







 本文提出VI-Diff方法,一种利用单模态标记数据处理可见-红外(VI)人像重识别任务的模型。通过改进的扩散过程,该模型在无监督和有监督场景下表现出色,尤其是在处理可见图像和红外图像之间的视觉差异时。实验对比显示了其在翻译效果和模态差距减小方面的优势。
本文提出VI-Diff方法,一种利用单模态标记数据处理可见-红外(VI)人像重识别任务的模型。通过改进的扩散过程,该模型在无监督和有监督场景下表现出色,尤其是在处理可见图像和红外图像之间的视觉差异时。实验对比显示了其在翻译效果和模态差距减小方面的优势。
VI-Diff: Unpaired Visible-Infrared Translation Diffusion Model for Single Modality Labeled Visible-Infrared Person Re-identification
reference
paper:https://arxiv.org/abs/2310.04122
code: https://github.com/hanhuang22/VI-Diff
1 Motivation
跨模态数据的收集和注释是费时费力,且容易出错的过程。
- 由于可见图像和红外图像之间存在视觉差异,一个人在可见图像中的外观可能与其红外图像对应物明显不同。
- 个体可能在白天被RGB摄像头捕获,但在夜间对红外摄像头不可见,导致数据不连贯,并且跨模态进行配对匹配变得更加复杂。
