



 本文探讨了在TensorFlow.Keras中使用LSTM时,`units`参数代表隐藏状态的维度,是LSTM单元内部隐向量的大小,而`input_size`则涉及输入数据的维度。通过参考不同博客和官方文档,澄清了关于LSTM网络中这些参数的常见误解。
本文探讨了在TensorFlow.Keras中使用LSTM时,`units`参数代表隐藏状态的维度,是LSTM单元内部隐向量的大小,而`input_size`则涉及输入数据的维度。通过参考不同博客和官方文档,澄清了关于LSTM网络中这些参数的常见误解。
参考博客:
(11条消息) 关于LSTM的units参数_LeoRainy的博客-优快云博客_lstm units怎么设置
Keras LSTM的参数input_shape, units等的理解_ygfrancois的博客-优快云博客_keras lstm units
见到过lstm(80)的用法
查到80对应的是units这个参数,由于关于lstm网上的图大多是来自Understanding LSTM Networks -- colah's blog的下面这张图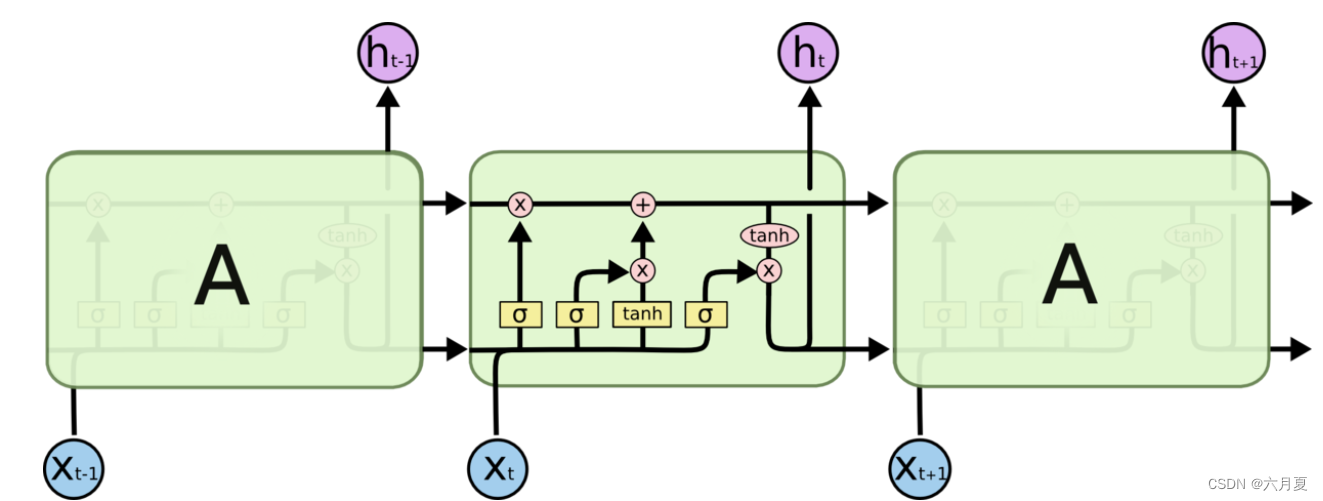
所以一开始会以为是这样多个矩阵的连接。注意,这样的理解是错误的。这张图只是为了便于理解lstm cell的工作原理绘制的不同状态cell的图,实际上只有一个cell在不停地更新状态。
对于units的理解,经过查阅博客还有吴恩达老师的讲解后,我认为可以理解为是hidden_state的维度,是lstm cell内部的隐向量的维度,是一个超参数。
还有关于输入维度的参数,官方文档LSTM layer (keras.io)描述如下
- inputs: A 3D tensor with shape
[batch, timesteps, feature]
timestep就是lstm考虑要考虑的时间步,拿前几个时间步的信息分析当下的数据。feature就是特征向量的维度,batch就是批次。在我的项目中,我是用前6个交通流数据预测当下的交通流量。我的timestep是6,feature是1,batch就是几千个由六个时间步信息构成的序列,这和我平时理解的32,64这样的批次不太一样,不知道batch是否可以直接当作样本数量。
看到传输入的方法有:
# 1
model = tf.keras.Sequential([
LSTM(4),
Dense(1)
])
#将输入x_train reshape成(sample_number, time_step, feature)的形式
model.fit(x_train, y_train,epochs=100)
# 2
# input_dim 是feature的维度
model_input = Input(shape=(time_steps, input_dim))
x = LSTM(64, return_sequences=True)(model_input)
x = Attention(units=32)(x)
x = Dense(1)(x)
model = Model(model_input, x)
model.compile(loss='mae', optimizer='adam')batch_size可以不定义


















 1324
1324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









