




老齐架构(31 - 40)
文章目录
一:rabbitMQ解决消息积压【宜信】
假设现在rabbitMQ使用的是简单模式
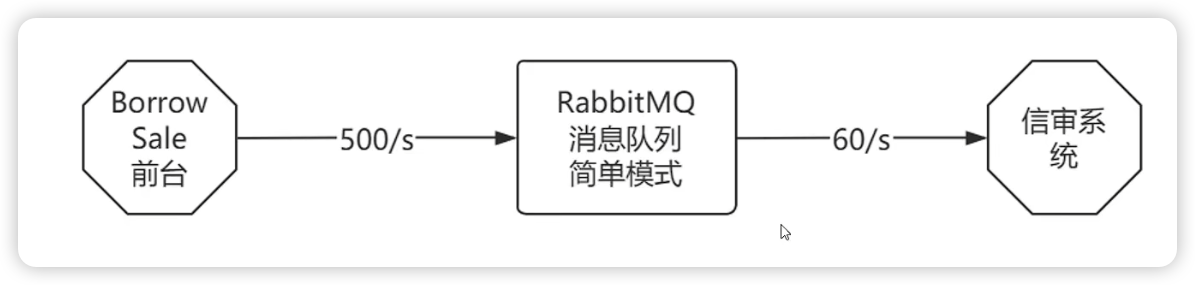
每天的上午10点,全国2万多个客户经理集中录入上一天的JK单到BorrowSale系统。
峰值能达到500单/s的QPS,但是信审系统任务重,最多支持到60单/s,每天会造成大量的消息积压
解决方式一:工作队列模式
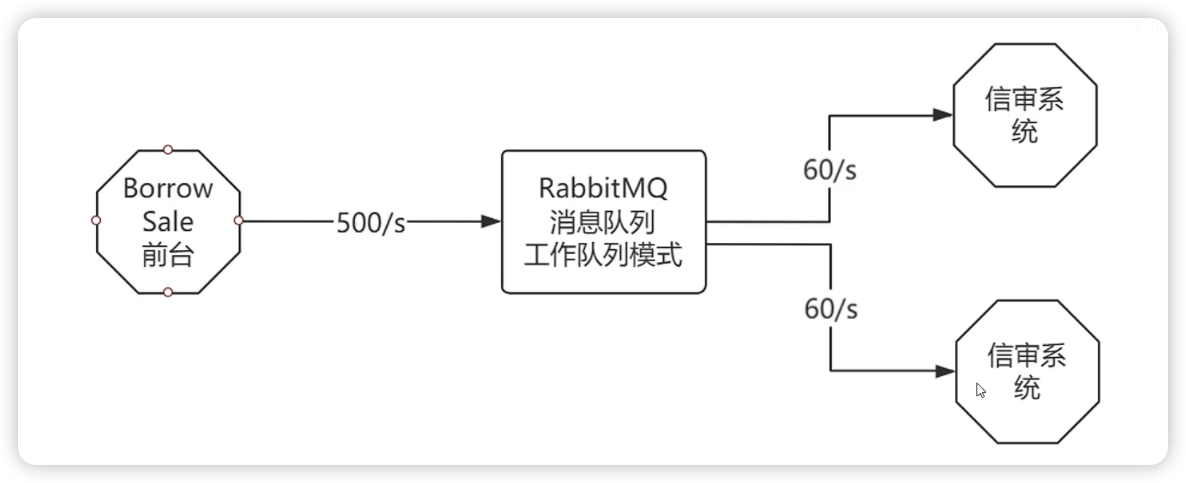
这是解决消息积压最简单的方式,将RabbitMQ改成工作队列模式,将消息发送给9个信审系统并行完成。
但是显然有问题啊,预算太高了,所以此时作为BS前台就需要自己想办法解决消息积压问题
解决方式二:死信队列
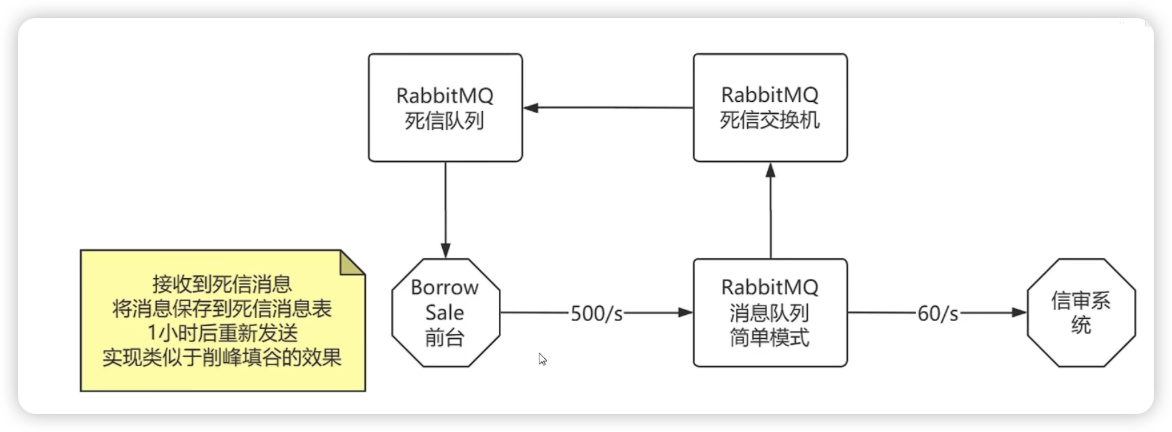
BS前台解决方案:依赖RabbitMQ的死信队列的特性,将死信消息自动送到死信队列中,BS前台接收到死信消息之后,1个小时会进行重发,等待闲的时候由信审系统再次进行处理,这样便能实现在不增加资源的情况下,对信审系统资源进行“填谷削峰”
所谓死信:就是过期或者无法处理的消息
RabbitMQ中,死信产生的原因如下:
- 消费者拒绝接受,并且没有重入进入队列的属性
- 队列满了, 无法进入队列
- 消息设置了TTL过期时间,超过有效的时间之后的消息
- 队列设置了TTL过期时间,超过有效的时间之后的消息
二:大平台主键禁用UUID
1:UUID介绍
UUID = 全球唯一标识符
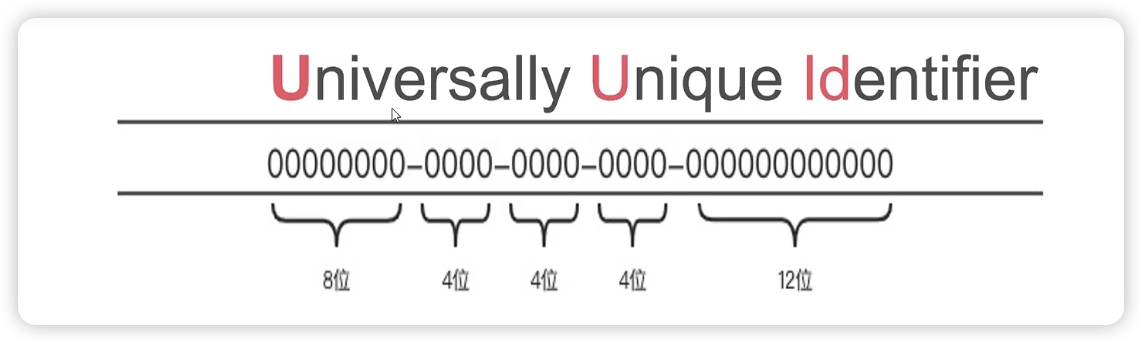
UUID并不是一个固定的算法,现在市面上厂家常见的有5个版本的UUID
UUID版本1 - 基于时间的UUID
- 能保证不同设备上的UUID是唯一的
- 在同一个设备上生成UUID是可能重复的
UUID版本2 - DEC安全
- DCE = 身份验证和安全服务
- 涉及侵犯用户的隐私
- 有损时间戳导致精度丢失
