






 本文提供在Windows 10环境下配置Hadoop和Spark集群的详细步骤,包括虚拟机安装、网络配置、防火墙设置、SSH免密等,最终实现集群搭建及示例运行。
本文提供在Windows 10环境下配置Hadoop和Spark集群的详细步骤,包括虚拟机安装、网络配置、防火墙设置、SSH免密等,最终实现集群搭建及示例运行。
WIN10环境下配置 hadoop + spark 并运行开发实例的教程
前期准备
基本环境配置
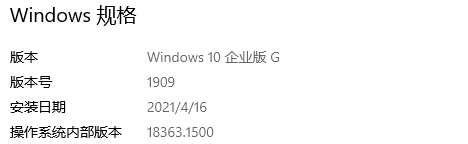
系统:windows 10
电脑基本配置

需要用到的软件
百度网盘链接:
链接: https://pan.baidu.com/s/1D3MScCEXlk2h9rlzUc__fw.
提取码:1111
复制这段内容后打开百度网盘手机App,操作更方便哦–来自百度网盘超级会员V3的分享
虚拟机管理软件:
VMware-workstation-full-15.5.6-16341506.exe
Linux系统:
CentOS-7-x86_64-DVD-2003
ssh软件:
Xshell-7.0.0065p.exe
hadoop版本:
hadoop-2.7.7.tar.gz
jdk版本:
jdk-8u171-linux-x64.tar.gz
scala版本:
scala-2.12.11.tgz
spark版本:
spark-3.0.2-bin-hadoop2.7.tgz
虚拟机的安装
我们需要三台虚拟机:
主机 master
从机1 s1
从机2 s2
下面开始安装虚拟机
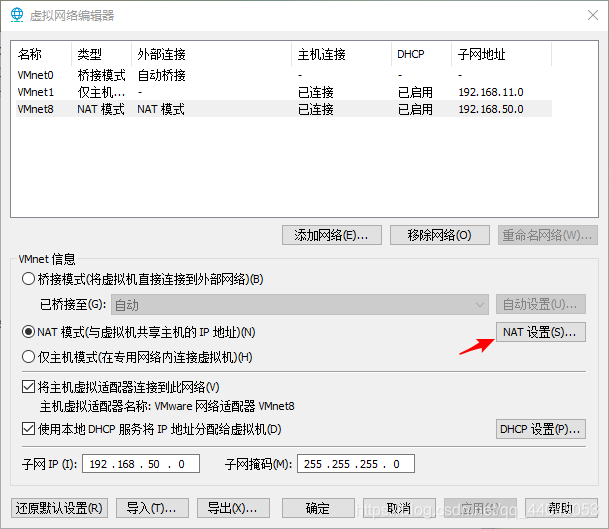
打开界面,点击编辑,打开虚拟网络编辑器
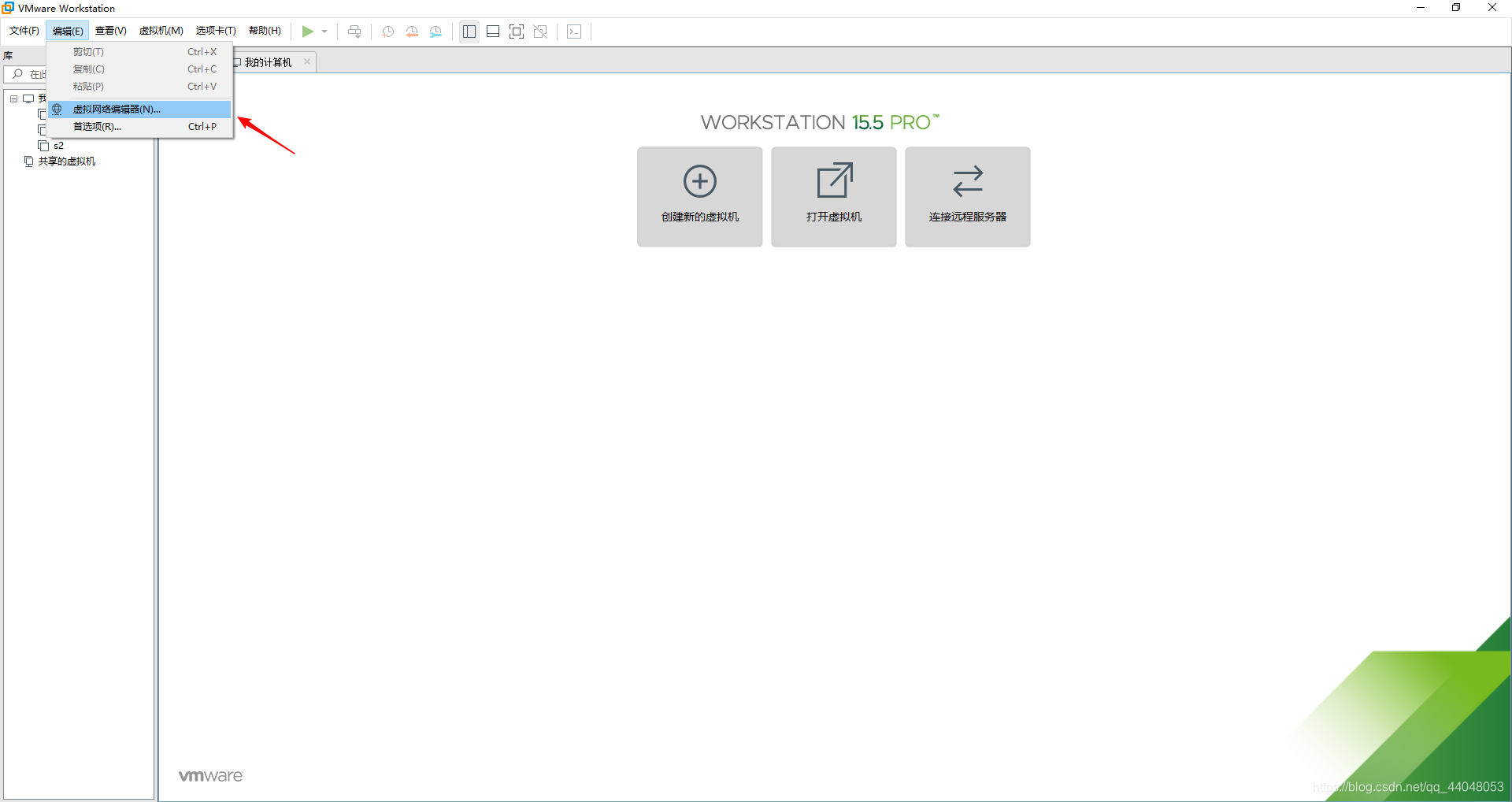
点击红色箭头所指向的位置
点击创建虚拟机
点击下一步

选择2003版本
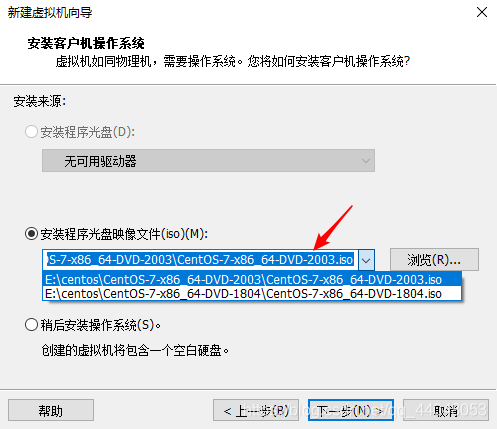
选择安装位置,注意名字要改一下我的是master
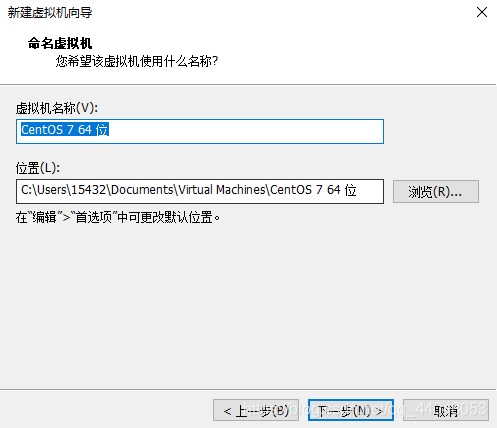
主机设置40GB,两个从机设置30GB
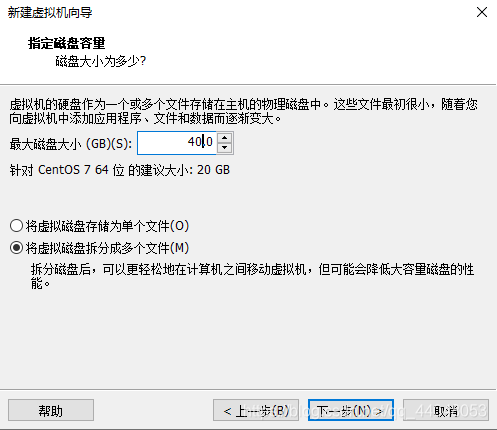
