







老齐架构(11 - 20)
文章目录
一:MySQL高可用MHA架构方案
1:什么是MHA
MHA是日本 yoshinorim 开发的一个MySQL高可用方案,使用Perl语言进行开发,MHA是最为成熟的MySQL高可用方案
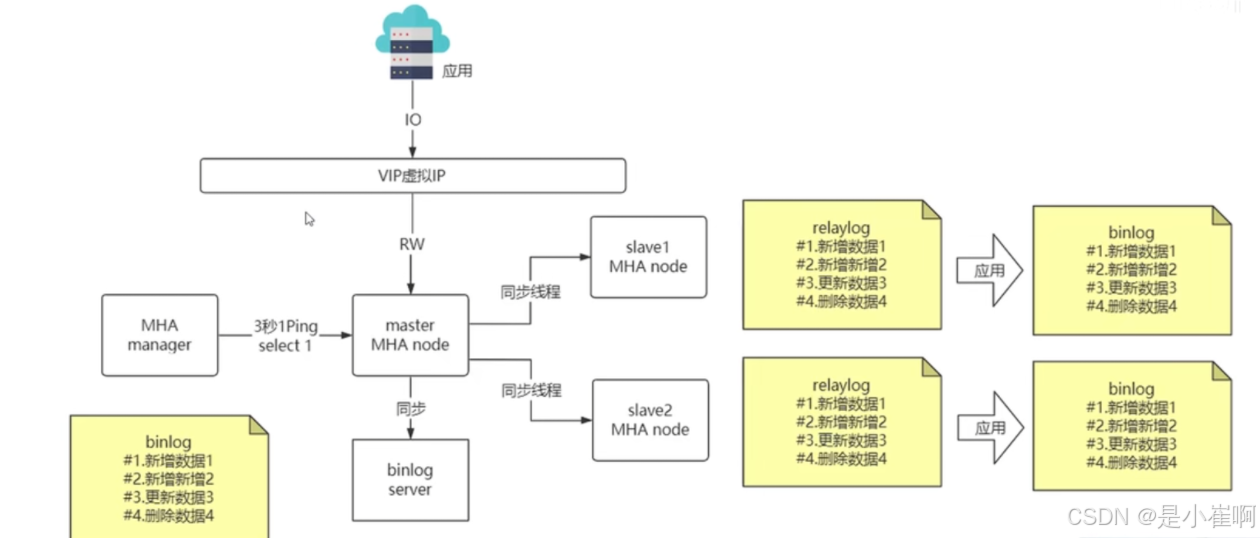
上面抛开MHA的组件内容就是MySQL单纯的主从复制的内容【binlog & relaylog那部分】
但是单纯的主从复制是不具备高可用的【也就是说,在单纯的主从复制模式下,一旦主节点宕机,从节点不能主动的进行重新选主恢复,而是直接瘫痪】
此时就可以在原有的主从复制的结构基础上外挂MHA,MHA主要增加了如下几个部分:
- VIP -> 虚拟IP,对用户暴露的虚拟IP,可以根据MHA进行内部的漂移转换和实际IP的映射关系
- MHA Manager -> MHA管理者
- MHA Node -> 办事节点,接收MHA的命令,Node节点会在本机完成一些自动化工作,自动转移和迁移数据的工作
- binlog server -> 备份机制,记录了主服务器完整的binlog操作日志,所以binlog就是一个备份机制


2:MHA故障发现和转移的过程
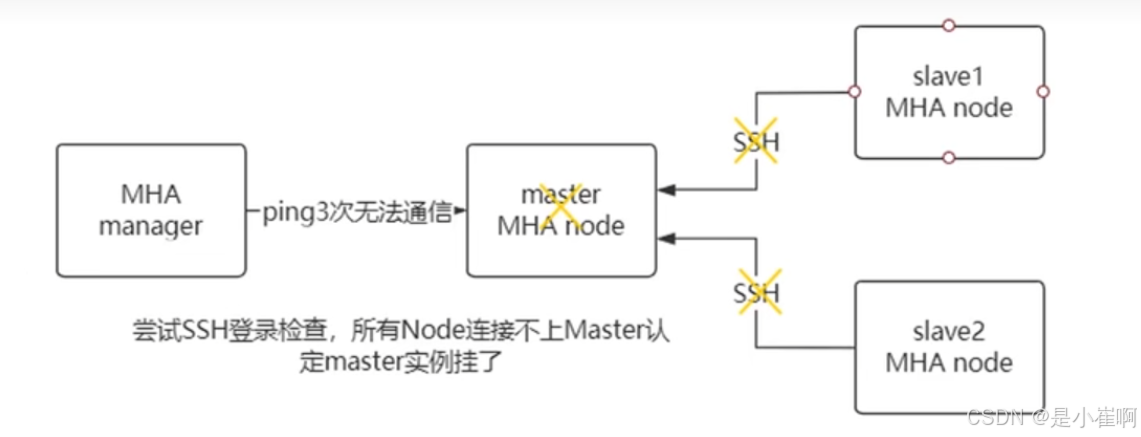
1:检查监听:(下面两个条件要同时满足)
- MHA manager 每过3s向主节点发送探活ping,如果连续发送3次都ping不通,MHA Manager主动认为master宕机
- 此时manager 就会通知所有的MHA node,都向master进行SSH登录检查,如果都连不上了,说明master确实宕机了,下面将进行重新选主
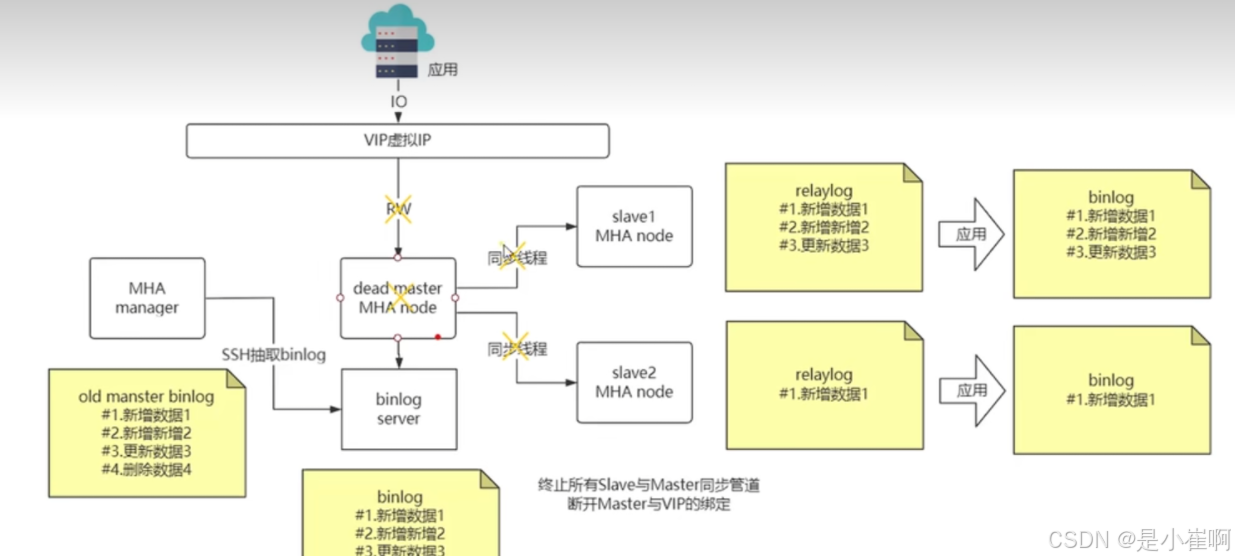
2:故障发现
终止所有的slave和Master同步通道,断开master和VIP的绑定,同时manager从binlog server中拿到所有的binlog到本地
3:转移过程
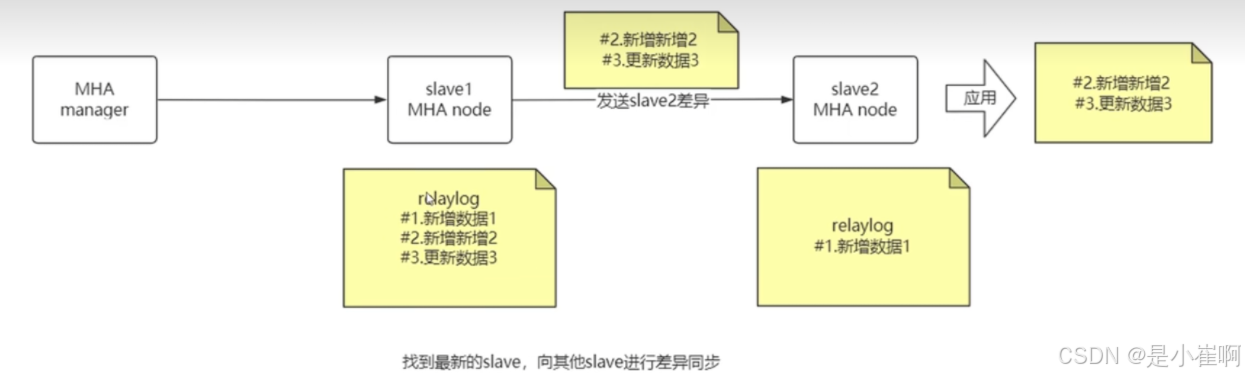
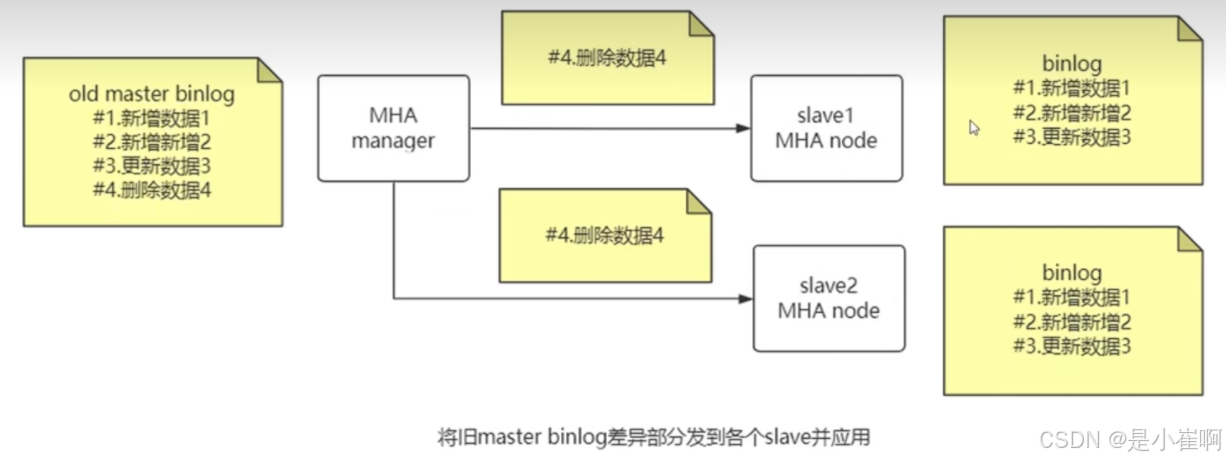
- slave之间进行比较,找到最新的slave[对比最大的同步记录,类比ZK, Kafka],然后向其他的slave进行差异同步【保证slave之间同步】
