




 本文介绍了一种使用Java和HtmlUnit库爬取唐诗三百首网页的方法,通过构造无界面浏览器,禁用JS和CSS,高效获取每首诗的详情页URL。
本文介绍了一种使用Java和HtmlUnit库爬取唐诗三百首网页的方法,通过构造无界面浏览器,禁用JS和CSS,高效获取每首诗的详情页URL。
目的:
获取到当前访问的网页,包括其内容及布局等。以便我们后期获取每一首诗。即把当前网页以html文件形式保存至本地。
步骤:
(1)通过HttpClient请求到达某网页的url访问地址
(2)获取网页源码
(3)查看源码中我们需要的模块的标签属性等
(4)从列表页上获取到每一首唐诗的详情页url
具体实现:
1) 构造(模拟)一个无界面的浏览器,构造方法中可传入浏览器版本,以BrowserVersion.xxx的形式
WebClient webClient = new WebClient(BrowserVersion.CHROME);
2) 为了加快页面的访问速度,禁用js和css脚本。
htmlunit默认是会对网页中的css、js解析的,对于一般的非Js加载页面采集,我们可以把css、javascript解析去掉,这样可以提高效率。
//关闭了浏览器中的js执行引擎
webClient.getOptions ().setJavaScriptEnabled (false);
//关闭了浏览器中的ccs执行引擎
webClient.getOptions ().setCssEnabled (false);
3) 获取页面源码,其中传入的是当前需要获取的页面网址。
HtmlPage page = webClient.getPage ("https://so.gushiwen.org/gushi/tangshi.aspx");
File file = new File ("唐诗三百首\\列表页.html");
4) 根据源码的标签属性等拿到我们需要的内容,即每一首诗详情页的url。
从得到的网页源码中找到我们需要的内容,或者在当前网页,打开开发者工具,查看源码。
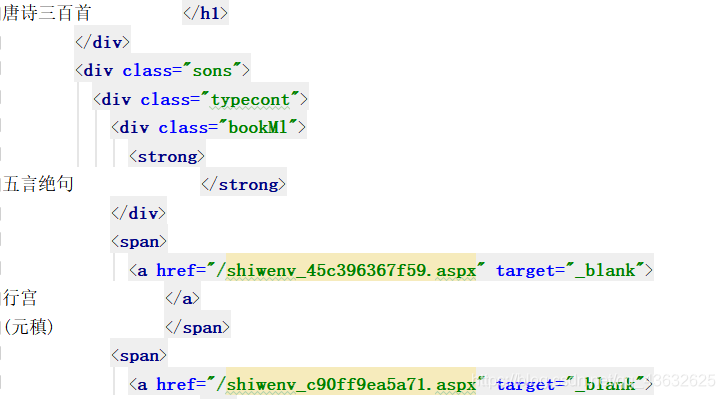
对应到当前网页当前模块:
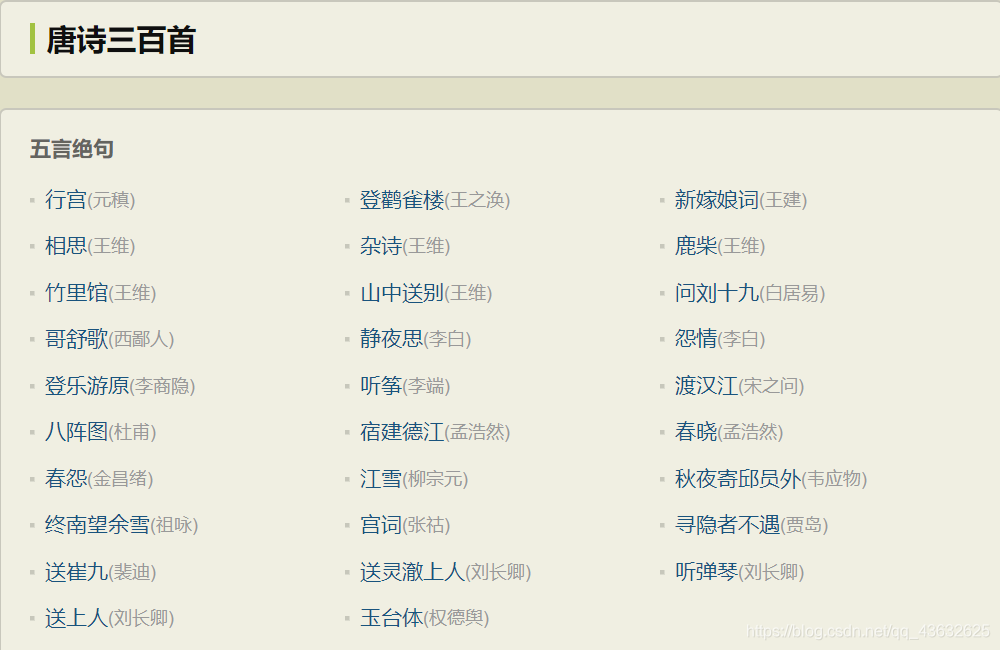
所有的唐诗都在 “唐诗三百首” 这个模块中,是我们需要的内容,则根据当前模块的标签将其提取出来。
HtmlElement body = page.getBody ();
List<HtmlElement> elements = body.getElementsByAttribute
("div","class","typecont");
System.out.println ("获取到的每首唐诗的url:");
4) 得到每一首诗的url。
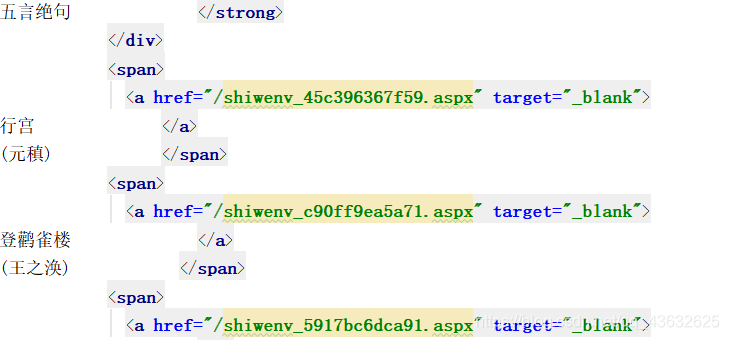
