






 本文介绍Pandas库中的高级数据处理技巧,包括数据分组计算、聚合统计、时间序列操作以及数据IO处理。详细讲解了如何使用groupby进行数据分组,应用自定义函数进行数据处理,以及如何利用Pandas处理时间序列数据,包括生成日期范围、时间频率转换和重采样等。
本文介绍Pandas库中的高级数据处理技巧,包括数据分组计算、聚合统计、时间序列操作以及数据IO处理。详细讲解了如何使用groupby进行数据分组,应用自定义函数进行数据处理,以及如何利用Pandas处理时间序列数据,包括生成日期范围、时间频率转换和重采样等。
分组计算
分组计算三步曲:拆分 -> 应用 -> 合并
拆分:根据什么进行分组?
应用:每个分组进行什么样的计算?
合并:把每个分组的计算结果合并起来。
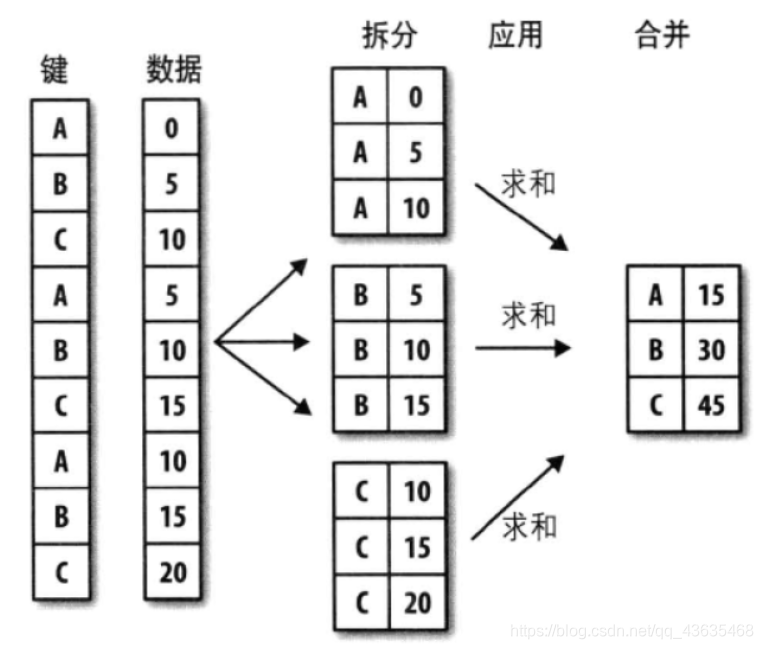
分组计算
创建一个DataFrame
df = pd.DataFrame({'key1': ['a', 'a', 'b', 'b', 'a'],
'key2': ['one', 'two', 'one', 'two', 'one'],
'data1': np.random.randint(1, 10, 5),
'data2': np.random.randint(1, 10, 5)})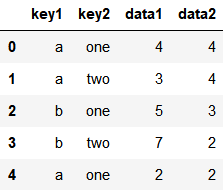
1、对 Series 分组
通过索引对齐关联起来
grouped = df['data1'].groupby(df['key1'])
print(f'mean:\n{grouped.mean()}\n')
print(f'sum:\n{grouped.sum()}\n')
print(f'first:\n{grouped.first()}')
# 运行结果
mean:
key1
a 3
b 6
Name: data1, dtype: int32
sum:
key1
a 9
b 12
Name: data1, dtype: int32
first:
key1
a 4
b 5
Name: data1, dtype: int32使用多个索引进行分组
df['data1'].groupby([df['key1'], df['key2']]).mean()
# 运行结果
key1 key2
a one 3
two 3
b one 5
two 7
Name: data1, dtype: int322、对 DataFrame 分组
df.groupby('key1').mean()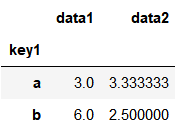
多索引分组
means = df.groupby(['key1', 'key2']).mean()
转换形式
means.unstack()
3、分组中的元素个数统计
df.groupby(['key1', 'key2']).size()
# 运行结果
key1 key2
a one 2
two 1
b one 1
two 1
dtype: int644、对分组进行迭代
for name, group in df.groupby('key1'):
print(name)
print(group)
# 运行结果
a
key1 key2 data1 data2
0 a one 4 4
1 a two 3 4
4 a one 2 2
b
key1 key2 data1 data2
2 b one 5 3
3 b two 7 2多索引
for name, group in df.groupby(['key1', 'key2']):
print(name)
print(group)
# 运行结果
('a', 'one')
key1 key2 data1 data2
0 a one 4 4
4 a one 2 2
('a', 'two')
key1 key2 data1 data2
1 a two 3 4
('b', 'one')
key1 key2 data1 data2
2 b one 5 3
('b', 'two')
key1 key2 data1 data2
3 b two 7 25、分组转化为字典
d = dict(list(df.groupby('key1')))
print(d)
# 运行结果
{'a': key1 key2 data1 data2
0 a one 4 4
1 a two 3 4
4 a one 2 2,
'b': key1 key2 data1 data2
2 b one 5 3
3 b two 7 2}查看字典元素
d['a']
6、按列分组
df.dtypes
# 运行结果
key1 object
key2 object
data1 int32
data2 int32
dtype: objectdf.groupby(df.dtypes, axis=1).sum()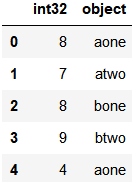
其他分组方法
1、通过字典进行分组
创建一个DataFrame
df = pd.DataFrame(np.random.randint(1, 10, (5, 5)),
columns=['a', 'b', 'c', 'd', 'e'],
