









 本文介绍了如何在PyTorch中创建自定义模型,通过nn.Module和nn.functional.conv2d理解卷积操作,包括卷积的步长、填充等概念,并展示了卷积层在图像数据上的应用。
本文介绍了如何在PyTorch中创建自定义模型,通过nn.Module和nn.functional.conv2d理解卷积操作,包括卷积的步长、填充等概念,并展示了卷积层在图像数据上的应用。
创建自己的第一个模型
了解内容即为Pytorch官网文档 pytorch
import torch
from torch import nn
"""
pytorch提供所有神经网络里的细节操作(卷积、线性变换、非线性变化等)。
用户只需要在创建自己的模型时想好每步所要执行的功能,进行组合实现。
创建模型继承官方书写的nn.Module,初始化所需变量。并在前向传播中书写自己所要执行的动作。
"""
class MyModule(nn.Module):
def __init__(self) -> None:
super().__init__()
def forward(self, input):
output = input + 1
return output
# 断点打入,单步执行,观看程序执行步骤。
my_module = MyModule()
x = torch.tensor(1.0)
output = my_module(x)
print(output)
卷积的初步了解
nn.funcational.conv2d
卷积的理解可能不知道其这样做究竟有啥用处,或者是这样做的过程是为了啥。自己理解的这个可以和图像处理中的滤波等价理解,(均值滤波)。开始学可以只知道他是如何计算的即可,在后面学习深度学习原理在做思考即可。
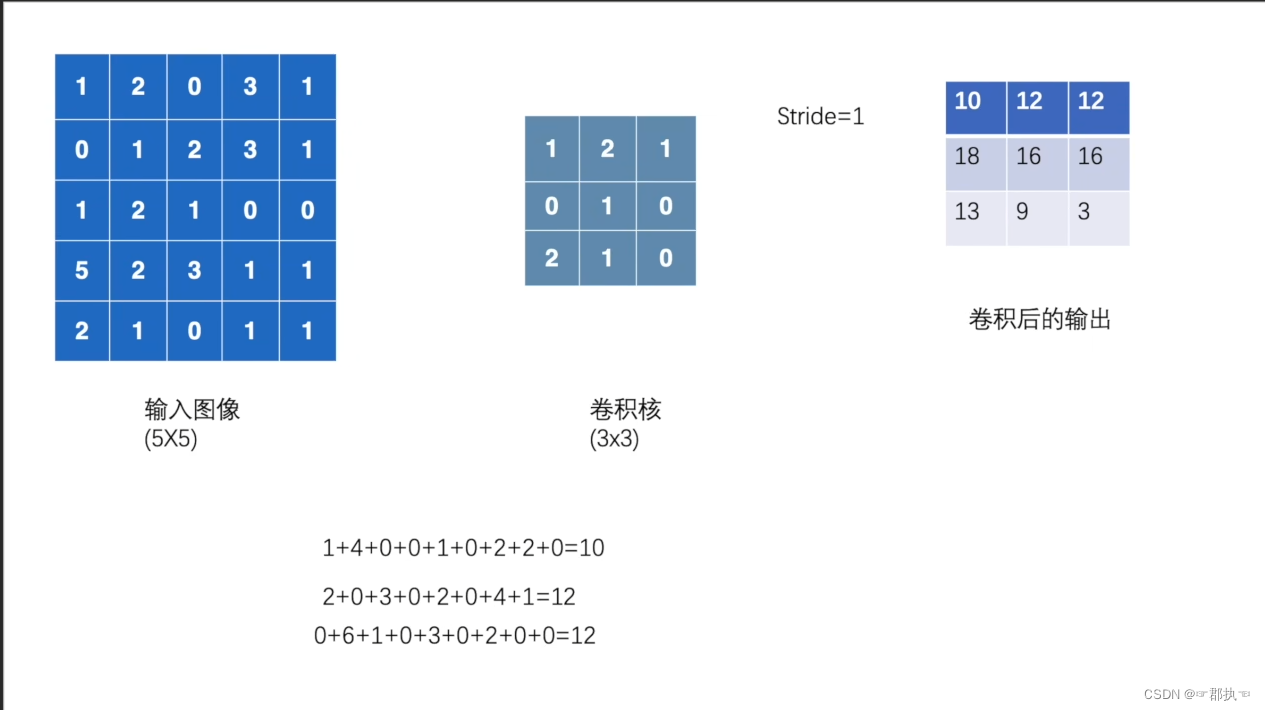
灰度图像示例,对应图像像素值与卷积核对应相乘再相加得到卷积的输出。卷积函数中的Stride指出卷积核在图像中的移动步骤,单数字即表示横向纵向均移动x,也可为一个元组(xw,yw)。
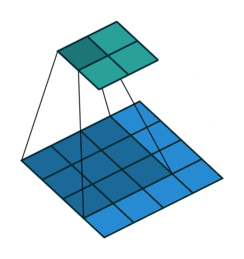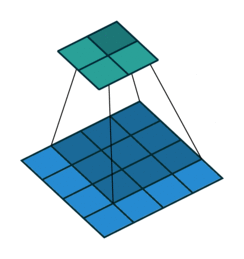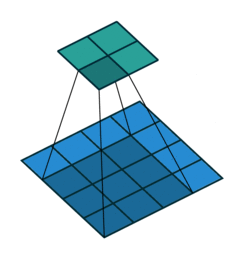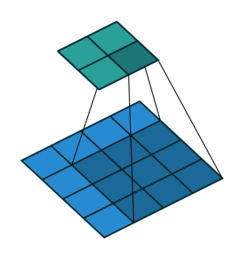

import torch
