







 本文详细介绍了Java集合框架的概念,包括集合与数组的区别、集合框架的三大要素、集合的存储结构分类。重点讨论了Collection接口及其基本方法,如迭代器的使用和foreach遍历。此外,文章还深入讲解了List接口及其ArrayList、LinkedList、Vector和Stack的实现,Set集合中的HashSet、TreeSet和LinkedHashSet,以及Map集合的特点和遍历方式。最后提到了集合工具类如Arrays和Collections的使用。
本文详细介绍了Java集合框架的概念,包括集合与数组的区别、集合框架的三大要素、集合的存储结构分类。重点讨论了Collection接口及其基本方法,如迭代器的使用和foreach遍历。此外,文章还深入讲解了List接口及其ArrayList、LinkedList、Vector和Stack的实现,Set集合中的HashSet、TreeSet和LinkedHashSet,以及Map集合的特点和遍历方式。最后提到了集合工具类如Arrays和Collections的使用。
集合

一、 集合概念:
集合是JavaAPI中提供的一种容器工具,可以用来存储多个数据。
1.1集合和数组之间的区别有:
- 数组的长度是固定的,集合的长度是可变的
- 数组中存储的是同一类型的元素,集合中存储的数据可以是不同类型的
- 数组中可以存放基本类型数据或者对象,集合中只能存放对象
- 数组是由JVM中现有的 类型+[] 组合而成的,除了一个length属性,还有从Object中继承过来的方法之外,数组对象就调用不到其他属性和方法了
- 集合是由JavaAPI中的java.util包里面所提供的接口和实现类组成的,这里面定义并实现了很多方法,可以使用集合对象直接调用这些方法,从而操作集合存放的数据
1.2集合框架中主要有三个要素组成:
-
接口
整个集合框架的上层结构,都是用接口进行组织的。
接口中定义了集合中必须要有的基本方法。
通过接口还把集合划分成了几种不同的类型,每一种集合都有自己对应的接口。 -
实现类
对于上层使用接口划分好的集合种类,每种集合的接口都会有对应的实现类。
每一种接口的实现类很可能有多个,每个的实现方式也会各有不同。 -
数据结构
每个实现类都实现了接口中所定义的最基本的方法,例如对数据的存储、检索、操作等方法。
但是不同的实现类,它们存储数据的方式不同,也就是使用的数据结构不同
1.3集合按照其存储结构可以分为两大类:
- java.util.Collection 单列集合
- java.util.Map 双列集合
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mKOBIXCt-1622810064704)(C:\Users\86132\AppData\Roaming\Typora\typora-user-images\image-20210603204419998.png)]](https://i-blog.csdnimg.cn/blog_migrate/1743fe8dc52f05f0aa669f9d8397b833.png)
二、Collection接口 :所有集合的顶层
2.1 他的一些基本方法:
//向集合中添加元素
boolean add(E e)
//把一个指定集合中的所有数据,添加到当前集合中
1 2 3一些方法的使用样例:
boolean addAll(Collection<? extends E> c)
//清空集合中所有的元素。
void clear()
//判断当前集合中是否包含给定的对象。
boolean contains(Object o)
//判断当前集合中是否包含给定的集合的所有元素。
boolean containsAll(Collection<?> c)
//判断当前集合是否为空。
boolean isEmpty()
//返回遍历这个集合的迭代器对象
Iterator<E> iterator()
//把给定的对象,在当前集合中删除。
boolean remove(Object o)
//把给定的集合中的所有元素,在当前集合中删除。
boolean removeAll(Collection<?> c)
//判断俩个集合中是否有相同的元素,如果有当前集合只保留相同元素,如果没有当前集合元素清空
boolean retainAll(Collection<?> c)
//返回集合中元素的个数。
int size()
//把集合中的元素,存储到数组中。
Object[] toArray()
//把集合中的元素,存储到数组中,并指定数组的类型
<T> T[] toArray(T[] a)
2.1.1 对于迭代器的使用:
Collection继承 java.lang.Iterable 后就有了Iterator iterator(); 方法
public static void main(String[] args) {
Collection c1 = new ArrayList();
c1.add("hello1");
c1.add("hello2");
c1.add("hello3");
//获取c1集合的迭代器对象
Iterator iterator = c1.iterator();
//判断迭代器中,是否还有下一个元素
while(iterator.hasNext()){
//如果有的话,就取出来
Object obj = iterator.next();
System.out.println(obj);
}
}
2.1.2对于foreach的使用:遍历集合,数组
for(变量类型 变量名 : 集合){
//操作变量
}
2.1.3 将集合转变为数组:
System.out.println(Arrays.toString(list.toArray()))
2.2. 数据结构:栈、队列、数组、链表、红黑树、哈希表
2.2.1数据存储的常用结构有:产生不同的集合
-
栈:先进后出,最先存进去的元素,最后才能取出来。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QnZvjh9U-1622810064707)(C:\Users\86132\AppData\Roaming\Typora\typora-user-images\image-20210603213044518.png)]](https://i-blog.csdnimg.cn/blog_migrate/fc83eea2e987970483fe798a4431e4b2.png)
-
队列:先进先出,最先存进去的元素,可以最先取出来
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UbYwCmV0-1622810064709)(C:\Users\86132\AppData\Roaming\Typora\typora-user-images\image-20210603213100358.png)]](https://i-blog.csdnimg.cn/blog_migrate/ef3658b2657ce3c62df591397e423107.png)
-
数组:
-
通过下标索引,可以快速访问指定位置的元素,但是在数组中间位置添加数据或者删除数据
会比较慢,因为数组中间位置的添加和删除元素,为了元素数据能紧凑的排列在一起,那么就会引起其后面的元素移动位置。![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-86kyBdYb-1622810064712)(C:\Users\86132\AppData\Roaming\Typora\typora-user-images\image-20210603213122438.png)]](https://i-blog.csdnimg.cn/blog_migrate/2709fb059649909f83ead9ec55e8952c.png)
-
-
链表:
-
链表(linked list),是有一个一个node节点组成,每个node节点中存储了一个数据,以及一个指向下一个node节点对象的引用(单向链表),如果是双向链表的话,还会存储另一个引用,指向了上一个node节点对象。
-
查找元素慢,因为需要通过连接的节点,依次向后查找指定元素(没有直接的下标索引)
-
新增和删除元素较快,例如删除,只需要让当前node节点中的引用指向另一个节点对象即可,原来
的指向的node节点就相当于删除了。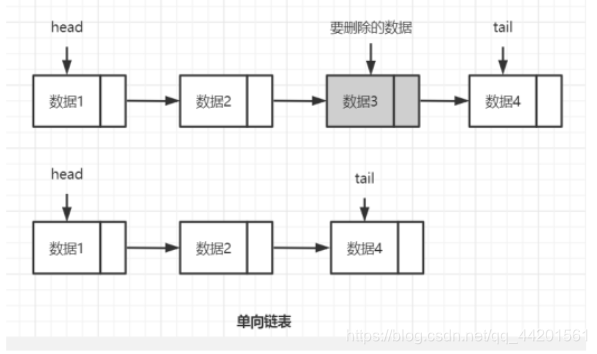
-
-
红黑树:
-
红黑树是一种特殊化的平衡二叉树,它可以在进行插入和删除的时候,如果左右子数的高度相差较大,那么就通过特定操作(左旋、右旋)保持二叉查找树的平衡(动态平衡),从而获得较高的查找性能。
-
-
根节点必须是黑色
-
其他节点可以是红色的或者黑色
-
叶子节点(特指null节点)是黑色的
-
每个红色节点的子节点都是黑色的
-
任何一个节点到其每一个叶子节点的所有路径上黑色节点数相同
-
-
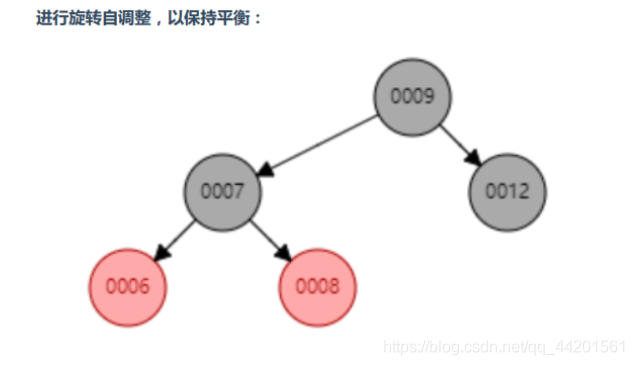
-
哈希表 :
-
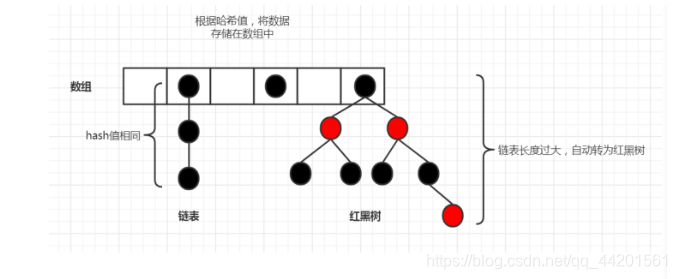
java中的哈希表(hash),在JDK1.8之前是采用数组+链表进行实现