- 将旧的master binlog差异部分发到各个的slave并应用
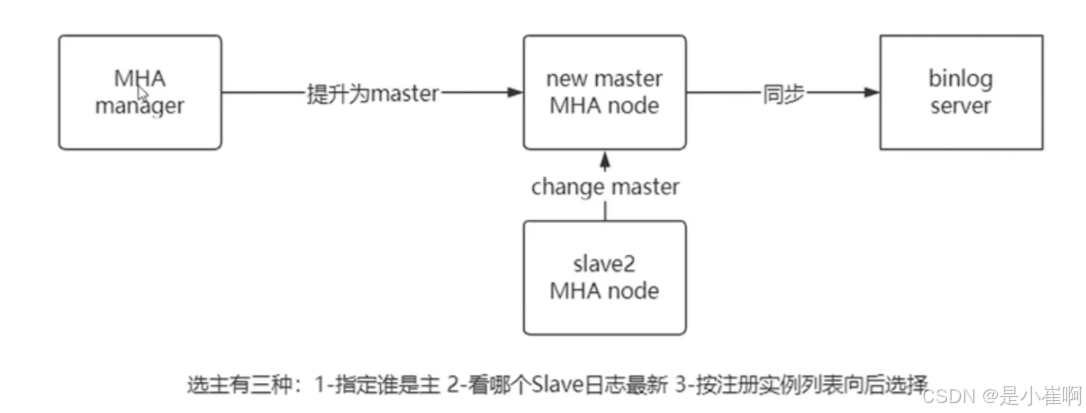
4:选主机制
5:善后工作
MHA自动将VIP漂移到新主节点对外提供服务【改变VIP的映射IP】
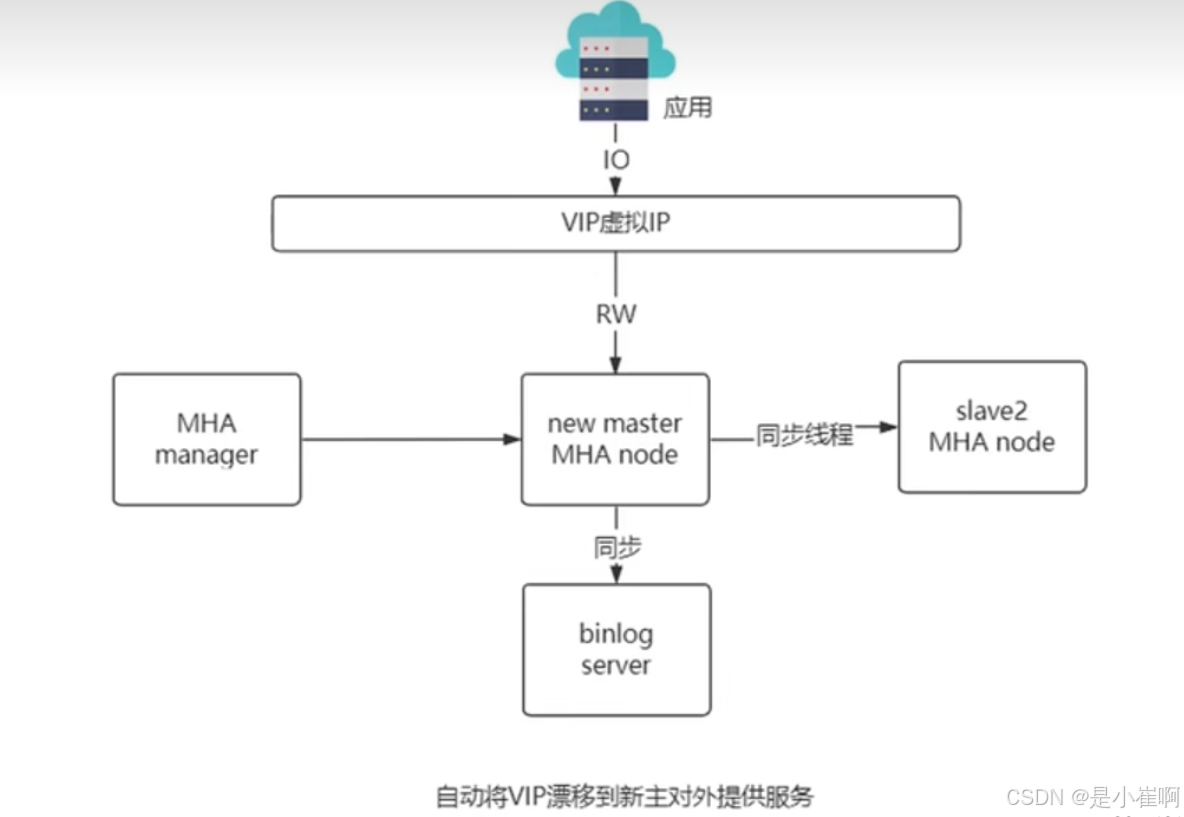
旧主恢复之后设置为自动变成slave跟随新主

可能得问题??? -> 1、binlog不完整 2、迁移丢包,数据不完整 3、旧主服务器跟binlog日志不一致
3:MHA优缺点分析
优点:
- 由per语言开发的开源工具
- 可以支持基于GTD的复制模式
- 当主DB不可用时,从多个从服务器中选举出来新的主DB
- 提供了主从切换和故障转移功能,在线故障转移时不易丢失数据
- 同一个监控节点可以监控多个集群
缺点:
- 需要编写脚本或利用第三方工具来实现VP的配置
- MHA启动后只只监控主服务器是否可用,没办法监控从服务器
- 需要基于SSH免认证登陆配置,存在一定的安全隐患
- 没有提供从服务器的读负载均衡功能
- 可靠但是不是绝对可靠【可能会丢失数据】
二:架构设计的一些感悟
- 没有场景的架构设计就是耍流氓
- 发现问题的复杂性是根本,这些包含在用户的关键需求中
- 解耦是架构设计无时无刻考虑的事情
- 尊重“爬 -> 走 -> 跑 -> 跳”的自然规律,好的架构一定是演化来的
- 千万不要为了“炫技”进行设计,否则整个公司都要为此进行买单
- 好的架构师一定是一个聆听的高手,跟客户交流要说人话
三:Redis Sentinel高可用架构
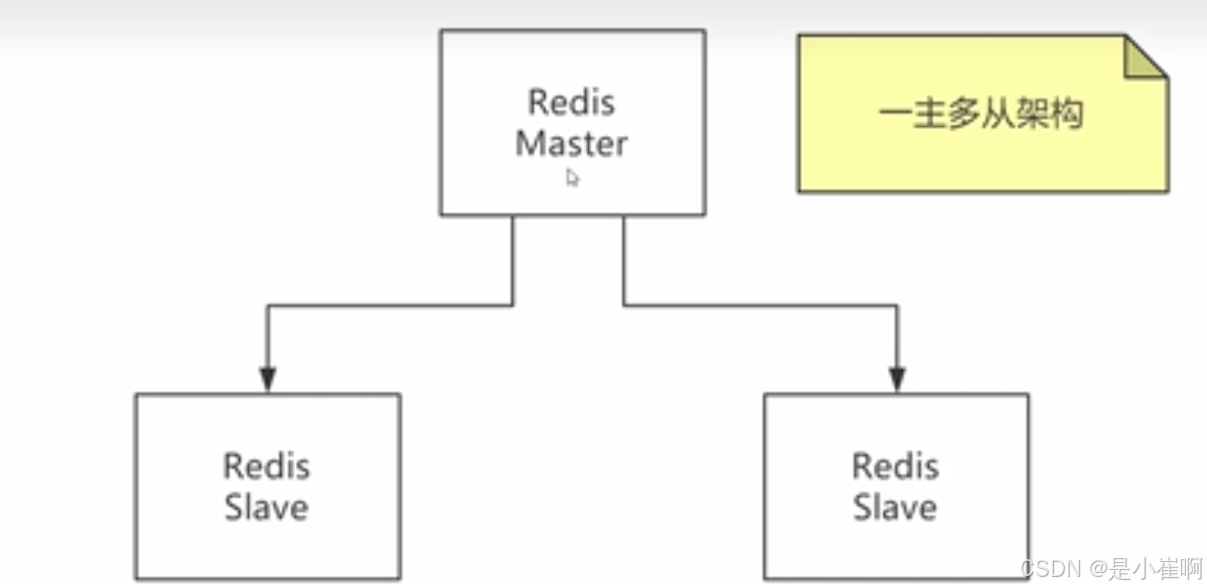
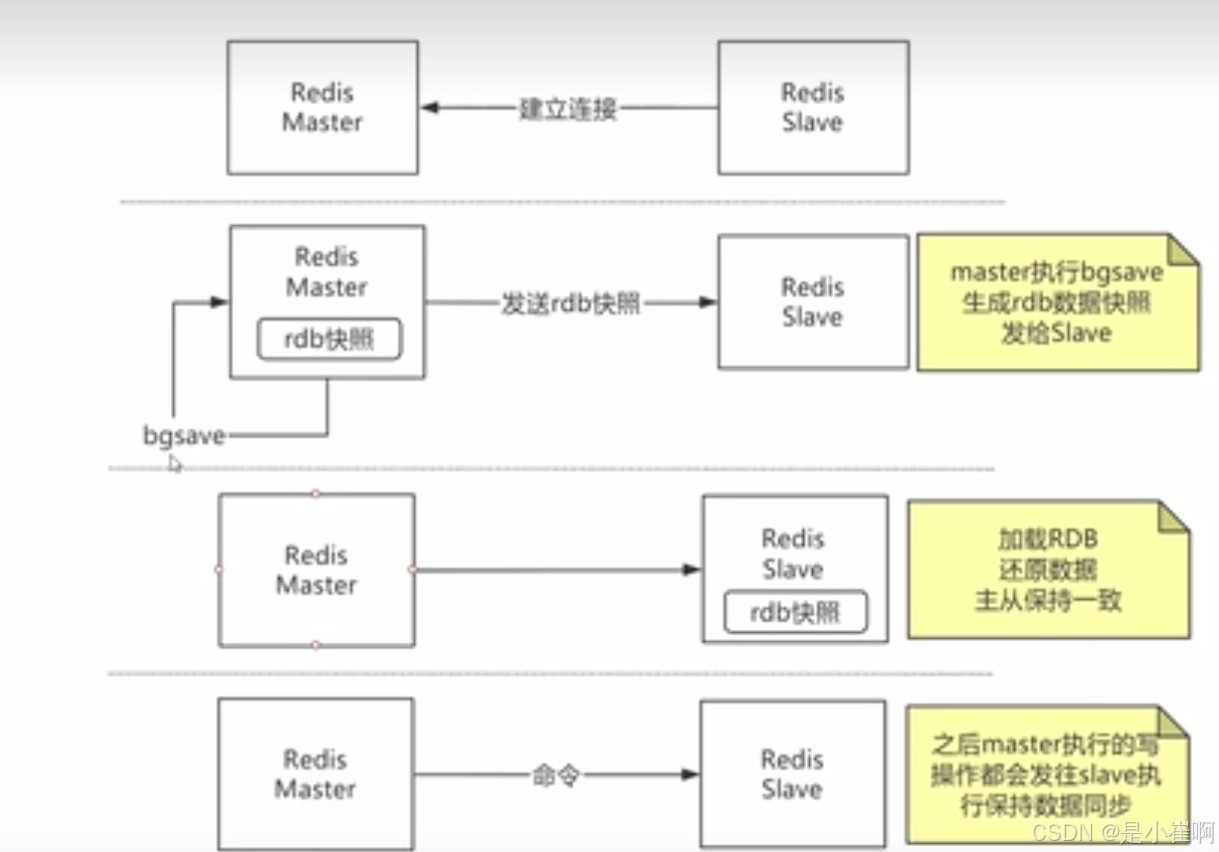
1:redis主从复制的过程
2:redis Sentinel高可用集群
每一个Sentinel以每秒钟一次的频率向着它所知的Master,Slave以及其他的Sentinel实例发送一个Ping命令
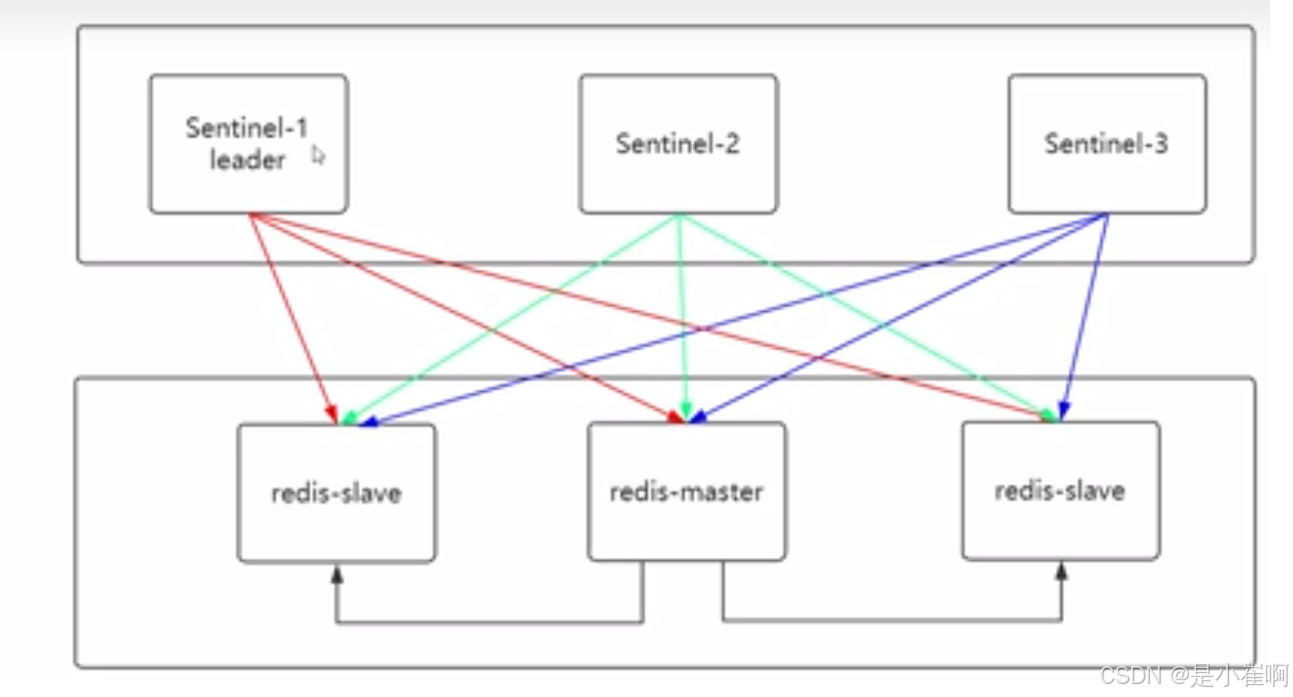
如果一个示例(instance)距离最后一次有效回复Ping命令的时间超过了own-after-millseconds选项中指定的值
那么这个实例会被Sentinel标记为主观下线