点击完成
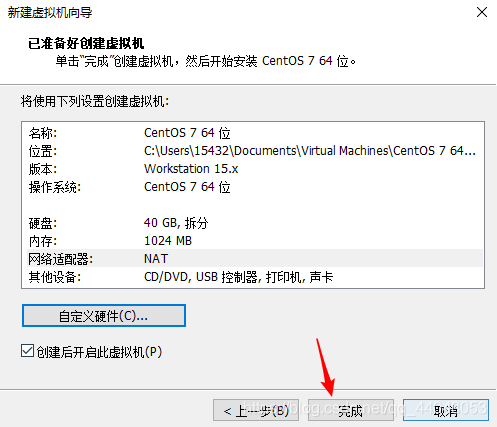
进入到这个界面
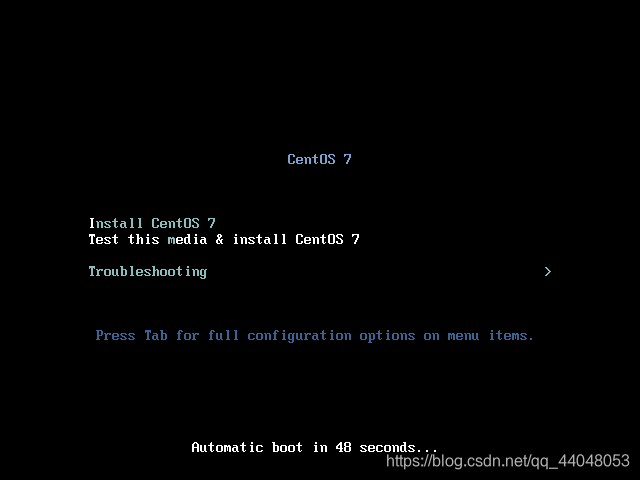
按回车安装,进入到该界面
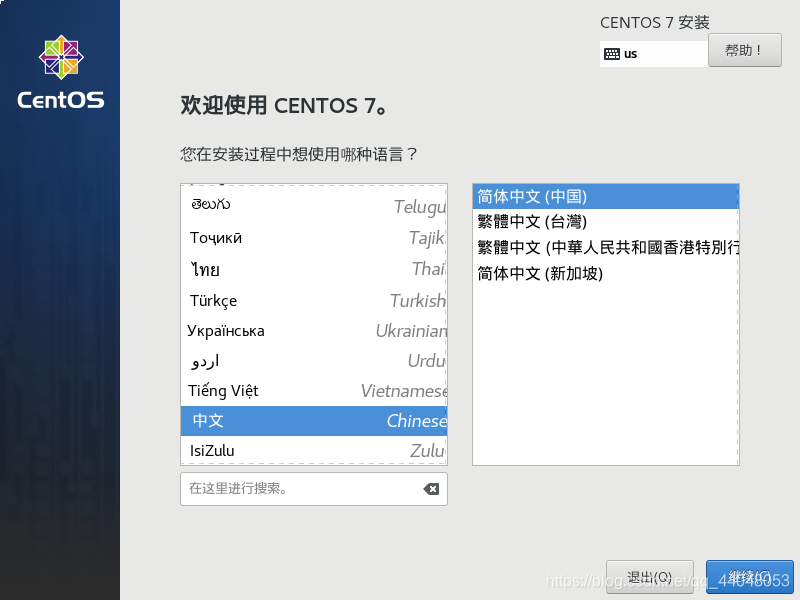
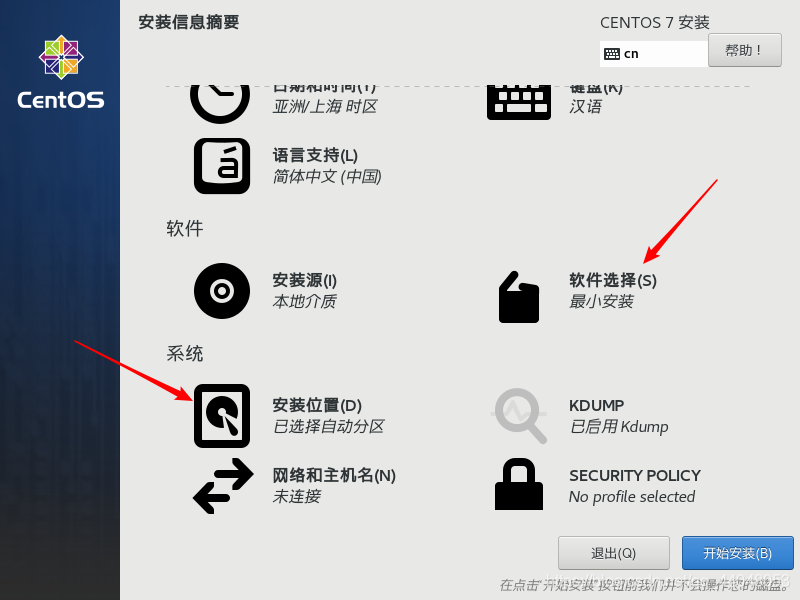
点击继续先选择软件选择,再选择安装位置
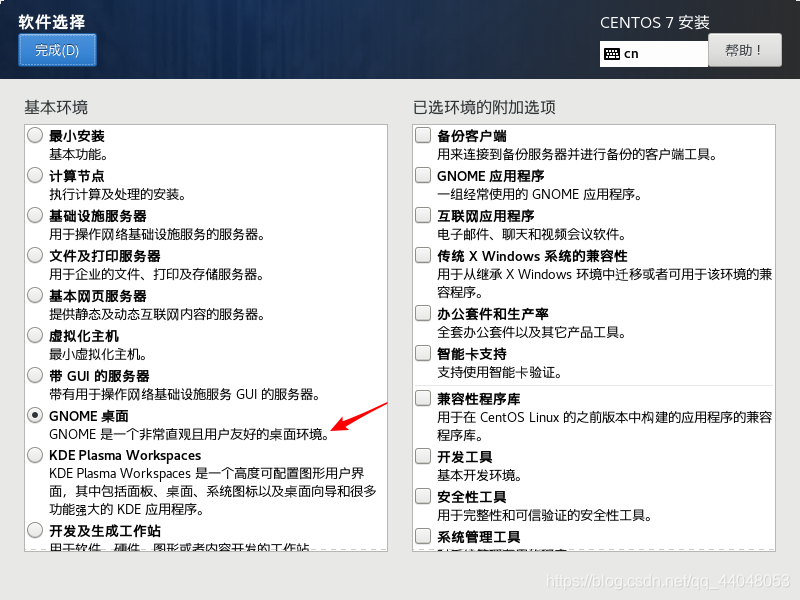
选择GNOME桌面
点击完成后推出再点击安装位置,点击磁盘,再点击完成
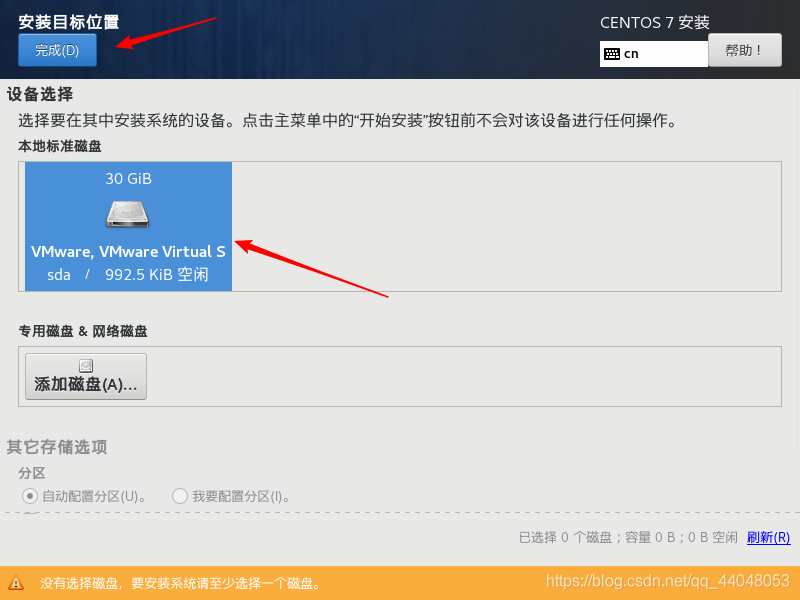
点击完成后,在界面选择开始安装,设置密码 建议123456 或者 简单一些的
在此界面下等待安装成功
点击重启
接受许可证
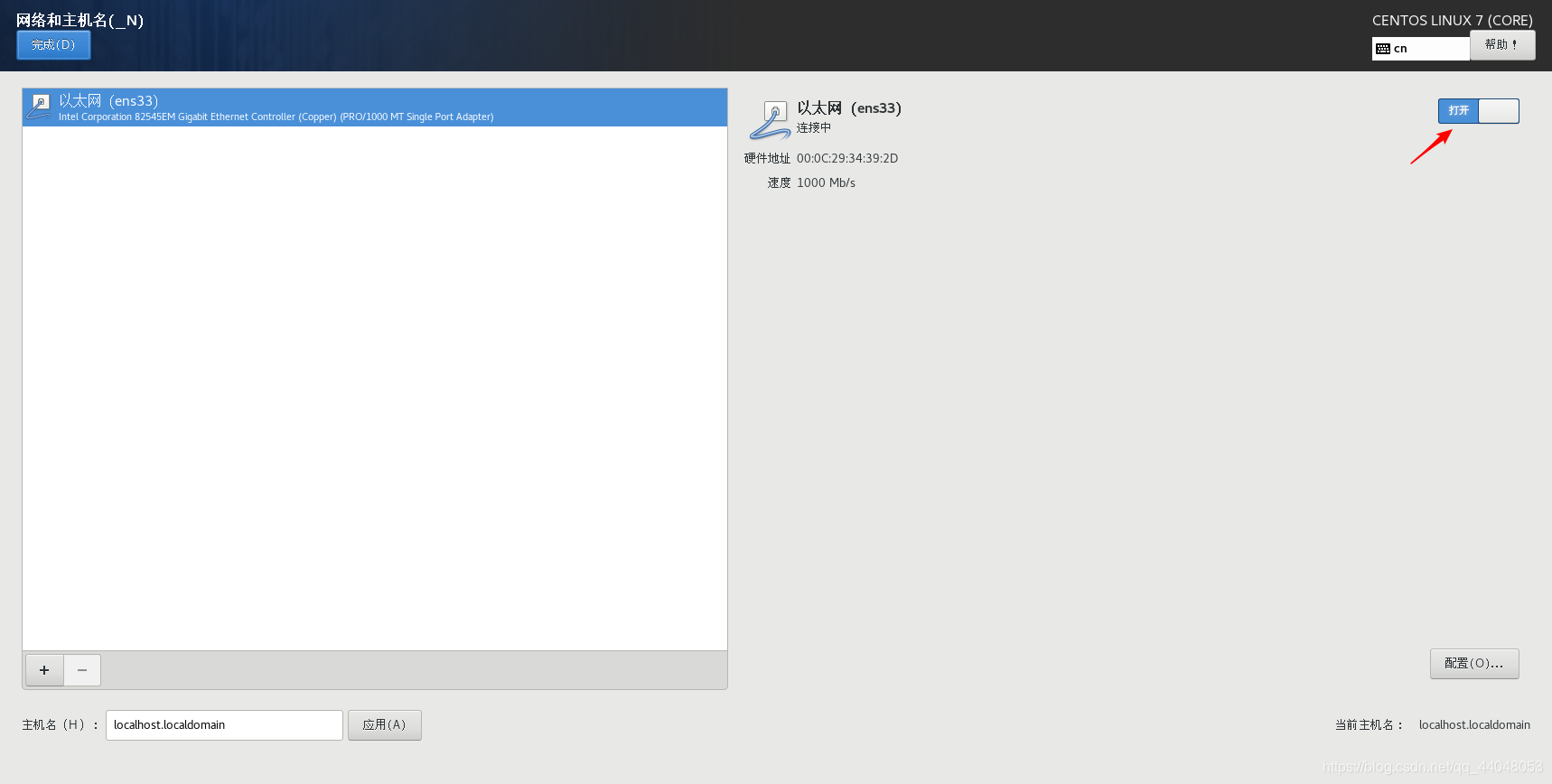
打开网络连接
不用点击配置,直接点击完成配置,进入界面
在进入图形化界面时,会让我们注册一个用户,不用担心,我们只是使用root用户登录
用户名:root
密码:123456 (你设置的密码)
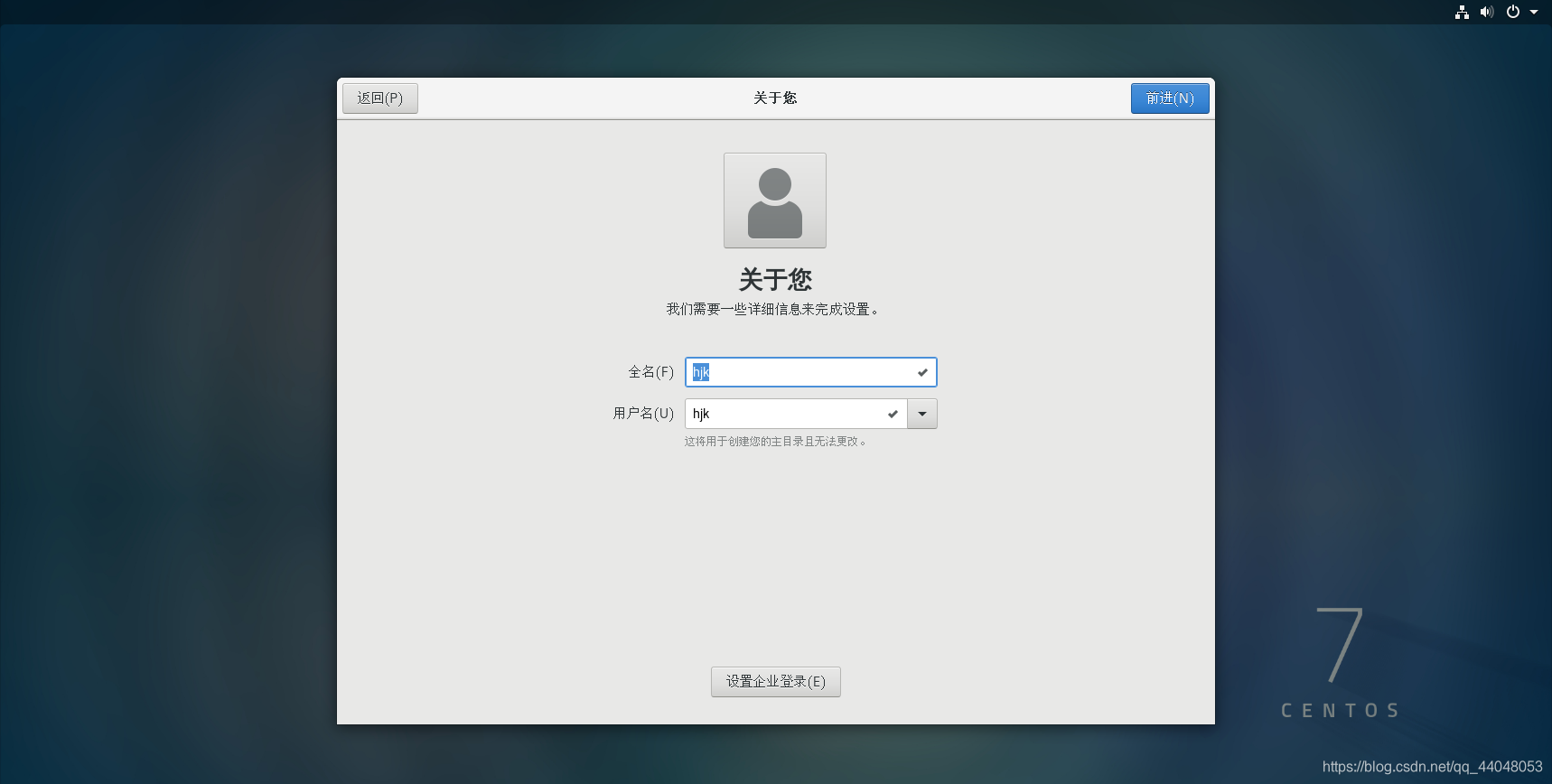
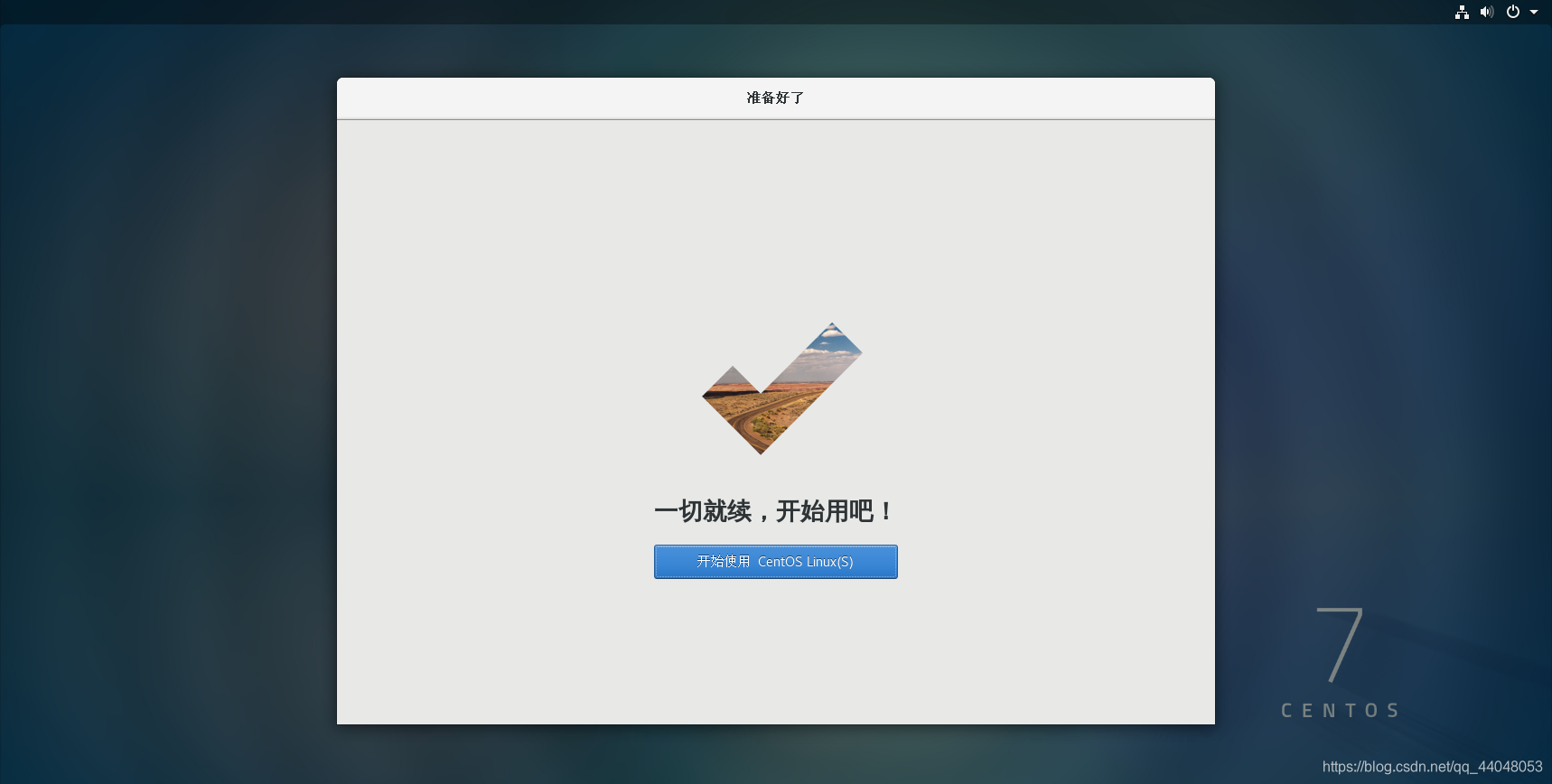
这里我们是以hjk登录的,我们可以重启并选择root用户登录
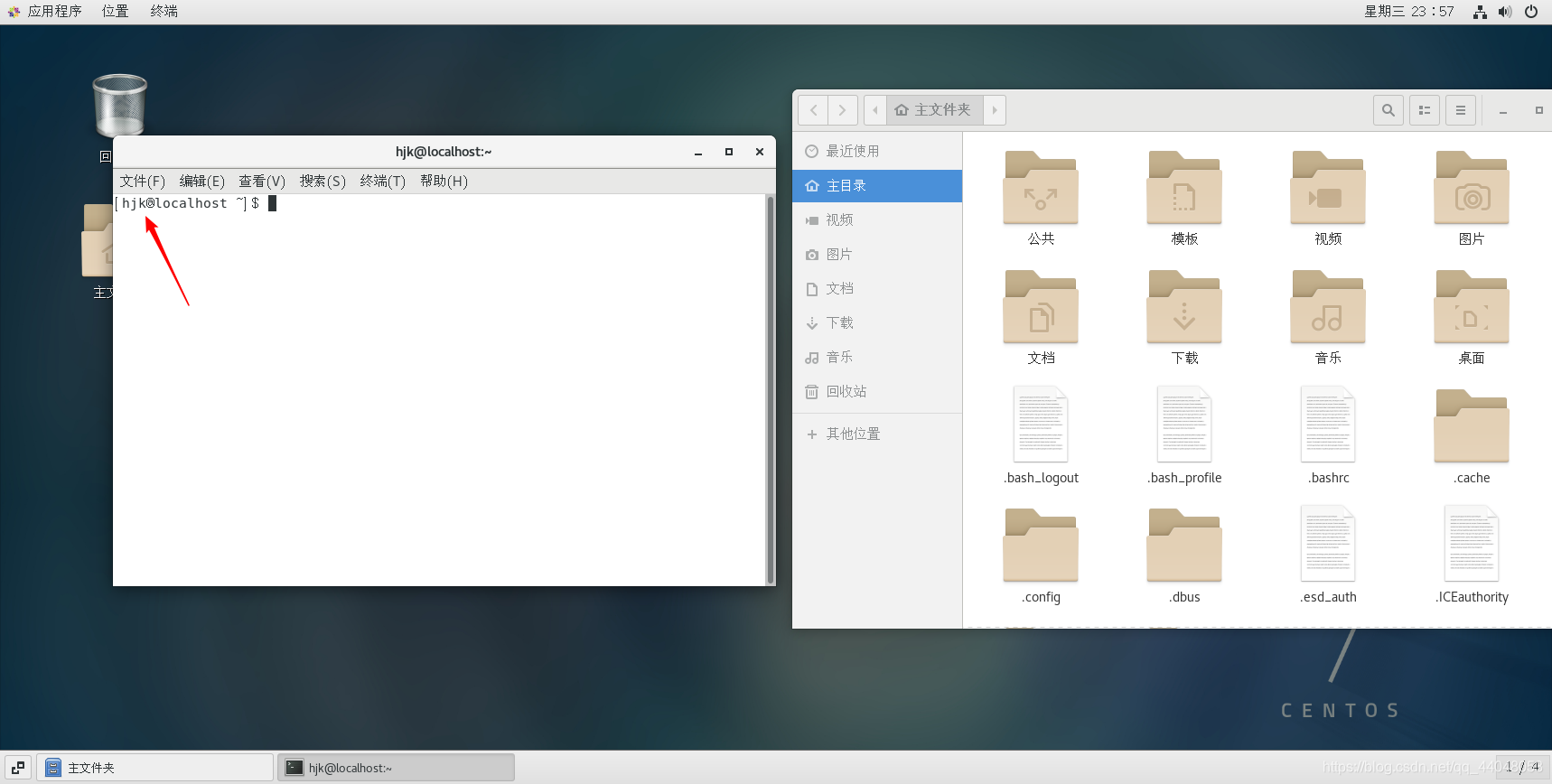
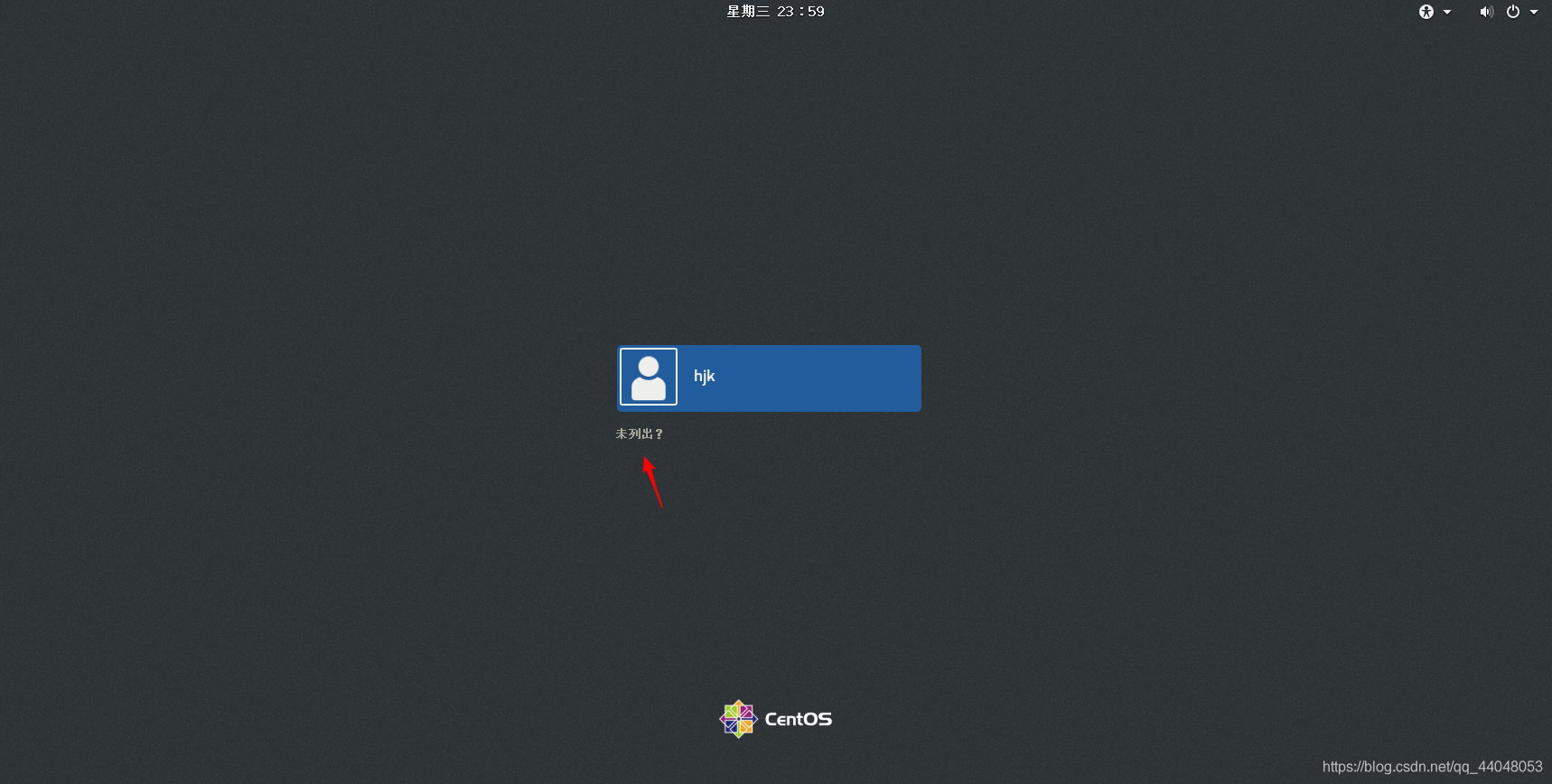
到这里,我们master主机就安装成功啦
同样地,修改名字,其他都一样,配置好s1,s2
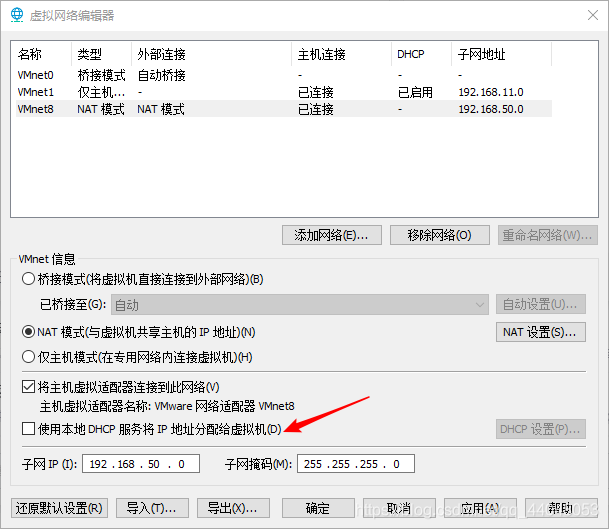
配置虚拟机中的静态网络
打开虚拟机master,打开终端
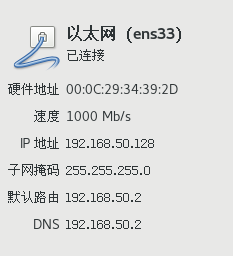
测试网络连接
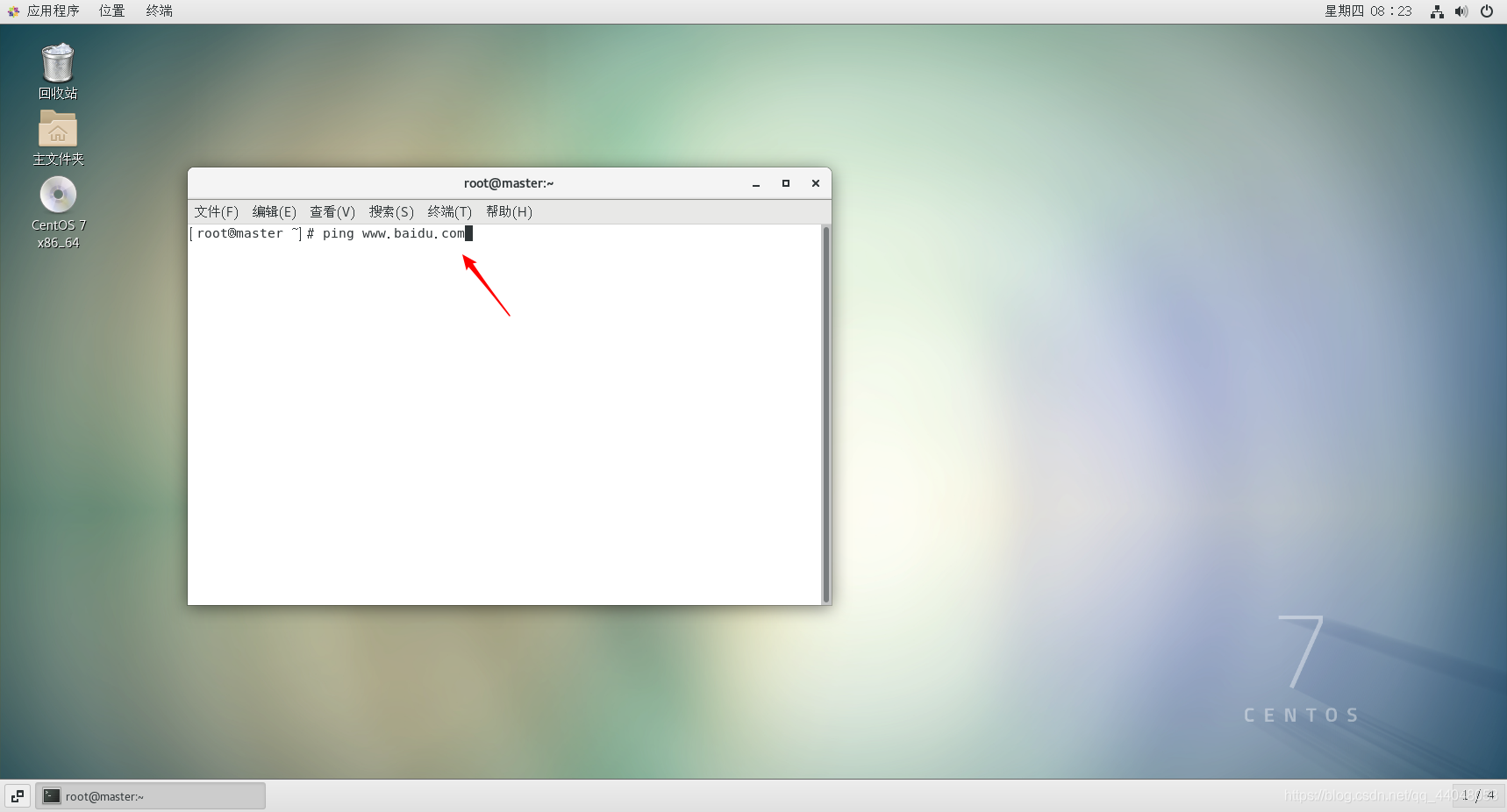
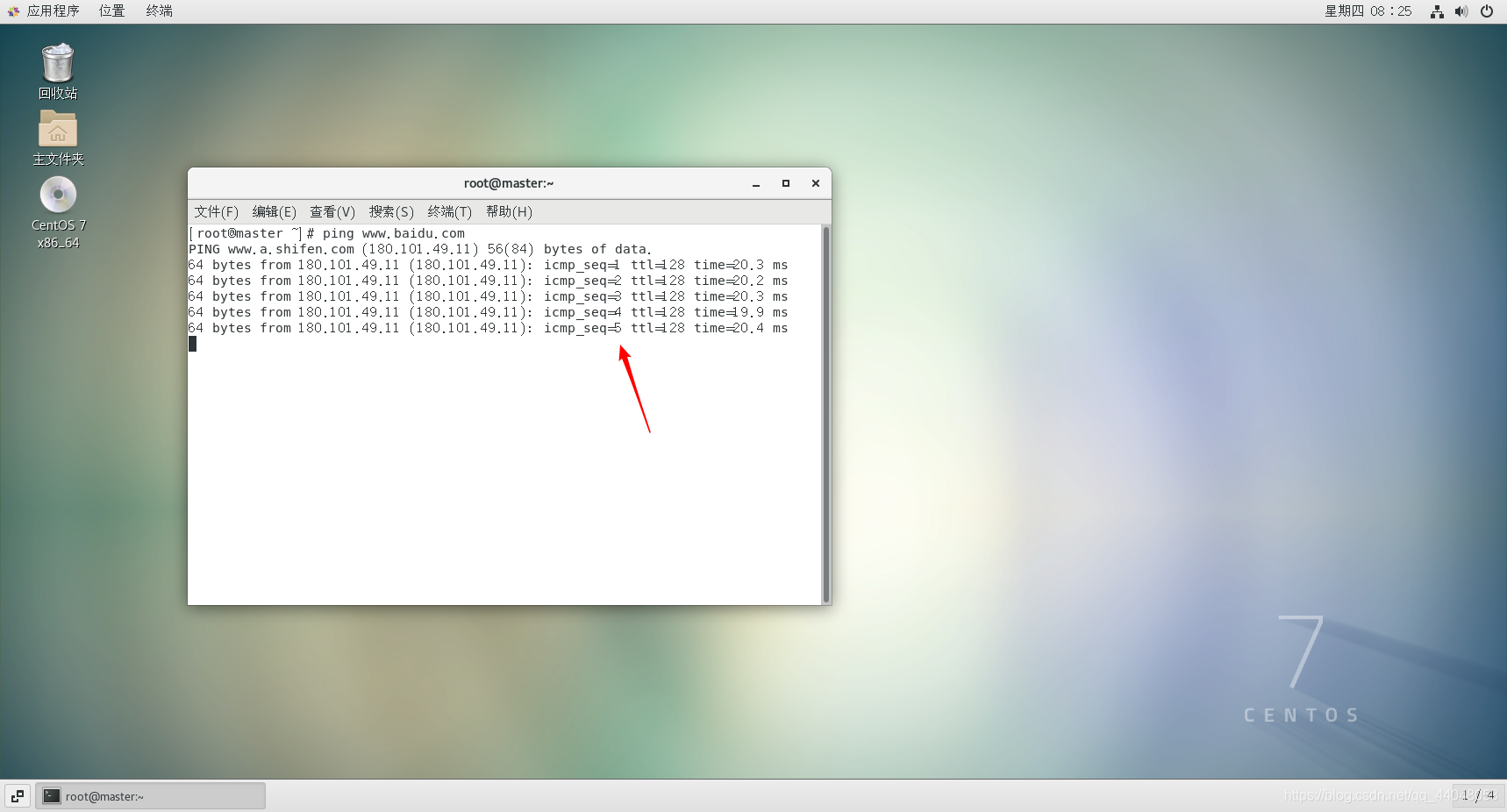
打开终端,输入以下代码,
