







DeepRapper
论文解说:DeepRapper 论文
readme
DeepRapper: Neural Rap Generation with Rhyme and Rhythm Modeling, by Lanqing Xue, Kaitao Song, Duocai Wu, Xu Tan, Nevin L. Zhang, Tao Qin, Wei-Qiang Zhang, Tie-Yan Liu, ACL 2021,是一个基于Transformer的RAP生成系统,它可以模拟韵律和节奏。它以相反的顺序生成歌词,具有押韵表示和韵律增强的约束,并在歌词中插入节拍符号,用于节奏/节拍建模。据我们所知,DeepRapper是第一个同时产生押韵和节奏的说唱的系统。
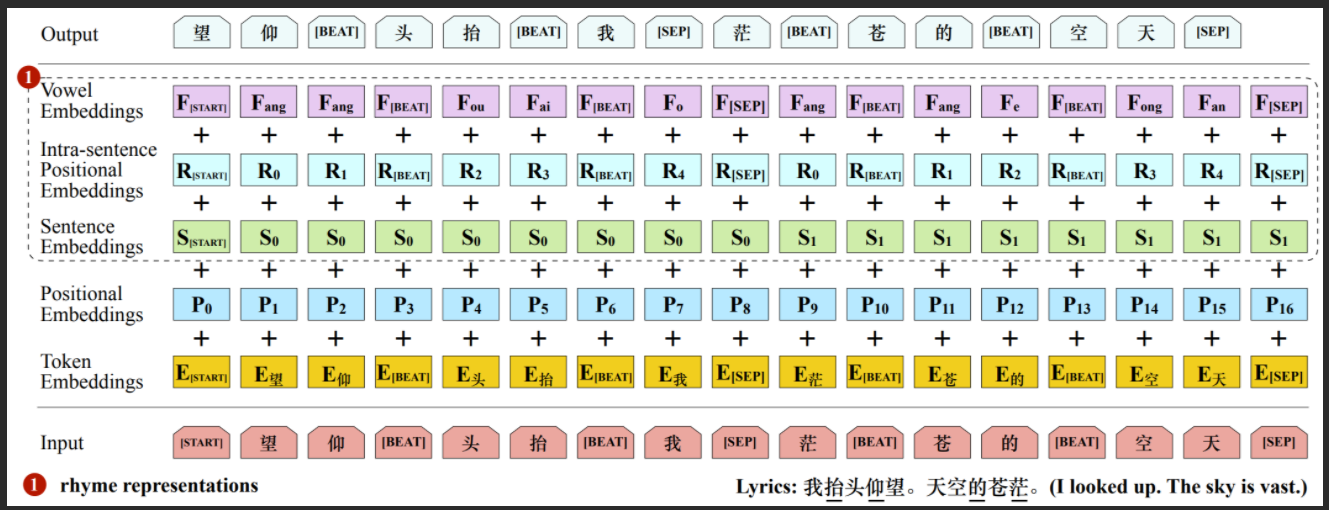
The input and output representation of DeepRapper model
1. Data Preparation
为每首歌准备歌词和拼音。我们提供了一些数据样本 in DeepRapper/data/.
├── data
│ └── lyrics
│ └── lyrics_samples
│ └── raw
│ └── singer01
│ └── album01
│ ├── song01
│ │ ├── lyric_with_beat_global.txt
│ │ └── mapped_final_with_beat_global.txt
│ └── song02
│ ├── lyric_with_beat_global.txt
│ └── mapped_final_with_beat_global.txt
Here is a sample of lyric_with_beat_global.txt:
20_[01:12.56][BEAT]那就[BEAT]让我再沉[BEAT]沦这一世
21_[01:14.49][BEAT]不理[BEAT]解早已[BEAT]经不止一次
22_[01:16.59][BEAT]那就[BEAT]让我孤[BEAT]注最后一掷
23_[01:18.61][BEAT]不想昏[BEAT]暗之中[BEAT]度过每日
24_[01:20.60][BEAT]那就[BEAT]让我再[BEAT]沉沦这一世
25_[01:22.48][BEAT]不理[BEAT]解早已[BEAT]经不止一次
26_[01:24.58][BEAT]那就[BEAT]让我孤[BEAT]注最后一掷
27_[01:26.47][BEAT]不想昏[BEAT]暗之[BEAT]中度过每日
Here is a sample of mapped_final_with_beat_global.txt:
20_[01:12.56][BEAT] a ou [BEAT] ang o ai en [BEAT] en e i i
21_[01:14.49][BEAT] u i [BEAT] ie ao i [BEAT] in u i i i
22_[01:16.59][BEAT] a ou [BEAT] ang o u [BEAT] u ei ou i i
23_[01:18.61][BEAT] u ang en [BEAT] an i ong [BEAT] u o ei i
24_[01:20.60][BEAT] a ou [BEAT] ang o ai [BEAT] en en e i i
25_[01:22.48][BEAT] u i [BEAT] ie ao i [BEAT] in u i i i
26_[01:24.58][BEAT] a ou [BEAT] ang o u [BEAT] u ei ou i i
27_[01:26.47][BEAT] u ang en [BEAT] an i [BEAT] ong u o ei i
2. Training & Generation
我们提供了一个训练和生成的示例脚本.