当有足够数量的Sentinel(大于等于配置文件指定的值)在指定的事件范围内确认master进入了主观下线的状态,就会将Master标记为客观下线
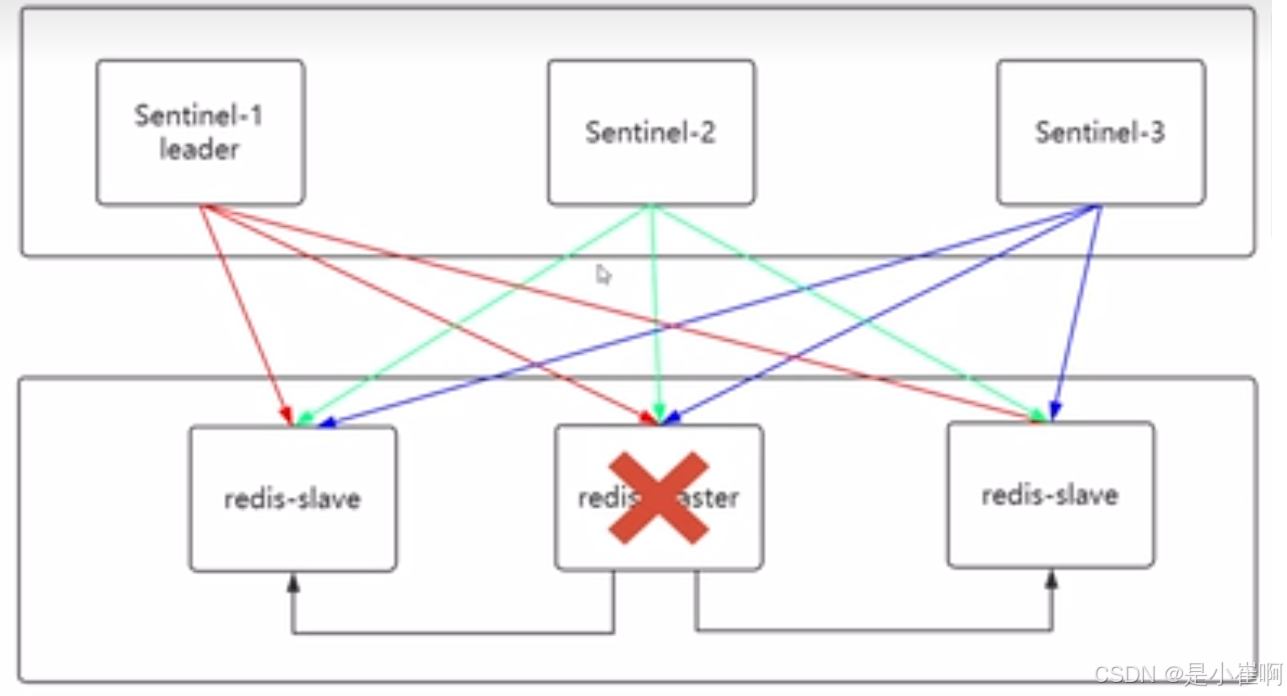
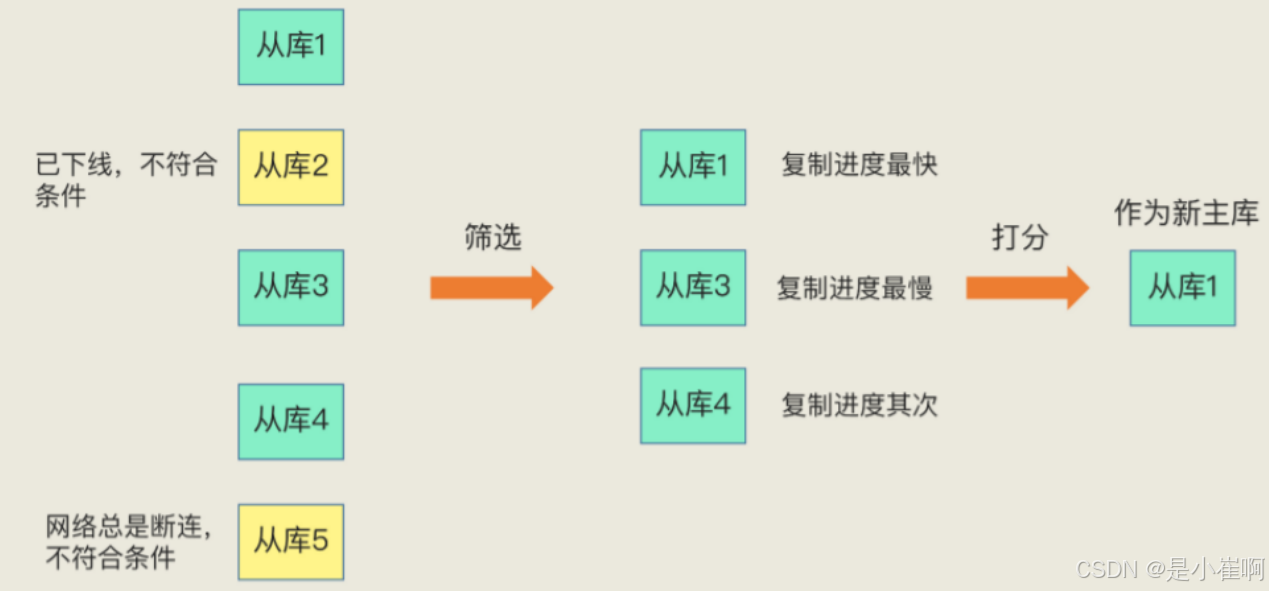
sentinel从slave中选出新的master, 选取新的master的条件如下:
- 剔除主观下线,已经断线了,或者最后一次回复Ping命令的时间 > 5s钟的slave
- 剔除和失效主服务器连接断开时长超过down-after选项指定的时长10倍的slave
- 按照同步数据的偏移量,选出数据量最为完整的Slave
- 如果偏移是相同的,选出其中ID最小的Slave
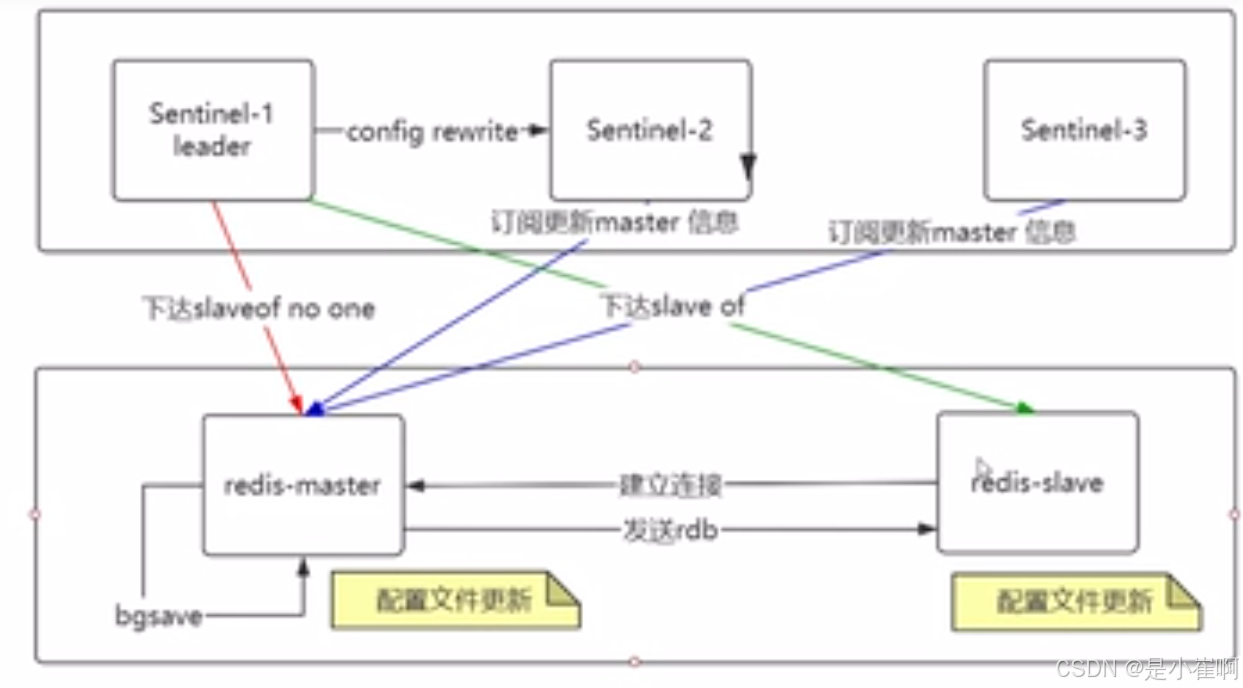
然后进行新主库的数据同步:
-
向被选中的服务器发送slaveof no one命令,让他转变成为主服务器
-
通过发布和订阅功能,将更新后的配置传播给所有的其他的Sentinel,其他的Sentinel对他们自己的配置进行更新
-
向所有的slave下达slaveof 命令,指向新的主节点
-
redis-slave向master重新建立连接,重放rdb保持数据同步
-
上述转移过程中,伴随着redis本地配置文件的自动重写,这样即使是实例重启,配置也不会丢失
-
原有的master在恢复之后降级成为slave,然后和新的slave进行全量同步
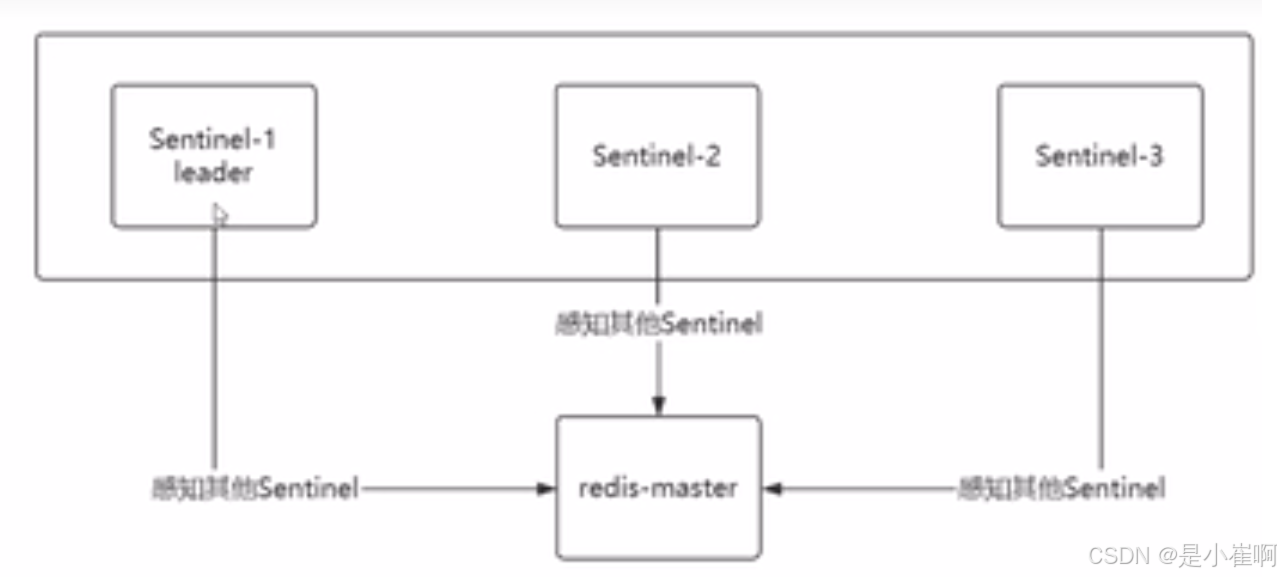
sentinel哨兵故障选举: -
sentinel 自动故障转移使用的是raft算法来实现选举sentinel的leader sentinel
-
超过半数投票选举出了leader,sentinel leader用于下达故障转移的指令
-
如果某一个leader挂了,则使用raft从剩余的sentinel中选出leader
四:Seata分布式事务解决方案(AT)
1:分布式事务 & 事务协调者
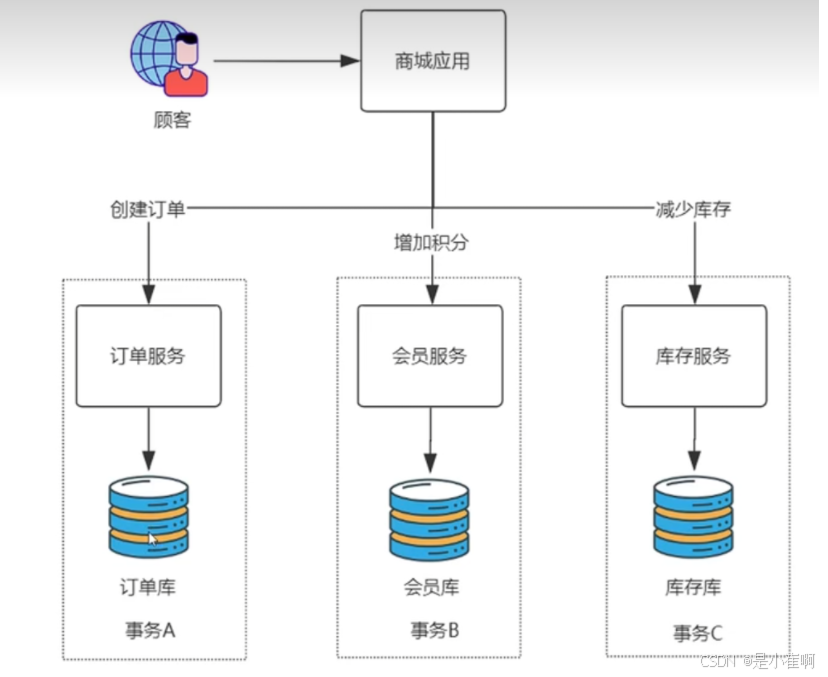
不管是那种分布式事务的实现方式,都会有一个事务协调者这么一个角色
试想一下,也很好理解,就是作为我们的应用来说,总要有一个东西下发回滚和提交的指令,充当一个统筹的角色办这个事情
这个统筹者在概念层面上就是“事务协调者”
