







网络编程的无冕之王-Netty
Netty在Java网络编程中的地位,好比JavaEE中的Spring。下面这些应用都是基于Netty构建的:
- Spring5 WebFlux
- ES 搜索引擎中间件
- RocketMQ 消息中间件
- gRPC RPC框架
- Zookeeper 分布式协调
- Dobbo 分布式框架
- Hadoop 分布式文件系统
- Storm 大数据实时计算
- Spark 大数据离线计算
一:快速入门
Netty框架,其实这个框架是基于Java原生NIO技术的进一步封装,在其中对Java-NIO技术做了进一步增强
Netty作者充分结合了Reactor线程模型,将Netty变为了一个基于异步事件驱动的网络框架
Netty从诞生至今共发布了五个大版本,目前最常用的是4.x系列的版本
而至于为什么要对NIO再次封装,核心原因就是NIO设计的过于繁琐,还存在一系列的安全隐患,因此Netty横空出世
1:Hello Netty
先引入netty依赖
<dependency>
<groupId>io.netty</groupId>
<artifactId>netty-all</artifactId>
<version>4.1.43.Final</version>
</dependency>
server端编写
package com.cui.mynetty.hello;
import io.netty.bootstrap.ServerBootstrap;
import io.netty.channel.*;
import io.netty.channel.nio.NioEventLoopGroup;
import io.netty.channel.socket.nio.NioServerSocketChannel;
import io.netty.channel.socket.nio.NioSocketChannel;
import io.netty.handler.codec.string.StringDecoder;
import io.netty.util.CharsetUtil;
/**
* @author cui haida
* 2025/2/21
*/
public class HelloNettyServer {
public static void main(String[] args) {
// 创建两个事件循环组
EventLoopGroup bossGroup = new NioEventLoopGroup();
EventLoopGroup workerGroup = new NioEventLoopGroup();
// 创建启动器
ServerBootstrap serverBootstrap = new ServerBootstrap();
try {
// 前面创建的两个EventLoopGroup绑定在server上
serverBootstrap.group(bossGroup, workerGroup)
// 指定服务端的通道是Nio类型的
.channel(NioServerSocketChannel.class)
// 为到来的客户端Socket添加处理器
.childHandler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel nioSocketChannel) throws Exception {
// 添加一个字符解码处理器:对客户端的数据解码
nioSocketChannel.pipeline().addLast(new StringDecoder(CharsetUtil.UTF_8));
// 添加一个入站处理器,对收到的数据进行处理
nioSocketChannel.pipeline().addLast(
new SimpleChannelInboundHandler<String>() {
// 读取事件的回调方法
@Override
protected void channelRead0(ChannelHandlerContext ctx, String msg) {
System.out.println("收到客户端信息:" + msg);
}
});
}
});
// 为当前服务端绑定IP与端口地址(sync是同步阻塞至连接成功为止)
ChannelFuture cf = serverBootstrap.bind("127.0.0.1", 8080).sync();
// 关闭服务端的方法(之后不会在这里关闭)
cf.channel().closeFuture().sync();
} catch (Exception e) {
e.printStackTrace();
} finally {
// 关闭两个事件循环组
bossGroup.shutdownGracefully();
workerGroup.shutdownGracefully();
}
}
}
编写客户端
package com.cui.mynetty.hello;
import io.netty.bootstrap.Bootstrap;
import io.netty.channel.ChannelFuture;
import io.netty.channel.ChannelInitializer;
import io.netty.channel.nio.NioEventLoopGroup;
import io.netty.channel.socket.SocketChannel;
import io.netty.channel.socket.nio.NioSocketChannel;
import io.netty.handler.codec.string.StringEncoder;
import io.netty.util.CharsetUtil;
/**
* @author cui haida
* 2025/2/21
*/
public class HelloNettyClient {
public static void main(String[] args) {
// 创建一个事件循环组,由于无需处理连接事件,所以只需要创建一个EventLoopGroup
NioEventLoopGroup worker = new NioEventLoopGroup();
// 创建一个客户端启动器
Bootstrap client = new Bootstrap();
try {
// 将事件循环组worker绑定到客户端上
client.group(worker)
// 指定通道类型为nio
.channel(NioSocketChannel.class)
// 处理通道中的内容
.handler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel sc) {
// 添加一个编码处理器,对数据编码为UTF-8格式
sc.pipeline().addLast(new StringEncoder(CharsetUtil.UTF_8));
}
});
// 和指定的地址建立连接
ChannelFuture cf = client.connect("127.0.0.1", 8080).sync();
// 连接成功后,就可以发送数据了
cf.channel().writeAndFlush("hello, 我是客户端");
} catch (Exception e) {
e.printStackTrace();
} finally {
worker.shutdownGracefully();
}
}
}
🎉 Netty是支持链式编程的一个框架,也就是如上述中的代码调用,所有的方法都可以一直用.连下去
先启动服务端,客户端启动之后可以发现客户端发送完成消息之后,完成关闭,服务端接受到消息并打印
二:Netty核心组件(重中之重)
1:启动器Bootstrap
这个和其他IO模型对比一下就清楚了:就是换了个叫法而已
| 对比项 | 服务端 | 客户端 |
|---|---|---|
| BIO | ServerSocket | Socket |
| NIO | ServerSocketChannel | SocketChannel |
| AIO | AsynchronousServerSocketChannel | AsynchronousSocketChannel |
| Netty | ServerBootstrap | Bootstrap |
2:事件组EventLoopGroup
2.1:事件循环本质
EventLoop这东西翻译过来就是事件循环的意思,可以理解成NIO中的Selector选择器,因为内部会维护一个Selector
然后由一条线程会循环处理Channel通道上发生的所有事件,所以每个EventLoop对象都可以看成一个单线程执行器。
EventLoopGroup可以将其理解成AIO中的AsynchronousChannelGroup,在AIO的AsynchronousChannelGroup中,需要手动指定一个线程池
然后AIO的所有客户端工作都会使用线程池中的线程进行管理
而Netty中的EventLoopGroup就类似于AIO-ACG这玩意儿,只不过不需要我们管理线程池了,而是Netty内部维护。
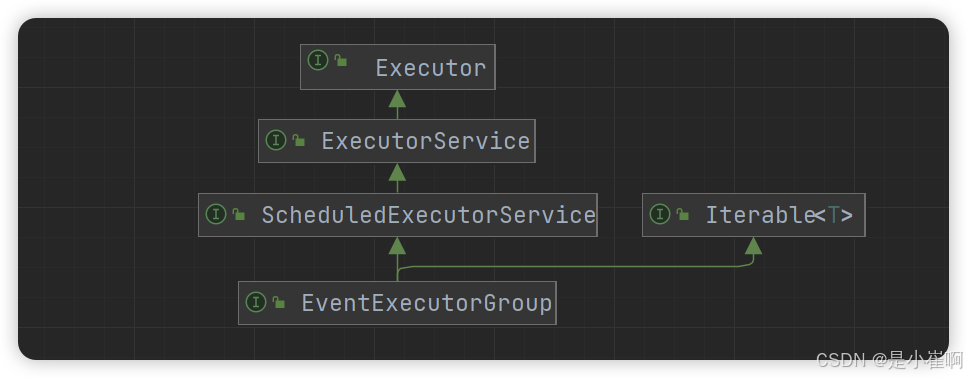
EventLoop/EventLoopGroup继承自JDK原生的定时线程池
那也就代表着:它拥有JDK线程池中所有提供的方法,同时也应该会支持执行异步任务、定时任务的功能
package com.cui.mynetty.hello;
import io.netty.channel.nio.NioEventLoopGroup;
import io.netty.util.concurrent.Future;
import java.util.concurrent.TimeUnit;
/**
* @author cui haida
* 2025/2/21
*/
public class EventLoopGroupTest {
public static void main(String[] args) {
// 创建一个线程组
NioEventLoopGroup threadPool = new NioEventLoopGroup();
// 递交Runnable执行普通的异步任务
threadPool.execute(() -> {
System.out.println("execute()方法提交的任务....");
});
// 递交Callable类型的有返回异步任务
Future<String> submit = threadPool.submit(() -> {
System.out.println("submit()方法提交的任务....");
return "我是执行结果噢!";
});
try {
System.out.println(submit.get());
} catch (Exception e) {
e.printStackTrace();
}
// 递交Callable类型的延时调度任务,3秒后执行
threadPool.schedule(()->{
System.out.println("schedule()方法提交的任务,三秒后执行....");
return "调度执行后我会返回噢!";
}, 3, TimeUnit.SECONDS);
// 递交Runnable类型的延迟间隔调度任务, 每隔一秒执行一次,3秒后开始执行
threadPool.scheduleAtFixedRate(()->{
System.out.println("scheduleAtFixedRate()方法提交的任务....");
}, 3, 1, TimeUnit.SECONDS);
}
}
除了线程池之外,还提供了一些其他的方法:【了解一下即可,这三个方法只在netty源码中用到】
- EventLoop.inEventLoop(Thread):判断一个线程是否属于当前EventLoop。
- EventLoop.parent():判断当前EventLoop属于哪一个事件循环组。
- EventLoopGroup.next():获取当前事件组中的下一个EventLoop(线程)。
2.2:boss组和worker组
为啥在服务端一般都搞两个NioEventLoopGroup?一个不可以吗?
