




python操作文件和文件夹
文章目录
一:文件处理
以前都是使用os模块,这里介绍更加的精细的模块,是os的"升级版" - shutil
shutil 是 python 的 内置模块,不需要额外安装。
1:文件的复制(shutil)
from shutil import copy
# 核心方法 -> 源地址赋值到目标地址
copy(src_path, dist_path)
import os
from shutil import copy
'''
源地址文件夹,复制到目标文件夹
'''
def copy_files(src_dir, dest_dir):
for file in os.listdir(src_dir):
if file.endswith('.txt'):
src_file = os.path.join(src_dir, file)
dest_file = os.path.join(dest_dir, file)
copy(src_file, dest_file)
if __name__ == '__main__':
src_dir = 'C:/Users/user/Documents/txt'
dest_dir = 'C:/Users/user/Documents/txt_copy'
copy_files(src_dir, dest_dir)
🎉 当目标文件夹是一个文件的时候,就是文件内容的复制,将源文件的文件内容复制给目标文件
import os
from shutil import copyfile
'''
文件内容的复制
copyfile(src - 源文件路径, dst - 目标文件路径)
'''
def copy_file_content(src, dst):
copyfile(src, dst)
if __name__ == '__main__':
src = input("Enter the source file path: ")
dst = input("Enter the destination file path: ")
copy_file_content(src, dst)
print("File content copied successfully!")
2:裁剪和变相重命名(shutil)
所谓文件的裁剪就是从一个目标路径的文件A移动到目标路径B中去。
A和B名称可能是相同的也可能是不同的,当移动后A目标这个路径下就不存在这个文件了,只存在目标B这个文件下。
当然,它也支持目标A裁剪到直接裁剪到目标A ,但是它可以支持将目标A这个路径下的这个文件名称进行改变,所以它也是一个变相的重命名。
from shutil import move
move(src, dist)
import os
from shutil import move
def move_files(src_dir, dest_dir):
for filename in os.listdir(src_dir):
if filename.endswith('.txt'):
src_file = os.path.join(src_dir, filename)
dest_file = os.path.join(dest_dir, filename)
move(src_file, dest_file)
if __name__ == '__main__':
src_dir = '/home/user/Documents/office/txt'
dest_dir = '/home/user/Documents/office/txt_files'
move_files(src_dir, dest_dir)
3:文件的删除(os)
单文件的删除一般使用os的remove模块
from os import remove
def remove_file(file_path):
remove(file_path)
if __name__ == '__main__':
remove_file("txt01.py")
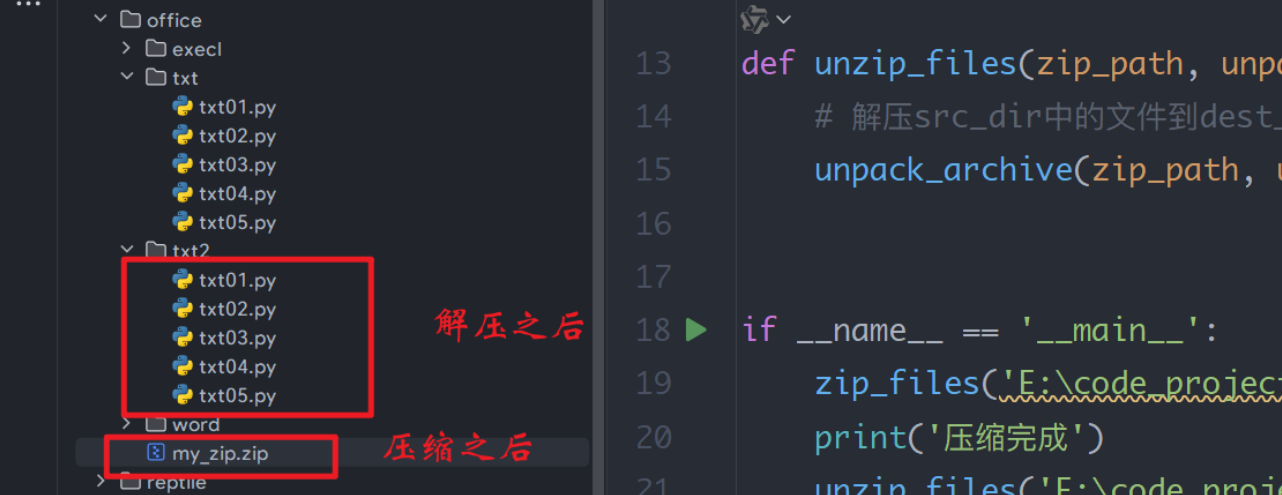
4:文件的压缩和解压缩(shutil)
# 如果只需要压缩可以使用这个
from shutil import make_archive
# 如果只需要解压可以使用这个
from shutil import unpack_archive
# 如果只需要压缩可以使用这个
from shutil import make_archive
# 如果只需要解压可以使用这个
from shutil import unpack_archive
# src_dir中的文件压缩到dest_dir中
def zip_files(src_dir, zip_path):
# 压缩src_dir中的文件到dest_dir中,format是zip
make_archive(zip_path, 'zip', src_dir)
def unzip_files(zip_path, unpack_dir):
# 解压src_dir中的文件到dest_dir中
unpack_archive(zip_path, unpack_dir)
if __name__ == '__main__':
zip_files('E:\code_project\python\office\\txt', 'E:\code_project\python\office\\my_zip')
print('压缩完成')
unzip_files('E:\code_project\python\office\\my_zip.zip', 'E:\code_project\python\office\\txt2')
print('解压完成')
5:文件的查找(glob)
glob 是一个快速查找文件夹中内容的包,我们可以通过模糊查找的形式找到我们想要的内容。
