







1. 批量移除xml标注中的某一个类别标签
当我们拿到一个数据集,我只希望使用其中的一种或者几种标签,要删除其中的一些标签,就可以使用这个代码。
# 批量移除xml标注中的某一个类别标签
import xml.etree.cElementTree as ET
import os
# xml文件路径
xml_path = r'./Annotations'
xml_files = os.listdir(xml_path)
# 需要删除的类别名称,可以填多个
CLASSES = ["person"]
for axml in xml_files:
path_xml = os.path.join(xml_path, axml)
tree = ET.parse(path_xml)
root = tree.getroot()
for child in root.findall('object'):
name = child.find('name').text
if name in CLASSES:
root.remove(child)
tree.write(os.path.join(xml_path, axml))
# import xml.etree.cElementTree as ET
# import os
# import shutil
# import logging
# # 配置日志
# logging.basicConfig(filename='xml_process.log', level=logging.INFO,
# format='%(asctime)s - %(levelname)s - %(message)s')
# def process_xml(xml_path, classes_to_remove):
# backup_path = os.path.join(xml_path, '_backup')
# os.makedirs(backup_path, exist_ok=True)
# for filename in os.listdir(xml_path):
# if not filename.endswith('.xml'):
# continue
# src_path = os.path.join(xml_path, filename)
# dest_path = os.path.join(backup_path, filename)
# try:
# # 备份原始文件
# shutil.copy2(src_path, dest_path)
# logging.info(f"已备份文件: {filename}")
# # 解析XML
# tree = ET.parse(src_path, parser=ET.XMLParser(encoding='utf-8'))
# root = tree.getroot()
# # 查找并删除目标节点
# removed_count = 0
# for obj in root.findall('.//{*}object'): # 处理命名空间
# name_elem = obj.find('.//{*}name')
# if name_elem is not None and name_elem.text.lower() in [c.lower() for c in classes_to_remove]:
# root.remove(obj)
# removed_count += 1
# # 保存修改
# tree.write(src_path, encoding='utf-8', xml_declaration=True)
# logging.info(f"已处理文件: {filename}, 删除 {removed_count} 个标注")
# except ET.ParseError as e:
# logging.error(f"XML解析错误 {filename}: {str(e)}")
# except Exception as e:
# logging.error(f"处理文件 {filename} 时发生错误: {str(e)}")
# if __name__ == "__main__":
# xml_folder = r'./Annotations'
# target_classes = ["person"]
# process_xml(xml_folder, target_classes)
# print("批量处理完成,请检查日志文件 xml_process.log")2. 修改标签的label名字
在xml文件中,由于一些标签每个人给的名字不一样,我们为了统一他们,只能修改一些
"""
使用python xml解析树解析xml文件,批量修改xml文件里object节点下name节点的text
"""
import glob
import xml.etree.ElementTree as ET
path = r'./Annotations' # xml文件夹路径
i = 0
for xml_file in glob.glob(path + '/*.xml'):
# print(xml_file)
tree = ET.parse(xml_file)
obj_list = tree.getroot().findall('object')
for per_obj in obj_list:
if per_obj[0].text == 'dangerous-behavior': # 找到错误的标签“ dangerous-behavior ”
per_obj[0].text = 'climbing' # 修改成“自己想要的标签名”
i = i+1
tree.write(xml_file) # 将改好的文件重新写入,会覆盖原文件
print('共完成了{}处替换'.format(i))
3. VOC 转 YOLO 的 txt 格式
我们使用yolo很多时候需要把 voc 格式的数据集改成 txt
import os
import xml.etree.ElementTree as ET
# 定义类别顺序
categories = ['climbing']
category_to_index = {category: index for index, category in enumerate(categories)}
# 定义输入文件夹和输出文件夹
input_folder = r'./Annotations' # 替换为实际的XML文件夹路径
output_folder = r'./labels' # 替换为实际的输出TXT文件夹路径
# 确保输出文件夹存在
os.makedirs(output_folder, exist_ok=True)
