






 这是一个基于Java的轻量级命令行工具,用于快速搜索本地文件。它占用资源少,搜索速度快,支持文件名和文件类型的组合搜索。通过多线程遍历文件系统并使用Apache Commons IO进行文件监控,同时利用H2数据库存储文件信息。工具提供配置选项,如搜索结果数量、排序方式和排除特定路径。测试显示,创建索引可以显著提高搜索效率。
这是一个基于Java的轻量级命令行工具,用于快速搜索本地文件。它占用资源少,搜索速度快,支持文件名和文件类型的组合搜索。通过多线程遍历文件系统并使用Apache Commons IO进行文件监控,同时利用H2数据库存储文件信息。工具提供配置选项,如搜索结果数量、排序方式和排除特定路径。测试显示,创建索引可以显著提高搜索效率。
1. 简介
基于Java语言开发的轻量级命令行文件搜索工具,占用极低的系统资源,得到超高的搜索效率。
2. 背景
有时候忘了文件的存储位置,但Windows系统自带的搜索执行起来太慢了,所以开发一款命令行工具,用来实现快速搜索文件的功能。
3. 功能
功能就是搜索文件所在路径。支持两种方式的搜索,一种是根据文件名获取文件路径,另一种是根据文件名+文件类型获取文件路径。结果显示可以自定义(比如对返回结果的数量限制;按照文件目录级数升序或降序排列;支持对搜索路径进行自定义,可以自己选择在搜索时排除掉哪些路径,比如C盘中的Windows目录下一般存放系统文件,我们在搜索时就可以排除这个目录;并且具有文件监控功能,当系统中有创建新的文件或删除文件时,会在命令行提示我们)。

4. 技术
- Java(文件操作,输入输出流)
- Database
- JDBC
- Java多线程
- 文件系统监控(Apache Commons IO)
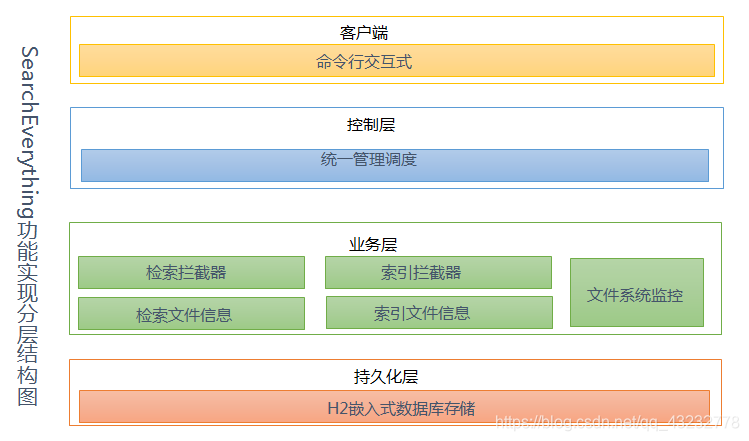
5. 实现
实现部分,我们总体可以分为以下三部分
- 程序入口
这部分比较简单 ,我们只需要根据用户输入的命令,调用统一配置管理中相应的方法,给用户返回相应的结果即可。 - 程序配置
程序配置我们需要对索引路径进行定义,定义一些要排除的路径,比如C:\Windows、C:\ProgramData类似这样的路径。除此之外,我们还需要配置
结果的返回数量,结果显示排序方式,是否需要构建索引。这些配置信息我在代码中直接设置了默认值,此外我提供了一个properties文件,在这里用户可以自己定义要配置的信息,代码会优先读取文件中的配置信息,并做设置工作,如果文件为空,使用默认值。 - 核心业务代码
核心业务就是遍历本机中的所有文件,存储到数据库中,根据指定文件名搜索,返回结果。
我将业务拆分一下,首先就是要遍历本机中所有文件,遍历文件使用java中File的相关操作。为了提高效率,这里采用多线程来遍历,一个线程遍历一个盘符
public void buildIndex() {
//建立索引
DataSourceFactory.databaseInit(true);
HandlerPath handlerPath = config.getHandlerPath();
Set<String> includePaths = handlerPath.getIncludePath();
new Thread(() -> {
System.out.println("Build Index Started ...");
String startTime = Test.printTime();
System.out.println(startTime);
System.out.println();
final CountDownLatch countDownLatch = new CountDownLatch(includePaths.size());
for (String path : includePaths) {
executorService.submit(() -> {
fileScan.index(path);
countDownLatch.countDown();
});
}
try {
countDownLatch.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("Build Index Complete ...");
String endTime = Test.printTime();
System.out.println(endTime);
}).start();
}
在这里,我没有直接将遍历到的结果都存储到某个容器中,而是引入了一个拦截器类,由拦截器拦截到这些遍历到的文件,对它进行操作。
public void index(String path) {
Set<String> excludePaths = config.getHandlerPath().getExcludePath();
// C:\Windows
// C:\Windows C:\Windows\system32
// 判断 A path 是否在 B path中
