




 本文深入探讨了支持向量机(SVM)的数学原理及工程应用。从模型思路出发,详细解析了SVM如何通过寻找最优分离超平面解决分类问题,并介绍了拉格朗日对偶在求解SVM最优化问题中的作用。此外,还讨论了核函数如何增强SVM的拟合能力。
本文深入探讨了支持向量机(SVM)的数学原理及工程应用。从模型思路出发,详细解析了SVM如何通过寻找最优分离超平面解决分类问题,并介绍了拉格朗日对偶在求解SVM最优化问题中的作用。此外,还讨论了核函数如何增强SVM的拟合能力。
机器学习(六)——支持向量机
概述
支持向量机(Support Vector Machine,SVM)是一个非常强大的分类模型,它曾经被称为万能分类器。这个模型在数学的处理和推导上较为复杂,本文会在大体上介绍这个模型的数学原理,对于证明细节将不会涉及。
本文主要讨论二分类的问题,对于多元分类问题,SVM通常采用OVR的方法,将多分类问题转化为多个二元分类问题,具体实现方法与逻辑回归中相同,将不再赘述。
模型思路
首先我们考虑一个简单的情况,我们有一系列含有两个特征的样本,它们分别被分类为0和1,我们将散点图绘制出来,可以很自然地想到一个思路:是否可以用一条直线来将平面分成两部分:一部分全部为0,一部分全部为1呢?于是我们画出这样的图像:
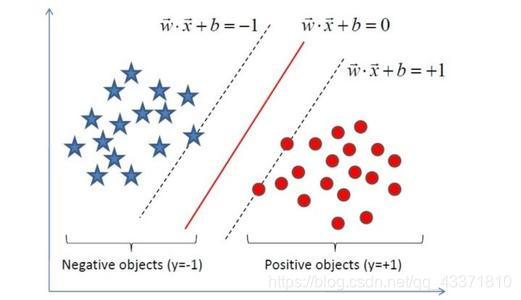
这样可以用一条直线(或是点、平面、超平面)将两类样本完全分开的数据在学术上被称为线性可分,这条直线(或点、平面、超平面)被称为分离超平面。这类模型被称为线性支持向量机。
然而,现实情况下的数据往往不是这样的,在绝大多数情况下,数据都不是线性可分的。这个时候,我们只能将偏差定义为一个损失函数,然后找到使得损失函数最小的分离超平面。
代数抽象
接下来我们就将这个问题转化为代数问题,首先定义假设函数,也就是模型的形式。我们知道在线性支持向量机中,假设函数应当是点、直线、平面、超平面的形式,用一个公式表示出来,就是:
H
(
w
⃗
)
:
w
⃗
⋅
x
⃗
+
b
=
0
H(\vec{w}):\vec{w}\cdot\vec{x}+b=0
H(w):w⋅x+b=0对于线性可分的数据,我们发现实际上会有无数条直线能够将两种类别的数据分割开来,这时,我们怎么选择这条直线呢?有这样的一个原则:我们需要找到一条直线(点、平面、超平面,以下皆用直线指代),使得对于不同类别的、距离这条直线最近的两个点,到这条直线的距离相等,而且到这条直线的距离之和最大。设这两个点到分离直线最近的点满足:
w
⃗
⋅
x
⃗
+
b
=
±
1
\vec{w}\cdot\vec{x}+b=\pm1
w⋅x+b=±1 这就是上图中的两条虚线的直线方程。根据点到直线的距离公式,可以得到这两个点到分离直线的距离为:
l
=
1
∥
w
⃗
∥
(
∥
w
∥
表
示
向
量
的
模
)
l=\frac{1}{\|\vec{w}\|}(\|w\|表示向量的模)
l=∥w∥1(∥w∥表示向量的模) 这样我们就能把问题转化为数学上的最优化问题:
m
a
x
2
∥
l
∥
=
2
∥
w
∥
任
意
X
属
于
类
别
1
,
w
⃗
⋅
x
⃗
+
b
≥
1
任
意
X
属
于
类
别
0
,
w
⃗
⋅
x
⃗
+
b
≤
−
1
\left. \begin{aligned} max2&\|l\|=\frac{2}{\|w\|} \\ 任意X属于类别1,&\vec{w}\cdot\vec{x}+b\geq1 \\ 任意X属于类别0,&\vec{w}\cdot\vec{x}+b\leq-1 \end{aligned} \right.