UUID版本3 - 基于命名空间的UUID(MD5, SH1)
- 在相同的命名空间下可能会出现UUID的重复
UUID版本4 - 基于随机数的UUID
- 完全随机生成,会存在极小的概率重复的情况
- 与外部的环境没有关系,不涉及到环境的信息
- 生成内容没有顺序,没有规律
- 目前的主流做法
public static UUID randomUUID(); // java.util.UUID
2:为啥随机的UUID不适合作为主键
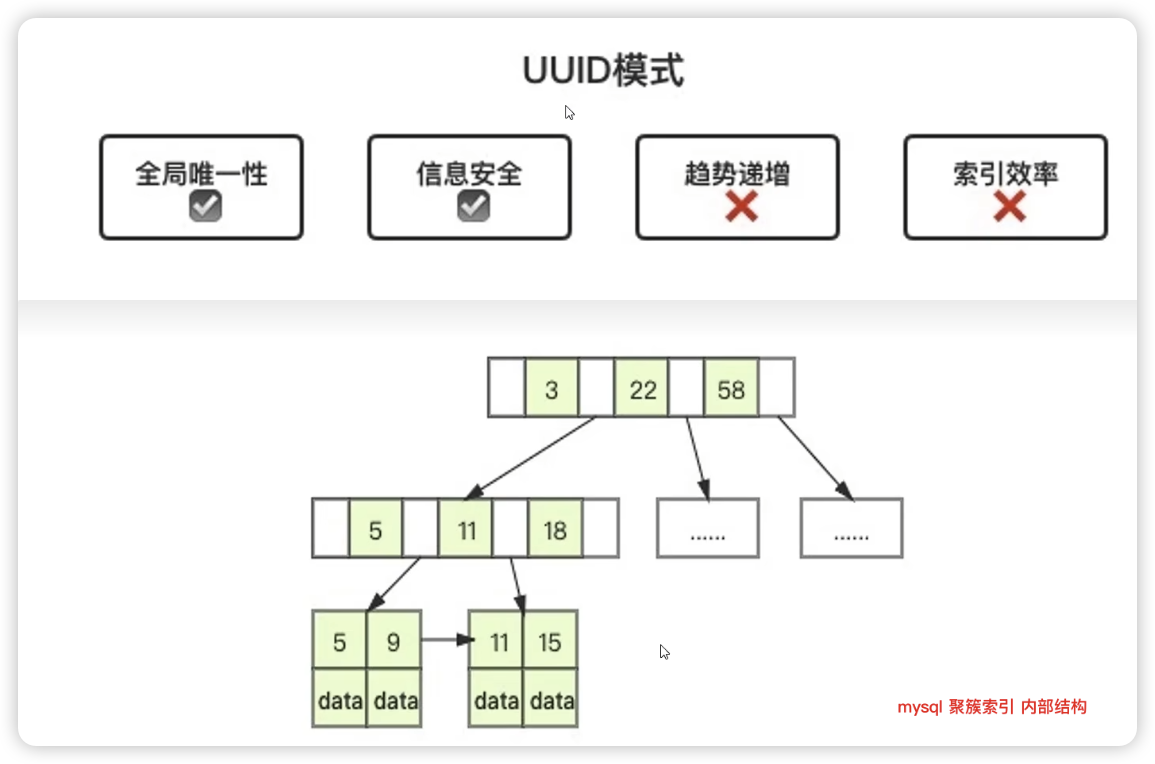
如果主键索引是有序的,那么插入的时候,只需要在最后面进行追加就可以了,而不用像UUID一样遍历整个叶子,找到自己的合适的位置
UUID是无序的,当UUID坑能在索引的中间的某一页的插入数据的时候,新增记录所在的数据页如果已经满了,数据库需要申请一个新的数据页存储数据,这种现象被称为页分裂。
页分裂确保后一个数据页中的所有的ID值一定比数据页中的ID大,在大并发的情况下增加了磁盘IO的压力,无序的ID弊端就会十分明显
对此推荐是由有序的递增主键就可以解决页分裂的问题,推荐主流的:美团Leaf,阿里的UidGenerator,推特的Snowflake
三:Kafka高性能原因
0:Kafka & RocketMQ
现在国内主流的两大消息中间件分别是Kafka和RocketMQ,很多人会对二者进行对比,二者虽然都是消息中间件,但是使用场景完全不同:

Kafka可以想象成为河道:河道很宽,但是流速很慢 - 吞吐量十分的大,适合处理并行任务 - 大数据
RocketMQ可以想象成为高压水枪:出口很窄,但是流速很快 - 吞涂量小,但是可以高效的处理
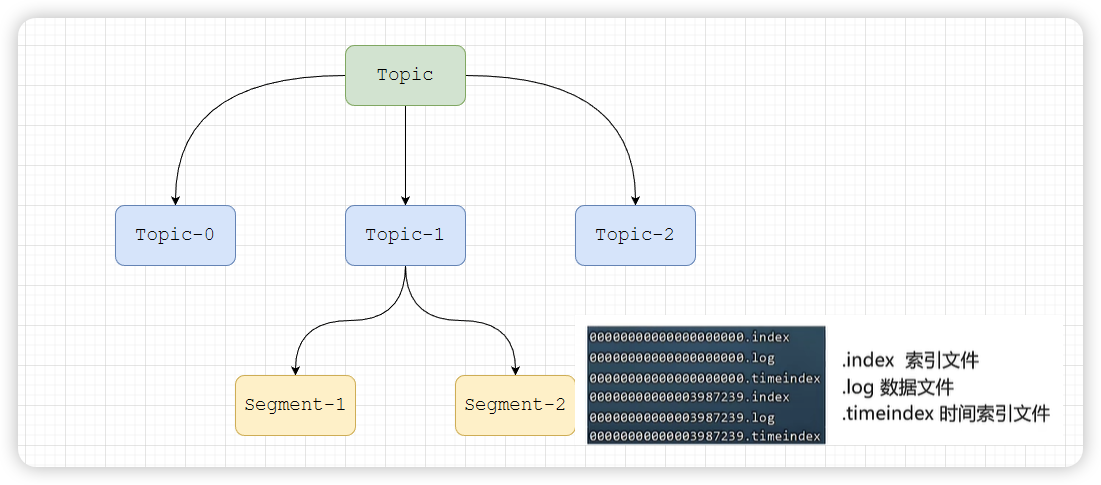
1:消息分区(不受单台限制)
- 不受单台服务器的限制,可以不受限的处理更多的数据
- 并且数据量过大之后,还会分段存储
2:顺序读写(磁盘顺序读写)
- Kafka的消息时存储在磁盘中的文件中的,在写文件时
以追加的方式写入,这个顺序读写效率是很高的 - 效率高主要是和随机读写进行比较,主要是磁盘的寻址过程效率高