index=['Alice', 'Bob', 'Candy', 'Dark', 'Emily'])
df.iloc[1, 1:3] = np.NaN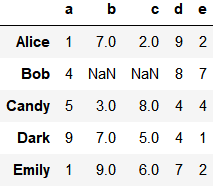
mapping = {'a': 'red', 'b': 'red', 'c': 'blue', 'd': 'orange', 'e': 'blue'}
grouped = df.groupby(mapping, axis=1)分组求和
grouped.sum()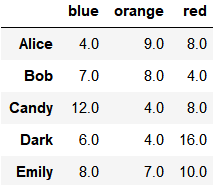
统计分组后每个位置包含的数据
grouped.count()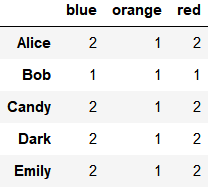
统计每个分组包含的数据
grouped.size()
# 运行结果
blue 2
orange 1
red 2
dtype: int642、通过函数分组
当函数作为分组依据时,数据表里的每个索引(可以是行索引,也可以是列索引)都会调用一次函数,函数的返回值作为分组的索引,即相同的返回值分在同一组。
创建一个DataFrame
df = pd.DataFrame(np.random.randint(1, 10, (5, 5)),
columns=['a', 'b', 'c', 'd', 'e'],
index=['Alice', 'Bob', 'Candy', 'Dark', 'Emily'])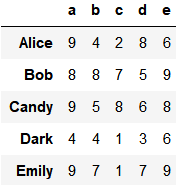
根据id长度分组
def _dummy_group(idx):
print(idx)
return(len(idx))
grouped = df.groupby(_dummy_group)
print(f'\nmean:\n{grouped.mean()}\n')
print(f'sum:\n{grouped.sum()}\n')
print(f'size:\n{grouped.size()}\n')
print(f'count:\n{grouped.count()}\n')
# 运行结果
Alice
Bob
Candy
Dark
Emily
mean:
a b c d e
3 8.0 8.000000 7.000000 5.0 9.000000
4 4.0 4.000000 1.000000 3.0 6.000000
5 9.0 5.333333 3.666667 7.0 7.666667
sum:
a b c d e
3 8 8 7 5 9
4 4 4 1 3 6
5 27 16 11 21 23
size:
3 1
4 1
5 3
dtype: int64
count:
a b c d e
3 1 1 1 1 1
4 1 1 1 1 1
5 3 3 3 3 33、通过索引级别进行分组
创建一个DataFrame
columns = pd.MultiIndex.from_arrays([['China', 'USA', 'China', 'USA', 'China'],
['A', 'A', 'B', 'C', 'B']], names=['country', 'index'])
df = pd.DataFrame(np.random.randint(1, 10, (5, 5)), columns=columns)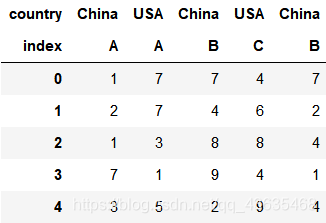
根据第一级列索引进行分组
grouped = df.groupby(level='country', axis=1)
print(f'sum:\n{grouped.sum()}\n')
print(f'count:\n{grouped.count()}\n')
# 运行结果
sum:
country China USA
0 15 11
1 8 13
2 13 11
3 17 5
4 9 14
count:
country China USA
0 3 2
1 3 2
2 3 2
3 3 2
4 3 2根据第二级列索引进行分组
grouped2 = df.groupby(level='index', axis=1)
print(f'sum:\n{grouped2.sum()}\n')
print(f'count:\n{grouped2.count()}\n')
# 运行结果
sum:
index A B C
0 8 14 4
1 9 6 6
2 4 12 8
3 8 10 4
4 8 6 9
count:
index A B C
0 2 2 1
1 2 2 1
2 2 2 1
3 2 2 1
4 2 2 1聚合统计
数据聚合
分组运算,先根据一定规则拆分后的数据,然后对数据进行聚合运算,如前面见到的 mean(),sum() 等就是聚合的例子。聚合时,拆分后的第一个索引指定的数据都会依次传给聚合函数进行运算。最后再把运算结果合并起来,生成最终结果。
创建一个DataFrame
df = pd.DataFrame({'key1': ['a', 'a', 'b', 'b', 'a'],
'key2': ['one', 'two', 'one', 'two', 'one'],
