




先安装好适配的cuda(我选择的是12.1), 然后环境中的python版本为3.11, pytorch可以先不安装,后面安装llamafactory的时候自动安装适配的pytorch
先安装llamafactory
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]" --no-build-isolation
这一步,会自动安装适配的torch, torchvision, torchaudio,以及一些其他的适配的Nvidia包:
pip install -e ".[torch,metrics]" --no-build-isolation
量化报错(我这张图是量化成功后的):
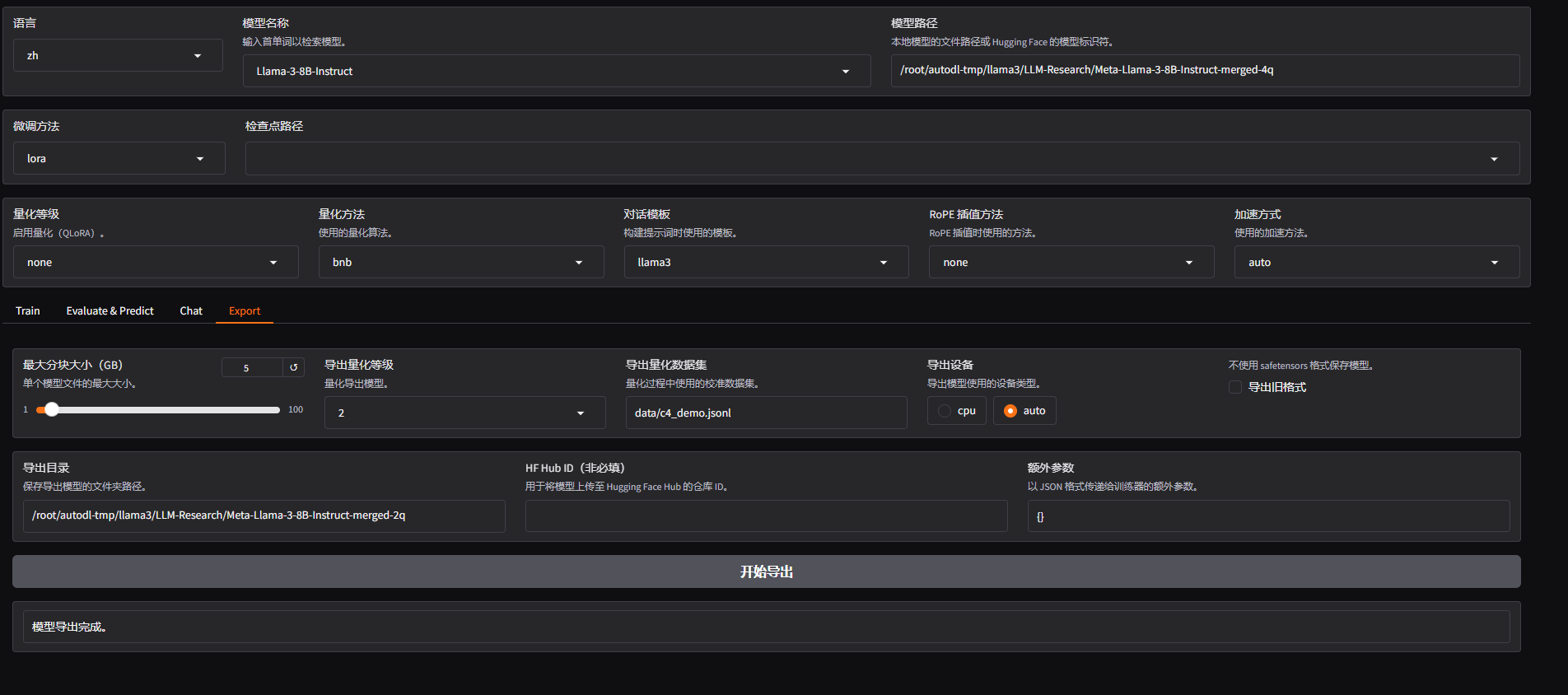
一开始会报确实optimum, 这个直接pip安装就好
pip install optimum
然后会报gptqmodel版本不匹配,这个很麻烦,下面是解决方法:
安装gptqmodel(也可以先在webui尝试一下,会报错“缺失gptqmodel”):
pip install gptqmodel
然后再安装vllm(为了可以正常部署大模型,这个版本是因为与现在的llamafactory版本匹配)
pip install vllm==0.8.5
此时会出现这个包(protobuf)冲突:
接着安装这个:
pip install --upgrade protobuf>=5.29.3
就可以正常使用llamafactory进行量化与部署了

















 1948
1948

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









