王道数据结构-第二章-链式表示算法题
1.在带头结点的单链表L中,删除所有值为x的结点,并释放其空间,假设值为x的结点不唯一,试编写算法以实现上述操作。 2. 试编写在带头结点的单链表L中删除一个最小值结点的高效算法(假设该结点唯一)。 3. 试编写算法将带头结点的单链表就地逆置,所谓“就地”是指辅助空间复杂度为O(1)。
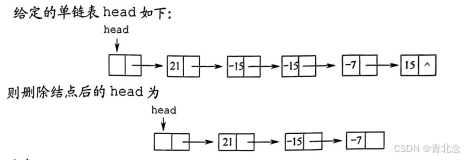
4. 设在一个带表头结点的单链表中,所有结点的元素值无序,试编写一个函数,删除表中所有介于给定的两个值(作为函数参数给出)之间的元素(若存在)。 5. 给定两个单链表,试分析找出两个链表的公共结点的思想(不用写代码)。 6. 设C={a1,b1,a2,b2,…,an,bn}为线性表,采用带头结点的单链表存放,设计一个就地算法,将其拆分为两个线性表,使得A{a1,a2,…,an},B={bn,…,b2,b1}。 7. 在一个递增有序的单链表中,存在重复的元素。设计算法删除重复的元素,例如(7,10,10,21,30,42,42,42,51,70)将变为(7,10,21,30,42,51,70)。 8. 设A和B是两个单链表(带头结点),其中元素递增有序。设计一个算法从A和B中的公共元素产生单链表 C,要求不破坏 A、B的结点。 9. 已知两个链表A和B分别表示两个集合,其元素递增排列。编制函数,求A与B的交集,并存放于A链表中。 10. 两个整数序列A=a1,a2?a3,…,am和B=b1,b2,b3,…,bn已经存入两个单链表中,设计一个算法,判断序列B是否是序列 A的连续子序列。 11. 设计一个算法用于判断带头结点的循环双链表是否对称。 12. 有两个循环单链表,链表头指针分别为h1和h2,编写一个函数将链表h2链接到链表h1之后,要求链接后的链表仍保持循环链表形式。 13. 设有一个带头结点的非循环双链表 L,其每个结点中除有 pre、data 和 next 域外,还有一个访问频度域 freq,其值均初始化为零。每当在链表中进行一次 Locate(L,x)运算时,令值为x的结点中freq域的值增1,并使此链表中的结点保持按访问频度递减的顺序排列,且最近访问的结点排在频度相同的结点之前,以便使频繁访问的结点总是靠近表头。试编写符合上述要求的 Locate(L,x)函数,返回找到结点的地址,类型为指针型。 14. 14.设将n(n>1)个整数存放到不带头结点的单链表L中,设计算法将L中保存的序列循环右移k(0<k<n)个位置。例如,若k=1,则将链表{0,1,2,3}变为{3,0,1,2}。要求:1)给出算法的基本设计思想。2)根据设计思想,采用C或C++语言描述算法,关键之处给出注释。3)说明你所设计算法的时间复杂度和空间复杂度。 15. 单链表有环,是指单链表的最后一个结点的指针指向了链表中的某个结点(通常单链表的最后一个结点的指针域是空的)。试编写算法判断单链表是否存在环。1)给出算法的基本设计思想。2)根据设计思想,采用C或C+语言描述算法,关键之处给出注释。3)说明你所设计算法的时间复杂度和空间复杂度。 16. 设有一个长度n(n为偶数)的不带头结点的单链表,且结点值都大于0,设计算法求这个单链表的最大孪生和。孪生和定义为一个结点值与其孪生结点值之和,对于第i个结点(从0开始),其孪生结点为第n-i-1个结点。要求:1)给出算法的基本设计思想。2)根据设计思想,采用C或C++语言描述算法,关键之处给出注释。3)说明你的算法的时间复杂度和空间复杂度。 17. 已知一个带有表头结点的单链表,结点结构为data link 假设该链表只给出了头指针 list。在不改变链表的前提下,请设计一个尽可能高效的算法,查找链表中倒数第k个位置上的结点(k为正整数)。若查找成功,算法输出该结点的 data域的值,并返回 1;否则,只返回0。要求:1)描述算法的基本设计思想。2)描述算法的详细实现步骤。3)根据设计思想和实现步骤,采用程序设计语言描述算法(使用 C、C++或 Java 语言实现),关键之处请给出简要注释。 18. 18.假定采用带头结点的单链表保存单词,当两个单词有相同的后级时,可共享相同的后缀存储空间,例如,loading和being.的存储映像如下图所示。设str1和str2分别指向两个单词所在单链表的头结点,链表结点结构为data next请设计一个时间上尽可能高效的算法,找出由str1和str2所指向两个链表共同后级的起始位置(如图中字符i所在结点的位置p)。要求:1)给出算法的基本设计思想。2)根据设计思想,采用C或 C++或Java语言描述算法,关键之处给出注释。3)说明你所设计算法的时间复杂度。 19. 19.用单链表保存m个整数,结点的结构为[data][link],且data|≤n(n为正整数)。现要求设计一个时间复杂度尽可能高效的算法,对于链表中 data 的绝对值相等的结点,仅保留第一次出现的结点而删除其余绝对值相等的结点。例如,若给定的单链表 head 如下:1)给出算法的基本设计思想。2)使用 C或 C++语言,给出单链表结点的数据类型定义。3)根据设计思想,采用C或 C+语言描述算法,关键之处给出注释。4)说明你所设计算法的时间复杂度和空间复杂度。 20. 设线性表L=(a1,a2,a3,…,an-2,an-1,an)采用带头结点的单链表保存,链表中的结点定义如下请设计一个空间复杂度为 O(1)且时间上尽可能高效的算法,重新排列L中的各结点,得到线性表L'=(a1,an,a2,an-1,a3,an-2)。要求:1)给出算法的基本设计思想。2)根据设计思想,采用C或C++语言描述算法,关键之处给出注释。3)说明你所设计的算法的时间复杂度。