- 磁盘顺序读写,提升读写效率
3:内核态页缓存(缓存)
- 页缓存是linux中的概念,可以理解为linux系统的缓存
- Kafka在读数据时,
把磁盘中的数据缓存到内存中,把对磁盘的访问变为对内存的访问
4:零拷贝(重点,难点)
Linux的IO模型:划分两个空间,用户空间和内核空间,用户空间权限比较小,内核空间权限更大一些,可以调用系统的一切资源。
非零拷贝
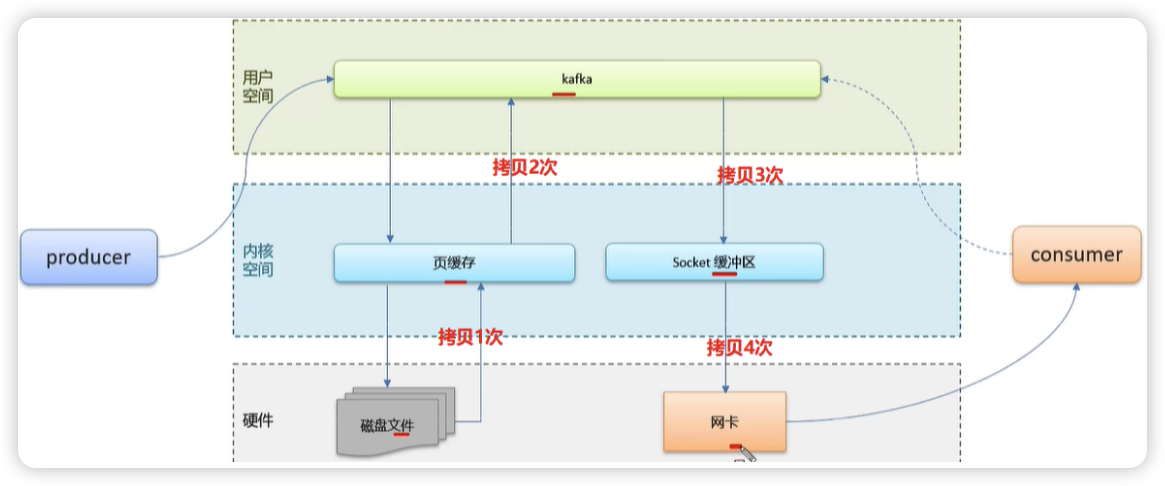
保存消息的流程:一个生产者去发送消息,肯定是在用户空间发起的,消息时要存储在磁盘文件中,用户空间没有权限调用磁盘读写,会先把数据拷贝到内核空间的页缓存中去处理,页缓存中数据到了一定批次后,就会把数据写入到磁盘中。
消费消息的流程:一个消费者去消费消息,首先用户空间的Kafka服务会先到页缓存中去找有没有这个消息,没有再到磁盘文件中去读取文件中的消息。把消息拷贝到页缓存中,再从页缓存中将数据拷贝到用户空间的Kafka中。Kafka将消息拷贝到socket缓冲区,socket缓冲区在将消息拷贝给网卡发送给消费者。这个过程性能肯定是不高的,因为消息拷贝的次数太多了。
零拷贝
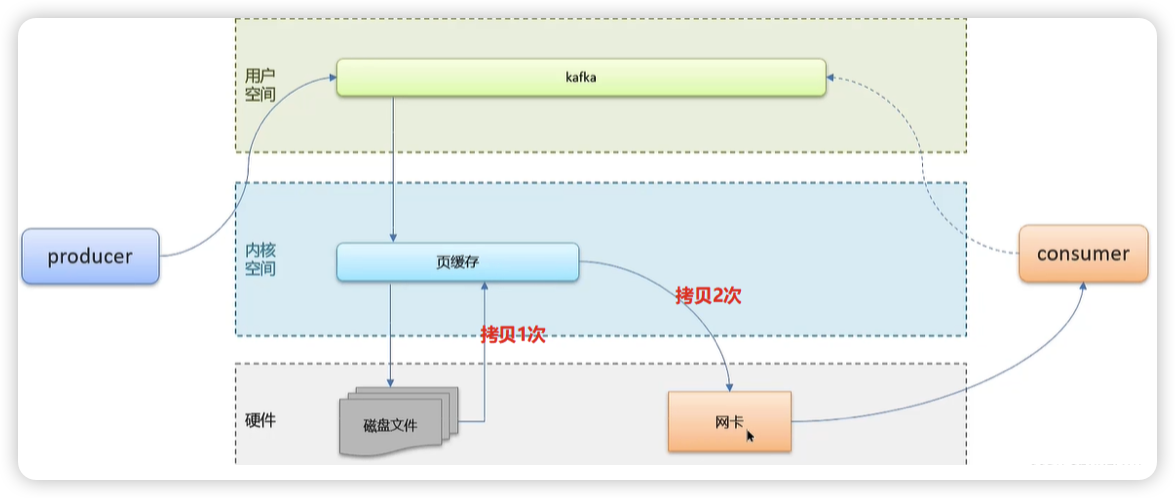
- 把所有的事情都委托给系统去操作,由系统直接从页缓存中将消息拷贝到网卡,发送给消费者
- 减少上下文切换及数据拷贝的次数
5:消息压缩
Kafka内部提供了多种的消息压缩算法,发送数据时可以专门进行设计:
压缩数据时,可以减少磁盘IO和网络IO
不过压缩会耗费一定的CPU,根据业务需求进行压缩设计
// compression.type:压缩,默认none,可配置值gzip、snappy、lz4和zstd
properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"snappy");
6:分批发送
将消息打包批量发送,减少网络传输开销,提高网络传输效率和吞吐量
