






 本文详细介绍了SQL查询的基本语法,包括SELECT、WHERE、GROUP BY、HAVING、ORDER BY和LIMIT子句的用法。通过实例解析了如何进行数据筛选、分组统计、排序和限制查询结果的数量。同时,讲解了在使用GROUP BY时配合统计函数如COUNT、MAX、MIN、AVG和SUM进行数据分析的方法。此外,还提到了HAVING子句在分组统计中的独特作用。
本文详细介绍了SQL查询的基本语法,包括SELECT、WHERE、GROUP BY、HAVING、ORDER BY和LIMIT子句的用法。通过实例解析了如何进行数据筛选、分组统计、排序和限制查询结果的数量。同时,讲解了在使用GROUP BY时配合统计函数如COUNT、MAX、MIN、AVG和SUM进行数据分析的方法。此外,还提到了HAVING子句在分组统计中的独特作用。
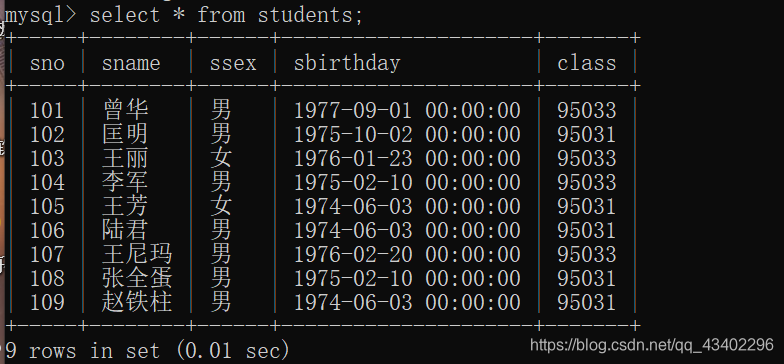
本数据库的数据,借用一下sq学姐的博客数据库数据:数据准备
然后下面进行我们的数据查询学习;
查询数据基本语法:
select + 字段列表/* + from + 表名 + [where 条件];
完整语法:
select + [select 选项] + 字段列表[字段别名]/* + from + 数据源 + [where 条件] + [1] + [2] + [3];
- [1] = [group by 子句]
- [2] = [order by 子句]
- [3] = [limit 子句]
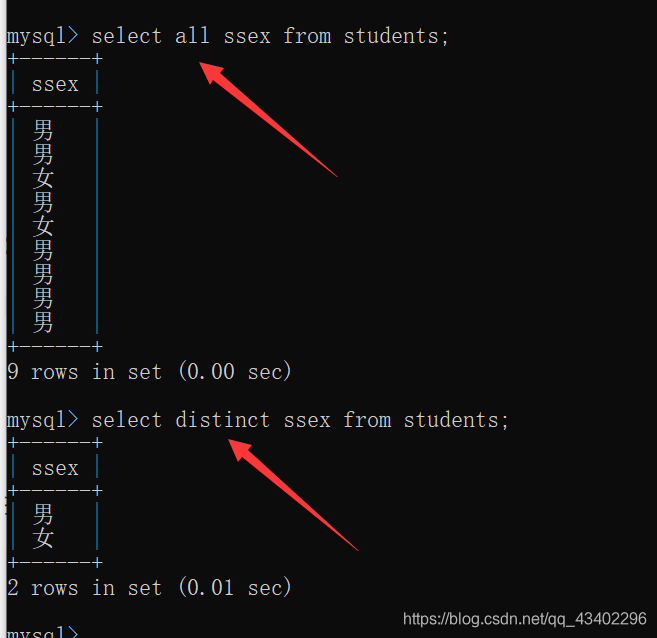
select 选项
- all :默认操作,表示保留所有的查询结果;
- distinct : 去重,将查出的结果中所有字段相同的记录去除;
例如:select all ssex from students;
和select distinct ssex from students;
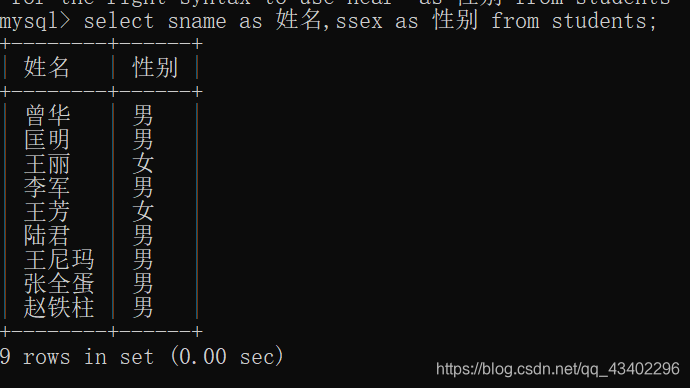
字段别名
就是对查询的字段取别名;
基本语法 字段名+ as+别名;
例如:select sname as 姓名,ssex as 性别 from students;
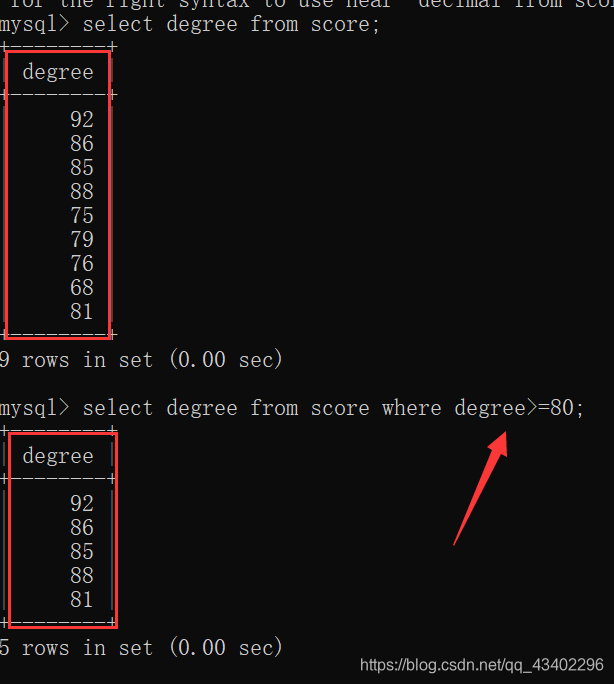
where 子句
where子句:
用来判断数据和筛选数据,返回的结果为0或者1,其中0代表false,1代表true,where是唯一一个直接从磁盘获取数据的时候就开始判断的条件,从磁盘中读取一条数据,就开始进行where判断,如果判断的结果为真,则保持,反之,不保存。
判断条件
- 比较运算符:>、<、>=、<=、<>、=、like、between and、in和not in;
