







背景
最近想要找一些去中心化联邦的论文看,然后找到了一篇Peer-to-Peer的文章。这些文章所用于去中心化的方法一般都是从网络协议入手,与上一篇分享的用gossip协议来完成去中心化的出发点一样。于是今天想分享一下这篇Peer-to-Peer的论文顺便对目前的去中心化的工作做一个小的总结
传统FL VS P2PFL
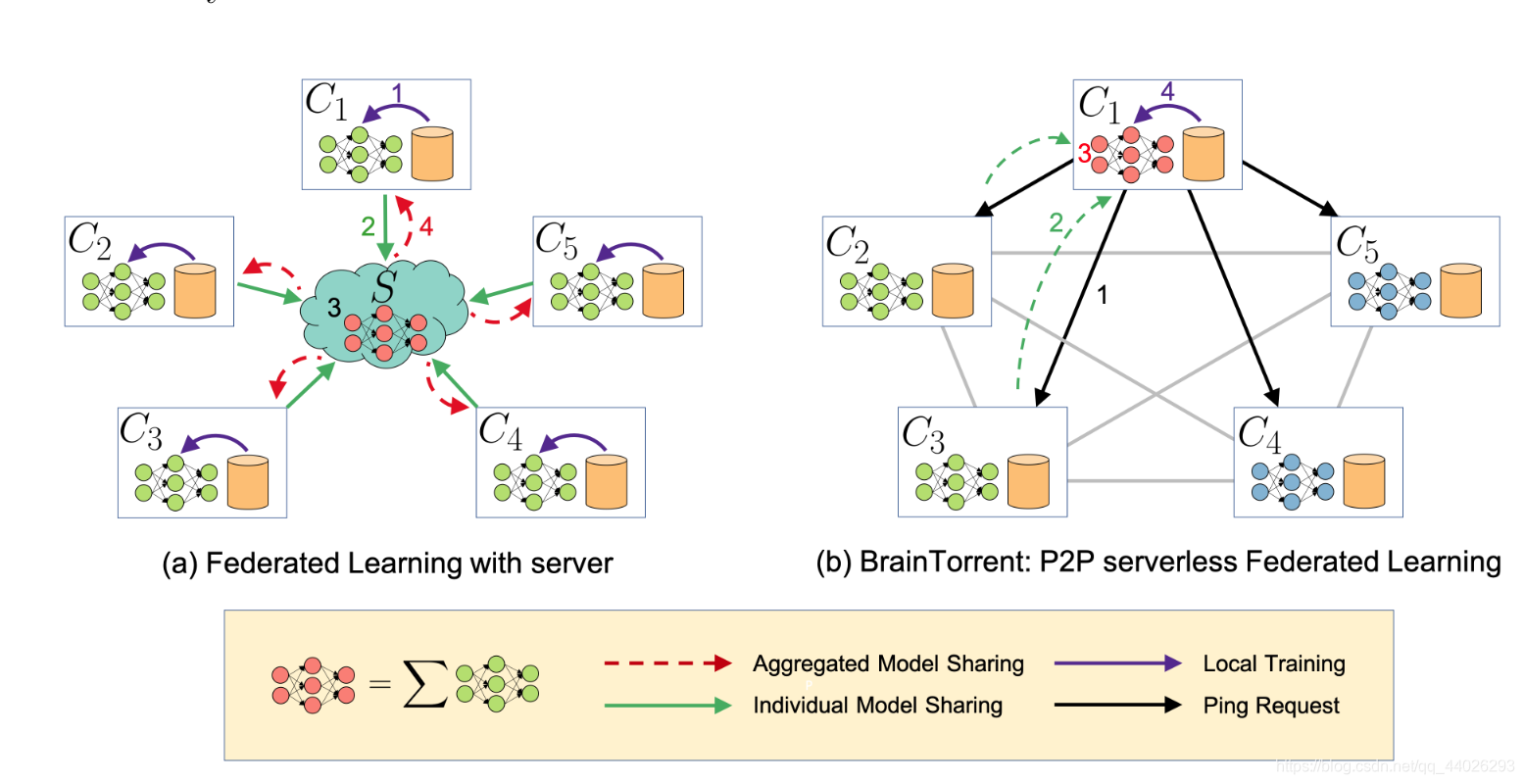
上图描述的是传统FL和P2PFL的比较。
传统FL在每一个round的训练方式是:
- 每一个client在本地用本地数据集训练出一个本地模型
- 每个client将训练好的本地模型发送到Server中
- Server聚合收到的所有模型
- Server将聚合得到的模型发回给每个client
P2PFL在每一个round的训练方式是:
- C 1 C_1 C1向其他的四个client发送ping请求
- C 2 C_2 C2和 C 3 C_3 C3有更新版本的模型, C 4 C_4 C4和 C 5 C_5 C5没有更新版本的模型,因此 C 2 C_2 C2和 C 3 C_3 C3将他们的模型发送给 C 1 C_1 C1
- C 1 C_1 C1将 C 2 C_2 C2和 C 3 C_3 C3发送给它的两个模型和自身的模型进行聚合
- C 1 C_1 C1用自身的数据集对聚合之后的模型进行微调
算法
每个client上都维护着一个vector v ∈ N N v \in \mathbb{N}^N v∈NN,包含了该client上的模型的版本还有最新用于聚合的其他 N − 1 N-1 N−1个client上模型的版本

算法步骤如下:
- 在训练的开始每个client先用本地的数据集训练本地模型几个轮次
- 然后在每个round,执行以下步骤:
- 随机选择一个client C i C_i Ci
- C i C_i Ci向剩下的 N − 1 N-1 N−1个client发送ping请求
- 对于每个 C j C_j Cj(其中 j ∈ { 1 , . . . , i − 1 , i + 1 , . . . , N } j\in \{1,...,i-1,i+1,...,N\} j∈{1,...,i−1,i+1,...,N}),如果它的模型版本大于 C i C_i Ci最近一次聚合所使用的 C j C_j Cj的版本,那么 C j C_j Cj将新的模型 W j W^j Wj和数据集大小 a j a_j aj发送给 C i C_i Ci
- C i C_i Ci使用公式 W ← W + a j a W j W\leftarrow W + \frac{a_j}{a}W^j W←W+aajWj聚合模型
- C i C_i Ci使用本地数据集对聚合得到的模型进行微调
- C i C_i Ci更新本地的版本数据 v i v^i vi
- 重复步骤(2)直至模型收敛
总结-网络协议实现去中心化
上周和这周分享的论文都是关于如何实现去中心化联邦,方法都是使用已有的网路协议来对传统的联邦聚合方法进行改进,达到去中心化的效果。使用gossip协议的优点在于,可以通过segmentation来达到降低单条通信链路上的开销,不足之处在于所有训练节点达成共识(每个节点上的模型一样)的过程过慢,并且整体通信开销要大;P2P的优点在于比起gossp协议,可以让所有训练节点达成公式,但是通信开销依旧是一个瓶颈。接下来打算继续看看有没有其他相关的网络协议可以有更好的效果。

















 255
255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









