




 本文探讨了面向字的微处理器中缺乏有效支持的高级位操作,如位收集、位分散和位排列,并提出在微处理器中直接支持这些操作以加速多种应用。位收集(pex)指令用于并行提取分散的位,位分散(pdep)指令执行相反操作,将位分散存储。位排列(grp)和蝴蝶(bfly/ibfly)操作提供更灵活的位排列功能。这些指令可以通过简单的电路实现,并能显著提升包括生物信息学、模式匹配、压缩等应用的性能。
本文探讨了面向字的微处理器中缺乏有效支持的高级位操作,如位收集、位分散和位排列,并提出在微处理器中直接支持这些操作以加速多种应用。位收集(pex)指令用于并行提取分散的位,位分散(pdep)指令执行相反操作,将位分散存储。位排列(grp)和蝴蝶(bfly/ibfly)操作提供更灵活的位排列功能。这些指令可以通过简单的电路实现,并能显著提升包括生物信息学、模式匹配、压缩等应用的性能。
文章目录
Fast Bit Gather, Bit Scatter and Bit Permutation Instructions for Commodity Microprocessors
Y edidya Hilewitz & Ruby B. Lee
Abstract
面向字的商用微处理器不能有效地支持高级位操作操作。编程技巧通常被设计来缩短模拟这些复杂的位操作所需的长指令序列。由于这些位操作与日益重要的应用相关,我们建议在微处理器中直接支持它们。特别地,我们提出了快速位聚集(或并行提取)、位分散(或并行存放)和位置换指令(包括分组、蝶形和反蝶形)。我们表明,所有这些指令都可以使用快速蝶形和反向蝶形网络数据路径有效地实现。具体地说,我们证明了并行存放可以映射到一个蝶形电路上,而并行提取可以映射到一个反向蝶形电路上。我们定义指令的静态、动态和循环不变版本,静态版本利用简单得多的功能单元。我们展示了如何为动态和循环不变版本实现硬件解码器,以动态生成蝶形和反蝶形数据路径的控制信号。我们提出的最简单的功能单元比ALU更小更快。我们还表明,对于来自生物信息学、隐写术、编码、压缩和随机数生成等应用领域的各种不同应用内核,这些指令在基本RISC架构上产生了显著的加速。
Keywords
Bit manipulations.Permutations.Bit scatter.
Bit gather.Parallel extract.Parallel deposit.Pack.Unpack.
Microprocessors.Instruction set architecture.ISA.
Algorithm acceleration.Bioinformatics.Pattern matching.
Compression.Steganography.Cryptology
位操作。排列。比特分散。比特聚集。平行提取。并行存放.打包.解包微处理器。指令集架构. ISA .算法加速。生物信息学。模式匹配。压缩。隐写术,密码学
1. Introduction
位操作通常不被微处理器很好地支持。然而,这些类型的位操作与越来越重要的应用程序相关。以前,加速位操作主要与开发聪明的编程技巧有关,这些技巧以非直观的方式使用现有的微处理器特性来加速位串处理。许多这样的技巧已经被收集和发表,例如,在Hacker的Delight[1]。在这篇文章中,我们展示了如何在一个普通的微处理器中定义和有效地实现一些高级位操作指令,以加速大量的应用。
例如,模式匹配和搜索在数据挖掘应用中扮演着核心角色。这些数据可能是生物信息学中的遗传模式,生物识别学中的虹膜或指纹信息,通信监控中的关键词等。数据和搜索项可以用位串向量表示。我们进行比较,看看数据库记录中是否存在某些属性或特性集,然后从比较中收集结果位以进行进一步处理。我们称这为收集指令。