其实也是可以的,但定义两个组的好处在于:可以让Group中的每个EventLoop分工更加明确
不同的Group分别处理不同类型的事件,各司其职。
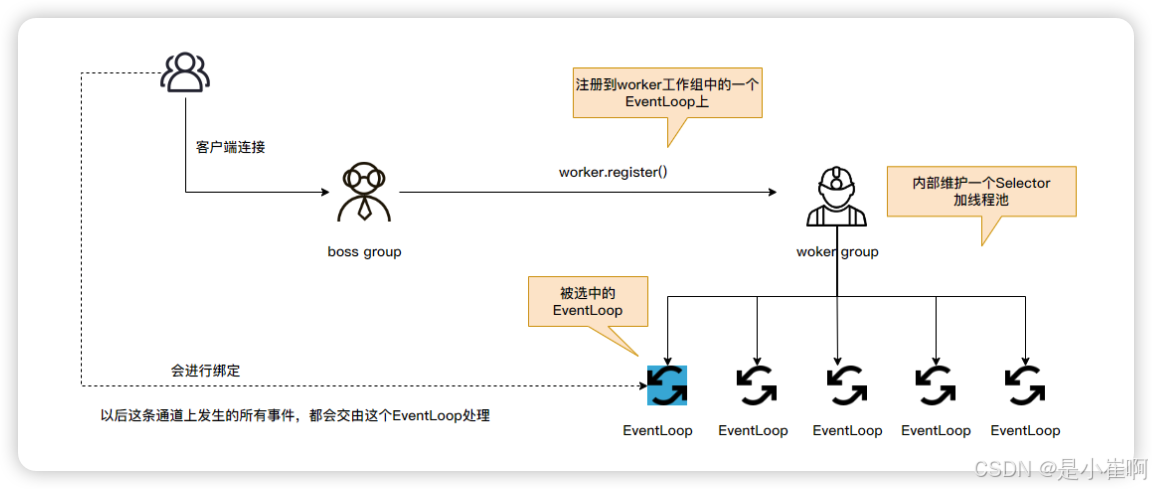
其中boss主要负责客户端的连接事件,而worker大多数情况下负责处理客户端的IO读写事件 - Reactor模型。
当客户端的SocketChannel连接到来时,首先会将这个注册事件的工作交给boss处理
boss会调用worker.register()方法,将这条客户端连接注册到worker工作组中的一个EventLoop上。
🎉 将一个Socket连接注册到一个EventLoop上之后,这个客户端连接则会和这个EventLoop绑定,以后这条通道上发生的所有事件,都会交由这个EventLoop处理
2.3:特殊处理器特殊处理一下
除开可以根据事件类型划分Group之外,也可以根据为每个处理器划分不同的事件组,如下:
// 创建EventLoopGroup和JDK原生的线程池一样,可以指定线程数量
EventLoopGroup extra = new NioEventLoopGroup(2); // 指定两个线程,这个事件组专门处理耗时长的处理器
sc.pipeline().addLast(extra, new xxxChannelHandler()); // 将使用extra对特殊处理器特殊处理
一个连接注册到EventLoop,之后所有的工作都会由这个EventLoop处理,而一个EventLoop又有可能同时管理多个连接
因此假设一条连接上的某个处理器,执行过程非常耗时,此时必然就会影响到这个EventLoop管理的其他连接
因此对于一些较为耗时的Handler,可以专门指派给一个额外的extra事件组处理,这样就不会影响到所管理的其他连接
🎉 当然,这个功能其实也略微有些鸡肋,一般多个Handler之间都会存在耦合关系,下一个Handler需要依赖上一个Handler的处理结果执行,因此也很难拆出来单独放到另一个事件组中执行。
2.4:现实对比
所以,EventLoop可以理解成有一条线程专门维护的Selector选择器,而EventLoopGroup则可以理解成一个有序的定时调度线程池,负责管理所有的EventLoop。
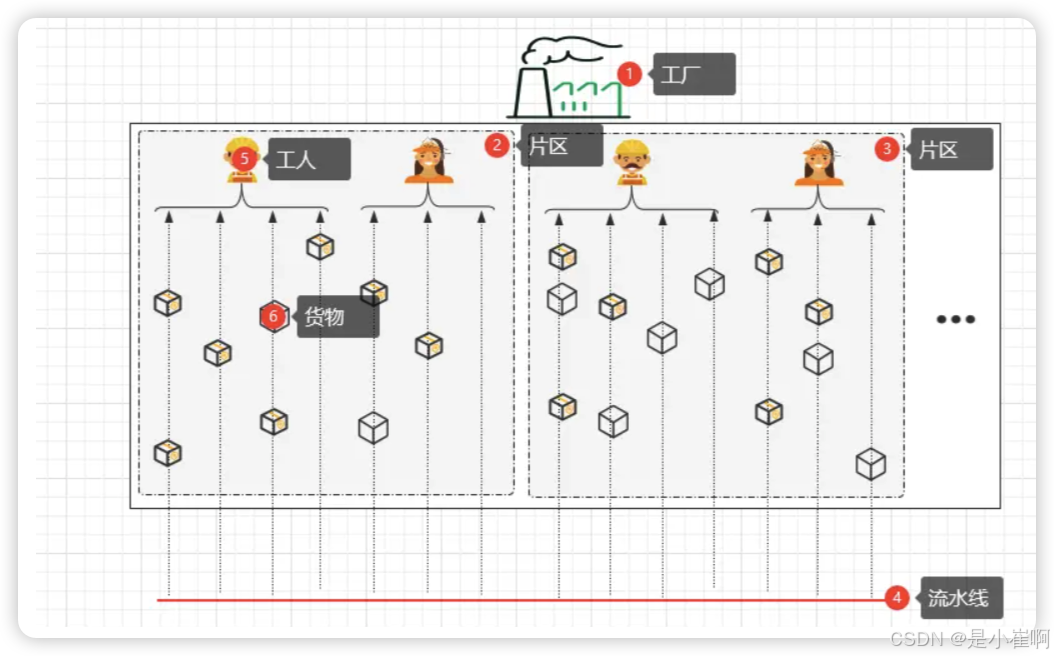
假设现在有个工厂(ServerBootstrap),其中分为了不同的片区(EventLoopGroup)
一个片区中有很多条流水线(SocketChannel),由每个工人(EventLoop)负责一部分流水线的作业。
开始工作后,流水线的传输带会源源不断的将货物传递过来,这些货物最终会等待工人进行加工(加工动作=处理通道上发生的事件)。
3:通道加强版ChannelFuture
3.1:通道类型
首先来看看通道类型,Netty根据不同的多路复用函数,分别拓展出了不同的通道类型:
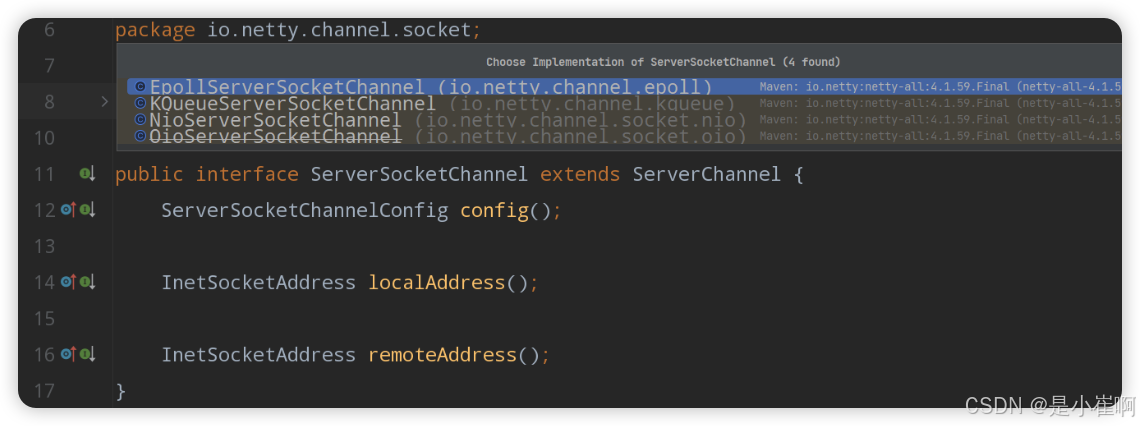
- NioServerSocketChannel:通用的NIO通道模型,也是Netty的默认通道。
- EpollServerSocketChannel:对应Linux系统下的epoll多路复用函数。
- KQueueServerSocketChannel:对应Mac系统下的kqueue多路复用函数。
- OioServerSocketChannel:对应原本的BIO模型,用的较少,一般用原生的。
3.2:Netty是如何增强的
增强的方面主要是支持了异步,但并非Future那种伪异步,而是更加的类似于CompletableFuture,支持异步回调处理结果
// 客户端连接代码
Bootstrap client = new Bootstrap();
client.connect("127.0.0.1", 8888);
这个connect()连接方法,本质上是一个异步方法,返回的并不是Channel对象,而是一个ChannelFuture对象
public ChannelFuture connect(String inetHost, int inetPort) {
return this.connect(InetSocketAddress.createUnresolved(inetHost, inetPort);
}
在Netty的机制中,绑定bind()/连接connect()工作都是异步的
因此如果要用Netty创建一个客户端连接,为了确保连接建立成功后再操作,通常情况下都会再调用.sync()方法同步阻塞
直到连接建立成功后再使用通道写入数据
// 和指定的地址建立连接
ChannelFuture cf = client.connect("127.0.0.1", 8080).sync();
// 连接成功后,就可以发送数据了
cf.channel().writeAndFlush("hello, 我是客户端");
上述这种方式能够确保连接建立成功后再写数据,当然也可以用回调的方式保证异步性
ChannelFuture cf = client.connect("127.0.0.1", 8888);
// 编写回调逻辑实现全过程的异步操作
cf.addListener((ChannelFutureListener) cfl -> {
// 这里可以用cf,也可以用cfl,返回的都是同一个channel通道
cf.channel().writeAndFlush("...");
});
还可以优雅的异步关闭
// 异步关闭Channel通道
ChannelFuture closeCF = cf.channel().closeFuture();
// 通道关闭后,添加对应的回调函数
closeCF.addListener((ChannelFutureListener) cfl -> {
// 关闭前面创建的EventLoopGroup事件组,也可以在这里做其他善后工作
worker.shutdownGracefully();
});
3.3:所有的API都是异步的
为什么都设计成为异步的呢,这个可以参考医院挂号:
- 导诊处:先说明大致情况,导诊人员根据你的病理,指导你挂什么科的号。
- 挂号处:去到对应的病理科排队挂号(暂且不考虑缴费,假设网上缴挂号费)。
- 诊断室:跟着挂的号找到对应的科室,医生根据你的情况进行诊断。
- 化验处:从你身上提取一些标本,然后去到化验处等待化验结果。
- 缴费处:医生根据化验结果分析病情,然后给出具体的治疗方案,让你来缴费。
- 拿药/治疗处:交完相关的费用后,根据治疗方案进行拿药/治疗等处理措施。
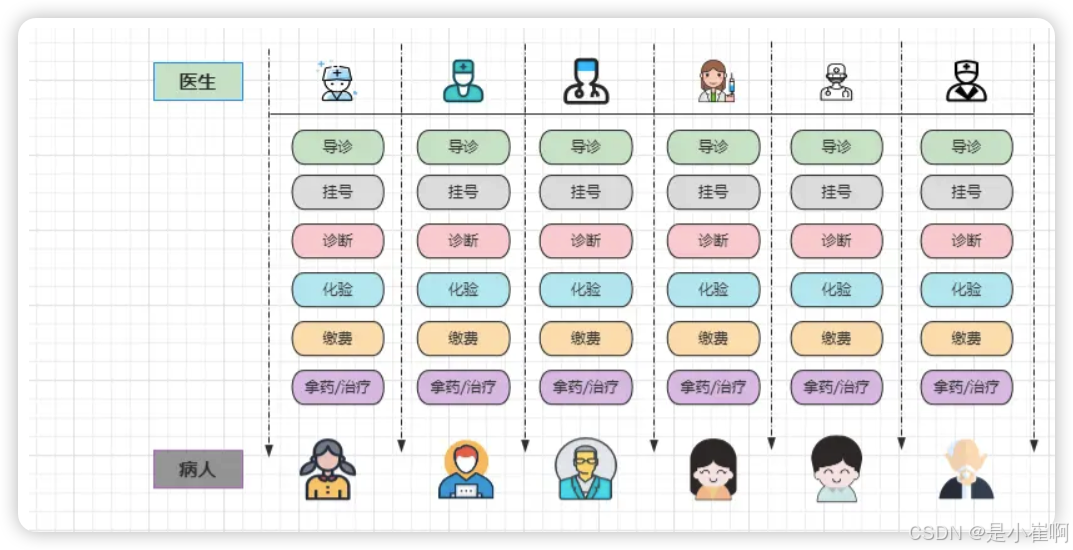
有上述这些步骤实际上并不奇怪,问题是在于每个步骤都分为了专门的科室处理,因此以上述流程为例,至少需要有六个医生提供服务,那么为什么不专门由这六位医生专门提供全系列服务呢
假设此时每个步骤平均要五分钟,一个病人的完整流程下来就需要半小时,而下一批预约看病的其他病人,则需要等待半小时后才能被受理,而把这些步骤拆开之后再来看看
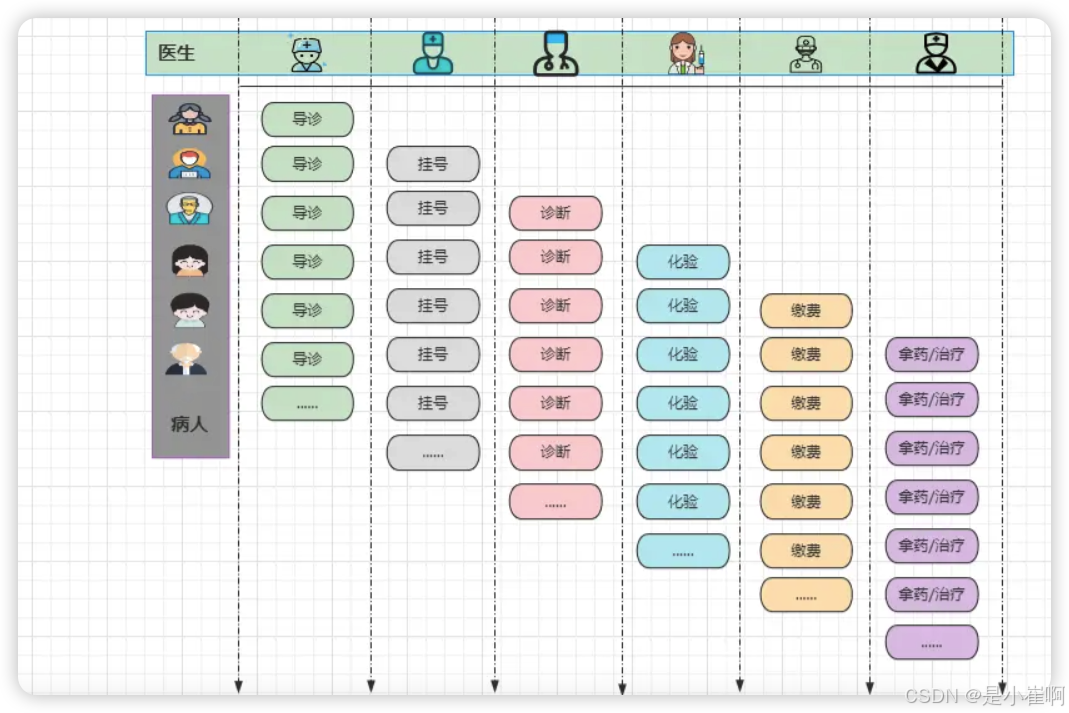
此时有六位医生各司其职,每位医生负责单一的工作
这样做的好处在于:每个挂号的病人只需要等待五分钟,就能够被受理,通过这种方式就将之前批次式看病,转变为了流水线式看病。
而Netty框架中的异步处理方式,也具备异曲同工之妙,将API的操作从批处理转变成了流式处理。
ChannelFuture, NettyFuture和JDK-Future的关系
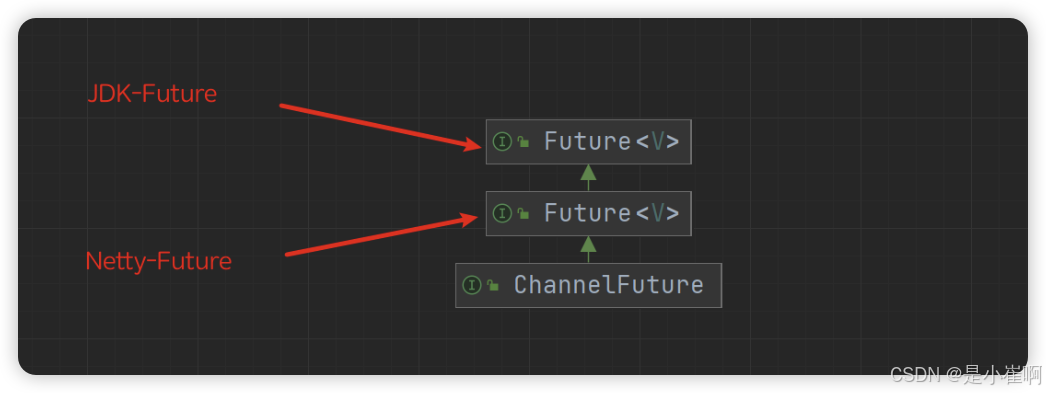
先来看看JDK-Future提供的核心方法:
| 方法名 | 方法作用 |
|---|---|
| isDone() | 判断当前异步任务是否结束 |
| cancel() | 取消当前异步任务 |
| isCancel() | 判断当前异步任务是否被取消 |
| get() | 阻塞等待当前异步任务执行完成 |
在JDK-Future接口中,想要获取一个异步任务的执行结果,此时只能调用get()方法
get()方法是一个阻塞方法,调用后会阻塞主线程直到任务结束为止,这显然依旧会导致异步变为同步执行,所以这种方式是一种“伪异步”
再来看看Netty-Future提供的核心方法:
| 方法名 | 方法作用 |
|---|---|
| getNow() | 非阻塞式获取任务结果,任务未执行完成时返回null |
| sync() | 阻塞等待至异步任务执行结束,执行出错时会抛出异常 |
| await() | 阻塞等待至异步任务执行结束,执行出错时不会抛出异常 |
| isSuccess() | 判断任务是否执行成功,如果为true代表执行成功 |
| cause() | 获取任务执行出错时的报错信息,如果执行未出错,则返回null |
| addLinstener() | 添加回调方法,异步任务执行完成后会主动执行回调方法中的代码 |
除开基本的Future接口外,Netty框架中还有一个Promise接口,该接口继承自Netty-Future接口:
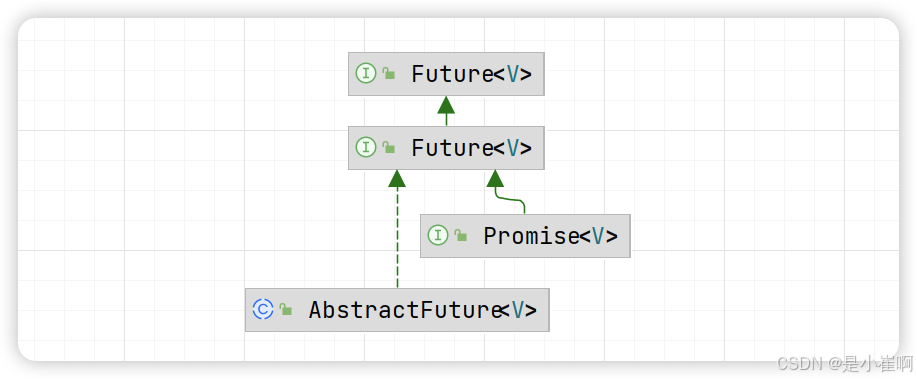
| 方法名 | 方法作用 |
|---|---|
| setSuccess() | 设置任务的执行状态为成功 |
| setFailure() | 设置任务的执行状态为失败 |
// 下面是三个Future的效果测试
package com.cui.commonboot.mynetty.hello;
import io.netty.channel.EventLoop;
import io.netty.channel.nio.NioEventLoopGroup;
import io.netty.util.concurrent.DefaultPromise;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* <p>
* 功能描述:
* </p>
*
* @author cui haida
* @date 2023/12/17/15:32
*/
public class FutureDemo {
// JDK_Future
public static void jdkFuture() throws Exception {
ExecutorService threadPool = Executors.newSingleThreadExecutor();
System.out.println("主线程:步骤①");
// 向线程池提交一个带有返回值的Callable任务
java.util.concurrent.Future<String> task =
threadPool.submit(() ->
"我是JDK-Future任务.....");
// 输出获取到的任务执行结果(阻塞式获取)
System.out.println(task.get());
System.out.println("主线程:步骤②");
// 关闭线程池
threadPool.shutdownNow();
}
// 测试一下netty-future
public static void nettyFuture() throws Exception {
System.out.println("--------Netty-Future测试--------");
// 创建一个Netty中的事件循环组(本质是线程池)
NioEventLoopGroup group = new NioEventLoopGroup();
EventLoop eventLoop = group.next(); // 拿到循环组的一个循环
System.out.println("主线程:步骤①");
// 向线程池中提交一个带有返回值的Callable任务
io.netty.util.concurrent.Future<String> task =
eventLoop.submit(() ->
"我是Netty-Future任务.....");
// 添加一个异步任务执行完成之后的回调方法
// 这个回调方法会在异步任务执行结束后调用,将获取任务结果的工作,放入到了回调方法中完成
// 此时会观测到,获取Netty-Future的执行结果并不会阻塞主线程