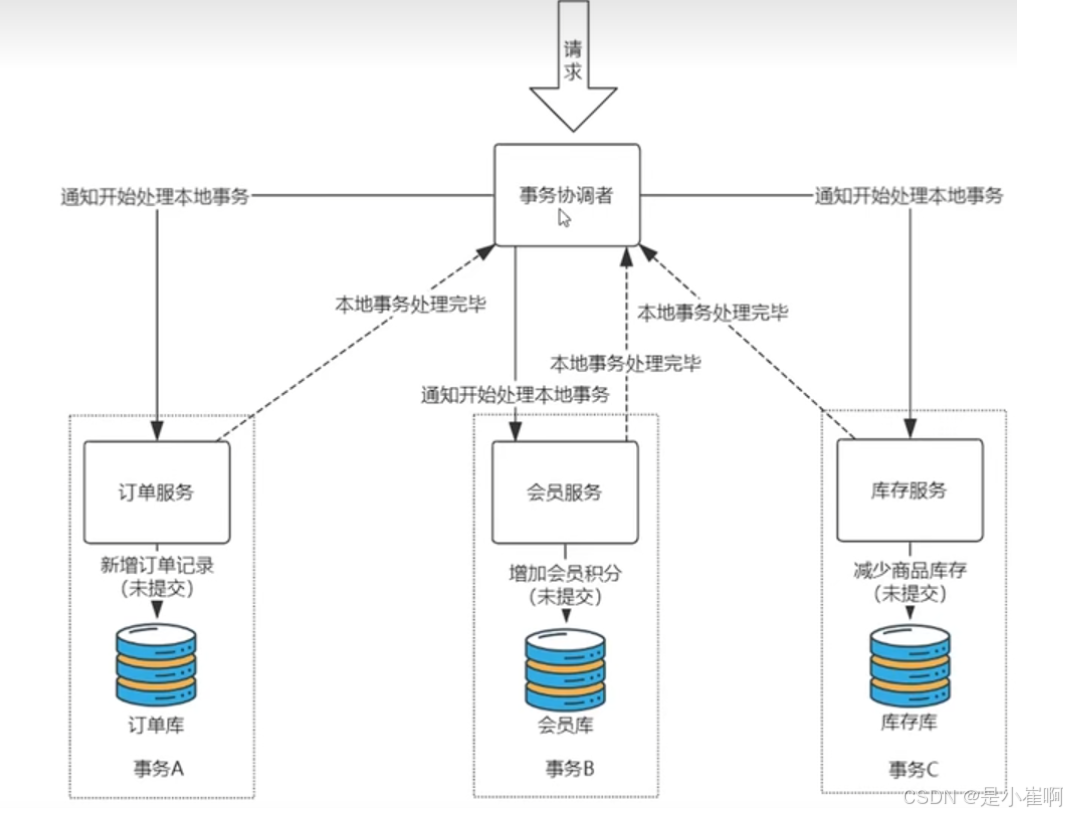
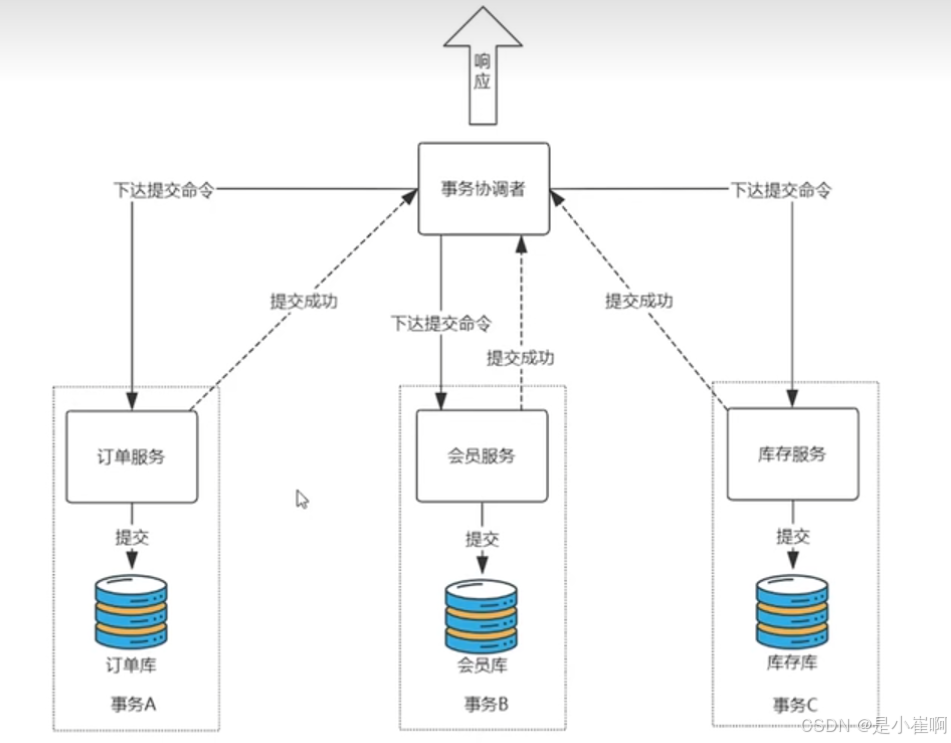
- 请求到了之后,事务协调者会通知各个业务服务:你们要开始进行业务处理了
- 各个业务服务分别进行业务的处理,处理完成之后分别向事务协调者报告自己处理的状态【各个服务业务不会自动提交】
- 如果事务协调者发现所有的事务协调者都处理完成了 -> 再次通知各个业务服务:你们可以提交了
- 如果发现有的没有完成或者失败了 -> 通知各个业务回滚自己的事务
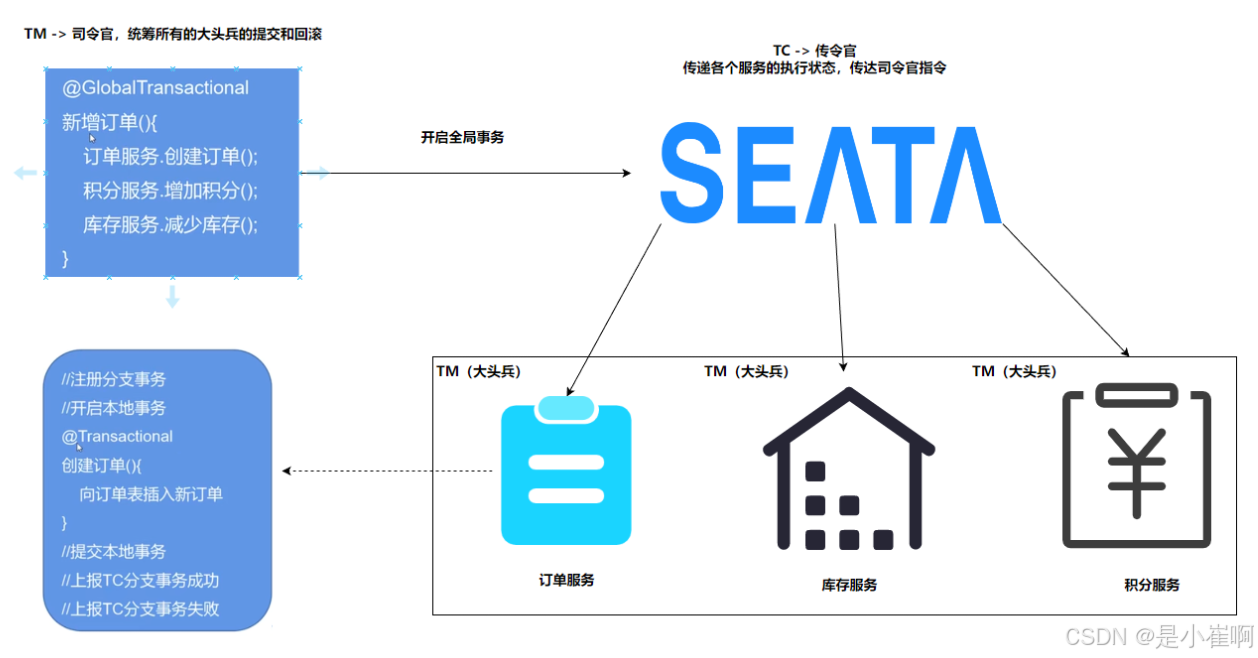
2:阿里Seata AT解决方案介绍
阿里Seata中分布式事务有三个角色:
- 事务管理器:决定什么时候全局提交、回滚(司令官)
- 事务协调者:负责通知命令的中间件Seata-server(传令官)
- 资源管理器:做具体事情的人(各个业务服务)
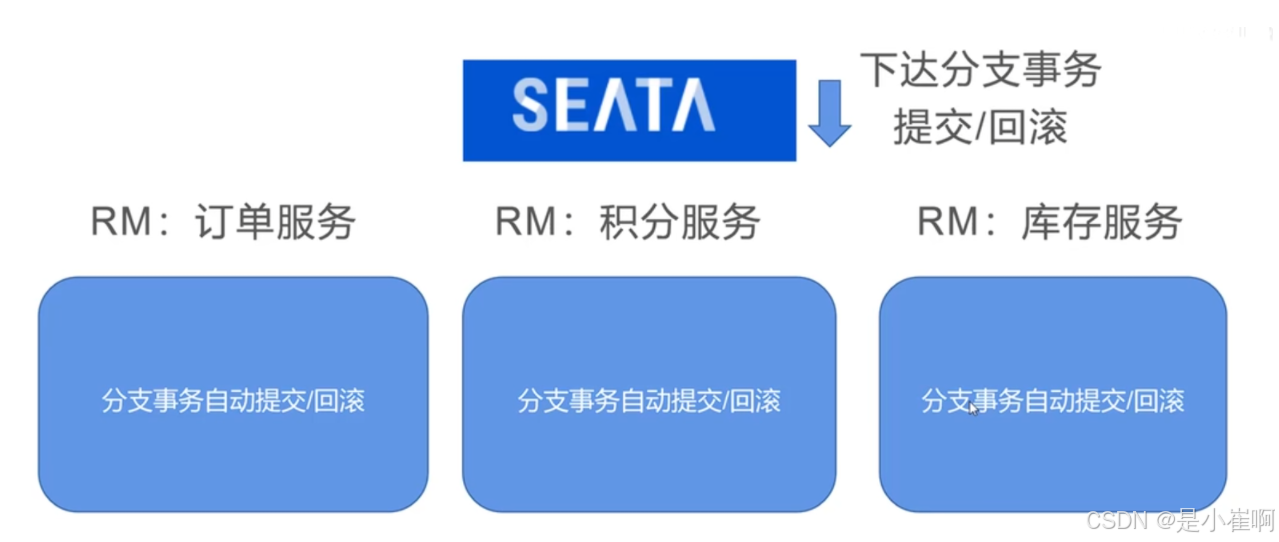
3:如何实现的自动提交、回滚
1.在TM和RM所有的数据库中添加了一张UNDO_LOG表(不要和mysql那个弄混,那个是undolog)
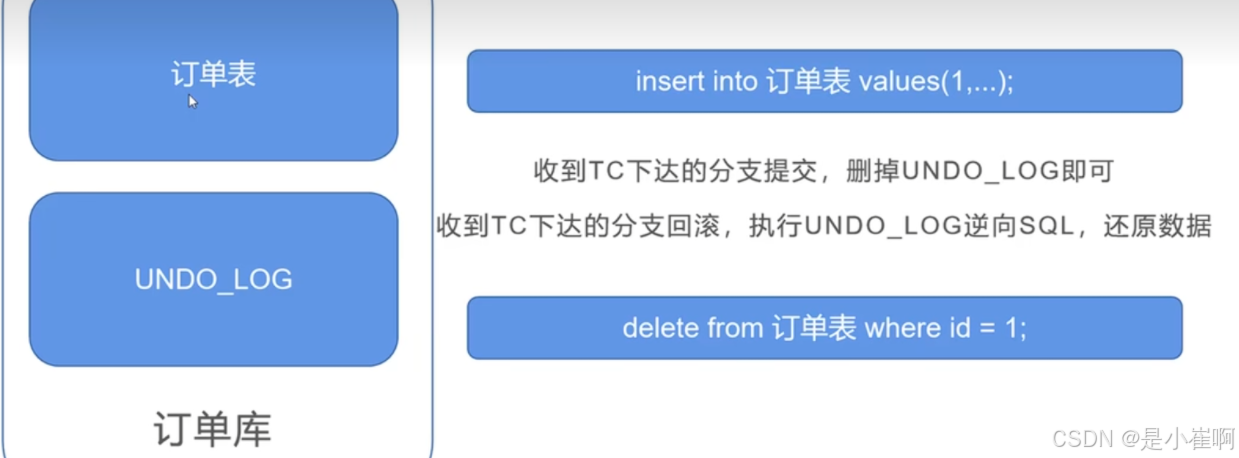
4:如何避免并发环境下的脏读和脏写
提供自带的分布式锁完成,只有获取到全局的分布式锁的事务才能进行操作
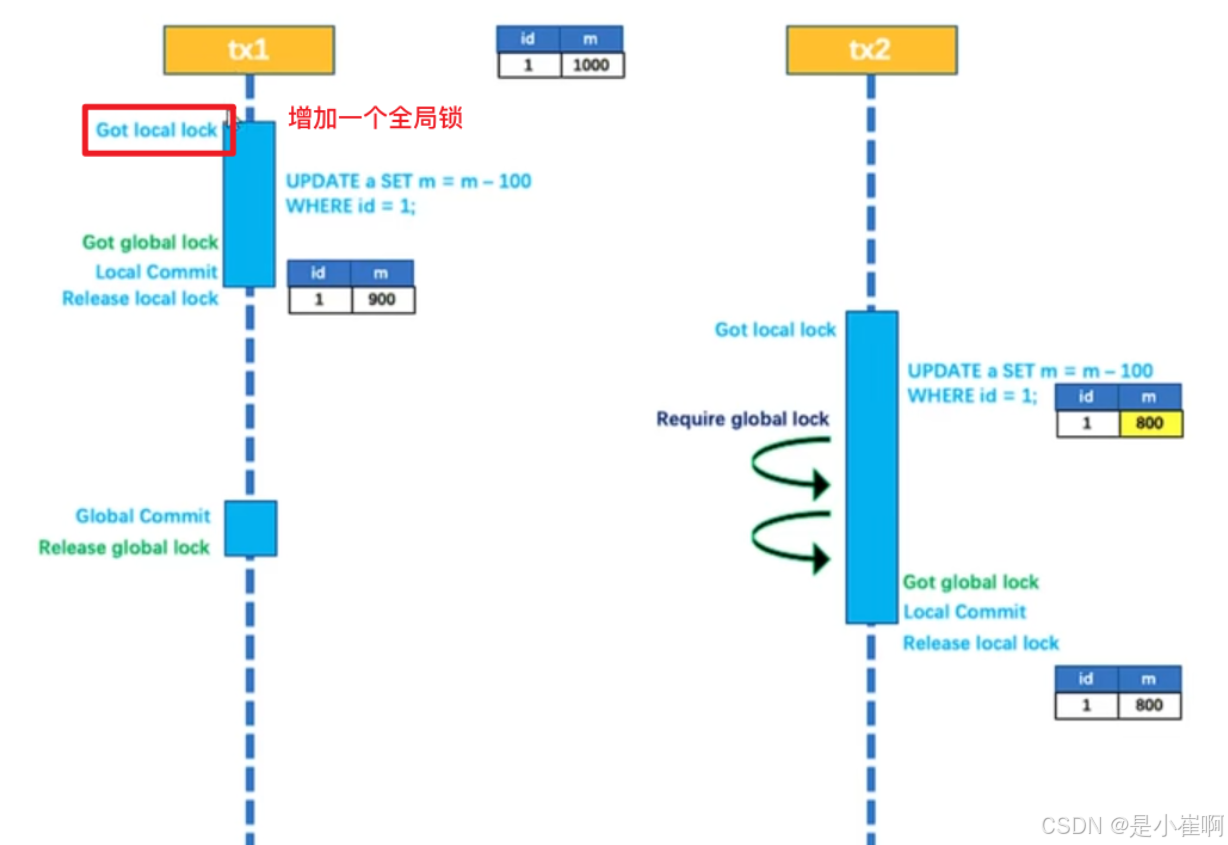
5:保证事务的隔离性
因seata-一阶段本地事务已提交,为防止其他事务脏读脏写需要加强隔离
- 脏读select语句加
for update,代理方法增加@GlobalLock+@Transactional或@GlobalTransaction - 脏写必须使用
@GlobalTransaction
五:接口幂等的保证
1:何为幂等性
发送一个接口调用和发送多次相同的接口消息都能得到和预期相符的结果
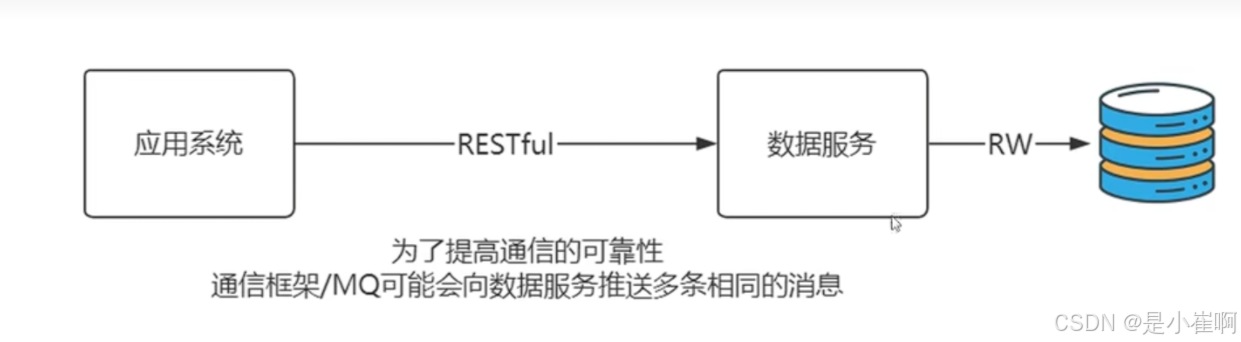
put https://xxx.com/employee/salary,然后更新数据是对员工1加500块的工资 -> {"id": 1, "incr_salary": 500}

上面的三行代码单看没有问题,但是放到幂等下就有一个大问题,就是“每一次重发请求都会导致1号员工的工资涨500元?”