import os
from glob import glob
def search_zip(base_path):
# 搜索当前目录下所有zip文件
# os.getcwd() -> 获取当前目录
# /*.zip -> 搜索当前目录下所有zip文件
search_path = base_path + "/*.zip"
search_ans = glob(search_path)
return search_ans
if __name__ == "__main__":
base_path = 'E:\code_project\python\office'
search_ans_of_office = search_zip(base_path) # ['E:\\code_project\\python\\office\\my_zip.zip']
for ans in search_ans_of_office:
print(ans)
print("=====================================")
# 注意是直接子节点就要有对应的文件,否则找不到
# 例如将base_path范围扩大到上层目录,就没有了
base_path = 'E:\code_project\python'
search_ans_of_office = search_zip(base_path) # []
for ans in search_ans_of_office:
print(ans)
或者我们不使用通配符,直接指定我们要查找的文件。
很多情况下我们知道文件名字,但是不知道文件在什么地方,我们就可以使用递归的方式进行查找。
final_result = []
# 通过名称递归查找文件到底在哪里
def search_by_name(base_path, name):
search_path = base_path + "/*"
search_ans = glob(search_path)
for ans in search_ans:
if os.path.isdir(ans):
search_by_name(ans, name)
else:
if name in ans:
final_result.append(ans)
if __name__ == "__main__":
# 从base_path这个大文件中找到所有包含name的全路径结果
base_path = "E:\code_project"
name = "txt05.py"
search_by_name(base_path, name)
print(final_result)
要是是查找指定内容的,要在是文件的情况下打开文件并进行字符串的匹配。
def search_all_by_content(base_path, content):
search_path = base_path + "/*"
search_ans = glob(search_path)
for ans in search_ans:
if os.path.isdir(ans):
search_all_by_content(ans, content)
else:
with open(ans, 'r', encoding="utf-8") as f:
# 读取文件内容
con = f.read()
if content in con:
final_result.append(ans)
if __name__ == "__main__":
# 从base_path这个大文件中找到所有包含name的全路径结果
base_path = "E:\code_project\python\office\\txt"
content = "import os"
search_all_by_content(base_path, content)
print(final_result)
6:重复文件的清理(hashlib)
原理很简单,就是使用hashlib进行是否是同一个文件的判断,然后删除就可以了
为了方便使用,这里使用tkinter进行图形化展示和确认删除的表示
import hashlib
def file_hash(file_path):
hash_md5 = hashlib.md5() # 创建md5对象, 准备计算文件的md5
with open(file_path, 'rb') as f:
# 读取文件内容,每次读取4k,防止文件过大一次性加载到内存造成的性能等问题
for chunk in iter(lambda: f.read(4096), b""):
hash_md5.update(chunk)
return hash_md5.hexdigest() # 返回文件的md5值
import hashlib
import os
import tkinter as tk
from tkinter import messagebox
def file_hash(file_path):
hash_md5 = hashlib.md5() # 创建md5对象, 准备计算文件的md5
with open(file_path, 'rb') as f:
# 读取文件内容,每次读取4k,防止文件过大一次性加载到内存造成的性能等问题
for chunk in iter(lambda: f.read(4096), b""):
hash_md5.update(chunk)
return hash_md5.hexdigest() # 返回文件的md5值
def get_same_and_delete(base_path):
"""在指定目录下查找并确认删除重复文件"""
hashes = {}
duplicates = []