-
JDK1.8中,哈希表存储采用数组+链表/红黑树进行实现,当链表长度超过阈值(8)时,将链表转换为红黑树,小于6是自动转为链表这样可以大大提高查找的性能
-
2.3. List集合:有序,带索引,保存重复数据
List接口继承了Collection接口,Collection接口继承了Iterable接口
2.3.1常用方法:
//返回集合中指定位置的元素。
E get(int index);
//用指定元素替换集合中指定位置的元素,并返回被替代的旧元素。
E set(int index, E element);
//将指定的元素,添加到该集合中的指定位置上。
void add(int index, E element);
//从指定位置开始,把另一个集合的所有元素添加进来
boolean addAll(int index, Collection<? extends E> c);
//移除列表中指定位置的元素, 并返回被移除的元素。
E remove(int index);
//查收指定元素在集合中的所有,从前往后查到的第一个元素(List集合可以重复存放数据)
int indexOf(Object o);
//查收指定元素在集合中的所有,从后往前查到的第一个元素(List集合可以重复存放数据)
int lastIndexOf(Object o);
//根据指定开始和结束位置,截取出集合中的一部分数据
List<E> subList(int fromIndex, int toIndex);
2.3.2 实现类1:ArrayList
java.util.ArrayList 是最常用的一种List类型集合, ArrayList 类中使用数组来实现数据的存储,
所以它的特点是就是:增删慢,查找快。
2.3.3 实现类2:LinkedList
java.util.LinkedList 存储数据采用的数据结构是链表,所以它的特点是:增删快,查找慢
它的特点刚好和 ArrayList 相反,所以在代码中,需要对集合中的元素做大量的增删操作的时候,可以选择使用 LinkedList
注意,调用的方法都一样,但是每次改变list指向的对象,分别执行ArrayList对象和LinkedList对象
注意, list.getClass().getSimpleName() 方法可以获取list引用当前指向对象的实际类型的简单名字
注意, System.currentTimeMillis(); 可以获取当前时刻的时间戳
注意,集合中操作的数据量小的时候,使用哪种实现类,性能差别都不大
了解内容:
LinkList为双向列表
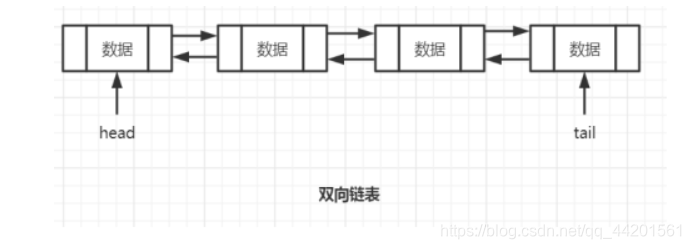
操作方法:
//将指定元素插入此列表的开头
void addFirst(E e)
//将指定元素添加到此列表的结尾
void addLast(E e)
//返回此列表的第一个元素
E getFirst()
//返回此列表的最后一个元素
E getLast()
//从此列表所表示的堆栈处弹出一个元素
E pop()
//将元素推入此列表所表示的堆栈
void push(E e)
//移除并返回此列表的第一个元素
E removeFirst()
//移除并返回此列表的最后一个元素
E removeLast()
LinkedList 类不仅实现了 List 接口,还有 Queue 接口以及子接口 Deque 也实现了 :
Queue 是队列接口, Deque 是双端队列
JavaAPI中提供了 java.util.Stack 来实现栈结构,但官方目前已不推荐使用,而是推荐使用
java.util.Deque 双端队列来实现队列与栈的各种需求
所以 LinkedList 同时具有队列和栈的操作方法,pop和push都是栈结构的操作方法
2.3.4 Vector
内部也是采用了数组来存储数据,但是 Vector 中的方法大多数都是线程安全的方法,所以在多线并发访问的环境中,可以使用 Vector 来保证集合中元据操作的安全。
查看 Vector 中方法的定义,可以看到多大数方法都使用了 synchronized 关键字,来给当前方法加锁。
2.3.5 Stack
模拟了栈的数据结构
2.4. Set 集合:无序、无索引、不可保存重复数据
2.4.1 实现类1:HashSet:
哈希表:数组+单链表/红黑树(超过8)
java.util.HashSet 类的实现,主要依靠的是HashMap:及
hashcode()将传入参数散列压缩为固定长度的哈希值,并以此为下标值存入数组,其无序的来源
- HashSet中存储元素是无序的,主要因为它是靠对象的哈希值来确定元素在集合中的存储位置。