max2任意X属于类别1,任意X属于类别0,∥l∥=∥w∥2w⋅x+b≥1w⋅x+b≤−1 为了数学上方便处理,我们用
y
=
1
y=1
y=1表示类别1,用
y
=
−
1
y=-1
y=−1表示类别0,我们可以方便地把两个条件合并成一个,同时,因为损失函数应当是一个最小化问题,通过取倒数再平方,我们可以将最大化问题转化为最小化问题:
m
i
n
∥
w
∥
2
2
y
(
w
⃗
⋅
x
⃗
+
b
)
≥
1
\left. \begin{aligned} min&\frac{\|w\|^2}{2}\\ y(\vec{w}\cdot\vec{x}&+b)\geq1 \end{aligned} \right.
miny(w⋅x2∥w∥2+b)≥1
∥
w
∥
2
\frac{\|w\|}{2}
2∥w∥就是线性可分情况的损失函数,接下来考虑误分类的情况,对于SVM来说,分类正确的样本对损失函数的贡献应该为0,分类错误或者处在两条直线之间时,我们放宽上述优化问题的约束条件:
y
(
w
⃗
⋅
x
⃗
+
b
)
≥
1
−
ξ
y(\vec{w}\cdot\vec{x}+b)\geq1-\xi
y(w⋅x+b)≥1−ξ移项后将不等号改为等号,我们就将
ξ
\xi
ξ作为单个分类错误或者处在两条直线之间的样本对损失函数的贡献,将两种情况统一起来,我们可以得到单个样本对损失函数的贡献为:
m
a
x
(
0
,
1
−
y
(
w
⃗
⋅
x
⃗
+
b
)
)
max(0,1-y(\vec{w}\cdot\vec{x}+b))
max(0,1−y(w⋅x+b))将我们上述的讨论综合起来,统一定义一个支持向量机的损失函数:
L
(
w
⃗
)
=
∥
w
∥
2
2
+
C
∑
m
a
x
(
0
,
1
−
y
(
w
⃗
⋅
x
⃗
+
b
)
)
L(\vec{w})=\frac{\|w\|^2}{2}+C\sum max(0,1-y(\vec{w}\cdot\vec{x}+b))
L(w)=2∥w∥2+C∑max(0,1−y(w⋅x+b)) 式子中
C
C
C为损失系数,是一个超参数,实际上是模型预测损失的权重,损失系数越大,模型就会越“在意”预测错误的损失,而轻视两条虚线间的距离,从而导致虚线之间的距离更小。在实际应用中,对于
C
C
C的处理与之前讨论的超参数没有什么区别,一般采用网格搜索法或者根据实际需求来确定取值。
工程求解——拉格朗日对偶
接下来我们来讨论怎么求解SVM的最优化问题,这一段涉及的数学知识较多,我会尽量讲述思路而忽略中间的数学推导。
首先来介绍拉格朗日对偶。我们把优化问题写成一般形式:
m
i
n
f
(
θ
)
g
i
(
θ
)
≥
0
(
i
=
1
,
2
,
.
.
.
,
k
)
h
i
(
θ
)
=
0
(
i
=
1
,
2
,
.
.
.
