







 本文深入讲解了XML的基础概念、用途、元素、属性、实体、注释、CSS修饰、命名空间和约束,以及Java中DOM、SAX解析和DOM4J的应用,助你理解并高效利用XML进行数据交换和配置管理。
本文深入讲解了XML的基础概念、用途、元素、属性、实体、注释、CSS修饰、命名空间和约束,以及Java中DOM、SAX解析和DOM4J的应用,助你理解并高效利用XML进行数据交换和配置管理。
金丹之境---XML的修行
1. 是什么?
w3c组织想要替代html的一款可拓展标记语言
区别:
XML 主要是用来描述数据的
HTML 主要是用来展现数据的
拓展:用户自定义的标签
标记:标签
1.1 有什么用?
- XML可以作为数据传输的标准(重要)
- XML可以作为配置文件(重要)
- XML可以持久化数据
- XML 简化平台变更
2 怎么使用
掌握这五种基本:文档声明、元素、属性、实体、注释
2.1 文档声明
<?xml version="1.0" encoding="utf-8"?>
用于描述版本信息,以及编码方式,放在xml文件第一行,可写可不写
2.2 元素
元素,指的就是XML中的标记,这种标记也被称为标签、节点。
命名规则:
- 可以包含字母、数字以及其它一些可见字符
- 不能以数字或标点符号开头
- 不能包含空格
- 不可以以xml字符开始
使用规则:
- XML 必须包含根元素
- 元素是可以包含标签体的
- XML标签允许 嵌套 但是不允许 交叉
2.3 属性
XML属性(Attribute)提供了元素相关的一些额外信息
<?xml version="1.0" encoding="utf-8"?>
<root>
<person sex="female" age='18' email='briup@briup.com'></person>
</root>
2.4 实体
在 XML 中,一些字符拥有特殊的意义,在XML文档中,是不能直接使用的。
例如,如果把字符 “<” 放在 XML 元素中,会发生错误,这是因为解析器会把它当作新元素的开始。
XML中实体的格式: &实体名;
<?xml version="1.0" encoding="utf-8"?>
<message>if salary < 1000 then</message>
预定义实体: 任何用到这些字符的地方,都可以使用实体来代替
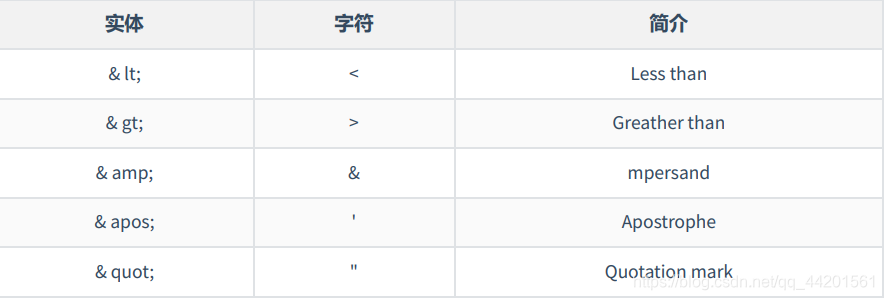
自定义实体:
格式:
<!DOCTYPE 根元素名称[
<!ENTITY 实体名 实体内容>
]>
举个栗子:
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE root[
<!ENTITY company "二橘学java">
]>
<root>
<name>&company;</name>
</root>
2.5 与实体作用相识
在一些情况下,我们在xml中编写的特殊内容,例如特殊字符、代码等,并不希望解析器去解析,而是希望把这些内容按字符串原样输出即可,不需要做额外任何解析处理。
<?xml version="1.0" encoding="utf-8"?>
<root>
<tag>
<name>&</name>
<entity>&</entity>
</tag>
</root>
我们希望以上代码输出:&而不需要转译
在xml中:
解析器进行解析的内容,称为PCDATA(Parsed CDATA)
解析器不会解析的内容,称为CDATA,(Character Data)
CDATA区域的格式要求:
<![CDATA[需要原样输出的字符串]]>
示例
<?xml version="1.0" encoding="utf-8"?>
<root>
<tag>
<name>&</name>
<entity><![CDATA[&]]></entity>
</tag>
</root>
2.6 注释
注意点:
注释内容中不要出现 –
不要把注释放在标签中间
注释不能嵌套
3.CSS修饰xml
使用处理指令,简称PI (processing instruction),可以用来指定解析器如何解析XML文档内容。
例如,在XML文档中可以使用xml-stylesheet指令,通知XML解析引擎,使用test.css文件来渲染xml内容。
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet href="test.css" type="text/css"?>
<class>
<student id="001">
<name>张三</name>
<age>20</age>
</student>
<student id="002">
<name>李四</name>
<age>20</age>
</student>
</class>
4.命名空间:让这个自定义的标签具有唯一性
即包结构:三种方式
- 前缀的方式:
<y:table> - 声明这个前缀是属于哪个命名空间 :
<x:table xmlns:x="http://www.erju.com/y/"> - 不要前缀,直接定义默认的命名空间 :
