










 这篇博客介绍了决策树的学习目的,详细讲解了信息熵、信息增益、基尼系数的概念及其计算公式,并探讨了ID3、C4.5、CART三种决策树算法的划分条件。此外,还阐述了决策树的剪枝操作,包括预剪枝和后剪枝,以及如何处理连续值。最后,提到了连续属性的二分法处理。
这篇博客介绍了决策树的学习目的,详细讲解了信息熵、信息增益、基尼系数的概念及其计算公式,并探讨了ID3、C4.5、CART三种决策树算法的划分条件。此外,还阐述了决策树的剪枝操作,包括预剪枝和后剪枝,以及如何处理连续值。最后,提到了连续属性的二分法处理。
决策树理论知识
一、学习目的
决策树学习的目的是为了找到产生一颗泛化能力强,即处理未见示例能力强的决策树,遵循“分而治之”的策略。
二、信息熵、信息增益、基尼系数
1、 信息熵: 熵是表示随机变量不确定性的度量。
(简单点理解就是:如果你去苹果专卖店买手机,那么苹果手机在苹果专卖店中存在的概率就很大,相对的,信息熵就很小。而你去杂货店买本子,因为杂货店的货物比较混乱 ,那本子在杂货店中存在的概率就比较小, 相对的,熵就比较大。) ---->不确定性越大,概率越小, 熵越大。
信息熵的计算公式:
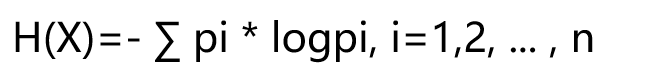
2、条件熵: 条件熵是通过获得更多的信息来减少不确定性。
(通俗点的理解就是通过结点分裂后的各个子结点信息熵的加权和)
