









组合两个表
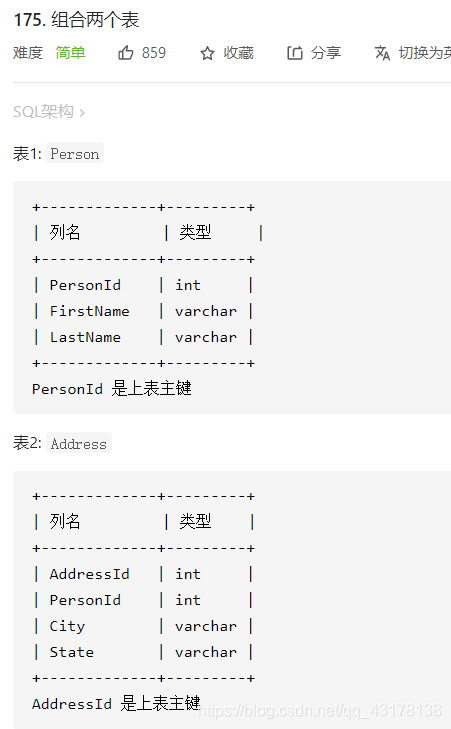
因为表Address中的personld是表Person的外关键字,可以连接两个表来获取一个人的地址信息。
考虑到可能不是每个人都有地址信息,该使用left join而不是默认的inner join。
select FirstName,LastName,City,State
from Person left join Address
on Person.PersonId = Address.PersonId;
第二高的薪水
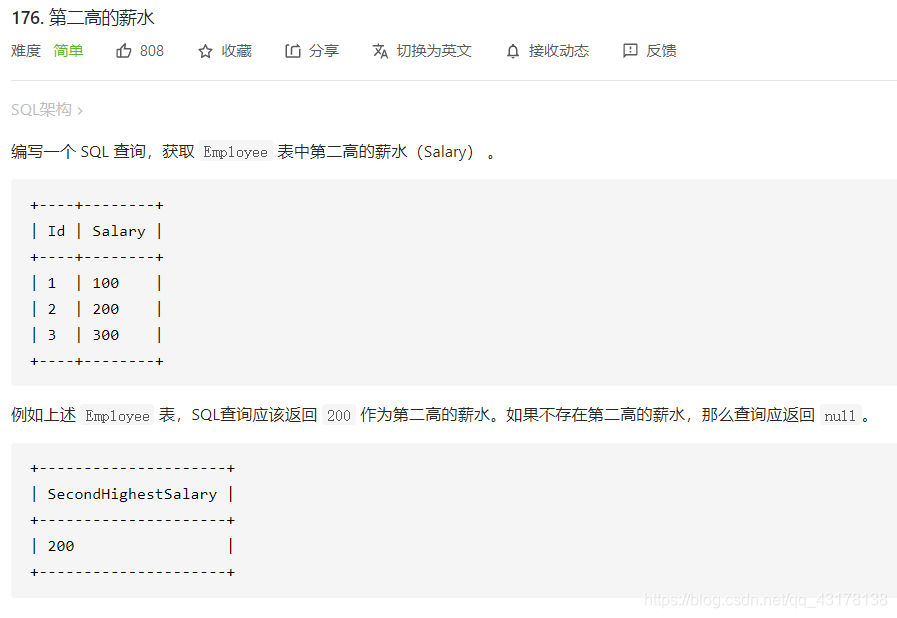
select distinct Salary as SecondHighestSalary
from Emplyee
order by Salary desc
limit 1 offset 1;
如果没有这样的第二高,比如只有一项记录,会被判错。
但是看评论区说这样写也是可以的…
select
(
select distinct Salary
from Employee
order by Salary desc
limit 1 offset 1
)as SecondHighestSalary;
select
ifnull(
(select distinct Salary
from Employee
order by Salary desc
limit 1 offset 1), null
) as SecondHighestSalary;
部门工资最高的员工
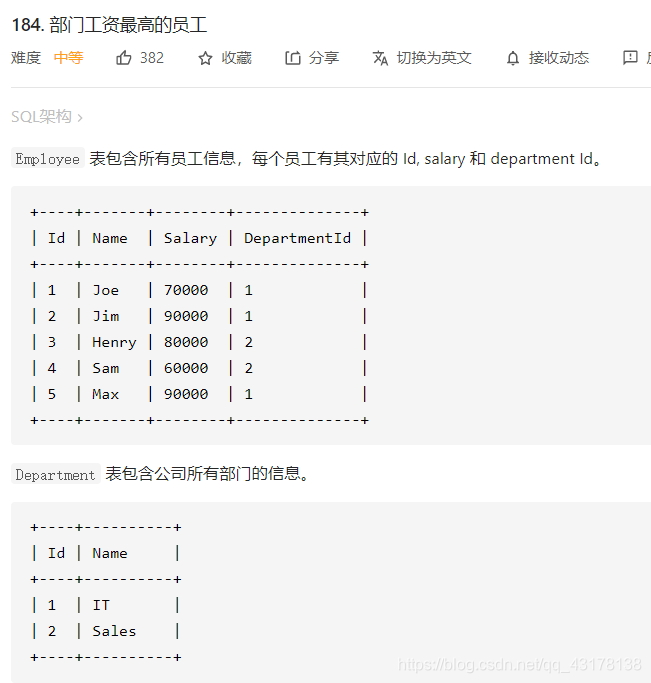