2:对于幂等问题怎么解决
传统的办法就是代码增加前置判断:
if (!员工已经调薪) {
进行调薪
}
但是上面有一个非常严重的问题就是需要前置判断的地方太多了,一不留神就漏掉了,这种问题不应该成为干扰写业务代码的因素
所以我们需要一种无侵入的幂等解决方案,构建幂等表时我们通用解决方案
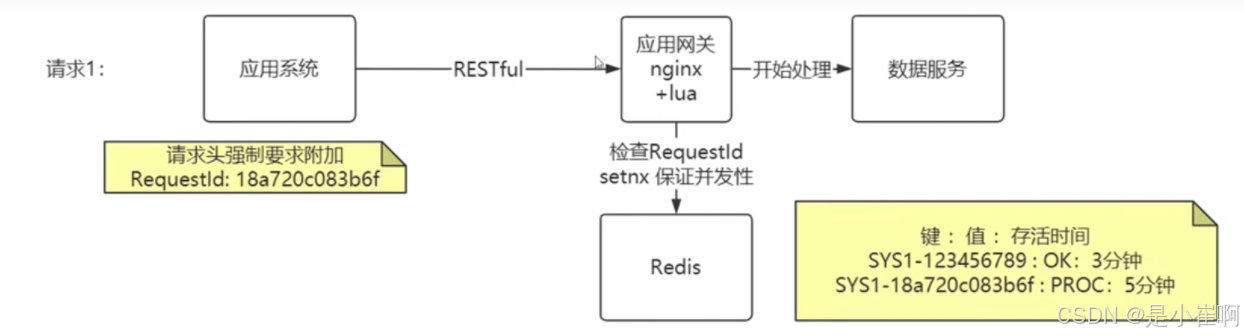
redis中存储了这个最近几分钟执行的请求的编号是什么,同时有存活时间,到时间之后,这个键将会自动移除
3:@Idempotent封装
package com.study.mycommondemo.anno;
import java.lang.annotation.*;
import java.util.concurrent.TimeUnit;
/**
* <p>
* 功能描述:幂等注解
* `@Idempotent(key = "#demo.username", expireTime = 3, info = "请勿重复查询")`
* `@GetMapping("/test")`
* </p>
*
* @author cui haida
* @date 2024/07/03/16:30
*/
@Inherited
@Target(ElementType.METHOD)
@Retention(value = RetentionPolicy.RUNTIME)
public @interface Idempotent {
/**
* <p>
* 如果是实体类的话,默认拦截不会生效. objects.toString()会返回不同地址.
* </p>
* 幂等操作的唯一标识,使用spring el表达式 用#来引用方法参数
* @return Spring-EL expression
*/
String key() default "";
/**
* 有效期 默认:1 有效期要大于程序执行时间,否则请求还是可能会进来
* @return expireTime
*/
int expireTime() default 1;
/**
* 时间单位 默认:s
* @return TimeUnit
*/
TimeUnit timeUnit() default TimeUnit.SECONDS;
/**
* 提示信息,可自定义
* @return String
*/
String info() default "重复请求,请稍后重试";
/**
* 是否在业务完成后删除key true:删除 false:不删除
* @return boolean
*/
boolean delKey() default false;
}
package com.study.mycommondemo.aspeat;
import com.study.mycommondemo.anno.Idempotent;
import com.study.mycommondemo.exception.IdempotentException;
import com.study.mycommondemo.pojo.domain.expression.KeyResolver;
import org.aspectj.lang.JoinPoint;
import org.aspectj.lang.annotation.After;
import org.aspectj.lang.annotation.Aspect;
import org.aspectj.lang.annotation.Before;
import org.aspectj.lang.annotation.Pointcut;
import org.aspectj.lang.reflect.MethodSignature;
import org.redisson.api.RMapCache;
import org.redisson.api.RedissonClient;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
import org.springframework.util.CollectionUtils;
import org.springframework.util.StringUtils;
import org.springframework.web.context.request.RequestContextHolder;
import org.springframework.web.context.request.ServletRequestAttributes;
import javax.servlet.http.HttpServletRequest;
import java.lang.reflect.Method;
import java.time.LocalDateTime;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.TimeUnit;
/**
* <p>
* 功能描述:幂等切面