<table xmlns="http://www.briup.com/XML/ns">
5. XML约束:
让用户按照要求去编写XML文件内容,并不能真的让他自己随意的自定义标签。
俩种约束:
可以使用dtd文件或者Schema文件对XML文件内容作出约束,dtd文件和schema文件中,只是语法不同,但是最终的效果都是一样的。
良构和有效:
一个XML文件,如果里面的内容,满足XML的基本语法要求,那么这个XML文件就可以说是良构的。
在XML文件是良构的基础上,如果这个XML文件还通过dtd文件或者Schema文件的约束验证,那么这个XML文件就可以说是有效的。总结如下:
良构的XML文件不一定是有效的
有效的XML文件一定是良构的
5.1 DTD
对于元素的约束:
<!ELEMENT 元素名 (内容模式)>
-
EMPTY:元素不能包含子元素和文本(空元素)
-
(#PCDATA):可以包含任何字符数据,但是不能在其中包含任何子元素
-
ANY:元素内容为任意的,主要是使用在元素内容不确定的情况下
-
修饰符:() | + * ? ,
-
() 用来给元素分用组 | 在列出的元素中选择一个
-
+表示该元素最少出现一次,可以出现多次 (1或n次)
-
*表示该元素允许出现零次到任意多次(0到n次)
-
?表示该元素可以出现,但只能出现一次 (0到1次)
-
,对象必须按指定的顺序出现
-
对于属性的约束:
<!ATTLIST 元素名称
属性名称 属性类型 属性特点
属性名称 属性类型 属性特点
>
属性类型:
-
CDATA:属性值可以是任何字符(包括数字和中文)
-
ID:属性值必须唯一,属性值必须满足xml命名规则
-
IDREF:属性的值指向文档中其它地方声明的ID类型的值。
-
IDREFS:同IDREF,但是可以具有由空格分开的多个引用。
-
enumerated:(枚举值1|枚举值2|枚举值3…),属性值必须在枚举值中
属性特点:
-
#REQUIRED:元素的所有示例都必须有该属性
-
#IMPLIED :属性可以不出现
-
default-value:属性可以不出现,但是会有默认值
-
#FIXED :属性可以不出现,但是如果出现的话必须是指定的属性值
如何在xml中生效:
-
内部的DTD,DTD和xml文档在同一个文件中。(不常用)
<?xml version="1.0" encoding="UTF-8"?> <!-- 内部DTD --> <!DOCTYPE students[ <!ELEMENT students (stu)> <!ELEMENT stu (id,name,age)> <!ELEMENT id (#PCDATA)> <!ELEMENT name (#PCDATA)> <!ELEMENT age (#PCDATA)> ]> <students> <stu> <id>1</id> <name>tom</name> <age>20</age> </stu> </students> -
外部的DTD,DTD和xml文档不在同一个文件中。(常用)
-
本地DTD文件引入,这种方式一般都是自己编写DTD,然后自己使用。
<!DOCTYPE 根元素 SYSTEM "DTD文件的路径<?xml version="1.0" encoding="UTF-8"?> <!-- 外部DTD --> <!DOCTYPE students SYSTEM "dtd/students.dtd"> <students> <stu> <id>1</id> <name>tom</name> <age>20</age> </stu> </students> -
公共DTD文件引入,这种方式可以让很多人使用共同的一个DTD文件。
<!DOCTYPE 根元素 PUBLIC "DTD名称" "DTD文档的URL"><?xml version='1.0' encoding='UTF-8'?> <!DOCTYPE hibernate-configuration PUBLIC "-//Hibernate/Hibernate Configuration DTD 3.0//EN" "http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd"> <hibernate-configuration> </hibernate-configuration>Eclipse默认会根据第一个双引号中的内容,查找对应的DTD所在位置
如果有DTD文件,那么就读取并验证,同时可以根据DTD的内容给出自动提示的信息(Alt+/)
如果没有DTD文件,那么就根据第二个双引号中的内容(URL地址),去网络中下载并读取、验证 -
对于外部公共DTD文件的因为网络不稳定需要下载下网络上的dtd包手动导入。
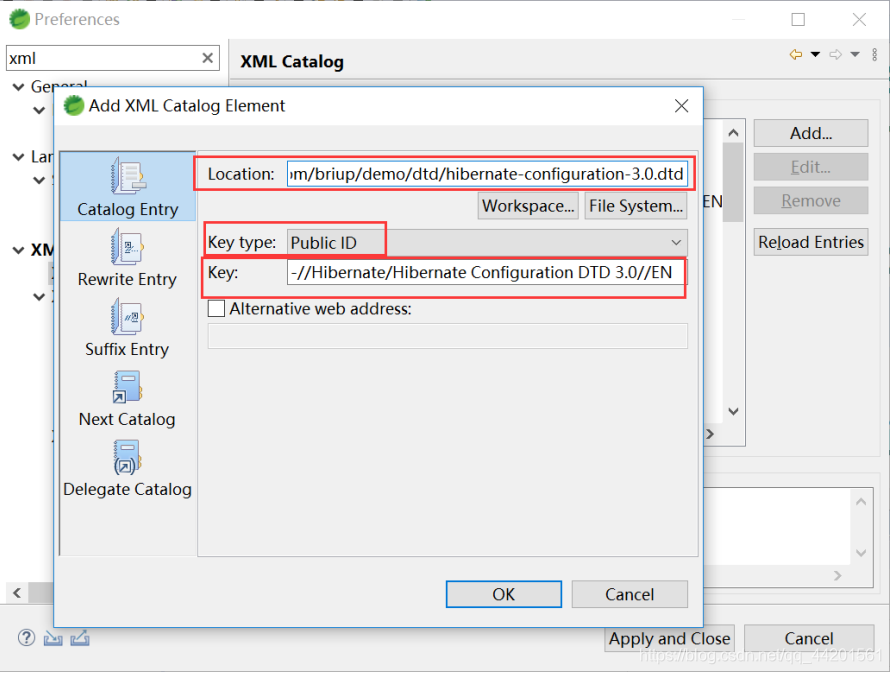
-
5.2 Schema :
Schema文件中就是正常的XML语法 ,因此我们要学的是如何导入
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans-4.3.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context-4.3.xsd">