task.addListener(listenerTask ->
System.out.println(listenerTask.getNow()));
System.out.println("主线程:步骤②");
// 关闭事件组(线程池)
group.shutdownGracefully();
}
// 测试Netty-Promise的方法
public static void nettyPromise() throws Exception {
System.out.println("--------Netty-Promise测试--------");
// 创建一个Netty中的事件循环组(本质是线程池)
NioEventLoopGroup group = new NioEventLoopGroup();
EventLoop eventLoop = group.next();
// 主动创建一个传递异步任务结果的容器
DefaultPromise<String> promise = new DefaultPromise<>(eventLoop);
// 创建一条线程执行,往结果中添加数据
new Thread(() -> {
try {
// 主动抛出一个异常
int i = 100 / 0;
// 如果异步任务执行成功,向容器中添加数据
promise.setSuccess("我是Netty-Promise容器:执行成功!");
}catch (Throwable throwable){
// 如果任务执行失败,将异常信息放入容器中
promise.setFailure(throwable);
}
}).start();
// 输出容器中的任务结果
System.out.println(promise.get());
}
public static void main(String[] args) throws Exception {
jdkFuture();
nettyFuture();
nettyPromise();
}
}
4:通道处理器Handler
4.1:入站和出站
Handler可谓是整个Netty框架中最为重要的一部分
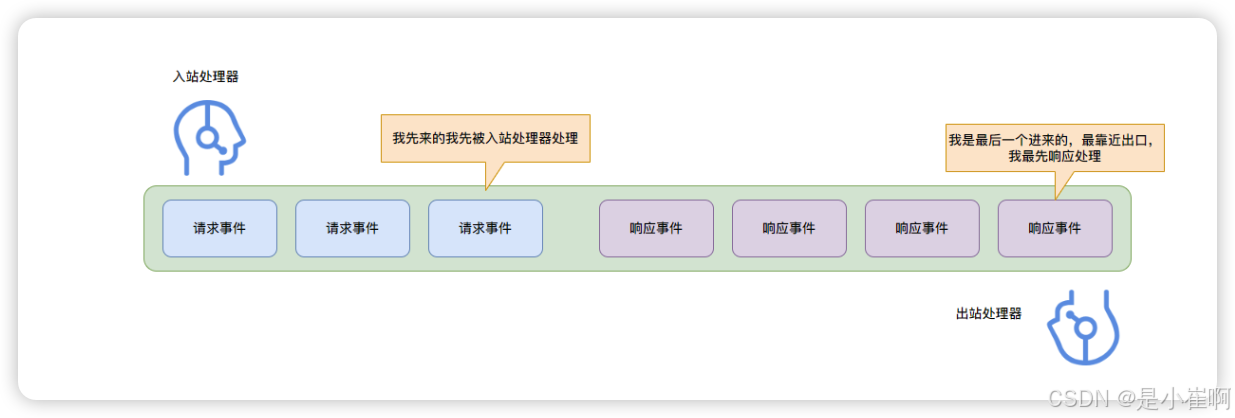
它的职责主要是用于处理Channel通道上的各种事件,所有的处理器都可被大体分为两类:
- 入站处理器:一般都是
ChannelInboundHandlerAdapter以及它的子类实现。 - 出站处理器:一般都是
ChannelOutboundHandlerAdapter以及它的子类实现。
所谓的入站即是指接收请求,反之,所谓的出站则是指返回响应
Netty中的入站处理器,会在客户端消息到来时被触发,而出站处理器则会在服务端返回数据时被触发
package com.cui.commonboot.mynetty.pipelineTest;
import io.netty.bootstrap.ServerBootstrap;
import io.netty.buffer.ByteBuf;
import io.netty.channel.*;
import io.netty.channel.nio.NioEventLoopGroup;
import io.netty.channel.socket.nio.NioServerSocketChannel;
import io.netty.channel.socket.nio.NioSocketChannel;
import java.net.InetSocketAddress;
/**
* <p>
* 功能描述:
* </p>
*
* @author cui haida
* @date 2023/12/17/16:51
*/
public class TestServer {
public static void main(String[] args) {
NioEventLoopGroup boss = new NioEventLoopGroup();
NioEventLoopGroup worker = new NioEventLoopGroup();
// 创建一个服务端启动器
ServerBootstrap server = new ServerBootstrap();
try {
server.group(boss, worker)
.channel(NioServerSocketChannel.class)
// 处理客户端消息,通过ChannelInitializer完成通道的初始化工作
.childHandler(new ChannelInitializer<NioSocketChannel>() {
@Override
protected void initChannel(NioSocketChannel ch) throws Exception {
ch.pipeline().addLast("in-first", new ChannelInboundHandlerAdapter() {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
System.out.println("这是第一个入站处理器...");
// 向下调用
super.channelRead(ctx, msg);
}
});
ch.pipeline().addLast("in-second", new ChannelInboundHandlerAdapter() {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
System.out.println("这是第二个入站处理器...");
// 向下调用
super.channelRead(ctx, msg);
}
});
ch.pipeline().addLast("in-third", new ChannelInboundHandlerAdapter() {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
System.out.println("这是第三个入站处理器...");
// 利用通道向客户端返回数据
ByteBuf resultMsg = ctx.channel().alloc().buffer();
resultMsg.writeBytes("111".getBytes());
ch.writeAndFlush(resultMsg);
// 乡下调用
super.channelRead(ctx, msg);
}
});
// 基于pipeline链表向通道上添加出站处理器
ch.pipeline().addLast("Out-A",new ChannelOutboundHandlerAdapter(){
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise)
throws Exception {
System.out.println("我是Out-A出站处理器...");
super.write(ctx, msg, promise);
}
});
ch.pipeline().addLast("Out-B",new ChannelOutboundHandlerAdapter(){
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise)
throws Exception {
System.out.println("我是Out-B出站处理器...");
super.write(ctx, msg, promise);
}
});
ch.pipeline().addLast("Out-C",new ChannelOutboundHandlerAdapter(){
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise)
throws Exception {
System.out.println("我是Out-C出站处理器...");
super.write(ctx, msg, promise);
}
});
}
});
server.bind(new InetSocketAddress("127.0.0.1", 8888));
} catch (Exception e) {
e.printStackTrace();
}
}
}
package com.cui.commonboot.mynetty.pipelineTest;
import io.netty.bootstrap.Bootstrap;
import io.netty.channel.ChannelFuture;
import io.netty.channel.ChannelInitializer;
import io.netty.channel.ChannelPipeline;
import io.netty.channel.nio.NioEventLoopGroup;
import io.netty.channel.socket.SocketChannel;
import io.netty.channel.socket.nio.NioServerSocketChannel;
import io.netty.channel.socket.nio.NioSocketChannel;
import io.netty.handler.codec.string.StringEncoder;
import io.netty.util.CharsetUtil;
/**
* <p>
* 功能描述:
* </p>
*
* @author cui haida
* @date 2023/12/17/16:58
*/
public class TestClient {
public static void main(String[] args) {
NioEventLoopGroup nlg = new NioEventLoopGroup();
Bootstrap client = new Bootstrap();
try {
client.group(nlg)
.channel(NioSocketChannel.class)
// 初始化通道,添加一个UTF-8编码器,就是消息进入通道之前都要进行UTF-8编码
.handler(new ChannelInitializer<SocketChannel>() {
@Override
protected void initChannel(SocketChannel sc) throws Exception {
// 添加一个编码处理器,对数据编码为UTF-8格式
ChannelPipeline pipeline = sc.pipeline();
pipeline.addLast(new StringEncoder(CharsetUtil.UTF_8));
}
});
// 绑定ip和端口
ChannelFuture cf = client.connect("127.0.0.1", 8888).sync();
System.out.println("正在向服务端发送信息......");
// 将消息写入通道
String msg = "你好,我是客户端";
cf.channel().writeAndFlush(msg);
} catch (Exception e) {
e.printStackTrace();
} finally {
nlg.shutdownGracefully();
}
}
}
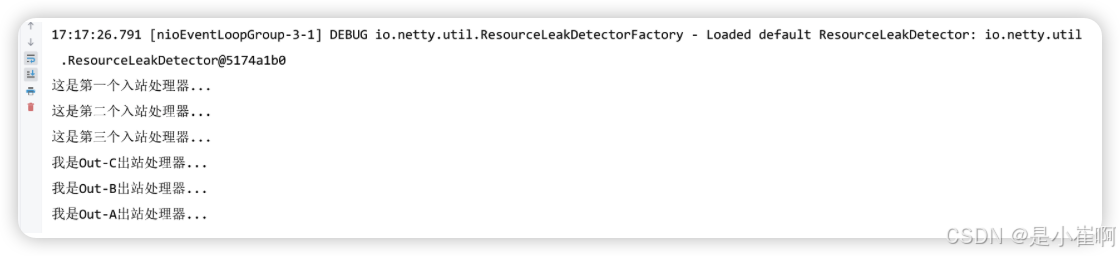
- 入站处理器的执行顺序,会按照添加的顺序执行,两个过滤器之间,依靠super.channelRead(ctx, msg);这行代码来实现向下调用的逻辑,这和之前Servlet中的过滤器相差无几;
- 而出站处理器的执行顺序和添加的顺序正好相反,这其实是因为pipeline的原因。
除了上述的方法, 入站和出站还有很多方法可以被重写
// ========== 入站 ============
// 会在当前Channel通道注册到选择器时触发(与EventLoop绑定时触发)
public void channelRegistered(ChannelHandlerContext ctx) ...