,
l
)
\left. \begin{aligned} min&f(\theta)\\ g_i(\theta)\geq&0(i=1,2,...,k)\\ h_i(\theta)=&0(i=1,2,...,l) \end{aligned} \right.
mingi(θ)≥hi(θ)=f(θ)0(i=1,2,...,k)0(i=1,2,...,l)在高等数学中,我们学习过拉格朗日乘数法,我们就由拉格朗日乘数法定义拉格朗日函数:
L
(
θ
,
α
⃗
,
β
⃗
)
=
f
(
θ
)
+
∑
i
k
α
i
g
i
(
θ
)
+
∑
i
l
β
i
h
i
(
θ
)
L(\theta,\vec{\alpha},\vec{\beta})=f(\theta)+\sum_i^k\alpha_ig_i(\theta)+\sum_i^l\beta_ih_i(\theta)
L(θ,α,β)=f(θ)+i∑kαigi(θ)+i∑lβihi(θ)然后我们确定拉格朗日乘数
α
⃗
,
β
⃗
\vec{\alpha},\vec{\beta}
α,β的值,让
L
(
θ
,
α
⃗
,
β
⃗
)
L(\theta,\vec{\alpha},\vec{\beta})
L(θ,α,β)最大化,定义:
P
(
θ
)
=
m
a
x
α
,
β
L
(
θ
,
α
⃗
,
β
⃗
)
P(\theta)=max_{\alpha,\beta}L(\theta,\vec{\alpha},\vec{\beta})
P(θ)=maxα,βL(θ,α,β)那么整个最优化问题等价为一个双重优化问题(原始问题):
m
i
n
P
(
θ
)
=
m
i
n
θ
m
a
x
α
,
β
L
(
θ
,
α
⃗
,
β
⃗
)
minP(\theta)=min_\theta max_{\alpha,\beta}L(\theta,\vec{\alpha},\vec{\beta})
minP(θ)=minθmaxα,βL(θ,α,β)接下来来定义所谓的对偶问题,实际上就是将最大化和最小化过程换一个位置。我们不妨设
D
(
α
⃗
,
β
⃗
)
=
m
i
n
θ
L
(
θ
,
α
⃗
,
β
⃗
)
D(\vec{\alpha},\vec{\beta})=min_\theta L(\theta,\vec{\alpha},\vec{\beta})
D(α,β)=minθL(θ,α,β),得到对偶问题为:
m
a
x
α
,
β
D
(
α
⃗
,
β
⃗
)
=
m
a
x
α
,
β
m
i
n
θ
L
(
θ
,
α
⃗
,
β
⃗
)
max_{\alpha,\beta}D(\vec{\alpha},\vec{\beta})=max_{\alpha,\beta}min_\theta L(\theta,\vec{\alpha},\vec{\beta})
maxα,βD(α,β)=maxα,βminθL(θ,α,β)在满足某些条件时,原始问题和对偶问题是等价的,我们将条件罗列如下:
- 函数 f ( θ ) f(\theta) f(θ)和 g i ( θ ) g_i(\theta) gi(θ)都是凸函数;
- 函数 h i ( θ ) h_i(\theta) hi(θ)为仿射变换;
- 存在 θ \theta θ使得对于所有的函数 g i g_i gi都有 g i ( θ ) < 0 g_i(\theta)<0 gi(θ)<0.
回到SVM,在上一部分我们得到了SVM的损失函数,但在损失函数中包含一个在数学上难以处理的
m
a
x
(
0
,
1
−
y
(
w
⃗
⋅
x
⃗
+
b
)
)
max(0,1-y(\vec{w}\cdot\vec{x}+b))
max(0,1−y(w⋅x+b)),因此,我们还用
ξ
\xi
ξ代回式子中,将它转化为一个带约束优化问题:
m
i
n
∥
w
∥
2
2
+
C
∑
ξ
y
(
w
⃗
⋅
x
⃗
+
b
)
≥
1
−
ξ
ξ
≥
0
\left. \begin{aligned} min\frac{\|w\|^2}{2}+&C\sum\xi\\ y(\vec{w}\cdot\vec{x}+b)\geq&1-\xi\\ \xi\geq&0 \end{aligned} \right.
