




通用知识-正则表达式
一:快速入门
1:什么是正则表达式
正则表达式是一种匹配和操作文本的工具,常用于文本查找,文本替换,文本格式校验等等。





2:正则表达式的语法分类【重点】

2.1:普通字符



2.2:字符集合





2.3:限定符



2.4:定位符


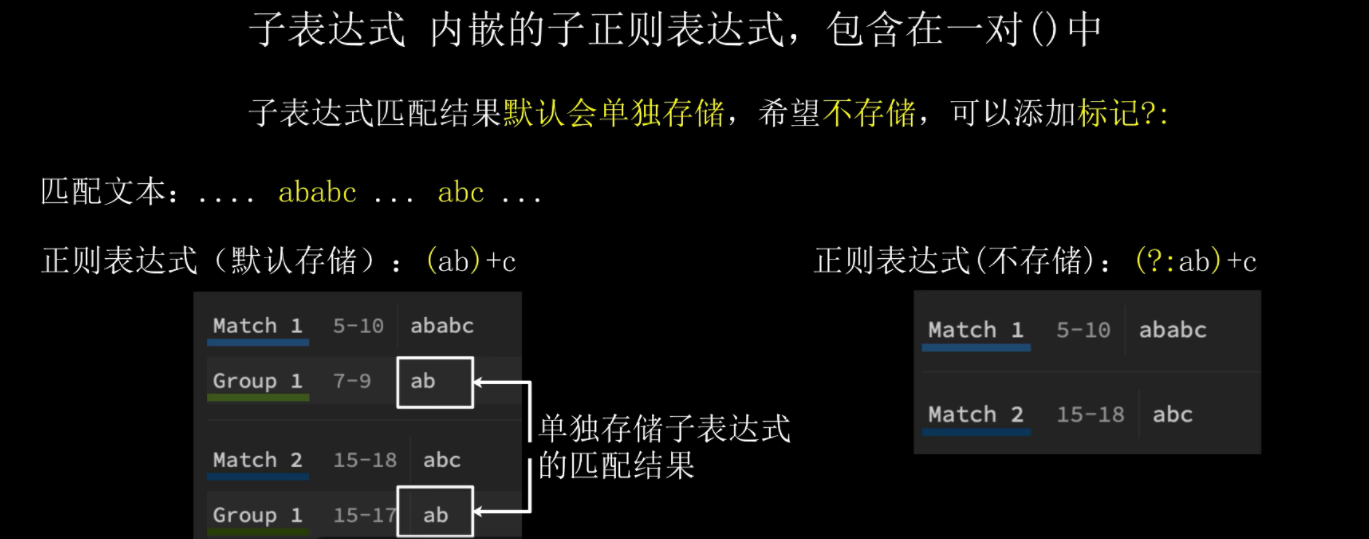
2.5:子表达式(重中之重)