通过参数的配置来批量发送消息的大小,默认:16KB
也可以设置等待时间,在等待时间内,如果消息没达到16KB大小,Kafka也会将缓冲区中的消息发送出去,避免消息积压
// batch.size:批次大小,默认16K
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
四:MySQL如何选型硬件
1:cpu的选择
先明确两点:
- mysql不支持多cpu对同一个sql进行并发处理
- 5.6以后对多核CPU进行了优化
对于cpu的选择:
- 64位的CPU一定要工作在64位的系统之下
- 对于并发比较高的场景CPU的数量比频率更加的重要
- 对于CPU密集型场景和复杂SQL则是频率越高越好
2:内存的选择
- 理想的选择是服务器的内存大于数据总量
- 内存频率越高处理的速度越快
- 内存总量小要合理组织热点数据,保证内存的覆盖
- 内存对于写操作也有重要的性能影响
3:硬盘的选择
硬盘分为:高速SSD硬盘,混合硬盘,机械硬盘
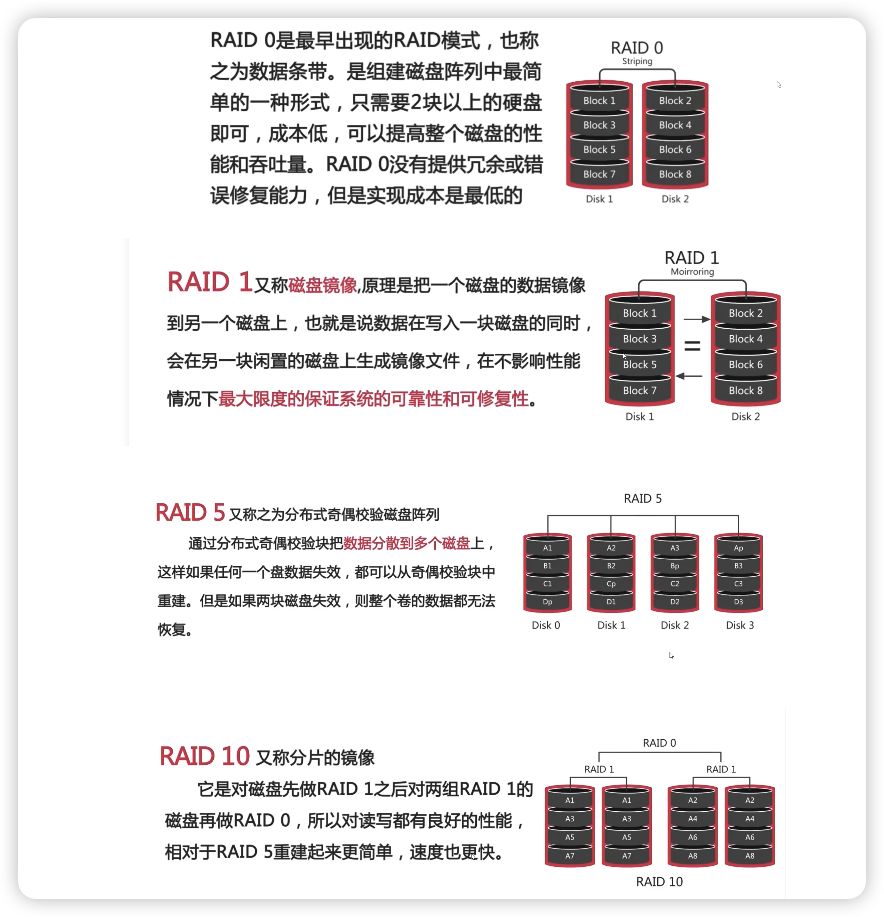
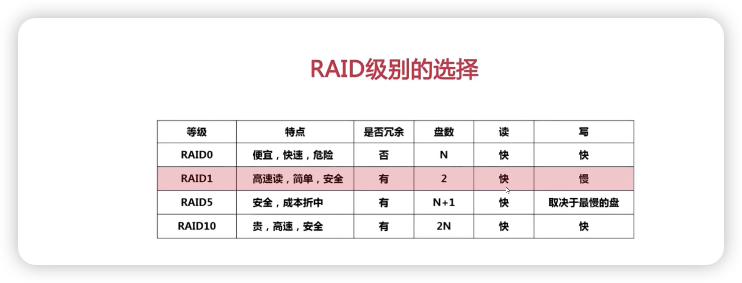
RAID
RAID叫做磁盘冗余队列
简单来说RAID的作用就是可以将多个容量较小的磁盘组成一个容量更大的磁盘
并且提供数据冗余保证数据的完整性技术
五:微博动态通知的推拉模式
1:推拉模式
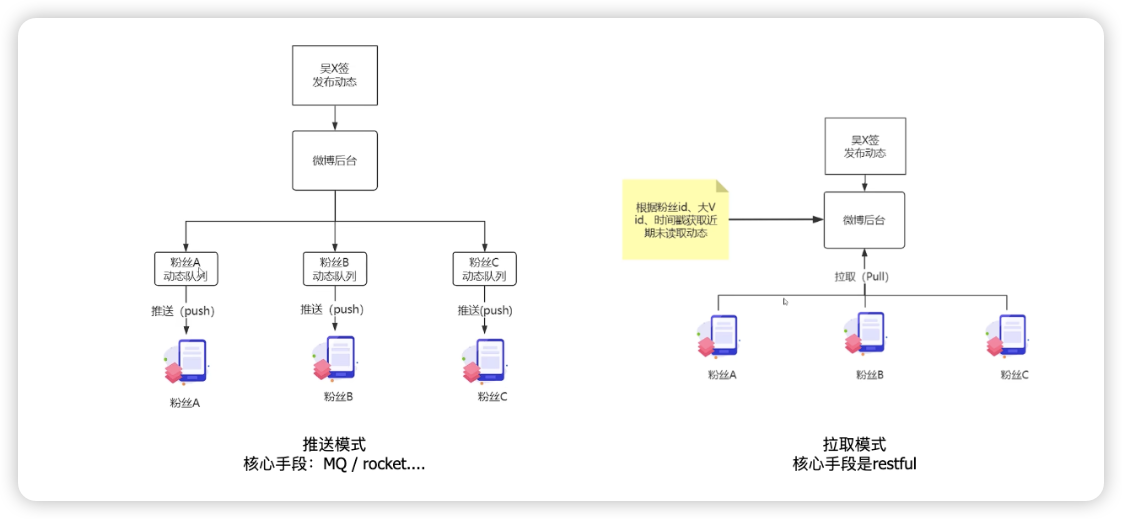
| push模式 | pull模式 | |
|---|---|---|
| 实时性 | 实时性较好,通过网络管道准实时发送 | 较差,取决于定时轮训时间 |
| 服务器状态 | 有状态,需要持久化动态队列 | 无状态,根据请求实时查询 |
| 风险项 | 容易写扩散 大量动态队列的持久化造成磁盘高IO | 容易读扩散 准点并发查询搞垮服务器 |
| 应用场景 | 微信 | 早期的微博 |
2:写扩散(push问题)的优化
- 设置上限,例如微信的好友最多5000个
- 限流设置,X分钟内完成消息发布