# 遍历输入文件夹中的所有XML文件
for filename in os.listdir(input_folder):
if filename.endswith('.xml'):
xml_path = os.path.join(input_folder, filename)
# 解析XML文件
tree = ET.parse(xml_path)
root = tree.getroot()
# 提取图像的尺寸
size = root.find('size')
width = int(size.find('width').text)
height = int(size.find('height').text)
# 存储name和对应的归一化坐标
objects = []
# 遍历XML中的object标签
for obj in root.findall('object'):
name = obj.find('name').text
if name in category_to_index:
category_index = category_to_index[name]
else:
continue # 如果name不在指定类别中,跳过该object
bndbox = obj.find('bndbox')
xmin = int(bndbox.find('xmin').text)
ymin = int(bndbox.find('ymin').text)
xmax = int(bndbox.find('xmax').text)
ymax = int(bndbox.find('ymax').text)
# 转换为中心点坐标和宽高
x_center = (xmin + xmax) / 2.0
y_center = (ymin + ymax) / 2.0
w = xmax - xmin
h = ymax - ymin
# 归一化
x = x_center / width
y = y_center / height
w = w / width
h = h / height
objects.append(f"{category_index} {x} {y} {w} {h}")
# 输出结果到对应的TXT文件
txt_filename = os.path.splitext(filename)[0] + '.txt'
txt_path = os.path.join(output_folder, txt_filename)
with open(txt_path, 'w') as f:
for obj in objects:
f.write(obj + '\n')4. 划分YOLOv11数据集
转为 txt 格式后,我们需要对数据集进行划分
# 该代码用于划分yolov11数据集
import os
import shutil
import random
# random.seed(0) #随机种子,可自选开启
def split_data(file_path, label_path, new_file_path, train_rate, val_rate, test_rate):
images = os.listdir(file_path)
labels = os.listdir(label_path)
images_no_ext = {os.path.splitext(image)[0]: image for image in images}
labels_no_ext = {os.path.splitext(label)[0]: label for label in labels}
matched_data = [(img, images_no_ext[img], labels_no_ext[img]) for img in images_no_ext if img in labels_no_ext]
unmatched_images = [img for img in images_no_ext if img not in labels_no_ext]
unmatched_labels = [label for label in labels_no_ext if label not in images_no_ext]
if unmatched_images:
print("未匹配的图片文件:")
for img in unmatched_images:
print(images_no_ext[img])
if unmatched_labels:
print("未匹配的标签文件:")
for label in unmatched_labels:
print(labels_no_ext[label])
random.shuffle(matched_data)
total = len(matched_data)
train_data = matched_data[:int(train_rate * total)]
val_data = matched_data[int(train_rate * total):int((train_rate + val_rate) * total)]
test_data = matched_data[int((train_rate + val_rate) * total):]
# 处理训练集
for img_name, img_file, label_file in train_data:
old_img_path = os.path.join(file_path, img_file)
old_label_path = os.path.join(label_path, label_file)
new_img_dir = os.path.join(new_file_path, 'train', 'images')
new_label_dir = os.path.join(new_file_path, 'train', 'labels')
os.makedirs(new_img_dir, exist_ok=True)
os.makedirs(new_label_dir, exist_ok=True)
shutil.copy(old_img_path, os.path.join(new_img_dir, img_file))
shutil.copy(old_label_path, os.path.join(new_label_dir, label_file))
# 处理验证集
for img_name, img_file, label_file in val_data:
old_img_path = os.path.join(file_path, img_file)