train
To train run:
bash train.sh
When training, you may see the logs:
starting training
epoch 1
time: 2021-xx-xx 11:17:57.067011
51200
now time: 11:17. Step 10 of piece 0 of epoch 1, loss 9.587631130218506
now time: 11:18. Step 20 of piece 0 of epoch 1, loss 9.187388515472412
你可以在bash文件中指定参数,如number of epoch, bach size, etc.
经过训练的模型被保存在 [model_dir]/lyrics/[raw_data_dir][_reverse]/[model_sign]/final_model.
For example, in the default train.sh, the path is model/lyrics/lyrics_samples_reverse/samples/final_model.
generate
To generate by the trained DeepRapper, run
bash generate.sh
您可以在bash文件中指定参数,例如 beam width, number of samples, etc.
For 获取更多生成的样本, visit https://ai-muzic.github.io/deeprapper/.
3. Pretrained Model
You can download a pretrained DeepRapper https://msramllasc.blob.core.windows.net/modelrelease/deeprapper-model.zip.
To generate by our provided pretrained DeepRapper, first unzip the pretrained DeepRapper. Then, put the unzipped directory deeprapper-model under the folder model/. 因此,完整的路径如下:
├── model
│ └── deeprapper-model
│ ├── pytorch_model.bin
│ └── config.json
最后,运行以下命令来生成:
bash generate_from_pretrain.sh
创建环境
requirement
scikit-learn==0.21.3
miditoolkit==0.1.14
fastBPE
dtw-python
nltk
keras
tqdm
matplotlib
pretty_midi
PyYAML
pypianoroll
fairseq==0.10.0
torch==1.7.1
transformers==3.5.1
pypinyin==0.39.1
jieba==0.42.1
tensorboard==2.4.0
scipy==1.3.1
librosa
pyworld
soundfile
pyOpenSSL
secrets
建deeprapper环境
conda create --name deeprapper python=3.7
安装包
conda install --yes --file requirements.txt
pip3 install -r requirements.txt
也可以一个一个装
pip3 install jieba==0.42.1
一、从预训练的模型生成rap
下载预训练模型
cd 到model目录
输入
curl https://msramllasc.blob.core.windows.net/modelrelease/deeprapper-model.zip --output deeprapper-model.zip

jar xvf deeprapper-model.zip
上述问题最主要的原因是 文件没有完全下载成功 重新下就行
jar 可以解压 但是是不完全的
bash generate_from_pretrain.sh
开头设置为”蛋黄的长裙蓬松的头发“

二、bash train.sh
cd 到对应的目录
bash train.sh
train.sh
#!/bin/bash
python train.py \
--device '0,1' \
--stride 1024 \
--model_config 'config/model_config_small.json' \
--model_dir 'model' \
--root_path 'data/lyrics/' \
--raw_data_dir 'lyrics_samples' \
--batch_size 1 \
--epochs 4 \
--enable_final \
--enable_sentence \
--enable_relative_pos \
--enable_beat \
--reverse \
--model_sign 'samples' \
--with_beat \
--beat_mode 0 \
--tokenize \
--raw
train.py
import argparse
import os
import random
import sys
from datetime import datetime
import numpy as np
from tqdm import tqdm
from utils import swap_value
if __name__ == '__main__':
main()
def main
def main():
parser = argparse.ArgumentParser()
# path to data
parser.add_argument('--model_dir', default='model', type=str, required=False, help='directory of learned models')
parser.add_argument('--root_path', default='data/lyrics/', type=str, required=False, help='root path')
parser.add_argument('--raw_data_dir', default='lyric_with_final_small', type=str, required=False, help='directory of raw data')
parser.add_argument('--model_sign', default='1a', type=str, required=False, help='model sign, to identify each model')
parser.add_argument('--writer_dir', default='tensorboard_summary/', type=str, required=False, help='directory of tensorboard logs')
# path to dictionary
parser.add_argument('--tokenizer_path', default='tokenizations/chinese_dicts.txt', type=str, required=False, help='vocabulary of tokens')
parser.add_argument('--finalizer_path', default='tokenizations/finals.txt', type=str, required=False, help='vocabulary of finals')
parser.add_argument('--sentencer_path', default='tokenizations/sentences.txt', type=str, required=False, help='vocabulary of sentence numbers')
parser.add_argument('--poser_path', default='tokenizations/sentences.txt', type=str, required=False, help='vocabulary of intra-sentence positions')
parser.add_argument('--beater_path', default='tokenizations/beats.txt', type=str, required=False, help='vocabulary of beats')
# hyperparameters for training
parser.add_argument('--device', default='0', type=str, required=False, help='choose gpus')
parser.add_argument('--init_device', default=0, type=int, required=False, help='set the main gpu number')