2.6:省略符


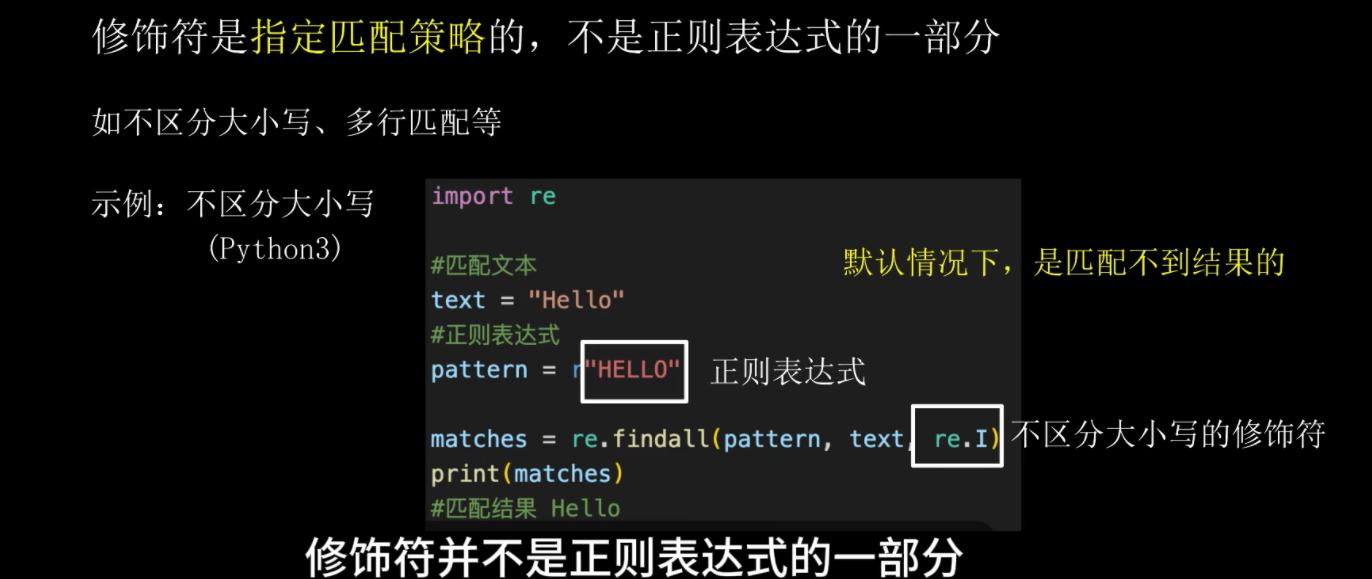
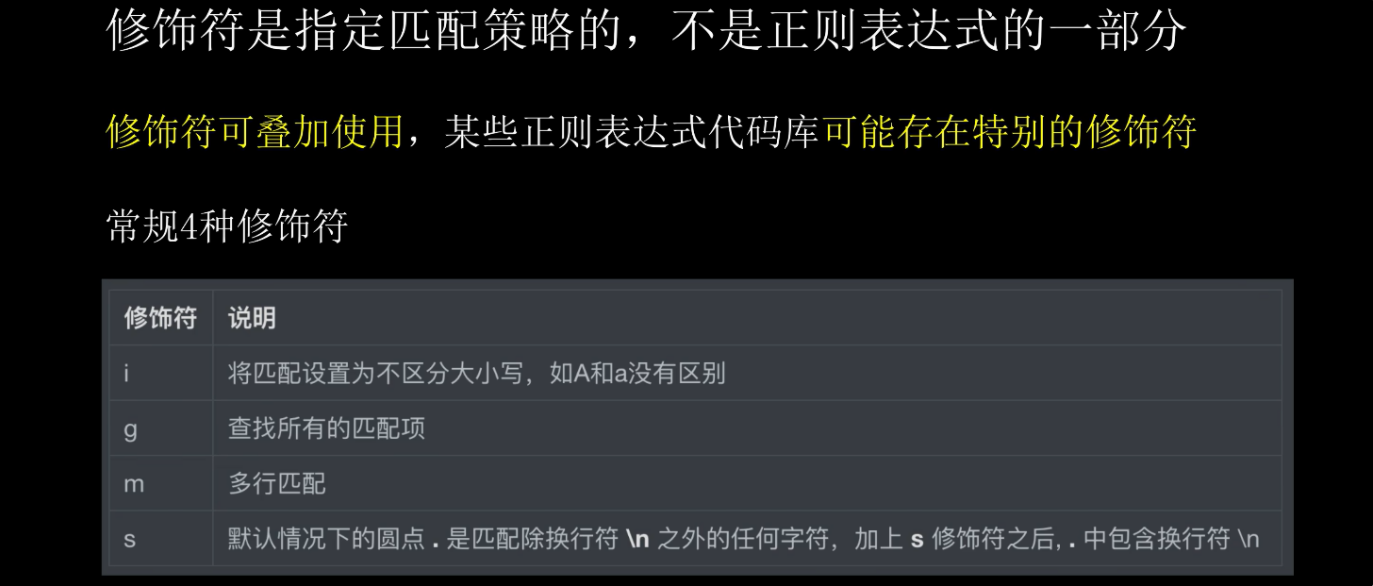
2.7:修饰符
3:Java基本操作
String content = "xxxx"; // 待匹配的字符串
Pattern p_script = Pattern.compile("正则表达式", Pattern.CASE_INSENSITIVE); // pattern
Matcher m_script = p_script.matcher(content); // 进行匹配操作
while (m_script.find()) {
// 找到匹配内容,进行后续事情
String strAid = m_script.group(1);
// todo
}
3.1:常用方法
matches(): 返回整个目标字符串与Pattern是否匹配
find(): 返回与Pattern匹配的下一个子串
group(): 返回上一次与Pattern匹配的子串中的内容。
group是针对()来说的group(0)就是指的整个串group(1)指的是第一个括号里的东西group(2)指的第二个括号里的东西
start(): 返回上一次与Pattern匹配的子串在目标字符串中的开始位置
end(): 返回上一次与Pattern匹配的子串在目标字符串中的结束位置加1
二:基础正则表达式速查表
1:字符
| 表达式 | 描述 |
|---|---|
[abc] | 字符集。匹配集合中所含的任一字符。 |
[^abc] | 否定字符集。匹配任何不在集合中的字符。 |
[a-z] | 字符范围。匹配指定范围内的任意字符。 |
. | 匹配除换行符以外的任何单个字符。 |
\ | 转义字符。 |
\w | 匹配任何字母数字,包括下划线(等价于[A-Za-z0-9_])。 |
\W | 匹配任何非字母数字(等价于[^A-Za-z0-9_])。 |
\d | 数字。匹配任何数字。 |
\D | 非数字。匹配任何非数字字符。 |
\s | 空白。匹配任何空白字符,包括空格、制表符等。 |
\S | 非空白。匹配任何非空白字符。 |
2:分组和引用
| 表达式 | 描述 |
|---|---|