import torch.nn.functional as F
"""
一个简单的测试卷积过程。并解释函数的部分参数
torch.nn.functional.conv2d的参数需求
conv2d()
第一个参数为输入数据,需要形状为(minibatch,通道数,高,宽)
卷积核 为tensor类型,也需要和上述一样的形状
stride 即步数,每次运行走几步,可以但数字也可以元组指定高宽
padding 在输入数据的左右两边作填充,默认不填从,单数字则指定填充大小。也可以为元组大小(H,W)
"""
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
# 卷积核 Kernel
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
# 此处就是修改输入数据的shape,使其能够满足卷积函数的输出参数的形状,第一个1为batch_size,第二个1 为一个通道,后面为宽乘高。
input = torch.reshape(input, (1, 1, 5, 5))
kernel = torch.reshape(kernel, (1, 1, 3, 3))
print(input.shape)
print(kernel.shape)
output = F.conv2d(input, kernel, stride=1)
print(output)
# 步数改变,输出形状大小改变
output2 = F.conv2d(input, kernel, stride=2)
print(output2)
# 添加填充周围,输出形状大小均改变。
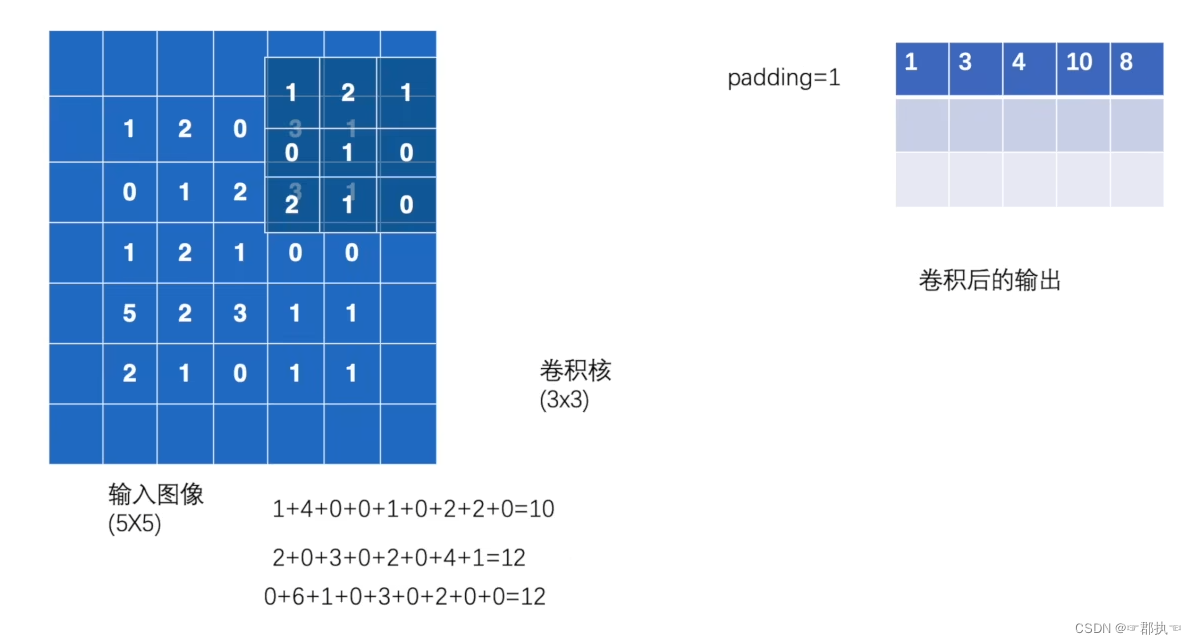
output3 = F.conv2d(input, kernel, stride=1, padding=1)
print(output3)
结果:
torch.Size([1, 1, 5, 5])
torch.Size([1, 1, 3, 3])
tensor([[[[10, 12, 12],
[18, 16, 16],
[13, 9, 3]]]])
tensor([[[[10, 12],
[13, 3]]]])
tensor([[[[ 1, 3, 4, 10, 8],
[ 5, 10, 12, 12, 6],
[ 7, 18, 16, 16, 8],
[11, 13, 9, 3, 4],