因为Employee表包含Salary和Departmentld字段,我们可以在此部门内查询最高工资。
select DepartmentId, MAX(Salary)
from Employee
group by DepartmentId;
可能有多个员工同时拥有最高工资,所以最好在这个查询中不包含雇员名字的信息。
select
Department.name AS 'Department',
Employee.name AS 'Employee',
Salary
from
Employee join Department on Employee.DepartmentId = Department.Id
where
(
(Employee.DepartmentId, Salary) in
(
select
DepartmentId, max(Salary)
from
Employee
group by DepartmentId
)
)
部门工资前三高的所有员工
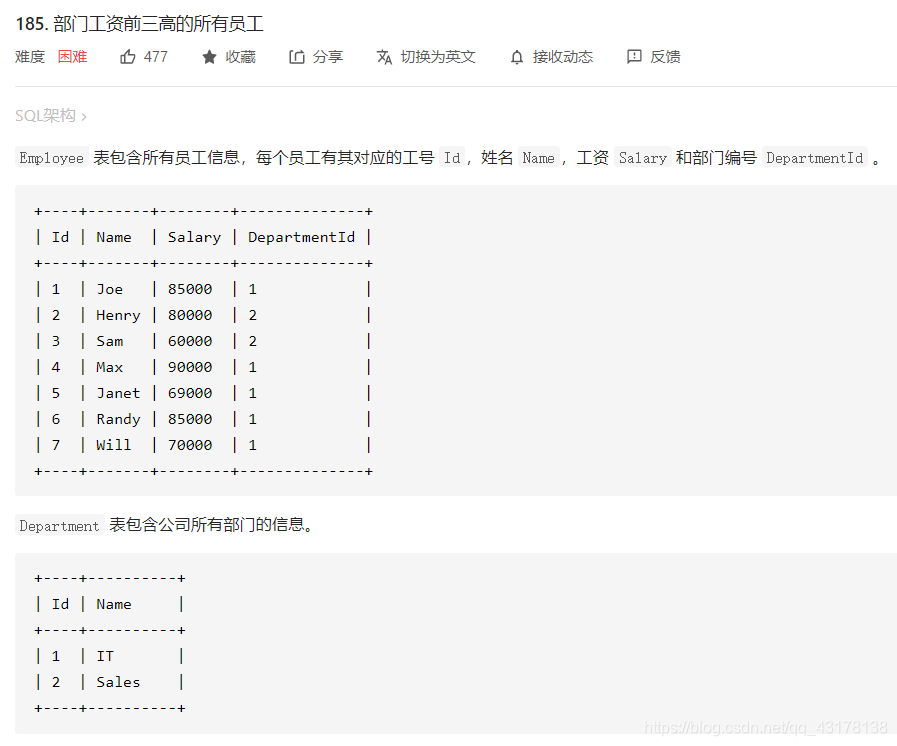
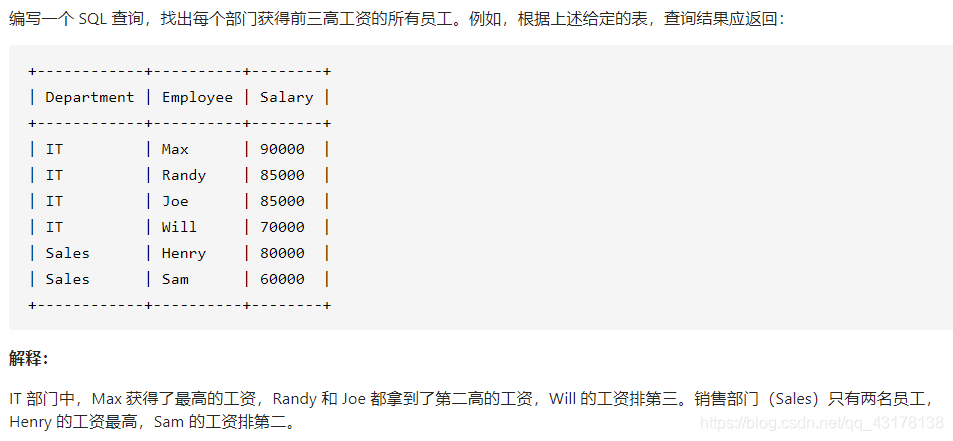
公司里前3高的薪水意味着有不超过3个工资比这些值大。
select el.Name as 'Employee',el. Salary
from Employee el
where 3 >
(
select count(distinct e2.Salary)
from Employee e2
where e2.Salary > e1.Salary
);
select
d.Name as 'Department',