parser.add_argument('--model_config', default='config/model_config_small.json', type=str, required=False,
help='model configurations')
parser.add_argument('--epochs', default=5, type=int, required=False, help='number of epochs')
parser.add_argument('--start_epoch', default=0, type=int, required=False, help='the initial epoch')
parser.add_argument('--batch_size', default=8, type=int, required=False, help='batch size')
parser.add_argument('--lr', default=1.5e-4, type=float, required=False, help='learning rate')
parser.add_argument('--warmup_steps', default=2000, type=int, required=False, help='warm up steps')
parser.add_argument('--log_step', default=10, type=int, required=False,
help='steps of each printing of logs')
parser.add_argument('--stride', default=1024, type=int, required=False, help='windows of context in training')
parser.add_argument('--gradient_accumulation', default=1, type=int, required=False, help='steps of gradient accumulation')
parser.add_argument('--fp16', action='store_true', help='mixed precision')
parser.add_argument('--fp16_opt_level', default='O1', type=str, required=False)
parser.add_argument('--max_grad_norm', default=1.0, type=float, required=False)
parser.add_argument('--num_pieces', default=1, type=int, required=False, help='number of pieces of data')
parser.add_argument('--min_length', default=0, type=int, required=False, help='min length of the lyrics')
parser.add_argument('--pretrained_model', default='', type=str, required=False, help='path to the pretrianed model')
# ways to process data
parser.add_argument('--encoder_json', default="tokenizations/encoder.json", type=str, help="encoder.json", required=False)
parser.add_argument('--vocab_bpe', default="tokenizations/vocab.bpe", type=str, help="vocab.bpe", required=False)
parser.add_argument('--raw', action='store_true', help='whether the preprocessing is done', required=False)
parser.add_argument('--tokenize', action='store_true', help='whether the tokenization is done', required=False)
parser.add_argument('--segment', action='store_true', help='do Chinese Word Segmentation or not', required=False)
parser.add_argument('--bpe_token', action='store_true', help='use subword', required=False)
parser.add_argument('--enable_final', action='store_true', help='whether to use final embedding', required=False)
parser.add_argument('--enable_sentence', action='store_true', help='whether to use sentence embedding', required=False)
parser.add_argument('--enable_relative_pos', action='store_true', help='whether to use intra-sentence positional embedding', required=False)
parser.add_argument('--enable_beat', action='store_true', help='whether to use beat embedding', required=False)
parser.add_argument('--reverse', action='store_true', help='whether to use reverse language model', required=False)
parser.add_argument('--with_beat', action='store_true', help='whether to generate beat', required=False)
parser.add_argument('--beat_mode', default=0, type=int, help='beat mode:0.no control;1.global control;2.local control', required=False)
args = parser.parse_args()
print('args:\n' + args.__repr__())
# basic settings
# set envs and import related packages
os.environ["CUDA_VISIBLE_DEVICES"] = args.device
import torch
import transformers
from torch.nn import DataParallel
from torch.utils.tensorboard import SummaryWriter
from prepare_train_data import build_files_separate, read_lyrics, prepare_lyrics, get_shuffled_samples
from tokenizations.bpe_tokenizer import get_encoder
from module import GPT2Config, GPT2Model, GPT2LMHeadModel
# choose tokenizer
if args.segment:
from tokenizations import tokenization_bert_word_level as tokenization_bert
else:
from tokenizations import tokenization_bert
# set tokenizer
if args.bpe_token:
full_tokenizer = get_encoder(args.encoder_json, args.vocab_bpe)
full_tokenizer.max_len = 999999
else:
full_tokenizer = tokenization_bert.BertTokenizer(
vocab_file=args.tokenizer_path,
do_lower_case=False
)
full_finalizer = tokenization_bert.BertTokenizer(
vocab_file=args.finalizer_path,
tokenize_chinese_chars=False,
do_lower_case=False
)
full_sentencer = tokenization_bert.BertTokenizer(
vocab_file=args.sentencer_path,