'data1': np.random.randint(1, 10, 5),
'data2': np.random.randint(1, 10, 5)})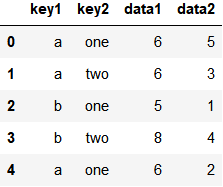
1、内置聚合函数
df.groupby('key1').describe()
2、自定义聚合函数 agg
聚合函数除了内置的 sum(), min(), max(), mean() 等等之外,还可以自定义聚合函数。自定义聚合函数时,使用 agg() 或 aggregate() 函数。
def peak(s):
return s.max() - s.min()
grouped = df.groupby('key1')
grouped.agg(peak)
3、一次性应用多个聚合函数
grouped.agg(['mean', 'std', peak])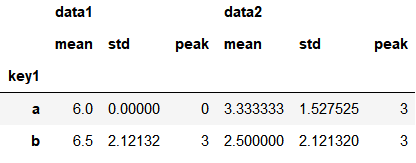
给聚合后的列取名
grouped['data1'].agg([('agerage', 'mean'), ('max-range', peak)])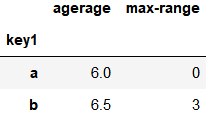
4、不同的列应用不同聚合函数
使用 dict 作为参数来实现
d = {'data1': ['mean', peak, 'max', 'min'],
'data2': 'sum'}
grouped.agg(d)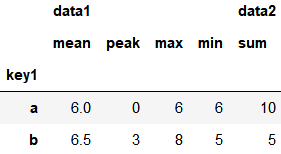
5、重置索引
grouped.agg(d).reset_index()
# 或者在分组之时重置 df.groupby('key1', as_index=False).agg(d)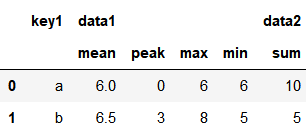
分组运算和转换
1、分组数据变换 transform
k1_mean = df.groupby('key1').mean().add_prefix('mean_')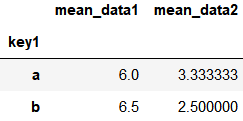
将结果转化为原表的格式并插入原来的表中
pd.merge(df, k1_mean, left_on='key1', right_index=True)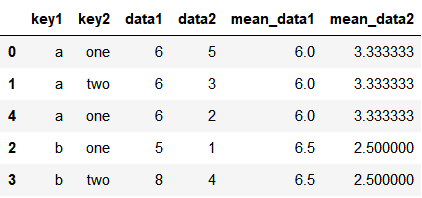
使用 transform 简化处理
k1_mean = df.groupby('key1').transform(np.mean).add_prefix('mean_')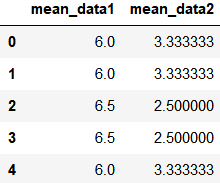
插入原表中
df[k1_mean.columns] = k1_mean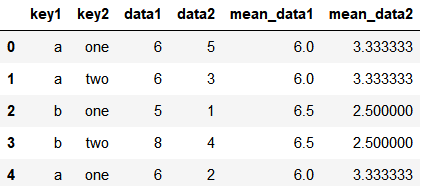
使用自定义函数
def demean(s):
return s - s.mean()
demeaned = df.groupby('key1').transform(demean)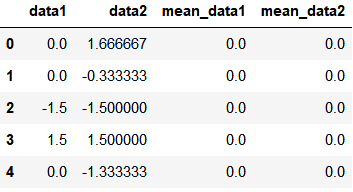
2、自定义数据处理 apply
DataFrame 的 apply 函数是逐行或逐列来处理数据,GroupBy 的 apply 函数对每个分组进行计算。
创建一个DataFrame
df = pd.DataFrame({'key1': ['a', 'a', 'b', 'b', 'a', 'a', 'a', 'b', 'b', 'a'],
'key2': ['one', 'two', 'one', 'two', 'one', 'one', 'two', 'one', 'two', 'one'],
'data1': np.random.randint(1, 10, 10),
'data2': np.random.randint(1, 10, 10)})
根据 column 排序,输出其最大的 n 行数据
def top(df, n=2, column='data1'):
return df.sort_values(by=column, ascending=False)[:n]
df.groupby('key1').apply(top)
传递参数
df.groupby('key1').apply(top, n=3, column='data2')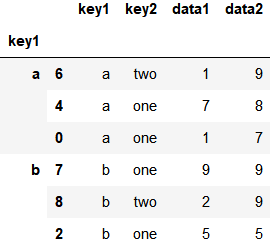
禁用分组键
df.groupby('key1', group_keys=False).apply(top)
apply 应用示例:用不同的分组平均值填充空缺数据
states = ['Ohio', 'New York', 'Vermont', 'Florida',
'Oregon', 'Nevada', 'California', 'Idaho']
data = pd.Series(np.random.randn(8), index=states)
data[['Vermont', 'Nevada', 'Idaho']] = np.nan
print(data)