# 遍历指定目录及其所有子目录
# os.walk(base_path) -> 遍历指定目录及其所有子目录
# os.walk(directory) 是一个生成器函数,它会递归地遍历指定目录及其所有子目录
# 并返回一个三元组 (root, dirs, files)。具体来说,每次迭代时,os.walk 会返回以下内容:
# - root (str): 当前遍历到的目录路径。
# - dirs (list): 当前目录下的子目录列表(不包括子目录的子目录)。
# - files (list): 当前目录下的文件列表。
for dirpath, _, filenames in os.walk(base_path):
for filename in filenames:
filepath = os.path.join(dirpath, filename) # 获取文件的完整路径
try:
# 计算文件的md5值,如果之前有相同的md5值,说明该文件是重复的文件
file_hash_value = file_hash(filepath)
if file_hash_value in hashes:
# 此时找到了重复的文件,追加到重复文件列表中,一会进行删除询问
duplicates.append(filepath)
else:
# 否则将文件的md5值和文件路径添加到字典中
hashes[file_hash_value] = filepath
except Exception as e:
print(f"Error processing file {filepath}: {e}")
# 创建Tkinter根窗口
root = tk.Tk()
root.withdraw() # 隐藏主窗口
# 遍历重复文件列表,逐个确认是否删除
for dup in duplicates:
# 显示确认对话框
response = messagebox.askyesno("是否确认删除?", f"你要删除这个重复文件吗?:\n{dup}")
if response: # 如果确定删除,则删除该文件,否则跳过删除
try:
os.remove(dup)
print(f"已经删除了重复文件: {dup}")
except Exception as e:
print(f"删除文件错误 {dup}: {e}")
else:
print(f"你跳过了该重复文件: {dup}")
root.destroy() # 销毁Tkinter根窗口
if __name__ == '__main__':
base_path = r"E:\code_project\python\office\txt"
get_same_and_delete(base_path)
7:批量修改文件名称(shutil & glob)
首先我们知道文件名需要修改的指定字符串,至于实现方法,那当然是通过循环,将目标字符串加入到文件名并进行修改。
import shutil
import glob
import os
def update_name(base_path):
result = glob.glob(base_path)
for index, data in enumerate(result):
if os.path.isdir(data):
_path = os.path.join(data, '*') # 获取当前目录下所有文件
update_name(_path) # 递归调用
else:
# 不是文件夹,是文件了
path_list = os.path.split(data)
# 单独把名字拿出来
name = path_list[-1]
# 生成一个新的名称
new_name = '%s_%s' % (index, name)
# 替换旧名称
new_data = os.path.join(path_list[0], new_name)
shutil.move(data, new_data)
if __name__ == '__main__':
base_path = r'E:\code_project\python\office\txt2'
update_name(base_path)
二:文件夹处理
1:文件夹的复制(shutil)
同样使用shutil,使用其中的copytree(src, dist)就可以完成
from shutil import copytree
def copy_files(src_dir, dest_dir):
copytree(src_dir, dest_dir)
if __name__ == '__main__':
src_dir = 'C:/Users/user/Documents/txt'
dest_dir = 'C:/Users/user/Documents/txt_copy'
copy_files(src_dir, dest_dir)
2:文件夹的删除(shutil)
同样使用shutil,使用其中的rmtree(src)就可以删除指定的文件夹
import os.path
from shutil import rmtree
def remove_file(file_path):
if os.path.isfile(file_path):
os.remove(file_path)
print(f"文件 {file_path} 已被删除")
else:
try:
rmtree(file_path)
print(f"文件夹 {file_path} 已被删除")
except Exception as e:
print(f"删除文件错误 {file_path}: {e}")
3:文件夹的裁剪和重命名(shutil)
文件夹的裁剪跟我们文件裁剪的使用函数其实是一样的 -> move(src, dist)


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