// 会在选择器移除当前Channel通道时触发(与EventLoop解除绑定时触发)
public void channelUnregistered(ChannelHandlerContext ctx) ...
// 会在通道准备就绪后触发(Pipeline处理器添加完成、绑定EventLoop后触发)
public void channelActive(ChannelHandlerContext ctx) ...
// 会在通道关闭时触发
public void channelInactive(ChannelHandlerContext ctx) ...
// 会在收到客户端数据时触发(每当有数据时都会调用该方法,表示有数据可读)
public void channelRead(ChannelHandlerContext ctx, Object msg) ...
// 会在一次数据读取完成后触发
public void channelReadComplete(ChannelHandlerContext ctx) ...
// 当通道上的某个事件被触发时,这个方法会被调用
public void userEventTriggered(ChannelHandlerContext ctx, Object evt) ...
// 当通道的可写状态发生改变时被调用(一般在发送缓冲区超出限制时调用)
public void channelWritabilityChanged(ChannelHandlerContext ctx) ...
// 当通道在读取过程中抛出异常时,当前方法会被触发调用
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) ...
// ======== 出站 ===========
// 当通道调用bind()方法时触发(当Channel绑定端口地址时被调用,一般用于客户端通道)
public void bind(...) ...
// 当通道调用connect()方法,连接到远程节点/服务端时触发(一般也用于客户端通道)
public void connect(...) ...
// 当客户端通道调用disconnect()方法,与服务端断开连接时触发
public void disconnect(...) ...
// 当客户端通道调用close()方法,关闭连接时触发
public void close(...) ...
// 当通道与EventLoop解除绑定时触发
public void deregister(...) ...
// 当通道中读取多次数据时被调用触发
public void read(...) ...
// 当通道中写入数据时触发
public void write(...) ...
// 当通道中的数据被Flush给对端节点时调用
public void flush(...) ...
对于出站/入站处理器的这些其他方法/事件,可根据业务的不同,选择重写不同的方法
其中每个不同的方法,其触发时机也不同,因此可以在适当的位置重写方法,作为业务代码的切入点。
4.2:pipeline处理链表
一个处理器被称为Handler,而一个Handler添加到一个通道上之后,则被称之为ChannelHandler
而一个通道上的所有ChannelHandler全部连接起来,则被称之为ChannelPipeline处理器链表。
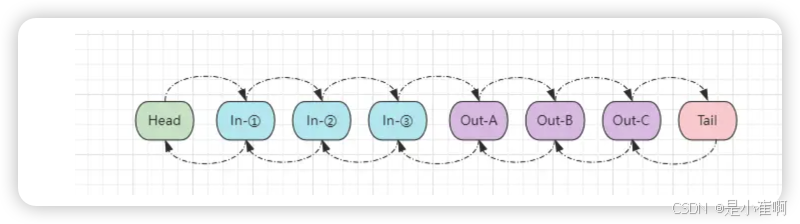
pipeline本质上是一个双向链表,同时具备head、tail头尾节点
每当调用pipeline.addLast()方法添加一个处理器时,就会将处理器封装成一个节点,然后加入pipeline链表中:
- 当接收到客户端的数据时,Netty会从Head节点开始依次往后执行所有入站处理器。
- 而当服务端返回数据时,Netty会从Tail节点开始依次向前执行所有入站处理器。【这也是为什么出站的处理顺序和添加顺序相反】
4.3:自定义出入站处理器
在实际的开发中,通常pipeline.addLast并不会直接new接口,而是自己定义处理器类,然后继承对应的父类
package com.cui.commonboot.mynetty.pipelineTest;
import io.netty.channel.ChannelHandlerContext;
import io.netty.channel.ChannelInboundHandlerAdapter;
/**
* <p>
* 功能描述:自定义入站处理器
* </p>
*
* @author cui haida
* @date 2023/12/18/15:35
*/
public class MyHandle extends ChannelInboundHandlerAdapter {
public MyHandle() {
super();
}
@Override
public void channelRead(ChannelHandlerContext ctx, Object mes) throws Exception {
System.out.println("请在这里处理入站msg的核心逻辑");
System.out.println("msg is: " + mes);
super.channelRead(ctx, mes);
}
}
// 自定义handle
ch.pipeline().addLast("my-in", new MyHandle());
自定义出站处理器同理,只要继承ChannelOutboundHandlerAdapter然后重写write方法即可
package com.cui.commonboot.mynetty.pipelineTest;
import io.netty.channel.ChannelHandlerContext;
import io.netty.channel.ChannelOutboundHandlerAdapter;
import io.netty.channel.ChannelPromise;
/**
* <p>
* 功能描述:自定义出站处理器
* </p>
*
* @author cui haida
* @date 2023/12/18/16:36
*/
public class MyOutHandler extends ChannelOutboundHandlerAdapter {
public MyOutHandler() {
super();
}
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
// 在这里实现自定义出站逻辑
super.write(ctx, msg, promise);
}
}
5:重构后的缓冲区ByteBuf
和原生的NIO中的ByteBuffer一样,ByteBuf也是用于服务端和客户端之间传输数据的容器,同时也支持堆内存和本地内存两种方式创建
// 使用堆内存的方式创建ByteBuf
// 基于堆内存创建的ByteBuf对象会受到GC机制管理,在发生GC时需要来回移动Buffer对象
ByteBufAllocator.DEFAULT.heapBuffer(cap);
// 使用本地内存的方式创建ByteBuf
ByteBufAllocator.DEFAULT.directBuffer(cap);
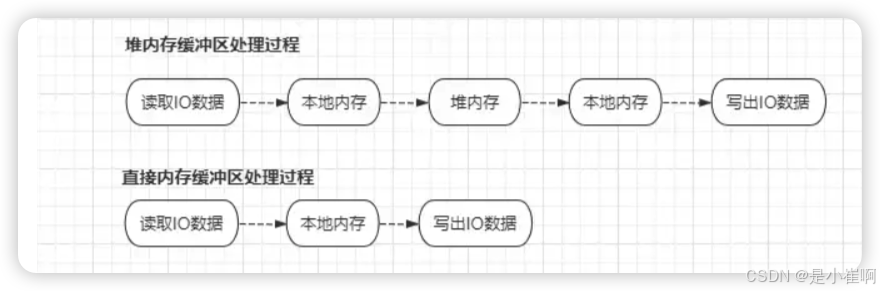
- 堆内存因为直接受到JVM管理,所以在Java程序中创建时,分配效率较高,但读写效率低。
- 本地内存因为OS可直接操作,所以读写效率高,但由于创建时,需要向OS额外申请,分配效率低。
5.1:ByteBuf池化技术
池化应该都不陌生,Java线程池、数据库连接池,这些都是池化思想的产物
一般系统中较为珍贵的资源,都会采用池化技术来缓存,以便于下次需要时可直接使用,而无需经过繁琐的创建过程
Netty默认会采用本地内存创建ByteBuf对象,而本地内存因为不是操作系统分配给Java程序使用的,所以基于本地内存创建对象时,则需要额外单独向OS申请,这个过程自然开销较大,在高并发情况下,频繁的创建、销毁ByteBuf对象,一方面会导致性能降低,同时还有可能造成OOM的风险【使用完没及时释放,内存未归还给OS的情况下会出现内存溢出】
而使用池化技术后,一方面能有效避免OOM问题产生,同时还可以省略等待创建缓冲区的时间
Netty中的池化技术是分平台的:Android系统默认会采用非池化技术,而其他系统,如Linux、Mac、Windows等会默认启用。(Netty4.1+)
4.1之前的版本默认会禁用池化技术。
如果你在某些平台下想自行决定是否开启池化,可通过下述参数控制:
-Dio.netty.allocator.type=unpooled:关闭池化技术。-Dio.netty.allocator.type=pooled:开启池化技术。
这两个参数直接通过JVM参数的形式,在启动Java程序时指定即可。
如果你想要查看自己创建的ByteBuf对象,是否使用了池化技术,可直接打印对象的Class即可
import io.netty.buffer.ByteBuf;
import io.netty.buffer.ByteBufAllocator;
/**
* @author cui haida
* 2025/2/24
*/
public class MyPool {
public static void main(String[] args) {
int cap = 16;
ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(cap);
System.out.println(buffer.getClass());
}
}
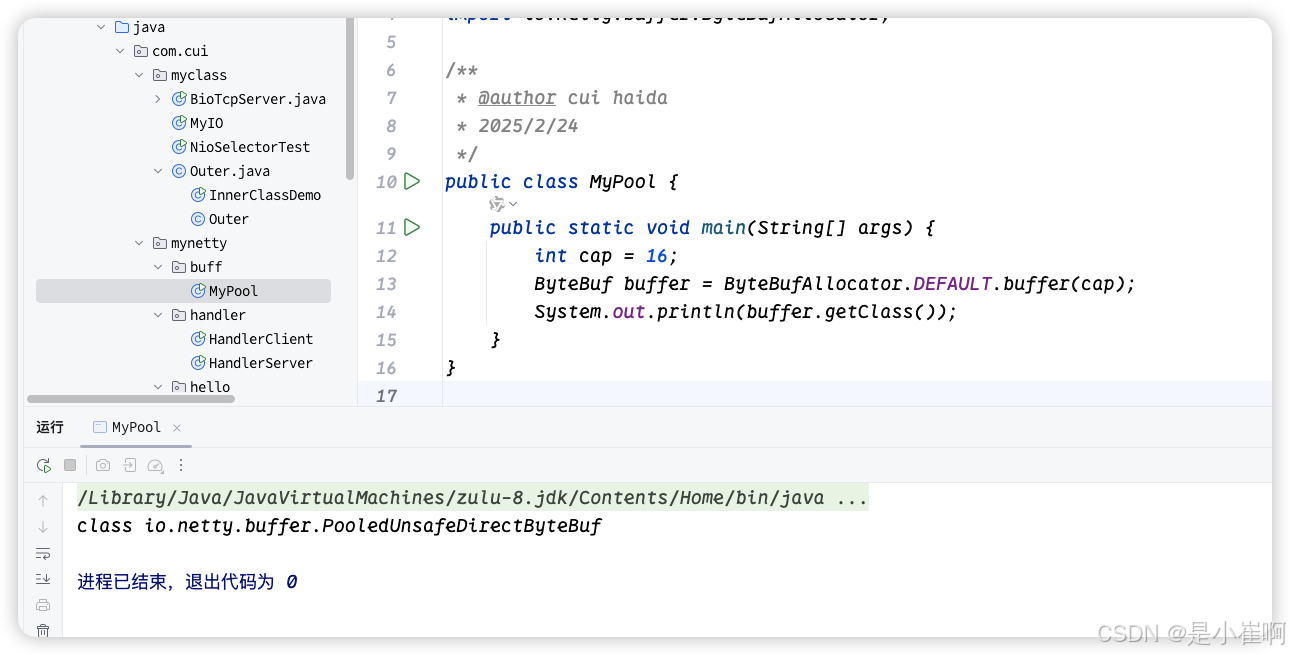
如果是以Pooled开头的类名,则表示当前ByteBuf对象使用池化技术,如若是以Unpooled开头的类名,则表示未使用池化技术。
5.2:动态扩容机制
在NIO的每个Buffer对象都拥有一根limit指针,这根指针用于控制读取/写入模式
因此在使用NIO-Buffer时,每次写完缓冲区后,都需要调用flip()方法来反转指针,以此来确保NIO-Buffer的正常读写。
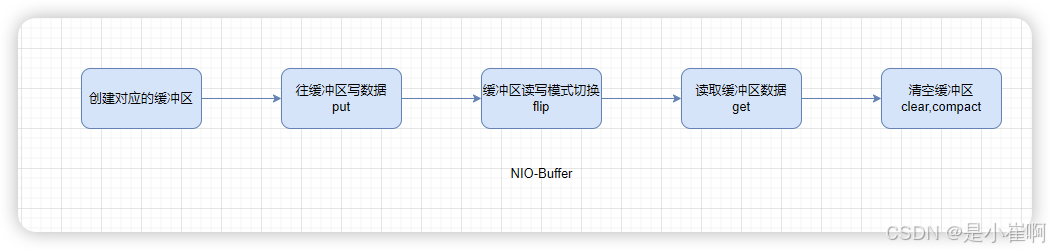
由于Java-NIO原生的Buffer设计的不合理,因此Netty中直接重构了整个缓冲区组件,在Netty-ByteBuf中,存在四个核心属性:
- initialCapacity:初始容量,创建缓冲区时指定的容量大小,默认为256字节。
- maxCapacity:最大容量,当初始容量不足以供给使用时,ByteBuf的最大扩容限制。
- readerIndex:取指针,默认为0,当读取一部分数据时,指针会随之移动。
- writerIndex:写入指针,默认为0,当写入一部分数据时,指针会随之移动。
这四个属性相对于NIO的Buffer有主要两点改进:
- 将原本一根指针变为了两根,分别对应读/写操作,这样就保障了使用ByteBuf时,无需每次读写数据时手动翻转模式。
- 加入了一个最大容量限制,在创建的ByteBuf无法存下数据时,允许在最大容量的范围内,对ByteBuf进行自动扩容
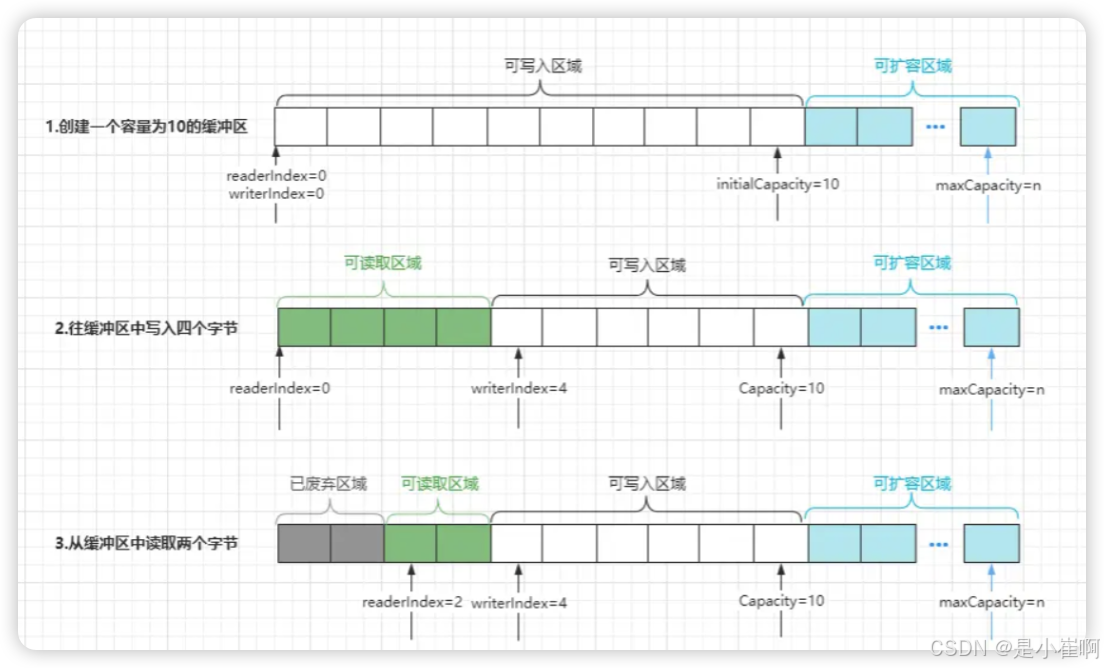
