







废话不多说,先看看文章的作者信息!!!!
| 论文题目 | Align before Fuse: Vision and Language Representation Learning with Momentum Distillation |
|---|---|
| 作者 | Junnan Li, Ramprasaath R. Selvaraju, Akhilesh D. Gotmare Shafiq Joty, Caiming Xiong, Steven C.H. Hoi |
| 状态 | 已读完 |
| 会议或者期刊名称 | Advances in Neural Information Processing Systems 34 (NeurIPS 2021) |
| 被引次数 | 谷歌学术1188次 |
| 所属团队 | Salesforce 研究 |
| 摘要【摘要摘要中的摘要】 | In this paper, we introduce a contrastive loss to ALign the image andtext representations BEfore Fusing (ALBEF) them through cross-modal attention,which enables more grounded vision and language representation learning. Unlikemost existing methods, our method does not require bounding box annotations nor high-resolution images… |
| 代码链接 | 代码地址 |
1.摘要
老规矩先让机器总结摘要还是满准确的唉!

1.大多数现有方法采用基于transformer的多模态编码器来联合建模视觉标记(基于区域的图像特征)和单词标记。由于视觉标记和单词标记未对齐,因此多模态编码器学习图像文本交互具有挑战性。在本文中,我们引入了一种对比损失 ITC Loss ,通过跨模态注意力在融合之前对齐图像和文本表示(ALBEF),从而实现更基础的视觉和语言表示学习。
2.与大多数现有方法不同,我们的方法不需要边界框注释或高分辨率图像。为了改进对噪声网络数据的学习,我们提出了 动量蒸馏 ,这是一种从动量模型产生的伪目标中学习的自我训练方法。我们从互信息最大化的角度对 ALBEF 进行了理论分析,表明不同的训练任务可以解释为生成图像文本对视图的不同方式。
3.ALBEF 在多个下游视觉语言任务上实现了最先进的性能。在图像文本检索方面,ALBEF 的性能优于在大数量级数据集上预训练的方法。 在 VQA 和 NLVR2 上,ALBEF 与最先进的技术相比,绝对提高了 2.37% 和 3.84%,同时享有更快的推理速度。
2.关键图
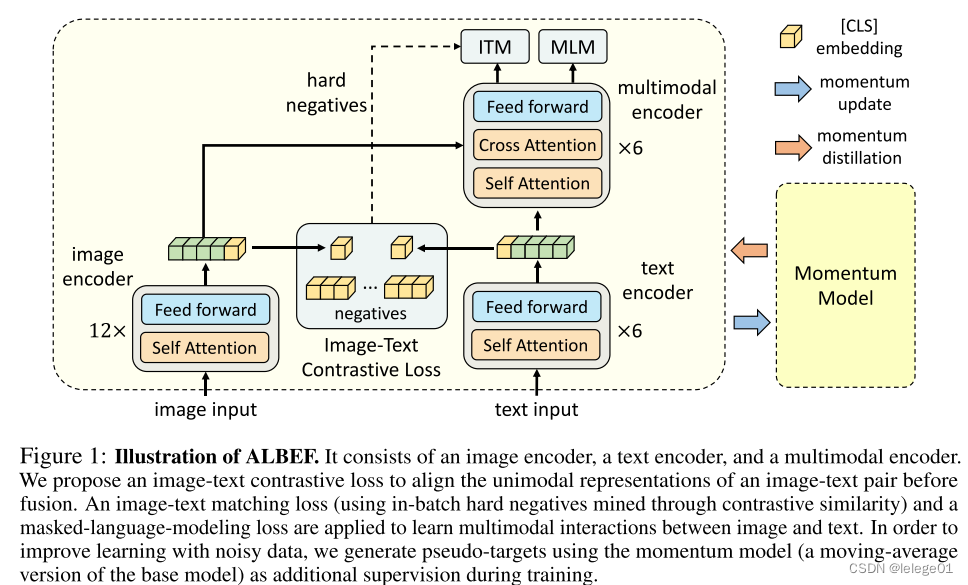
ALBEF的模型架构图,典型的双流多模态多模态模型,首先文本和图像的词嵌入和pixel嵌入,再分别经过text encoder和image encoder得到各自编码器的处理输出,之后先做ITC(即就是对比学习)前提是一点,先把两个不同模态的数据映射到同一个共享的空间,在代码中的体现就是分别通过一个线性层将其转化为同一个维度和空间的特征:
self.vision_proj = nn.Linear(vision_width, embed_dim) # 将图像特征做线性映射
self.text_proj = nn.Linear(text_width, embed_dim) # 将文本特征做线性映射
其次再做文章中提到的ITM(即就是图文匹配任务)和MLM(掩码的语言模型)任务,这个在后续的章节会仔细讲。
3.结论
1.本文提出了 ALBEF,一种用于视觉语言表示学习的新框架。 ALBEF 首先对齐单模态图像表示和文本表示,然后将它们与多模态编码器融合。我们从理论上和实验上验证了所提出的图像文本对比学习和动量蒸馏的有效性。
2.与现有方法相比,ALBEF 在多个下游 V+L 任务上提供了更好的性能和更快的推理速度。
4.导言
视觉和语言预训练(VLP)旨在从大规模图像文本对中学习多模态表示,从而改进下游视觉和语言(V+L)任务。
大多数现有的 VLP 方法(例如 LXMERT [1]、UNTER [2]、OSCAR [3])依赖于预先训练的目标检测器来提取基于区域的图像特征,并采用多模态编码器将图像特征与单词标记融合。
多模态编码器经过训练可以解决需要联合理解图像和文本的任务,例如掩码语言建模(MLM)和图像文本匹配(ITM)。
虽然有效,但该 VLP 框架存在几个关键限制:
(1)图像特征和单词标记嵌入位于各自的空间中,这使得多模态编码器学习建模它们的交互变得具有挑战性;即就是怎么将不同空间/模态的数据进行空间统一化或者怎么将其进行对齐
(2) 目标检测器的注释成本和计算成本都很高,因为它在预训练期间需要边界框注释,并且在推理期间需要高分辨率(例如 600⇥1000)图像; 我们知道目标检测需要将对应在图像中的内容用矩形框标注出来这需要大量的算力和很高的计算成本。
(3)广泛使用的图像文本数据集[4, 5]是从网络收集的,本质上是有噪声的,现有的预训练目标(例如MLM)可能会过度拟合噪声文本并降低模型的泛化性能。数据集本身存在大量的噪音点,使得我们的数据不规整
所以本文的作者提出了ALign BEfore Fuse (ALBEF),这是一个新的 VLP 框架来解决以上这些限制。
- 我们首先使用无检测器的图像编码器和文本编码器独立地对图像和文本进行编码。
- 然后我们使用多模态编码器通过跨模态注意力将图像特征与文本特征融合。
我们在单模态编码器的表示上引入了中间图像文本对比(ITC)损失,
它有三个目的:
(1)它对齐图像特征和文本特征,使多模态编码器更容易执行跨模态学习; 这边有个疑问,为什么做对比学习可以实现图像文本对齐?答案是:对比学习有一个正样本和一个负样本,它的目的是使得正样本之间的距离不断减小,使得负样本之间的距离不断地增大,这样即实现了对齐;
(2)改进了单模态编码器,以更好地理解图像和文本的语义;
(3)它学习一个共同的低维空间来嵌入图像和文本,这使得图像文本匹配目标能够通过我们的对比硬负挖掘找到更多信息样本。
为了改善噪声监督下的学习,我们提出了动量蒸馏(MoD),这是一种简单的方法,使模型能够利用更大的未经管理的Web数据集。
动量蒸馏:是知识蒸馏的一个分支,是一种模型压缩技术,通过教师模型的动量信息来指导学生模型的训练,可以提高学习速度,增强泛化能力,减少模型在训练过程中的过拟合,以及能对现有模型进行压缩以此来减少模型的参数量和计算复杂度。
5.相关工作
5.1.视觉语言表征学习
5.1.1基于transformer的多模态编码器进行交互建模
这类方法需要对图像和文本进行复杂的推理可以实现下游V+L任务的性能提升,但是大多数都需要高分辨率的输入图像和预先训练的对象检测器。就是借用对象识别和检测任务来实现我们的图文匹配任务,有方法去除了对象检测器以此来提升推理速度,但是性能大幅降低。
5.1.2侧重于学习图像和文本的独立单峰编码器
你比如现在比较活的clip和align使用对比损失对大量的嘈杂的web数据进行预训练,这是表示学习最有效的损失之一。但是缺乏为其他V+L任务建模图像和文本之间更复杂交互的能力。
但是ALBEF它统一了这两个类别,导致强大的单峰和多峰表示与检索和推理任务的卓越的性能。
5.2知识蒸馏
知识蒸馏的目的是通过教师模型中提取知识来提高学生模型的性能,通常是通过将学生的预测与教师的预测相匹配来实现的。代码中的体现是:
@torch.no_grad()
def copy_params(self):
for model_pair in self.model_pairs:
for param, param_m in zip(model_pair[0].parameters(), model_pair[1].parameters()):
param_m.data.copy_(param.data) # initialize
param_m.requires_grad = False # not update by gradient
大多数现有的方法侧重于从预先训练的教师模型中提取知识,在线蒸馏同时训练训练多个模型并使用他们的集合作为教师。
ps:在线蒸馏: 是一种在训练过程中动态地将教师模型的知识传递给学生模型的方法。与传统的蒸馏方法不同,在线蒸馏不需要预先训练好的教师模型,而是在训练过程中不断更新教师模型的参数,并实时地将其知识传递给学生模型。
基本思想是: 基本思想是在每个训练迭代中,通过监督学习和知识蒸馏的方式来更新学生模型的参数。具体来说,每个训练迭代中,我们使用当前的教师模型来辅助训练学生模型,使得学生模型的预测尽可能地接近教师模型的预测。通过这种方式,学生模型不断地从教师模型中学习知识,并逐渐提升自己的性能。
6.ALBEF预训练模型
6.1模型架构
使用12层视觉转换器 VIT-B/16 作为图像编码器,并用ImageNet-1k上预先训练的权重对其进行初始化。输入图像i被编码成嵌入序列。我们将6层转换器用于文本编码器和多模式编码器。文本编码器使用BERTbase模型的前6层进行初始化,多模式编码器使用BERTbase模型的后6层进行初始化。文本编码器将输入文本T转换成嵌入序列,该序列被馈送到多模式编码器。在多模式编码器的每一层通过 交叉注意力机制 将图像特征与文本特征融合。