tokenize_chinese_chars=False,
do_lower_case=False
)
full_poser = tokenization_bert.BertTokenizer(
vocab_file=args.poser_path,
tokenize_chinese_chars=False,
do_lower_case=False
)
full_beater = tokenization_bert.BertTokenizer(
vocab_file=args.beater_path,
tokenize_chinese_chars=False,
do_lower_case=False
)
# run tokenizeing
# dataset root key
key = args.root_path.rstrip('/').split('/')[-1]
# processed data root path
processed_path = os.path.join(args.root_path, args.raw_data_dir, 'processed')
tokenized_path = os.path.join(processed_path, 'tokenized')
reverse_str = '_reverse' if args.reverse else ''
tokenized_data_path = os.path.join(tokenized_path, f'tokenized{reverse_str}')
finalized_data_path = os.path.join(tokenized_path, f'finalized{reverse_str}')
sentenced_data_path = os.path.join(tokenized_path, f'sentenced{reverse_str}')
posed_data_path = os.path.join(tokenized_path, f'posed{reverse_str}')
beated_data_path = os.path.join(tokenized_path, f'beated{reverse_str}')
if args.tokenize:
# prepare data
if args.raw:
print('Processing from raw data...')
prepare_fn = {
'lyrics': prepare_lyrics
}
prepare_fn[key](
ins_path=os.path.join(args.root_path, args.raw_data_dir, 'raw'), # demo: data/lyrics/lyrics_22w/raw
out_path=processed_path, # demo: data/lyrics/lyrics_22w/processed
with_beat=args.with_beat,
beat_mode=args.beat_mode
)
print('Loading processed data for training...')
read_fn = {
'lyrics': read_lyrics,
}
train_lines, train_finals, train_sentences, train_pos, train_beats = read_fn[key](processed_path, reverse=args.reverse)
print('Tokenizing processed data for training...')
build_files_separate(num_pieces=args.num_pieces,
stride=args.stride,
min_length=args.min_length,
lines=train_lines,
finals=train_finals,
sentences=train_sentences,
pos=train_pos,
beats=train_beats,
tokenized_data_path=tokenized_data_path,
finalized_data_path=finalized_data_path,
sentenced_data_path=sentenced_data_path,
posed_data_path=posed_data_path,
beated_data_path=beated_data_path,
full_tokenizer=full_tokenizer,
full_finalizer=full_finalizer,
full_sentencer=full_sentencer,
full_poser=full_poser,
full_beater=full_beater,
enable_final=args.enable_final,
enable_sentence=args.enable_sentence,
enable_pos=args.enable_relative_pos,
enable_beat=args.enable_beat,
segment=args.segment)
print('End')
# Training settings
# calculate total training steps
full_len = 0
print('calculating total steps')
for i in tqdm(range(args.num_pieces)):
with open(os.path.join(tokenized_data_path, 'tokenized_train_{}.txt'.format(i)), 'r') as f:
full_len += len([int(item) for item in f.read().strip().split()])
total_steps = int(full_len / args.stride * args.epochs / args.batch_size / args.gradient_accumulation)
print('total steps = {}'.format(total_steps))
# build model
model_config = GPT2Config.from_json_file(args.model_config)
print('config:\n' + model_config.to_json_string())
if not args.pretrained_model:
model = GPT2LMHeadModel(config=model_config)
else:
model = GPT2LMHeadModel.from_pretrained(args.pretrained_model)
model.train()
# set whether to use cuda
gpu_count = torch.cuda.device_count()
if gpu_count > 0:
device_ids = [int(i) for i in range(gpu_count)]
swap_value(device_ids, 0, args.init_device)
device = f'cuda:{device_ids[0]}'
else:
device = 'cpu'
print('using device:', device)
model.to(device)
# check parameters number of the built model
num_parameters = 0
parameters = model.parameters()
for parameter in parameters:
num_parameters += parameter.numel()
print('number of parameters: {}'.format(num_parameters))
# set optimizer
optimizer = transformers.AdamW(model.parameters(), lr=args.lr, correct_bias=True)
# change WarmupLinearSchedule to get_linear_schedule_with_warmup for current version of Transformers
scheduler = transformers.get_linear_schedule_with_warmup(optimizer,
num_warmup_steps=args.warmup_steps,
num_training_steps=total_steps)
# set whether to use 16-bits parameters to save GPU memory if your GPU support the operations of 16-bits number
if args.fp16:
try:
from apex import amp
except ImportError:
raise ImportError("Please install apex from https://www.github.com/nvidia/apex to use fp16 training.")