- 优化存储的策略,采用NoSQL或者大数据的方式
3:读扩散(pull问题)的优化
- MQ削峰填谷,超长队列直接拒绝掉
- 增加轮训的间隔,减少请求的次数
- 服务端增加缓存,优化查询的效率
- 增加验证码,分散时间,减少机器人刷票
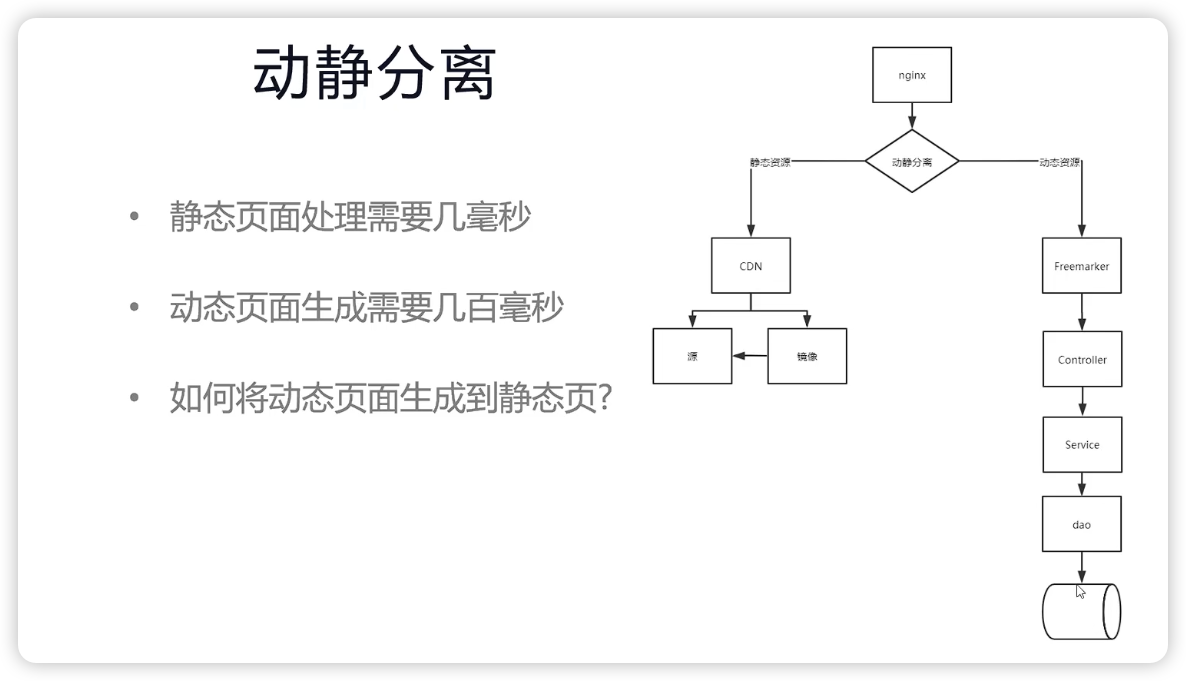
六:动静分离架构抗住京东超高并发
三大分离结构:读写分离,动静分离,前后台分离
1:动态数据和静态数据
正确有效的区分动态数据和静态数据是优化的关键:
所谓静态数据,就是非个性化数据 ->
- 静态文件,例如html, css, js
- 低频变动的文件,例如字典数据,组织结构数据,行政区划数据
所谓动态数据,就是个性化数据 ->
- 个性化推荐
- 高频写 -> 股市行情,5g信号数据,天气变化
2:动静数据案例

先分析动静数据,上面这个苹果售卖页面中,只有红色部分是动态数据,其他的全部是静态数据。
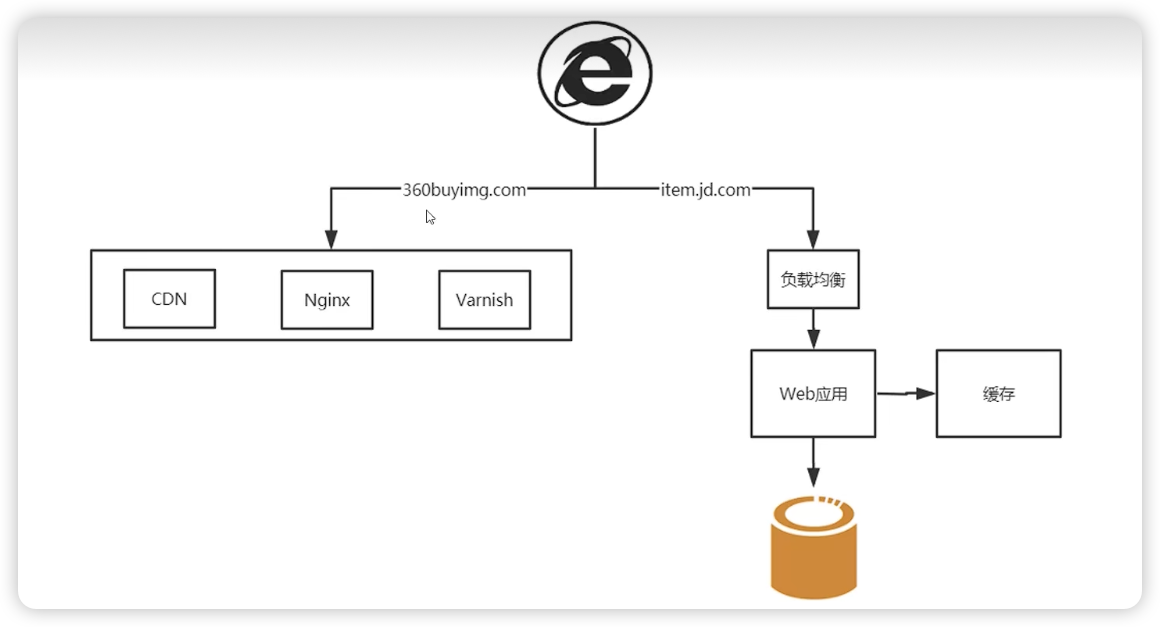
页面静态化技术
- 将动态界面另存为静态界面保存到磁盘上
- 利用nginx直接路由到磁盘文件,不再进入到后端
- 文件碎片化严重,文件同步管理麻烦
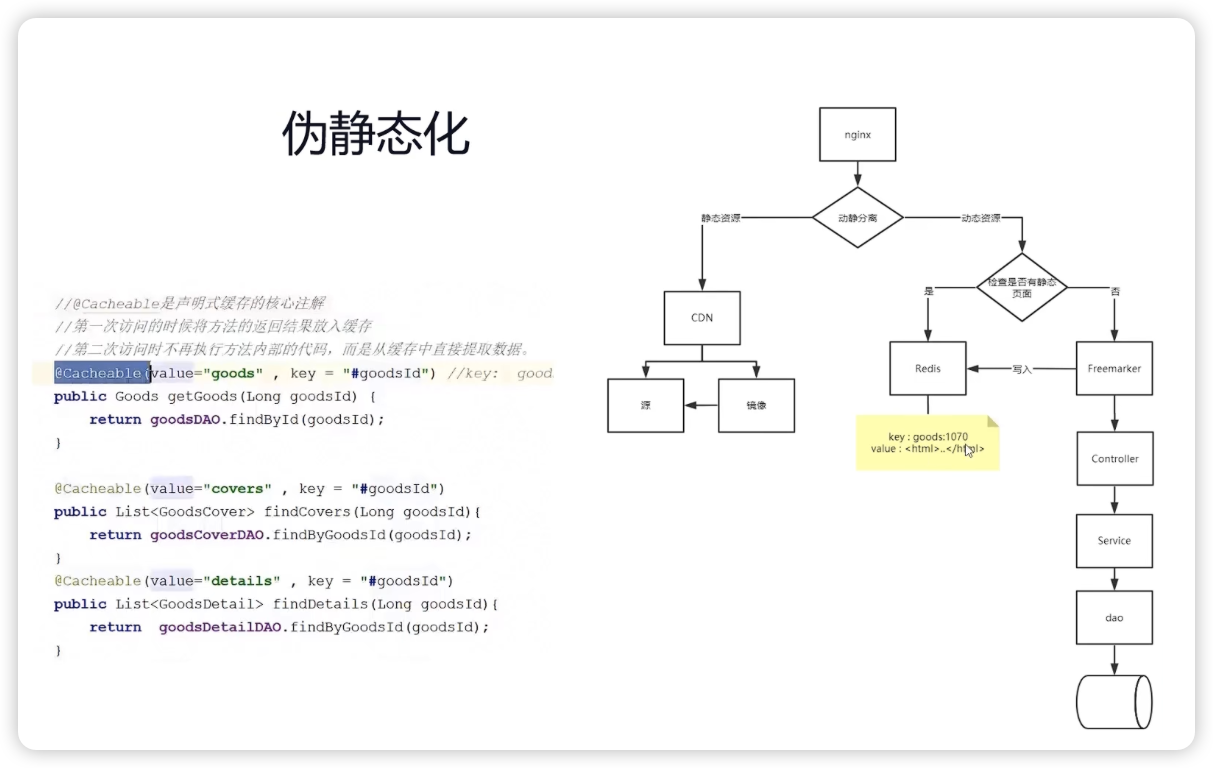
页面伪静态化技术(推荐)
- 例如redis缓存将第一访问之后的返回结果放入缓存
- 第二次访问的时候不再执行方法的内部代码了,而是直接从缓存中提取数据
3:静态化不是万能的

4:动静整合方案
服务端 nginx + SSI -> 搭积木

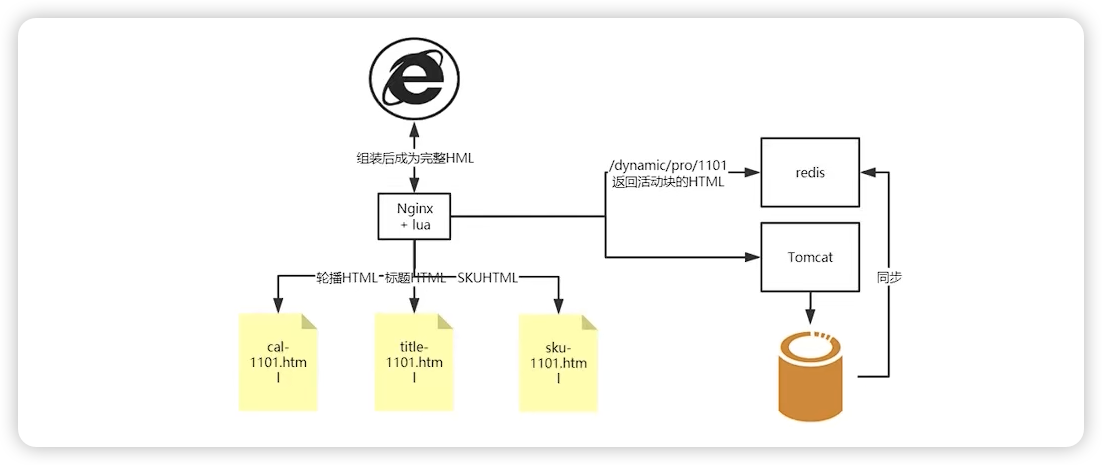
ajax 异步请求法

七:为什么抛弃MySQL去拥抱MongoDB

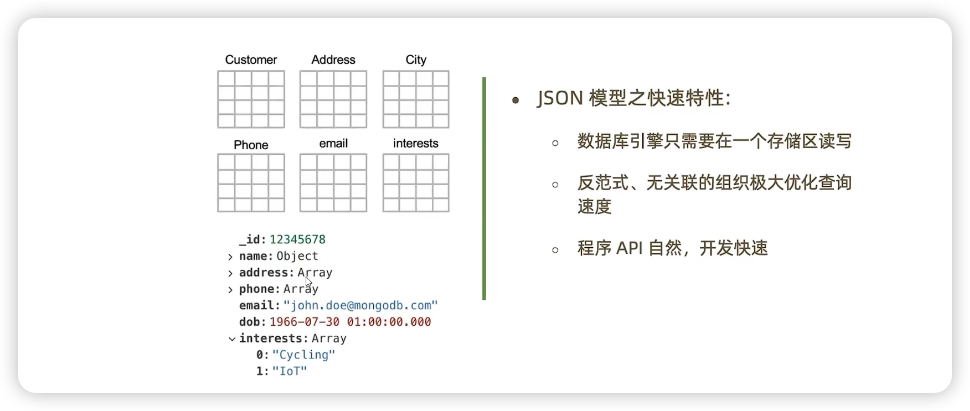
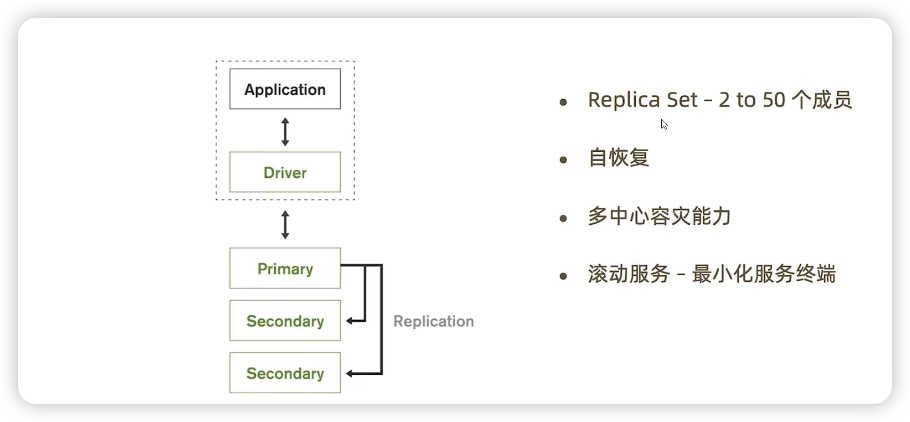
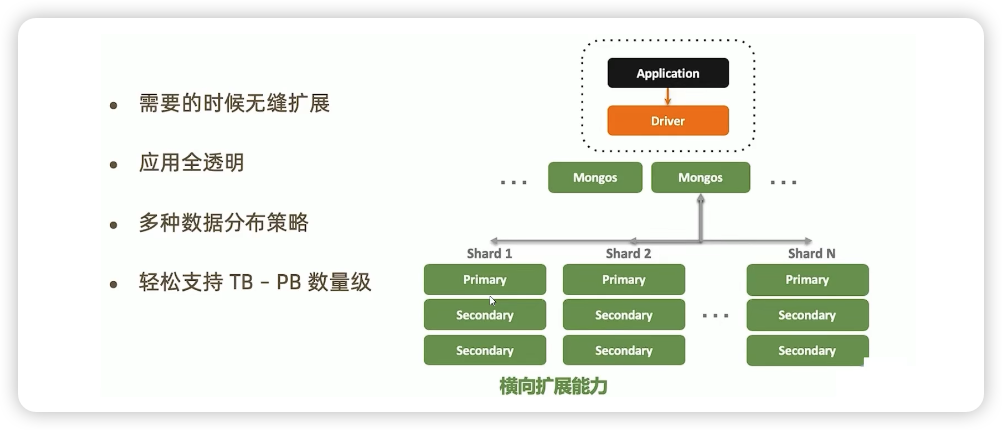