* </p>
*
* @author cui haida
* @date 2024/07/03/16:35
*/
@Aspect
@Component
public class IdempotentAspect {
private static final Logger LOGGER = LoggerFactory.getLogger(IdempotentAspect.class);
private static final ThreadLocal<Map<String, Object>> THREAD_CACHE = ThreadLocal.withInitial(HashMap::new);
private static final String RMAPCACHE_KEY = "idempotent";
private static final String KEY = "key";
private static final String DELKEY = "delKey";
@Autowired
private RedissonClient redissonClient;
@Autowired
private KeyResolver keyResolver;
@Pointcut("@annotation(com.study.mycommondemo.anno.Idempotent)")
public void pointCut() {
}
@Before("pointCut()")
public void beforePointCut(JoinPoint joinPoint) {
ServletRequestAttributes requestAttributes = (ServletRequestAttributes) RequestContextHolder
.getRequestAttributes();
HttpServletRequest request = requestAttributes.getRequest();
MethodSignature signature = (MethodSignature) joinPoint.getSignature();
Method method = signature.getMethod();
if (!method.isAnnotationPresent(Idempotent.class)) {
return;
}
Idempotent idempotent = method.getAnnotation(Idempotent.class);
String key;
// 若没有配置 幂等 标识编号,则使用 url + 参数列表作为区分
if (!StringUtils.hasLength(idempotent.key())) {
String url = request.getRequestURL().toString();
String argString = Arrays.asList(joinPoint.getArgs()).toString();
key = url + argString;
}
else {
// 使用jstl 规则区分
key = keyResolver.resolver(idempotent, joinPoint);
}
// 当配置了el表达式但是所选字段为空时,会抛出异常,兜底使用url做标识
if (key == null) {
key = request.getRequestURL().toString();
}
long expireTime = idempotent.expireTime();
String info = idempotent.info();
TimeUnit timeUnit = idempotent.timeUnit();
boolean delKey = idempotent.delKey();
// do not need check null
RMapCache<String, Object> rMapCache = redissonClient.getMapCache(RMAPCACHE_KEY);
String value = LocalDateTime.now().toString().replace("T", " ");
Object v1;
if (null != rMapCache.get(key)) {
// had stored
throw new IdempotentException(info);
}
synchronized (this) {
v1 = rMapCache.putIfAbsent(key, value, expireTime, timeUnit);
if (null != v1) {
throw new IdempotentException(info);
}
else {
LOGGER.info("[idempotent]:has stored key={},value={},expireTime={}{},now={}", key, value, expireTime,