条件熵的计算公式: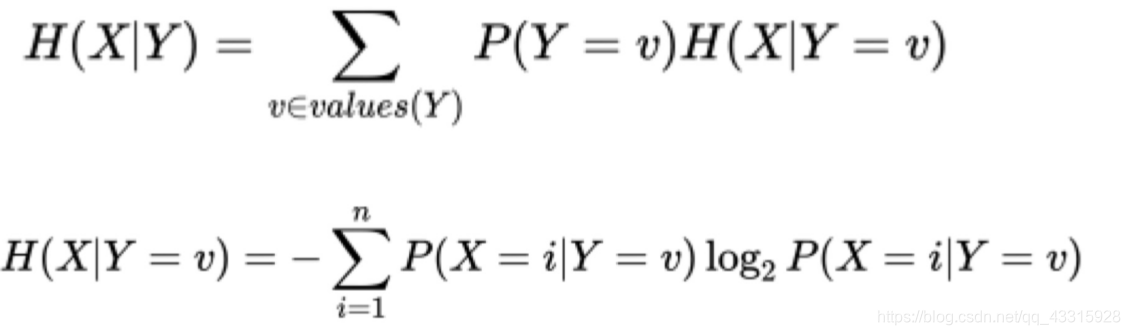
3、信息增益: 表示特征X使得类Y的不确定性减少的程度。
(分类后的专一性,希望分类后的结果是同类在一起,用于属性节点的划分,信息增益越大,说明该属性划分后的信息熵越小,纯度越高)
信息增益的计算公式:
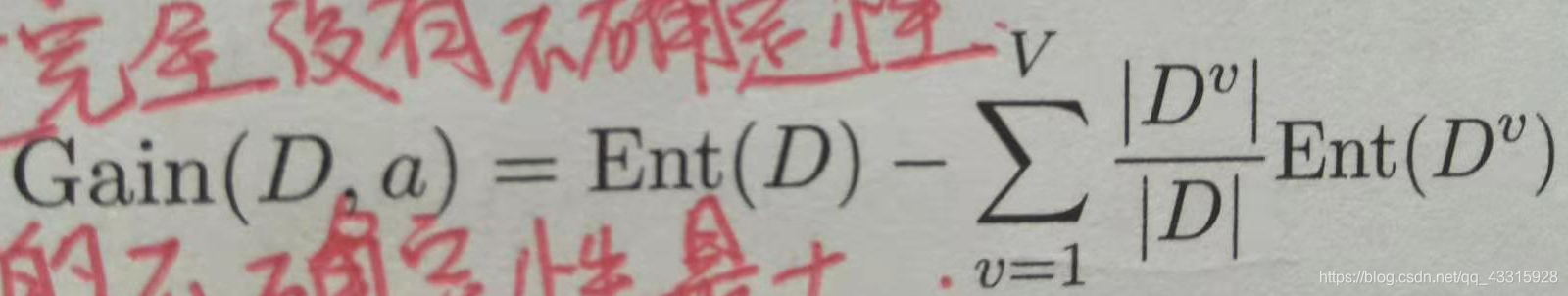 文字化理解:
文字化理解:
信息增益 = 信息熵 - 条件熵 = 信息熵 - 分裂后各个子结点的信息熵加权和
4、基尼系数: 度量数据集的纯度,纯度越高,基尼系数越小
基尼系数计算公式: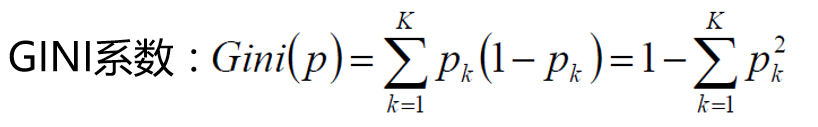
5、信息增益率: 信息增益率 = 信息增益 / 自身信息熵
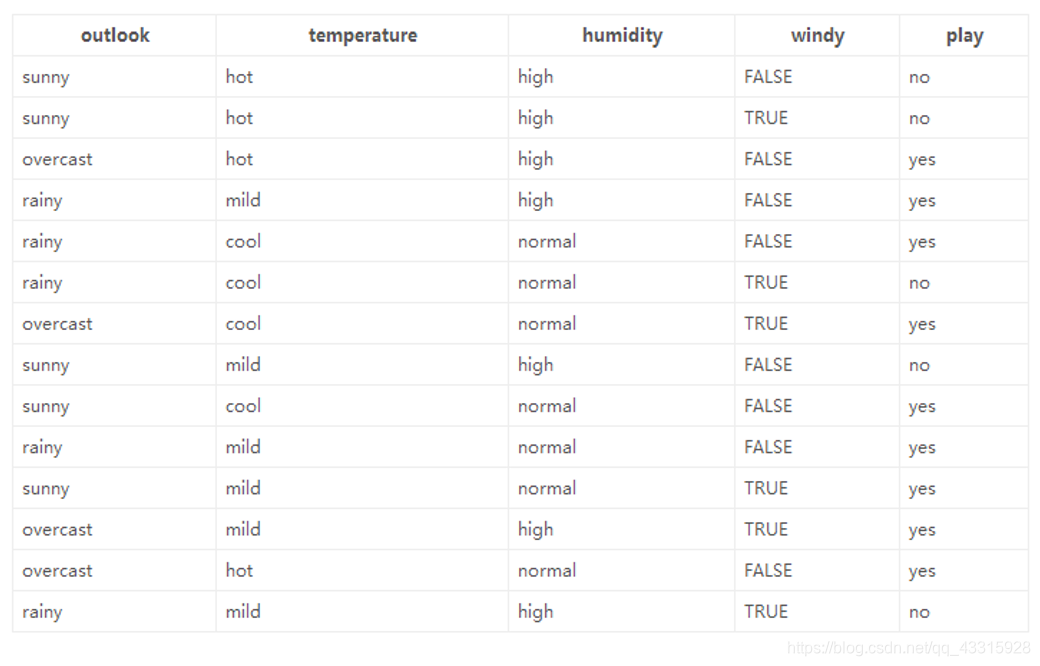
实例展示:
数据集描述:
特征数:4个
数据:14天打球情况
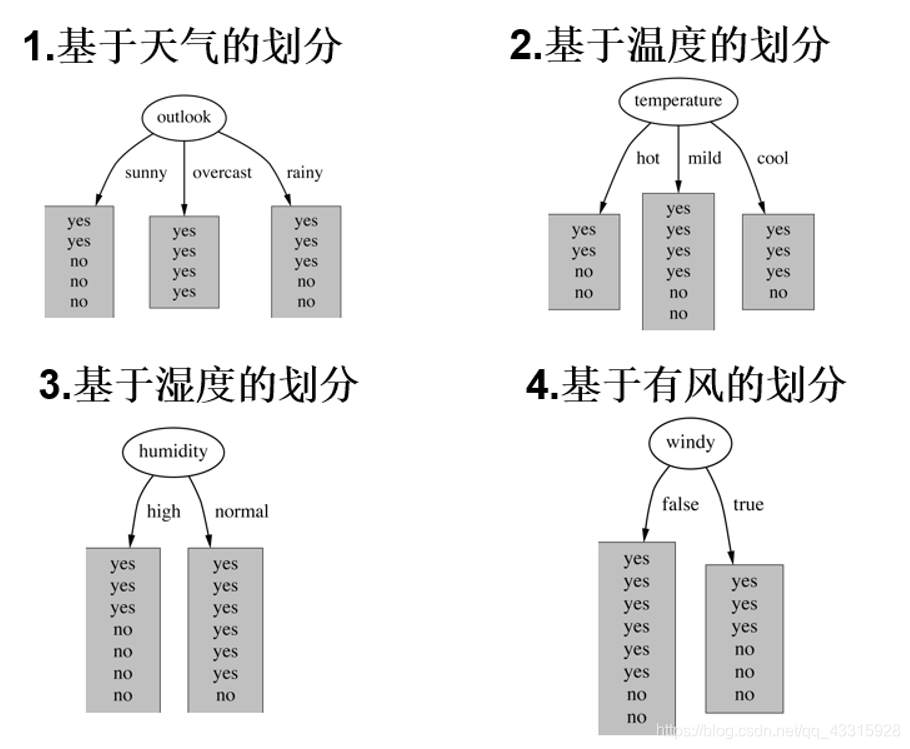



三、划分条件
决策树有三种使用不同划分条件的方法,分别是:
1、ID3算法: 选择一个使信息增益最大化的属性(信息增益准则对可取值数目较多的属性有所偏好)
2、C4.5算法: 使用信息增益率来划分最优属性(增益率准则对可取值数目较少的属性有所偏好,因此。C4.5算法并不是直接选择增益率最大的候选划分属性,而是先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的)