- 环境条件的变化(如光照、天气和周围环境的改变)可能加剧可见图像和红外图像之间的视觉差距,引入噪音和不一致性。
是否可以仅仅利用单模态的数据来解决问题?
2. Contribution
- 新的场景:利用单模态标记数据来完成跨模态VI-ReID任务
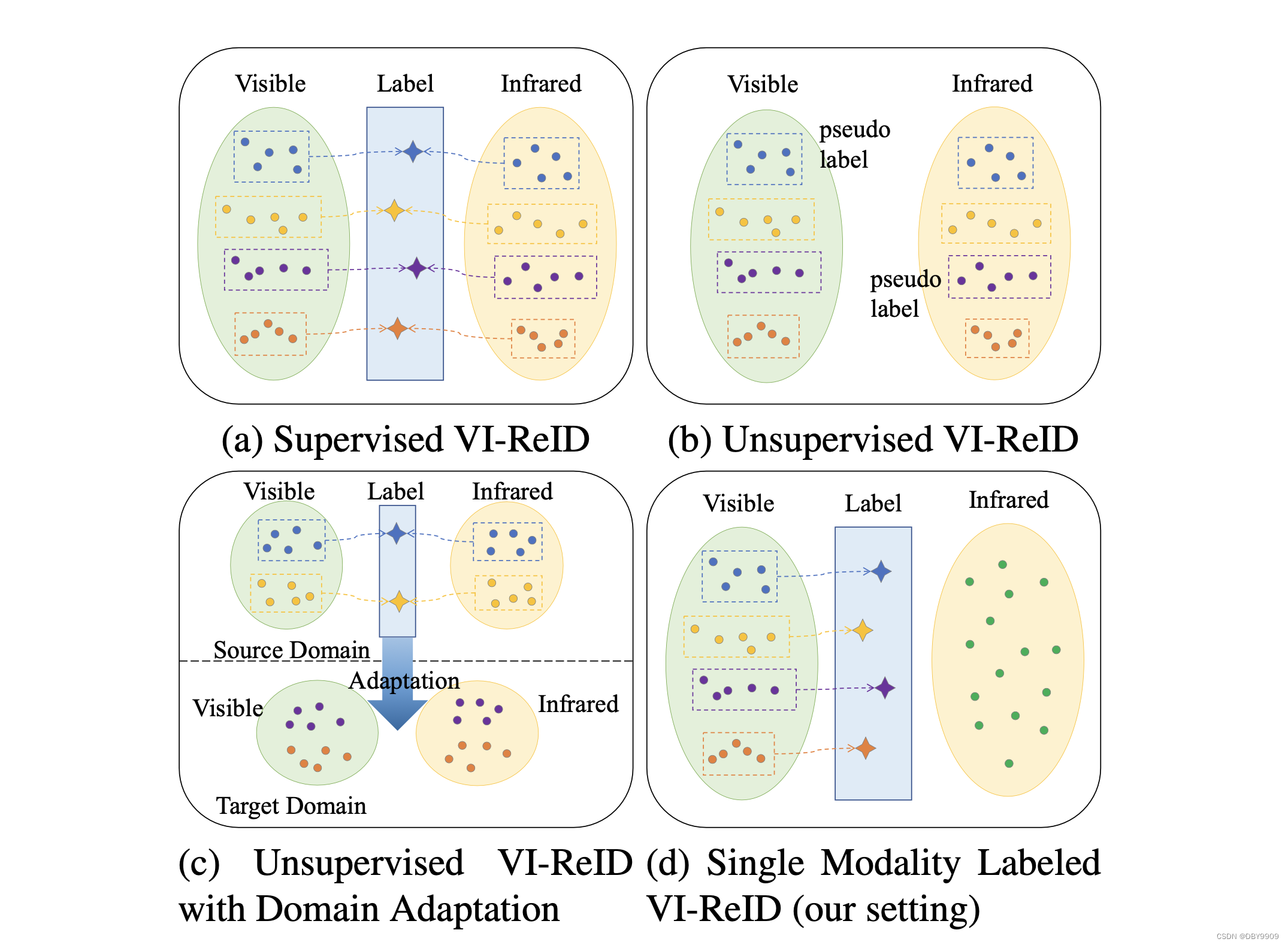
- 有监督VI-ReID:可见光和红外图片都有标注。
- 无监督VI-ReID:可见光和红外图片都没有标注。
- 无监督域泛化VI-ReID:多了有标注的原域数据,用来辅助目标域学习。
- 单模态标注VI-ReID: 只有可见光有标注,红外图片无标注。
- 提出了VI-Diff方法,这是一种能够进行可见-红外人员图像转换的扩散模型,利用单模态标记数据进行VI-ReID任务。
- 实验验证。
3. Method
方法在DDPM的基础上进行了改进。
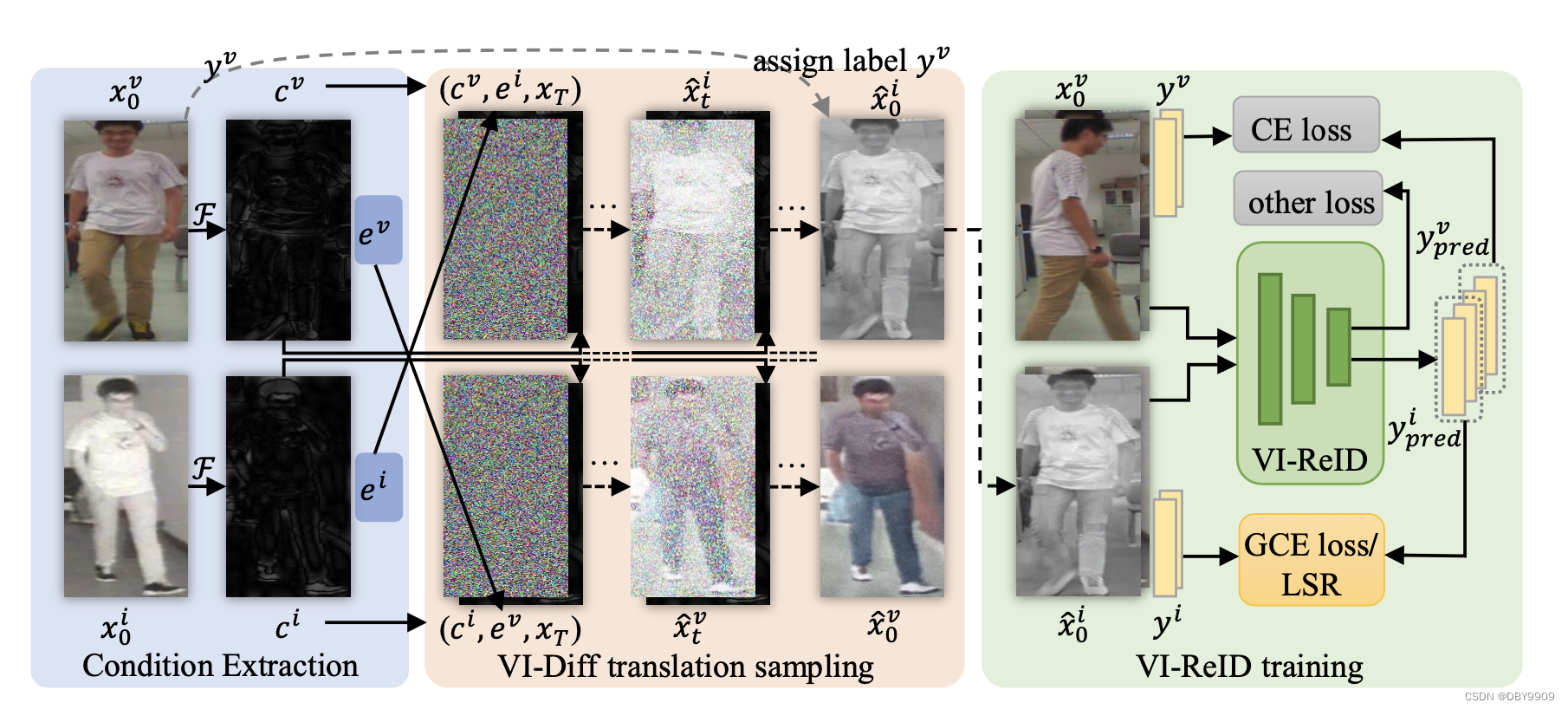
3.1 Modality-Insensitive ID-Relevant Condition

- 使用通过高通滤波器的图片作为条件c
- 从视觉上,高频信息之间模态信息差异较小。
3.2 Modality Indicator and Guidance
引入模态标识
- traing: σ θ ( x t v , t , c v , e v ) \sigma_\theta (x_t^v, t , c^v, e^v) σθ(xtv,t,cv,ev), σ θ ( x i v , i , c i , e i ) \sigma_\theta (x_i^v, i , c^i, e^i) σθ(xiv,i,ci,ei)
