







避免过拟合
一、正则化
1、
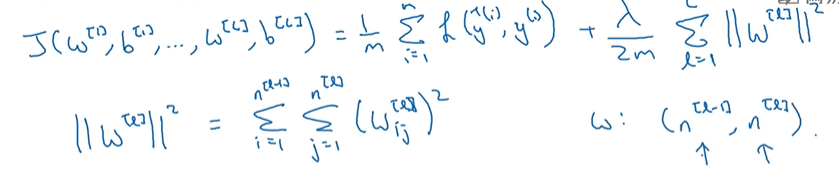
(m,样本数),W为第n层的权重的大小(前一层的输出*当前层的神经元数),损失函数加上正则化项(神经网络所有权重参数)
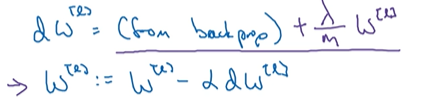
然后对w计算偏导,即可更新权重
2、droupout
即随机移除百分比(如0.2)的神经元,使其暂时不参与运算,即当次不更新其权重,使总的网络更“平均”,不依特定的几个神经元或权重。并且在下一层计算时,为保证期望不变结果需要除以0.8(1-0.2)
3、数据增强。可以通过翻转、旋转、切割、扭曲等方法增强数据表现能力。
4、正则化输入。对输入数据进行归一化、标准化,使权重更新时,从各个方向都更容易到达收敛。
二、参数调试
1.学习率a
2.min-batch
3、优化器参数惯性B,B越大,受当前的影响越大,受历史信息趋势越小,对更新值dw的加权平均。
4.隐藏单元
5、隐藏层数
6.学习衰减
A 、网格筛选
比如学习率为0.0001-0.1之间,可通过遍历特定规律的随机数,进行一一实验。特定规律可以以10**(0~-4) 例如:10 **(np.random.rand(10) * (-4)),然后再缩减范围,寻找最优参数。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