考虑生物信息学比对程序BLASTZ[2]。对齐程序获取两个DNA字符串,并试图在最佳匹配上对它们进行对齐(最佳匹配允许替换、插入和删除)。这些程序通常比较一个种子,一个DNA数据的短子串,如果匹配良好,种子就会扩展。BLASTZ程序允许在种子中指定某些子字符串位置,而其他子字符串位置作为通配符。程序选择并压缩指定子字符串位置中的数据,并将结果用作哈希表的索引,以查找在第二个字符串中找到该种子的位置。这些步骤涉及对位串的几个位操作。而不是让位操作的加速被降级到深奥的“编程技巧”[1,3],我们想要通过直接构建对这些操作的支持到商品化的微处理器来加速位操作。超级计算机通常直接支持高级位操作(例如,参见Cray位矩阵乘指令[4])。我们将展示,我们可以向一个商品微处理器添加一个低成本的功能单元,该功能单元支持一组有用的比特操作,可加速许多不同的应用程序。
具体来说,我们建议支持的操作有:
- 位收集操作,我们也称其为并行提取[5,6];
- 位分散操作,我们也称之为并行存储[6];
- 位排列,它可以任意重新排列处理器字中的位。具体来说,我们重点研究了蝴蝶和蝴蝶逆排列指令[7-9]和群排列指令[10,11]。
我们给出了这些指令的指令集体系结构(ISA)定义,考虑了这些操作的使用模式,并展示了如何使用几个简单的电路构建块来设计一个支持这些指令的高效功能单元。我们证明了位收集操作可以映射到反向蝴蝶网络,位分散操作可以映射到蝴蝶网络。我们建议的最简单的功能单元是比算术逻辑单元(ALU)更小和更快。我们还表明,这些指令改善了许多应用程序的性能,包括生物信息学、图像处理、隐写术、压缩和编码。我们的性能结果表明,并行存储和并行提取指令增强的处理器在基本的RISC体系结构上的最大加速达到10.04×,平均加速2.29×。
本文的组织如下:第2节描述了我们的高级位操作。第3节讨论了执行操作所需的数据路径,最后概述了高级位操作功能单元。第4节总结了新指令的ISA定义。第5节详细介绍了从位操作指令中受益的应用程序,第6节总结了基准测试结果。第7节提供了功能单元的详细实现,并给出了综合结果。第8节给出了相关的工作。第9节总结全文。
2. Advanced Bit Manipulation Operations
微处理器中的简单位操作包括and, or, xor和not。这些是位并行操作,在面向字的处理器中很容易完成。微处理器中其他常见的非位并行的位操作指令是移位和旋转指令。在这些指令中,一个字中的所有位移动相同的量。在本节中,我们将介绍更高级的位操作指令,这些指令目前还没有出现在普通的微处理器中。在当前的微处理器中,每一种操作都需要花费数十到数百个周期来模拟。但是,通过为它们定义新的指令,每个指令都可以在一个或几个循环中实现。
2.1 Bit Gather or Parallel Extract: pex
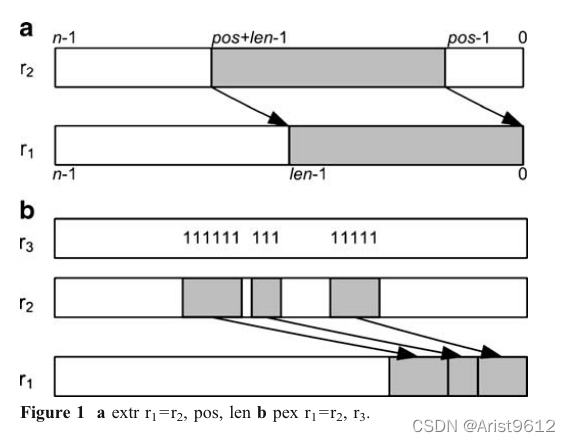
位收集指令收集分散在寄存器中的位,并将它们连续地放在结果中。这样从数据中选择非连续位通常是必要的。例如,在模式匹配中,可以比较许多对特征。然后,这些比较结果位的一个子集被选择、压缩并用作索引来查找表。这种位的选择和压缩是位收集指令。位收集指令也可以被认为是并行提取指令,或pex指令[5,6]。之所以这样命名,是因为它类似于extract (extr)指令的并行版本[12,13]。图1比较了extr和pex。extr指令从源寄存器的任意位置提取单个位域,并在目标寄存器中对其进行右对齐。pex指令从源寄存器中提取多个位域,压缩它们并在目标寄存器中对其右对齐。选定的位(在r2中)由位掩码(在r3中)指定,并在结果寄存器(r1)中连续和右对齐放置。
