







大模型推理部署工具之vLLM系列文章:
文章目录
前言
首先介绍一下vLLM是什么?
vLLM 是一个快速且易用的用于 LLM 推理和服务的库。vLLM最初由UC Berkeley的Sky Computing Lab 开发,现已发展成为一个由学术界和工业界共同贡献的社区驱动项目。
- vLLM 论文:https://arxiv.org/abs/2309.06180
- Github地址:https://github.com/vllm-project/vllm
- vLLM官方文档(英文):https://docs.vllm.ai/en/latest/
- vLLM中文文档(中文):https://vllm-zh.llamafactory.cn/
- 官方博客(PagedAttention):https://blog.vllm.ai/2023/06/20/vllm.html
vLLM 的速度很快,因为它具有以下几个特点:
- 最先进的服务吞吐量
- 使用 PagedAttention 对注意力键和值内存进行高效管理
- 对传入请求进行连续批处理
- 使用 CUDA/HIP 图进行快速模型执行
- 量化:GPTQ、AWQ、INT4、INT8 和 FP8
- 优化的 CUDA 内核,包括与 FlashAttention 和 FlashInfer 的集成。
- 推测解码
- 分块预填充
一、vLLM的使用
1.1 安装方式
- Linux环境基于pip安装
pip install vllm
注意:为了提高性能,vLLM 必须编译许多 CUDA 内核。不幸的是,编译会引入与其他 CUDA 版本和 PyTorch 版本的二进制不兼容性,即使对于具有不同构建配置的相同 PyTorch 版本也是如此。
因此,建议使用 全新的conda环境 安装vLLM。如果你使用的是不同版本的CUDA,或者想要使用现有的PyTorch安装,你需要从源代码构建vLLM。请参阅以下说明。
- 推荐用 全新的conda环境 来安装vLLM,不然很可能出现PyTorch 版本不兼容的情况,出现报错。
- 整个vllm库的安装时间比较长,需要耐心等待。
- 基于源代码构建
git clone https://github.com/vllm-project/vllm.git
cd vllm
pip install -e . # This may take 5-10 minutes.
1.2 离线批处理推理(Offline Inference)
这里我们以 GLM-4-9B 和 GLM-4-9B-Chat 模型为例,来具体讲解如何使用vLLM进行推理及部署。
GLM-4-9B 官方Github地址:https://github.com/THUDM/GLM-4
官方提供了两种快速调用的方式:使用 transformers 后端进行推理 和 使用 vLLM 后端进行推理。本篇博客主要关注 使用 vLLM 后端进行推理 的方式。
(1)vLLM官方示例
参照vLLM官方示例,这里我们以 GLM-4-9B 基础版本 为例,给出了vLLM的推理方式,实现代码如下:
主要过程为:
-
从 vLLM 导入 LLM 和 SamplingParams 类。LLM 类是使用 vLLM 引擎进行离线推理的主要类。SamplingParams 类指定了采样过程的参数。
-
调用 llm.generate 生成输出。它将输入提示添加到 vLLM 引擎的等待队列中,并执行 vLLM 引擎以高吞吐量生成输出。
-
输出以 RequestOutput 对象列表的形式返回,其中包含所有输出标记。
示例代码如下:
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
model_path = "../../model/glm-4-9b"
llm = LLM(model=model_path, trust_remote_code=True, tensor_parallel_size=1) # tensor_parallel_size 代表使用的GPU数量
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
在上面的示例中,我们模拟了4条prompts并发的情况。
(2)GLM-4官方示例