# 运行结果
Ohio 0.078612
New York 0.418883
Vermont NaN
Florida -0.713649
Oregon 0.569255
Nevada NaN
California -1.027527
Idaho NaN
dtype: float64分组求平均值
group_key = ['East'] * 4 + ['West'] * 4
data.groupby(group_key).mean()
# 运行结果
East -0.072051
West -0.229136
dtype: float64用分组平均值填充空缺数据
fill_mean = lambda g: g.fillna(g.mean())
data.groupby(group_key).apply(fill_mean)
# 运行结果
Ohio 0.078612
New York 0.418883
Vermont -0.072051
Florida -0.713649
Oregon 0.569255
Nevada -0.229136
California -1.027527
Idaho -0.229136
dtype: float64数据IO
1、载入数据到 Pandas
索引:将一个列或多个列读取出来构成 DataFrame,其中涉及是否从文件中读取索引以及列名
类型推断和数据转换:包括用户自定义的转换以及缺失值标记
日期解析
迭代:针对大文件进行逐块迭代,这个是Pandas和Python原生的csv库的最大区别
不规整数据问题:跳过一些行,或注释等等
2、索引及列名
自带列名的数据
ex1.csv
a,b,c,d,message
1,2,3,4,hello
5,6,7,8,world
9,10,11,12,foodf = pd.read_csv('data/ex1.csv')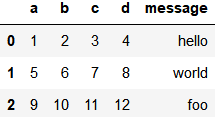
缺失列名的数据
ex2.csv
1,2,3,4,hello
5,6,7,8,world
9,10,11,12,foo直接读取将自动分配索引及列名
pd.read_csv('data/ex2.csv', header=None)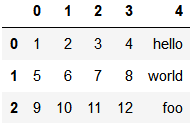
也可指定列名
pd.read_csv('data/ex2.csv', header=None, names=['a', 'b', 'c', 'd', 'msg'])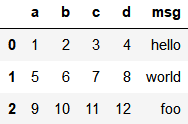
指定行索引
pd.read_csv('data/ex2.csv', header=None, names=['a', 'b', 'c', 'd', 'msg'], index_col='msg')
多层行索引
pd.read_csv('data/ex2.csv', header=None, names=['a', 'b', 'c', 'd', 'msg'], index_col=['msg', 'a'])
3、处理不规则的分隔符
ex3.csv
A B C
aaa -0.264438 -1.026059 -0.619500
bbb 0.927272 0.302904 -0.032399
ccc -0.264273 -0.386314 -0.217601
ddd -0.871858 -0.348382 1.100491利用正则表达式
pd.read_table('data/ex3.csv', sep='\s+')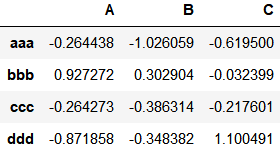
4、缺失值处理
ex5.csv
something,a,b,c,d,message
one,1,2,3,4,NA
two,5,6,,8,world
three,9,10,11,12,foopd.read_csv('data/ex5.csv')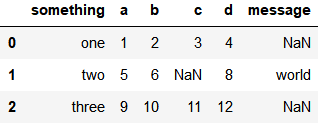
可指定特定的字符为NaN
pd.read_csv('data/ex5.csv', na_values=['NA', 'NULL', 'foo'])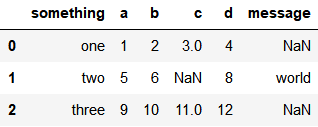
也可指定不同列下不同的字符为NaN
pd.read_csv('data/ex5.csv', na_values={'message': ['foo', 'NA'], 'something': ['two']})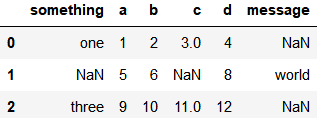
5、逐块读取数据
读取10行
pd.read_csv('data/ex6.csv', nrows=10)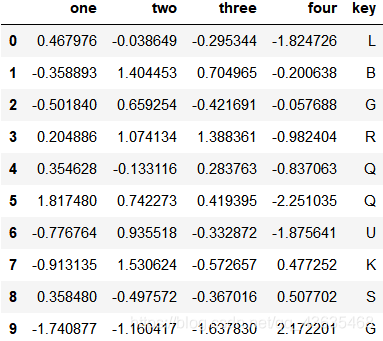
每次读取1000条,逐块读取,统计每个key值出现的次数,并显示前10个
tr = pd.read_csv('data/ex6.csv', chunksize=1000)
key_count = pd.Series([])
for pieces in tr:
key_count = key_count.add(pieces['key'].value_counts(), fill_value=0)