说明,
- xmlns,指定了当前XML中,标签所属的默认命名空间地址
- xmlns:context,指定了当前XML中,context作为前缀开头的标签所属的命名空间地址
- xmlns:xsi,指定了当前XML中,所使用的schema实例的命名空间地址,xsi(XMLSchema-instance
- xsi:schemaLocation,指定了当前XML中,所使用的schema文件都有哪些,已经分别对应的URL地址
同样因为网络的问题手动导入:
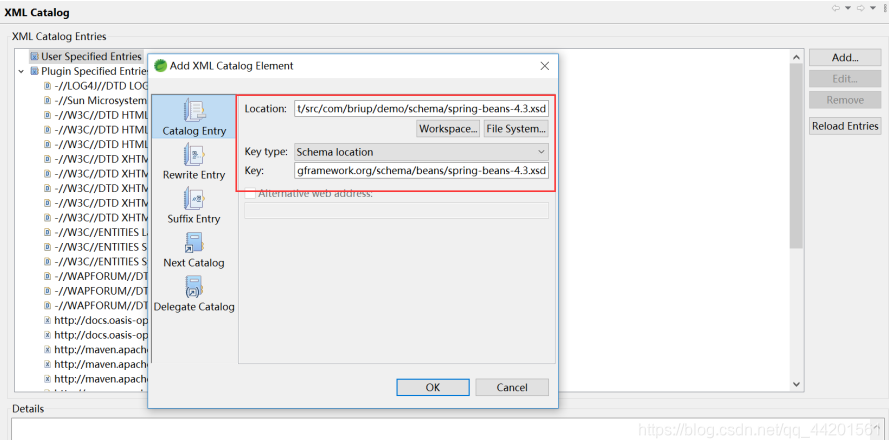
6. XML解析:将xml中的拿出来再放到xml中
方式:
- DOM解析
- SAX解析
意义:方便多平台,简化操作
注意,DOM和SAX都是解析XML文档的一种模型/标准/理论,是需要编写具体的代码去实现的,而
实现了这些解析方式的代码,被称之为XML解析器。
6.1 java自带Xerces的DOM解析:
DOM,(Document Object Model)文档对象模型,是 W3C 组织推荐的处理 XML 的一种方式。
使用DOM方式解析,要求解析器把整个XML文档装载到一个Document对象中。Document对象包含文档元素,即根元素,根元素包含N个子元素。
根据DOM的定义,XML 文档中的每个元素都是一个节点(Node):
- XML文档只有一个根节点
- XML中每个元素都是一个元素节点
- XML中每个文本都是一个文本节点
- XML中每个属性都是一个属性节点
- XML中每个注释都是一个注释节点
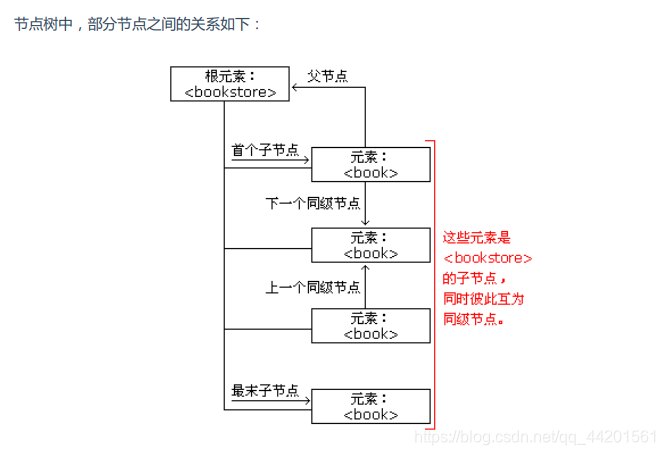
从xml中解析:
public class Test {
public static void main(String[] args) {
Test test = new Test();
String filePath = "src/com/briup/demo/class.xml";
test.domParse(filePath);
}
public void domParse(String filePath) {
// 创建DocumentBuilderFactory类的对象
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();
try {
// 通过工厂对象创建出DocumentBuilder对象
DocumentBuilder documentBuilder = builderFactory.newDocumentBuilder();
// 通过DocumentBuilder对象,解析xml文件,并且获取document
// document就是dom中的文档对象,用来表示被解析的xml文件
Document document = documentBuilder.parse(filePath);
// 获取根元素
Element root = document.getDocumentElement();
// 获取根元素下面所以的子节点(儿子节点)
NodeList childNodes = root.getChildNodes();
for (int i = 0; i < childNodes.getLength(); i++) {
// 获取当前处理的子节点
Node node = childNodes.item(i);
// 判断节点的类型,是文本节点还是元素节点
switch (node.getNodeType()) {
case Node.TEXT_NODE:
System.out.println("文本节点内容:" + node.getTextContent());
break;
case Node.ELEMENT_NODE:
System.out.println("元素节点名字: " + node.getNodeName());
// 获取当前元素节点中的所有属性
NamedNodeMap attributes = node.getAttributes();
// 循环变量拿到每一个属性
for (int j = 0; j < attributes.getLength(); j++) {
// 强制转换为Attr类型的对象,表示属性
Attr attr = (Attr) attributes.item(j);
// 可以通过方法获取到属性名和属性值
System.out.println(attr.getName() + "= " + attr.getValue());
}
// 获取当前节点下面的子节点
NodeList nodeList = node.getChildNodes();
for (int k = 0; k < nodeList.getLength(); k++) {
Node item = nodeList.item(k);
// 如果这个节点是元素节点的话