参照vLLM官方示例,这里我们以 GLM-4-9B-chat 对话版本 为例,给出了vLLM的推理方式,实现代码如下:
from transformers import AutoTokenizer
from vllm import LLM, SamplingParams
# GLM-4-9B-Chat-1M
# max_model_len, tp_size = 1048576, 4
# 如果遇见 OOM (Out of Memory) 现象,建议减少max_model_len,或者增加tp_size
max_model_len, tp_size = 131072, 1
model_name = "../../model/glm-4-9b-chat"
prompt = [{"role": "user", "content": "你好"}]
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
llm = LLM(
model=model_name,
tensor_parallel_size=tp_size,
max_model_len=max_model_len,
trust_remote_code=True,
enforce_eager=True,
# GLM-4-9B-Chat-1M 如果遇见 OOM (Out of Memory) 现象,建议开启下述参数
# enable_chunked_prefill=True,
# max_num_batched_tokens=8192
)
stop_token_ids = [151329, 151336, 151338]
sampling_params = SamplingParams(temperature=0.95, max_tokens=1024, stop_token_ids=stop_token_ids)
inputs = tokenizer.apply_chat_template(prompt, tokenize=False, add_generation_prompt=True)
outputs = llm.generate(prompts=inputs, sampling_params=sampling_params)
print(outputs[0].outputs[0].text)
上述参数中:
- tensor_parallel_size 代表使用的GPU的数量,如果有多个GPU,可以增大该值。
- 如果遇见 OOM (Out of Memory) 现象,建议减少max_model_len,需要设置为2的指数次方。
- trust_remote_code 最好加上这个参数并设置为True,不然有时候会报错。
1.3 OpenAI 兼容服务器(OpenAI-Compatible Server)
参考官方文档:
vLLM 可以部署为实现 OpenAI API 协议的服务器。这允许 vLLM 用作使用 OpenAI API 的应用程序的直接替代品。
1.3.1 开启服务
默认情况下,它在 http://localhost:8000 上启动服务器。你可以使用 --host 和 --port 参数指定地址。该服务器目前一次只托管一个模型(下面命令中的 glm-4-9b),并实现了 列出模型、创建聊天完成 和 创建完成 等功能。
- 基于
vllm serve命令开启server:
vllm serve "../../model/glm-4-9b"
- 此服务器可以使用与OpenAI API相同的格式进行查询。例如,要列出模型:
curl http://localhost:8000/v1/models
- 也可以传入参数–api-key或环境变量VLLM_api_key,使服务器能够检查标头中的api密钥。如下所示:
vllm serve "../../model/glm-4-9b" \
--dtype auto \
--api-key token-abc123 (API KEY)
1.3.2 调用服务
服务器启动后,可以基于curl命令 或 OpenAI 客户端 来调用模型提供的服务。
(1)基于curl命令,使用输入提示调用模型服务:
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "../../model/glm-4-9b",
