






中英文关键词抽取
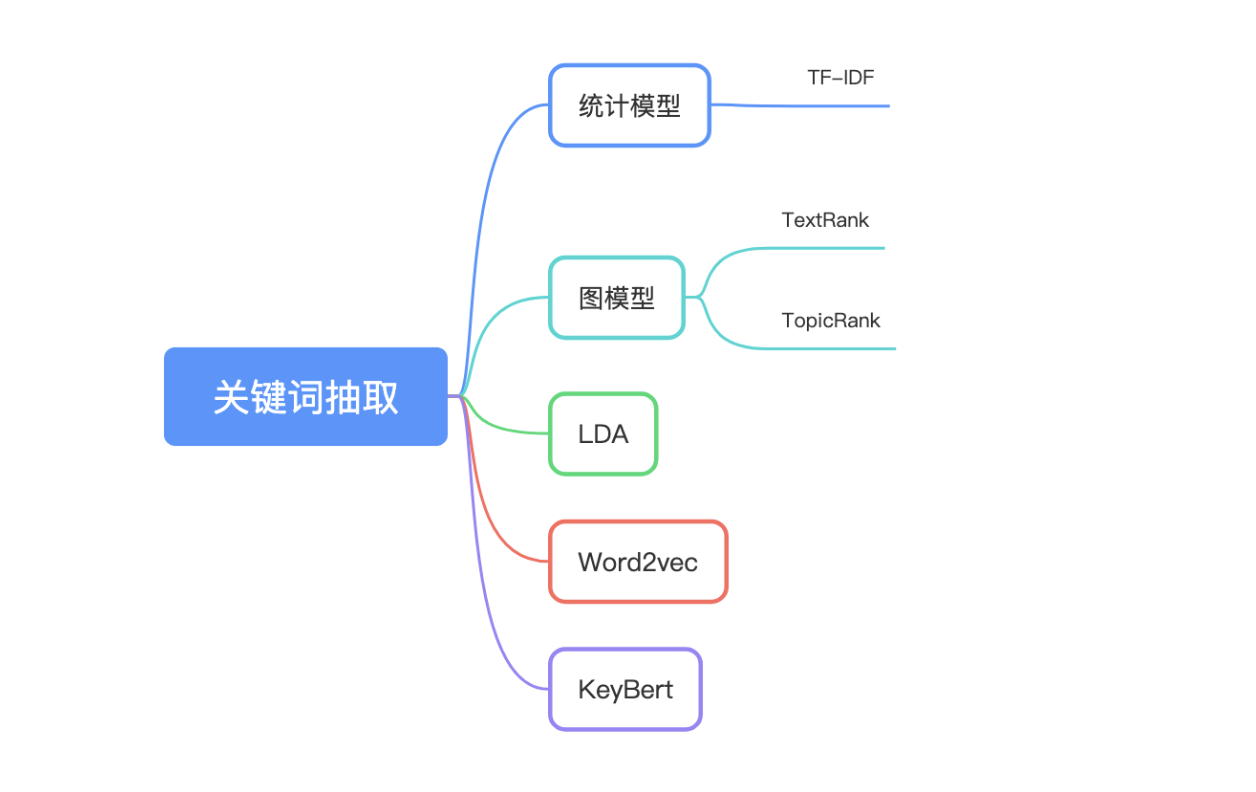
欢迎使用中英文关键词抽取工具,本工具支持多种关键词抽取算法,帮助用户从文本中快速提取重要信息。下图展示了我们所支持的关键词抽取算法:
介绍
本工具提供多种关键词抽取算法,满足不同需求。支持的算法如下:
- TF-IDF:通过词频和逆文档频率来衡量词汇的重要性。
- TextRank:基于图算法的无监督关键词抽取方法。
- KeyBERT:结合BERT模型的关键词抽取技术,能捕捉语义相关性。
- Word2Vec:利用词向量表示来进行关键词提取。
- LDA:一种基于主题模型的关键词抽取方法。
使用方法
1、TF-IDF
from keyword_extract import KeywordExtract
input_list = [
"自然语言处理是人工智能领域中的一个重要方向。它研究人与计算机之间如何使用自然语言进行有效沟通。"
]
key_extract = KeywordExtract(type="TF-IDF")
# 基于TF-IDF进行关键词的抽取
print(key_extract.infer(input_list))2、TextRank
from keyword_extract import KeywordExtract
input_list = ["自然语言处理是人工智能领域中的一个重要方向。它研究人与计算机之间如何使用自然语言进行有效沟通。"]
key_extract = KeywordExtract(type="TextRank")
# 基于TextRank进行关键词的抽取
print(key_extract.infer(input_list))
3、KeyBERT
from keyword_extract import KeywordExtract
input_list = ["自然语言处理是人工智能领域中的一个重要方向。它研究人与计算机之间如何使用自然语言进行有效沟通。"]
key_extract = KeywordExtract(type="KeyBERT")
# 基于KeyBERT进行关键词的抽取
print(key_extract.infer(input_list))
4、Word2Vec
from keyword_extract import KeywordExtract
input_list = ["自然语言处理是人工智能领域中的一个重要方向。它研究人与计算机之间如何使用自然语言进行有效沟通。"]
key_extract = KeywordExtract(type="Word2Vec")
# 基于Word2Vec进行关键词的抽取
print(key_extract.infer(input_list))
5、LDA
from keyword_extract.lda_model.lda import LDA
input_list = ["自然语言处理是人工智能领域中的一个重要方向。它研究人与计算机之间如何使用自然语言进行有效沟通。"]
lda_model = LDA(type="LDA")
# 基于LDA 进行关键词的抽取,topic_num是主题的个数
print(lda_model.infer(input_list, topic_num=3))
本项目地址:https://github.com/TW-NLP/KeywordExtract
欢迎使用和交流,大家可以在问题单中提出自己认为好的关键词抽取算法,我们会进行复现和集成。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









