




JDK原生序列化
示例代码:
import java.io.*;
public class Student implements Serializable {
private int no;
private String name;
public int getNo() {
return no;
}
public void setNo(int no) {
this.no = no;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "Student{" +
"no=" + no +
", name='" + name + '\'' +
'}';
}
public static void main(String[] args) throws IOException, ClassNotFoundException {
String home = System.getProperty("user.home");
String basePath = home + "/Desktop";
FileOutputStream fos = new FileOutputStream(basePath + "student.dat");
Student student = new Student();
student.setNo(100);
student.setName("TEST_STUDENT");
ObjectOutputStream oos = new ObjectOutputStream(fos);
oos.writeObject(student);
oos.flush();
oos.close();
FileInputStream fis = new FileInputStream(basePath + "student.dat");
ObjectInputStream ois = new ObjectInputStream(fis);
Student deStudent = (Student) ois.readObject();
ois.close();
System.out.println(deStudent);
}
}
JDK序列化具体的实现是由ObjectOutputStream完成的,而反序列化的具体实现是由ObjectInputStream完成的。
JDK的序列化过程:
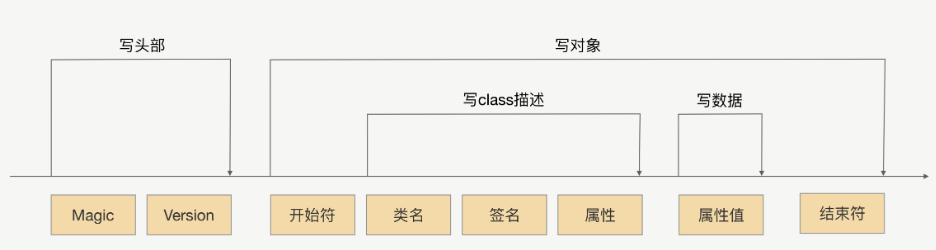
序列化过程就是在读取对象数据的时候,不断加入一些特殊分隔符,这些特殊分隔符用于在反序列化过程中截断用。
- 头部数据用来声明序列化协议、序列化版本,用于高低版本向后兼容
- 对象数据主要包括类名、签名、属性名、属性类型及属性值,当然还有开头结尾等数据,除了属性值属于真正的对象值,其他都是为了反序列化用的元数据
- 存在对象引用、继承的情况下,就是递归遍历“写对象”逻辑。
任何一种序列化框架,核心思想就是设计一种序列化协议。
JSON
典型的Key-Value方式,没有数据类型,是一种文本型序列化框架。
JSON进行序列化有两个问题:
- JSON进行序列化的额外空间开销比较大,对于大数据量服务这意味着需要巨大的内存和磁盘开销;
- JSON没有类型,像Java这种强类型语言,需要通过反射统一解决,所以性能不会太好。
如果RPC框架选用JSON序列化,服务提供者与服务调用者之间传输的数据量要相对较小,否则将严重影响性能。
Hessian
Hessian是动态类型、二进制、紧凑的,并且可跨语言移植的一种序列化框架。Hessian协议要比JDK、JSON更加紧凑,性能上要比JDK、JSON序列化高效很多,而且生成的字节数也更小。
代码如下:
Student student = new Student();
student.setNo(101);
student.setName("HESSIAN");
// 把student对象转化为byte数组
ByteArrayOutputStream bos = new ByteArrayOutputStream();
Hessian2Output output = new Hessian2Output(bos);
output.writeObject(student);
output.flushBuffer();
byte[] data = bos.toByteArray();
bos.close();
// 把刚才序列化出来的byte数组转化为student对象
ByteArrayInputStream bis = new ByteArrayInputStream(data);
Hessian2Input input = new Hessian2Input(bis);
Student deStudent = (Student) input.readObject();
input.close();
System.out.println(deStudent);
相对于JDK、JSON,由于Hessian更加高效,生成的字节数更小,有非常好的兼容性和稳定性,所以Hessian更加适合作为RPC框架远程通信的序列化协议。
但Hessian也有问题,官方版本对Java里面一些常见对象的类型不支持,比如:
- Linked系列,LinkedHashMap、LinkedHashSet等,但是可以通过扩展CollectionDeserializer类修复;
- Locale类,可以通过扩展ContextSerializerFactory类修复;
- Byte/Short反序列化的时候变成Integer。
在使用Hessian做序列化框架时,需要注意上述类型不兼容问题。
Protobuf
Protobuf 是 Google 公司内部的混合语言数据标准,是一种轻便、高效的结构化数据存储格式,可以用于结构化数据序列化,支持Java、Python、C++、Go等语言。Protobuf使用的时候需要定义IDL(Interface description language),然后使用不同语言的IDL编译器,生成序列化工具类。
优点:
- 序列化后体积相比 JSON、Hessian小很多;
- IDL能清晰地描述语义,足以帮助并保证应用程序之间的类型不会丢失,无需类似 XML 解析器;
- 序列化反序列化速度很快,不需要通过反射获取类型;
- 消息格式升级和兼容性不错,可以做到向后兼容。
代码示例:
/**
*
* // IDl 文件格式
* synax = "proto3";
* option java_package = "com.test";
* option java_outer_classname = "StudentProtobuf";
*
* message StudentMsg {
* //序号
* int32 no = 1;
* //姓名
* string name = 2;
* }
*
*/
StudentProtobuf.StudentMsg.Builder builder = StudentProtobuf.StudentMsg.newBuilder();
builder.setNo(103);
builder.setName("protobuf");
// 把student对象转化为byte数组
StudentProtobuf.StudentMsg msg = builder.build();
byte[] data = msg.toByteArray();
// 把刚才序列化出来的byte数组转化为student对象
StudentProtobuf.StudentMsg deStudent = StudentProtobuf.StudentMsg.parseFrom(data);
System.out.println(deStudent);
Protobuf 非常高效,但是对于具有反射和动态能力的语言来说,用起来很费劲,这一点就不如Hessian,比如用Java的话,这个预编译过程不是必须的,可以考虑使用Protostuff。
Protostuff不需要依赖IDL文件,可以直接对Java领域对象进行反/序列化操作,在效率上跟Protobuf差不多,生成的二进制格式和Protobuf是完全相同的,可以说是一个Java版本的Protobuf序列化框架。
一些不支持的情况:
- 不支持null;
- ProtoStuff不支持单纯的Map、List集合对象,需要包在对象里面。
RPC框架应该如何选择序列化?
参考几点指标:
- 序列化与反序列化的性能和效率势必将直接关系到RPC框架整体的性能和效率。
- 空间开销(序列化之后的二进制数据的体积大小)。序列化后的字节数据体积越小,网络传输的数据量就越小,传输数据的速度也就越快,由于RPC是远程调用,那么网络传输的速度将直接关系到请求响应的耗时。
- 序列化协议的通用性和兼容性。
- 序列化协议安全性。
在序列化的选择上,与序列化协议的效率、性能、序列化协议后的体积相比,其通用性和兼容性的优先级会更高,因为他是会直接关系到服务调用的稳定性和可用率的,对于服务的性能来说,服务的可靠性显然更加重要。
更加看重这种序列化协议在版本升级后的兼容性是否很好,是否支持更多的对象类型,是否是跨平台、跨语言。
序列化协议的安全性也是非常重要的一个参考因素,甚至应该放在第一位去考虑。以JDK原生序列化为例,它就存在漏洞。如果序列化存在安全漏洞,那么线上的服务就很可能被入侵。