model, optimizer = amp.initialize(model, optimizer, opt_level=args.fp16_opt_level)
# set whether to use multi GPUs
multi_gpu = False
if gpu_count > 1:
print("Let's use", gpu_count, "GPUs!", device_ids)
model = DataParallel(model, device_ids=device_ids)
multi_gpu = True
# set log info
log_dir = os.path.join(args.writer_dir, key, f'{args.raw_data_dir}{reverse_str}', args.model_sign)
tb_writer = SummaryWriter(log_dir=log_dir)
assert args.log_step % args.gradient_accumulation == 0
output_dir = os.path.join(args.model_dir, key, f'{args.raw_data_dir}{reverse_str}', args.model_sign)
if not os.path.exists(output_dir):
os.makedirs(output_dir)
print('starting training')
overall_step = 0
running_loss = 0
for epoch in range(args.start_epoch, args.epochs):
print('epoch {}'.format(epoch + 1))
now = datetime.now()
print('time: {}'.format(now))
# shuffle pieces of data
x = np.linspace(0, args.num_pieces - 1, args.num_pieces, dtype=np.int32)
random.shuffle(x)
piece_num = 0
# enumerate data pieces
for i in x:
# prepare training sentences
with open(os.path.join(tokenized_data_path, 'tokenized_train_{}.txt'.format(i)), 'r') as f:
line = f.read().strip()
tokens = line.split()
# print(len(tokens))
tokens = [int(token) for token in tokens]
# tokens = torch.Tensor(tokens)
if args.enable_final:
with open(os.path.join(finalized_data_path, 'tokenized_train_{}.txt'.format(i)), 'r') as f:
final = f.read().strip()
finals = final.split()
# print(len(finals))
finals = [int(final) for final in finals]
# finals = torch.Tensor(finals)
if args.enable_sentence:
with open(os.path.join(sentenced_data_path, 'tokenized_train_{}.txt'.format(i)), 'r') as f:
sentence = f.read().strip()
sentences = sentence.split()
# print(len(sentences))
sentences = [int(sentence) for sentence in sentences]
# sentences = torch.Tensor(sentences)
if args.enable_relative_pos:
with open(os.path.join(posed_data_path, 'tokenized_train_{}.txt'.format(i)), 'r') as f:
p = f.read().strip()
pos = p.split()
# print(len(sentences))
pos = [int(p) for p in pos]
# sentences = torch.Tensor(sentences)
if args.enable_beat:
with open(os.path.join(beated_data_path, 'tokenized_train_{}.txt'.format(i)), 'r') as f:
beat = f.read().strip()
beats = beat.split()
# print(len(sentences))
beats = [int(beat) for beat in beats]
# sentences = torch.Tensor(sentences)
# print('training: ', len(tokens), len(finals), len(sentences))
start_point = 0
samples_token, samples_final, samples_sentence, samples_pos, samples_beat = [], [], [], [], []
n_ctx = model_config.n_ctx # the length of a sentence for training
stride = args.stride
print(len(tokens))
while start_point < len(tokens) - stride:
samples_token.append(tokens[start_point: start_point + stride])
if args.enable_final:
samples_final.append(finals[start_point: start_point + stride])
if args.enable_sentence:
samples_sentence.append(sentences[start_point: start_point + stride])
if args.enable_relative_pos:
samples_pos.append(pos[start_point: start_point + stride])
if args.enable_beat:
samples_beat.append(beats[start_point: start_point + stride])
start_point += stride
if start_point < len(tokens):
samples_token.append(tokens[len(tokens) - stride:])
if args.enable_final:
samples_final.append(finals[len(tokens) - stride:])
if args.enable_sentence:
samples_sentence.append(sentences[len(tokens) - stride:])
if args.enable_relative_pos:
samples_pos.append(pos[len(tokens) - stride:])
if args.enable_beat:
samples_beat.append(beats[len(tokens) - stride:])
samples_token, samples_final, samples_sentence, samples_pos, samples_beat = get_shuffled_samples(
samples_token, samples_final,
samples_sentence, samples_pos, samples_beat
)