if (item.getNodeType() == Node.ELEMENT_NODE) {
// 拿出元素节点的名字和它的文本值
System.out.println(item.getNodeName() + "=" + item.getTextContent());
}
}
break;
default:
throw new RuntimeException("解析到意外的节点类型:" + node);
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
当有dtd的时候我们想要跳过dtd可以在上面的代码中添加以下代码
//通过工厂对象创建出DocumentBuilder对象
DocumentBuilder documentBuilder = builderFactory.newDocumentBuilder();
/*====其他地方不变,添加此处代码=====*/
documentBuilder.setEntityResolver((publicId, systemId) -> {
String str = "<?xml version=\"1.0\" encoding=\"UTF-8\"?>";
InputStream in = new ByteArrayInputStream(str.getBytes());
return new InputSource(in);
//本来是需要读取dtd文件所在路径的,例如下面代码
//但是我们想跳过dtd的解析,所有就重写为上面代码
//return new InputSource(systemId);
});
/*====其他地方不变,添加此处代码====*/
//通过DocumentBuilder对象,解析xml文件,并且获取document
//document就是dom中的文档对象,用来表示被解析的xml文件
Document document = documentBuilder.parse(filePath);
解析到xml文档中:
public class Test {
public static void main(String[] args) {
Test dom = new Test();
String filePath = "src/com/briup/demo/my.xml";
dom.createDocument(filePath);
}
//创建Document文档对象,并写出去成为xml
public void createDocument(String filePath) {
//创建DocumentBuilderFactory类的对象
DocumentBuilderFactory builderFactory = DocumentBuilderFactory.newInstance();
try {
//通过工厂对象创建出DocumentBuilder对象
DocumentBuilder documentBuilder = builderFactory.newDocumentBuilder();
//通过DocumentBuilder对象,创建出一个新的document对象
Document document = documentBuilder.newDocument();
//创建一个根节点
Element root = document.createElement("root");
//创建一个元素节点student
Element studentNode = document.createElement("student");
//设置这个元素节点的属性
studentNode.setAttribute("id", "2022001");
//创建一个元素节点name
Element nameNode = document.createElement("name");
//创建一个注释节点comment
Comment comment = document.createComment("这里是注释信息");
//创建name节点中的文本内容
nameNode.setTextContent("tom");
//将根节点添加到document中
document.appendChild(root);
//将注释节点添加到根节点中
root.appendChild(comment);
//将student节点添加到根节点中
root.appendChild(studentNode);
//将name节点添加到student节点中
studentNode.appendChild(nameNode);
//调用自定义的私有方法,将document对象写出为指定路径的xml文件
createXMLByDocument(document, filePath);
} catch (ParserConfigurationException e) {
e.printStackTrace();
}
}
/***
* 通过document对象创建出对应的xml文件*
*
* @param document 内存中构建好的document对象*
* @param filePath 生成xml文件的位置