bool delteElement ( LinkList & L, int x) {
LNode * p = L-> next;
LNode * pre = L, * q;
while ( p != NULL ) {
if ( p-> data == x) {
q= p;
p= p-> next;
pre-> next = p;
free ( q) ;
} else {
pre = p;
p = p-> next;
}
}
return true ;
}
bool deleteMin ( Linklist & L) {
LNode * p = L-> next;
int value = 9999999 ;
LNode * pre = L, * min = L-> next, * preMin = L;
while ( p != NULL ) {
if ( p-> data < value) {
value= p-> data;
min = p;
preMin = pre;
p = p-> next;
} else {
pre = p;
p = p-> next;
}
}
preMin-> next = min-> next;
free ( min) ;
return true ;
}
bool invertList ( Linklist & L) {
LNode * p = L-> next, * q ;
L-> next = NULL ;
while ( p != NULL ) {
q= p-> next;
p-> next= L-> next;
L-> next= p;
p= q;
}
return true ;
}
bool invertList2 ( Linklist & L) {
if ( L == NULL || L-> next == NULL ) {
return true ;
}
LNode * p = L-> next;
LNode * pre;
LNode * r ;
L-> next = nullptr ;
while ( p != NULL ) {
r = p-> next;
p-> next = pre;
pre = p;
p = r;
}
L-> next = pre;
return true ;
}
bool deleteBetween ( Linklist & L, int x, int y) {
if ( x >= y) {
return false ;
}
if ( L-> next == nullptr ) {
return false ;
}
LNode * p = L-> next, * pre = L, * q;
while ( p != nullptr ) {
if ( x <= p-> data && p-> data <= y) {
q = p;
p = p-> next;
pre-> next = p;
free ( q) ;
} else {
pre = p;
p = p-> next;
}
}
return true ;
}
两个单链表有公共结点,即两个链表从某一结点开始,它们的 next 都指向同一结点。由于每 本题极容易联想到“蛮”方法:在第一个链表上顺序遍历每个结点,每遍历一个结点,在第 接下来我们试着去寻找一个线性时间复杂度的算法。先把问题简化:如何判断两个单向链表 根据这一思路中,我们先要分别遍历两个链表得到它们的长度,并求出两个长度之差。在长
bool splitList ( Linklist & L, Linklist & L2) {
LNode * p = L-> next, * r = L, * q;
L2 = ( LNode * ) malloc ( sizeof ( LNode) ) ;
L2-> next = NULL ;
int count = 1 ;
while ( p != NULL ) {
if ( count % 2 != 0 ) {
r-> next = p;
r = p;
p = p-> next;
} else {
q= p-> next;
p-> next= L2-> next;
L2-> next = p;
p = q;
}
count++ ;
}
r-> next = NULL ;
return true ;
}
bool deleteRepeat ( Linklist & L) {
LNode * p = L-> next, * q;
while ( p-> next!= NULL ) {
q= p-> next;
if ( p-> data== q-> data) {
p-> next= q-> next;
free ( q) ;
} else {
p= p-> next;
}
}
return true ;
}
Linklist getCommonList ( Linklist & L1, Linklist & L2) {
Linklist commonList= ( LNode * ) malloc ( sizeof ( LNode) ) ;
commonList-> next= NULL ;
LNode * p1= L1-> next, * p2= L2-> next, * r= commonList, * q;
while ( p1!= NULL && p2!= NULL ) {
if ( p1-> data< p2-> data) {
p1= p1-> next;
