







官方文档地址
https://kvcache-ai.github.io/ktransformers/en/install.html
适配模型
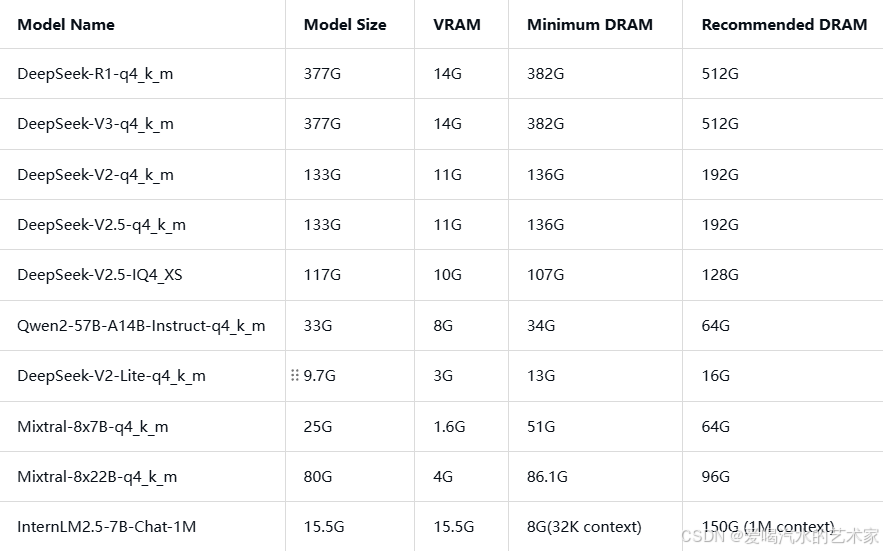
设备
所需硬件设备:4090单卡24G显存
模型文件下载脚本
from modelscope import snapshot_download
try:
snapshot_download(
repo_id="unsloth/DeepSeek-R1-GGUF",
local_dir="/models/LargeLanguageModels/Deepseek-R1-Q2_K_XL",
allow_patterns=["*UD-Q2_K_XL*"]
)
print("文件下载成功!")
except Exception as e:
print(f"下载过程中出现错误:{e}")
环境部署
准备基础环境(一定要注意顺序问题,一些该装的得提前装)
这里沿用官方的建议。
如果还没有 CUDA 12.1 及以上版本,可以从 这里 安装。
export PATH=/usr/local/cuda/bin:$PATH
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:$LD_LIBRARY_PATH
export CUDA_PATH=/usr/local/cud
Linux-x86_64 系统,需要安装 gcc、g++ 和 cmake
sudo apt-get update
sudo apt-get install gcc g++ cmake ninja-build
建议使用 Conda 创建一个 Python=3.11 的虚拟环境来运行我们的程序。
最好用新的虚拟环境哈,免得各种报错
conda create --name ktransformers python=3.11
conda activate ktransformers # 您可能需要先运行 ‘conda init’ 并重新打开 shell
确保安装了 PyTorch、packaging、ninja
pip install torch packaging ninja cpufeature numpy
安装flash-attn(注意,这个加速服务需要很久很久,我用新的虚拟环境,这一步装了我1.5小时,一直在编译,可以按照我下面的来做,会稍微快点):
python -m pip install ninja -i https://pypi.tuna.tsinghua.edu.cn/simple
MAX_JOBS=4 pip install flash-attn --no-build-isolation -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install ktransformers -i https://pypi.tuna.tsinghua.edu.cn/simple
Ubuntu 22.04 安装需要更新以下需求
sudo add-apt-repository ppa:ubuntu-toolchain-r/test
sudo apt-get update
sudo apt-get install --only-upgrade libstdc++6
拉取KTransformers并进行相关配置
git clone https://github.com/kvcache-ai/ktransformers.git
#进入项目目录
cd ktransformers
#安装子模块
git submodule init
#然后更新一下
git submodule update
出现以下则成功