- HashSet中元素不可重复,主要是靠对象的hashCode和equals方法来判断对象是否重复。
去重:重写Student中的hashCode方法和equals方法
public class Student {
String name;
int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public Student() {
}
@Override
public String toString() {
return "Student [name=" + name + ", age=" + age + "]";
}
@Override
public int hashCode() {
return Objects.hash(name,age);
}
@Override
public boolean equals(Object obj) {
if (obj==null) {
return false;
}
if (obj instanceof Student) {
return true;
}
Student s = (Student)obj;
if (this.name.equals(s.name)&&this.age==s.age) {
return true;
}
return false;
}
/*自然排序:八大基本--包装、String
* lang包下comparable---compareTo(Object o)
*
* Student 实现comparable
*客户化排序
* until包下 Comparator-----compare
* new TreeSet(Comparator c);
* compare(Object o1,Object o2)
* >0 大 <0 小 = 相等
*
*
* */
2.4.2 实现类2:TreeSet排序
注意,TreeSet是Set接口的子接口SortedSet的实现类
- 自然排序
- 比较器排序(也称客户化排序)
存入的时候自动向上转型为Integer ,调用的是integer中的compare方法
八大基本–包装、String下有 comparable—compareTo(Object o)方法
- Set hashSet = new TreeSet();
比较器排序(也称客户化排序):
- Comparator comparator = new Comparator() {}
- Set hashSet = new TreeSet(comparator);
compareTo方法的放回结果,只关心正数、负数、零,不关心具体的值是多少
内部类使用:
public class Student{
String name;
int age;
public Student(){}
public Student(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}
public static void main(String[] args) {
//使用Comparator接口,创建出匿名内部类对象,这个对象就是要用的比较器对象
Comparator c = new Comparator() {
@Override
//o1要排序的对象,o2已经排好序的对象
public int compare(Object o1, Object o2) {
Student s1 = (Student) o1;
Student s2 = (Student) o2;
return s1.age > s2.age? 1 : (s1.age==s2.age? 0 : -1);
}
};
//创建TreeSet对象的时候,把比较器对象传入
Set set = new TreeSet(c);
set.add(new Student("mary",23));
set.add(new Student("jack",21));
set.add(new Student("tom",20));
set.add(new Student("lucy",22));
for(Object obj : set){
System.out.println(obj);
}
//运行结果:
Student{name='tom', age=20}
Student{name='jack', age=21}
Student{name='lucy', age=22}
Student{name='mary', age=23}
2.4.3 实现类3:LinkedHashSet
使用链表维护了一个添加进集合中的顺序。导致当我们遍历LinkedHashSet集合元素时,是按照添加进去的顺序遍历的!