for (String excludePath : excludePaths) {
if (path.startsWith(excludePath)) {
return;
}
}
File file = new File(path);
if (file.isDirectory()) {
File[] files = file.listFiles();
if (files != null) {
for (File f : files) {
// count++;
index(f.getAbsolutePath());
}
}
}
// 将结果交给拦截器去处理
for (FileInterceptor interceptor : this.interceptors) {
interceptor.apply(file);
}
// System.out.println("文件总数"+count);
}
这样我们每遍历到一个文件就直接对它进行处理,不占用多余的内存空间。拦截器拿到文件后,可以进行很多操作。此处我只需要把文件插入到数据库中。
// 拦截器对拦截到的文件进行处理
public void apply(File file) {
Thing thing = FileConvertThing.convert(file);
this.fileIndexDao.insert(thing);
}
但是数据库不支持File类型的存储,因此在这里,我需要把File对象抽象成一个可存储到数据库中的对象,我选择把文件抽象成一个Thing类,类中有文件名,文件路径,文件深度,文件类型这些属性。我将这些属性作为数据库表中每一列的属性即可存储进去。
public class FileConvertThing {
public static Thing convert(File file) {
Thing thing = new Thing();
String name = file.getName();
thing.setName(name);
thing.setPath(file.getAbsolutePath());
//目录 -> *
//文件 -> 有扩展名,通过扩展名获取FileType
// 无扩展,*
int index = name.lastIndexOf(".");
String extend = "*";
if (index != -1 && (index + 1) < name.length()) {
extend = name.substring(index + 1);
}
thing.setFileType(FileType.lookupByExtend(extend));
thing.setDepth(getFileDepth(file.getAbsolutePath()));
return thing;
}
private static int getFileDepth(String path) {
//path => D:\a\b => 2
//path => D:\a\b\hello.java => 3
//window : \
//Linux : /
int depth = 0;
for (char c : path.toCharArray()) {
if (c == File.separatorChar) {
depth += 1;
}
}
return depth;
}
}
将Thing对象插入数据库
public void insert(Thing thing) {
//JDBC操作
Connection connection = null;
PreparedStatement statement = null;
try {
connection = this.dataSource.getConnection();
String sql = "insert into thing (name,path,depth,file_type) values (?,?,?,?)";
statement = connection.prepareStatement(sql);
//预编译命令中SQL的占位符赋值
statement.setString(1, thing.getName());
statement.setString(2, thing.getPath());
statement.setInt(3, thing.getDepth());
statement.setString(4, thing.getFileType().name());
statement.executeUpdate();
} catch (SQLException e) {
e.printStackTrace();
} finally {
releaseResource(null, statement, connection);
}
}
在这里我没有使用MySQL数据库,而是嵌入式H2数据库,考虑到H2数据库比较轻量级,可以随着程序一起发布,而且我们只需要存储文件的相关信息,用MySQL存储有点“杀鸡焉用宰牛刀”的意思。H2连接数据库和MySQL不太一样,按照官方文档配置即可。
