




 TSN(Temporal Segment Networks)旨在解决现有动作识别模型对长期时间信息分析不足的问题,通过稀疏采样策略和双流网络结构,结合光流与RGB信息。在有限数据下,通过预训练、正则化和增强数据增强等手段提高模型性能。文章探讨了端到端网络的概念,指出TSN并非端到端模型,并分享了论文中的关键发现和实验结果。
TSN(Temporal Segment Networks)旨在解决现有动作识别模型对长期时间信息分析不足的问题,通过稀疏采样策略和双流网络结构,结合光流与RGB信息。在有限数据下,通过预训练、正则化和增强数据增强等手段提高模型性能。文章探讨了端到端网络的概念,指出TSN并非端到端模型,并分享了论文中的关键发现和实验结果。
【注】这是我在动作识别领域,认真研读的第一篇文章,对很多概念还理解得不透彻,名词翻译不准确,请大家谅解并在评论区指正。最近正在看TSN的实现代码,后期还会出一篇代码研读的博客。
解决问题(motivation):
- 现有模型缺乏对long-range时间动作信息的分析
目前主流的动作识别模型,往往专注于提取空间信息(appearance)和short-term的时间动作信息,缺乏对long-range的时间动作信息的分析应用。而不去提取long-range的时序信息的原因,在于现有解决方案使用的是稠密时序采样(dense temporal sampling with a predefined sampling interval),这会导致极大的计算量,导致特征提取的视频长度有限。 - 训练数据有限
由于视频数据的采集和标注十分困难,现有的训练数据十分有限。例如现有的两个主流数据集:UCF101,HMDB51,在大小以及动作类别上都十分有限。如何在有限的数据下训练得到效果较好的模型也是一个问题。
解决方案(方案关键点):
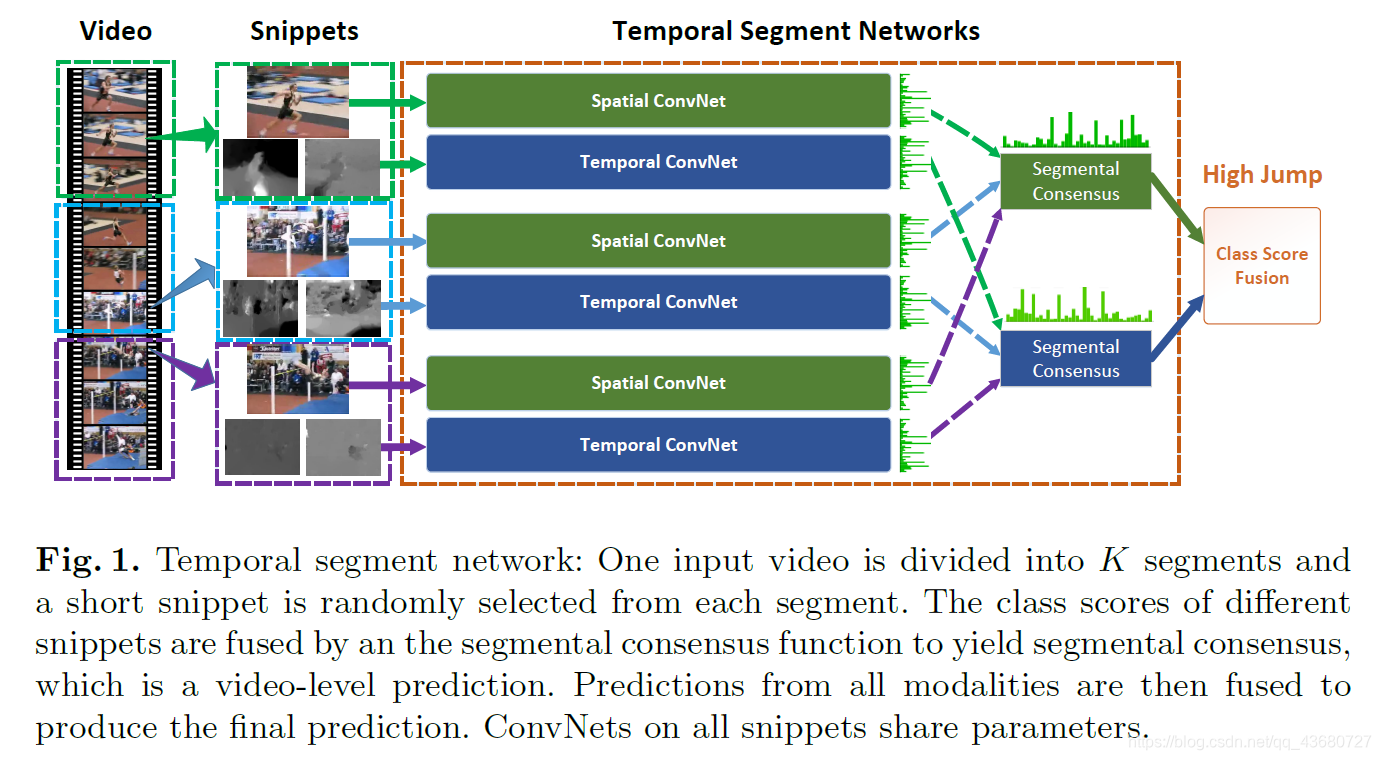
1.提出基于双流网络结构的TSN网络 ,并使用稀疏采样的策略,获得视频长度上的时间动作信息。
2.在模型训练中使用一系列改进方法及技巧,使得在有限的数据下模型也能较好的训练。
①cross-modality pre-training; ②regularization; ③enhanced data augmentation;④study four types of input modalities to two-stream ConvNets.
一些疑问:
- 解决方案2中的多模态融合的实现细节?
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 870
870

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