6.2预训练任务
预训练目标:1.单峰编码器上的图文对比学习ITC,多模态编码器上的掩码语言建模MLM和图文匹配任务ITM
6.2.1图文对比学习
图文对比学习的目的是在融合前学习更好的单峰表征。即就是怎么使得正样本之间的距离不断地缩小,负样本之间的距离不断增大,其实就是先把图文各自映射到256的低维映射空间中,再通过计算cossimlarity计算出映射到的图像文本之间的语义相似度;
s
=
g
v
(
v
c
l
s
)
T
g
w
(
w
c
l
s
)
s=g_v(v_{cls})^{T}g_{w}(w_{cls})
s=gv(vcls)Tgw(wcls)对于每个图像文本,计算softmax归一化图文之间的相似度,其中
τ
\tau
τ是一个可学习的温度参数,温度参数可以控制生成结果的多样性,提高模型的鲁棒性,增强生成的语义的一致性。
p
m
i
2
t
(
I
)
=
e
x
p
(
s
(
I
,
T
m
)
/
τ
)
∑
m
=
1
M
e
x
p
(
s
(
I
,
T
m
)
/
τ
)
p_{m}^{i2t}(I) = \frac{exp(s(I,T_{m})/\tau )}{\sum_{m=1}^{M}exp(s(I,T_{m})/\tau )}
pmi2t(I)=∑m=1Mexp(s(I,Tm)/τ)exp(s(I,Tm)/τ)
p
m
t
2
i
(
I
)
=
e
x
p
(
s
(
T
,
I
m
)
/
τ
)
∑
m
=
1
M
e
x
p
(
s
(
T
,
I
m
)
/
τ
)
(1)
p_{m}^{t2i}(I) = \frac{exp(s(T,I_{m})/\tau )}{\sum_{m=1}^{M}exp(s(T,I_{m})/\tau )} \tag{1}
pmt2i(I)=∑m=1Mexp(s(T,Im)/τ)exp(s(T,Im)/τ)(1)
其在代码中的体现是:
sim_i2t_m = image_feat_m @ text_feat_m_all / self.temp
sim_t2i_m = text_feat_m @ image_feat_m_all / self.temp
之后在取对数进行归一操作,转化为最终的损失为:
L
i
t
c
=
1
2
E
(
I
,
T
)
∼
D
[
H
(
y
i
2
t
(
i
)
,
p
i
2
t
(
I
)
)
+
H
(
y
t
2
i
(
T
)
,
p
t
2
i
(
I
)
)
]
(2)
\ L_{itc}=\frac{1}{2}E_{(I,T)\sim D}\left [ H(y^{i2t}(i),p^{i2t}(I)) + H(y^{t2i}(T),p^{t2i}(I)) \right] \tag{2}
Litc=21E(I,T)∼D[H(yi2t(i),pi2t(I))+H(yt2i(T),pt2i(I))](2)ITC随机生成的的负样本字幕