key_count = key_count.sort_values(ascending=False)
print(key_count.sum())
print(key_count[:10])
# 运行结果
10000.0
E 368.0
X 364.0
L 346.0
O 343.0
Q 340.0
M 338.0
J 337.0
F 335.0
K 334.0
H 330.0
dtype: float646、保存数据到磁盘
df:
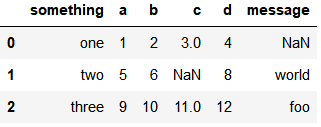
df.to_csv('data/ex5_out.csv')
# 运行结果
,something,a,b,c,d,message
0,one,1,2,3.0,4,
1,two,5,6,,8,world
2,three,9,10,11.0,12,foo不写索引
df.to_csv('data/ex5_out.csv', index=False)
# 运行结果
something,a,b,c,d,message
one,1,2,3.0,4,
two,5,6,,8,world
three,9,10,11.0,12,foo指定分隔符
df.to_csv('data/ex5_out.csv', index=False, sep='|')
# 运行结果
something|a|b|c|d|message
one|1|2|3.0|4|
two|5|6||8|world
three|9|10|11.0|12|foo只写出一部分列
df.to_csv('data/ex5_out.csv', index=False, columns=['a', 'b', 'message'])
# 运行结果
a,b,message
1,2,
5,6,world
9,10,foo7、二进制数据
二进制的优点是容量小,读取速度快。缺点是可能在不同版本间不兼容。比如 Pandas 版本升级后,早期版本保存的二进制数据可能无法正确地读出来。
8、其他格式简介
HDF5: HDF5是个C语言实现的库,可以高效地读取磁盘上的二进制存储的科学数据;
Excel文件: pd.read_excel/pd.ExcelFile/pd.ExcelWriter;
JSON: 通过 json 模块转换为字典,再转换为 DataFrame;
SQL 数据库:通过 pd.io.sql 模块来从数据库读取数据NoSQL ;(MongoDB) 数据库:需要结合相应的数据库模块,如 pymongo 。再通过游标把数据读出来,转换为 DataFrame。
时间序列
时间戳 tiimestamp:固定的时刻 -> pd.Timestamp;
固定时期 period:比如 2016年3月份,再如2015年-> pd.Period;
时间间隔 interval:由起始时间和结束时间来表示,固定时期是时间间隔的一个特殊。
Python 里的 datetime
python 标准库里提供了时间日期的处理,这个是时间日期的基础。
1、时间戳
from datetime import datetime
from datetime import timedelta
now = datetime.now()
print(now)
print(now.year, now.month, now.day)
# 运行结果
2020-03-23 23:32:21.012478
2020 3 232、时间间隔
date1 = datetime(2020, 3, 20)
date2 = datetime(2020, 3, 16)
delta = date1 - date2
print(delta)
print(delta.days)
print(delta.seconds)
print(delta.total_seconds())
# 运行结果
4 days, 0:00:00
4
0
345600.0时间间隔运算
print(date2 + delta)
print(date2 + timedelta(4.5))
# 运行结果
2020-03-20 00:00:00
2020-03-20 12:00:003、字符串和 datetime 转换
date = datetime(2020, 3, 20, 8, 30)
print(date)
print(type(date))
# 运行结果
2020-03-20 08:30:00
<class 'datetime.datetime'>datetime转化为字符串
s = str(date)
print(s)
print(type(s))
# 运行结果
2020-03-20 08:30:00
<class 'str'>字符串转化为datetime
datetime.strptime('2020-03-20 09:30', '%Y-%m-%d %H:%M')
# 运行结果
datetime.datetime(2020, 3, 20, 9, 30)Pandas 里的时间序列
Pandas 里使用 Timestamp 来表达时间。
dates = [datetime(2020, 3, 1), datetime(2020, 3, 2), datetime(2020, 3, 3), datetime(2020, 3, 4)]