min2∥w∥2+y(w⋅x+b)≥ξ≥C∑ξ1−ξ0我们可以一一验证上面的条件,发现SVM是满足拉格朗日对偶的条件的。首先得到拉格朗日函数:
L
(
w
⃗
,
b
,
ξ
,
α
,
β
)
=
∥
w
∥
2
2
+
C
∑
ξ
−
∑
α
[
y
(
w
⃗
⋅
x
⃗
+
b
)
−
1
+
ξ
]
−
∑
β
ξ
L(\vec{w},b,\xi,\alpha,\beta)=\frac{\|w\|^2}{2}+C\sum\xi-\sum\alpha[y(\vec{w}\cdot \vec{x}+b)-1+\xi]-\sum\beta\xi
L(w,b,ξ,α,β)=2∥w∥2+C∑ξ−∑α[y(w⋅x+b)−1+ξ]−∑βξ于是对偶函数为
D
(
α
,
β
)
=
m
i
n
w
⃗
,
b
,
ξ
L
(
w
⃗
,
b
,
ξ
,
α
,
β
)
D(\alpha,\beta)=min_{\vec{w},b,\xi}L(\vec{w},b,\xi,\alpha,\beta)
D(α,β)=minw,b,ξL(w,b,ξ,α,β),接下来求解这个函数,令它对三个自变量的偏导为零:
∂
L
∂
w
=
0
⇒
w
⃗
=
∑
α
y
x
⃗
∂
L
∂
ξ
=
0
⇒
C
−
α
−
β
=
0
∂
L
∂
b
=
0
⇒
∑
y
α
=
0
\left. \begin{aligned} \frac{\partial L}{\partial w}=0\Rightarrow \vec{w}=\sum\alpha y\vec{x}\\ \frac{\partial L}{\partial\xi}=0\Rightarrow C-\alpha-\beta=0\\ \frac{\partial L}{\partial b}=0\Rightarrow \sum y\alpha=0 \end{aligned} \right.
∂w∂L=0⇒w=∑αyx∂ξ∂L=0⇒C−α−β=0∂b∂L=0⇒∑yα=0根据这三个公式,经过一系列比较复杂的计算,我们就能得到SVM最优化问题的对偶形式:
m
a
x
α
∑
α
i
−
1
2
∑
y
i
y
j
α
i
α
j
(
x
i
⃗
⋅
x
j
⃗
)
0
≤
α
i
≤
C
;
∑
α
i
y
i
=
0
\left. \begin{aligned} max_\alpha\sum\alpha_i-\frac{1}{2}&\sum y_iy_j\alpha_i\alpha_j(\vec{x_i}\cdot\vec{x_j})\\ 0\leq\alpha_i\leq C&;\sum\alpha_iy_i=0\\ \end{aligned} \right.
maxα∑αi−210≤αi≤C∑yiyjαiαj(xi⋅xj);∑αiyi=0预测公式可以写为:
y
j
^
=
s
i
g
n
(
∑
α
i
y
i
(
x
i
⃗
⋅
x
j
⃗
)
+
c
)
\hat{y_j}=sign(\sum\alpha_iy_i(\vec{x_i}\cdot\vec{x_j})+c)
yj^=sign(∑αiyi(xi⋅xj)+c)其中
s
i
g
n
(
)
sign()
sign()为符号函数。
将模型转化为对偶问题能够让我们深入地理解模型的训练过程以及预测过程。并且由于将SVM的预测公式转化成了对偶形式,也由此催生出了一种非常巧妙的增强SVM拟合能力的方法——核函数。