八:日千万级订单系统的高可用、高性能架构
一个非常简单的订单系统
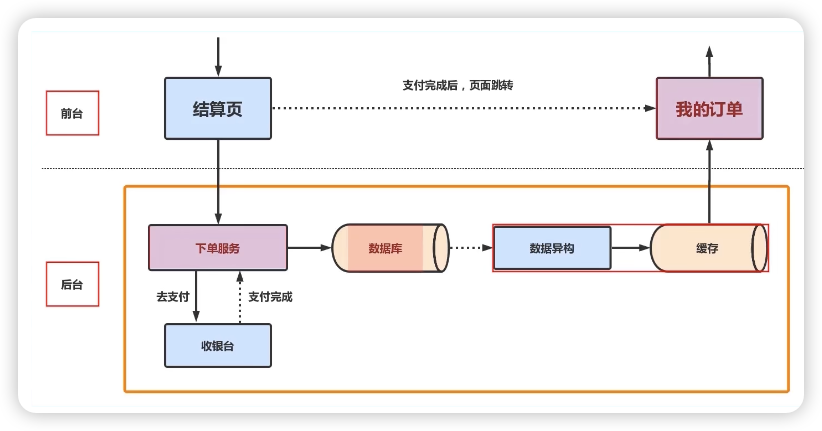
避免丢单的要点如下:
- 关键逻辑不要采用读写分离的方式,避免因为从库延迟导致的订单查询异常事件
- 关键逻辑不能使用缓存来进行订单的查询
- 订单补偿不要粗暴的使用消息队列的方式,避免中间件引发的订单丢失
- 接受消息处理失败的时候一定要进行消息重试,避免丢失,尤其要注意return, continue关键字
日万级别的订单系统的设计要考虑的问题:
- 写数据库的时候,一定要注意事务的粒度级别,避免锁表,关闭慢SQL
- 关注数据异构的性能和稳定性,尤其实在网络抖动的情况下,可能会影响用户体验。
- 关注数据的幂等性,防止影响后续操作
日千万级的订单系统的设计要考虑的问题:
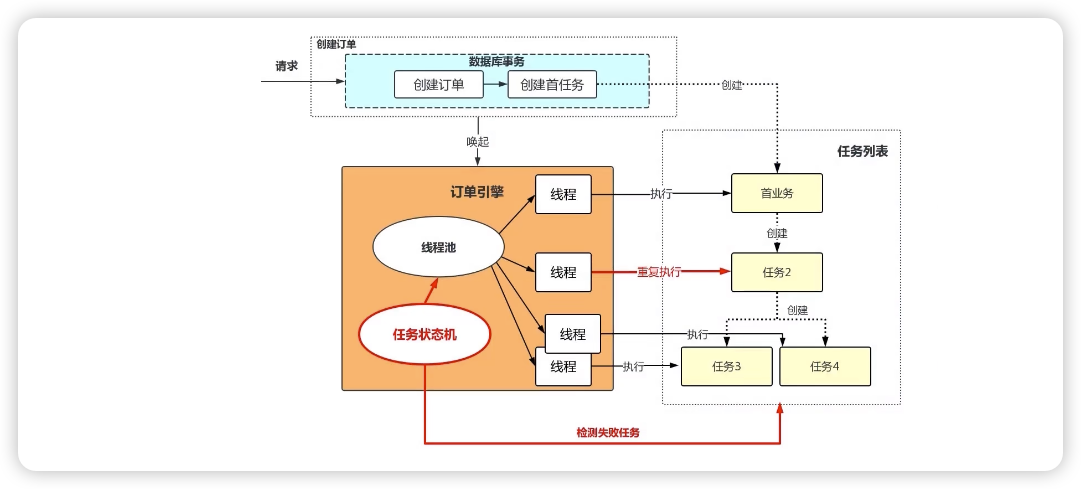
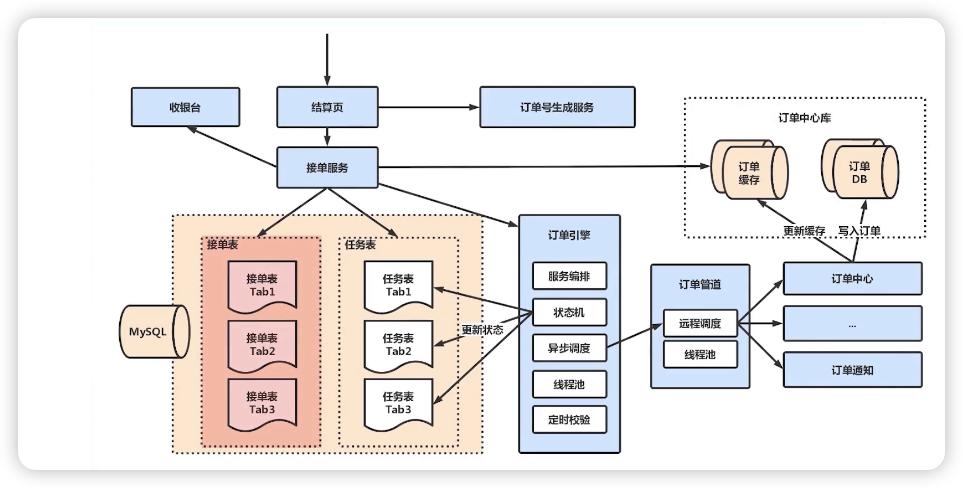
九:分布式架构开发时N点血的教训
1:分布式架构的问题
-
以往单体应用是在单机中进行进程内通信,通信稳定性相当好。但是打散为分布式系统后,变为进程间通信,往往这个过程还伴随着跨设备的网络访问,架构师在设计时必须考虑上下游系统因为网络因素无法通信的情况,要假设网络是不可靠的,并设计微服务在网络异常时也能进行符合预期的异常处理。以支付模块为例,用户支付成功后系统自动调用短信服务向用户手机发送“订单支付成功"的消息,此时架构师就必须假设短信服务在服务或者网络不可用时不会影响到订单业务的正常执行。
-
第二点,相比传统单体架构进程内通信,跨进程、跨网络的微服务通信在网络传输与消息序列化带来的延迟是不可被忽略的,尤其是在五个以上微服务间消息调用时,因为网络延迟对于实时系统的影响是是很大的。早些年我和一个军事院校合作了一个雷达仿真训练的系统,因为要模拟”导弹打飞机"的场景,在计算飞行轨道时1毫秒的响应增加都可以会影响到最终的结果,显然这类系统采用分布式设计就不再合适。
-