1.进入相应目录
cd /etc/sysconfig/network-scripts/
2.编辑要修改的文件
vi ifcfg-ens33
按 i 编辑
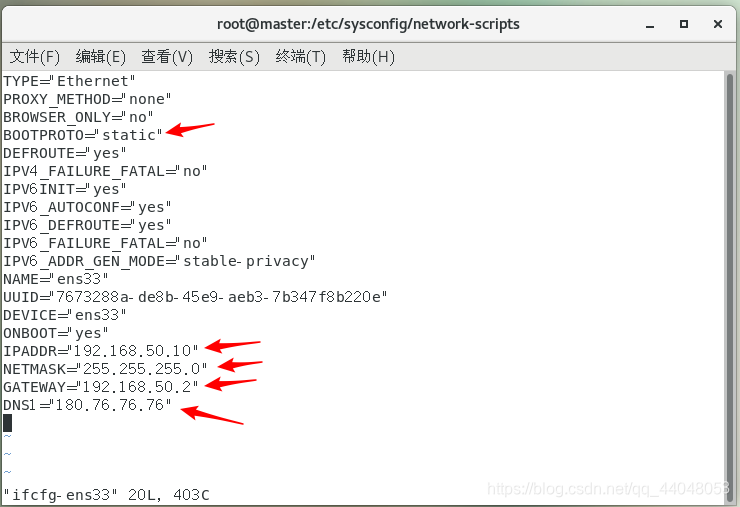
第一个改为静态,后面四个按照自己电脑的实际情况来做
IPADDR:
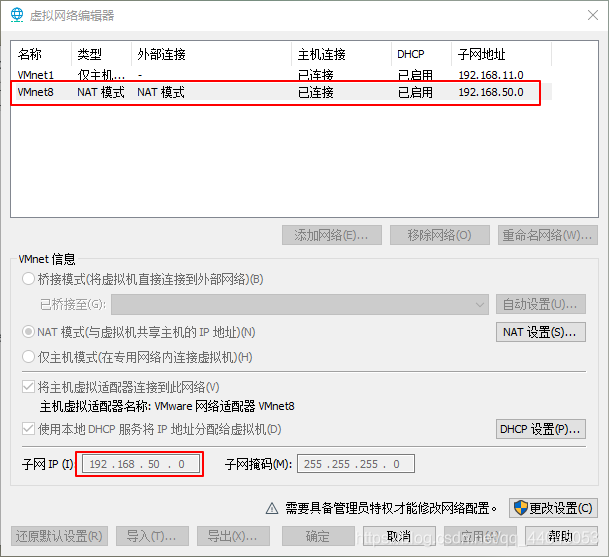
我的是192.168.50.0 , 注意最后的数字可以修改成自己喜欢的数字
我的是
主机master
IPADDR:192.168.50.10
NETMASK:
GATEWAY:
每个人的电脑都不一样
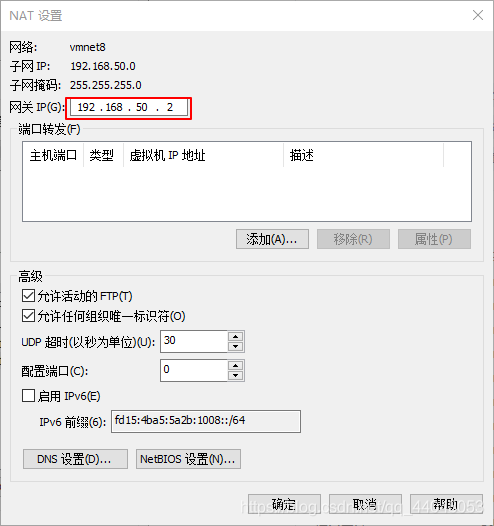
DNS1:我选择的是公用的百度DNS
180.76.76.76
全部修改好以后,按ESC退出编辑,再按 Shift + ;输入wq保存退出
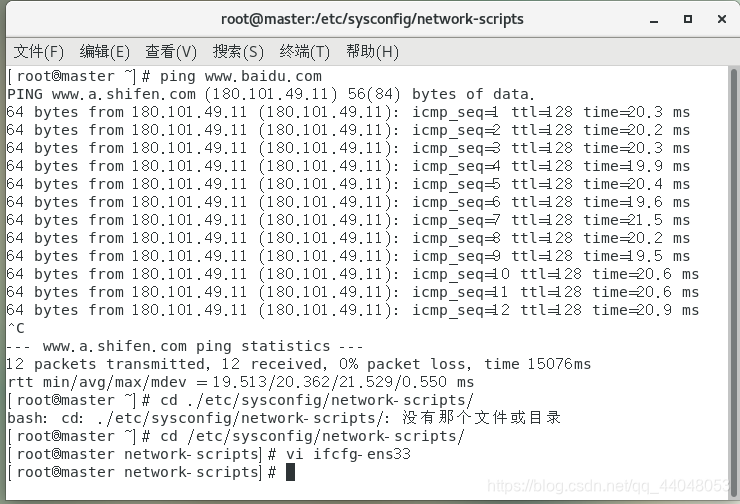
将网络服务重启
service network restart
再次测试网络连接
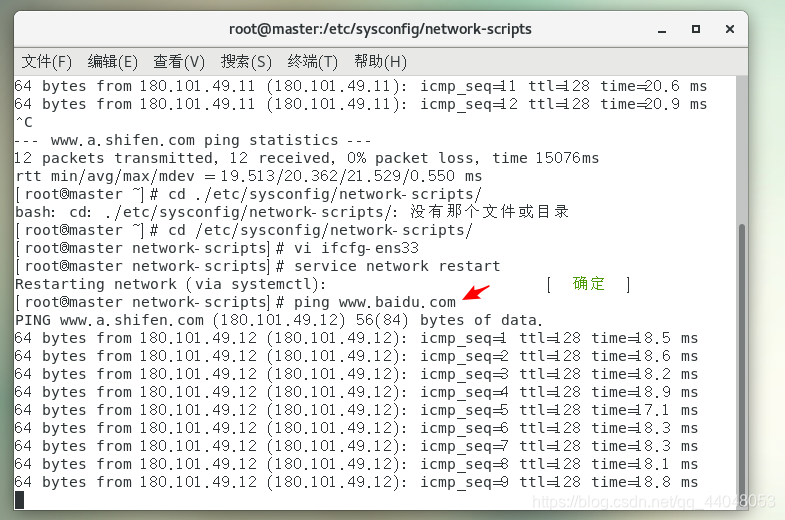
关闭并禁用防火墙
关闭
systemctl stop firewalld
禁用
systemctl stop firewalld
查看状态
systemctl status firewalld
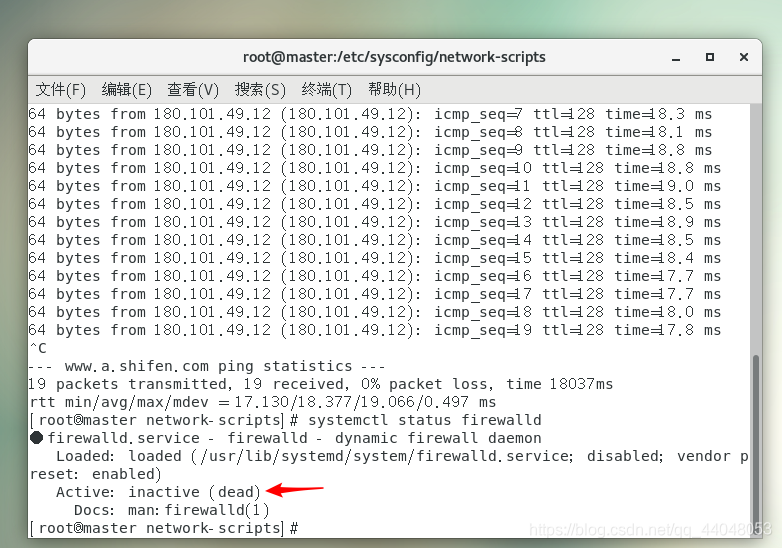
到这里,我们的静态网络配置和防火墙关闭并禁用就完成了.
s1 s2 也是同样的操作
注意!!!
在 IPADDR 最后一个数字组中,数字要不一样,这是我的设置
master:
IPADDR:192.168.50.10
s1:
IPADDR:192.168.50.11
s2
IPADDR:192.168.50.12
配置主机名
在终端下输入代码来改变z
master主机下:
hostnamectl set-hostname master
hostnamectl set-hostname s1
hostnamectl set-hostname s2
名字已经改变了。
编辑host文件
在终端输入以下代码
vi /etc/hosts