在把数据村进数据库后,搜索时只需在数据库中搜索即可。搜索时需要考虑使用模糊匹配还是精确匹配,我在这里对于文件名使用后模糊匹配法,文件路径使用精确匹配。这里要注意,如果文件是被排除掉的,就不返回这条记录了。
public List<Thing> query(Condition condition) {
List<Thing> things = new ArrayList<>();
Connection connection = null;
PreparedStatement statement = null;
ResultSet resultSet = null;
try {
connection = this.dataSource.getConnection();
StringBuilder sb = new StringBuilder();
sb.append("select name,path,depth,file_type from thing ");
sb.append(" where ");
//search <name> [file_type]
//采用模糊匹配
//前模糊
//后模糊 ✔
//前后模糊
sb.append(" name like '").append(condition.getName()).append("%'");
if (condition.getFileType() != null) {
FileType fileType = FileType.lookupByName(condition.getFileType());
sb.append(" and file_type='" + fileType.name() + "'");
}
sb.append(" order by depth ")
.append(condition.getOrderByDepthAsc() ? " asc" : "desc");
sb.append(" limit ").append(condition.getLimit());
statement = connection.prepareStatement(sb.toString());
resultSet = statement.executeQuery();
//处理结果
while (resultSet.next()) {
//Record -> Thing
Thing thing = new Thing();
thing.setName(resultSet.getString("name"));
thing.setPath(resultSet.getString("path"));
thing.setDepth(resultSet.getInt("depth"));
thing.setFileType(FileType.lookupByName(resultSet.getString("file_type")));
things.add(thing);
}
} catch (SQLException e) {
e.printStackTrace();
} finally {
releaseResource(resultSet, statement, connection);
}
return things;
}
这里还有一个问题,就是系统中的文件必然是会发生变化的,可能会新创建文件,也可能删除文件,我们不能把用户已经删除的文件返回给结果。因此在这里需要做一个文件监控,Java有一个文件监控类WatchService : 是JDK1.7提供的,监听文件系统的变化,但是只能监听当前指定的目录(某个文件夹),显然不合适,我们要对电脑中所有目录做监听,就和遍历一样了。因此我选择 apache 的 coms.io 来进行文件监控。它会在有文件删除或创建时提醒我。
- 统一配置管理
为了让代码整体更清晰,我引入了统一配置管理类。对配置,索引模块,检索模块,拦截器模块组合调度
5. 测试
测试环境:
- 处理器:AMD A8-4500M APU with Radeon™ Graphics 1.90GHz
- 内存:4GB
- 磁盘:SSD
- 测试数据:去掉排除过的路径,文件总数为:332337
我从两个方面进行了测试,第一个是在数据库中创建索引和不创建索引,遍历文件系统耗时的对比,第二个是比较搜索文件耗时的对比。测试结果如下:
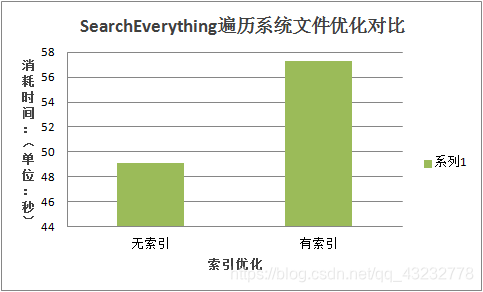
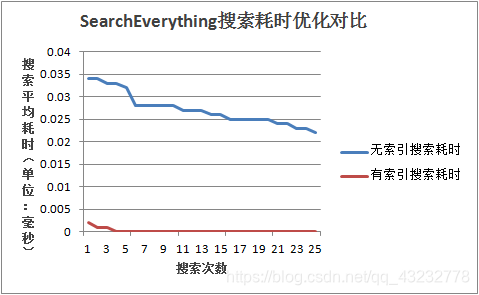
我们可以看到,在数据库中创建了索引后,数据库搜索效率得到了极大的提升,但是由于创建索引,我们写入数据会变得比较慢一点。
项目源码:SearchEverything项目源码


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