- 逻辑运算符:&&、||、和!
下面就简单举一个>=的例子。
注意:在使用between and的时候,其选择的区间为闭区间,即包含端点值。
group by 子句
group by子句:根据表中的某个字段进行分组,即将含有相同字段值的记录放在一组,不同的放在不同组。
基本语法
group by + 字段名;
group by分组的目的是为了(按分组字段)统计数据,并不是为了单纯的进行分组而分组。为了方便统计数据,SQL 提供了一系列的统计函数,例如:
cout():统计分组后,每组的总记录数;
max():统计每组中的最大值;
min():统计每组中的最小值;
avg():统计每组中的平均值;
sum():统计每组中的数据总和。
举个例子:
select ssex,count(),max(sbirthday),min(sbirthday),avg(sbirthday),sum(sbirthday) from students group by ssex;

其中count()函数里面可以使用两种参数,分别为: ==== 表示统计全部记录的数量;字段名表示统计对应字段的非null的字段数量。
咱们在之前的示例中,是用单字段进行分组。实际上,咱们也可以使用多字段分组,即:先根据一个字段进行分组,然后对分组后的结果再次按照其他字段(前提是分组后的结果中包含此字段)进行分组。
having 子句
having 字句:和where一样,都是进行条件判断。但是having 要比where做的能力更多一点。
- 第 1 点:分组统计的结果或者说统计函数只有having能够使用
- 第 2 点:having能够使用字段别名,where则不能
order by子句
order by 子句:根据某个字段进行升序或者降序排序,依赖校对集。
基本语法: order by +[asc/desc];
其中,asc为升序,为默认值;desc为降序。
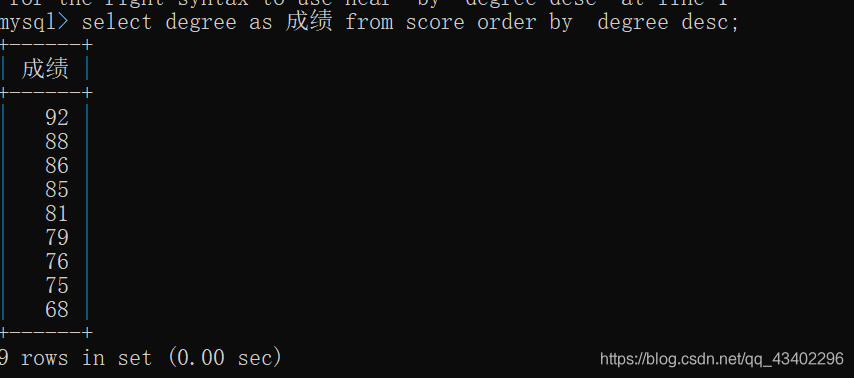
例如 给成绩排个序
select degree as 成绩 from score order by degree desc;
limit 子句
limit子句:是一种限制结果的语句,通常来限制结果的数量。
基本语法:limit + [offset] + length;
其中,offset为起始值;length为长度。
举个例子:select * from students limit 0,2;
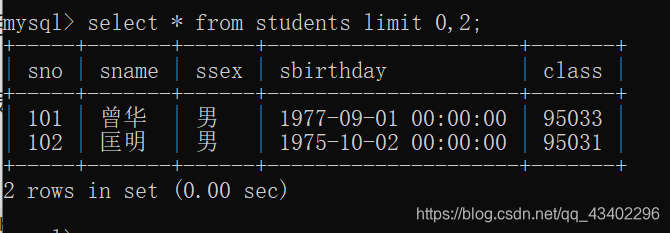
意思是:从第0条记录开始,选择2条记录,展示出来。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