在真正使用过程中,一个ByteBuf会被分为四个区域:
- 已废弃区域:这是指已经被读取过的数据区域,因为其中的数据已被使用,所以属于废弃区域。
- 可读取区域:这主要是指被写入过数据,但还未读取的区域,这块区域的数据都可被读取使用。
- 可写入区域:这主要是指写入指针和容量之间的区域,意味着这块区域是可以被写入数据的。
- 可扩容区域:这主要是指容量和最大容量之间的区域,代表当前缓冲区可扩容的范围。
ByteBuf的主要实现位于AbstractByteBuf这个子类中
内部还有两根markedReaderIndex、markedWriterIndex标记指针,这两根指针就类似于NIO-Buffer中的mark指针
内部还有两根markedReaderIndex、markedWriterIndex标记指针,这两根指针就类似于NIO-Buffer中的mark指针
// 先根据Netty框架自带的格式化方法、Dump方法输出缓冲区数据
package com.cui.commonboot.mynetty.bytebuftest;
import io.netty.buffer.ByteBuf;
import static io.netty.buffer.ByteBufUtil.appendPrettyHexDump;
import static io.netty.util.internal.StringUtil.NEWLINE;
/**
* byteBuf 单元类
*/
public class ByteBufUtil {
/**
* log
* @param buffer 将buf的日志格式化打印一下
*/
public static void log(ByteBuf buffer) {
int length = buffer.readableBytes();
int rows = length / 16 + (length % 15 == 0 ? 0 : 1) + 4;
StringBuilder buf = new StringBuilder(rows * 80 * 2)
.append("read index:").append(buffer.readerIndex())
.append(" write index:").append(buffer.writerIndex())
.append(" capacity:").append(buffer.capacity())
.append(NEWLINE);
// 利用Netty框架自带的格式化方法、Dump方法输出缓冲区数据
appendPrettyHexDump(buf, buffer);
System.out.println(buf);
}
}
// 模拟扩容,开辟的初始空间大小是16,但是写入17个字符
package com.cui.commonboot.mynetty.bytebuftest;
import io.netty.buffer.ByteBuf;
import io.netty.buffer.ByteBufAllocator;
/**
* @author cui haida
* @date 2023/12/19/6:48
*/
public class MyTest {
public static void main(String[] args) {
// 申请一个初始空间为16的ByteBuffer
ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(16);
// 模拟扩容
StringBuilder sbd = new StringBuilder();
for (int i = 0; i < 17; i++) {
sbd.append("a");
}
// 将17个字节大小的数据写入缓冲区
buffer.writeBytes(sbd.toString().getBytes());
ByteBufUtil.log(buffer);
}
}
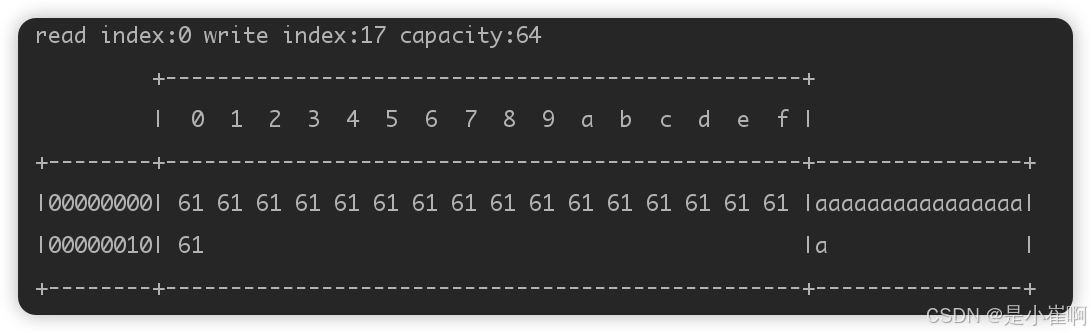
会发现容量自动扩展到了64,而这个Netty的美化输出,中间是字节值,后面是具体的值
5.3:读写API
NIO在Buffer读写API中还有一大问题就是它的Buffer是一个抽象类,不能直接使用,要实例化他的子类,但是其子类有十几种之多,但是一般常用的只有八大基本类型:ByteBuffer, CharBuffer, IntBuffer…
此时当你想要向缓冲区中写入不同类型的数据,要么得自己手动转换成Byte字节类型,要么得new一个对应的子实现,十分臃肿
而Netty的作者显然意识到了这点,因此并未提供多种数据类型的缓冲区,仅提供了ByteBuf这一种缓冲区,因为计算机上的所有数据资源,在底层本质上都是0、1形成的字节数据,所以只提供Byte类型的ByteBuf缓冲区就够了,毕竟它能够存储所有类型的数据,同时为了便于写入其他类型的数据,如Int、boolean、long…,Netty框架中也对外提供了相关的写入API
// Netty-ByteBuf抽象类
public abstract class ByteBuf implements ReferenceCounted, Comparable<ByteBuf> {
// 写入boolean数据的方法,内部使用一个字节表示,0=false、1=true
public abstract ByteBuf writeBoolean(boolean var1);
// 写入字节数据的方法
public abstract ByteBuf writeByte(int var1);
// 大端写入Short数据的方法
public abstract ByteBuf writeShort(int var1);
// 小端写入Short数据的方法
public abstract ByteBuf writeShortLE(int var1);
// 下述方法和写Short类型的方法仅类型不同,都区分了大小端
// medium
public abstract ByteBuf writeMedium(int var1);
public abstract ByteBuf writeMediumLE(int var1);
// int
public abstract ByteBuf writeInt(int var1);
public abstract ByteBuf writeIntLE(int var1);
// long
public abstract ByteBuf writeLong(long var1);
public abstract ByteBuf writeLongLE(long var1);
// char
public abstract ByteBuf writeChar(int var1);
// float
public abstract ByteBuf writeFloat(float var1);
public ByteBuf writeFloatLE(float value) {
return this.writeIntLE(Float.floatToRawIntBits(value));
}
// double
public abstract ByteBuf writeDouble(double var1);
public ByteBuf writeDoubleLE(double value) {
return this.writeLongLE(Double.doubleToRawLongBits(value));
}
// 将另一个ByteBuf对象写入到当前缓冲区
public abstract ByteBuf writeBytes(ByteBuf var1);
// 将另一个ByteBuf对象的前N个长度的数据,写入到当前缓冲区
public abstract ByteBuf writeBytes(ByteBuf var1, int var2);
// 将另一个ByteBuf对象的指定范围数据,写入到当前缓冲区
public abstract ByteBuf writeBytes(ByteBuf var1, int var2, int var3);
// 向缓冲区中写入一个字节数组
public abstract ByteBuf writeBytes(byte[] var1);
// 向缓冲区中写入一个字节数组中,指定范围的数据
public abstract ByteBuf writeBytes(byte[] var1, int var2, int var3);
// 将一个NIO的ByteBuffer数据写入到当前ByteBuf对象
public abstract ByteBuf writeBytes(ByteBuffer var1);
// 将一个输入流中的数据写入到当前缓冲区
public abstract int writeBytes(InputStream var1, int var2) throws IOException;
// 将一个NIO的ScatteringByteChannel通道中的数据写入当前缓冲区
public abstract int writeBytes(ScatteringByteChannel var1, int var2) throws IOException;
// 将一个NIO的文件通道中的数据写入当前缓冲区
public abstract int writeBytes(FileChannel var1, long var2, int var4) throws IOException;
// 将一个任意字符类型的数据写入缓冲区(CharSequence是所有字符类型的老大)
public abstract int writeCharSequence(CharSequence var1, Charset var2);
// 省略其他写入数据的API方法........
}
NIO是为不同数据类型提供了不同的实现类,而Netty则仅仅只是为不同类型,提供了不同的API方法
显然后者的做法更佳,因为整体的代码结构会更为优雅。
大端写入和小端写入
大小端写入是网络编程中的通用概念,因为网络数据传输过程中,所有的数据都是以二进制的字节格式传输的
所谓的大端(Big Endian)写入,是指先写高位,再写低位,高低位又是什么意思呢?
- 高位写入:指从前往后写,例如1这个数字,比特位形式为00000000 00000001。
- 低位写入:指从后往前写,依旧是1这个数字,比特位形式为00000001 00000000。
这里不了解的小伙伴又会疑惑:为啥高位写入时,1在最后面呀?这是因为要先写0,再写1的原因导致的。
而所谓的小端(Little Endian)写入,也就是指先写低位,再写高位。
默认情况下,网络通信会采用大端写入的模式。
读取API:read指针移动,get不移动
// 一系列read开头的读取方法,这种方式会改变读取指针(区分大小端)
public abstract boolean readBoolean();
public abstract byte readByte();
public abstract short readUnsignedByte();
// 其他read开头的方法结构也都是如此
public abstract xxx readXxx();
public abstract xxx readXxxLE();
// 省略其他的read方法.....