ip地址填入上面配置好的IPADDR,后面跟着主机名。
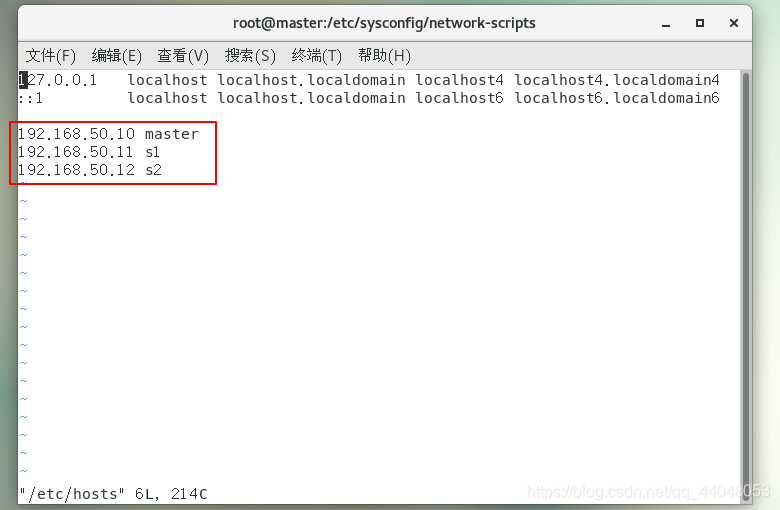
测试连接(输入ip地址也可以,这里是可以输入从机的名字也可以连接)
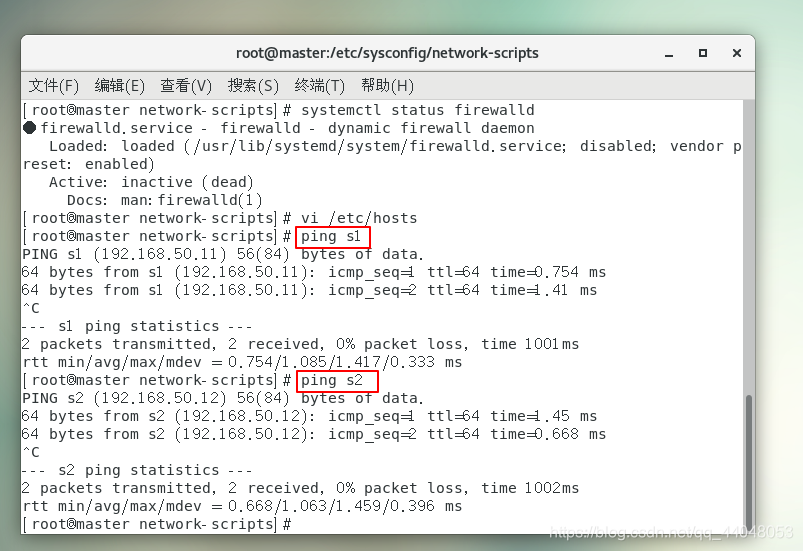
host配置完成
使用ssh传输文件
打开 shell

新建连接
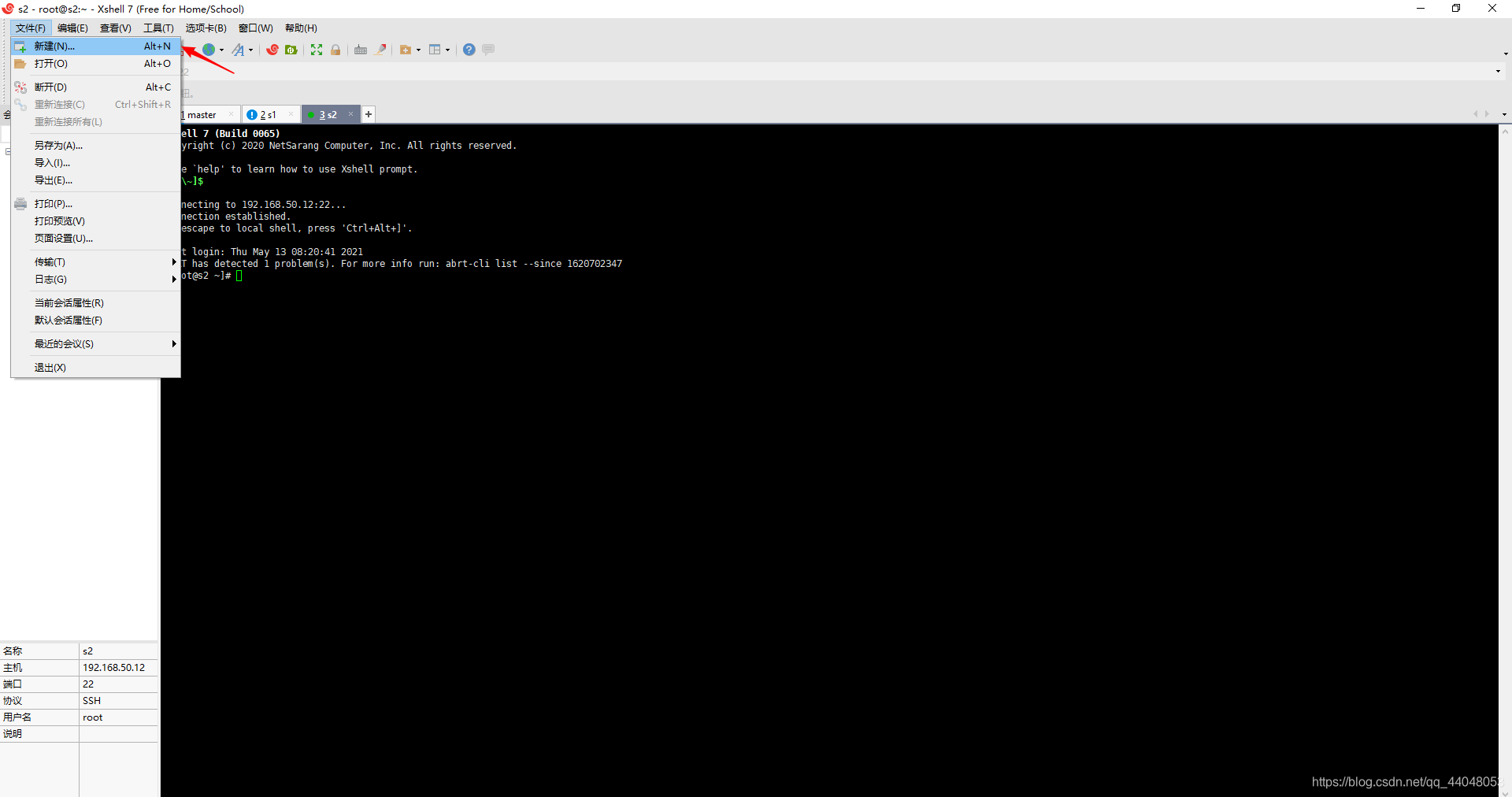
主机输入master 从机输入s1或者s2。
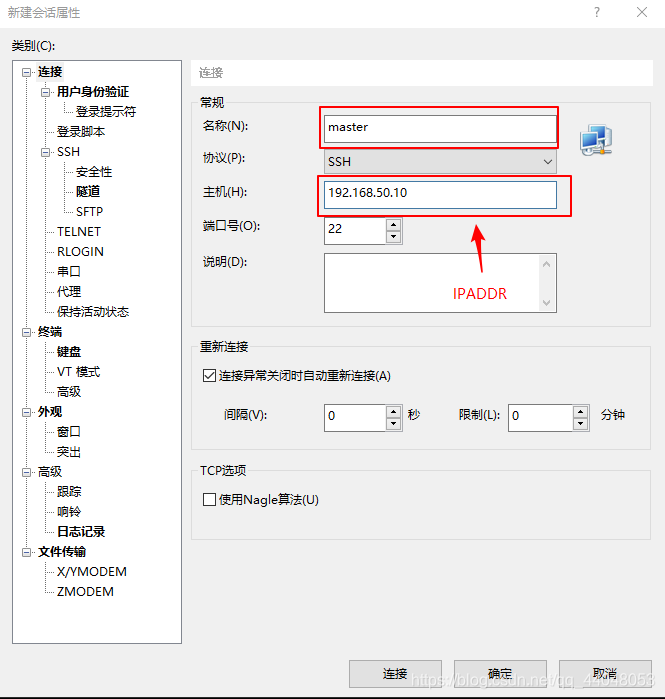
点击连接后,输入用户名,将记住用户勾选。
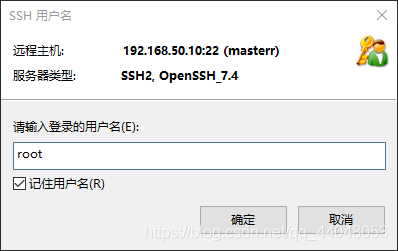
输入密码,记得勾选记住密码。
连接完成,s1,s2同样的操作。
在xshell界面输入
rz
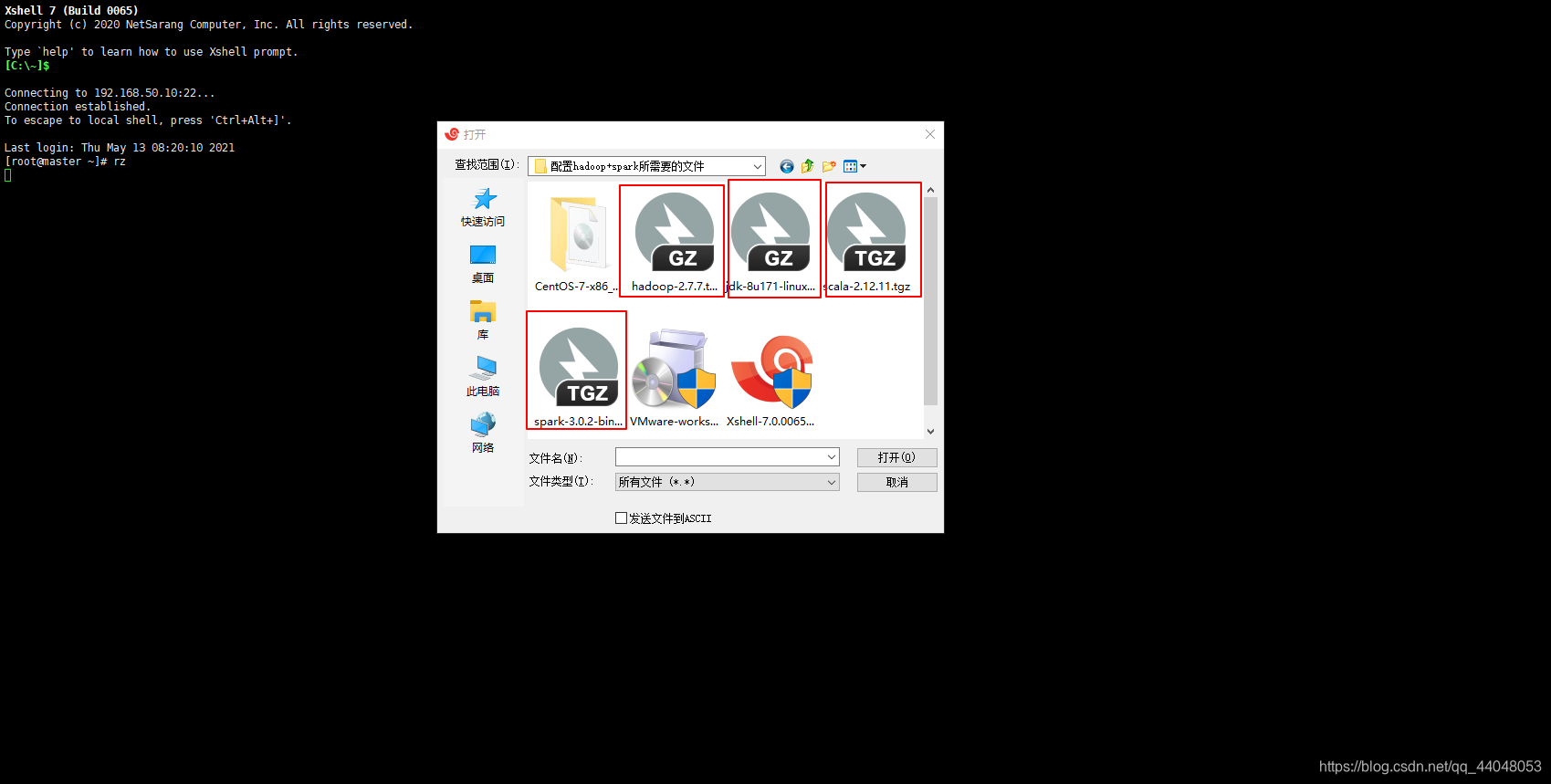
把四个文件传入虚拟机master中
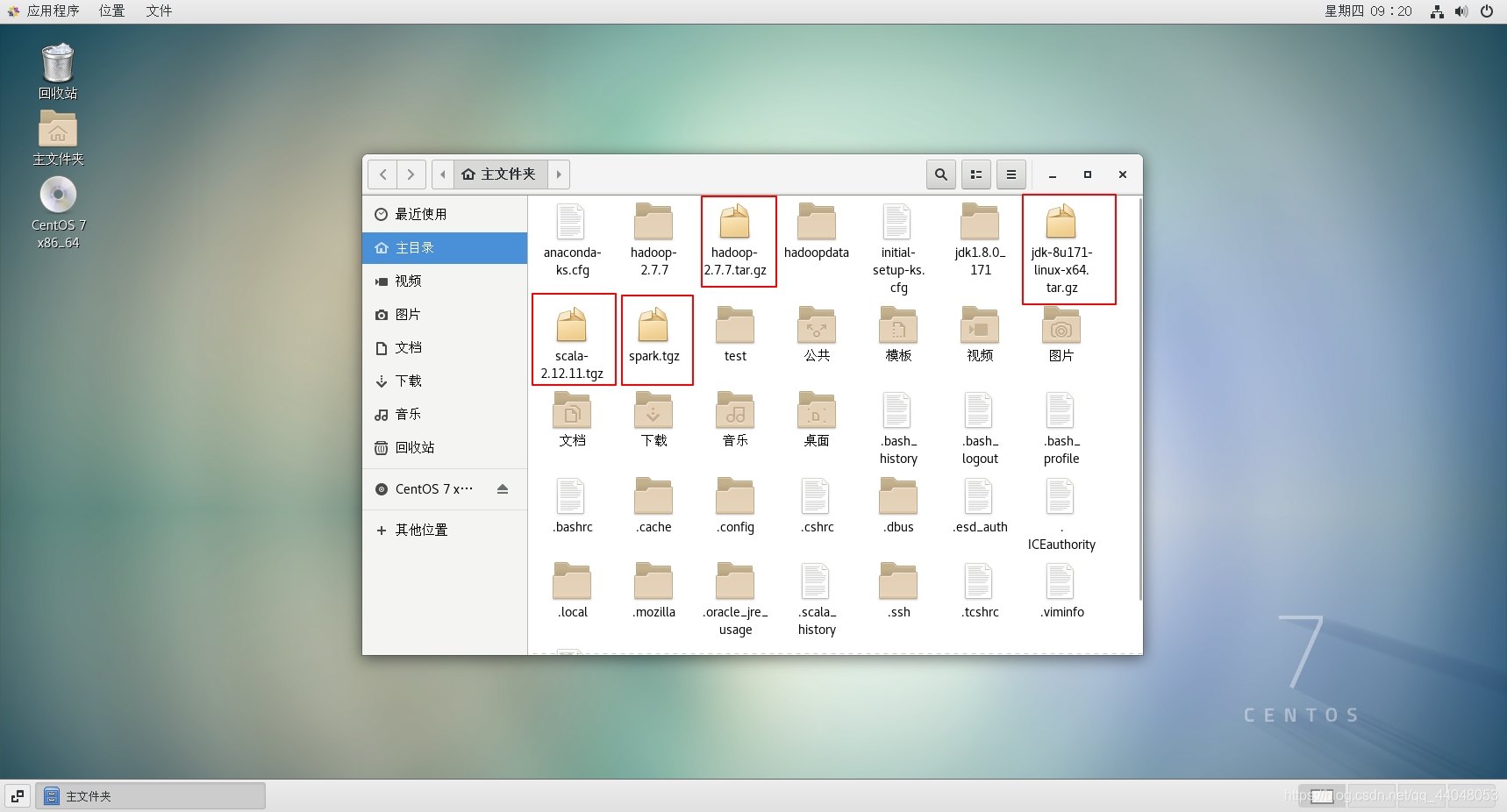
文件传输完毕
SSH免密配置
在主文件夹下进入 .shh 文件夹(ctrl + h显示隐藏文件)没有自己新建(别忘了前面有个 . )
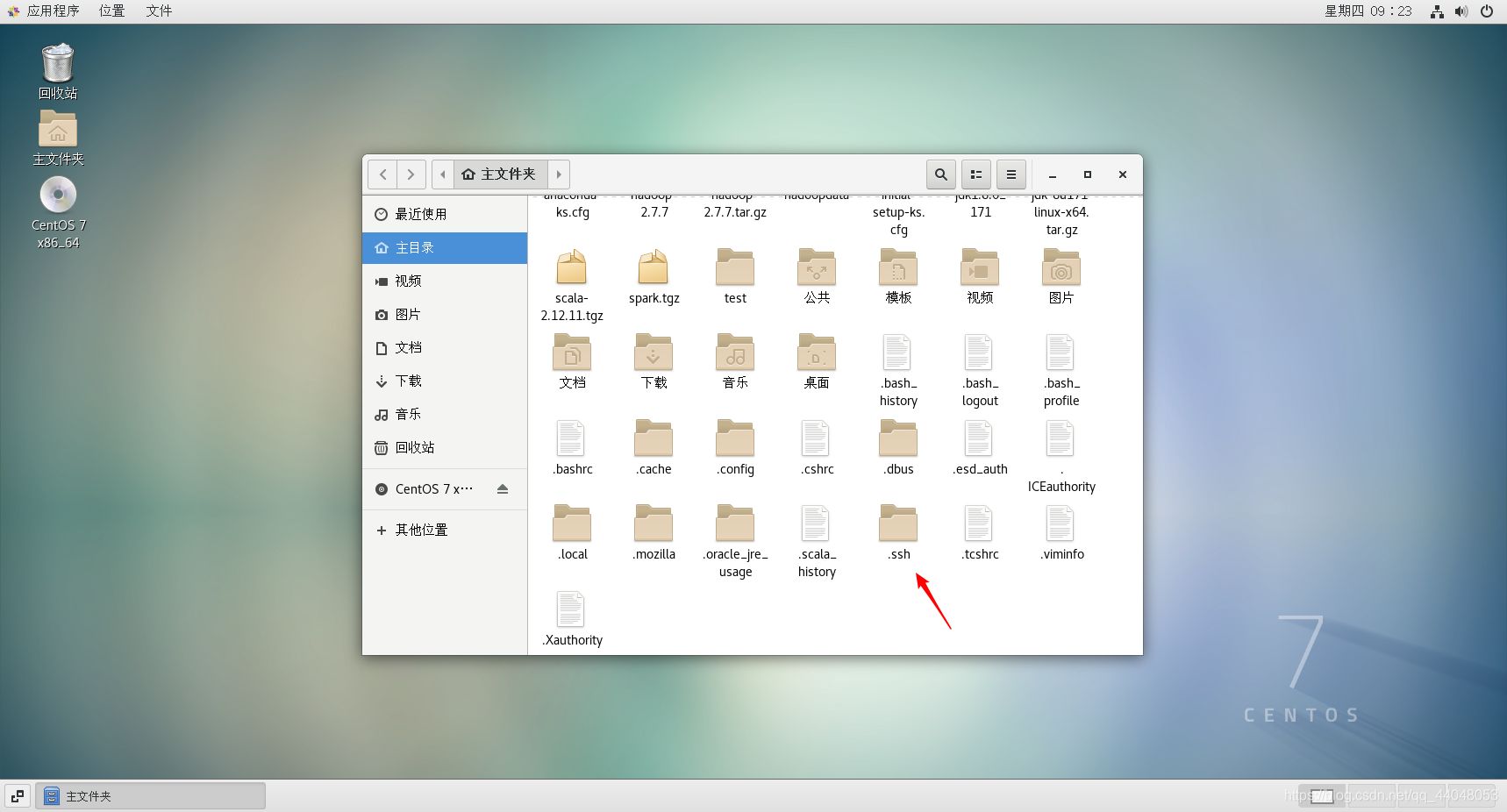
在目录下选择终端打开

输入
ssh-keygen
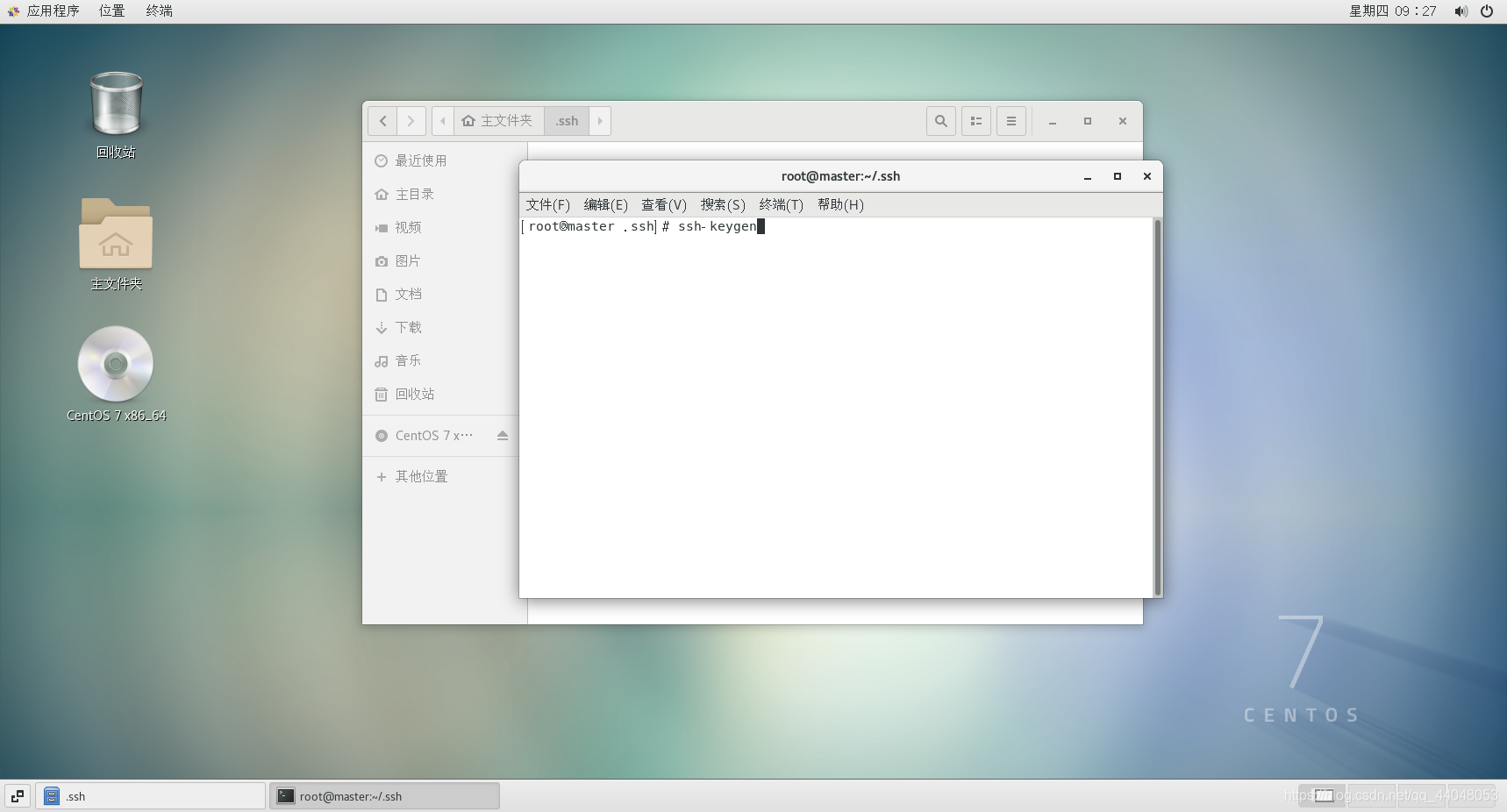
连续按三次回车
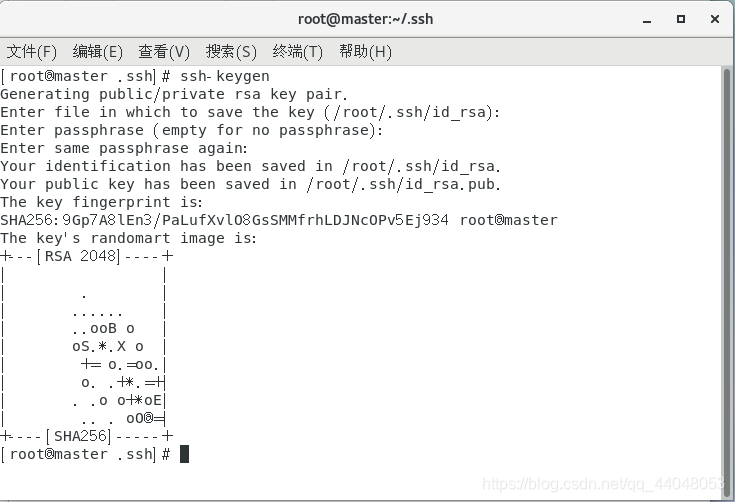
.ssh目录下有了文件
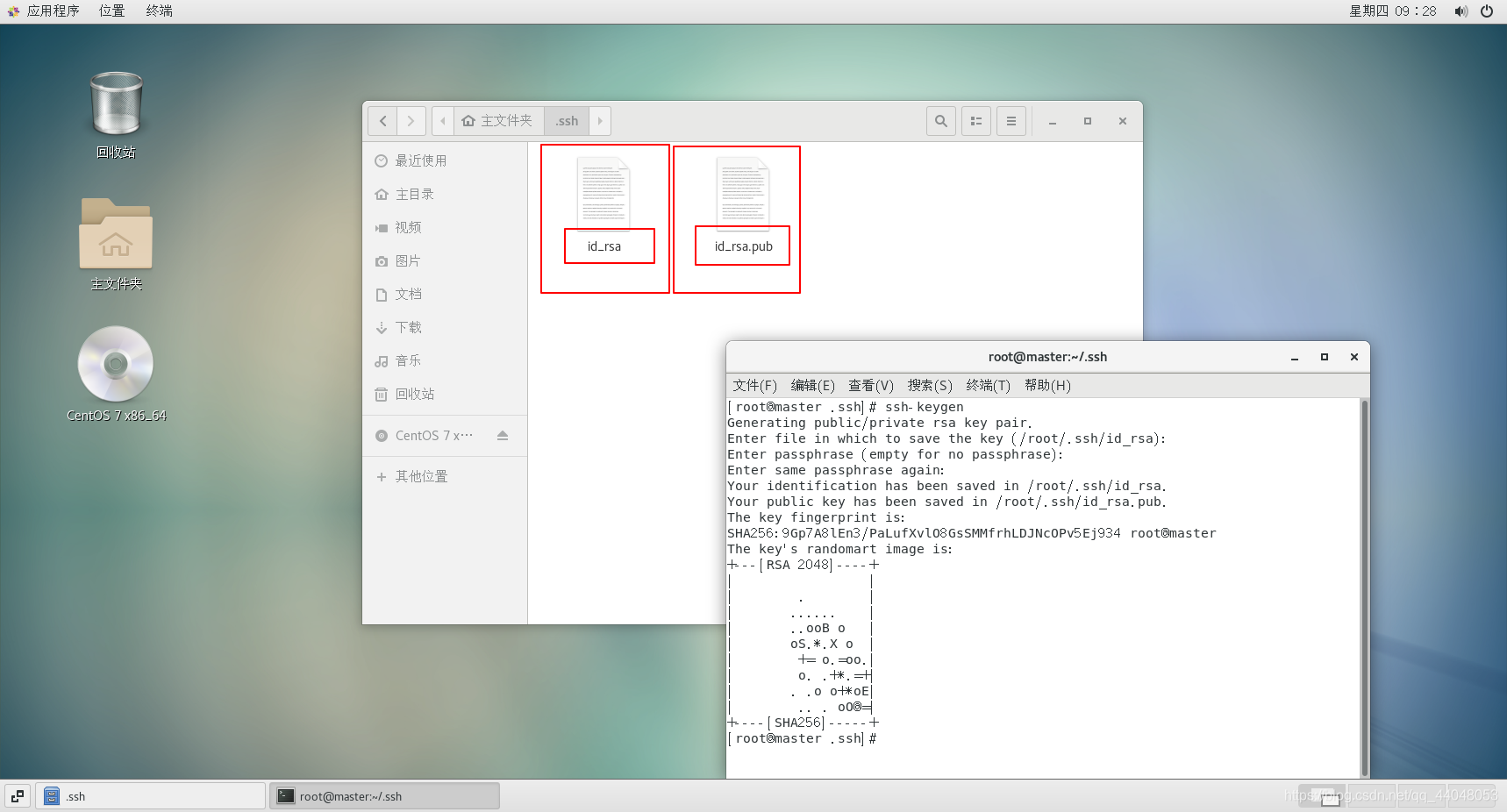
把 密钥拷贝到其他的从机和自己的主机
ssh-copy-id master
ssh-copy-id s1
ssh-copy-id s2
别的从机就可以免密登录主机master
同理,其他两台从机也是依法炮制
测试登录
ssh master
ssh s1
ssh s2
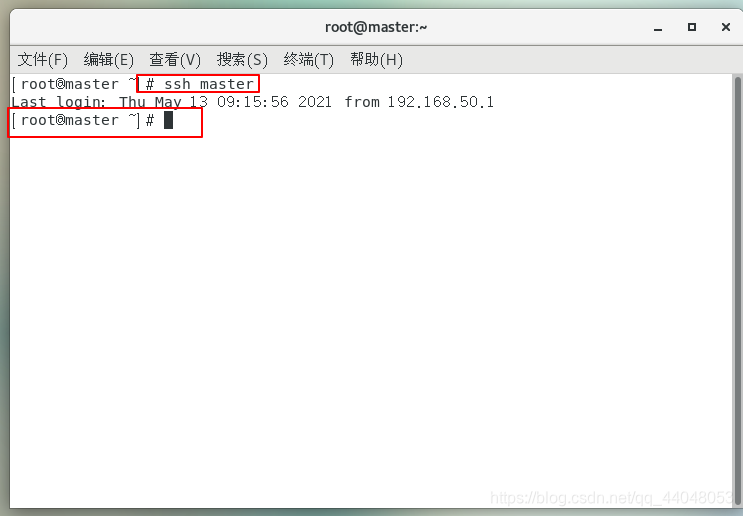
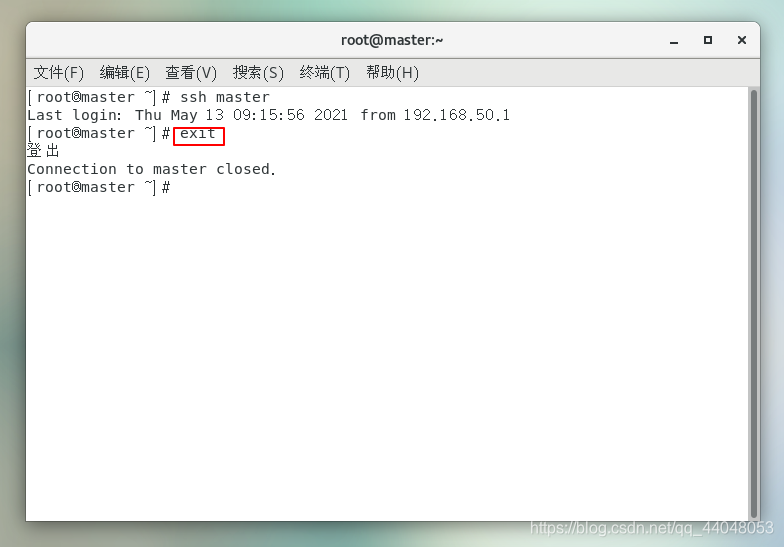
输入 exit 登出(最好三台虚拟机都测试以下以防万一)