old_label_path = os.path.join(label_path, label_file)
new_img_dir = os.path.join(new_file_path, 'val', 'images')
new_label_dir = os.path.join(new_file_path, 'val', 'labels')
os.makedirs(new_img_dir, exist_ok=True)
os.makedirs(new_label_dir, exist_ok=True)
shutil.copy(old_img_path, os.path.join(new_img_dir, img_file))
shutil.copy(old_label_path, os.path.join(new_label_dir, label_file))
# 处理测试集
for img_name, img_file, label_file in test_data:
old_img_path = os.path.join(file_path, img_file)
old_label_path = os.path.join(label_path, label_file)
new_img_dir = os.path.join(new_file_path, 'test', 'images')
new_label_dir = os.path.join(new_file_path, 'test', 'labels')
os.makedirs(new_img_dir, exist_ok=True)
os.makedirs(new_label_dir, exist_ok=True)
shutil.copy(old_img_path, os.path.join(new_img_dir, img_file))
shutil.copy(old_label_path, os.path.join(new_label_dir, label_file))
print("数据集已划分完成")
if __name__ == '__main__':
file_path = r"./data/JPEGImages" # 图片文件夹
label_path = r'./data/labels' # 标签文件夹
new_file_path = r"./VOCdevkit" # 新数据存放位置
split_data(file_path, label_path, new_file_path, train_rate=0.8, val_rate=0.1, test_rate=0.1)5. 将视频数据划分成图片
在做数据集的时候,我们只有视频数据,就需要将视频截成图片
import cv2
import os
# 视频文件夹路径
video_dir = "video"
# 输出主目录
output_main_dir = "output"
# 确保输出目录存在
os.makedirs(output_main_dir, exist_ok=True)
# 遍历视频文件夹中的所有文件
for video_file in os.listdir(video_dir):
video_path = os.path.join(video_dir, video_file)
# 检查是否为视频文件(可根据需要添加其他扩展名)
if os.path.isfile(video_path) and video_file.lower().endswith(('.mp4', '.avi', '.mov')):
# 创建视频对应的输出子目录
video_name = os.path.splitext(video_file)[0]
output_dir = os.path.join(output_main_dir, video_name)
os.makedirs(output_dir, exist_ok=True)
# 打开视频文件
cap = cv2.VideoCapture(video_path)
if not cap.isOpened():
print(f"无法打开视频文件: {video_path}")
continue
# 处理视频帧
frame_count = 0
while True:
ret, frame = cap.read()
if not ret:
break
# 每隔5帧保存一次(可根据需要修改间隔)
if frame_count % 5 == 0:
output_path = os.path.join(output_dir, f"frame_{frame_count}.jpg")
cv2.imwrite(output_path, frame)
frame_count += 1
print(f"已处理 {video_file}, 共提取 {frame_count//5} 张图片")
cap.release()
cv2.destroyAllWindows()6.win10 快速创建多个空txt文件
创建文件夹新建一个txt文件,将如下代码粘贴到txtx文件中
@echo off
for /l %%i in (1,1,10) do (
type nul > "File%%i.txt"
)1,1,10 表示从1开始,步长为1,生成到10
File%%i.txt 文件名格式为 File1.txt, File2.txt 等。
将文件保存为 1.bat(命名任意,只要改成bat文件就可以),双击运行即可在当前目录生成文件
7.Labelimg导入预设标签
我使用 pip 安装的labelimg,所以找到自己的python安装位置,在如下路径下可以找到 labelimg文件夹,在该文件中新建data文件夹
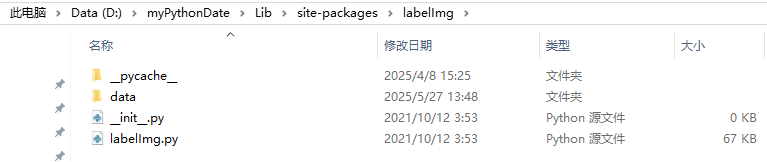
在data文件夹中新建 predefined_classes.txt 文件,其中存放我们想要预设的种类名,一行代表一类,标签在txt中的数字为行数,比如 car 打出的标签数字就为 2
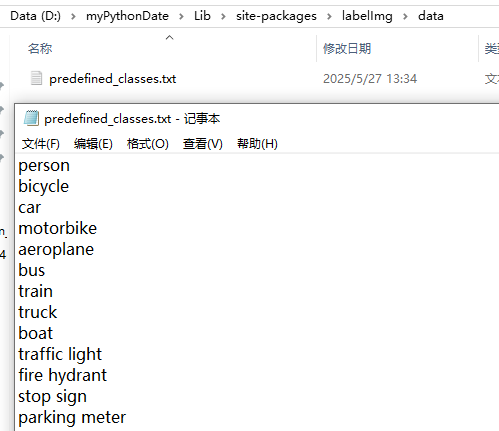
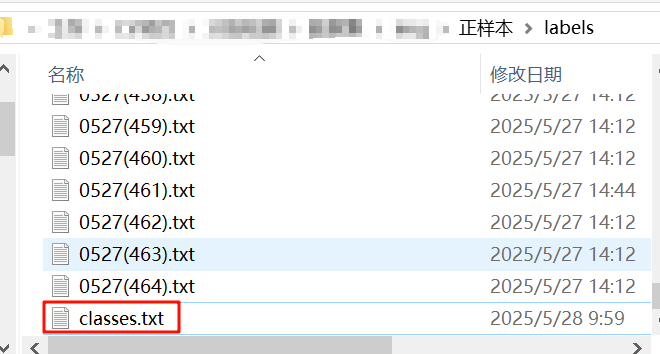
在自己存放标签的文档中放入classes.txt,其中的内容和 predefined_classes.txt 中的一样,存放标签种类,没有这个文件打开labelimg会报错
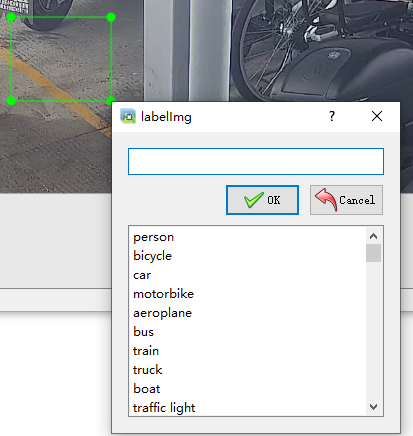
打开labelimg使用快捷键 w 打标签,就可以看到自己预设的标签了
本文代码一部分自于优快云博主,本文是为了方便自己使用做了汇总,参考:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