*/
private void createXMLByDocument(Document document, String filePath) {
//获取TransformerFactory工厂类对象
TransformerFactory transformerFactory = TransformerFactory.newInstance();
try {
//通过工厂类对象,获得转换器对象
//负责把document对象转换为xml文件
Transformer transformer = transformerFactory.newTransformer();
//设置xml中的编码
transformer.setOutputProperty(OutputKeys.ENCODING, "UTF-8");
//设置xml中的内容换行,否则全部写到一行中
transformer.setOutputProperty(OutputKeys.INDENT, "yes");
//把document对象转为xml文件
transformer.transform(new DOMSource(document), new StreamResult(filePath));
} catch (Exception e) {
e.printStackTrace();
}
}
}
6.2 java自带解析SAX
SAX,(Simple API for XML)它不是W3C标准,但它是 XML 社区事实上的标准,因为使用率也比较高,
几乎所有的 XML 解析器都支持它。
使用SAX方式解析,每当读取一个开始标签、结束标签或者文本内容的时候,都会调用我们重写的一个指
定方法,该方法中编写当前需要完成的解析操作。直到XML文档读取结束,在整个过程中,SAX解析方法不会在内存中保存节点的信息和关系。
- 使用SAX解析方式,不会占用大量内存来保存XML文档数据和关系,效率高。
- 但是在解析过程中,不会保存节点信息和关系,并且只能从前往后,顺序读取、解析。
解析xml文件:
public class Test {
public static void main(String[] args) {
Test dom = new Test();
String filePath = "src/com/briup/demo/class.xml";
dom.saxParse(filePath);
}
public void saxParse(String filePath) {
//获取SAXParserFactory工厂类对象
SAXParserFactory saxParserFactory = SAXParserFactory.newInstance();
try {
//使用工厂对象,创建出SAX解析器
SAXParser saxParser = saxParserFactory.newSAXParser();
//解析xml文件,重写DefaultHandler类中的方法,进行事件处理
saxParser.parse(filePath, new DefaultHandler() {
@Override
public void startDocument() throws SAXException {
System.out.println("<?xml version='1.0' encoding='utf-8'?>");
}
@Override
public void startElement(String uri, String localName, String qName, Attributes atts)
throws SAXException {
StringBuilder sb = new StringBuilder();
sb.append("<").append(qName);
for (int i = 0; i < atts.getLength(); i++) {
sb.append(" ");
sb.append(atts.getQName(i));
sb.append("=");
sb.append("'");
sb.append(atts.getValue(i));
sb.append("'");
}
sb.append(">");
System.out.print(sb.toString());
}
@Override
public void endElement(String uri, String localName, String qName) throws SAXException {
System.out.print("</" + qName + ">");
}
@Override
public void characters(char[] ch, int start, int length) throws SAXException {
System.out.print(new String(ch, start, length));
}
});
} catch (Exception e) {
e.printStackTrace();
