






 本文汇总了Python爬虫开发中的实用技巧,包括字符串合并、请求处理、JSON操作、存储方式等,并介绍了如何利用PyCharm优化代码格式及调试流程。
本文汇总了Python爬虫开发中的实用技巧,包括字符串合并、请求处理、JSON操作、存储方式等,并介绍了如何利用PyCharm优化代码格式及调试流程。
目录
1.Python字符串合并
a='前半句'
all=a+'后半句'
2.response [200]
requests抓取内容为空(网址不对,反爬)
3.UA伪装
#3.UA伪装
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36 Edg/87.0.664.75'
} # 头信息
写成字典形式,具体键值从浏览器里找
4.post/get请求参数处理
具体用哪一个视浏览器抓包工具的格式而定
5.json包
将json格式的文件转化成直白的可懂的信息。json格式一堆代号,用text格式显示是一堆符号。
dic_obj = response.json()
6. 永久化存储
fp = open(file_name, 'w', encoding='utf-8')
json.dump(dic_obj, fp=fp, ensure_ascii=False)
7. 开发人员工具的》network》XHR数据包的更新
-
网页分块更新
!!!需要先打开开发人员工具, 再 去点击网页进行更新。更新部分的数据包才会出现在列表。 -
post/get 向服务器请求的信息
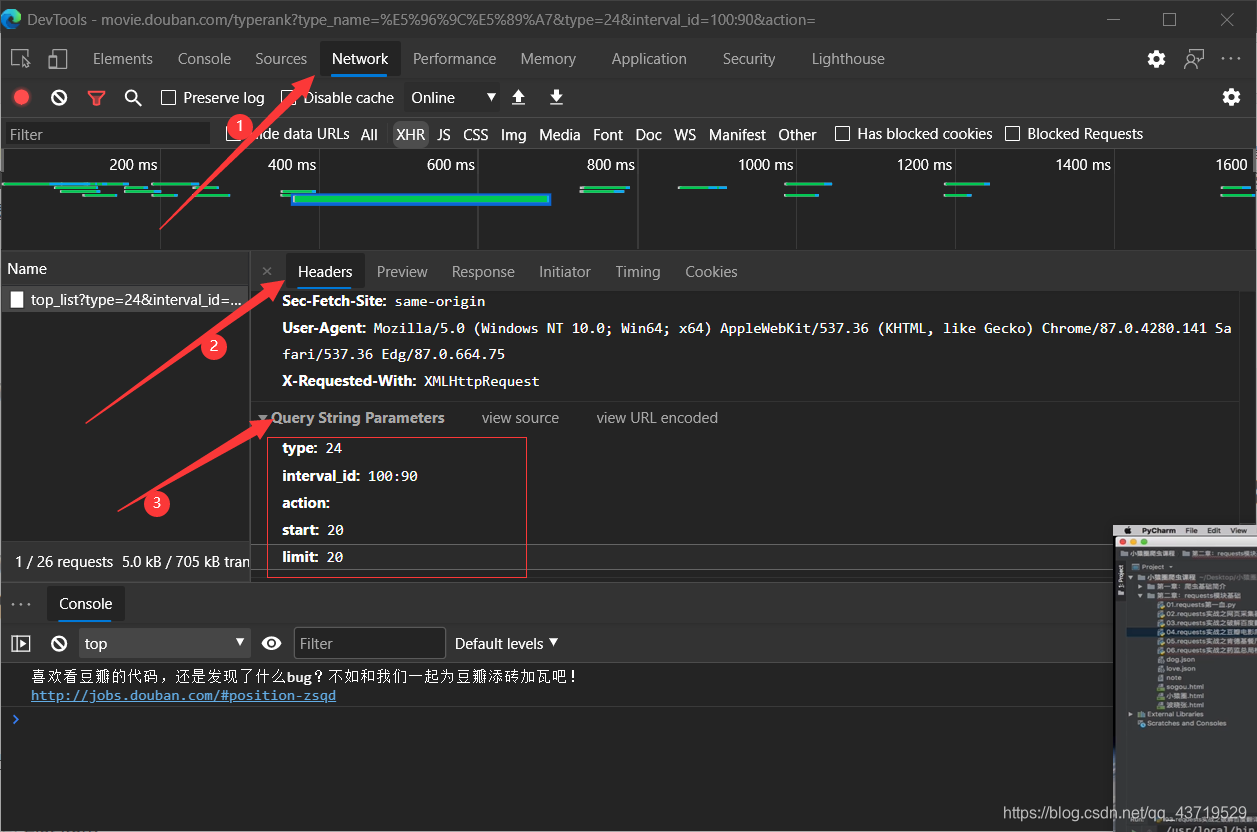
向服务器提供这些信息,才会返回更新part的数据
这些数据被写成字典:
param = {
'type' : '24',
'interval_id' : '100:90',
'action' : '',
'start' : '1',#从库中第几部电影去取
'limit' : '20',#每次取多少
}
然后向服务器请求数据
requests.get(url=post_url, params=param, headers=headers)
8. pycharm一键调整代码格式
‘Ctrl + Alt + L’
原来间距紧凑,调整之后间距合理,清晰,赏心悦目
9.json校验工具
将json文件的内容复制到这里,点击校验,即可,与被爬取原网页比对,检查是否正确
10. 阿贾克斯请求判断
点击查询前后,地址栏未发生改变,则是阿贾克斯请求,页面局部刷新
对数据包指定的url发请求,则可获取刷新数据
11.写入text类型的文件
with open(file_name, 'w', encoding='utf-8') as fp:
fp.write(p_obj)
12.python读取Excel文件
(1)xlsx文件的读取总是失败,据说是新版本的xlrd不支持对这种类型的读取,需要用其他方法,openpyxl这个库,我试了一下可以正常读取。参见新版本的xlsx读取和
(2)可以在pycharm中,右键查看一下文件的位置,然后复制文件路径过来。
(3*)python中使用xlrd、xlwt库读写excel(xls),
用openpyxl库读写excel(xlsx)。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