"prompt": "San Francisco is a",
"max_tokens": 7,
"temperature": 0
}'
(2)使用OpenAI客户端调用模型服务
由于此Server与OpenAI API兼容,因此可以使用官方的OpenAI Python客户端或任何其他HTTP客户端来要调用server提供的服务。
在上面开启服务部分,我们使用的是 Instruct 类型的模型,在调用服务时,
- instruct 类型的模型:使用
client.completions.create进行推理。 - chat 类型的模型:使用
client.chat.completions.create进行推理。
from openai import OpenAI
client = OpenAI(
base_url="http://localhost:8000/v1",
api_key="token-abc123",
)
# instruct 类型的模型
completion = client.completions.create(
model="../../model/glm-4-9b",
prompt="你好"
)
print(completion.choices[0].text)
如果是chat 类型的模型如glm-4-9b-chat,使用 client.chat.completions.create 进行推理:
# chat 类型的模型
completion = client.chat.completions.create(
model="../../model/glm-4-9b-chat",
messages=[
{"role": "user", "content": "Hello!"}
]
)
print(completion.choices[0].message)
二、vLLM的高吞吐量
关于PageAttention的介绍可以参考官方博客:https://blog.vllm.ai/2023/06/20/vllm.html
为了测试vLLM的吞吐量,vLLM官方主要做了两个实验,对比的模型加载方式分别为:
- HuggingFace Transformers (HF)
- HuggingFace Text Generation Inference (TGI)
加载的模型和GPU环境为:
- LLaMA-7B ,1个NVIDIA A10G GPU
- LLaMA-13B,1个NVIDIA A100 GPU (40GB)
我们来看看官方给出的实验结果:
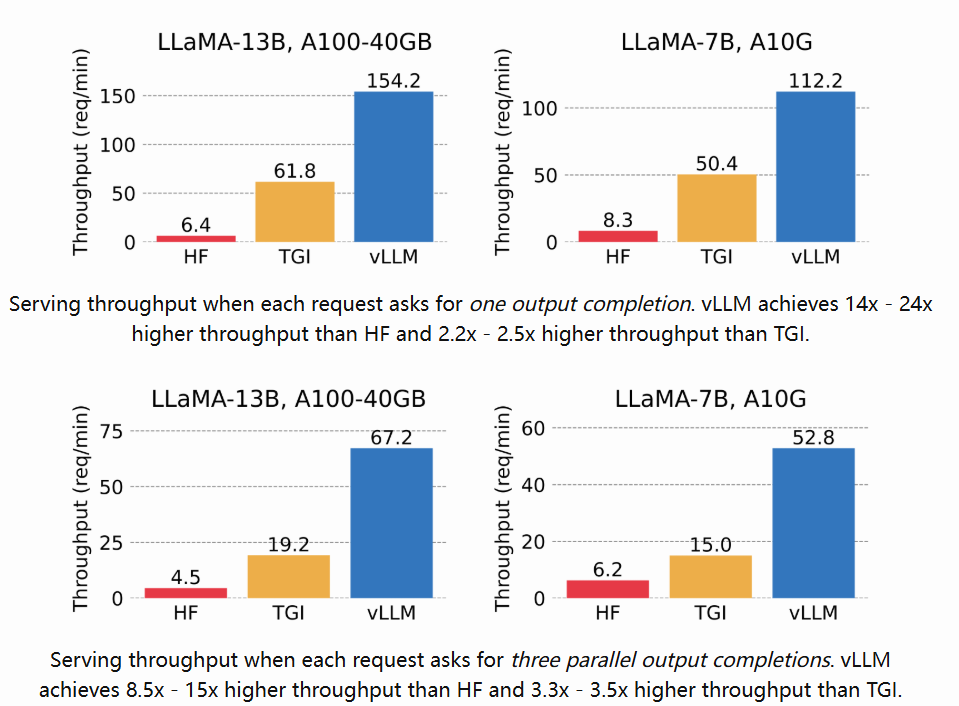
从实验结果可以看出vLLM的吞吐量比HF高出24倍,比TGI高出3.5倍。
那么为什么vLLM能做到这么大的吞吐量呢?这主要归功于它所使用的 PagedAttention 技术。
三、PagedAttention 技术
在vLLM中,我们发现LLM服务的性能受到内存的瓶颈。在自回归解码过程中,LLM的所有输入token都会产生它们的注意键(Key)和值(Value)张量,这些张量保存在GPU内存中以生成下一个令牌。 这些缓存的键和值张量通常被称为KV缓存。KV缓存具体以下特点:
- 大型:LLaMA-13B中的单个序列最多占用1.7GB。
- 动态:其大小取决于序列长度,这是高度可变和不可预测的。因此,高效管理KV缓存是一个重大挑战。我们发现,由于碎片化和过度保留,现有系统浪费了60%-80%的内存。
为了解决这个问题,引入了PagedAttention,这是一种受操作系统中虚拟内存和分页经典思想启发的注意力算法。与传统的注意力算法不同,PagedAttention允许在非连续的内存空间中存储连续的键和值。
因为块在内存中不需要是连续的,所以我们可以像在操作系统的虚拟内存中一样以更灵活的方式管理键和值:可以将块视为页面,将token视为字节,将序列视为进程。序列的连续逻辑块通过块表映射到非连续物理块。随着新token的生成,物理块会按需分配。
关于PagedAttention技术的详细介绍,可以参考博客: 【大模型】大模型推理部署工具之vLLM的核心技术-PagedAttention(2)

















 5419
5419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