6.2.2掩码的语言模型
掩码的语言模型利用图像和上下文文本来预测掩蔽词。以15%的概率对输入的token进行随机掩码,将掩蔽的词语替换为特殊的令牌**[MASK]**
p
m
s
k
(
I
,
T
^
)
p^{msk}(I, \widehat{T})
pmsk(I,T
)代表预测的被掩蔽的词的概率
y
m
s
k
y^{msk}
ymsk代表独热词汇表分布,其中token为预测正确的概率为1
L
m
l
m
=
E
(
I
,
T
^
)
∼
D
(
H
(
y
m
s
k
,
p
m
s
k
(
I
,
T
^
)
)
(3)
\ L_{mlm}=E_{(I, \widehat{T}) \sim D}(H(y^{msk},p^{msk}(I, \widehat{T})) \tag{3}
Lmlm=E(I,T
)∼D(H(ymsk,pmsk(I,T
))(3)MLM的最小交叉熵损失如上,MLM随机生成的的负样本字幕

6.2.3图文匹配
预测图文是否正确匹配,我们使用一个多模态编码器输出 [cls] token作为图文对的联合表示,并在后面附加全连接层FC和softmax来预测两类概率
p
i
t
m
p^{itm}
pitm,则图文匹配的损失可记为:
L
i
t
m
=
E
(
I
,
T
)
∼
D
(
H
(
y
i
t
m
,
p
i
t
m
(
I
,
T
)
)
(4)
\ L_{itm}=E_{(I, T) \sim D}(H(y^{itm},p^{itm}(I, T)) \tag{4}
Litm=E(I,T)∼D(H(yitm,pitm(I,T))(4)其中
y
i
t
m
y^{itm}
yitm是表示匹配正确的二维的独热向量。
我们提出了一种在零计算开销下为 ITM 任务采样负例困难的策略。如果负样本对具有相似的语义但在细粒度细节上不同,这样就很难去处理他们。我们使用公式1中的对比相似性来找出一批样本内的难负样本。对于小批次中的每一幅图像,我们按照对比相似度分布从同一批次中采样一个负文本,其中与图像越相似的文本被采样的机会越高。同样,我们还为每个文本采样一张负样例图像。ALBEF的完整的预训练损失为
L
=
L
i
t
c
+
L
m
l
m
+
L
i
t
m
(5)
\ L = L_{itc} + L_{mlm} + L_{itm} \tag{5}
L=Litc+Lmlm+Litm(5)
6.3动量蒸馏
用于预训练的图文对大多是从网络上收集的,噪声较大。正样本对通常是弱相关的:文本可能包含与图像无关的单词,或者图像可能包含文本中未描述的实体。 对于ITC学习,图像的负文本也可能与图像的内容相匹配。对于MLM,可能存在与注释不同的其他词,它们对图像的描述同样好(或更好)。然而,ITC和MLM的单一标签惩罚所有负面预测,无论其正确性如何。为了解决这个问题,我们建议向动量模型产生的伪目标学习。动量模型是一个不断进化的教师,它由单模和多模编码器的指数移动平均版本组成。在训练期间,我们训练基本模型,使其预测与动量模型中的预测相匹配。
6.4预训练数据集
使用了两个web数据集Conceptual Captions,SBU Captions和两个域内数据集COCO和 数据集Visual Genome。总共的图像数量是400万张,图文对数为510万张。
6.5实现的细节
我们的模型由123.7M参数的 BERTbase 和85.8M参数的 VIT-B/16 组成。我们在8个NVIDIA A100 GPU上使用512的批量大小对模型进行了30个时期的预训练。我们使用权重衰减率为0.02的 AdamW 优化器。学习速度在前1000次迭代中预热到1e-4,并以余弦函数的方式衰减到1e-5。在 预训练中 ,我们以分辨率为256 RandAugment的随机图像裁剪作为输入,并应用。在 微调过程 中,我们将图像分辨率提高到384。用于更新动量模型的动量参数设置为0.995,用于图文对比学习的队列大小设置为65,536。在第一个周期内,我们线性地将蒸馏权重↵从0提高到0.4.
7.下游任务+实验
7.1.下游任务
此预训练任务适应于五个下游的V+L任务上;
1.图文检索
图像-文本检索包括两个子任务:图像-文本检索(TR)和文本-图像检索(IR)。在Flickr30K和COCO基准上评估ALBEF,并使用每个数据集中的训练样本微调预训练模型。对于Flickr30K上的零样本检索,我们使用在COCO上微调的模型进行评估。在微调过程中,我们联合优化ITC损失(公式2)和ITM损失(公式4)。ITC基于单峰特征的相似性学习图像-文本评分函数,而ITM对图像和文本之间的细粒度交互进行建模以预测匹配分数。在推理过程中,我们首先计算所有图文对的特征相似度得分。然后,我们计算并取前k个得分排名。由于k可以设置为非常小,因此我们的推理速度比需要计算所有图文对的ITM分数的方法快得多。
2.视觉蕴含
视觉蕴涵是一种细粒度的视觉推理任务,用于预测图像和文本之间的关系是蕴涵关系、中性关系还是矛盾关系。我们根据UNITER,将VE视为一个三向分类问题,并在多模式编码器的[CLS]token表示上使用多层感知器(MLP)来预测类别概率。
3.视觉问答
视觉问答(VQA)要求模型在给定图像和问题的情况下预测答案。我们将VQA视为一个答案生成问题。使用6层transformer解码器来生成答案[解码器]。如下图所示,自回归答案解码器通过交叉注意接收多模式嵌入,并且序列开始令牌([CLS])被用作解码器的初始输入令牌。同样,序列结束令牌([SEP])被附加到解码器输出的末尾,其指示生成完成。