timeUnit, LocalDateTime.now().toString());
}
}
Map<String, Object> map = THREAD_CACHE.get();
map.put(KEY, key);
map.put(DELKEY, delKey);
}
@After("pointCut()")
public void afterPointCut(JoinPoint joinPoint) {
Map<String, Object> map = THREAD_CACHE.get();
if (CollectionUtils.isEmpty(map)) {
return;
}
RMapCache<Object, Object> mapCache = redissonClient.getMapCache(RMAPCACHE_KEY);
if (mapCache.size() == 0) {
return;
}
String key = map.get(KEY).toString();
boolean delKey = (boolean) map.get(DELKEY);
if (delKey) {
mapCache.fastRemove(key);
LOGGER.info("[idempotent]:has removed key={}", key);
}
THREAD_CACHE.remove();
}
}
六:乐观锁解决并发数据冲突
1:为什么会产生并发冲突

2:行锁(悲观锁)解决方案

3:版本号(乐观锁)

七:为啥禁止三表Join关联
1:禁用原因
1:产品强制要求
- 阿里OceanBase只允许2表关联
- MyCat只支持2表关联
2:算法NLJ非常耗费性能
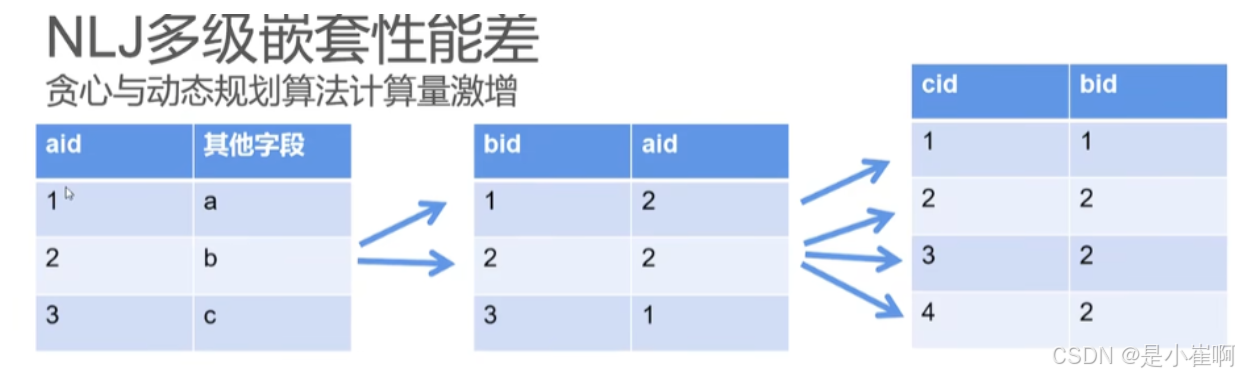
3:依赖数据源特性获取数据,数据迁移改造困难
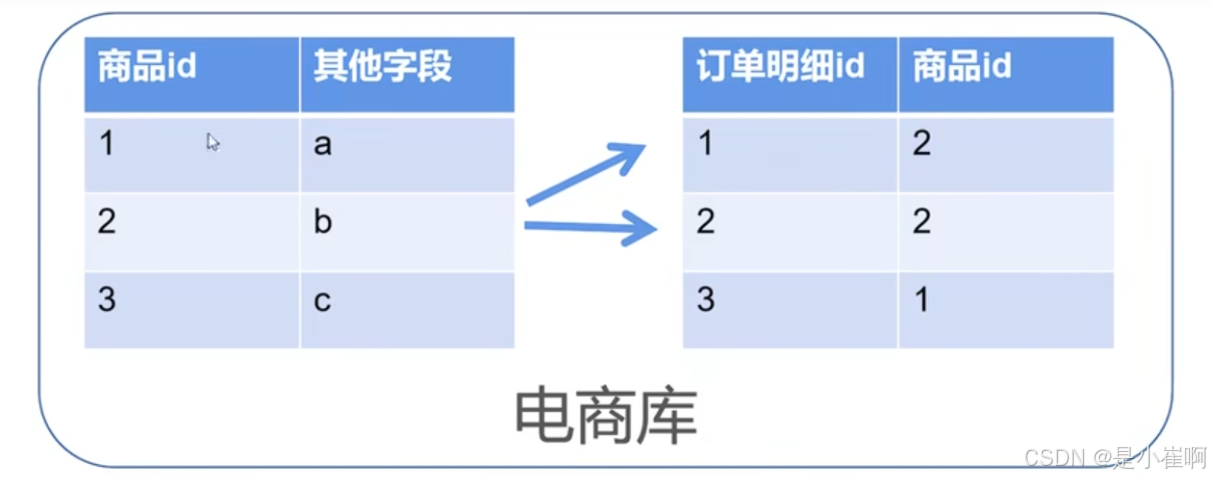
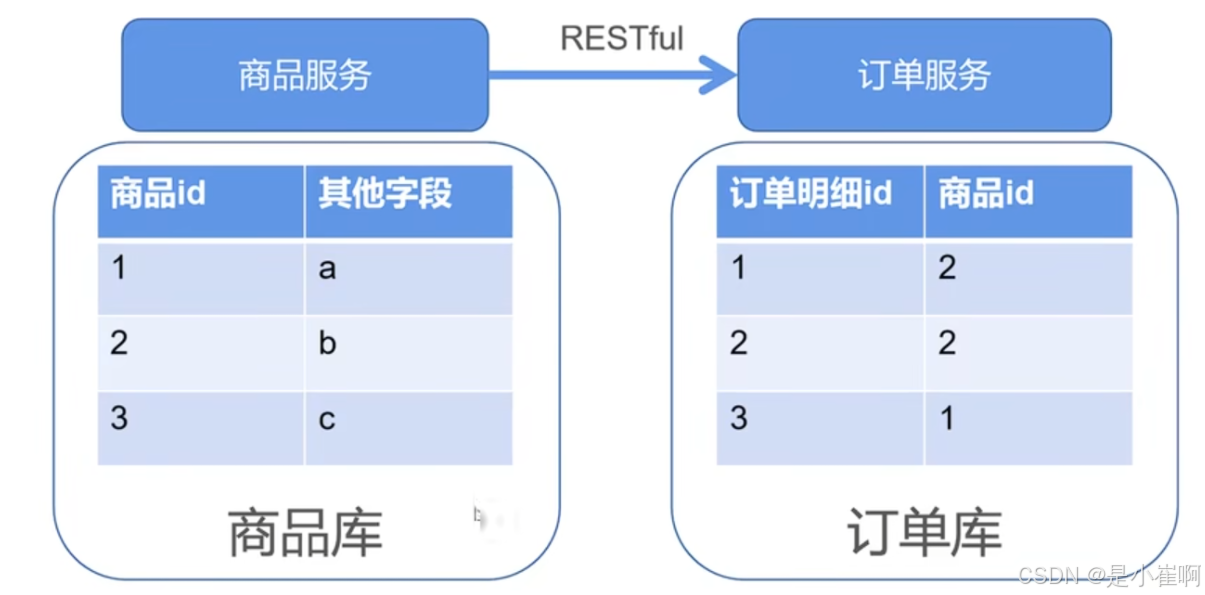
体量大了之后:跨库Join问题
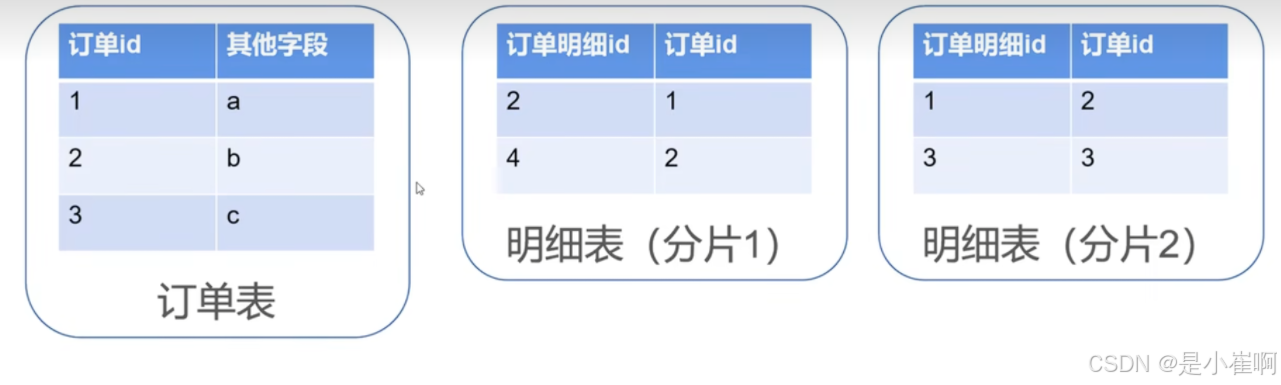
分库分表拆分问题的join问题(对所有的订单分片遍历)
2:反范式表的引入
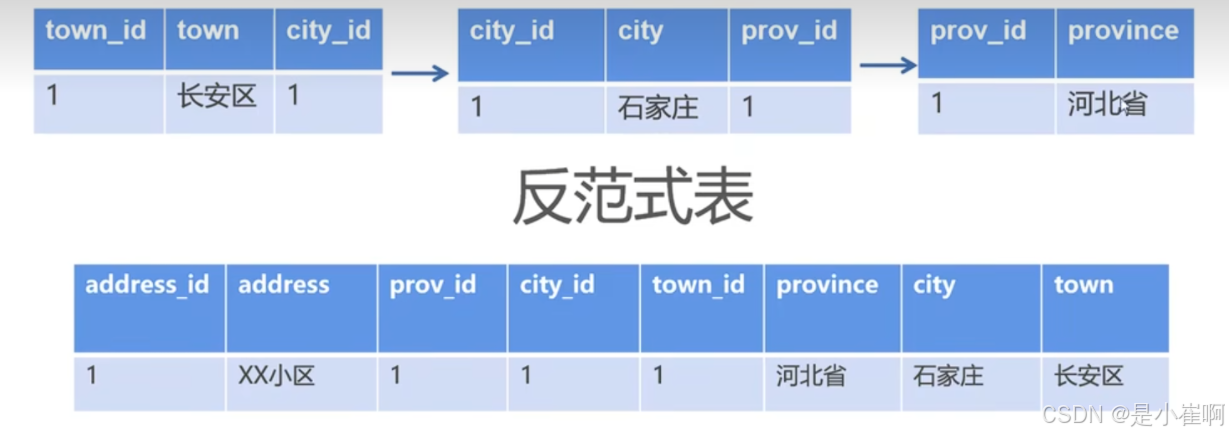
3:数仓大数据
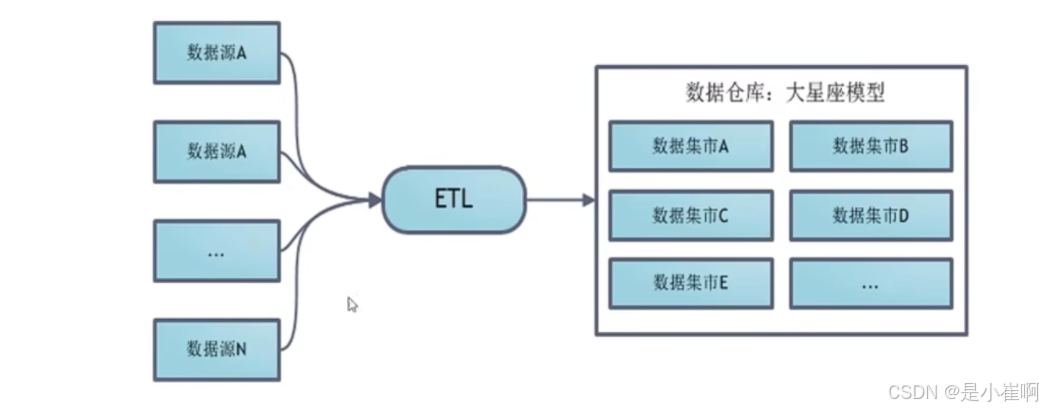
八:为啥禁止存储过程
1:为什么银行都在用存储过程
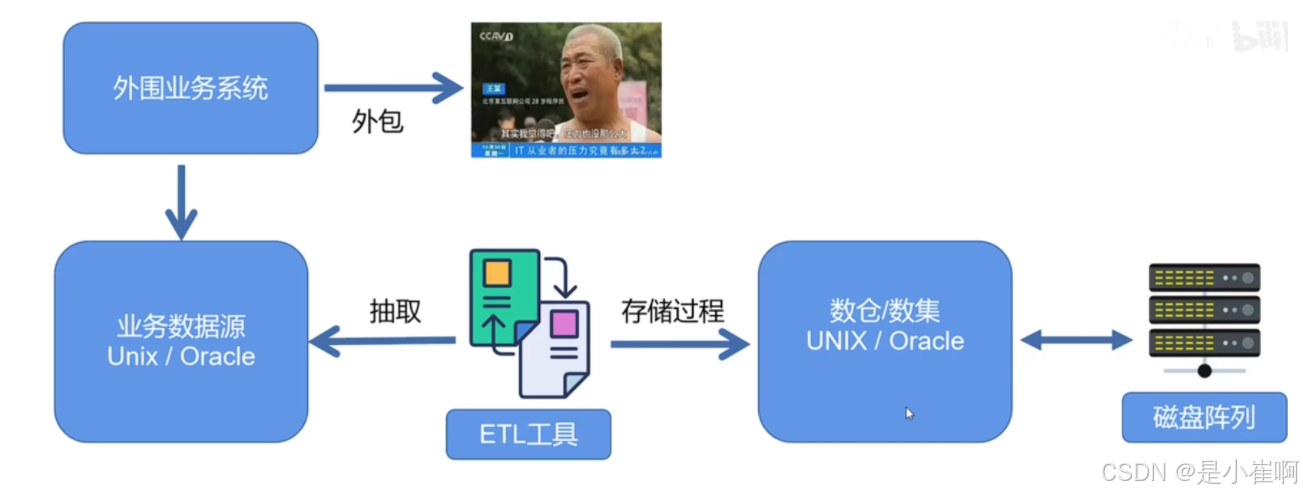
国内的银行的存储数据库主要以Oracle/DB2为主,因为成熟的企业级数据库提供厂商能提供完整的售后服务等信息
银行采用空间换时间的策略将数据定时通过ETL工具抽取到数据仓库中,从而实现数仓存储
从上图可以发现,在ETL -> 数仓这个位置,使用了存储过程来执行,存储过程依附于Oracle数据库。
综上所述,下面是银行使用存储过程的四个原因
- 而银行业务是以数据为核心,所有的都是数据优先
- Oracle,DB2一统江湖,存储过程和语言无关
- 预算充足,好多个W采购小型机满足性能要求
- 存储过程几乎是每一个信息科技处开发员工的入职要求
2:为什么存储过程称为了互联网的弃子
- 银行被存储过程绑架

如果要进行数据国产化方面的迁移,存储过程要全部进行重写,谁来承担核心业务的风险
- 存储过程在互联网分布式场景的问题
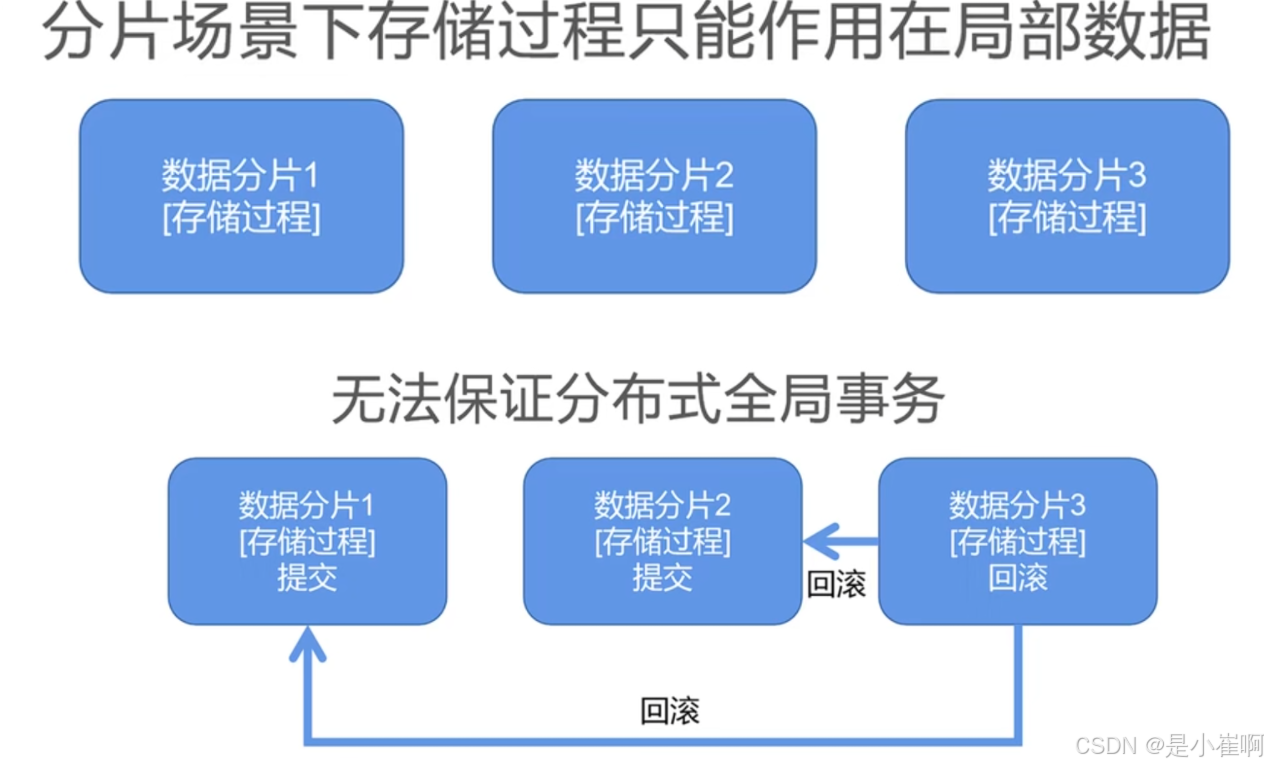
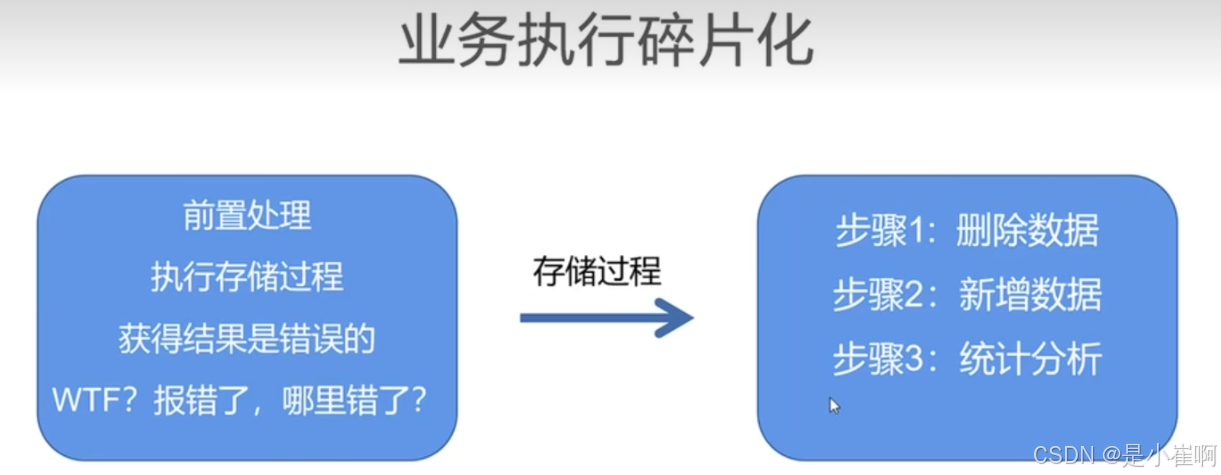
3. 存储过程难以调试,没有内置的版本管理方案
4. 业务执行的碎片化
九:前后端分离下的JWT
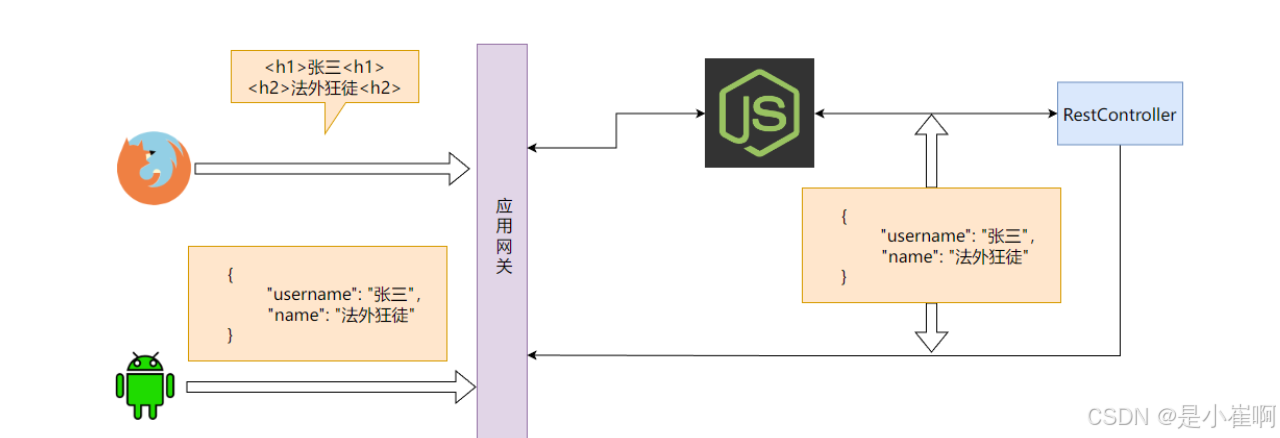
1:JWT
前后端分离架构
JWT是一个经过加密的,包含有用户信息的,且具有时效性的固定格式的字符串(Json Web Token)

橙黄色 -> 标头【元数据,使用的加密算法等】,绿色 -> 载荷【用户的信息在这里,非敏感】,蓝色 -> 签名
JWT的创建和校验不用自己实现 -> JJWT
String key = "xxx"; // 定义私钥字符串
String base64 = new BASE64Encoder().encode(key.getBytes()); // 对秘钥做bese64编码
// 生成秘钥的对象,会根据base64的长度自动选择相应的HMAC算法
SecretKey secretKey = Keys.hmacShaKeyFor(base64.getBytes());
// 利用JJWT生成Token
String data = "{\"userId\": 123}"; // 定义载荷数据
// 封装jwt