第三点,运维成本会直线上升,早期单体应用因为结构简单,规模也较小,发版时通常面对几台服务器部署几个Java文件就可以了。同时,应用的交付周期也是以周甚至月为单位,此时硬件设备成本与运维人员技术要求都比较低,采用手动部署即可满足要求。而对于微服务架构而言,每一个服务都是可独立运行、独立部署、独立维护的业务单元,再加上互联网时代用户需求的不断变化以及市场的不稳定因素,运维人员每天面对成百上干台服务器发布几十次已是家常便饭,传统手动部署显然已经无法满足互联网的快速变化。
-
第四点,组织架构层面的调整,微服务不但是一种架构风格,同样也是一种软件组织模型,以往软件公司会按照职能划分,如:研发、测试、运维部门进行独立管理考核,而在微服务的实施过程中,以业务模块进行划分团队,每一个团队是内聚的,要求可以独立完成从调研到发版的全流程,尽量减少对外界的依赖。如何将传统的职能团队调整为按业务划分组织架构,同样是对管理者的巨大挑战,要知道人的思想比架构更难改变。
-
第五点,服务间的集成测试变得举步维艰,传统单体架构集成测试是将不同的模块按业务流程进行组合,在进程内验证每一种可能性下其模块间协作是否符合预期即可。但对于微服务而言,系统被拆解为很多独立运行的单元,服务件采用接口进行网络通信。要获取准确的测试结果,必须搭建完整的微服务环境,光这一项工作就有很大的工作量。同时,因为是跨网络通信,网络延迟、超时、带宽、数据量等因素都将影响最终结果,测试结果易产生偏差。
2:经验优化
第一点,微服务的划分原则。将已有系统拆分为多个微姐服务,本就没有统一的标准。总结出几点通用原则:
-
单一职责原则,每一个微服务只做好一件事,体现出“高内聚、低耦合”,尽量减少对外界环境的依赖。
-
服务依赖原则,避免服务间的循环引用,在设计时就要对服务进行分级,例如区分核心服务与非核心服务。例如订单服务与短信服务,显然短信服务是非核心服务,服务间调用要遵循“核心服务“到“非核心服务”,不允许出现反向调用。同时,对于核心服务要做好保护,避免非核心服务出现问题影响核心服务的正常运行。
-