3.视觉推理的自然语言
用于视觉推理的自然语言(NLVR2)要求模型预测的文本是否描述了一对图像。我们扩展了我们的多模式编码器,使其能够对两幅图像进行推理。多模式编码器的每一层被复制为具有两个连续的transformer块,其中每个块包含一个自注意力层、一个交叉注意力层和一个前馈层。 每个层中的两个块使用相同的预先训练的权重进行初始化,并且两个交叉关注层共享关键字和值的相同的线性投影权重。在训练期间,这两个块接收图像对的两组图像嵌入。我们在多模式编码器的[CLS]表示上附加了一个MLP分类器用于预测。对于NLVR2,我们执行了额外的预训练步骤,以准备用于编码图像对的新的多模式编码器。我们设计了一个文本分配(TA)任务,如下所示:给定一对图像和一个文本,模型需要将文本分配给第一个图像、第二个图像或两者都不分配。我们将其视为一个三向分类问题,并在[CLS]表示上使用FC层来预测分配。

4.视觉定位
视觉定位旨在定位图像中与特定文本描述相对应的区域。我们研究了弱监督环境,其中没有边界框注释可用。我们在RefCOCO数据集上进行了实验,并根据与图像文本检索相同的策略,仅使用图像文本监督对模型进行了微调。
7.2实验
7.2.1评估提出的方法
与基线预训练任务(MLM+ITM)相比,加入ITC显著提高了预训练模型在所有任务中的性能【因为一开始先把图文对齐了】。提出的较难的负样例挖掘通过发现更多信息量更大的训练样本来改进ITM。此外,加入动量蒸馏改善了ITC、MLM和所有下游任务的学习。我们也可看到,当预训练使用的数据集越大,我们能训练的结果越好

7.2.2微调图文/文图检索
我们的ALBEF实现了最先进的性能,超过了CLIP和ALIGN,后者是在数量级更大的数据集上进行训练的。 考虑到当训练图像的数量从4M增加到14M时,ALBEF有相当大的改善,我们假设它有潜力通过在更大规模的Web图文对上进行训练来进一步增长。

7.2.3零样本上的图文检索

7.2.4其他下游任务以及其他方法的比较
ALBEF拥有400万张训练前图像,已经达到了最先进的性能。ALBEF有1400万张训练前图像,大大超过了现有的方法,包括额外使用对象标签的方法或对抗性数据增强。

7.2.5消融实验
消融实验主要做了图文检索中计算并取前k个得分排名,其中将k作为变量,探索了不同k值对于实验的影响。结果表明k的取值对实验的影响不是很大。
总结评论
本文提出了一种新的视觉语言表征学习框架ALBEF。 ALBEF首先使用对比学习将单峰图像表示和文本表示对齐,然后将它们与多模式编码器融合。我们从理论和实验上验证了图文对比学习和动量蒸馏的有效性。与已有方法相比,该算法在多个V+L下游任务上具有更好的性能和更快的推理速度。
自己的见解: 这篇文章提出使用对比学习作为图文对齐的一种方式,是一种很前卫的方式,但是这并不是唯一的方式,我们可以在图文对齐这块进行修改,比如使用注意力机制进行对齐或者是使用强化学习对齐,其次本文对于负样本挖掘我觉得比较费时,也可以对这块内容进行改善。

















 970
970

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