解压文件

tar -xzvf hadoop-2.7.7.tar.gz
解压四个文件
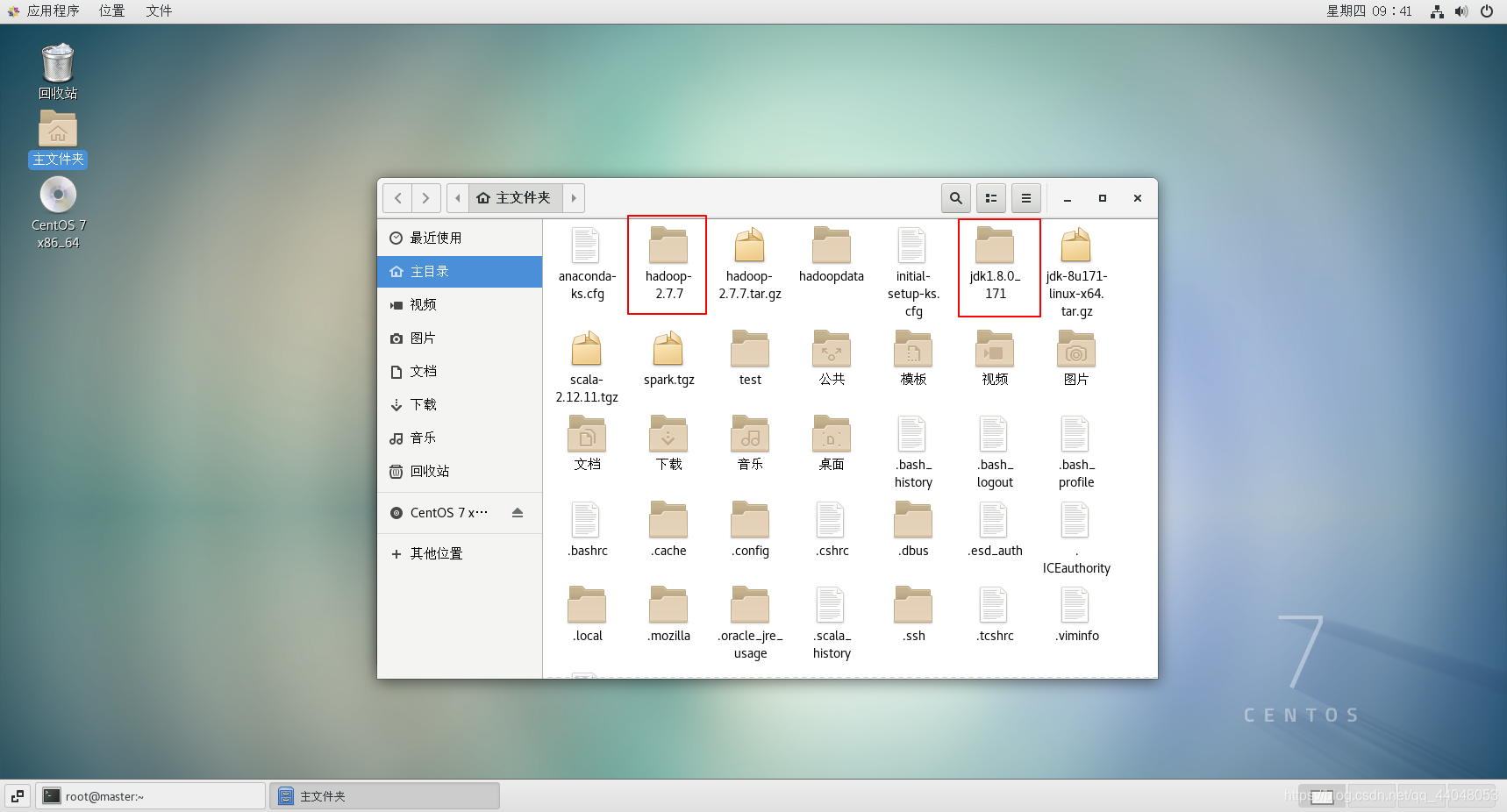
scala 和 spark 我解压在hadoop里(我对这两个解压的文件夹进行了重命名)
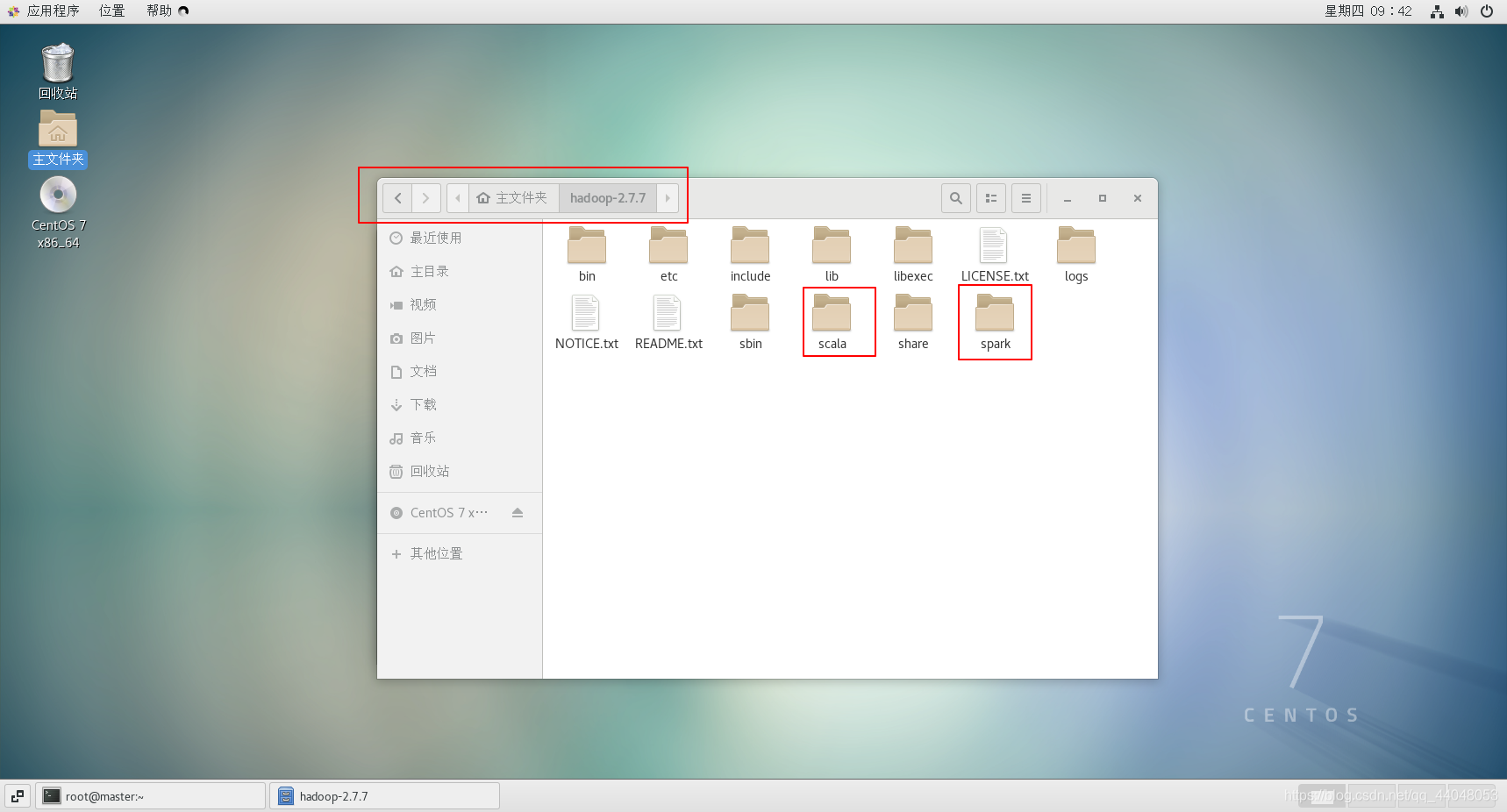
配置文件
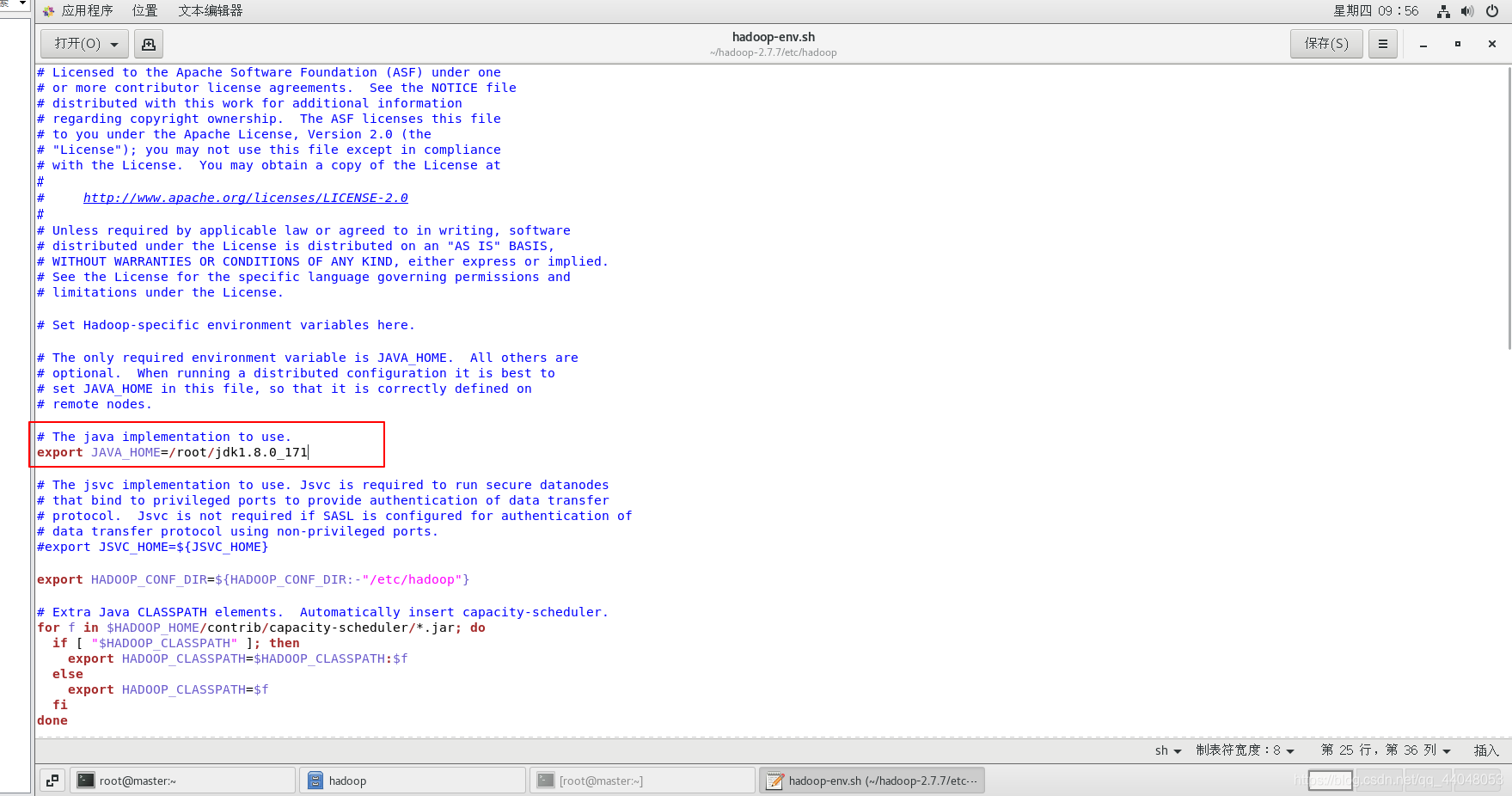
配置JDK
重新打开终端,输入
vim .bash_profile
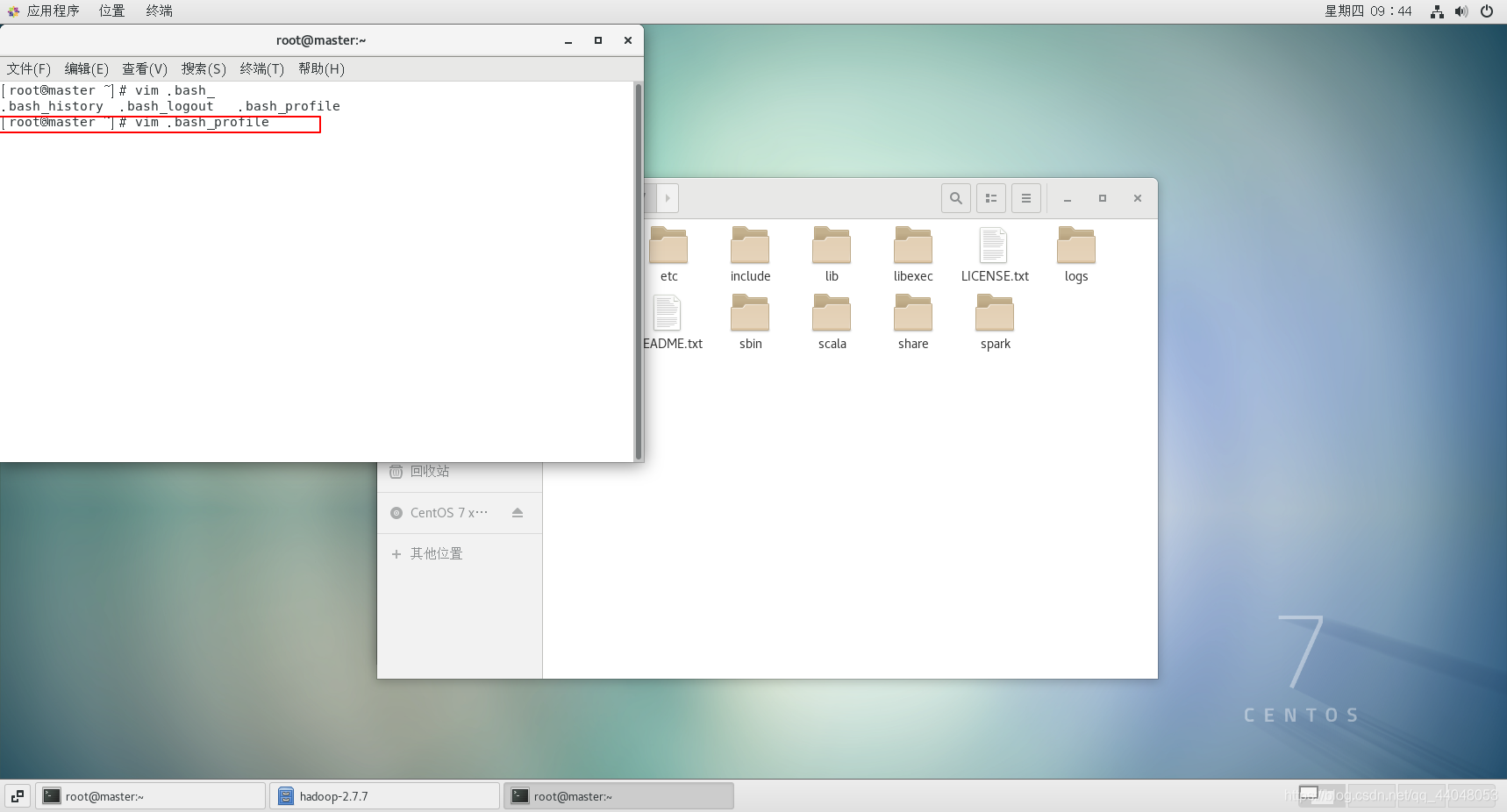
按照下图修改
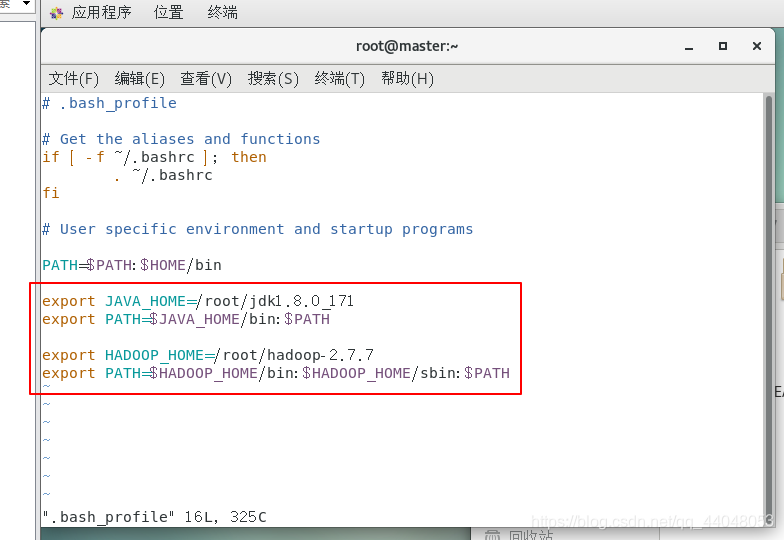
export JAVA_HOME=/root/jdk1.8.0_171
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/root/hadoop-2.7.7
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
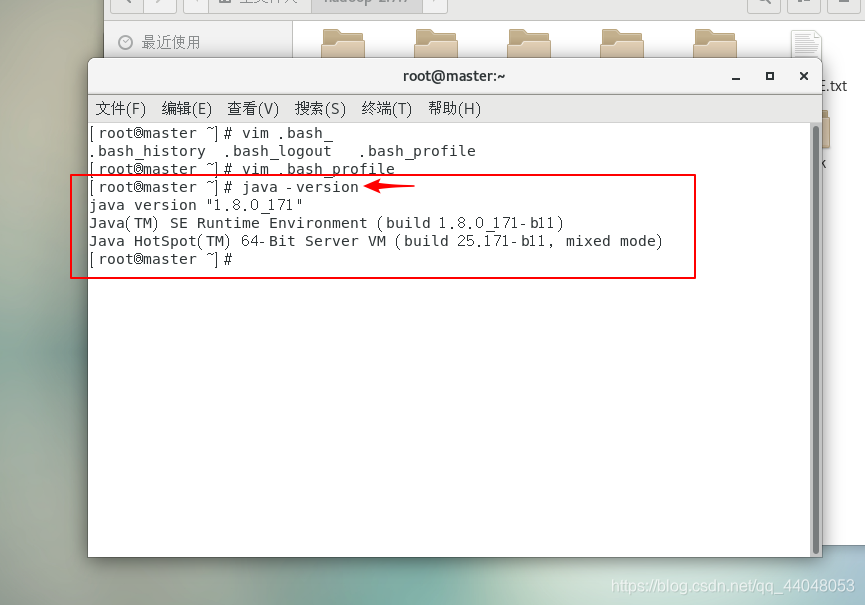
保存并退出,测试是否正确安装了JDK
将JDK复制给s1 s2 ,并按照上面的步骤对s1 s2配置 .bash_profile,验证s1,s2是否正确安装JDK
scp -r 复制的文件名 root@s1:~/
scp -r jdk1.8.0.171 root@s1:~/
配置hadoop中的文件
进入目录
修改文件
使用绝对路径稳一点
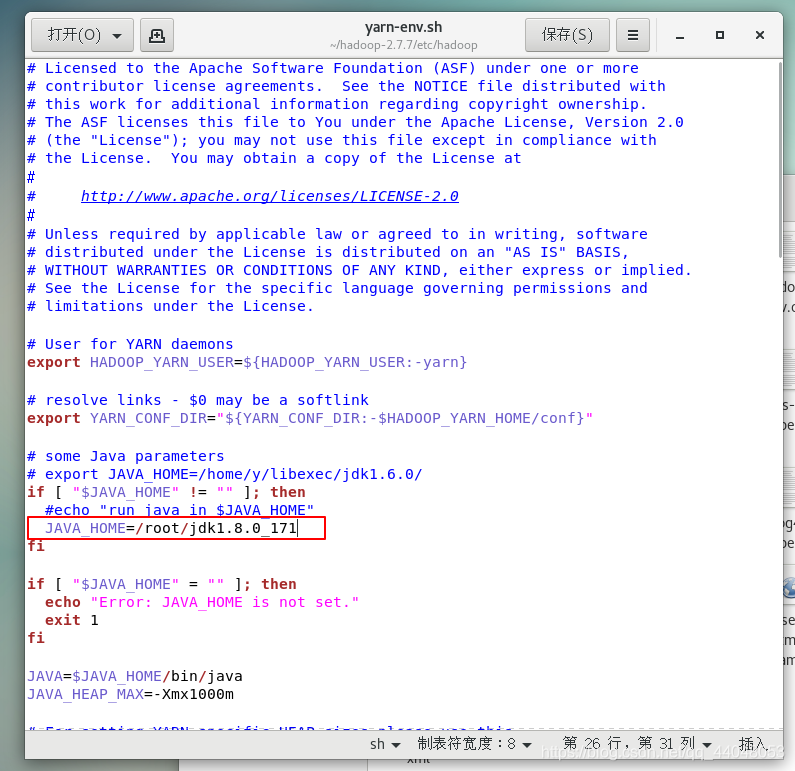
export JAVA_HOME=/root/jdk1.8.0_171
保存退出
修改文件
修改文件
在下添加以下代码
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoopdata</value>
</property>
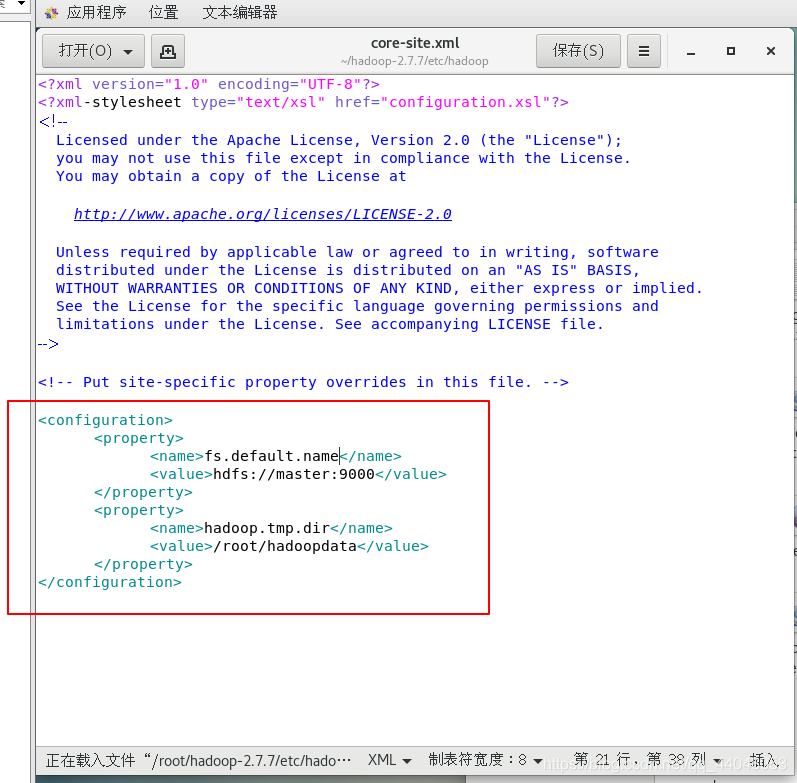
保存退出
修改文件
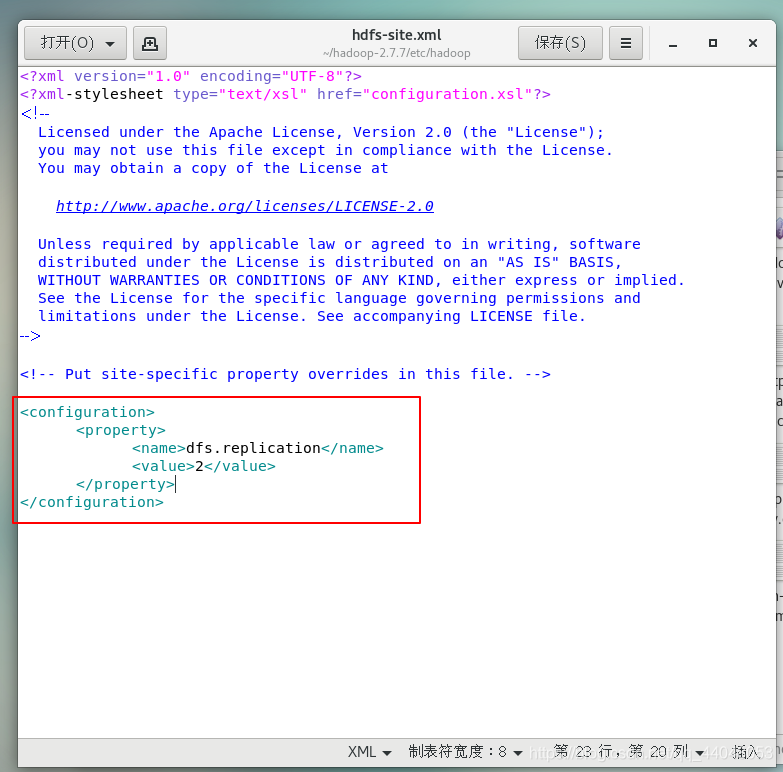