// 一系列get开头的读取方法,这种方式不会改变读取指针(区分大小端)
public abstract boolean getBoolean(int var1);
public abstract byte getByte(int var1);
public abstract short getUnsignedByte(int var1);
// 其他get开头的读取方法也都是如此结构
public abstract XXX getxxx(XXX xxx);
public abstract XXX getxxxLE(XXX xxx);
因为read开头的方法对改变读取指针,而读取指针之前的数据部分,都会被标记为废弃部分
这也就意味着通过read系列的方式读取一段数据后,会导致这些数据无法再次被读取到
package com.cui.commonboot.mynetty.bytebuftest;
import io.netty.buffer.ByteBuf;
import io.netty.buffer.ByteBufAllocator;
/**
* <p>
* 功能描述:
* </p>
*
* @author cui haida
* @date 2023/12/19/6:48
*/
public class MyTest {
public static void main(String[] args) {
// 分配一个初始容量为10的缓冲区
ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(10);
// 向缓冲区中写入10个字符(占位十个字节)
StringBuffer sb = new StringBuffer();
for (int i = 0; i < 10; i++) {
sb.append(i);
}
buffer.writeBytes(sb.toString().getBytes());
// 使用read方法读取前5个字节数据
ByteBufUtil.log(buffer);
buffer.readBytes(5);
ByteBufUtil.log(buffer);
// 再使用get方法读取后五个字节数据
buffer.getByte(5);
ByteBufUtil.log(buffer);
}
}
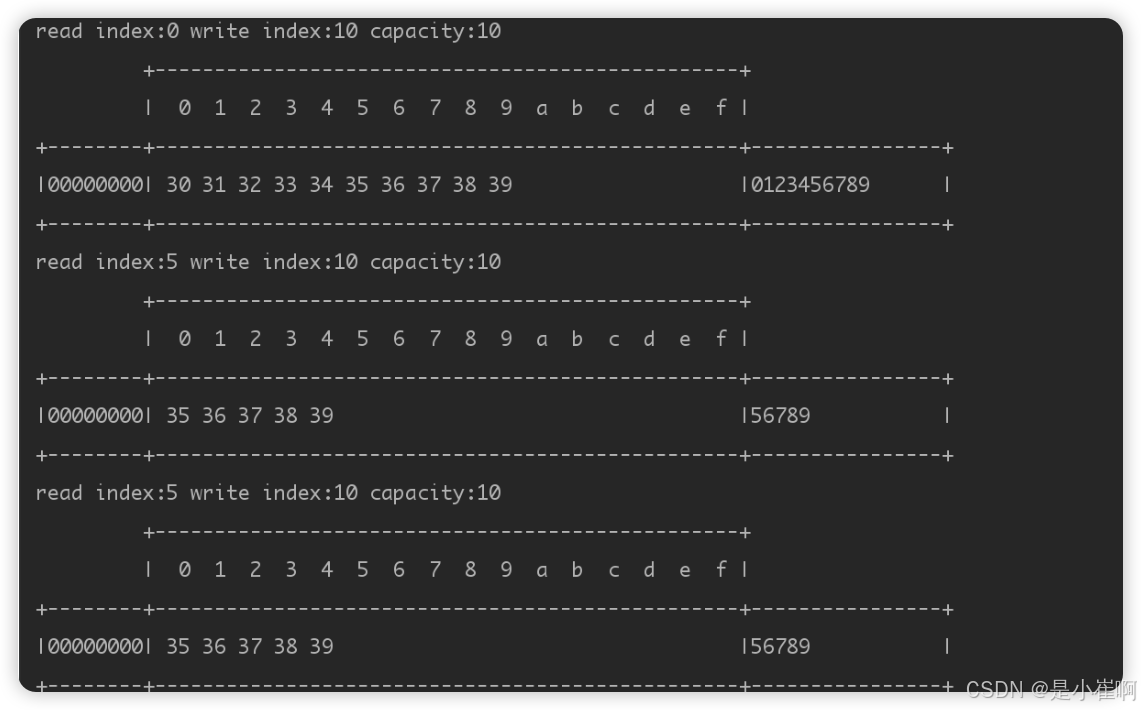
可看出,使用readBytes()方法读取五个字节后,读取指针会随之移动到5
接着看看前后的数据变化,此时会发现数据从0123456789变成了56789,这是因为前面五个字节的数据,已经属于废弃部分了
通过getByte()读取五个字节后,此时ByteBuf对象的读取指针,显然不会随之移动,并不会导致读过的数据废弃
如果使用read系列方法读取数据后,后续依旧想要读取数据该怎么办呢
可以使用ByteBuf内部的标记指针实现
// 在上述方法的最后继续追加下述代码:
// 使用mark标记一下读取指当前位置,然后再使用read方法读取数据
buffer.markReaderIndex();
buffer.readBytes(5);
ByteBufUtil.log(buffer);
// 此时再通过reset方法,使读取指针恢复到前面的标记位置
buffer.resetReaderIndex();
ByteBufUtil.log(buffer);
5.4:内存回收
jvm中有一个经典的判断对象是否存活的方法叫做引用计数法【当然JVM不用这个方法,因为这个方法存在循环引用时无法释放的问题,所以JVM用的是根可达算法】,但是在Netty-ByteBuf中却用了这个算法
// ReferenceCounted翻译过来就是引用计数
public abstract class ByteBuf implements ReferenceCounted, Comparable<ByteBuf>
public interface ReferenceCounted {
// 查看一个对象的引用计数统计值
int refCnt();
// 对一个对象的引用计数+1
ReferenceCounted retain();
// 对一个对象的引用计数+n
ReferenceCounted retain(int var1);
// 记录当前对象的当前访问位置,内存泄漏时会返回该方法记录的值
ReferenceCounted touch();
ReferenceCounted touch(Object var1);
// 对一个对象的引用计数-1
boolean release();
// 对一个对象的引用计数-n
boolean release(int var1);
}
当一个ByteBuf对象的引用计数变为0时,该缓冲区就会变为外部不可访问的状态
所以,在使用完一个ByteBuf对象后,明确后续不会用到该对象时,一定要记得手动调用release()清空引用计数
否则会导致该缓冲区长久占用内存,最终引发内存泄漏
🎉 在Netty-Channel中,都会采用ByteBuf来发送/接收数据,那这些通道传输数据用的ByteBuf对象,其占用的内存会在何时回收呢?
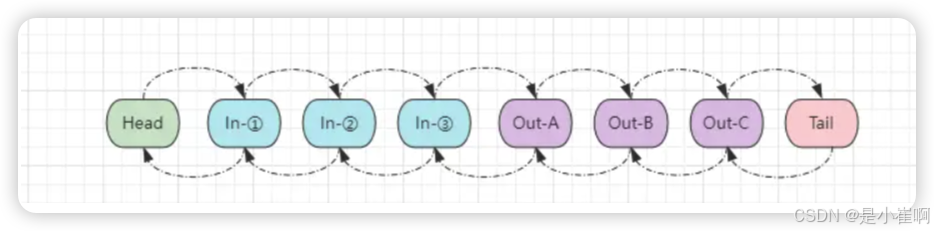
在其中有两个特殊的处理器,即Head、Tail处理器:
- Head处理器:
- 如果通道上只有入站处理器,它会作为整个处理器链表的第一个处理器调用。
- 如果通道上只有出站处理器,它会作为整个处理器链表的最后一个处理器调用。
- 如果通道上入/出站处理器都有,它会作为入站的第一个处理调用,出站的最后一个处理器调用。
- Tail处理器:
- 如果通道上只有入站处理器,Tail节点会作为整个链表的最后一个处理器调用。
- 如果通道上只有出站处理器,Tail节点会作为整个链表的第一个处理器调用。
- 如果通道上入/出站处理器都有,它会作为出站的第一个调用、入站的最后一个调用。
结合上面所说的内容,Head、Tail处理器在任何情况下,其中至少会有一个
作为通道上的最后一个处理器调用,而在这两个头尾处理器中,会自动释放ByteBuf的工作
⚠️ 明确后续不会用到该对象时,一定要记得手动调用release()清空引用计数!!!
pipeline.addLast("In-①",new ChannelInboundHandlerAdapter(){
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
System.out.println("俺是In-①入站处理器...");
// 在第一个入站处理器中,将接收到的ByteBuf数据转换为String向下传递
ByteBuf buffer = (ByteBuf) msg;
String message = buffer.toString(Charset.defaultCharset());
super.channelRead(ctx, message);
}
});
pipeline.addLast("In-②",new ChannelInboundHandlerAdapter(){
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
System.out.println("我是In-②入站处理器...");
super.channelRead(ctx, msg);
}
});
在第一个入站处理器中,将接收到的ByteBuf数据转换为String向下传递,也就意味着从In-②处理器开始,后面所有的处理器收到的msg都为String类型,当自定义的两个处理器执行完成后,最终会调用Tail处理器完成收尾工作,但是当Tail处理器中调用release()时,String并未实现ReferenceCounted接口,所以Tail无法对该msg进行释放,最终就会造成内存泄漏问题。
所以明确后续不会用到该对象时,一定要记得手动调用release()清空引用计数【重要的事情说三遍】
三:随处可见的零拷贝(重)
所谓的零拷贝,并不是不需要经过数据拷贝,而是减少内存拷贝的次数
比如Nginx向客户端提供文件下载的功能,客户端要下载的文件都位于Nginx所在的服务器磁盘中,如果当一个客户端请求下载某个资源文件时,这时需要经过的步骤如下:
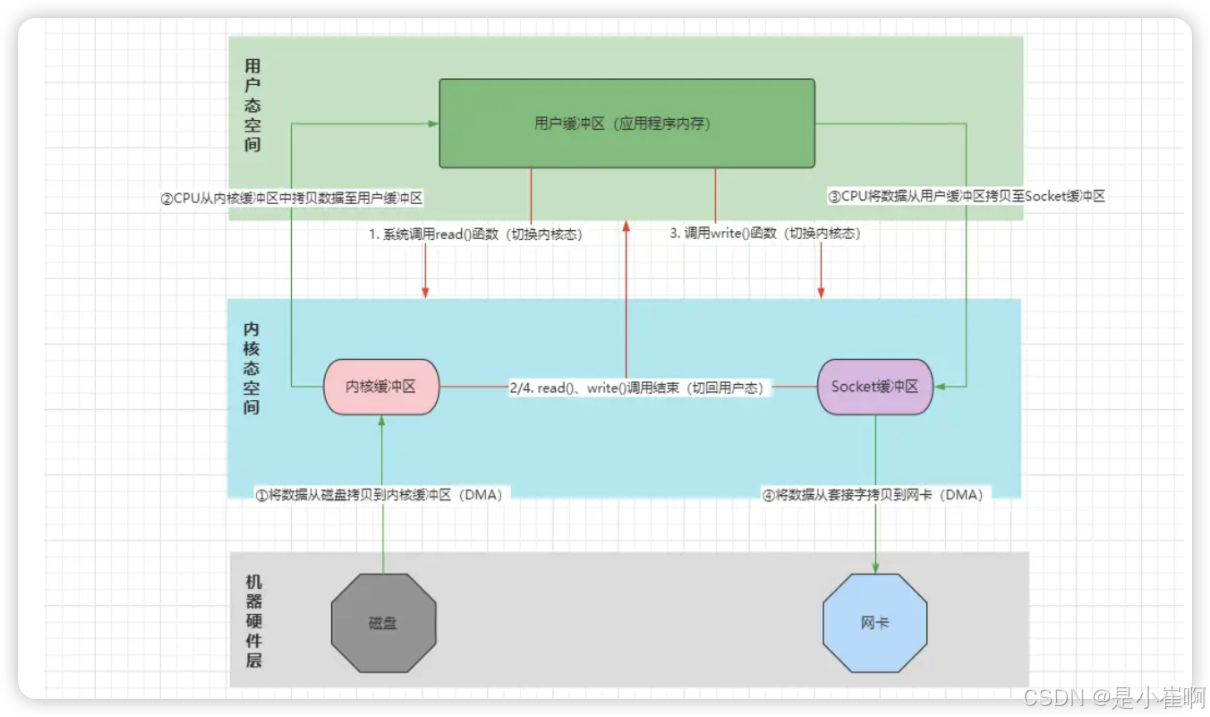
加载过程:两次切态,两次拷贝
- 客户端请求下载服务器上的某个资源,Nginx解析请求并得知客户端要下载的具体文件。
- Nginx向OS发起系统IO调用,调用内核read(fd)函数,应用上下文切态至内核空间。【第一次切态】
- read()函数通过DMA控制器,将目标文件的数据从磁盘读取至内核缓冲区。【第一次数据拷贝-DMA拷贝】
- DMA传输数据完成后,CPU将数据从内核缓冲区拷贝至用户缓冲区(程序的内存空间)【第二次数据拷贝-CPU拷贝】
- CPU拷贝数据完成后,read()调用结束并返回,上下文从内核态切回用户态。【第二次切态】
响应过程:两次切态,两次拷贝
- Nginx再次向OS发起内核write(fd)函数的系统调用,应用上下文再次切到内核态。【第三次切态】