3、CART算法: 使用“基尼指数”最小的属性作为最优属性划分
四、决策树基本算法递归返回三种情形:
1、当前结点包含的样本全属于同一类别,无需划分
2、当前属性集为空,或是所有样本在所有属性上取值相同,无法划分
3、当前结点包含的样本数据集合为空,不能划分
五、决策树的剪枝操作
决策树的剪枝是决策树学习算法对付“过拟合”的主要手段,剪枝操作分为两种:预剪枝和后剪枝。
预剪枝: 所谓预剪枝就是边建立决策树边进行剪枝操作。
预剪枝可以限制树的深度以及控制叶子结点的个数与样本数,判断树是否需要剪枝的标准有:1)、剪枝后该预测的精度是否有所上升或者不变,如果剪枝后预测的精度上升或者不变,则对该结点进行剪枝
2)、剪枝后该结点的熵或者信息增益是否变化。如果剪枝后该结点的熵增大,则说明该结点不应该进行剪枝,因为剪枝后会使得结点的纯度降低
后剪枝: 后剪枝是在建立完整个决策树之后再进行剪枝操作。衡量的标准可以是信息损失。
其中,C(T)为总的信息损失,T为叶子结点数。
C(T) = sum(叶子结点样本数*Gini系数)
六、连续值的处理
对于连续属性一般都是使用二分法进行处理,如有一个属性的取值为[1, 100],则可以将取值大于50的特征划分为A, 将取值小于50的属性划分为B
文章参考资料:
周志华:机器学习


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