添加
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
修改文件(后面有.template的把它删了)
添加
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
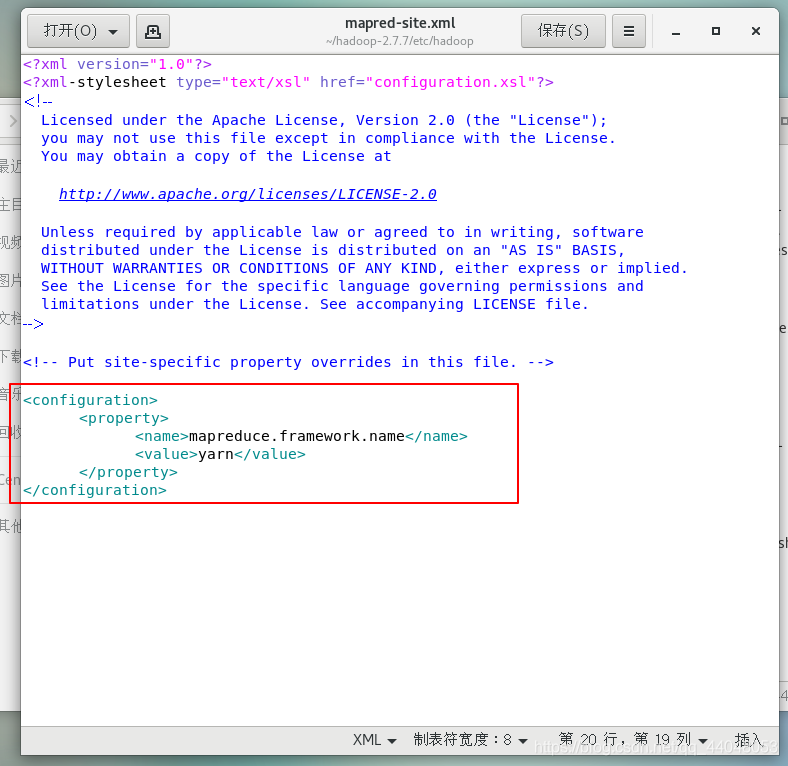
保存退出
修改文件
输入
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
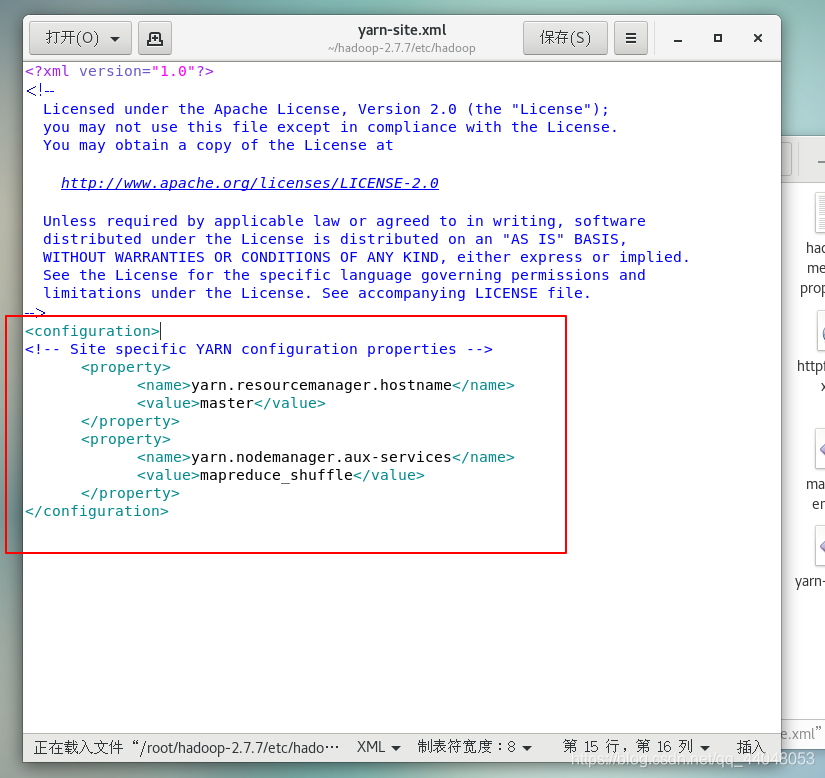
保存退出
修改文件
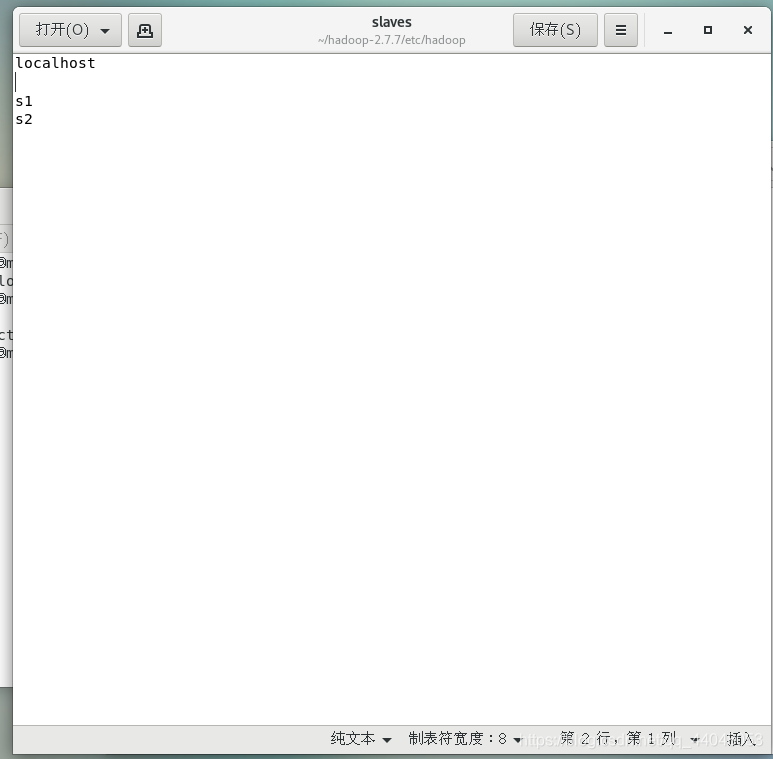
保存退出
配置spark文件
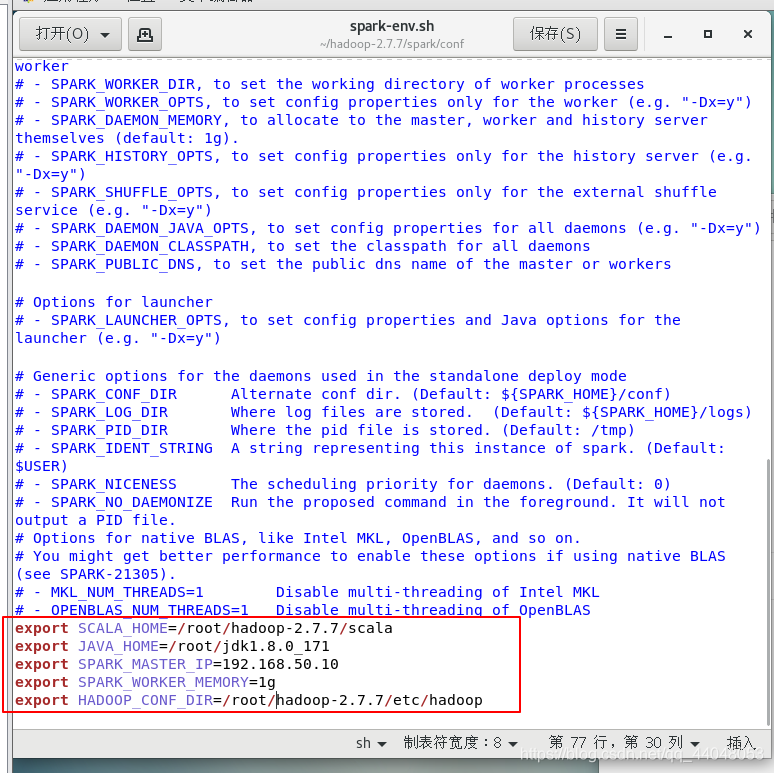
添加(注意ip是你的主机ip)
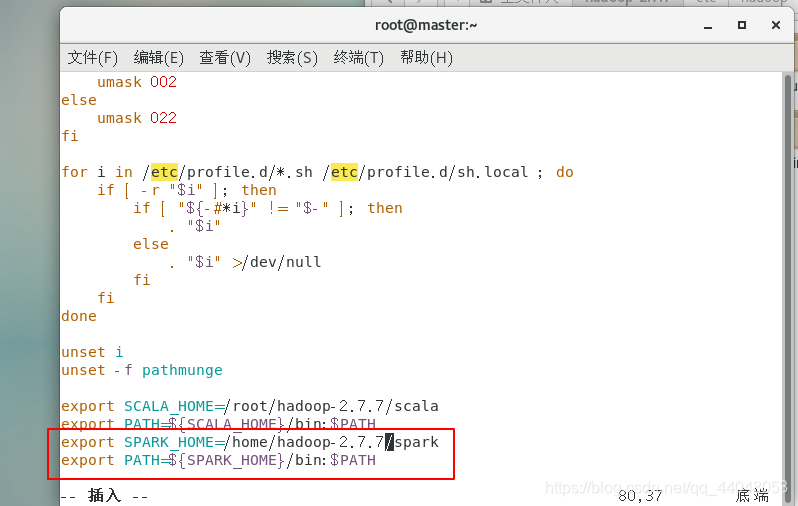
export SCALA_HOME=/root/hadoop-2.7.7/scala
export JAVA_HOME=/root/jdk1.8.0_171
export SPARK_MASTER_IP=192.168.50.10
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/root/hadoop-2.7.7/etc/hadoop
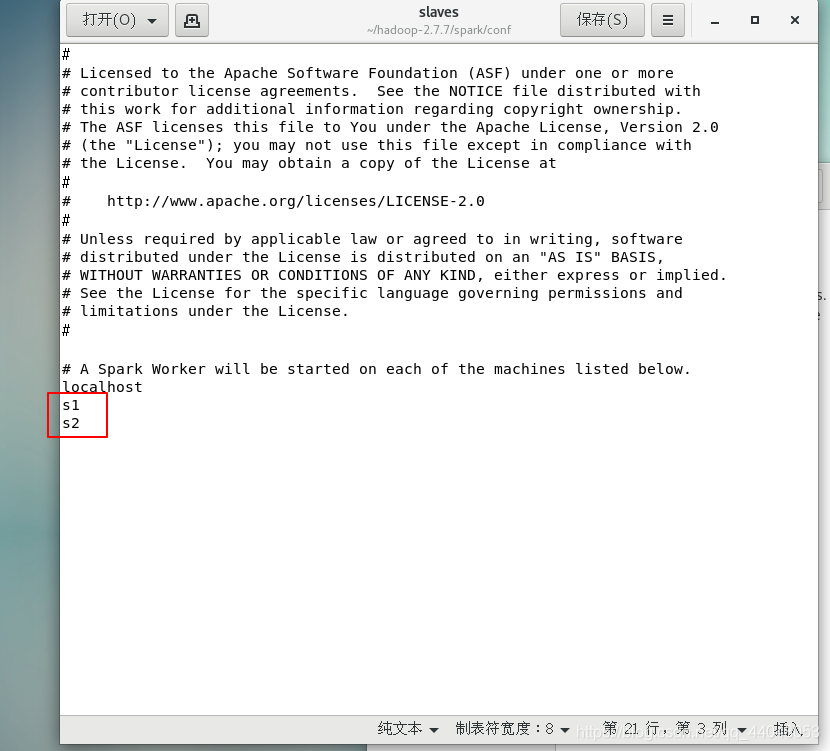
添加节点信息
把整个hadoop-2.7.7拷贝到s1和s2中
scp -r hadoop-2.7.7 s1:~/
scp -r hadoop-2.7.7 s2:~/
配置scala、spark和hadoop环境变量(s1和s2也要)
在前面我们已经把scala解压到hadoop下

在桌面重新打开终端,输入
vim /etc/profile
输入
export SCALA_HOME=/root/hadoop-2.7.7/scala
export PATH=${SCALA_HOME}/bin:$PATH
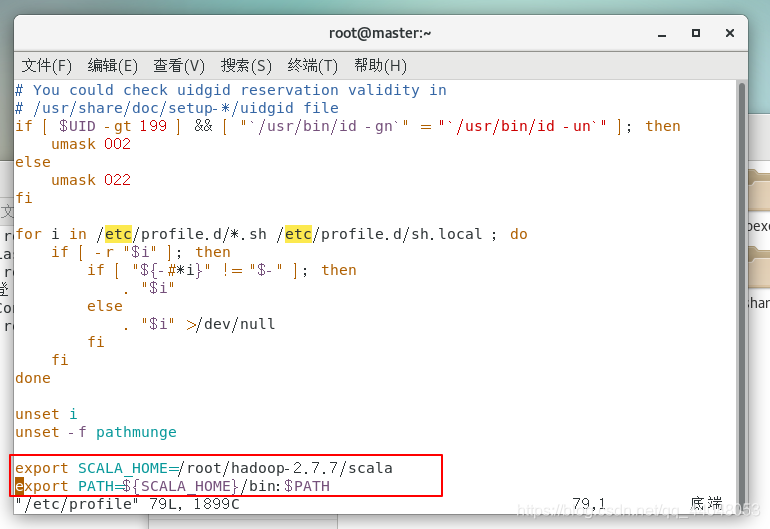