} else if ( p1-> data> p2-> data) {
p2= p2-> next;
}
if ( p1-> data== p2-> data) {
LNode * s= ( LNode * ) malloc ( sizeof ( LNode) ) ;
s-> data= p1-> data;
r-> next= s;
r= s;
p1= p1-> next;
p2= p2-> next;
}
}
r-> next= NULL ;
return commonList;
}
Linklist unionList ( Linklist & L1, Linklist & L2) {
LNode * p1= L1-> next, * p2= L2-> next, * r= L1, * q;
while ( p1&& p2) {
if ( p1-> data== p2-> data) {
r-> next= p1;
r= p1;
p1= p1-> next;
q= p2;
p2= p2-> next;
free ( q) ;
} else if ( p1-> data< p2-> data) {
q= p1;
p1= p1-> next;
free ( q) ;
} else if ( p1-> data> p2-> data) {
q= p2;
p2= p2-> next;
free ( q) ;
}
}
while ( p1) {
q= p1;
p1= p1-> next;
free ( q) ;
}
while ( p2) {
q= p2;
p2= p2-> next;
free ( q) ;
}
r-> next= NULL ;
free ( L2) ;
return L1;
}
bool continueList ( Linklist & L1, Linklist & L2) {
LNode * p1 = L1-> next, * p2 = L2-> next, * q = L1-> next;
while ( p1 != NULL && p2 != NULL ) {
if ( p1-> data == p2-> data) {
p1 = p1-> next;
p2 = p2-> next;
} else {
p1 = p1-> next;
p2 = L2-> next;
}
}
if ( p2 == NULL ) {
return true ;
} else {
return false ;
}
}
# include "istream" using namespace std;
typedef struct LNode {
int data;
struct LNode * prior, * next;
} LNode, * LinkList;
bool initList ( LinkList & L) {
L = ( LNode * ) malloc ( sizeof ( LNode) ) ;
L-> next = L;
L-> prior = L;
return true ;
}
void printList ( LinkList & head) {
if ( head == nullptr ) {
cout << "空链表" << endl;
return ;
}
LNode * p = head-> next;
while ( p != head) {
cout << p-> data << " " ;
p = p-> next;
}
}
bool insertNode ( LinkList & L) {
LNode * p = L-> next;
int values[ ] = { 1 , 2 , 3 , 2 , 1 } ;
int n = sizeof ( values) / sizeof ( values[ 0 ] ) ;
for ( int i = 0 ; i < n; i++ ) {
LNode * s = ( LNode * ) malloc ( sizeof ( LNode) ) ;
s-> data = values[ i] ;
s-> next = p-> next;
s-> prior = p;
p-> next-> prior = s;
p-> next = s;
}
return true ;
}
bool isSymmetry ( LinkList & L) {
if ( L == nullptr || L-> next == nullptr ) {
return false ;
}
LNode * p = L-> next;
LNode * q = L-> prior;
while ( p != q && p-> next != q) {
if ( p-> data == q-> data) {
p = p-> next;
q = q-> prior;
} else {
return false ;
}
}
return true ;
}
int main ( ) {
LinkList L;
initList ( L) ;
insertNode ( L) ;
bool e = isSymmetry ( L) ;
cout << e << endl;
return 0 ;
}
# include "iostream" using namespace std;
typedef struct LNode {
int data;
struct LNode * next;
} LNode, * LinkList;
bool initList ( LinkList & L) {