# print(len(samples_token), len(samples_final), len(samples_sentence), len(samples_))
# enumerate batch data
for step in range(len(samples_token) // args.batch_size): # drop last
# prepare batch data
batch_token = samples_token[step * args.batch_size: (step + 1) * args.batch_size]
batch_inputs_token = torch.Tensor(batch_token).long().to(device)
if samples_final is not None:
batch_final = samples_final[step * args.batch_size: (step + 1) * args.batch_size]
batch_inputs_final = torch.Tensor(batch_final).long().to(device)
else:
batch_inputs_final = None
if samples_sentence is not None:
batch_sentence = samples_sentence[step * args.batch_size: (step + 1) * args.batch_size]
batch_inputs_sentence = torch.Tensor(batch_sentence).long().to(device)
else:
batch_inputs_sentence = None
if samples_pos is not None:
batch_pos = samples_pos[step * args.batch_size: (step + 1) * args.batch_size]
batch_inputs_pos = torch.Tensor(batch_pos).long().to(device)
else:
batch_inputs_pos = None
if samples_beat is not None:
batch_beat = samples_beat[step * args.batch_size: (step + 1) * args.batch_size]
batch_inputs_beat = torch.Tensor(batch_beat).long().to(device)
else:
batch_inputs_beat = None
# forward pass
# Notes: Using Transformers, the labels are shifted inside the model,
# i.e. you can set labels = input_ids
outputs = model.forward(input_ids=batch_inputs_token,
sentence_ids=batch_inputs_sentence,
final_ids=batch_inputs_final,
pos_ids=batch_inputs_pos,
beat_ids=batch_inputs_beat,
labels=batch_inputs_token)
loss, logits = outputs[:2]
# get loss
if multi_gpu:
loss = loss.mean()
'''
running_loss += loss
overall_step += 1
'''
if args.gradient_accumulation > 1:
loss = loss / args.gradient_accumulation
# loss backward
if args.fp16:
with amp.scale_loss(loss, optimizer) as scaled_loss:
scaled_loss.backward()
torch.nn.utils.clip_grad_norm_(amp.master_params(optimizer), args.max_grad_norm)
else:
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
# optimizer step
if (overall_step + 1) % args.gradient_accumulation == 0:
running_loss += loss.item()
optimizer.step()
optimizer.zero_grad()
scheduler.step()
# log info of training process
if (overall_step + 1) % args.log_step == 0:
loss_log = running_loss * args.gradient_accumulation / (args.log_step / args.gradient_accumulation)
tb_writer.add_scalar('loss', loss_log, overall_step)
print('now time: {}:{}. Step {} of piece {} of epoch {}, loss {}'.format(datetime.now().hour,
datetime.now().minute,
step + 1, piece_num,
epoch + 1, loss_log))
running_loss = 0
overall_step += 1
piece_num += 1
# save model per epoch
print('saving model for epoch {}'.format(epoch + 1))
if not os.path.exists(os.path.join(output_dir, 'model_epoch{}'.format(epoch + 1))):
os.mkdir(os.path.join(output_dir, 'model_epoch{}'.format(epoch + 1)))
model_to_save = model.module if hasattr(model, 'module') else model
model_to_save.save_pretrained(os.path.join(output_dir, 'model_epoch{}'.format(epoch + 1)))
# torch.save(scheduler.state_dict(), output_dir + 'model_epoch{}/scheduler.pt'.format(epoch + 1))
# torch.save(optimizer.state_dict(), output_dir + 'model_epoch{}/optimizer.pt'.format(epoch + 1))
print('epoch {} finished'.format(epoch + 1))
then = datetime.now()
print('time: {}'.format(then))
print('time for one epoch: {}'.format(then - now))
# save final model
print('training finished')
if not os.path.exists(os.path.join(output_dir, 'final_model')):
os.mkdir(os.path.join(output_dir, 'final_model'))
model_to_save = model.module if hasattr(model, 'module') else model
model_to_save.save_pretrained(os.path.join(output_dir, 'final_model'))
# torch.save(scheduler.state_dict(), output_dir + 'final_model/scheduler.pt')
# torch.save(optimizer.state_dict(), output_dir + 'final_model/optimizer.pt')


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