2.2 Bit Scatter or Parallel Deposit: pdep
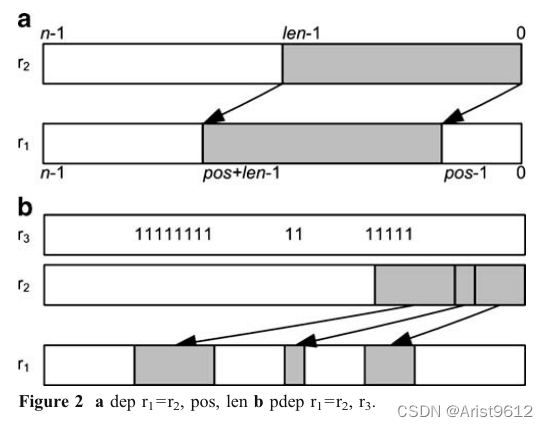
Bit Scatter(位分散)取寄存器中右对齐的、连续的位,并根据第二个输入寄存器中的掩码将其分散到结果寄存器中。这是位收集的反向操作。我们也称位分散为并行存储指令(pdep),因为它类似于在PA-RISC[12,13]和ia - 64[14]等处理器中发现的存储(dep)指令的并行版本。图2比较了dep和pdep。存储(dep)指令从源寄存器中取一个右对齐的位域,并将其存储在目标寄存器中的任何单个位置。并行存储(pdep)指令从源寄存器中取一个右对齐的位域,并将这些位存储在由位掩码指示的不同的非连续位置。
2.3 Bit Permutation Primitive: grp
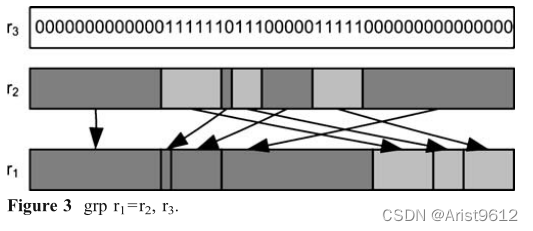
在[10,11]中,Shi和Lee定义了一种位排列指令grp,并证明了最多由lg(n)条grp指令组成的序列可以完成任意位排列,其中n是处理器的字大小。grp是一种排列原语,它将掩码中“1”选择的数据位向右收集,将掩码中“0”选择的数据位向左收集(见图3)。这可以看作是两个并行操作:grp_right (grpr)和grp_left (grpl)[15]。pex指令是grp操作的grp_right部分。它保留了grp的一些最有用的属性,同时更容易实现——原本应该收集到左边的位被归零了。
2.4 Butterfly and Inverse Butterfly Operations: bflyand ibfly
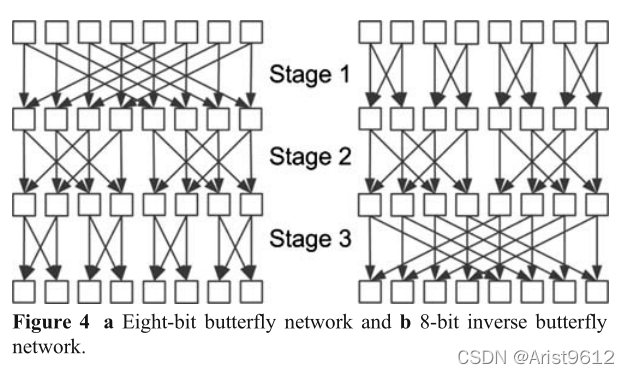
虽然grp操作可以用于在lg(n)指令中实现任意n位的排列,Lee [7-9]还发现了位置换原语,它可以在两个指令中完成这一操作。这就是蝴蝶(bfly)和反蝴蝶(ibfly)指令,它们分别使用蝴蝶和反蝴蝶网络对它们的输入进行置换(图4)。蝴蝶和反蝴蝶网络的串联形成一个Beneš网络,一个通用的置换网络[16]。因此,只需执行一次bfly,然后执行ibfly,就可以计算n!个n位的排列。
网络结构如图4所示,其中n=8。n位网络由lg(n)级组成。每级由n/2双输入开关组成,每个开关由两个2:1多路复用器构成。这些网络比相同宽度的ALU要快,因为ALU也有lg(n)级,比蝴蝶电路和反蝴蝶电路复杂。假设处理器周期足够长来覆盖ALU的延迟,每个bfly和ibfly操作都将有单周期延迟,因为这些电路比ALU的电路简单。此外,由于每个网络只有n×lg(n)多路复用器,整体电路面积较小。(请参阅第7节了解电路评估的细节。)
在第i级(i=1,2,3…),蝶形网络的输入位间隔为n/(2^i)位,反向网络的输入位间隔为2 ^(i−1)位。交换机根据配置位的值通过或交换其输入。因此,bfly或ibfly操作需要n/2×lg(n)个配置位。对于n=64,除了一个用于输入的寄存器外,还需要三个64位寄存器来保存配置位。因此,当bfly后面跟着ibfly指令时,最多可以在两条指令中完成任意的nbit排列,而不是需要lg(n)个 GRP指令,GRP每条指令只需要两个n位操作数,而bfly或ibfly每条指令需要(1+lg(n)/2) n位操作数。这提出了一个挑战,因为典型的isa和处理器数据路径每条指令只支持两个操作数。我们将在3.4节对此进行更详细的讨论。

















 1386
1386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