- sampling : σ θ ( x t v , t , c v , e i ) \sigma_\theta (x_t^v, t , c^v, e^i) σθ(xtv,t,cv,ei), σ θ ( x i v , i , c i , e v ) \sigma_\theta (x_i^v, i , c^i, e^v) σθ(xiv,i,ci,ev)
3.3 Noisy Label Smoothing
3.3.1 Generalized Cross Entropy Loss(GCE)
L q ( f ( x ) , e j ) = ( 1 − f j ( x ) q ) q L_q (f(x),e_j) =\frac{(1 - f_j(x)^q)}{q} Lq(f(x),ej)=q(1−fj(x)q)
- 神经网络的更新是与损失函数的导数有关的。
- 当q 趋近于无穷时,等价于交叉熵损失(Cross-Entropy Loss,CCE)。上式求极限为
−
l
n
f
j
(
x
)
q
-ln f_j(x)^q
−lnfj(x)q
L q C E ( f ( x ) , e j ) = − l o g ( f j ( x ) ) L_q{CE} (f(x),e_j) =-log(f_j(x)) LqCE(f(x),ej)=−log(fj(x)) - 当q趋近于1时,等价于平均绝对误差(Mean Absolute Error,MAE)损失。
L M A E ( f ( x ) , e j ) = 2 ( 1 − f j ( x ) ) L_{MAE}(f(x),e_j) = 2(1- f_j(x)) LMAE(f(x),ej)=2(1−fj(x)) noise-robust
- 当q 趋近于无穷时,等价于交叉熵损失(Cross-Entropy Loss,CCE)。上式求极限为
−
l
n
f
j
(
x
)
q
-ln f_j(x)^q
−lnfj(x)q
- 是交叉熵损失和平均绝对误差损失的折中。
3.3.2 label-smoothing regularization (LSR)
y ^ = ( 1 − α ) y + α K \hat{y} = (1 - \alpha)y +\frac{\alpha}{K} y^=(1−α)y+Kα
- 目的是为了降低one-hot 标签的置信度。
4. Experiment
4.1 Comparison with GANs And Diffusion Models
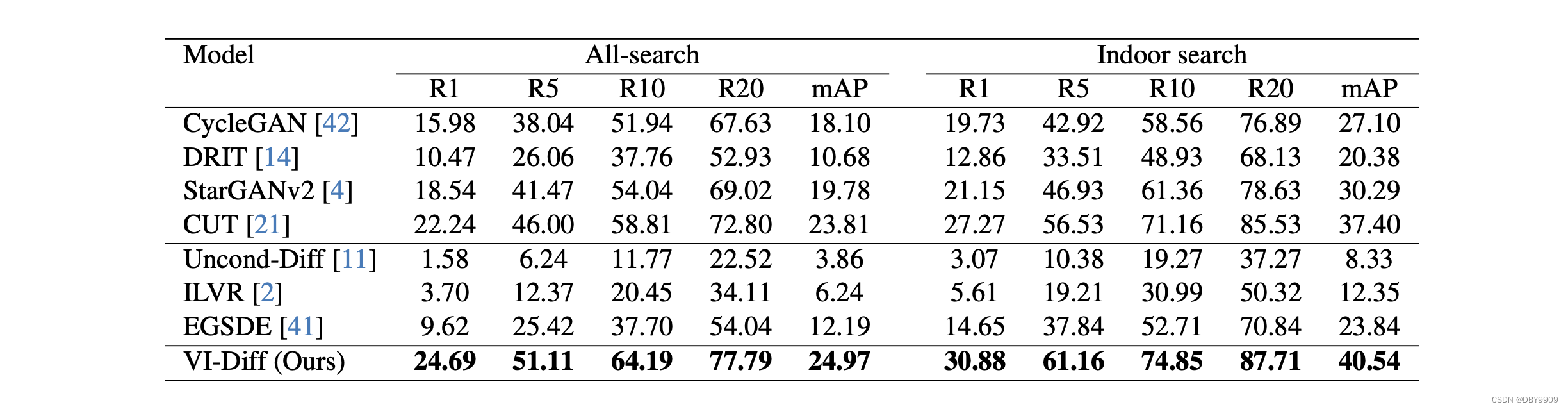
- 比普通GAN的方法性能好。
- 对比于未经改进的Diffusion方法。
4.2 Qualitative Evaluation
4.2.1 Translation Results Comparison

- GAN方法在转化过程中会丢失细节,导致结果受到影响和扭曲。
- ILVR和EGSDE)受到通过低通滤波器引入的色彩信息的不利影响(为什么不用高通?)