三、 Map集合:哈希表
很多时候,我们会遇到成对出现的数据,例如,姓名和电话,身份证和人,IP和域名等等,这种成对出
现,并且一一对应的数据关系,叫做映射。
java.util.Map<K, V> 接口,就是专门处理这种映射关系数据的集合类型。
3.1 注意点
- key值必须是唯一的,value值允许重复
- 键(key)和值(value)一一映射,一个key对应一个value
- 在Map中,通过key值(唯一的),可以快速的找到对应的value值
3.2 一些方法
//把key-value存到当前Map集合中
V put(K key, V value)
//把指定map中的所有key-value,存到当前Map集合中
void putAll(Map<? extends K,? extends V> m)
//当前Map集合中是否包含指定的key值
boolean containsKey(Object key)
//当前Map集合中是否包含指定的value值
boolean containsValue(Object value)
//清空当前Map集合中的所有数据
void clear()
//在当前Map集合中,通过指定的key值,获取对应的value
V get(Object key)
//在当前Map集合中,移除指定key及其对应的value
V remove(Object key)
//返回当前Map集合中的元素个数(一对key-value,算一个元素数据)
int size()
//判断当前Map集合是否为空
boolean isEmpty()
//返回Map集合中所有的key值
Set<K> keySet()
//返回Map集合中所有的value值
Collection<V> values()
//把Map集合中的的key-value封装成Entry类型对象,再存放到set集合中,并返回
Set<Map.Entry<K,V>> entrySet()
3.3 实现类
- HashMap :存储数据采用的数组+链表/红黑树结构,元素的存取顺序不能保证一致。由于要保证键的唯一、不重复,需要重写键的hashCode()方法、equals()方法。(重要,最常用)。当数组超过64,链表大于8链表会转换为红黑树,小于6退化为链表。
- HashTable :和之前List集合中的 Vector 的功能类似,可以在多线程环境中,保证集合中的数据的操作安全,类中的方法大多数使用了synchronized 修饰符进行加锁。(线程安全)
- TreeMap :该类是 Map 接口的子接口 SortedMap 下面的实现类,和 TreeSet 类似,它可以对key值进行排序,同时构造器也可以接收一个比较器对象作为参数。支持key值的自然排序和比较器排序俩种方式。(支持key排序)红黑树数据结构
- LinkedHashMap :该类是 HashMap 的子类,存储数据采用的数组+链表结构+双向链表。通过链表结构可以保证元素的存取顺序一致;(存入顺序就是取出顺序)
3.4 遍历方式:和Set亲密无间
3.4.1
Map中的keySet方法
Map中的values方法
3.4.5 最常用: entrySet() 方法
public static void main(String[] args) {
Map map = new LinkedHashMap();
map.put(4,"mary");
map.put(2,"jack");
map.put(1,"tom");
map.put(3,"lucy");
Set entrySet = map.entrySet();
for(Object obj : entrySet){
Map.Entry entry = (Map.Entry) obj;
System.out.println(entry.getKey()+" : "+entry.getValue());
}
}
3.5 集合工具类
java.util.Arrays 是一个工具类,专门用来操作数组对象的,里面都是静态方法,可直接调用。
java.util.Collections 也是一个工具类,专门用来操作集合对象的,里面都是静态方法,可以直接调用
Collections 中的常用方法:
- fill方法,使用指定元素替换指定列表中的所有元素
- Collections.fill(list, 20);
- max方法,根据元素的自然顺序,返回给定集合的最大元素
- Collections.max(list)
- reverse方法,反转集合中的元素
- sort方法,根据元素的自然顺序,对指定列表按升序进行排序
- shuffle方法,使用默认随机源对指定列表进行置换 :这个不是太理解
- addAll方法,往集合中添加一些元素
- synchronizedCollection,把非线程安全的Collection类型集合,转为线程安全的集合
- synchronizedList,把非线程安全的List类型集合,转为线程安全的集合
- synchronizedSet,把非线程安全的Set类型集合,转为线程安全的集合
- synchronizedMap,把非线程安全的Map类型集合,转为线程安全的集合


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