s = pd.Series(np.random.randn(4), index=dates)
print(s)
# 运行结果
2020-03-01 -0.740597
2020-03-02 1.465628
2020-03-03 1.077524
2020-03-04 -0.415087
dtype: float64查看索引的类型
print(type(s.index))
print(type(s.index[0]))
# 运行结果
<class 'pandas.core.indexes.datetimes.DatetimeIndex'>
<class 'pandas._libs.tslibs.timestamps.Timestamp'>日期范围
1、生成日期范围
pd.date_range('20200320', '20200331')
# 运行结果
DatetimeIndex(['2020-03-20', '2020-03-21', '2020-03-22', '2020-03-23',
'2020-03-24', '2020-03-25', '2020-03-26', '2020-03-27',
'2020-03-28', '2020-03-29', '2020-03-30', '2020-03-31'],
dtype='datetime64[ns]', freq='D')输入启始及数目
pd.date_range(start='20200320', periods=10)
# 运行结果
DatetimeIndex(['2020-03-20', '2020-03-21', '2020-03-22', '2020-03-23',
'2020-03-24', '2020-03-25', '2020-03-26', '2020-03-27',
'2020-03-28', '2020-03-29'],
dtype='datetime64[ns]', freq='D')2、时间频率
按星期递增
pd.date_range(start='20200320', periods=10, freq='W')
# 运行结果
DatetimeIndex(['2020-03-22', '2020-03-29', '2020-04-05', '2020-04-12',
'2020-04-19', '2020-04-26', '2020-05-03', '2020-05-10',
'2020-05-17', '2020-05-24'],
dtype='datetime64[ns]', freq='W-SUN')按月递增
pd.date_range(start='20200320', periods=10, freq='M')
# 运行结果
DatetimeIndex(['2020-03-31', '2020-04-30', '2020-05-31', '2020-06-30',
'2020-07-31', '2020-08-31', '2020-09-30', '2020-10-31',
'2020-11-30', '2020-12-31'],
dtype='datetime64[ns]', freq='M')每个月最后一个工作日组成的索引
pd.date_range(start='20200320', periods=10, freq='BM')
# 运行结果
DatetimeIndex(['2020-03-31', '2020-04-30', '2020-05-29', '2020-06-30',
'2020-07-31', '2020-08-31', '2020-09-30', '2020-10-30',
'2020-11-30', '2020-12-31'],
dtype='datetime64[ns]', freq='BM')按小时递增
pd.date_range(start='20200320', periods=10, freq='4H')
# 运行结果
DatetimeIndex(['2020-03-20 00:00:00', '2020-03-20 04:00:00',
'2020-03-20 08:00:00', '2020-03-20 12:00:00',
'2020-03-20 16:00:00', '2020-03-20 20:00:00',
'2020-03-21 00:00:00', '2020-03-21 04:00:00',
'2020-03-21 08:00:00', '2020-03-21 12:00:00'],
dtype='datetime64[ns]', freq='4H')时期及算术运算
pd.Period 表示时期,比如几日,月或几个月等。比如用来统计每个月的销售额,就可以用时期作为单位。
p1 = pd.Period(2020)
print(p1)
print(type(p1))
# 运行结果
2020
<class 'pandas._libs.tslibs.period.Period'>p2 = p1 + 2
print(p2)
print(type(p2))
# 运行结果
2022