e1.Name as 'Employee',
e1.Salary
from
Employee e1
join
Department d
on e1.DepartmentId = d.Id
where
3 > (
select
count(distinct e2.Salary)
from
Employee e2
where
e2.Salary > e1.Salary
and
e1.DepartmentId = e2.DepartmentId
);
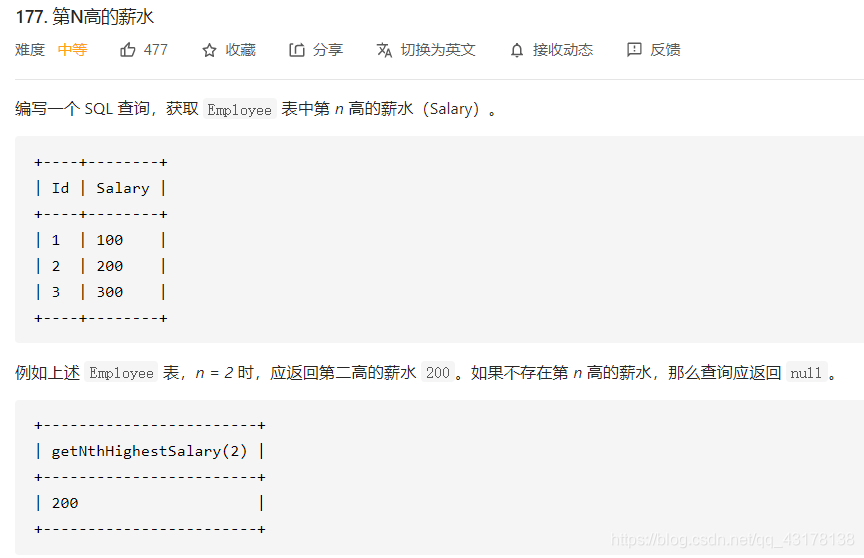
第N高的薪水
select
distinct e1.Salary as 'getHthHighestSalary'
from
Employee e1
where
(select
count(distinct salary)
from
Employee e2
where
e2.salary>e1.salary
)=N-1;
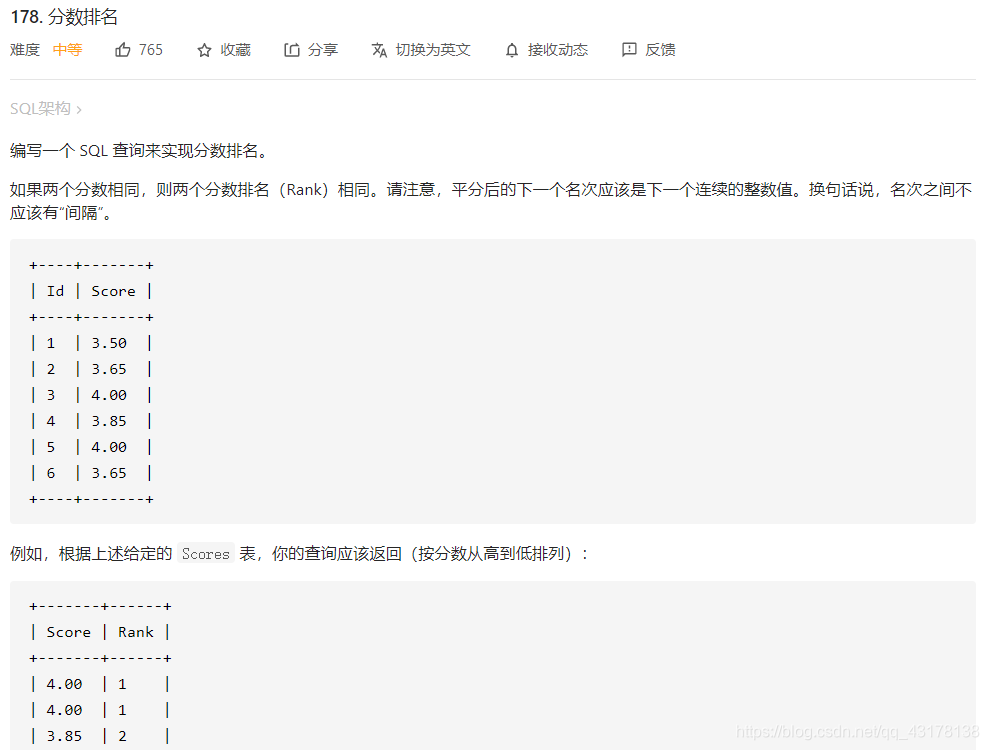
分数排名
- rank() over([partition by col1] order by col2)
- dense_rank() over([partition by col1] order by col2)
- row_number() over([partition by col1] order by col2)
其中[partition by col1]可省略,(PARTITION BY 将结果集划分为分区,并对分区数据的每个子集执行计算)。
三个分析函数都是按照col1分组内从1开始排序