- 接着CPU将用户缓冲区中的数据,写入到Socket网络套接字的缓冲区。【第三次数据拷贝-CPU拷贝】
- 数据复制到Socket缓冲区后,DMA控制器将Socket缓冲区的数据传输到网卡设备。【第四次数据拷贝-DMA拷贝】
- DMA控制器将数据拷贝至网卡设备后,write()函数调用结束,再次切回用户态。【第四次切态】
- 文件数据抵达网卡后,Nginx准备向客户端响应数据,组装报文返回数据…
可见,一次文件下载传统的IO流程,需要经过四次切态,四次数据拷贝(CPU、DMA各两次)
而所谓的零拷贝,并不是指不需要经过数据拷贝,而是指减少其中的数据拷贝次数。
1:操作系统中的零拷贝技术
这里的操作系统默认是Linux,因为MacOS、Windows系统相对闭源
1.1:MMAP共享内存
mmap 即 memory map,也就是内存映射。
mmap 是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。
实现这样的映射关系后,进程就可以采用指针的方式读写操作这一段内存,而系统会自动回写脏页面到对应的文件磁盘上,即完成了对文件的操作而不必再调用 read、write 等系统调用函数。
相反,内核空间对这段区域的修改也直接反映用户空间,从而可以实现不同进程间的文件共享。
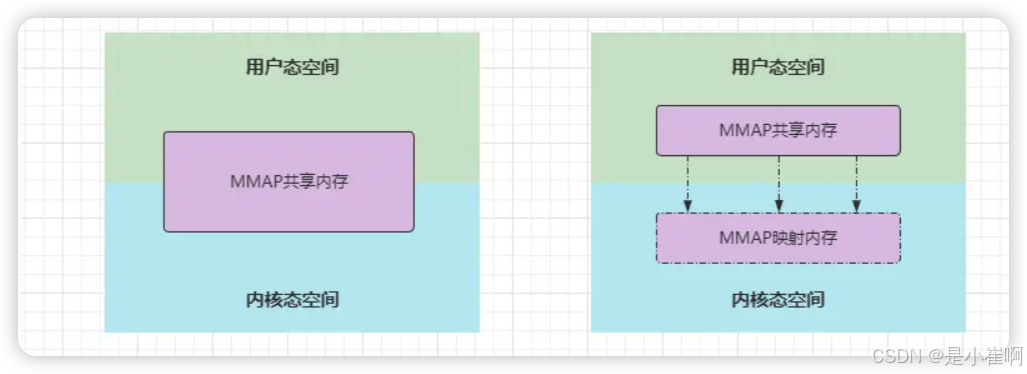
可以理解成为左边的图,但是实际上右边的图更加的准确,因为内核态和用户态本身是两个空间,各自之间并不存在真正的共享区域
MMAP共享内存是通过虚拟内存机制实现的,也就是通过内存映射技术【可以理解成为windows软件的快捷方式】实现的
在主流操作系统中都有一种名为虚拟内存的机制,这是指可以分配多个虚拟内存地址,指向同一个物理内存地址
此时内核态程序和用户态程序,可以通过不同的虚拟地址,来操纵同一块物理内存,这也就是MMAP共享内存技术的真正实现。
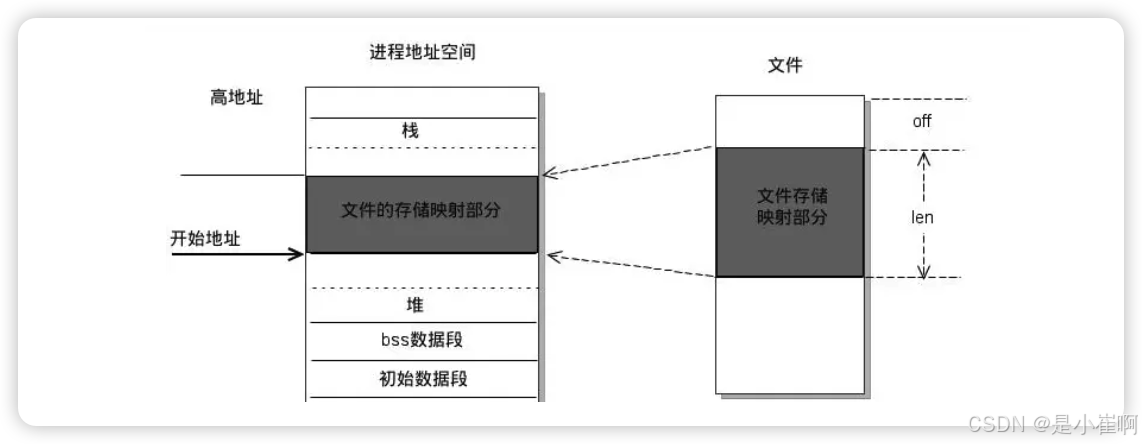
MMAP的系统定义如下:
// addr:指定映射的虚拟内存地址。
// length:映射的内存空间长度。
// prot:映射内存的保护模式。
// flags:指定映射的类型。
// fd:进行映射的文件句柄。
// offset:文件偏移量。
void *mmap(void *addr, size_t length, int prot, int flags, int fd, off_t offset);
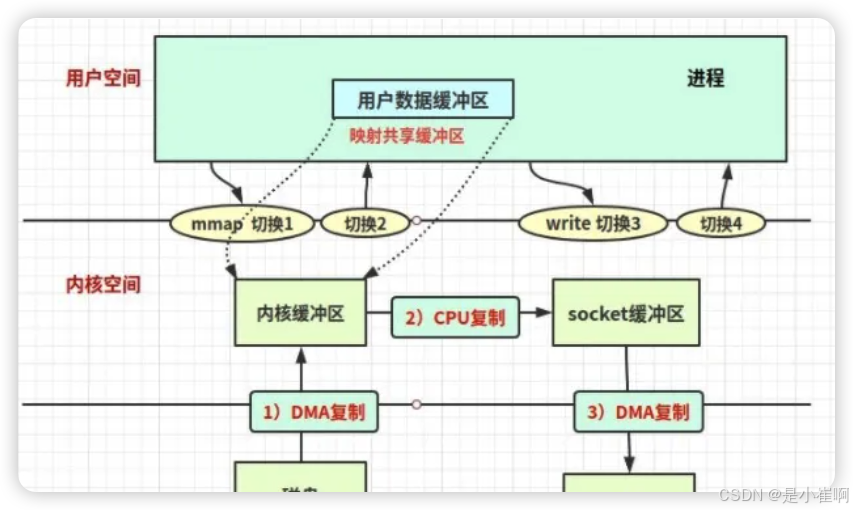
此时,如果内核缓冲区和用户缓冲区使用了MMAP共享内存,那当DMA控制器将数据拷贝至内核缓冲区时,因为这里的内核缓冲区,本质是一个虚拟内存地址指向用户缓冲区,所以DMA会直接将磁盘数据拷贝至用户缓冲区,这就减少了一次内核缓冲区到用户缓冲区的CPU拷贝过程
后续直接调用write()函数把数据写到Socket缓冲区即可
1.2:sendfile()内核函数
sendfile()是Linux2.1版本中推出的一个内核函数,系统调用的原型如下:
// fd_in:待写入数据的文件描述符(一般为Socket网络套接字的描述符)。
// fd_out:待读取数据的文件描述符(一般为磁盘文件的描述符)。
// offset:磁盘文件的文件偏移量。
// count:声明在fd_out和fd_in之间,要传输的字节数。
ssize_t sendfile(int fd_in, int fd_out, off_t *offset, size_t count);
当调用sendfile()函数传输数据时,会将out_fd指定为等待写入数据的网络套接字,将in_fd指定为待读取数据的磁盘文件
这样就可以直接在内核缓冲区中完成传输过程,无需经过用户缓冲区
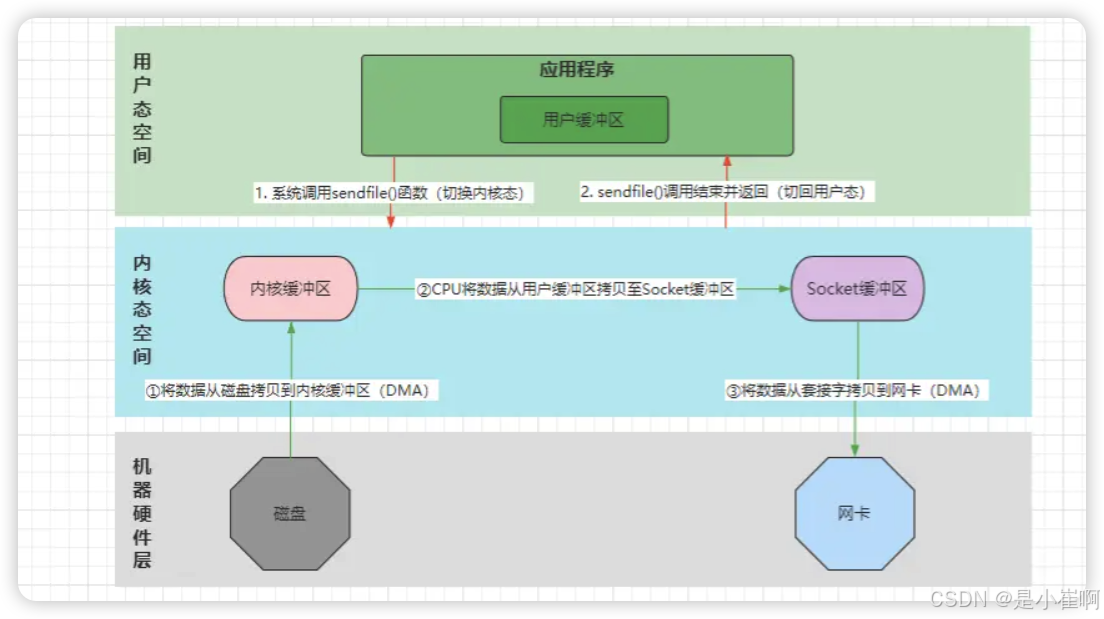
- 客户端请求下载服务器上的某个资源,Nginx解析请求并得知客户端要下载的具体文件。
- Nginx向OS发起系统IO调用,调用内核sendfile()函数,上下文切态至内核空间。【第一次切态】
- sendfile()函数通过DMA控制器,将目标文件的数据从磁盘读取至内核缓冲区。【DMA数据拷贝】
- DMA传输数据完成后,CPU将数据从内核缓冲区拷贝至Socket缓冲区。【CPU数据拷贝】
- CPU拷贝数据完成后,DMA控制器将数据从Socket缓冲区拷贝至网卡设备。【DMA数据拷贝】
- 数据拷贝到网卡后,sendfile()调用结束,应用上下文切回用户态空间。【第二次切态】
- Nginx准备向客户端响应数据,组装报文返回数据
可见相较于原本的MMAP+write()的方式,使用sendfile()函数来处理IO请求,这显然性能更佳,这里不仅仅减少了一次CPU拷贝,而且还减少了两次切态的过程。
1.3:S/G-DMA
到了Linux2.4版本中,又对sendfile()做了升级,引入了S/G-DMA技术支持
也就是在DMA拷贝阶段,如果硬件支持的情况下,会加入Scatter/Gather操作,这样就省去了仅有的一次CPU拷贝过程
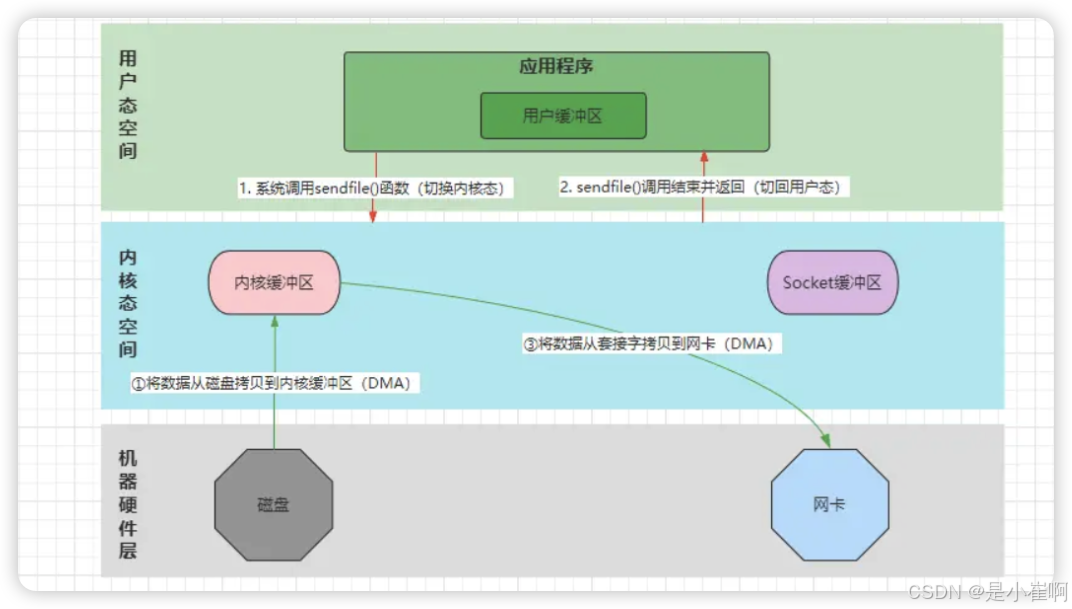
优化后的sendfile()函数,拷贝数据时只需要告知out_fd、in_fd、count即可
然后DMA控制器会直接将数据从磁盘拷贝至网卡,而无需经过CPU将数据拷贝至Socket缓冲区这一步。
1.4:splice()内核函数
sendfile()函数只适用于将数据从磁盘文件拷贝到Socket套接字或网卡上,所以这也限制了它的使用范围
因此在Linux2.6版本中,引入了splice()函数
// fd_in:等待写入数据的文件描述符。
// off_in:如果fd_in是一个管道文件(如Socket),该值必须为NULL,否则为文件的偏移量。
// fd_out:等待读取数据的文件描述符。
// off_out:作用同off_in参数。
// len:指定fd_in、fd_out之间传输数据的长度。
// flags:控制数据传输的模式
ssize_t splice(int fd_in, loff_t *off_in, int fd_out, loff_t *off_out, size_t len, unsigned int flags);
使用splice函数时,fd_in、fd_out中必须至少有一个是管道文件描述符,也就是说:必须要有一个文件描述符是Socket类型,如果两个磁盘文件进行复制,则无法使用splice函数
splice()函数的作用和DMA-Scatter/Gather版的sendfile()函数完全相同
与其不同的是:splice()函数不仅不需要硬件支持,而且能够做到两个文件描述符之间的数据零拷贝,实现的过程是基于一端的管道文件描述符,在两个FD之间搭建pipeline管道,从而实现两个FD之间的数据零拷贝。
2:另类零拷贝
2.1:缓冲区共享
缓冲区共享技术类似于Linux中的MMAP共享内存,但缓冲区共享则是真正意义上的内存共享技术,内核缓冲区和用户缓冲区共享同一块内存
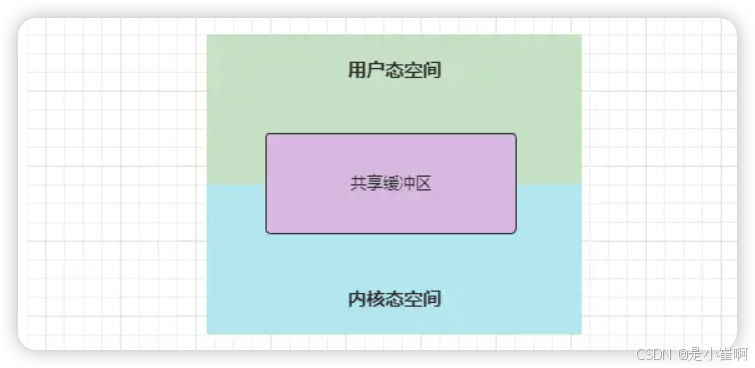
操作系统一般为了系统的安全性,在运行期间都会分为用户态和内核态,无法直接访问用户态程序内核态空间
所以Linux中的MMAP是基于虚拟内存实现的,而想要实现真正意义上的内存共享,这也就意味着需要重写内核结构
目前比较成熟的只有Solaris系统上的Fast Buffer技术
2.2:程序数据的零拷贝
前面的零拷贝技术,都是在减少磁盘文件和网络套接字之间的数据拷贝次数
程序中也会存在很多的数据拷贝过程,比如将一个大集合拆分为两个小集合、将多个小集合合并成一个大集合等等
// 传统做法如下:
List<Integer> a = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);
List<Integer> b = new ArrayList<>();
List<Integer> c = new ArrayList<>();
for (Integer num : a) {
int index = a.indexOf(num);
if (index < 5){
b.add(num);
} else {
c.add(num);
}
}
上述这个做法,会从a中将数据拷贝到b、c集合中,而所谓的零拷贝,即是无需发生拷贝动作,也能够将a拆分成b、c两个集合。
Netty中的ByteBuf就可以做到这一点,实现了程序数据的零拷贝
3:Java-IO中的零拷贝体现
3.1:NIO中的零拷贝
Java-NIO中,主要有三个方面用到了零拷贝技术:
- MappedByteBuffer.map():底层调用了操作系统的mmap()内核函数。
- DirectByteBuffer.allocateDirect():可以直接创建基于本地内存的缓冲区。
- FileChannel.transferFrom()/transferTo():底层调用了sendfile()内核函数。
3.2:Netty中的零拷贝