<class 'pandas._libs.tslibs.period.Period'>以月为单位
p1 = pd.Period(2020, freq='M')
p2 = p1 + 3
print(p1)
print(p2)
print(type(p1))
print(type(p2))
# 运行结果
2020-01
2020-04
<class 'pandas._libs.tslibs.period.Period'>
<class 'pandas._libs.tslibs.period.Period'>1、时期序列
与日期序列相似
输入起始及数目,按月递增
pd.period_range(start='2020-01', periods=12, freq='M')
# 运行结果
PeriodIndex(['2020-01', '2020-02', '2020-03', '2020-04', '2020-05', '2020-06',
'2020-07', '2020-08', '2020-09', '2020-10', '2020-11', '2020-12'],
dtype='period[M]', freq='M')输入起始与结束,按月递增
pd.period_range(start='2020-01', end='2020-10', freq='M')
# 运行结果
PeriodIndex(['2020-01', '2020-02', '2020-03', '2020-04', '2020-05', '2020-06',
'2020-07', '2020-08', '2020-09', '2020-10'],
dtype='period[M]', freq='M')2、时期的频率转换
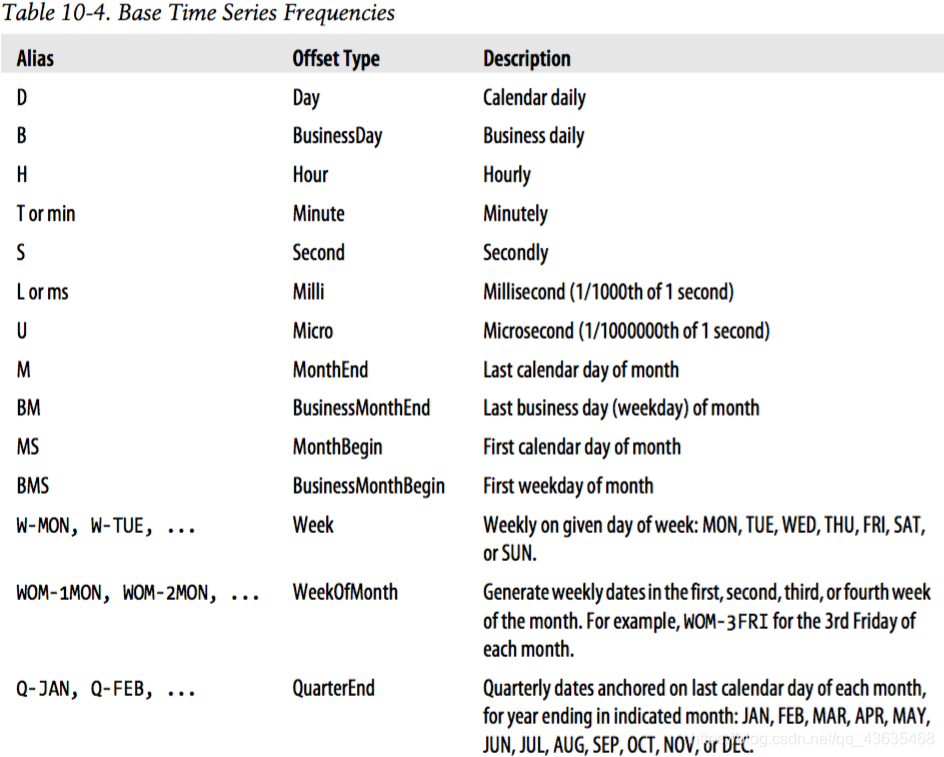
A-DEC: 以 12 月份作为结束的年时期
A-NOV: 以 11 月份作为结束的年时期
Q-DEC: 以 12 月份作为结束的季度时期
······
3、季度时间频率
Pandas 支持 12 种季度型频率,从 Q-JAN 到 Q-DEC。
p = pd.Period('2020Q4', 'Q-JAN')
p
#运行结果
Period('2020Q4', 'Q-JAN')以 1 月份结束的财年中,2020Q4 的时期是指 2019-11-1 到 2020-1-31
p.asfreq('D', how='start'), p.asfreq('D', how='end')
#运行结果
(Period('2019-11-01', 'D'), Period('2020-01-31', 'D'))获取该季度倒数第二个工作日下午4点的时间戳
p4pm = (p.asfreq('B', how='end') - 1).asfreq('T', 'start') + 16 * 60
p4pm
#运行结果
Period('2020-01-30 16:00', 'T')4、Timestamp 和 Period 相互转换
ts = pd.Series(np.random.randn(5), index = pd.date_range('2020-01-01', periods=5, freq='M'))
ts
# 运行结果
2020-01-31 -1.486640
2020-02-29 0.520976
2020-03-31 0.211298
2020-04-30 -0.493519
2020-05-31 -0.073244
Freq: M, dtype: float64转化为Period
pts = ts.to_period()
pts
# 运行结果
2020-01 -1.486640
2020-02 0.520976
2020-03 0.211298
2020-04 -0.493519
2020-05 -0.073244
Freq: M, dtype: float64转化为Period,以星期为单位
pts = ts.to_period(freq='W')
pts
# 运行结果
2020-01-27/2020-02-02 -1.486640
2020-02-24/2020-03-01 0.520976
2020-03-30/2020-04-05 0.211298
2020-04-27/2020-05-03 -0.493519
2020-05-25/2020-05-31 -0.073244
Freq: W-SUN, dtype: float64转化为Timestamp
pts.to_timestamp()
# 运行结果
2020-01-31 -1.486640
2020-02-29 0.520976
2020-03-31 0.211298
2020-04-30 -0.493519
2020-05-31 -0.073244
dtype: float64重采用
降采样:高频率 -> 低频率。例,5 分钟股票交易数据转换为日交易数据;
升采样 :低频率 -> 高频率 ;
其他重采样:例,每周三 (W-WED) 转换为每周五 (W-FRI)
例:将每分钟采集一次的数据重采样为每五分钟一次,数据处理方式为相加
生成数据
ts = pd.Series(np.random.randint(0, 50, 60), index=pd.date_range('2020-02-25 09:30', periods=60, freq='T'))