4.2.2 Visualization of Modality Gap in Conditions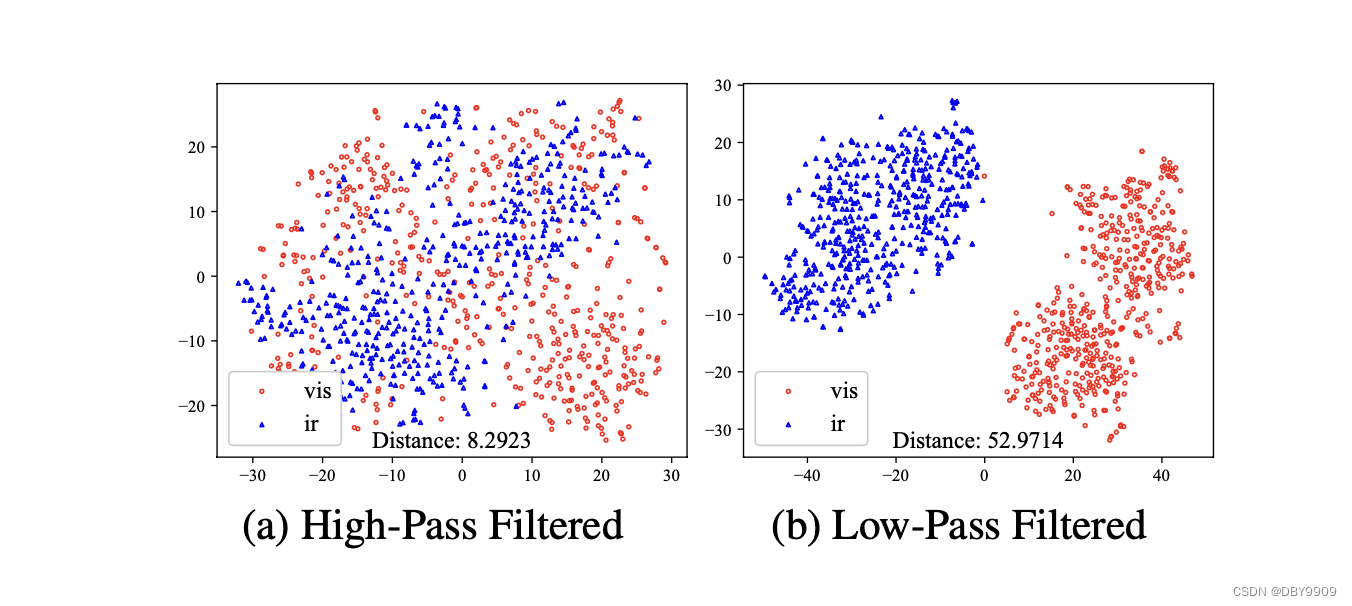
首先随机选择了500张可见图像和500张红外图像,分别将高通滤波器(Vi-Diff)和低通滤波器(ILVR/EGSDE中)应用到这些图像上。
- 两种模态的高通滤波条件图像存在相当大的重叠,表明模态差距减小了。
- 低通滤波图像显示出明显的模态差距。
VI-Diff通过高通滤波的图像是模态不敏感的,而现有扩散模型(即ILVR和EGSDE)中的低通滤波图像展现出显著的模态差距。
4.3 消融实验
4.3.1 Translation Without Condition c
- w/o 使用了SDEdit 方法,只给图片加一定程度的噪声,就重新采样返回。扩散到T / 2就返回。
4.3.2 Effectiveness of Noisy Label Smoothing
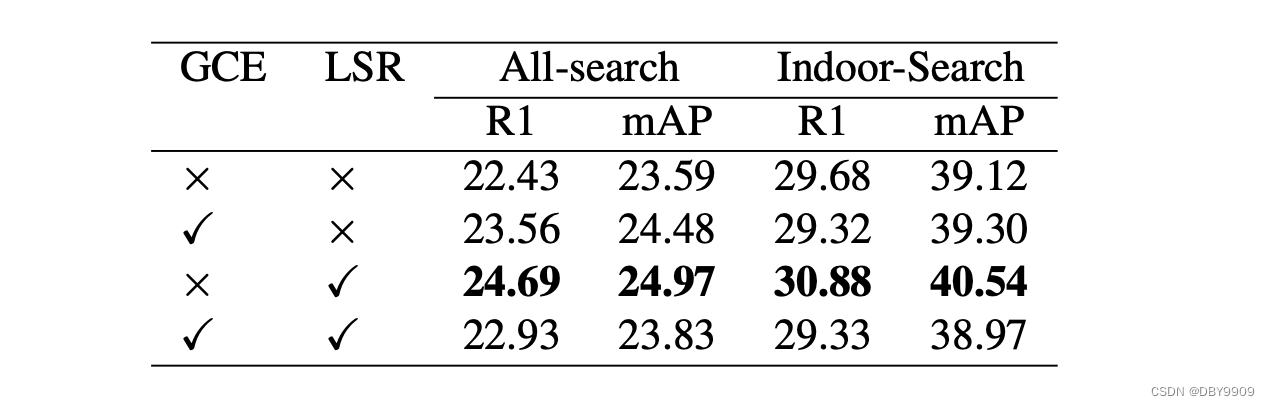
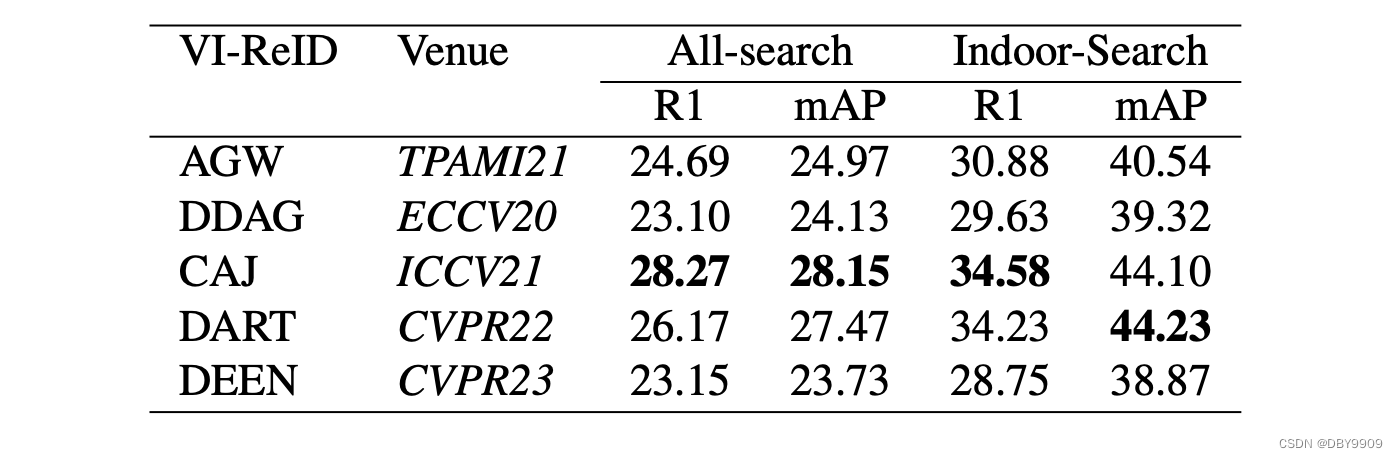
4.3.3 Comparison of Different VI-ReID models

















 800
800

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