- row_number() 是没有重复值的排序(即使两天记录相等也是不重复的),可以利用它来实现分页
- dense_rank() 是连续排序,两个第二名仍然跟着第三名
- rank() 是跳跃拍学,两个第二名下来就是第四名
SELECT Score,
dense_rank() over(order by Score desc) as 'Rank'
FROM Scores
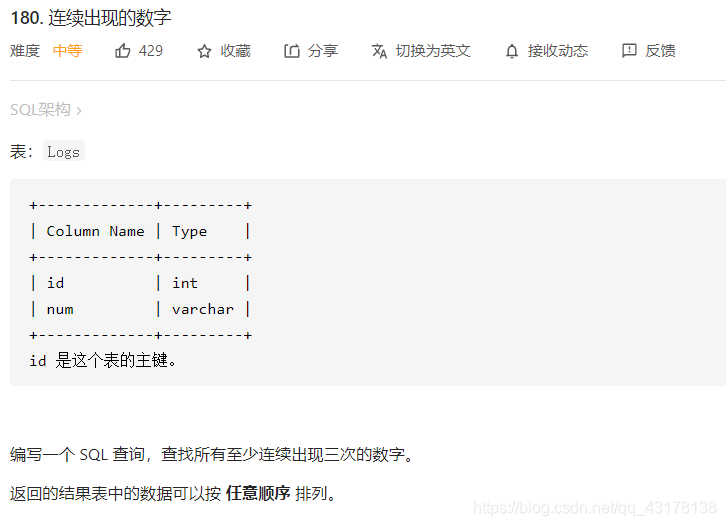
连续出现的数字
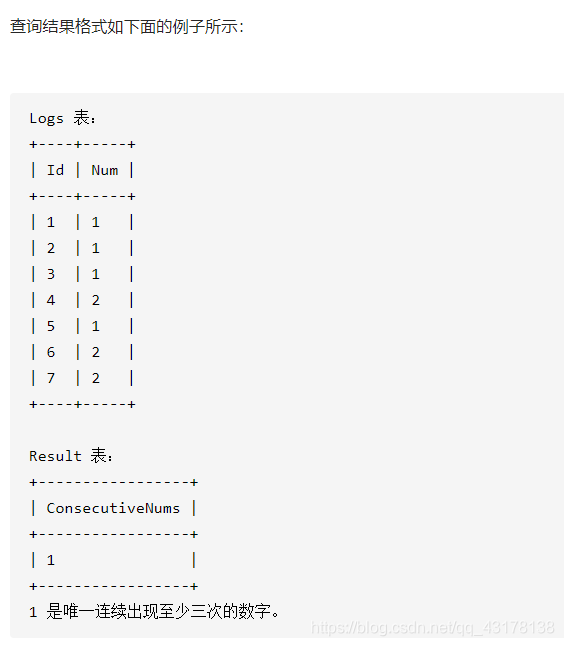
利用用户变量实现对连续出现的值进行计数:
select distinct Num as ConsecutiveNums
from (
select Num,
case
when @prev = Num then @count := @count + 1
when (@prev := Num) is not null then @count := 1
end as CNT
from Logs, (select @prev := null,@count := null) as t
) as temp
where temp.CNT >= 3
与自关联或自连接相比,这种方法的效率更高,不受Logs表中的Id是否连续的限制,而且可以任意设定某个值连续出现的次数。
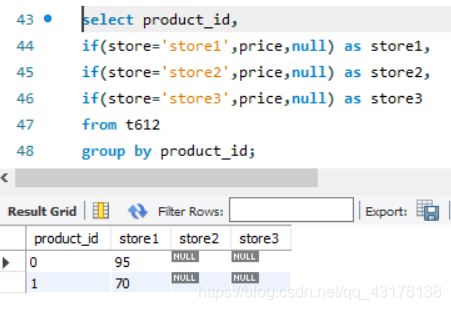
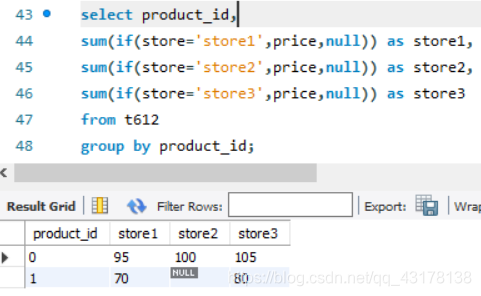
每家商店的产品价格