netty中的零拷贝是一种用户进程级别的零拷贝体现,主要包含三个方面:
- Netty的发送、接收数据的ByteBuf缓冲区,默认会使用堆外本地内存创建,采用直接内存进行Socket读写,数据传输时无需经过二次拷贝。如果使用传统的堆内存进行Socket网络数据读写,JVM需要先将堆内存中的数据拷贝一份到直接内存,然后才写入Socket缓冲区中,相较于堆外直接内存,消息在发送过程中多了一次缓冲区的内存拷贝。
- Netty的文件传输采用了transferTo()/transferFrom()方法,它可以直接将文件缓冲区的数据发送到目标Channel(Socket),底层就是调用了sendfile()内核函数,避免了文件数据的CPU拷贝过程。
- Netty提供了组合、拆解ByteBuf对象的API,咱们可以基于一个ByteBuf对象,对数据进行拆解,也可以基于多个ByteBuf对象进行数据合并,这个过程中不会出现数据拷贝,这个也就是上面说的程序数据的零拷贝
前两个已经说过了,重点说下第三个Netty-ByteBuf在程序数据的零拷贝
这是一种Java级别的零拷贝技术,ByteBuf中主要有slice()、composite()这两个方法,用于拆分、合并缓冲区
slice() -> 拆分出的ByteBuf对象,其数据依赖于原ByteBuf对象
package com.cui.commonboot.mynetty.bytebuftest;
import io.netty.buffer.ByteBuf;
import io.netty.buffer.ByteBufAllocator;
public class SliceTest {
public static void main(String[] args) {
ByteBuf byteBuf = ByteBufAllocator.DEFAULT.buffer(10);
byte[] bytes = new byte[]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
byteBuf.writeBytes(bytes);
ByteBufUtil.log(byteBuf);
// 使用Split拆分
// 从下标0开始,向后截取五个字节,拆分成一个新ByteBuf对象
ByteBuf b1 = byteBuf.slice(0, 5);
ByteBufUtil.log(b1);
// 从下标5开始,向后截取五个字节,拆分成一个新ByteBuf对象
ByteBuf b2 = byteBuf.slice(5, 5);
ByteBufUtil.log(b2);
// 证明切割出的两个ByteBuf对象,是共享第一个ByteBuf对象数据的
// 这里修改b1对象,会发现最初的byteBuf对象也变了
b1.setByte(0, 'a');
ByteBufUtil.log(byteBuf);
}
}
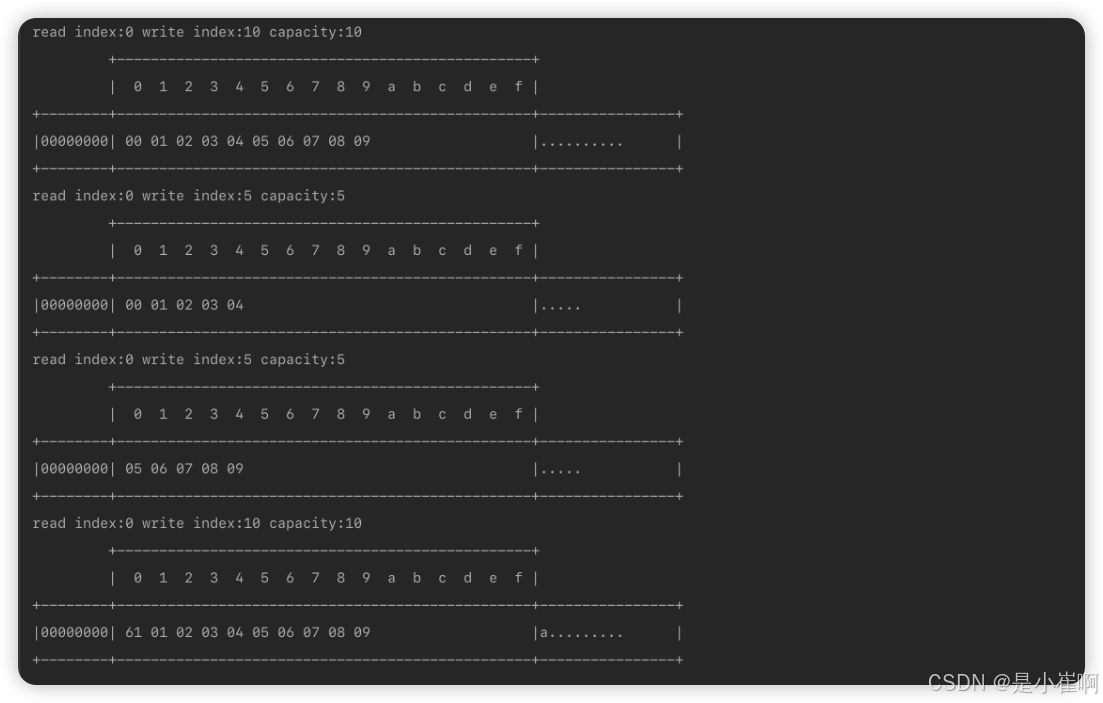
使用split拷贝的数据其实没有真正的拷贝,因为拆分出来的对象完全依赖于源对象,更像是一种映射
这种零拷贝方式,虽然减少了数据复制次数,但也会有一定的局限性:
- 不支持扩容,也就是切割的长度为5,最大长度也只能是5,超出长度时会抛出下标越界异常。
- 由于数据依赖于原ByteBuf对象,因此当原始ByteBuf对象被释放时,拆分出的缓冲区也会不可用,所以在使用slice()方法时,要手动调用retain()/release()来增加引用计数
package com.cui.commonboot.mynetty.bytebuftest;
import io.netty.buffer.ByteBuf;
import io.netty.buffer.ByteBufAllocator;
public class SliceTest {
public static void main(String[] args) {
ByteBuf buffer = ByteBufAllocator.DEFAULT.buffer(16, 20);
// 向buffer中写入数据
buffer.writeBytes(new byte[]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10});
// 分成两个部分
ByteBuf slice1 = buffer.slice(0, 5); // index & length
ByteBuf slice2 = buffer.slice(5, 5);
// 需要让分片的buffer引用计数加一
// 避免原Buffer释放导致分片buffer无法使用
slice1.retain();
slice2.retain();
ByteBufUtil.log(slice1);
ByteBufUtil.log(slice2);
// 更改buffer中的值
System.out.println("--------------- 修改原buffer中的值 --------------");
buffer.setByte(0, 5); // 将第1个内容改成5
System.out.println("--------------- slice中的值也会被改变 -----------");
ByteBufUtil.log(slice1);
}
}
duplicate()
和slice切片不同,duplicate()返回的是源ByteBuf的整个对象的一个浅层复制,包括如下内容:
- duplicate的读写指针、最大容量值,与源ByteBuf的读写指针相同。
- duplicate()不会改变源ByteBuf的引用计数。
- duplicate()不会复制源ByteBuf的底层数据。
duplicate()和slice()方法都是浅层复制。不同的是,slice()方法是切取一段的浅层复制,而duplicate( )是整体的浅层复制。
composite() -> 合并缓冲区
想要将多个缓冲区合并成一个大的缓冲区:
-
需要先创建一个CompositeByteBuf对象
-
接着调用它的addComponent()/addComponents()方法,将小的缓冲区添加进去即可。
但在合并多个缓冲区时,addComponents()方法中的第一个参数必须为true,否则不会自动增长读写指针。
package com.cui.commonboot.mynetty.bytebuftest;
import io.netty.buffer.ByteBuf;
import io.netty.buffer.ByteBufAllocator;
import io.netty.buffer.CompositeByteBuf;
/**
* <p>
* 功能描述:Netty Composite 零拷贝合并
* </p>
*
* @author cui haida
* @date 2023/12/20/19:40
*/
public class CompositeZeroCopy {
public static void main(String[] args) {
compositeZeroCopy();
}
private static void compositeZeroCopy() {
// 创建两个小的ByteBuf缓冲区,并往两个缓冲区中插入数据
ByteBuf b1 = ByteBufAllocator.DEFAULT.buffer(5);
ByteBuf b2 = ByteBufAllocator.DEFAULT.buffer(5);
byte[] data1 = {'a', 'b', 'c', 'd', 'e'};
byte[] data2 = {'n', 'm', 'x', 'y', 'z'};
b1.writeBytes(data1);
b2.writeBytes(data2);
// 创建一个合并缓冲区的CompositeByteBuf对象
CompositeByteBuf buffer = ByteBufAllocator.DEFAULT.compositeBuffer();
// 将前面两个小的缓冲区,合并成一个大的缓冲区
buffer.addComponents(true, b1, b2);
// print
ByteBufUtil.log(buffer);
}
}
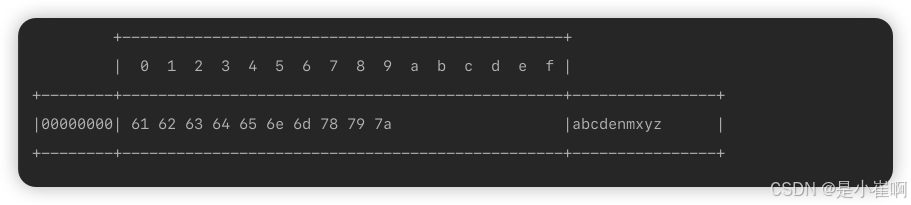
🎉 Netty-ByteBuf缓冲区的零拷贝方法,实际上也可以被称之为“一种特殊的浅拷贝”,与之对应的是“深拷贝”,而ByteBuf中的“深拷贝”,则是一系列以Copy开头的方法,通过这类方法复制缓冲区,会完全分配新的内存地址、读写指针。
🎉 在Netty内部还提供了一个名为Unpooled的工具类,这主要是针对于非池化缓冲区的工具类,内部也提供了一系列wrappend开头的方法,可以用来组合、包装多个ByteBuf对象或字节数组,调用对应方法时,内部也不会发生拷贝动作,这也是一类零拷贝的方法


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