假如网络有问题,可以直接下载,然后上传到对应目录
https://github.com/ggerganov/llama.cpp
https://github.com/pybind/pybind11
分别放到对应目录下即可(注意,这是我的目录):
/home/intop/ktransformers/third_party/llama.cpp
/home/intop/ktransformers/third_party/pybind11
查看是不是双路socket,因为双路和单路设置不一样,同时占用内存也不一样。
查看是不是双路,主要是看socket
lscpu
因为我们是双路CPU,这里跟着做就行。需设置一下NUMA信息
export USE_NUMA=1
然后开始编译:
make dev_install
#或者执行下面的,执行其中一个即可
bash install.sh
编译完成之后执行,记得修改模型路径和参数,如果没有满血版本的R1,可以直接用–model_path deepseek-ai/DeepSeek-R1
本地local_chat形式
python ./ktransformers/local_chat.py --model_path xxxx --gguf_path xxx --port 10002 --cpu_infer 65 --cache_lens 1536 --max_new_tokens 8192
参数解释:
--cache_lens 1536
含义: 设置缓存长度(可能是 KV 缓存的长度)。
解释: 在 Transformer 模型中,KV 缓存(键-值缓存)用于加速生成过程。这里设置为 1536,可能表示缓存 1536 个 token 的上下文信息,以优化性能或减少重复计算。
--max_new_tokens 8192
含义: 设置生成的最大新 token 数量。
解释: 模型在生成文本时,最多可以生成 8192 个新 token。这限制了输出的最大长度,适用于控制生成内容的规模。
--model_path(必填):模型的名称(例如 “"deepseek-ai/DeepSeek-V2-Lite-Chat”,它将自动从huggingface下载配置)。或者如果你已经有了本地文件,你可以直接使用该路径来初始化模型。注意:目录中不需要. safetensors 文件。我们只需要配置文件来构建模型和标记器。
--gguf_path(必填):包含 GGUF 文件的目录的路径,可以从拥抱脸下载。请注意,该目录应该只包含当前模型的 GGUF,这意味着每个模型需要一个单独的目录。
--optimize_rule_path(Qwen2Moe 和 DeepSeek-V2 除外):包含优化规则的 YAML 文件路径。有两个规则文件预先写在 ktransformers/optimize/optimize_rules目录中,用于优化 DeepSeek-V2 和 Qwen2-57B-A14,两个 SOTA MoE 模型。
--cpu_infer:Int(默认 = 10)。用于推理的 CPU 数量。理想情况下应该设置为(核心总数 - 2)。
API形式,严格注意–cache_lens参数和max_new_tokens,有可能会出现总长度超过了cache_lens的情况,必要可以按照官方的来,去掉cache_lens和temperature
python /root/ktransformers/ktransformers/server/main.py --model_path xxx --gguf_path xxx --port 8888 --cpu_infer 65 --cache_lens 1536 --max_new_tokens 8192 --host 0.0.0.0 --temperature 0.6
V0.2.1版本
测试版本v0.2.1
内存消耗:754.6G
prompt eval count: 6 token(s)
prompt eval duration: 0.9745948314666748s
prompt eval rate: 6.156404493722336 tokens/s
eval count: 902 token(s)
eval duration: 133.06817030906677s
eval rate: 6.778480517955548 tokens/s
评估了 902 个 token,用时 133.06817030906677 秒,评估速率约为 6.78 个 token / 秒

V0.3.0版本(注意:我这里只是替换了官方0.3.0的轮子)
直接安装用的版本是v0.2.1,使用官方的轮子下载v0.3.0
https://github.com/kvcache-ai/ktransformers/releases/download/v0.1.4/ktransformers-0.3.0rc0+cu126torch26fancy-cp311-cp311-linux_x86_64.whl
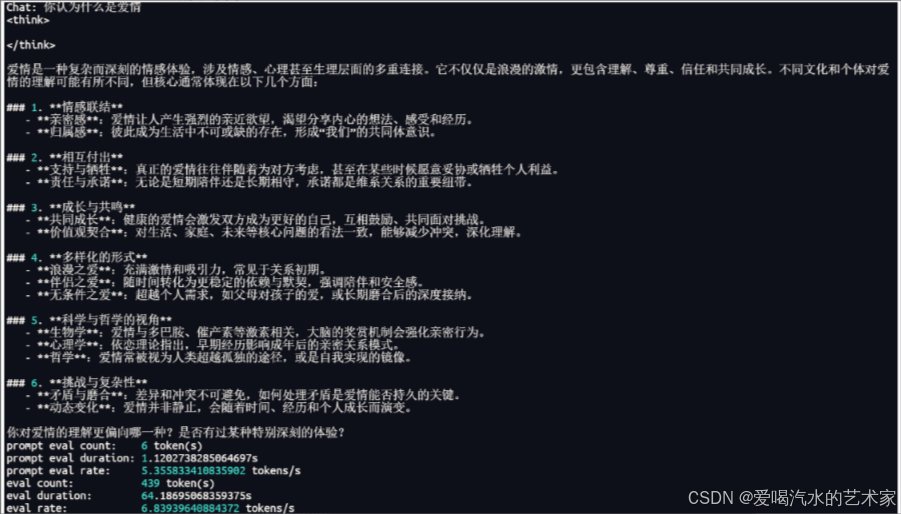
测试版本v0.3.0
prompt eval count: 6 token(s)
prompt eval duration: 1.1202738285064697s
prompt eval rate: 5.355833410835902 tokens/s
eval count: 439 token(s)
eval duration: 64.18695068359375s
eval rate: 6.83939640884372 tokens/s
评估了 439 个 token,用时 64.18695068359375 秒,评估速率约为 6.84 个 token / 秒

















 1662
1662

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