ts
# 运行结果
2020-02-25 09:30:00 15
2020-02-25 09:31:00 6
2020-02-25 09:32:00 47
2020-02-25 09:33:00 11
2020-02-25 09:34:00 42
2020-02-25 09:35:00 28
2020-02-25 09:36:00 10
2020-02-25 09:37:00 35
2020-02-25 09:38:00 23
2020-02-25 09:39:00 43
2020-02-25 09:40:00 34
······重采样为5分钟一个数据
ts.resample('5min').sum()
# 运行结果
2020-02-25 09:30:00 121
2020-02-25 09:35:00 139
2020-02-25 09:40:00 138
2020-02-25 09:45:00 83
2020-02-25 09:50:00 108
2020-02-25 09:55:00 172
2020-02-25 10:00:00 133
2020-02-25 10:05:00 95
2020-02-25 10:10:00 140
2020-02-25 10:15:00 103
2020-02-25 10:20:00 101
2020-02-25 10:25:00 105
Freq: 5T, dtype: int321、OHLC 重采样
金融数据专用,代表open开盘数据、high最高数据、low最低数据、close收盘数据。
ts.resample('5min').ohlc()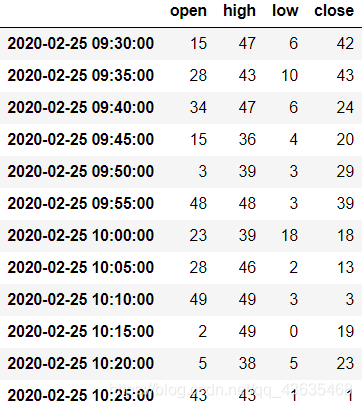
2、通过 groupby 重采样
利用lambda将每个小时内的数据分组求和
ts.groupby(lambda x: x.hour).sum()
# 运行结果
9 761
10 677
dtype: int32将索引转化为period后分组求和
ts.groupby(ts.index.to_period('H')).sum()
# 运行结果
2020-02-25 09:00 761
2020-02-25 10:00 677
Freq: H, dtype: int323、升采样和插值
以周为单位,每周五采样
df = pd.DataFrame(np.random.randint(1, 50, 2), index=pd.date_range('2020-02-22', periods=2, freq='W-FRI'))
df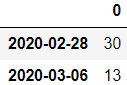
升采样为天,用前面的数值填充空值,并指定填充个数
df.resample('D').ffill(limit=3) #用后面的值填充为bfill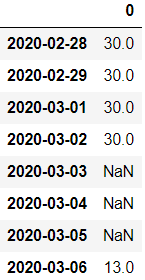
4、时期重采样
df = pd.DataFrame(np.random.randint(2, 30, (12, 4)),
index=pd.period_range('2019-07', '2020-6', freq='M'),
columns=list('ABCD'))
df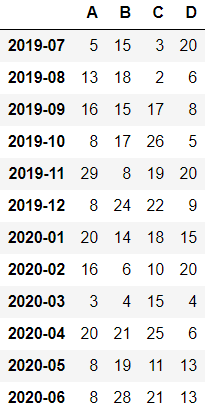
转化为以年为周期
adf = df.resample('A-DEC').mean()
adf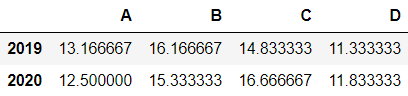
5、时间日期解析
从文件中直接读取信息时,日期不进行解析,类别为object
df = pd.read_csv('data/002001.csv', index_col='Date')
df.index
# 运行结果
Index(['2015-12-22', '2015-12-21', '2015-12-18', '2015-12-17', '2015-12-16'
,···,
'2015-10-06', '2015-10-05', '2015-10-02', '2015-10-01'],
dtype='object', name='Date')加上parse_dates=True可以对时间日期进行解析
df = pd.read_csv('data/002001.csv', index_col='Date', parse_dates=True)
df.index
# 运行结果
DatetimeIndex(['2015-12-22', '2015-12-21', '2015-12-18', '2015-12-17','2015-12-16'
,···,
'2015-10-06','2015-10-05', '2015-10-02', '2015-10-01'],
dtype='datetime64[ns]', name='Date', freq=None)
















 2188
2188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