从源码中得出每一首唐诗的详情页url,将其解析出来。根据此url我们可以找到每一首唐诗的详情页。
for(HtmlElement e : elements){
List<HtmlElement> aElements = e.getElementsByTagName ("a");
for(HtmlElement a : aElements){
System.out.println (a.getAttribute ("href"));
}
}
此时我们已经完成了获取列表页的全部任务。得到了每一首唐诗的详情页url。
此过程中,用到了很多不常见的类和方法,我们来了解一下:
(1)页面请求需要依赖的第三方库 HtmlUnit。
- HtmlUnit是一个无界面浏览器Java程序。它为HTML文档建模,提供了调用页面、填写表单、单击链接等操作的API。模拟浏览器的操作。
- HtmlUnit不错的JavaScript支持(不断改进),甚至可以使用相当复杂的AJAX库,根据配置的不同模拟Chrome、Firefox或Internet Explorer等浏览器。
- HtmlUnit通常用于测试或从web站点检索信息。
配置本地Maven仓库:
<dependency>
<groupId>net.sourceforge.htmlunit</groupId>
<artifactId>htmlunit</artifactId>
<version>2.36.0</version>
</dependency>
(2)WebClient
- 构造一个webclient,可以指定各类浏览器。
WebClient webClient = new WebClient(BrowserVersion.CHROME);
(3)HtmlPage 和 WebClient.getPage()
- WebClient.getPage(),传入url,获得指定url的页面对象,它包含页面的所有内容。
- 接受到的页面用 HtmlPage 接收。
HtmlPage page = webClient.getPage ("https://www.baidu.com");
(4)getElementsByAttribute()
通过页面对象获取页面中指定属性元素,可以得到此元素的所有相关信息。
HtmlElement elements = body.getElementsByAttribute
("div","class","typecont");
(5)getElementsByTagName()
通过页面对象获取页面中指定标签元素,可以得到此元素的所有相关信息。
HtmlElement aElements = e.getElementsByTagName ("a");

















 971
971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