[14, 13, 9, 7, 4]]]])
当padding为1时:空位置默认为0

注:torch.reshape()函数的使用
- 参数1 inpute输入需要改变的图像数据
- 参数后面的则为变更为什么形状。batchsize,通道,高,宽
- torch.reshape(input,(-1,3,25,25)) -1表示不知道,后面自己调节
- 目的就是一些torch的内部函数要求数据的维度必须遵守4维度或三维度。所以需要一个变换。
- 具体可以观察每个函数后面的需要:

nn.Conv2d
nn.functional是模型更细分的操作。nn是进一步对于functional的功能进行封装,更容易使用。
torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', device=None, dtype=None)
- in_channels 输入图像的通道数
- out_channels 卷积后输出图像的通道数
- kernel_size 卷积核大小,int或tuple类型 33 HW
- stride 卷积过程中的步进大小 int或tuple类型 默认为1
- padding 是否进行边缘填充 默认为0
- dilation 空洞卷积,不常用默认为1
- groups 默认为1
- bias 偏执 默认为true
- padding_mode 以什么形式填充边缘,一般以zeros形式填充
可以通过该动画演示查看参数对卷积过程的影响:卷积可视化
第一部分所展示的为单通道数的卷积过程,针对多通道数的图片卷积。
import torch
from torch import nn
import torchvision
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
"""
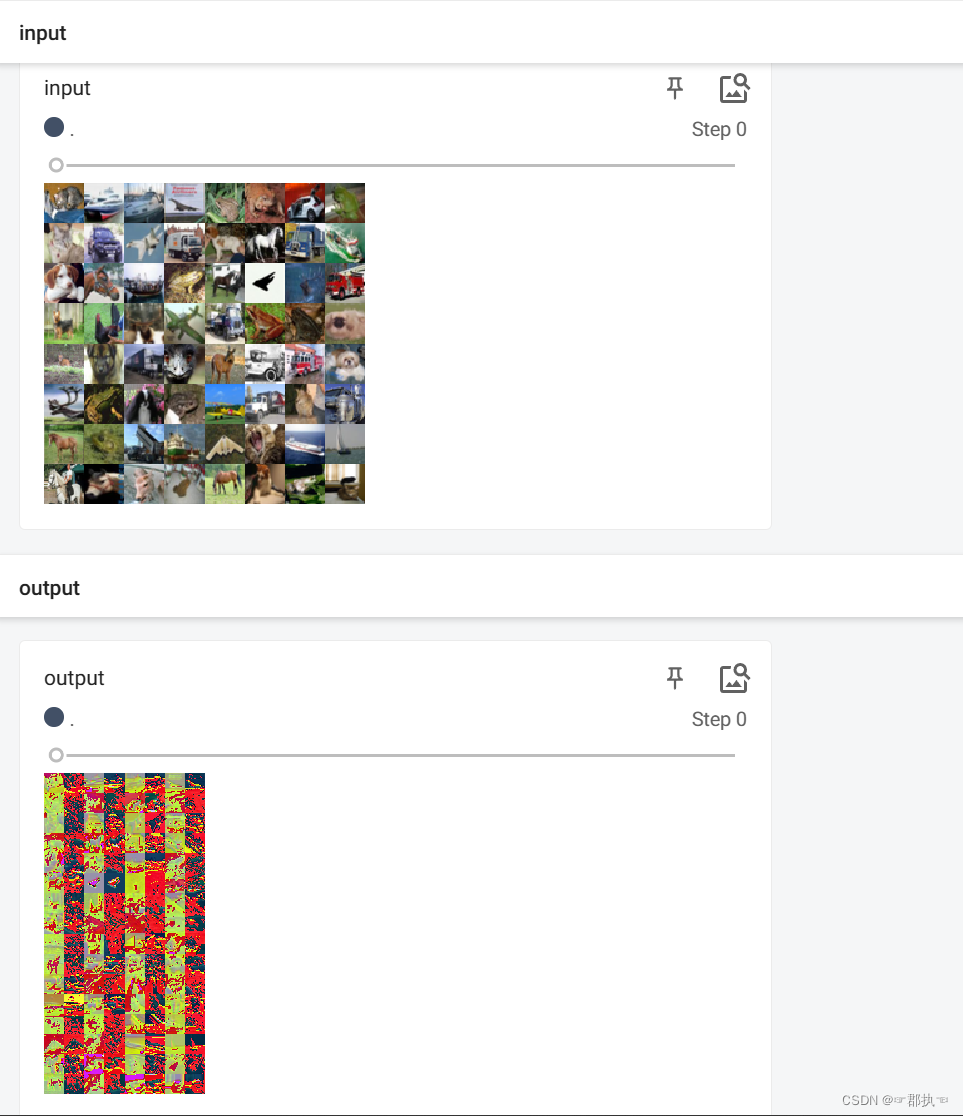
使用封装后的卷积层类进行实现自己的模型,该模型仅有一个卷积层,并测试卷积层中所需要的多个参数,得到输出数据的内容进行展示。
本节将会对以往学习过的所有知识进行整合!依次需要的知识点有:
图像数据的transform的变换器的使用。需要通过torchvision.transforms.Totensor()进行将PIL变换成tensor
获取网络数据集并进行初步变化 torchvision.datasets的使用
将数据集按照batchsize大小加载到数据加载器中,DataLoader
