后的程序所用的地址其实已经是程序应该在进程中使用的虚拟地址。Linux下一般从0x08048000开始分配。地址确定很简单,基址地址(0x08048000)+偏移地址(符号在进程中的地址)。
二、符号
链接的本质就是把多个不同的目标文件之间相互“粘”到一起,就像是拼图一样,把每一块“目标文件”拼接成一个完整的“程序”。
在链接中,目标文件之间相互拼合实际上就是目标文件之间地址的引用,即对函数和变量的地址的引用。将函数和变量统称为符号,函数名或变量名就是符号名。
符号的类型
定义在本目标文件的全局符号:可被其他目标文件引用
外部符号:在本目标文件中引用的全局符号
段名:由编译器产生,值为该段的起始地址。
局部符号:只在编译单元内部可见,其他目标文件不可见
特殊符号
在linux下使用ld作为链接器来链接可执行文件时,定义很多符号可以引用。这些符号称为特殊符号。以下是几个很具有代表性的特殊符号:
__executable_strat:代码段的起始地址
__etext或_etext或etext:代码段的结束地址
_edata或edata:数据段的结束地址
_end或end:程序的结束
ELF符号表结构
typedef struct
{
Elf32_Word st_name;
Elf32_Addr st_value;
Elf32_Word st_size;
unsigned char st_info;
unsigned char st_other;
Elf32_Half st_shndx;
}Elf32_Sym
符号修饰与函数签名
为了避免和库文件中的符号发生符号冲突,就出现了符号修饰机制。
UNIX下的C语言规定,C语言中的符号经过编译后需要在在符号名前加上下划线“_“。
int func()
{
...
}
以上函数名被修饰成 “_func”。
在C++中则增加了名称空间 namespace
C++中的符号修饰
因为C++支持重载的特征,所以函数符号修饰相对复杂,引入术语函数签名来表示C++中函数的符号修饰。函数签名包含了一个函数的信息,包括函数名、参数类型、所在类、以及名称空间。
linux下函数签名的规则:所有符号都以_Z开头,在名称空间或类中后面紧跟N,再以E结尾。比如一个名称空间foo中的全局变量bar就会被修饰为_ZN3foo3barE。
C++解决与C的兼容问题——extern
C和C++中的符号修饰是不同的,所以就存在不兼容问题,为了解决这个兼容问题,C++中有个用来声明或定义一个C符号的extern “C” 关键字用法。以下是一个示例:
extern “C”只能定义在全局范围,不能定义在函数内
extern "C"
{
int func(int);
int var;
}
同时C++编译器会在编译C++文件时默认定义一个宏**“__cplusplus”**,来使得能够兼容C语言的头文件,这也是能在C++中使用#include<stdio.h>的原因。
强符号和弱符号
在编程中会出现多个目标文件中含有相同名字全局符号的定义,这种情况就叫符号重复定义。为了解决这个问题,引入了强符号和弱符号规则。在C/C++语言中,编译器默认函数和初始化了的全局变量为强符号,未初始化的全局变量为弱符号。以下是发生符号重复定义的处理规则:
强符号与强符号之间:编译器报错
强符号与弱符号之间:编译器选择强符号
弱符号与弱符号之间:编译器选择其中占用空间最大的一个
强引用和弱引用
在编译器对引用的外部符号进行决议时,如果没有找到该符号定义,编译器就会报符号未定义错误的称之为强引用,如果没有找到该符号定义,编译器就默认其为0的称之为弱引用。
库中定义的弱符号可以被用户定义的强符号所覆盖,使得用户可以让程序使用自定义版本的库函数。
三、符号解析与重定位
重定位
#include "func.c"
int main()
{
func();
}在这段代码中的函数func()定义在其他文件中,所以编译器就暂时把地址0看做是“func()”的地址。等到链接器在完成地址和空间分配之后就可以确定所有符号的虚拟地址(包括func),那么链接器就可以根据重定位表对每个需要重定位的符号进行地址修正。
符号解析
链接是因为在目标文件中用到的符号被定义在其他目标文件。这也是编译过程中出现“undefined symbol”这类编译错误的原因。
重定位的过程往往也伴随着符号的解析过程,每个重定位的入口都是对一个符号的引用,那么当链接器需要对某个符号的引用进行重定位时,它就要确定这个符号的目标地址,这时候链接器就会去查找由所输入目标文件的符号表组成的全局符号表,找到相应的符号进行重定位。

















 625
625

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