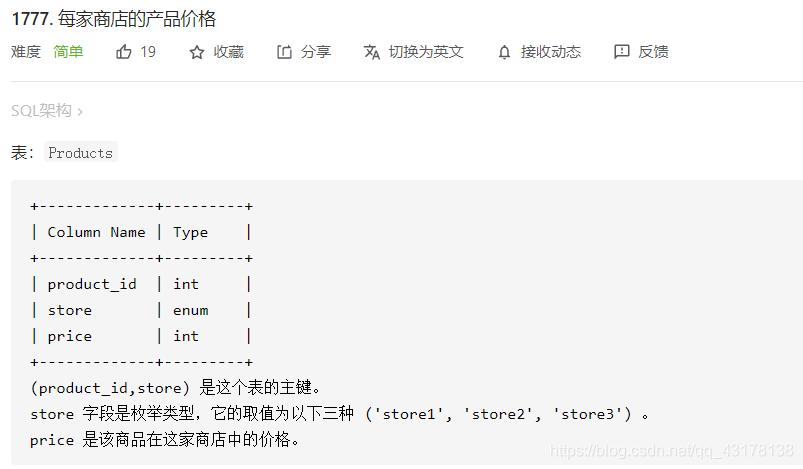

select product_id,
max(if(store='store1',price,null)) as store1,
max(if(store='store2',price,null)) as store2,
max(if(store='store3',price,null)) as store3
from Products
group by product_id;
在select指定的字段要么就要包含在Group By语句的后面,作为分组的依据;要么就要被包含在聚合函数中。
超过经理收入的员工

子链接:
select e1.Name as 'Employee'
from Employee e1
where e1.Salary >
(
select e2.Salary
from Employee e2
where e2.Id = e1.ManagerId
);
自链接:
select e1.Name as 'Employee'
from Employee e1, Employee e2
where e1.ManagerId = e2.Id
and e1.Salary > e2.Salary
删除重复的电子邮箱
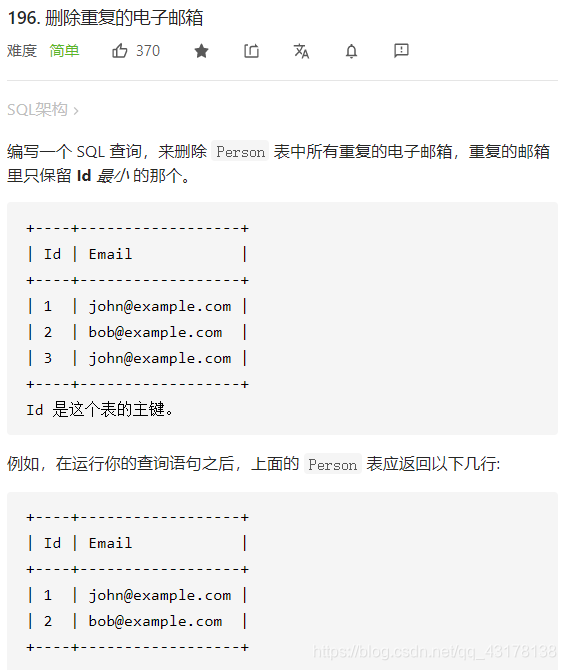
delete p1
from Person p1, Person p2
where p1.Email = p2.Email
and p1.Id > p2.Id;
delete使用别名的时候,要在delete和from间加上删除表的别名。
行程和用户