}
}
}
6.3 引入DOM4J的DOM解析
示例:
public class Work2 {
static List list = new ArrayList();
public static void main(String[] args) {
Work2 work2 = new Work2();
Document document = work2.creatDocument("src/com/erju/day25/aabb.xml");
work2.prase(document);
//文件保存对象集合
try(ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream(new File("src/com/erju/day25/ab.txt")));) {
objectOutputStream.writeObject(list);
objectOutputStream.flush();
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
list.forEach(Teacher->System.out.println(Teacher.toString()));
}
//对目标文件进行创建document对象
public Document creatDocument(String filePath) {
//创建一个解析器
SAXReader saxReader = new SAXReader();
Document document = null;
try {
//使用解析器对文件进行解读。返回一个document文件
document = saxReader.read(filePath);
} catch (DocumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return document;
}
//对document对象进行解析
public void prase(Document document) {
//获取到根节点
Element rootElement = document.getRootElement();
for(Iterator<Element> elementIterator = rootElement.elementIterator();elementIterator.hasNext();) {
Element element = elementIterator.next();
Teacher teacher = new Teacher();
//设置id
String attributeValue = element.attributeValue("id");
teacher.setId(Integer.valueOf(attributeValue));
//设置名字和salary
String name = element.elementText("name");
String salary = element.elementText("salary");
teacher.setName(name);
teacher.setSalary(Integer.valueOf(salary));
list.add(teacher);
}
}
}
写入xml:
public class Work1 {
public static void main(String[] args) {
Work1 work1 = new Work1();
String str = "src/com/erju/day25/aabb.xml";
Document creat = work1.creat(str);
work1.zhuanhuan(creat);
}
public Document creat(String str) {
SAXReader saxReader = new SAXReader();
Document read=null;
try {
read = saxReader.read(str);
} catch (DocumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return read;
}
public void zhuanhuan(Document document) {
FileWriter fileWriter;
try {
fileWriter = new FileWriter("src/com/erju/day25/bb.xml");
OutputFormat createPrettyPrint = OutputFormat.createPrettyPrint();
XMLWriter writer = new XMLWriter(fileWriter, createPrettyPrint);
writer.write(document);
writer.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









