







整个过程梳理
假设只有两层神经网络如下图:
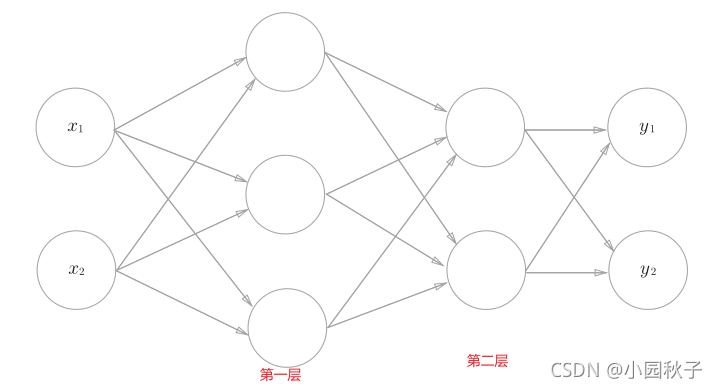
1 只有两个数据
若只有2个数据,则
1 数据先输入神经网络,然后在第一层进行计算,计算之后采用sigmoid函数进行变换。这里将有一批权重W1和偏置b1这里注意,并不是说只有W1和b1两个数,而是说有一批W1和b1,它们对于不同的神经元节点是不同的值,初始化的时候采用符合高斯分布的随机数进行初始化
2 然后传入第二层进行计算,使用softMax进行变换,然后输出。这里和上面一样有W2和b2
3 输出之后若使用交叉熵误差当做损失函数,如下
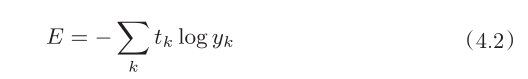
4 计算该损失函数对于权重W1、b1、W2、b2的偏导数(梯度)
5 更新权重参数和偏置,W1 = W1 - 步长 * 损失函数对于W1的偏导数,b1、W2、b2同理。
这里说一下我对 W1 = W1 - 步长 * 损失函数对于W1的偏导数。这个公式或者方法的理解,我找了很久都没有找到这个的严格数学定义,只听到别人说这是人工定义的就是这么干。为什么这么干呢,举个例子如下图:
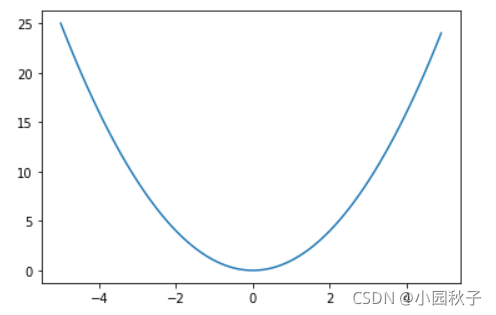
这是y = x^2的图像,随机选一点,你会发现,不管这个点在哪里,使用上面的公式都会发现x会朝x=0的方向更新。x为负或x为正都一样。
6 不断重复1 ~ 5这样进行更新权重和偏置
2 踩用多批次
若每次输入mini_batch批的数据,
则上面的3 会不同,上面的3 计算会变成下面这个
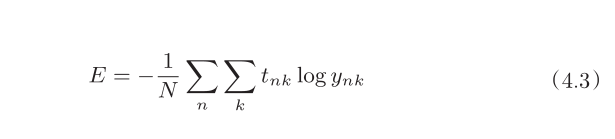
其它都一样。
整个更新权重的过程大致就这样了。
最后使用《深度学习入门:基于Python的理论与实现》书中的一段解释原话:


















 1719
1719

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