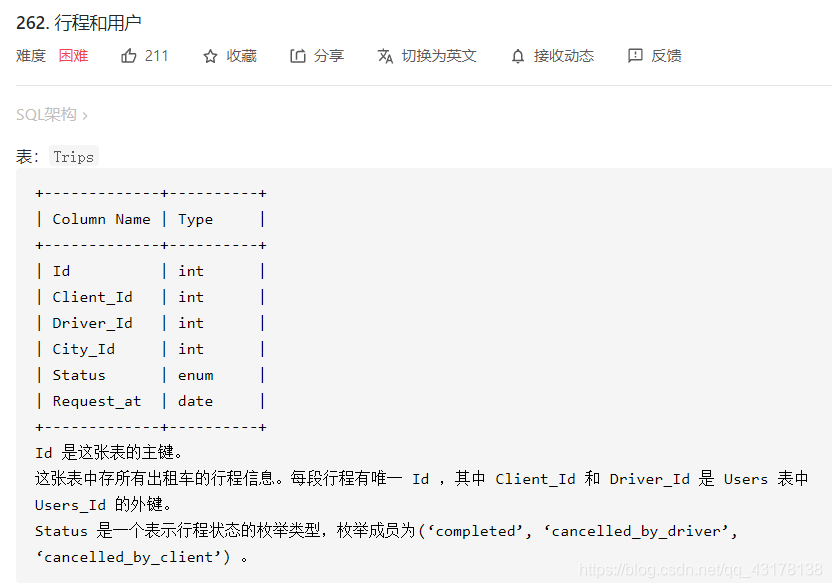

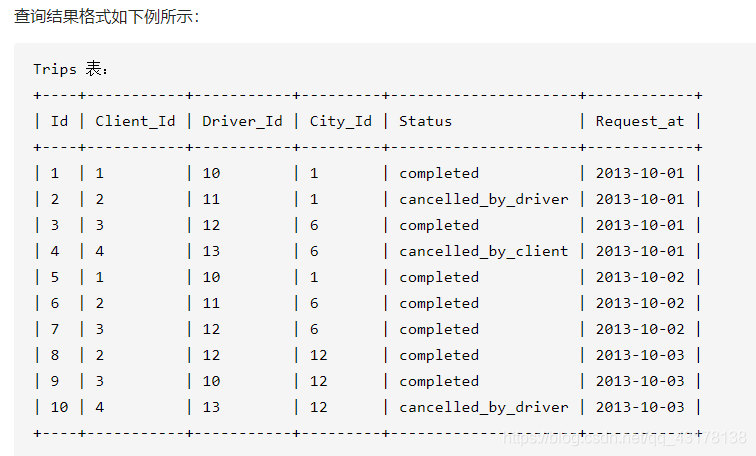
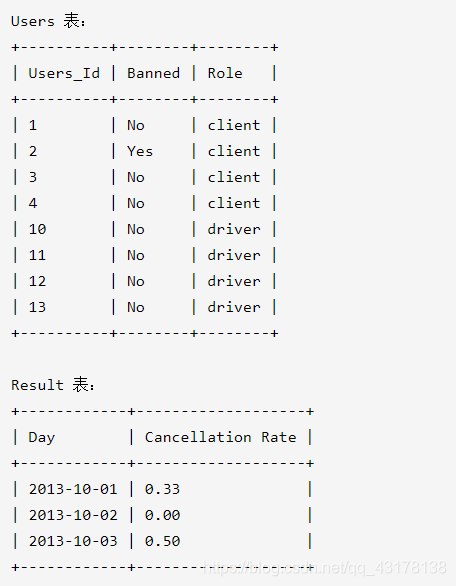

首先确定被禁止用户的行程记录,再剔除这些行程记录。行程表中,字段client_id和driver_id,都与用户表中的user_id关联。因此只要client_id和driver_id中有一个被禁止了,此条行程记录要被剔除。
select *
from
Trips as T
join Users as u1
on
(T.client_id = u1.users_id and u1.banned='No')
join Users as u2
on
(T.driver_id = u2.users_id and u2.banned='No')
完整的:
select T.request_at as 'Day',
round(
sum(
if(T.status = 'completed',0,1)
)/count(T.status),2) as 'Cancellation Rate'
from Trips as T
join Users as u1 on
(T.client_id = U1.users_id and U1.banned ='No')
join Users as u2 on
(T.driver_id = U2.users_id and U2.banned ='No')
where T.request_at between '2013-10-01' and '2013-10-03'
group by T.request_at