核函数
在讨论核函数的定义之前,我们先来谈谈前面讨论的线性支持向量机的缺点。很明显的一件事情是我们只能使用直线来分割平面上的点,对于下面这类情况我们就无能为力:
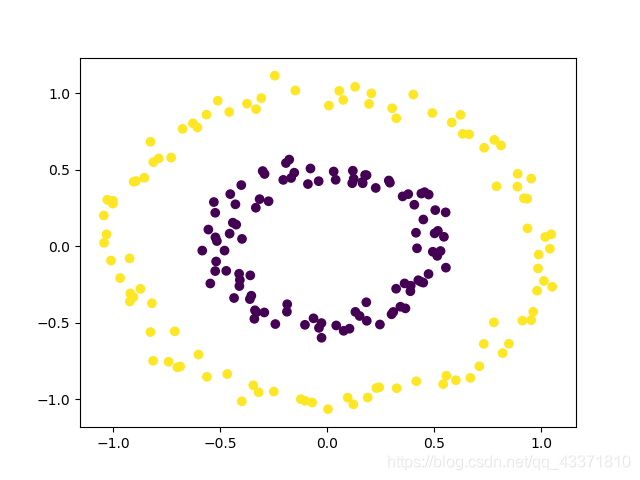
但我们将它转换到极坐标下,就能够用一条直线完全分离开。于是我们想到:是否能通过已知的数据构造特征,从而使得两类数据线性可分?这是完全合理的,但是存在着一个很重大的问题。如果我们将数据不断地扩大维度,直接使用扩维后的数据训练模型,则常常会导致模型的运算复杂度过高,工程上的时间成本过高。
核函数(kernel function)就提供了一个能够进行数据扩维又不会使得运算过为复杂的方法。从前面对偶形式的最优化问题可以看出,我们训练模型时,实际上并不会对所有的特征一一进行计算,我们只计算两个向量之间的点积。如果能找到一个扩维方法,使得扩维之后的数据的两向量的点积能够方便地运算出来(运用级数的知识),我们就可以达到既扩维,又不会使运算复杂化的效果。
核函数的证明是比较困难的,但好在目前已经找到了许多可供使用的核函数:
线
性
核
函
数
:
x
i
⃗
⋅
x
j
⃗
多
项
式
核
函
数
:
(
[
γ
(
x
i
⃗
⋅
x
j
⃗
)
+
c
o
e
f
]
n
)
s
i
g
m
o
i
d
核
函
数
:
t
a
n
h
(
γ
(
x
i
⃗
⋅
x
j
⃗
)
+
c
o
e
f
)
拉
普
拉
斯
核
函
数
:
e
x
p
(
−
γ
∥
x
i
⃗
−
x
j
⃗
∥
)
高
斯
核
函
数
:
e
x
p
(
−
γ
∥
x
i
⃗
−
x
j
⃗
∥
2
)
\left. \begin{aligned} 线性核函数:&\vec{x_i}\cdot\vec{x_j}\\ 多项式核函数:&([\gamma(\vec{x_i}\cdot\vec{x_j})+coef]^n)\\ sigmoid核函数:&tanh(\gamma(\vec{x_i}\cdot\vec{x_j})+coef)\\ 拉普拉斯核函数:&exp(-\gamma\|\vec{x_i}-\vec{x_j}\|)\\ 高斯核函数:&exp(-\gamma\|\vec{x_i}-\vec{x_j}\|^2) \end{aligned} \right.
线性核函数:多项式核函数:sigmoid核函数:拉普拉斯核函数:高斯核函数:xi⋅xj([γ(xi⋅xj)+coef]n)tanh(γ(xi⋅xj)+coef)exp(−γ∥xi−xj∥)exp(−γ∥xi−xj∥2)其中,后面三个核函数都相当于把数据映射到了无限维空间。式子中
γ
,
c
o
e
f
,
n
\gamma,coef,n
γ,coef,n都是超参数。
通过核函数,支持向量机对训练数据的拟合能力得到了大大的提升,但也带来了过拟合的问题。对于过拟合问题,我们在这里不再讨论。
小结
在这篇博文中主要介绍了支持向量机这个非常强大的分类模型。我认为这可能是机器学习中最困难的一部分内容。在下一篇博文中,我将暂时搁置监督学习的内容,转向机器学习的另一部分——无监督学习。

















 643
643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