(expression) | 分组。匹配括号里的整个表达式。 |
(?:expression) | 非捕获分组。匹配括号里的整个字符串但不获取匹配结果,拿不到分组引用。 |
\num | 对前面所匹配分组的引用。 |
3:锚点和边界
| 表达式 | 描述 |
|---|---|
^ | 匹配字符串或行开头。 |
$ | 匹配字符串或行结尾。 |
\b | 匹配单词边界。比如Sheep\b可以匹配CodeSheep末尾的Sheep,不能匹配CodeSheepCode中的Sheep |
\B | 匹配非单词边界。比如Code\B可以匹配HelloCodeSheep中的Code,不能匹配HelloCode中的Code。 |
4:数量
| 表达式 | 描述 |
|---|---|
? | 匹配前面的表达式0个或1个。即表示可选项。 |
+ | 匹配前面的表达式至少1个。 |
* | 匹配前面的表达式0个或多个。 |
| `` | 或运算符。并集,可以匹配符号前后的表达式。 |
{m} | 匹配前面的表达式m个。 |
{m,} | 匹配前面的表达式最少m个。 |
{m,n} | 匹配前面的表达式最少m个,最多n个。 |
5:断言
| 表达式 | 描述 |
|---|---|
(?=) | 正向预查。比如Code(?=Sheep)能匹配CodeSheep中的Code,但不能匹配CodePig中的Code。 |
(?!) | 正向否定预查。比如Code(?!Sheep)不能匹配CodeSheep中的Code,但能匹配CodePig中的Code。 |
(?<=) | 反向预查。比如(?<=Code)Sheep能匹配CodeSheep中的Sheep,但不能匹配ReadSheep中的Sheep。 |
(?<!) | 反向否定预查。比如(?<!Code)Sheep不能匹配CodeSheep中的Sheep,但能匹配ReadSheep中的Sheep |
6:特殊标记
| 表达式 | 描述 |
|---|---|
/.../i | 忽略大小写。 |
/.../g | 全局匹配。 |
/.../m | 多行修饰符。用于多行匹配。 |

















 1584
1584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