round是四舍五入函数。
体育馆的人流量


select t1.*
from stadium t1, stadium t2, stadium t3
where t1.people >= 100 and t2.people >= 100 and t3.people >= 100
and
(
(t1.id - t2.id = 1 and t1.id - t3.id = 2 and t2.id - t3.id =1) -- t1, t2, t3
or
(t2.id - t1.id = 1 and t2.id - t3.id = 2 and t1.id - t3.id =1) -- t2, t1, t3
or
(t3.id - t2.id = 1 and t2.id - t1.id =1 and t3.id - t1.id = 2) -- t3, t2, t1
)
;
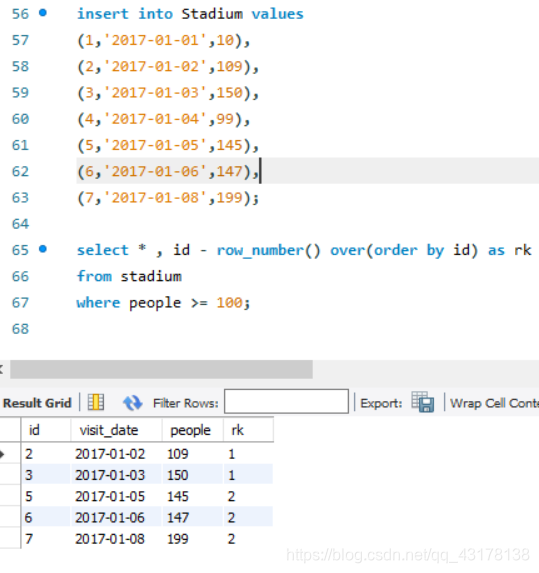
with t1 as(
select *,id - row_number() over(order by id) as rk
from stadium
where people >= 100
)
select id,visit_date,people
from t1
where rk in(
select rk
from t1
group by rk
having count(rk) >= 3
)


















 601
601

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