Two Pizz原则,就是说让团队保持在两个比萨能让队员吃饱的小规模的慨念。团队要小到让每个成员都能做出显著的贡献,并且相互依赖,有共同目标,以及统一的成功标准。一个微服务团队应涵盖从需求到发布运维的完整生命周期,使团队内部便可以解决大部分任务,从人数上4 ~ 6人是比较理想的规模。
第二点,为每一个微服务的模块明确使命,这里推荐一套标准的微服务叙述模板,集中体现“只做好一件事的原则”
- xxx微服务用来在出现痛点场景的情况下,解决现有的xx问题,从而达到了xxx的效果,提升了微服务的价值
- 商品检索微服务用来在商品数据全量多维度组合查询的情况下,解决了MySQL数据库全表扫描查询慢的问题,从而让查询相应减低到50ms以下,有效的提升了用户的体验。
第三点,微服务确保独立的数据存储,数据是任何系统最重要的资产。合适的服务选择合适的数据库存储
第四点,聚合化模式,暴露统一的聚合流程
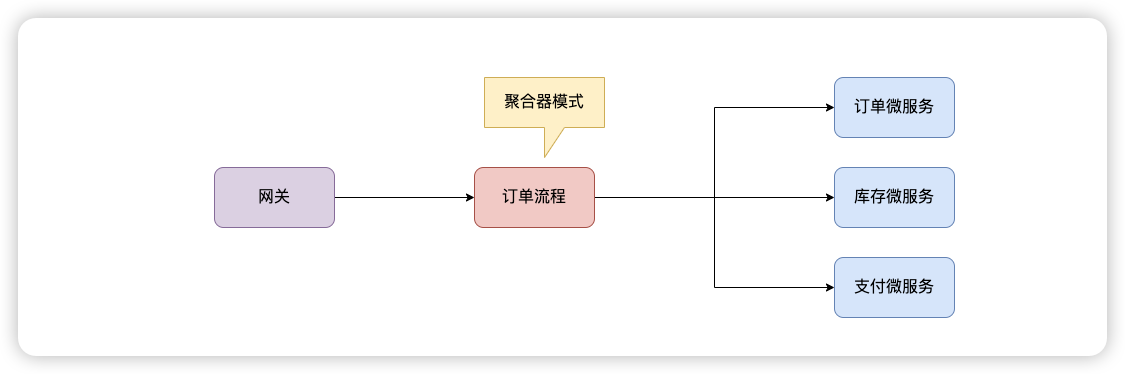
第五点,务实而不要强行上微服务
十:缓存一致性如何保障
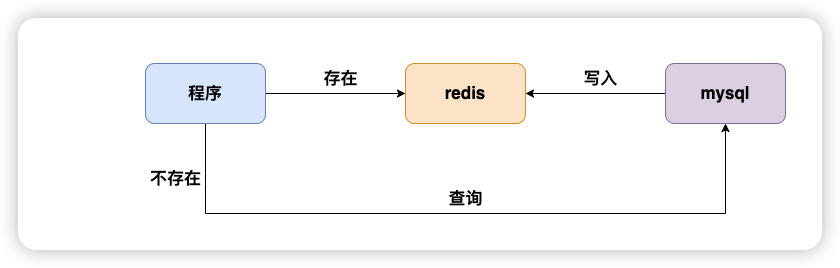
任何情况下都不要考虑更新缓存
因为会有并发问题:
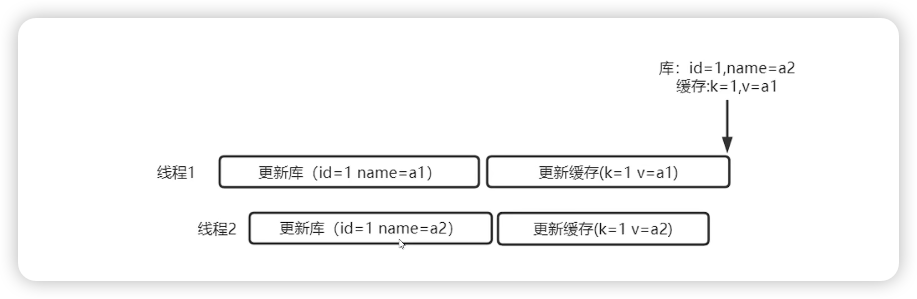
cache aside pattern -> 先写库,再删除缓存
-
要保证缓存和数据库的强一致性,最好的办法就是加入分布式锁,但是那样并发性能完蛋了
-
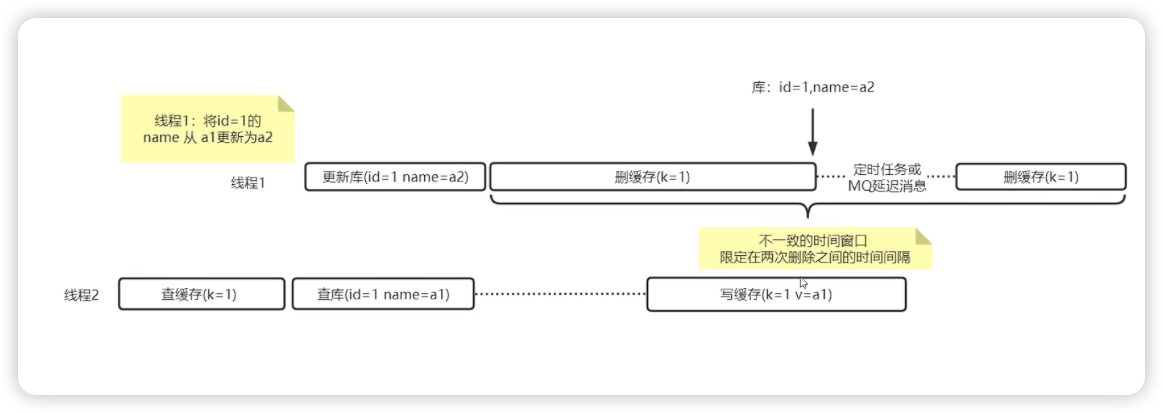
”cache aside pattern + 延迟双删“是在无锁方案下尽可能的减少不一致的手段,是AP模式下BASE的一种技术

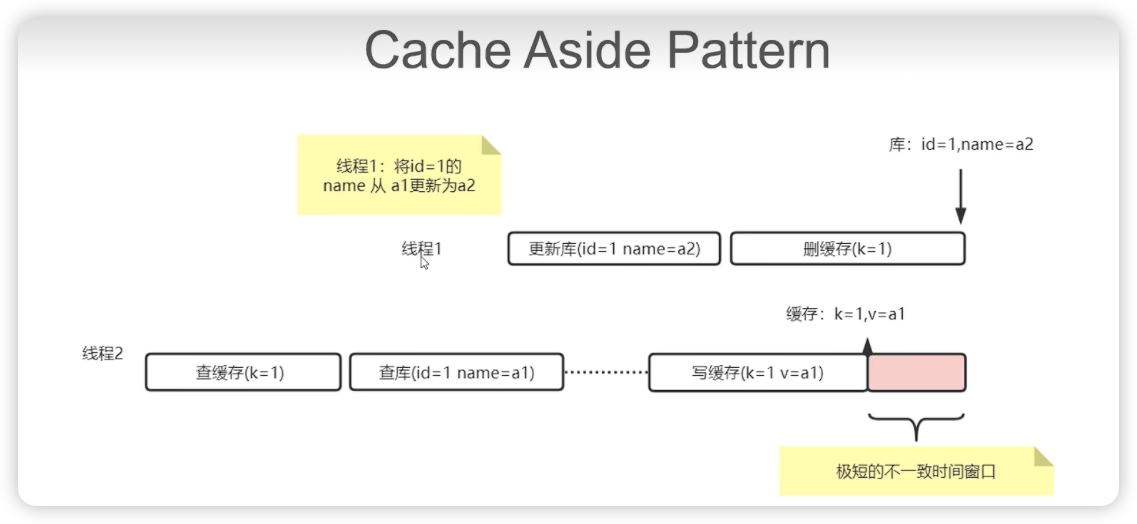
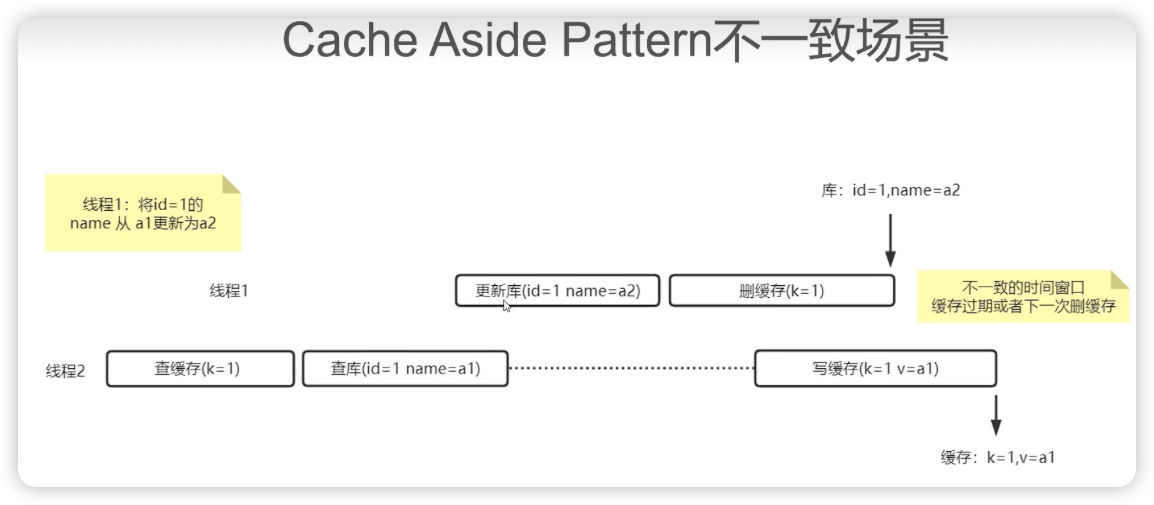
延迟双删

















 1991
1991

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









