




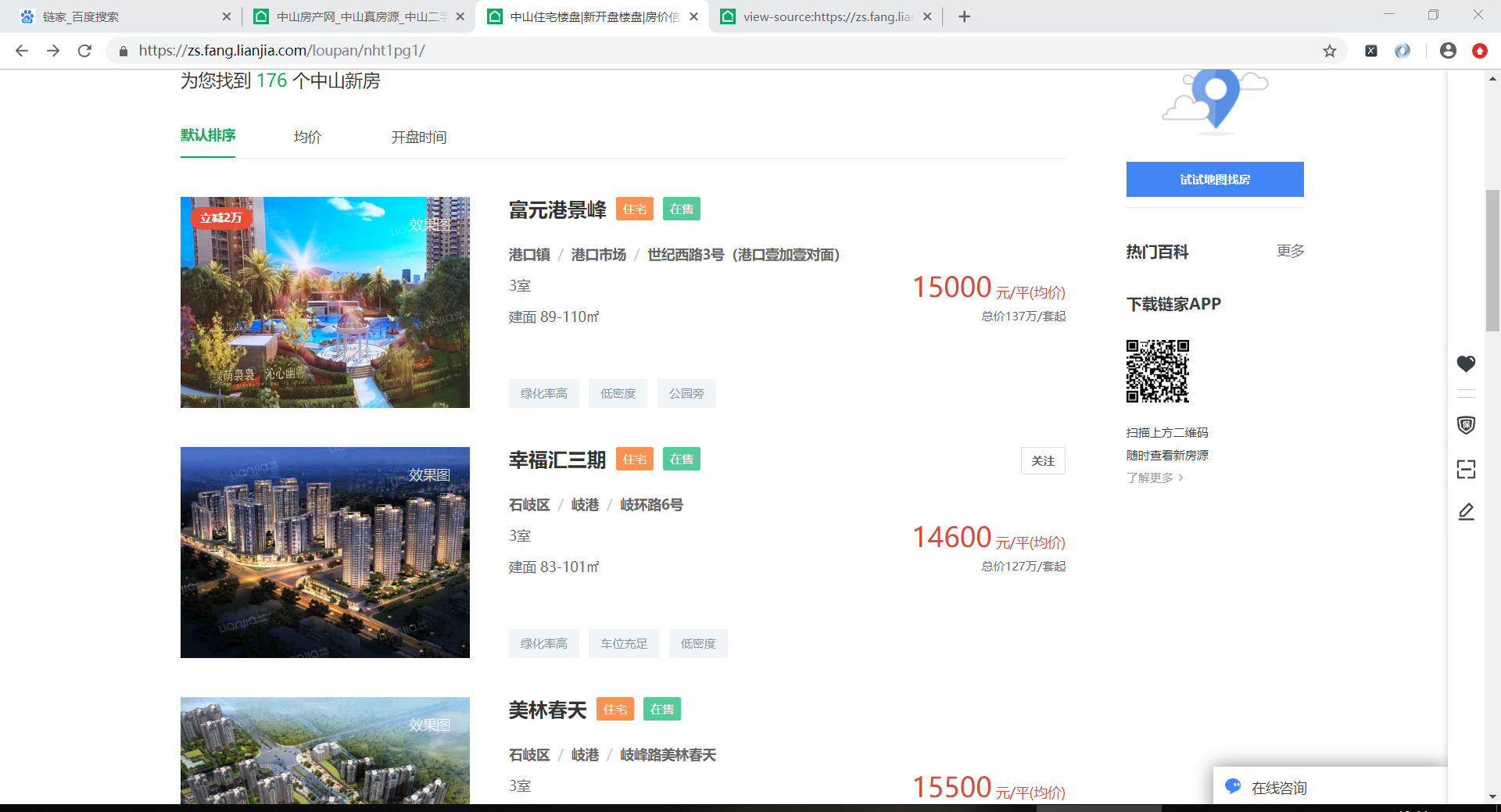
 本文介绍了一款使用Python的requests库和lxml库抓取链家网站房价数据的爬虫程序,该程序能有效获取并保存楼盘名称、地址、房间格式、面积、价格等详细信息。
本文介绍了一款使用Python的requests库和lxml库抓取链家网站房价数据的爬虫程序,该程序能有效获取并保存楼盘名称、地址、房间格式、面积、价格等详细信息。
感觉最近做的东西好菜~~随便了。
import requests
from lxml import etree
import csv
headers = {
'Referer': 'https://zs.fang.lianjia.com/loupan/nht1pg1/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36',
}
fp = open('D://链家房价数据.csv','wt',newline='',encoding='utf8')
writer = csv.writer(fp)
writer.writerow(('楼盘名', '地址', '房间格式', '房间面积', '价格', '起价', '优点'))
def get_html(url):
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.content.decode('utf8')
else:
print('1')
return None
except:
print('2')
return None
def get_info(html):
selector = etree.HTML(html)
li_list = selector.xpath(
'//li[contains(@class, "resblock-list")]/div[@class="resblock-desc-wrapper"]')
for li in li_list:
try:
name = li.xpath(
"div[@class='resblock-name']/a[@class='name ']/text()")[0]
adress_1 = li.xpath(
"div[@class='resblock-location']/span[1]/text()")[0]
adress_2 = li.xpath(
"div[@class='resblock-location']/span[2]/text()")[0]
adress_3 = li.xpath("div[@class='resblock-location']/a/text()")[0]
adress = adress_1 + '/' + adress_2 + '/' + adress_3
how_many_1 = li.xpath("a[@class='resblock-room']/span[1]/text()")[0]
how_many_2 = li.xpath("a[@class='resblock-room']/span[2]/text()")
if how_many_2:
how_many_1 = how_many_1 + '/' + how_many_2[0]
else:
pass
minaji = li.xpath("div[@class='resblock-area']/span/text()")[0]
price = li.xpath(
"div[@class='resblock-price']/div[@class='main-price']/span[@class='number']/text()")[0]
price += '元/平(均价)'
qijia = li.xpath(
"div[@class='resblock-price']/div[@class='second']/text()")[0]
advantge = li.xpath("div[@class='resblock-tag']//text()")
mylist = []
for i in advantge:
j = i.strip()
if len(j) == 0:
continue
else:
mylist.append(j)
real_advantge = ','.join(mylist)
x = [name, adress, how_many_1, minaji, price, qijia, real_advantge]
print(x)
writer.writerow(x)
except:
pass
if __name__ == '__main__':
urls = ['https://zs.fang.lianjia.com/loupan/nht1pg{}/'.format(i) for i in range(1,19)]
for url in urls:
html = get_html(url)
get_info(html)
结果


















 354
354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