String jwt = Jwts.builder().setSubject(data).signWith(secretKey).compact();
System.out.println(jwt);
String jwt = "xxx"; // 模拟从前端拿到jwt
// 私钥
String key = "xxx"; // 使用之前的私钥字符串进行解密
//1:对私钥进行base64编码
String base64 = new BASE64Encoder().encode(key.getBytes()); // 对秘钥做bese64编码
//2:生成秘钥的对象,会根据base64的长度自动选择相应的HMAC算法
SecretKey secretKey = Keys.hmacShaKeyFor(base64.getBytes());
//3:验证Token
try {
// 生成JWT解析器
JwtParser parser = Jwts.parserBuilder().setSigningKey(secretKey).build();
// 解析JWT
Jws<Claims> claimsJws = parser.parseClaimJws(jwt);
// 得到载荷中的用户数据
String subject = claimJws.getBody().getSubject();
System.out.println(subject);
} catch (JwtException e) {
// 所有的Jwt校验异常都继承JwtException
System.out.println("Jwt校验失败");
e.printStackTrace();
}
2:JWT校验
方案一:网关统一校验
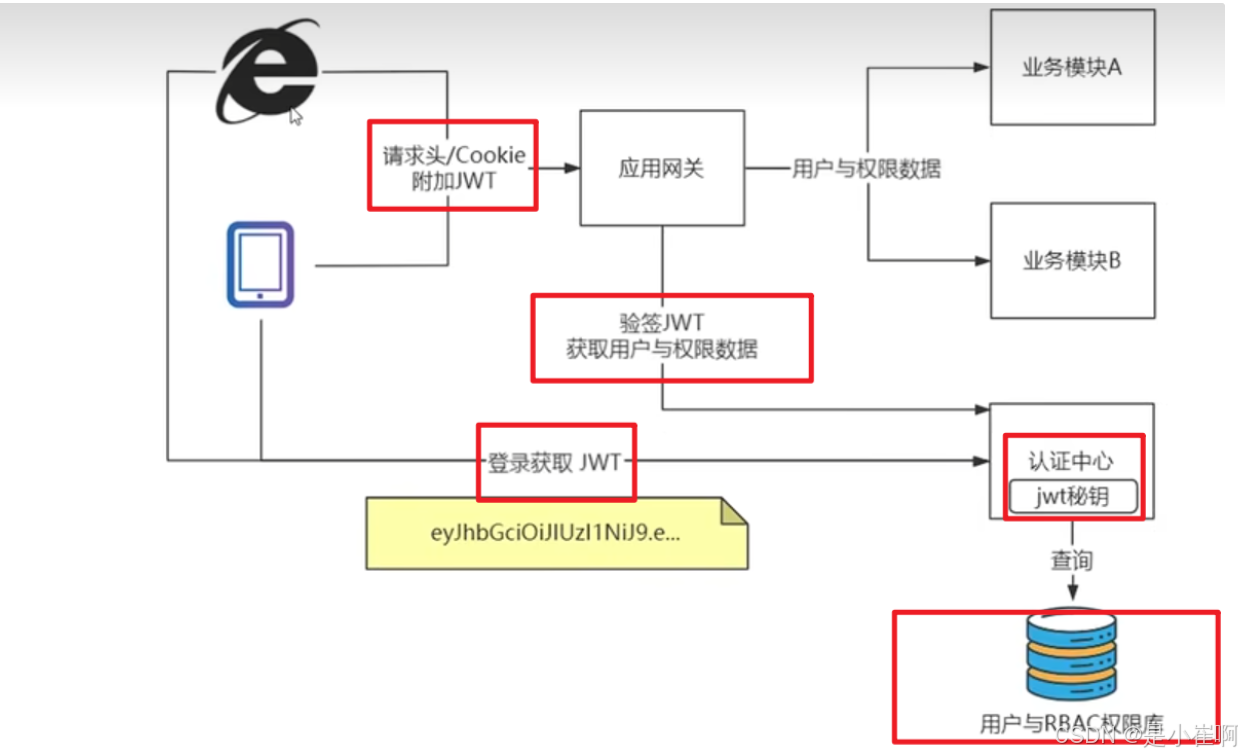
- 存在一个用户中台【上图中的认证中心】专门管理用户的登录和JWT创建,存储和验证
- 用户首先登录,通过用户中台获取JWT,此后不管访问什么,前端都会在请求头或者Cookie中附加JWT
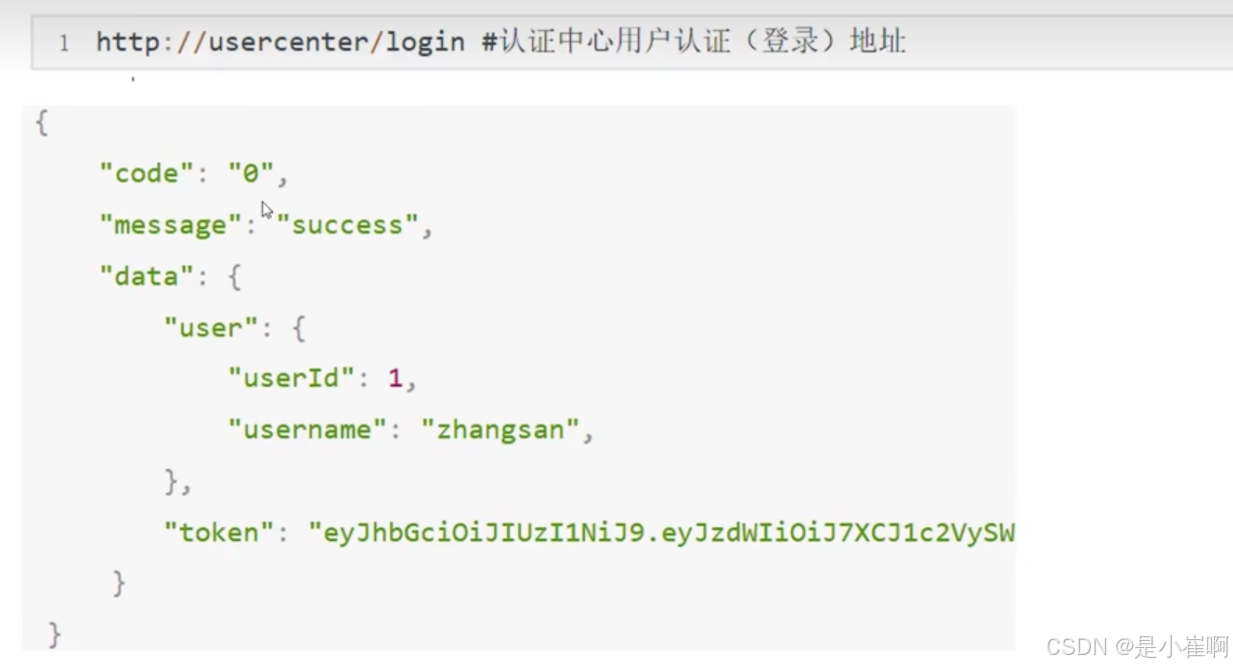
传给应用网关之后,由网关带着验签JWT去用户中心获取用户和权限数据,然后拿到结果之后,给到各个下层应用业务模块

方案二:应用认证方式
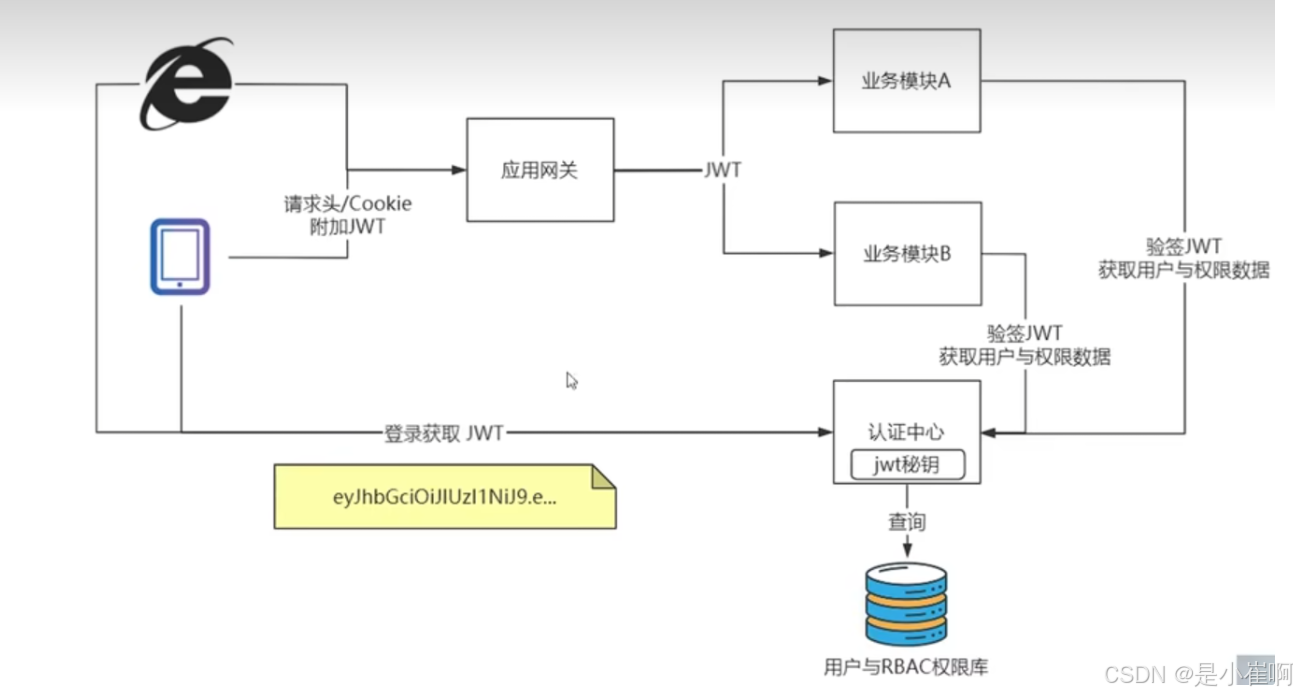
方案一:JWT校验无感知,验签过程没有侵入,执行的效率比较低,适用于低并发企业级应用
方法二:控制更加的灵活,有一定的代码侵入,代码可以灵活控制,适用于追求性能的互联网应用。
3:JWT续签
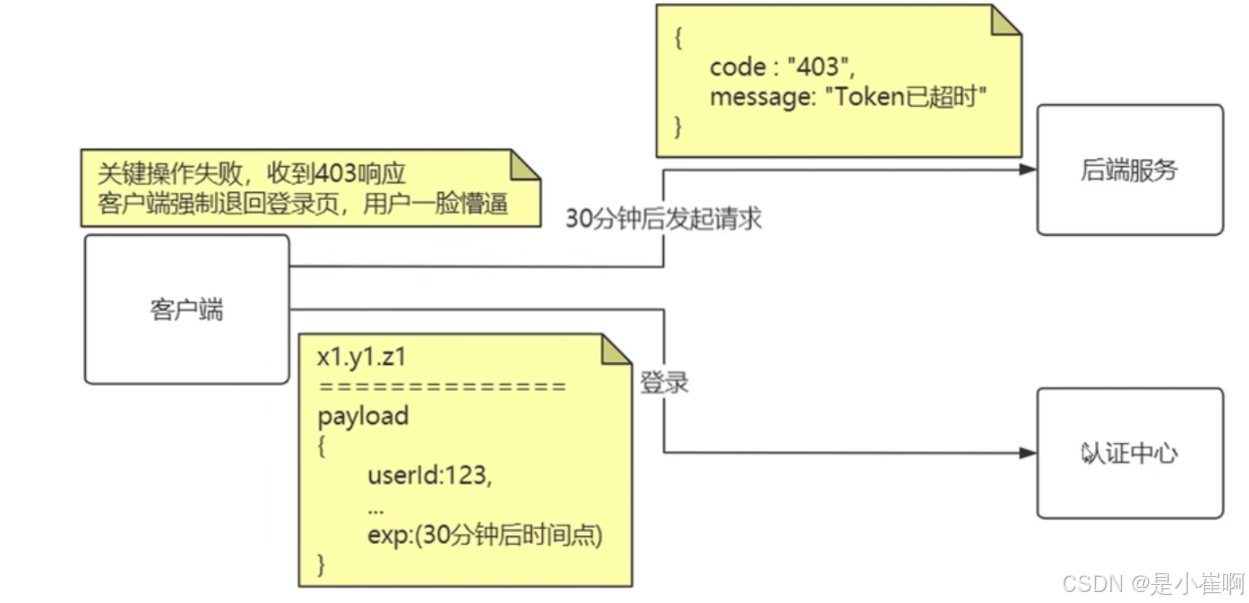
1:不允许改变Token令牌实现续签
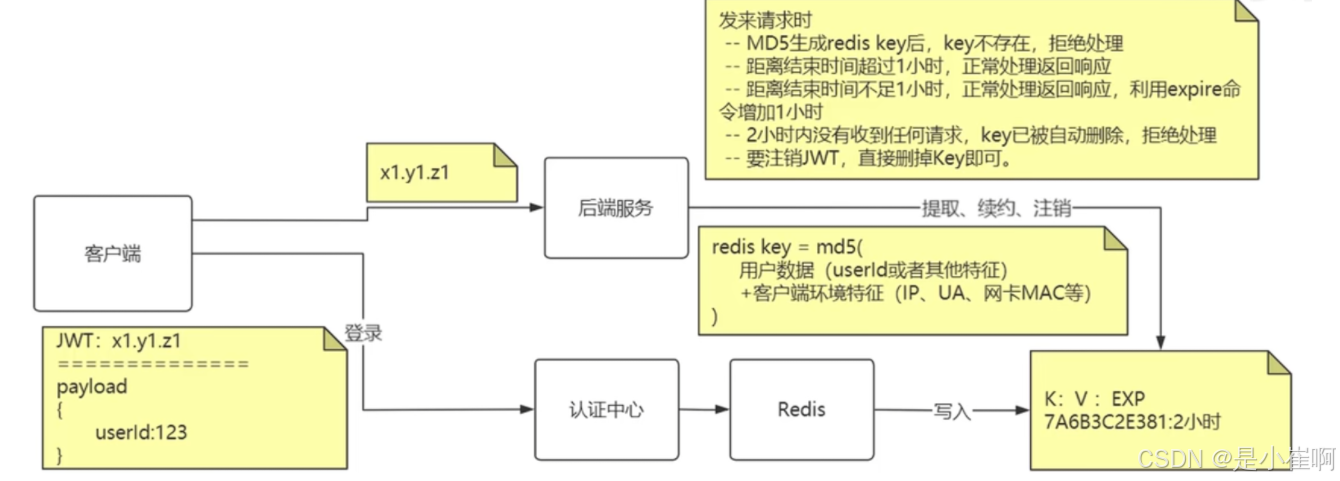
为什么redis的key不直接用Jwt,而是自己搞key
1:JWT的key比较长,放在redis中作为key不是很合适
2:安全需要,redisKey生成时,加入了环境特征,从最大限度上的避免人为的盗取,这同时意味着JWT是有状态的。
2:允许改变Token令牌实现续签
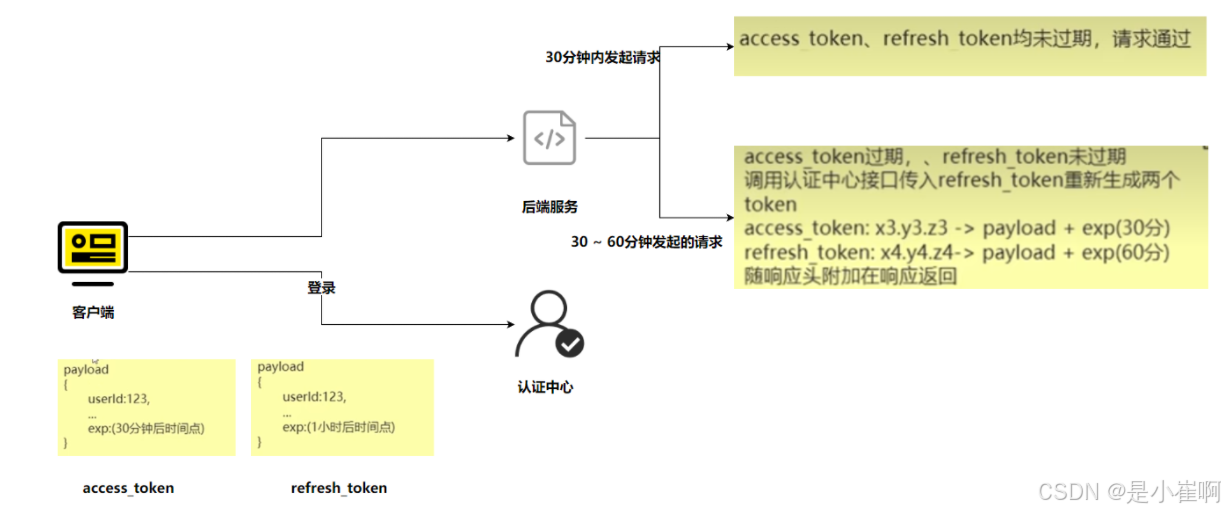
为什么要设置两个jwt,为什么不是直接设置jwt的过期时间是一个小时,判断要过期的时候,生成新的token进行替换
access token用于业务系统交互,是最核心的数据。
refresh_token只用于向认证中心获取新的access_token与refresh_token。
refresh_token的出现本质解决了在用户超过30分钟后,access_token已经失效,此时access_token被送给认证中心是无法解析的
而refresh_token因为生存时间更长,且主体内容与access_token一致,因此被送达认证中心后可以被正确解析
进而重新生成新的access_token与refresh_token。
十:经典高可用
1:最基本的长这样
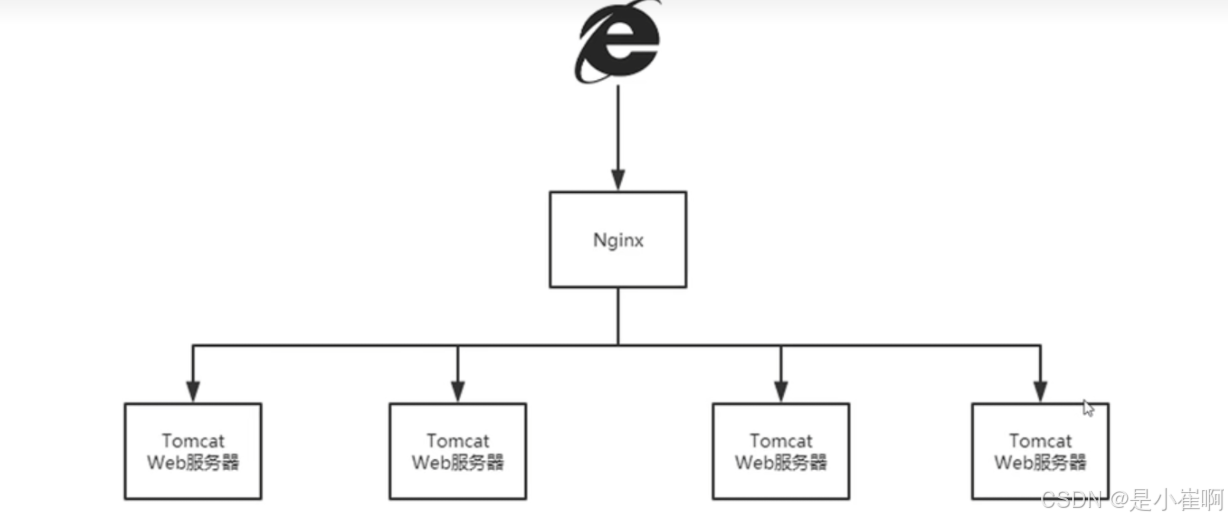
2:Nginx高可用
上面Nginx单个节点,会有单点故障问题,所以为了进行高可用,可以部署VIP + Keepalived
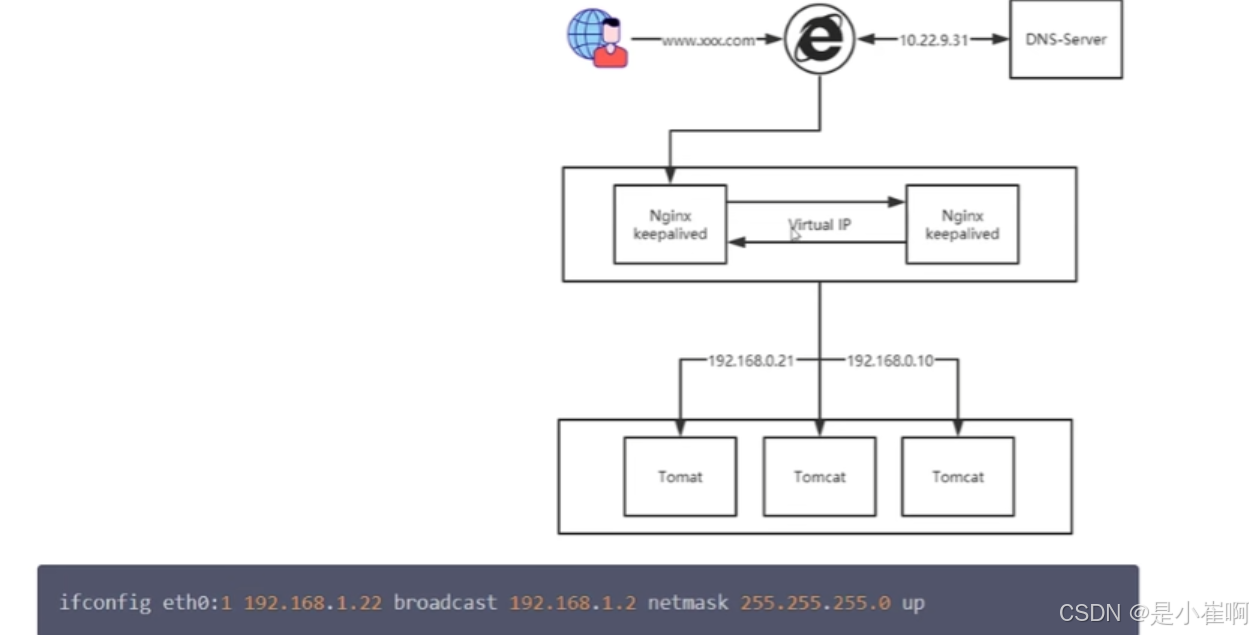
3:DNS轮询引入
VIP + Keepalived 只能有一个Nginx对外提供服务,如果想要有多个Nginx对外暴露服务,就要引入DNS解析了

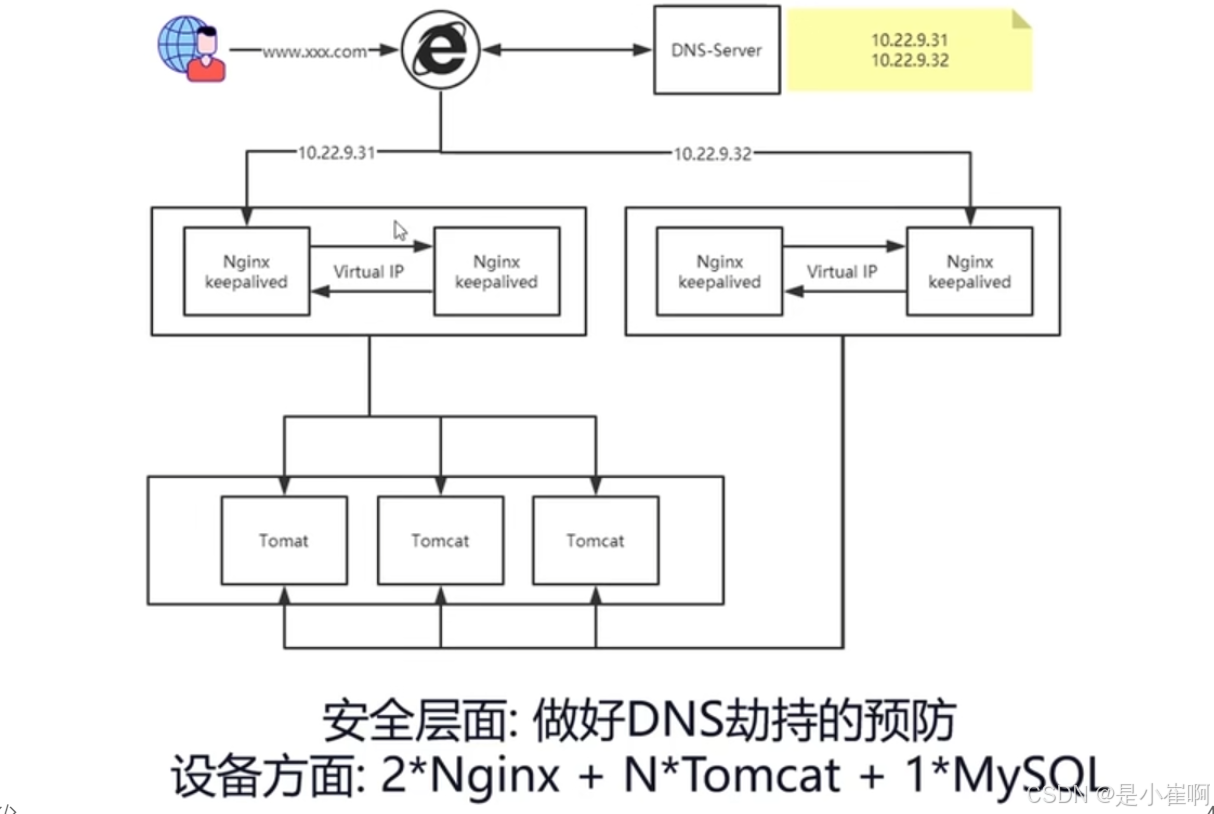
DNS有如下缺点:
- 只是负责IP轮询获取,不保证节点可用性
- DNS IP列表的变更有延迟
- 外网IP占用严重
所以不能跳过Nginx,而直接让DNS轮询后端Tomcat服务

















 676
676

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









