






《Deep Supervised Cross-modal Retrieval》论文阅读笔记
pipline
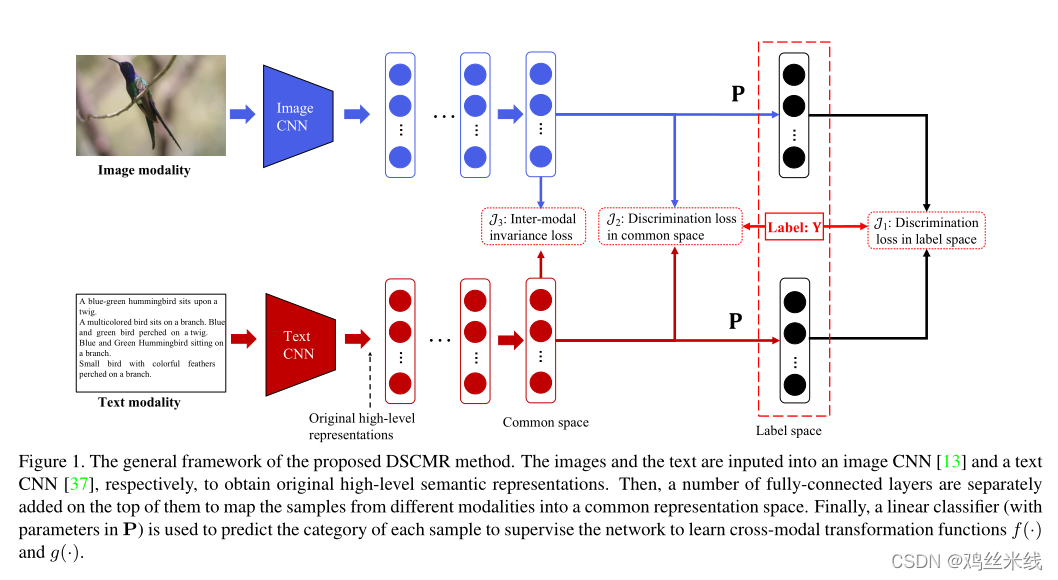
动机:定义了三个损失函数,最小化了标签空间和公共表示空间中的鉴别损失( discrimination loss),同时最小化模态不变性损失( modality invariance loss),并使用权重共享策略消除公共表示空间中多媒体数据的跨模态差异。
损失函数
标签空间的损失
U代表图像,V代表文本,Y代表标签
第一个目标是一个分类的 loss ,其中 Y 是label 的 one-hot 表示,计算一下分类结果与 Y 的差别。Frobenius norm 是对应元素的平方和再开方(可以理解成矩阵的 L2 范数)。
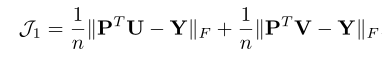
term1 = ((view1_predict-labels_1.float())**2).sum(1).sqrt().mean() + ((view2_predict-labels_2.float())**2).sum(1).sqrt().mean()
**公共表示空间中的损失 **
第二个误差包括三项。其中分别代表模态间的,图像模态的和文本模态的负对数似然。最小化负对数似然相当于最大化概率,这里的概率指的是两个特征属于同一个类别的概率。


负对数似然函数
余弦相似函数
计算a,b的相似度
如果向量a,b是二维的
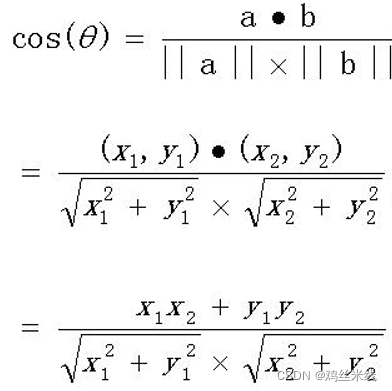
如果a,b向量是n维度的
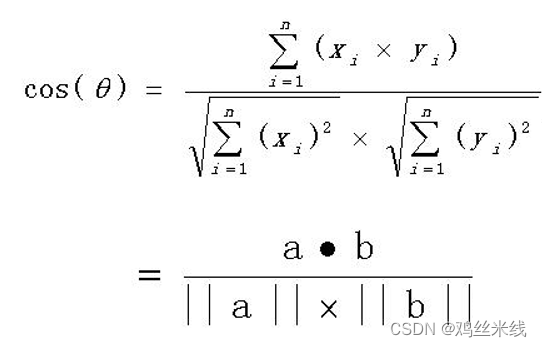
cos = lambda x, y: x.mm(y.t()) / ((x ** 2).sum(1, keepdim=True).sqrt().mm((y ** 2).sum(1, keepdim=True).sqrt().t())).clamp(min=1e-6) / 2.
theta11 = cos(view1_feature, view1_feature)
theta12 = cos(view1_feature, view2_feature)
theta22 = cos(view2_feature, view2_feature)
Sim11 = calc_label_sim(labels_1, labels_1).float()
Sim12 = calc_label_sim(labels_1, labels_2).float()
Sim22 = calc_label_sim(labels_2, labels_2).float()
term21 = ((1+torch.exp(theta11)).log() - Sim11 * theta11).mean()
term22 = ((1+torch.exp(theta12)).log() - Sim12 * theta12).mean()
term23 = ((1 + torch.exp(theta22)).log() - Sim22 * theta22).mean()
term2 = term21 + term22 + term23
模态不变性损失
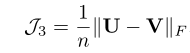
term3 = ((view1_feature - view2_feature)**2).sum(1).sqrt().mean()
损失函数
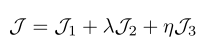
im_loss = term1 + alpha * term2 + beta * term3
模型框架
1.对于图像:利用预训练在 ImageNet 的网络提取出图像的 4096 维的特征作为原始的图像高级语义表达。然后后续是几个全连接层,来得到图像在公共空间中的表达。
2.对于文本:利用预训练在 Google News 上的 Word2Vec 模型,来得到 k 维的特征向量。一个句子可以表示为一个矩阵,然后使用一个 Text CNN 来得到原始的句子高级语义表达。之后也是同样的形式,后面是几个全连接层来得到句子在公共空间中的表达。
3.为了确保两个子网络能够为图像和文本学到公共的表达,我们使这两个子网络的最后几层共享权重。直觉上这样可以使得同一类的图片和文本生成尽可能相似的表达
4.最后面是一层全连接层来进行分类

class IDCM_NN(nn.Module):
"""Network to learn text representations"""
def __init__(self, img_input_dim=4096, img_output_dim=2048,
text_input_dim=1024, text_output_dim=2048, minus_one_dim=1024, output_dim=10):
super(IDCM_NN, self).__init__()
self.img_net = ImgNN(img_input_dim, img_output_dim)
self.text_net = TextNN(text_input_dim, text_output_dim)
self.linearLayer = nn.Linear(img_output_dim, minus_one_dim)
self.linearLayer2 = nn.Linear(minus_one_dim, output_dim)
def forward(self, img, text):
view1_feature = self.img_net(img)
view2_feature = self.text_net(text)
view1_feature = self.linearLayer(view1_feature)
view2_feature = self.linearLayer(view2_feature)
view1_predict = self.linearLayer2(view1_feature)
view2_predict = self.linearLayer2(view2_feature)
return view1_feature, view2_feature, view1_predict, view2_predict
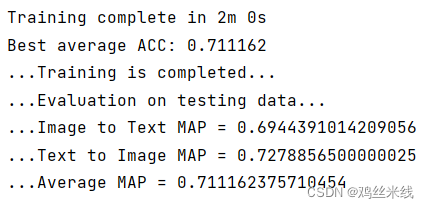
训练结果

















 838
838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