神经网络的自定义模型。需要手动实现nn.Module的初始化方法和forward方法。
进行卷积核的参数设置
进行数据集形状的改变以满足需求,使用torch.reshape(inpute,(batchsize,channels,H,W))
最后需要使用最初学习的tensorboard进行将卷积后的结果展示出来。writer.add_images()。
"""
# 获取数据集
dataset = torchvision.datasets.CIFAR10("../DataSet/dataset", train=False, transform=torchvision.transforms.ToTensor(),
download=False)
# 数据集切块取出
dataloader = DataLoader(dataset, batch_size=64)
# 创建自己的模型
class MyModule(nn.Module):
def __init__(self):
super().__init__()
# 给自己网络配置一个卷积层 这里的卷积核是内部给定的
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
x = self.conv1(x)
return x
mymodule = MyModule()
print(mymodule)
writer = SummaryWriter("conv2d")
for data in dataloader:
imgs, targets = data
output = mymodule(imgs)
print(imgs.shape)
print(output.shape)
# torch.Size([64, 3, 32, 32])
writer.add_images("input",imgs)
# torch.Size([64, 6, 30, 30])
output = torch.reshape(output,(-1,3,30,30))
writer.add_images("output",output)
# 此处的break仅为了展示第一个数据加载器中的处理结果。
break
writer.close()

















 1904
1904

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