保存退出
在控制台重新载入配置
source /etc/profile
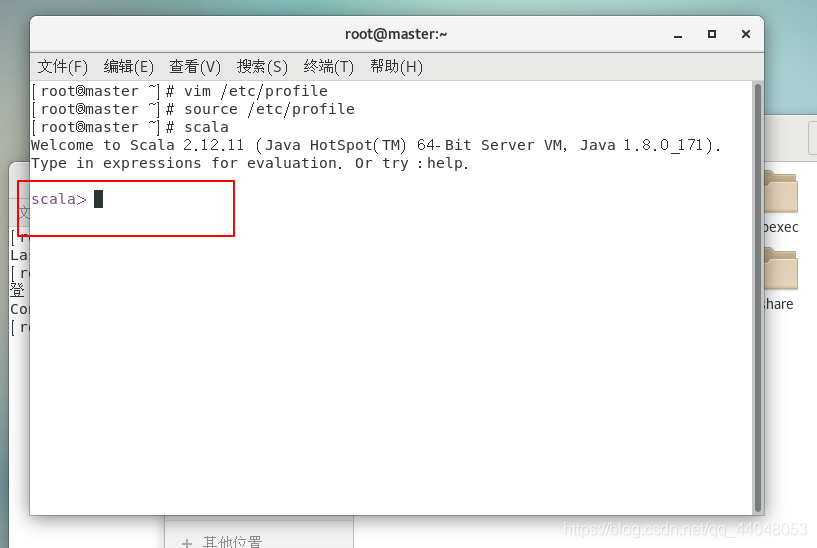
测试是否成功
scala
配置spark环境变量
在终端输入
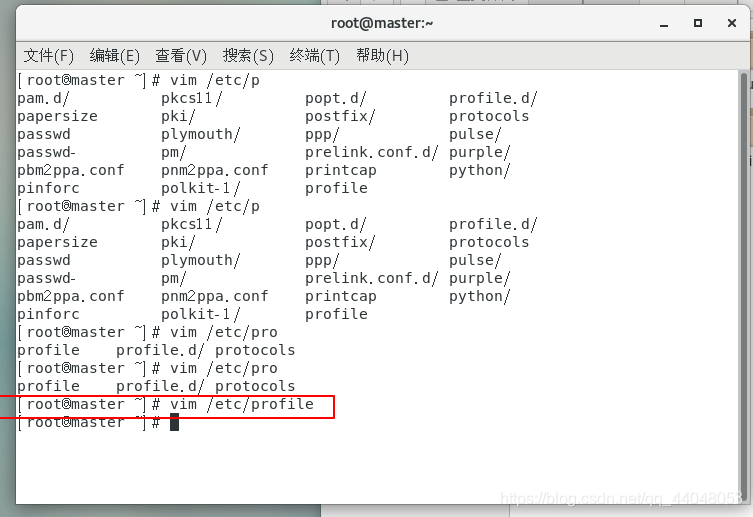
添加spark环境变量
保存退出
添加hadoop环境变量
vim .bash_profile

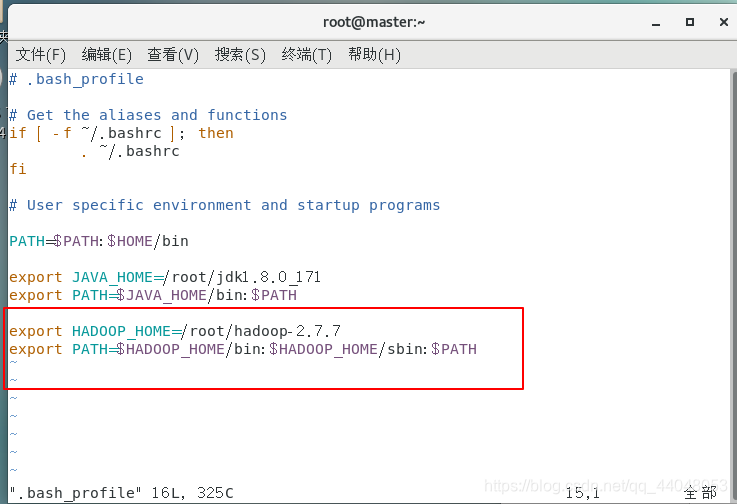
保存退出
重新载入配置文件
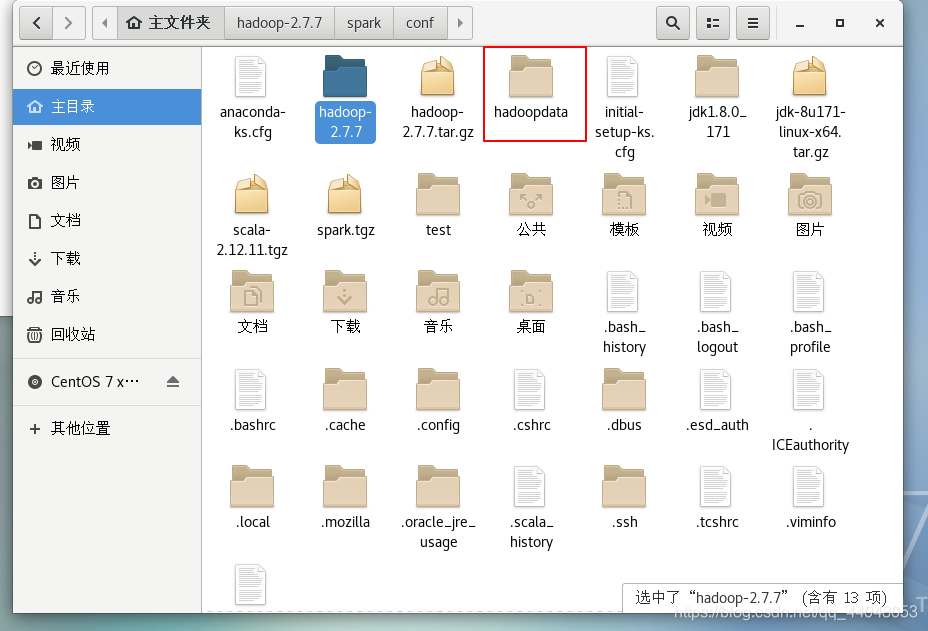
在hadoop,s1,s2下新建文件夹 hadoopdata
这一节的操作s1,s2也要重复一遍
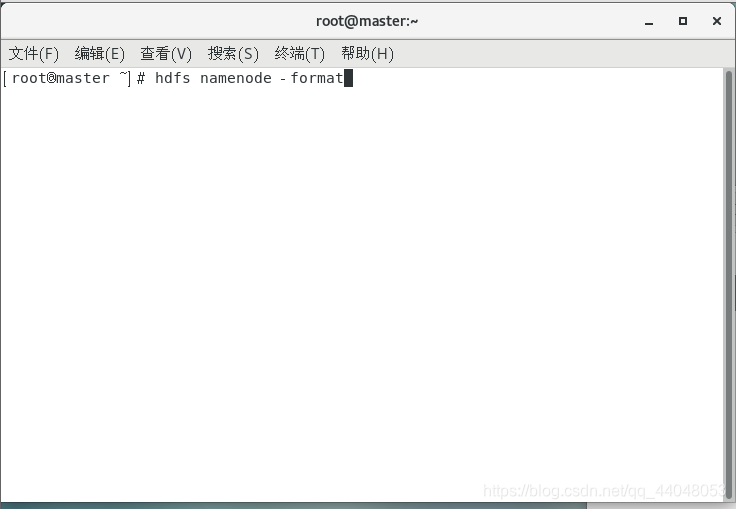
格式化hadoop(在master上进行)
hdfs namenode -format
启动hadoop&spark
启动hadoop 并运行实例
使用绝对路径来启动hadoop
/root/hadoop-2.7.7/sbin/start-all.sh
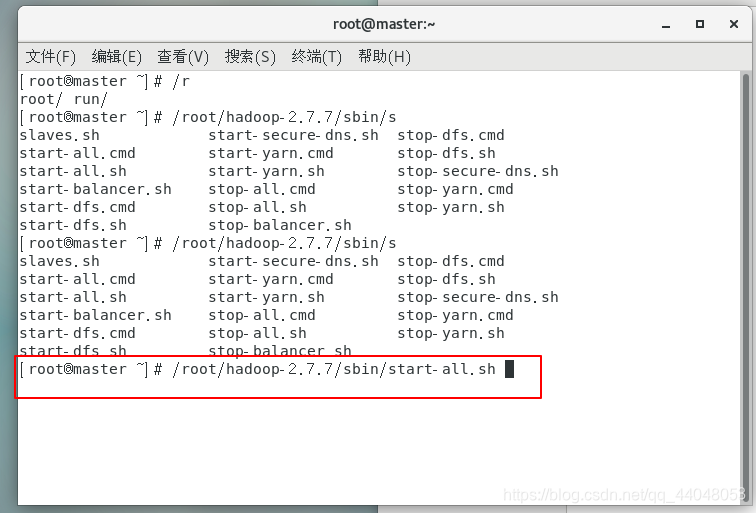
没有报错的话则启动成功
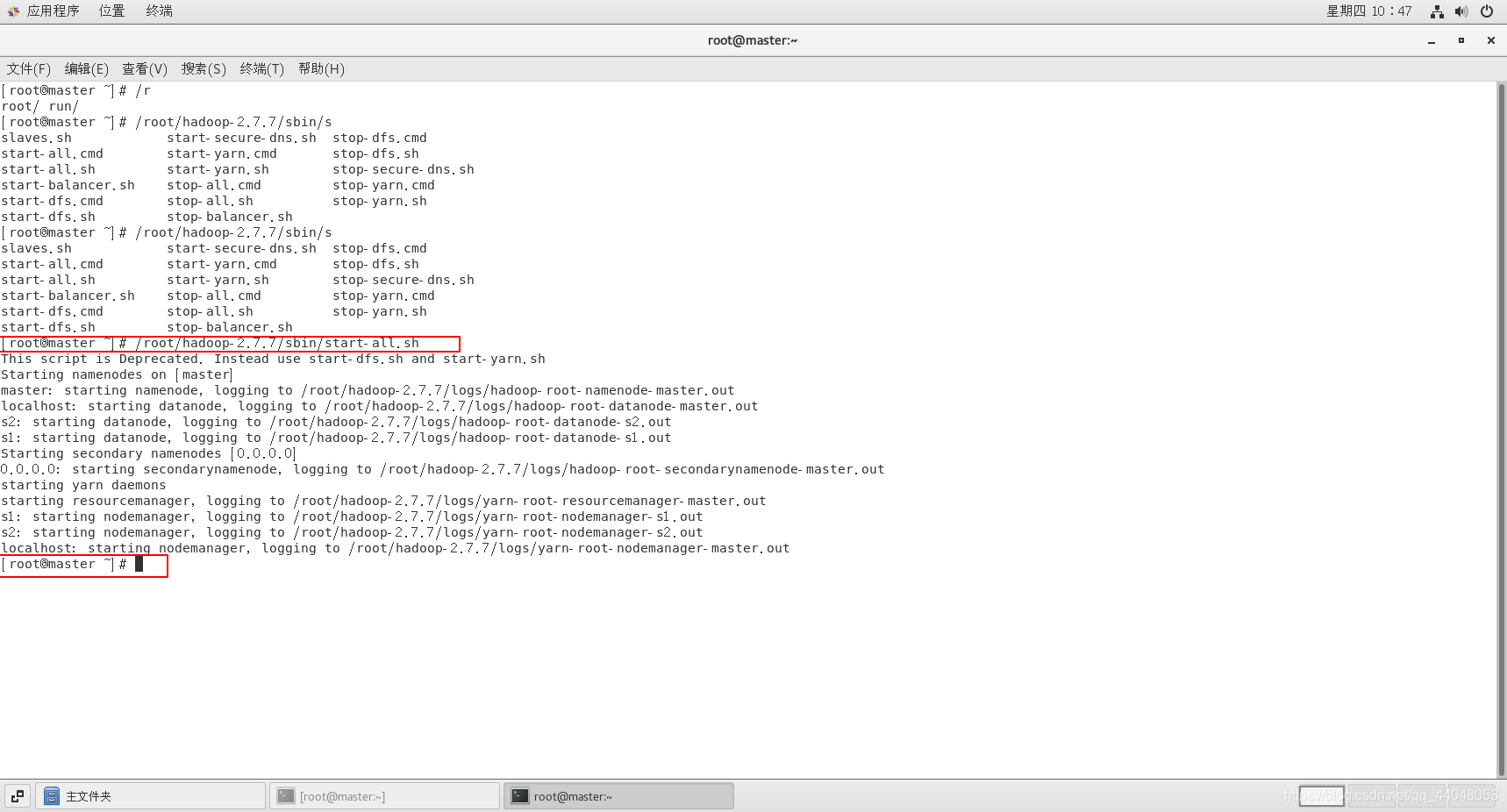
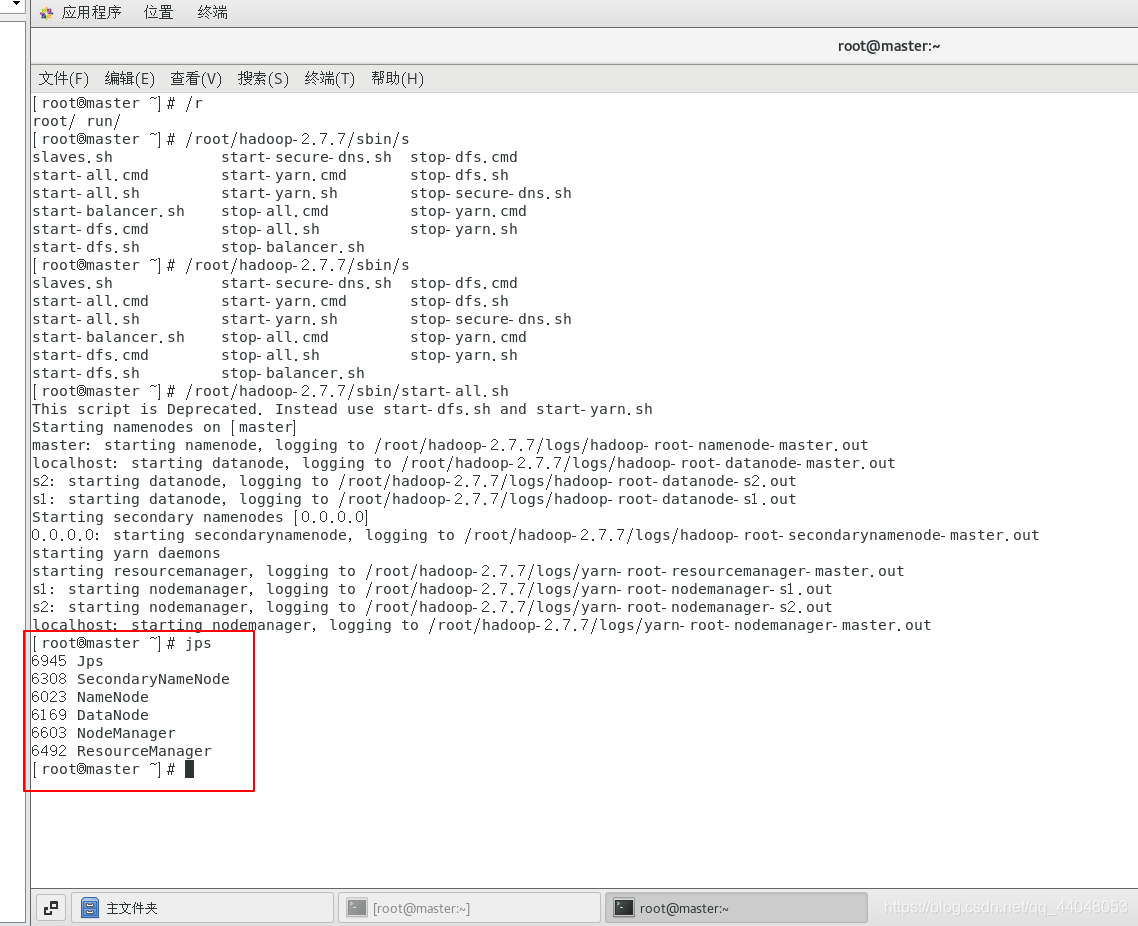
输入jps查看java接口的进程号
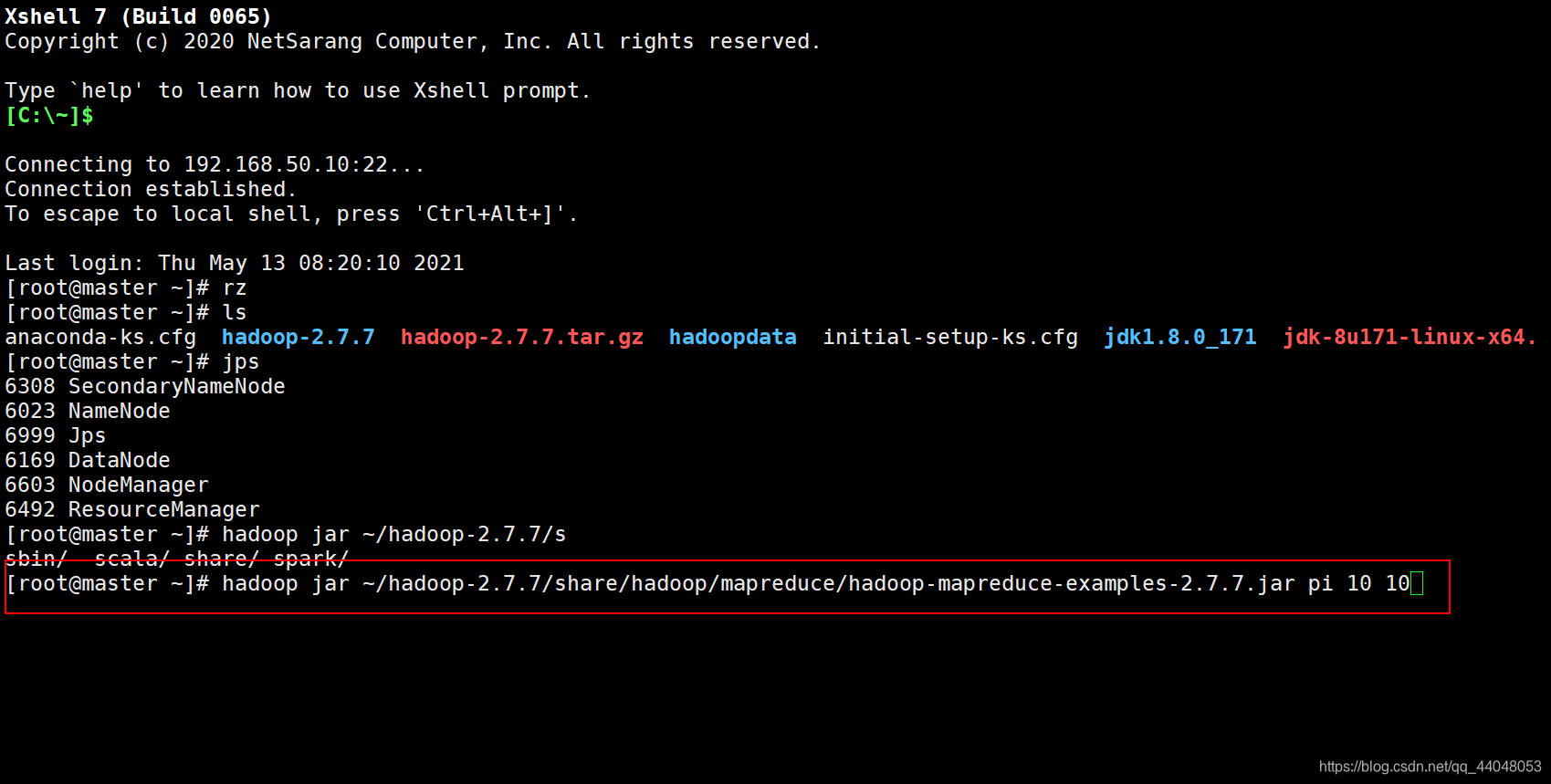
运行实例(计算PI)
打开Xshell,输入代码
hadoop jar ~/hadoop-2.7.7/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar pi 10 10
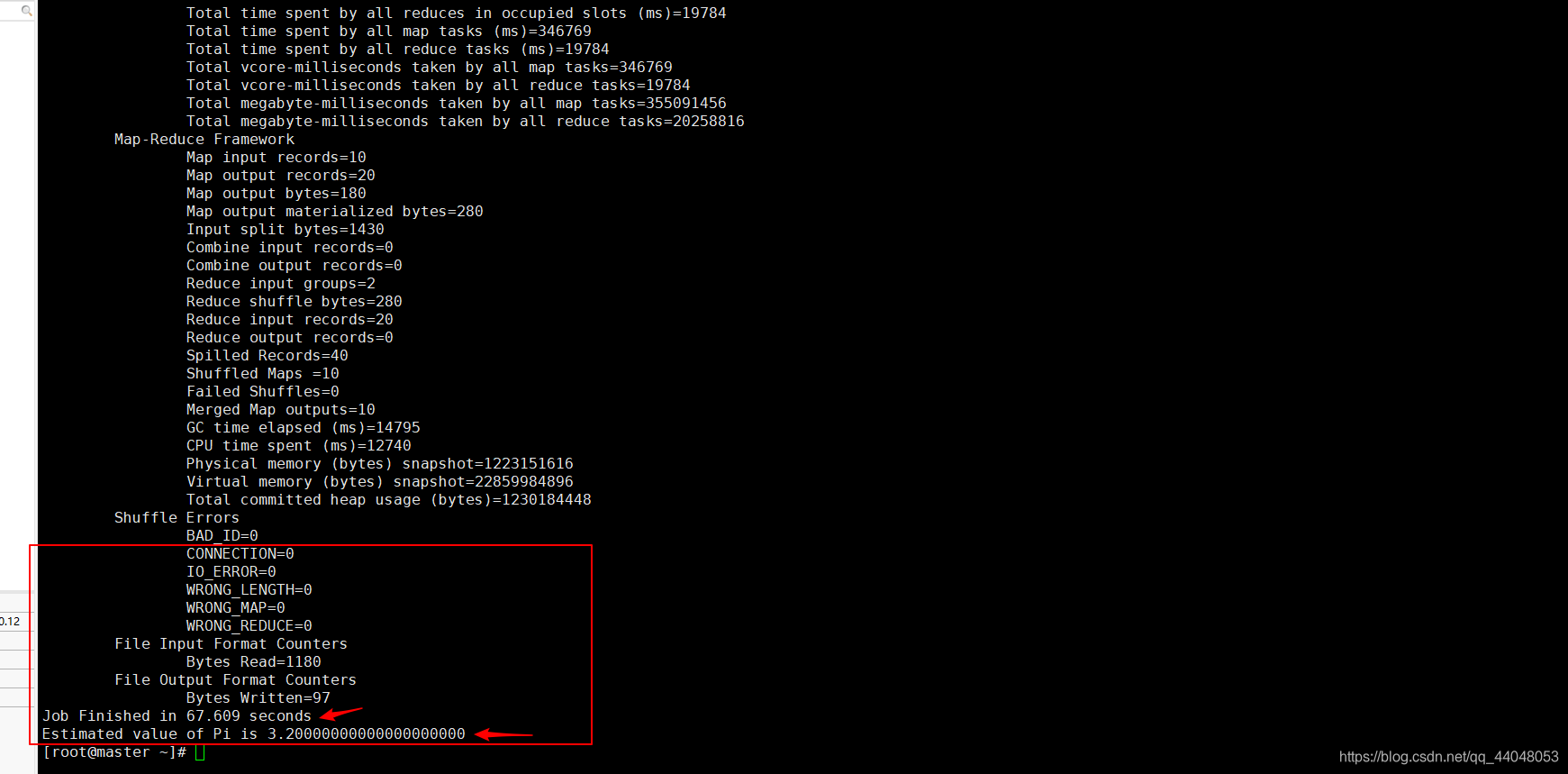
按回车,出现结果,实例运行结束,
过程大概2分钟左右
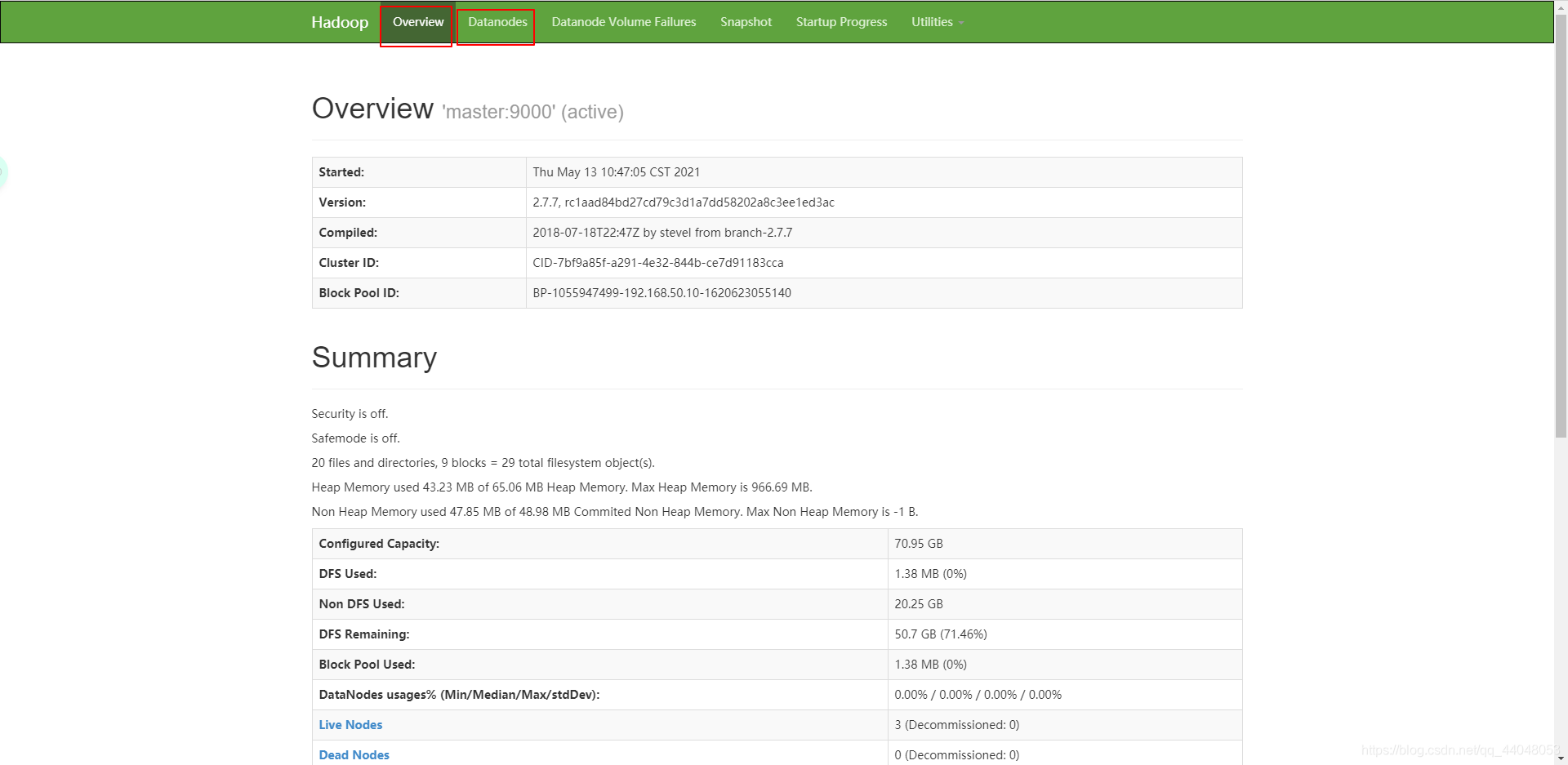
 查看hadoop启动状态
查看hadoop启动状态
点击该链接: http://192.168.50.10:50070/.