首选的还是Hessian与Protobuf,因为他们在性能、时间开销、空间开销、通用性、兼容性和安全性上,都满足上述要求。其中Hessian在使用上更加方便,在对象的兼容性上更好;Protobuf则更加高效,通用性上更有优势。
RPC框架在使用时要注意哪些问题?
-
对象构造得过于复杂:属性很多,并且存在多层的嵌套,对象依赖关系过于复杂。序列化框架在序列化与反序列化对象时,
对象越复杂就越浪费性能,消耗CPU,这会严重影响RPC框架整体的性能;另外,对象越复杂,在序列化与反序列化的过程中,出现问题的概率就越高。 -
对象过于庞大:
入参对象非常大,比如为一个大List或者大Map,序列化之后字节长度达到了上兆字节。这种情况同样会严重地浪费了性能、CPU,并且序列化一个如此大的对象是很耗费时间的,会直接影响到请求的耗时。 -
使用序列化框架不支持的类作为入参类:比如Hessian框架,天然是不支持LinkedHashMap、LinkedHashSet等,而且
大多数情况下最好不要使用第三方集合类,如Guava中的集合类,很多开源的序列化框架都是优先支持编程语言原生的对象。因此如果入参是集合类,应尽量选用原生的、最为常用的集合类,如HashMap、ArrayList。 -
对象有复杂的继承关系:大多数序列化框架在序列化对象时都会将对象的属性一一进行序列化,当有继承关系时,会不停地寻找父类,遍历属性。对象关系越复杂,就越浪费性能,同时很容易出现序列化上的问题。
在RPC框架的使用过程中,尽量构建简单的对象作为入参和返回值对象,避免上述问题。



















 565
565

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











