







0.数据准备
如果是训练paraformer模型,我们只需要准备train_wav.scp和train_text.txt以及验证集val_wav.scp和val_text.txt即可。如果是训练SenseVoice模型,我们需要准备下面几个文件:
train_text.txt
train_wav.scp
train_text_language.txt
train_emo.txt
train_event.txt
其中必须的是train_wav.scp和train_text.txt文件。
下面是每个文件的格式要求:
BAC009S0764W0121 甚至出现交易几乎停滞的情况
BAC009S0916W0489 湖北一公司以员工名义贷款数十员工负债千万
asr_example_cn_en 所有只要处理 data 不管你是做 machine learning 做 deep learning 做 data analytics 做 data science 也好 scientist 也好通通都要都做的基本功啊那 again 先先对有一些 > 也许对
ID0012W0014 he tried to think how it could be
注意:如果是中英混杂的句子,中文和英文之间要有空格。
BAC009S0764W0121 /root/train/data/BAC009S0764W0121.wav
BAC009S0916W0489 /root/train/data/BAC009S0916W0489.wav
asr_example_cn_en /root/train/data/asr_example_cn_en.wav
ID0012W0014 /root/train/data/ID0012W0014.wav
注意:音频路径不能使用URL路径,使用URL路径会导致生成的jsonl文件没有内容。
BAC009S0764W0121 <|zh|>
BAC009S0916W0489 <|zh|>
asr_example_cn_en <|zh|>
ID0012W0014 <|en|>
BAC009S0764W0121 <|NEUTRAL|>
BAC009S0916W0489 <|NEUTRAL|>
asr_example_cn_en <|NEUTRAL|>
ID0012W0014 <|NEUTRAL|>
BAC009S0764W0121 <|Speech|>
BAC009S0916W0489 <|Speech|>
asr_example_cn_en <|Speech|>
ID0012W0014 <|Speech|>
下面生成jsonl文件时需要注意,如果你只准备了train_wav.scp和train_text.txt文件,那么执行下面这样的命令。
# generate train.jsonl and val.jsonl from wav.scp and text.txt
sensevoice2jsonl \
++scp_file_list='["../../../data/list/train_wav.scp", "../../../data/list/train_text.txt"]' \
++data_type_list='["source", "target"]' \
++jsonl_file_out="../../../data/list/train.jsonl" \
++model_dir='iic/SenseVoiceSmall'
注意:SenseVoice会自动打标。
如果是准备了全部文件,那么执行下面命令。
# generate train.jsonl and val.jsonl from wav.scp, text.txt, text_language.txt, emo_target.txt, event_target.txt
sensevoice2jsonl \
++scp_file_list='["../../../data/list/train_wav.scp", "../../../data/list/train_text.txt", "../../../data/list/train_text_language.txt", "../../../data/list/train_emo.txt", "../../../data/list/train_event.txt"]' \
++data_type_list='["source", "target", "text_language", "emo_target", "event_target"]' \
++jsonl_file_out="../../../data/list/train.jsonl"
生成的jsonl文件会保存到上面指定的路径下。我们训练之前最好检查一下生成的jsonl文件是否对。
1.训练
现在我们可以开始训练了,首先是检查finetune.sh脚本中的参数看看对不对,如显卡索引对不对,默认是使用了两张显卡,如果你只有一张,那么就需要修改,如果你是两张,那么可以不用修改直接运行这个脚本。训练中的loss曲线可通过tensorboard来查看,下面是我使用了300多条专业名词数据集做的微调训练的loss曲线。
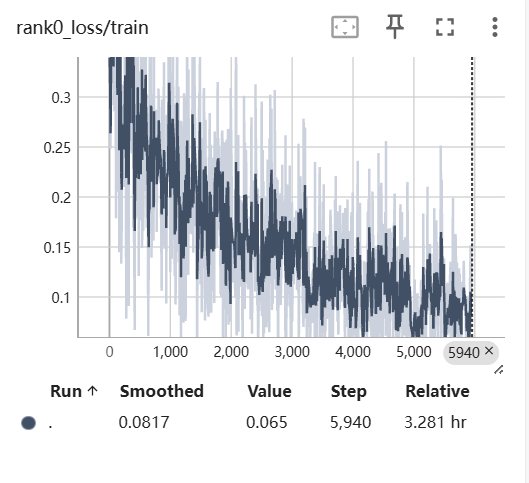
可以看到这个训练是有效果的,如果这个loss曲线是上升的,说明这个模型训练的参数设置的不对或者训练的数据集不干净,比如音频或文本没有对应上,或者音频采样率过低,比如8k。训练这个模型,我们推荐使用的音频采样率是大于等于16k。
训练的时候我们执行bash finetune.sh就可以了。
如果想要查看tensorboard曲线,需要先安装这个tensorboard依赖,如果你使用的是autodl平台训练的,那么可以执行下面命令先把默认启动的tensorboard结束掉,然后重新执行,并且指定端口和路径。
ps -ef | grep tensorboard | awk '{print $2}' | xargs kill -9
nohup tensorboard --port 6007 --logdir /path/to/your/tf-logs/direction > tensorboard.log 2>&1 &
3. 其它
更多内容可以访问我的博客,点击这里跳转。

















 2753
2753

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