L = ( LNode * ) malloc ( sizeof ( LNode) ) ;
L-> next = L;
return true ;
}
bool insertList ( LinkList & L) {
int values[ ] = { 1 , 2 , 3 , 4 , 5 } ;
int len = sizeof ( values) / sizeof ( values[ 0 ] ) ;
for ( int i = 0 ; i < len; i++ ) {
LNode * s = ( LNode * ) malloc ( sizeof ( LNode) ) ;
s-> data = values[ i] ;
s-> next = L-> next;
L-> next = s;
}
return true ;
}
bool insertList2 ( LinkList & L) {
int values[ ] = { 6 , 7 , 8 , 9 , 10 } ;
int len = sizeof ( values) / sizeof ( values[ 0 ] ) ;
for ( int i = 0 ; i < len; i++ ) {
LNode * s = ( LNode * ) malloc ( sizeof ( LNode) ) ;
s-> data = values[ i] ;
s-> next = L-> next;
L-> next = s;
}
return true ;
}
void printList ( LinkList L) {
LNode * p = L-> next;
while ( p != L) {
printf ( "%d " , p-> data) ;
p = p-> next;
}
printf ( "\n" ) ;
}
LinkList getLinkList ( LinkList & L1, LinkList & L2) {
LNode * p1 = L1-> next, * q = L1;
LNode * p2 = L2-> next, * head = L2;
while ( p1-> next != q) {
p1 = p1-> next;
}
p1-> next = p2;
while ( p2-> next != head) {
p2 = p2-> next;
}
p2-> next = L1;
return L1;
}
int main ( ) {
LinkList h1, h2;
initList ( h1) ;
initList ( h2) ;
insertList ( h1) ;
insertList2 ( h2) ;
printList ( h1) ;
printList ( h2) ;
LinkList list= getLinkList ( h1, h2) ;
cout<< "============================" << endl;
printList ( list) ;
return 0 ;
}
LinkList Locate ( LinkList & L, int x) {
LNode * p = L-> next, * q;
while ( p && p-> data != x) {
p = p-> next;
}
if ( ! p) {
exit ( 0 ) ;
} else {
p-> freq++ ;
if ( p-> prior == L || p-> prior-> freq > p-> freq) {
return p;
}
if ( p-> next != NULL )
p-> next-> prior = p-> prior;
p-> prior-> next = p-> next;
q = p-> prior;
while ( q != L && q-> freq <= p-> freq) {
q = q-> prior;
p-> next = q-> next;
if ( q-> next != NULL )
q-> next-> prior = p;
p-> prior = q;
q-> next = p;
}
return p;
}
}
Linklist rightShift ( Linklist & L, int k) {
LNode * p = L, * r= L, * q;
int count = 0 ;
while ( p!= NULL ) {
q= p;
p = p-> next;
count++ ;
}
q-> next = r;
k = k % count;
p= r;
for ( int i = 1 ; i < count - k; ++ i) {
p = p-> next;
}
L = p-> next;
p-> next = NULL ;
return L;
}
LNode* hasLoop ( Linklist & L) {
LNode * fast = L, * slow = L;
while ( fast != NULL && fast-> next != NULL ) {
fast = fast-> next-> next;
slow = slow-> next;
if ( fast == slow) {
break ;
}
}
if ( fast== nullptr || fast-> next== nullptr ) {
return NULL ;
}
LNode * p1 = L, * p2= slow;
while ( p1!= p2) {