出现界面
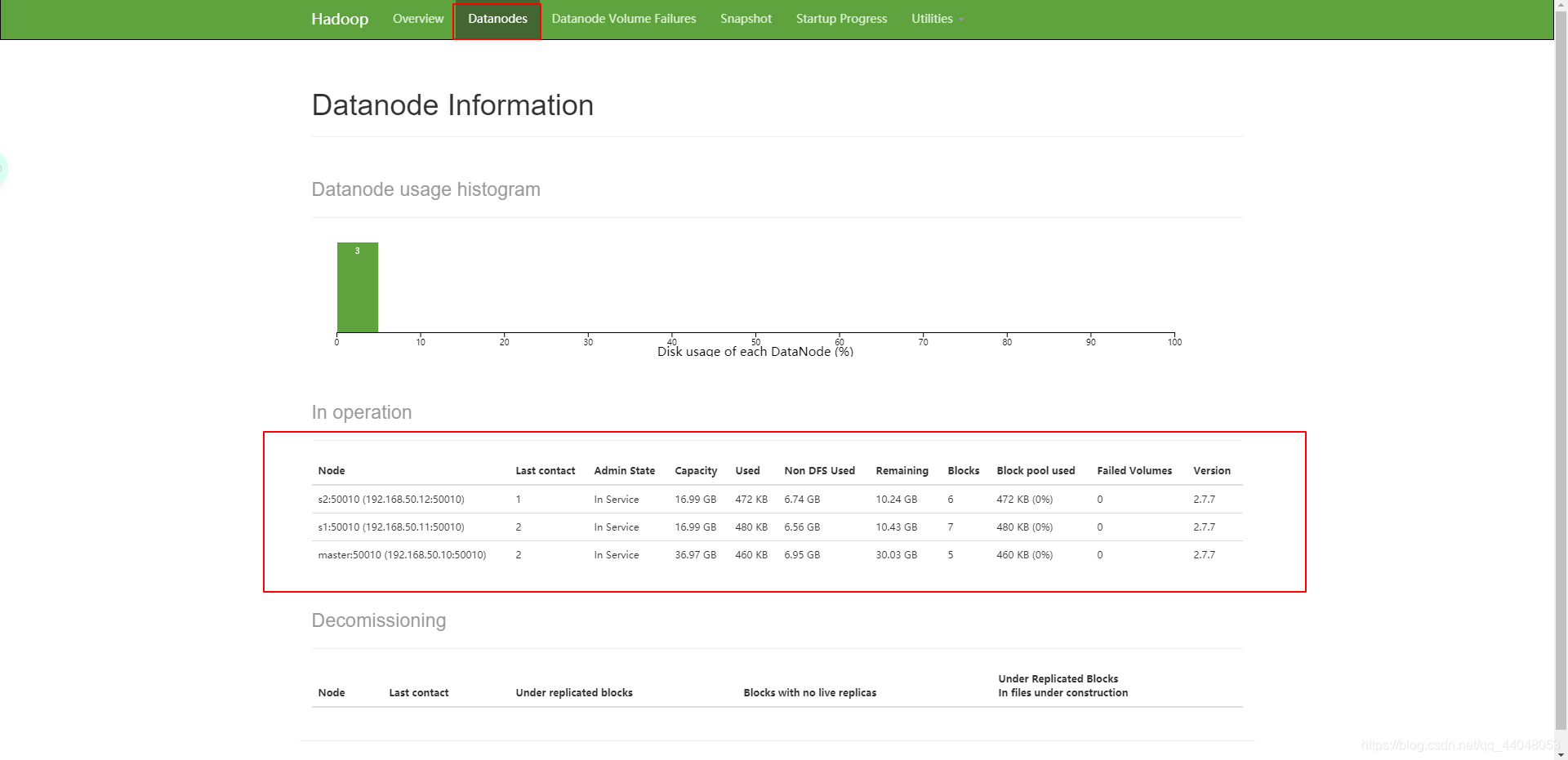
启动spark,并运行实例
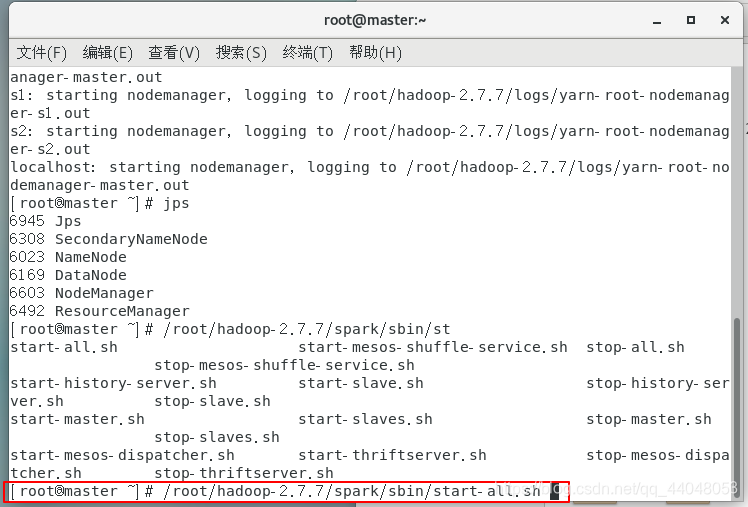
使用绝对路径启动spark
在终端输入
/root/hadoop-2.7.7/spark/sbin/start-all.sh
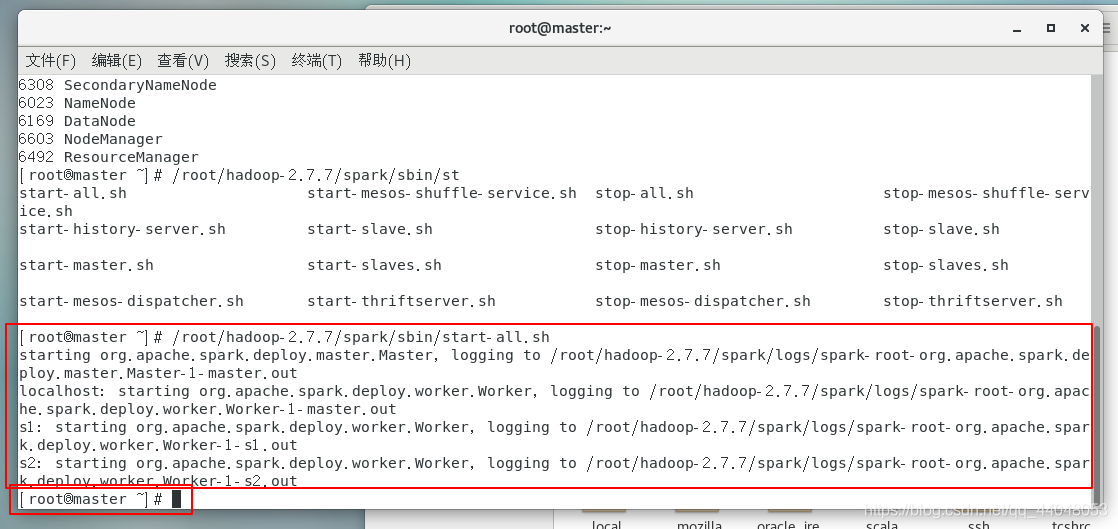
进入链接: http://192.168.50.10:8080/.
注意你的ip地址是主机的ip地址,和我不一样
出现界面就证明成功:
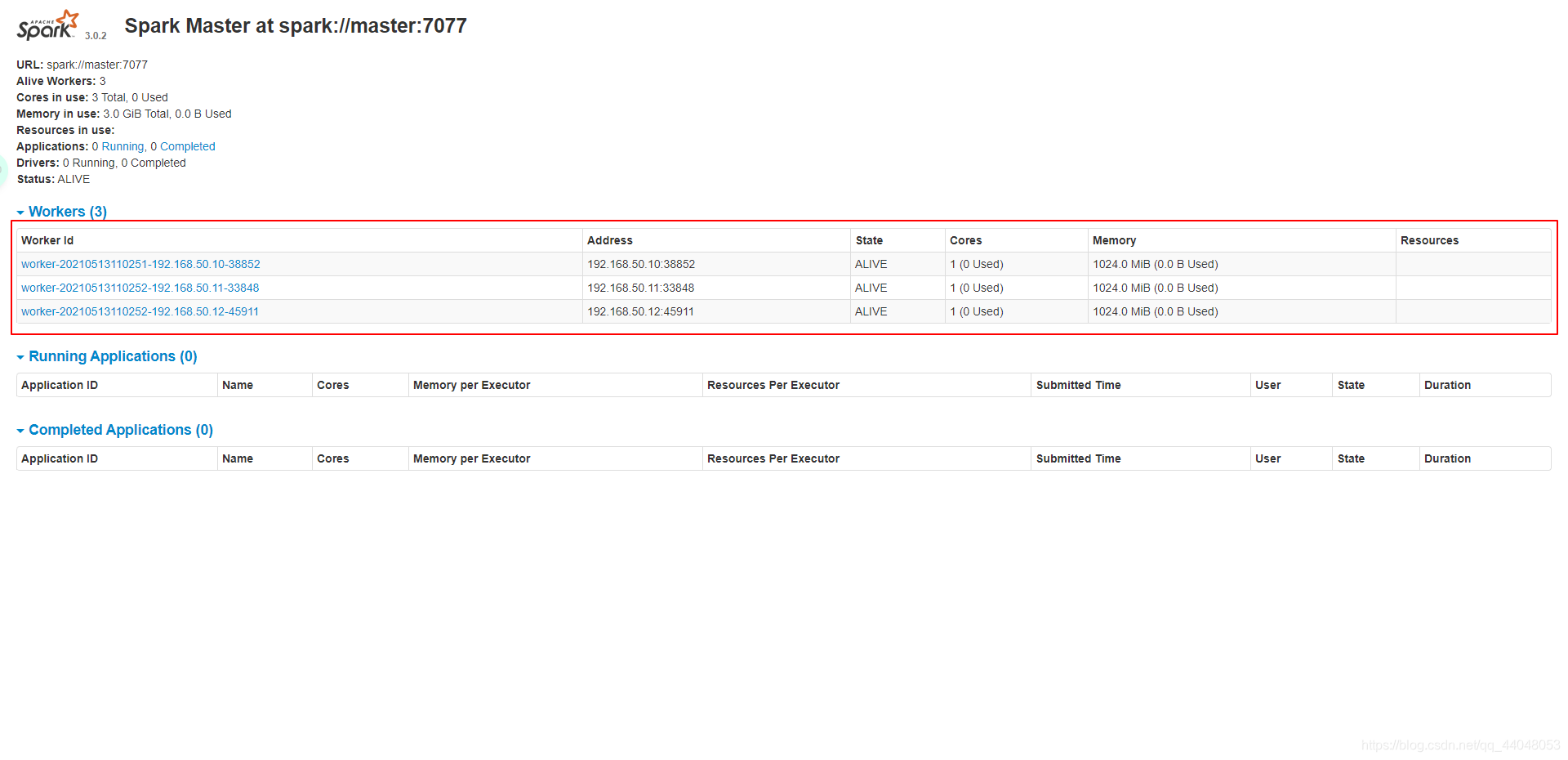
运行实例
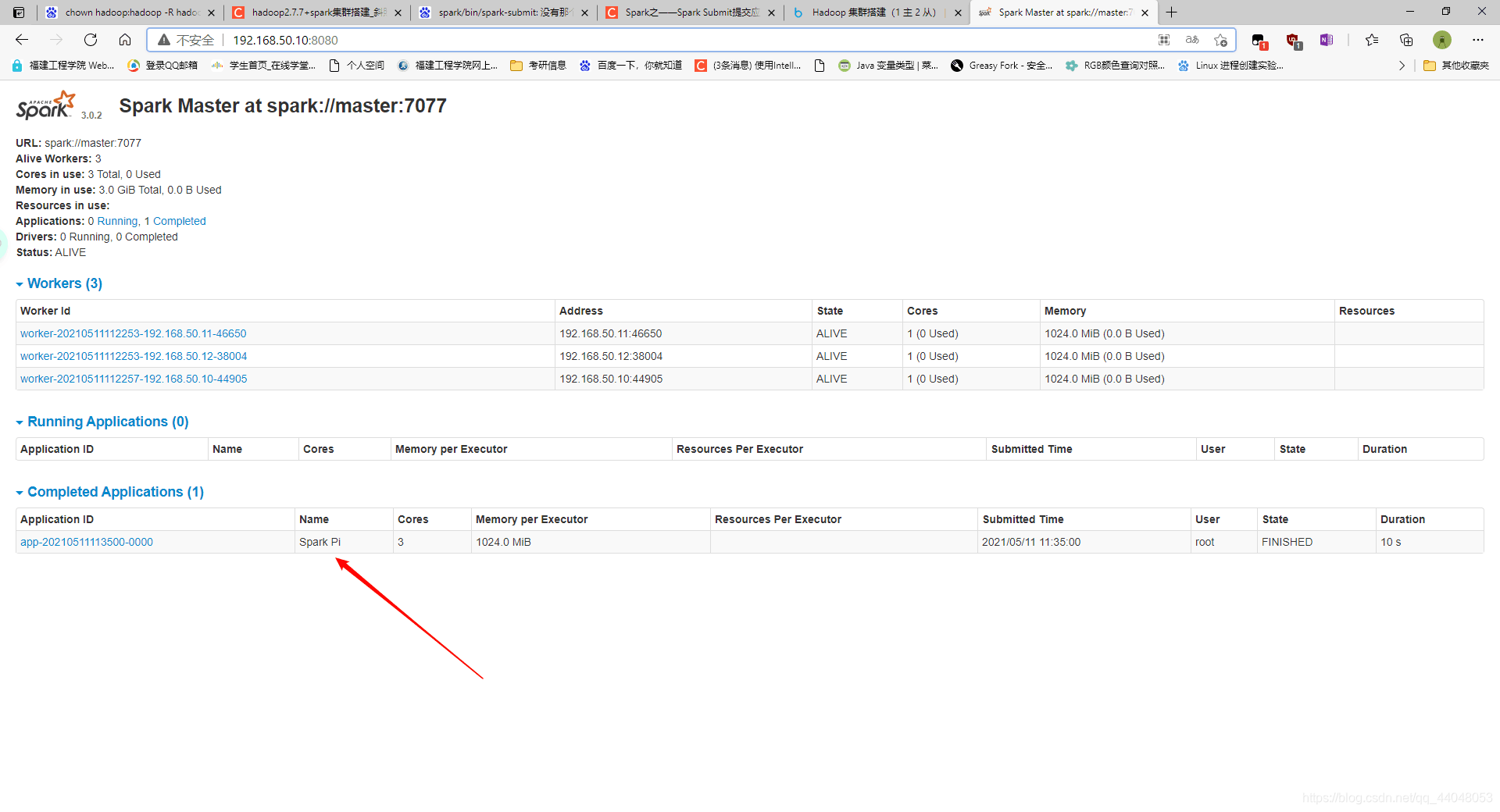
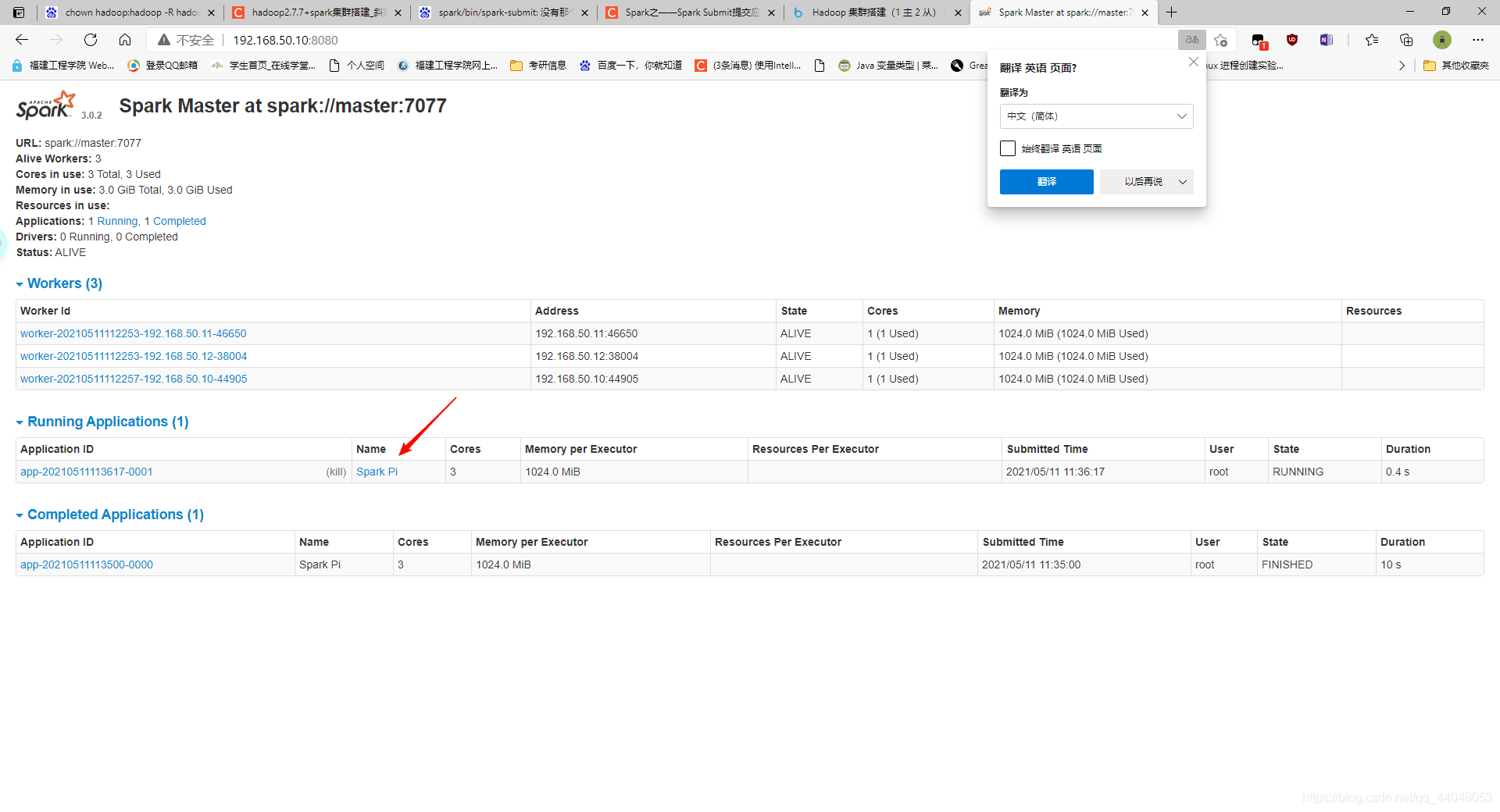
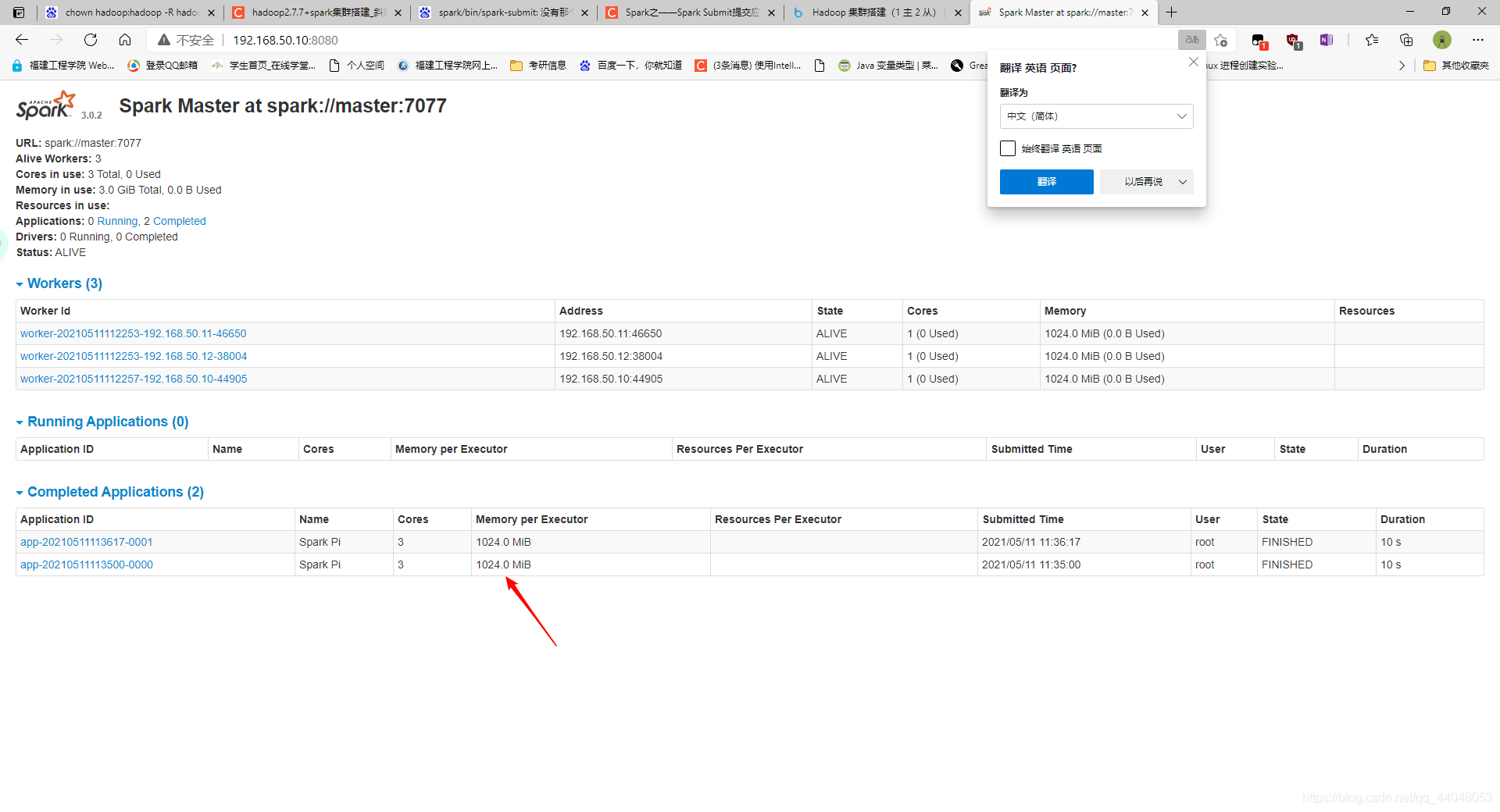
到这里 hadoop + spark 环境就配置完成啦,感谢观看


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