p1= p1-> next;
p2= p2-> next;
}
return p1;
}
int pairSum ( Linklist & L) {
LNode * fast = L-> next, * slow = L;
while ( fast != NULL && fast-> next != NULL ) {
fast = fast-> next-> next;
slow = slow-> next;
}
LNode * head= NULL , * p= slow-> next, * q;
while ( p!= NULL ) {
q = p-> next;
p-> next= head;
head= p;
p= q;
}
int maxSum = 0 ;
p= L;
LNode * k= head;
while ( k!= NULL ) {
if ( p-> data+ k-> data> maxSum)
maxSum= p-> data+ k-> data;
p = p-> next;
k= k-> next;
}
return maxSum;
}
思路:快慢指针,快指针先走k步,然后快慢指针同时走,当快指针到达链表尾部时,慢指针指向的结点就是倒数第k个结点。
因为q和p总是差k个单位,当p走完列表时,q指向的结点就是倒数第k个结点。
int findKthToTail ( Linklist & L, int k) {
LNode * p = L-> next, * q = L-> next;
int count = 0 ;
while ( p != NULL ) {
if ( count < k) {
count++ ;
} else {
q = q-> next;
}
p = p-> next;
}
if ( count < k) {
return 0 ;
} else {
cout << q-> data << endl;
}
return 1 ;
}
int getLength ( Linklist & L) {
LNode * p = L-> next;
int count = 0 ;
while ( p != NULL ) {
count++ ;
p = p-> next;
}
return count;
}
LNode * findCommon ( Linklist & L1, Linklist & L2) {
LNode * p1 = L1-> next, * p2 = L2-> next;
int size1 = getLength ( L1) ;
int size2 = getLength ( L2) ;
if ( size1 > size2) {
int count = 0 ;
while ( p1 != NULL && ( size1 - size2) != count) {
p1 = p1-> next;
count++ ;
}
} else if ( size1 < size2) {
int count = 0 ;
while ( p2 != NULL && ( size1 - size2) != count) {
p2 = p2-> next;
count++ ;
}
}
while ( p1-> next != NULL && p1-> next != p2-> next) {
p1 = p1-> next;
p2 = p2-> next;
}
return p1-> next;
}
int getAbs ( int x) {
return x >= 0 ? x : - x;
}
bool deleteAbsRepeat ( Linklist & L, int n) {
LNode * p = L, * q;
int arr[ 22 ] = { } ;
int m;
for ( int i = 0 ; i < n + 1 ; ++ i) {
arr[ i] = 0 ;
}
while ( p-> next!= NULL ) {
m = getAbs ( p-> next-> data) ;
if ( arr[ m] == 0 ) {
arr[ m] = 1 ;
p = p-> next;
} else {
q = p-> next;
p-> next = q-> next;
free ( q) ;
}
}
return true ;
}
bool reverseList ( Linklist & L) {
LNode * p = L, * q = L, * r, * s;
while ( q-> next != NULL ) {
p= p-> next;
q= q-> next;
if ( q-> next != NULL ) {
q= q-> next;
}
}
q= p-> next;
p-> next= NULL ;
while ( q != NULL ) {
r= q-> next;
q-> next= p-> next;
p-> next= q;
q= r;
}
s= L-> next;
q= p-> next;
p-> next= NULL ;
while ( q != NULL ) {
r= q-> next;
q-> next= s-> next;
s-> next= q;
s= q-> next;
q= r;
}
return 1 ;
}




























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











