



 本文全面介绍了SQL的基础知识,涵盖数据查询、数据更新、表与数据管理等方面。详细讲解了如何使用SQL语句进行数据检索、处理缺失值、聚合函数应用及复杂查询技巧等。
本文全面介绍了SQL的基础知识,涵盖数据查询、数据更新、表与数据管理等方面。详细讲解了如何使用SQL语句进行数据检索、处理缺失值、聚合函数应用及复杂查询技巧等。
一、处理的什么类型数据
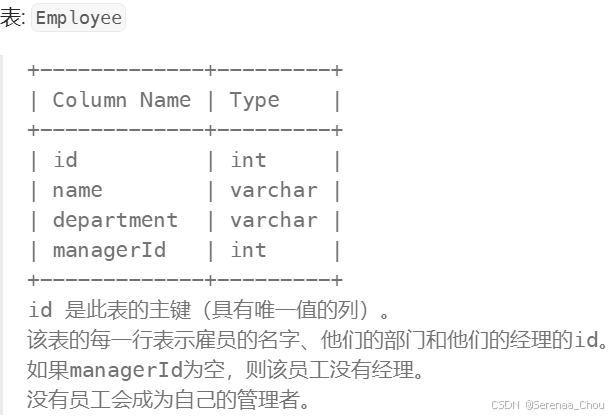
用SQL处理关系型DBMS(数据之间有关联relationship)databases management systems
首先介绍一下使用到的数据们,对应的是某站Mosh老师提供的数据资源。先来简单看一下各表格数据特征:
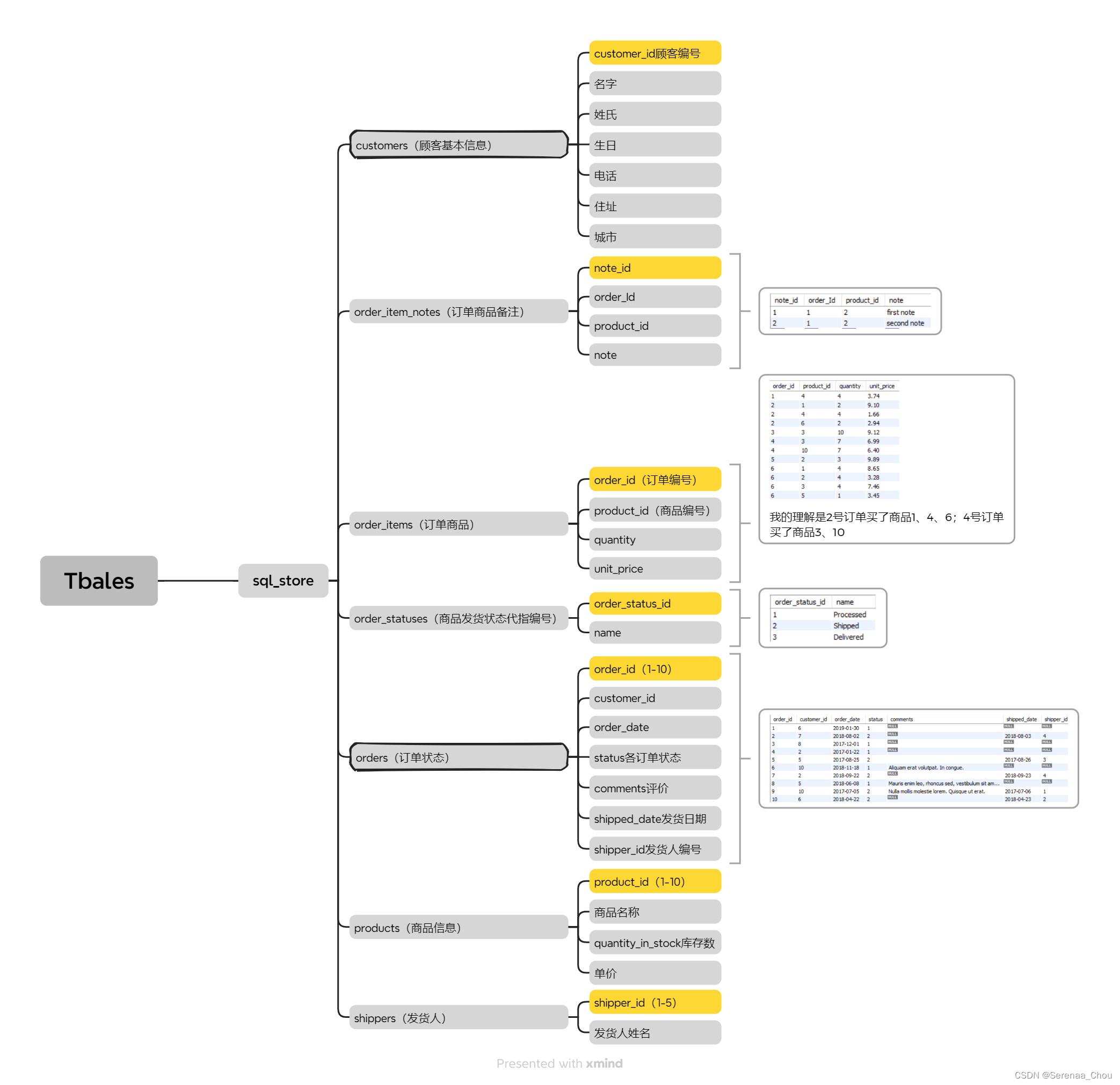
可见,对于order_items(订单商品)表格:每一订单都可能对应多个product
对于order_statuses、products、shippers表格:里面的编号是一一对应的(可以理解为spss中的新旧值转换hh)
二、基本语句
1、选择语句SELECT * FROM xxx 及其子句:
大间隔、换行、tab等在SQL处理中无用,所以可以将语句放置一行。
需用;终止上一语句。
在语句前加上--表示注释。
1.一般查询顺序和逻辑如下:使用数据库-从指定表格中提取所有行列-查找指定的-排序等,顺序不能错
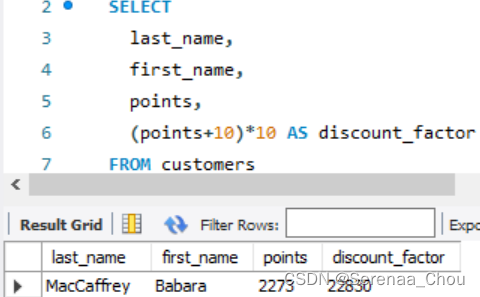
2.利用AS来对旧值进行处理,产生新值列,如要生成discount factor(中间有空格)则须加引号,即AS ’discount factor’
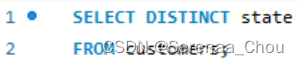
3. DISTINCT可以查找某一列的所有唯一值(剔除重复出现的)
练习题:

答:
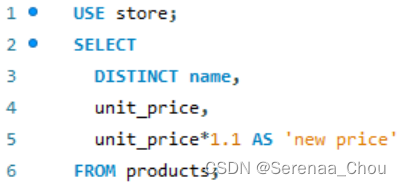
注意:new price这一新列不会被保存在products表格中,这是因为SELECT语句仅仅是在检索数据时计算和显示该新列,而不会在原始表格中创建或保存这个新列。
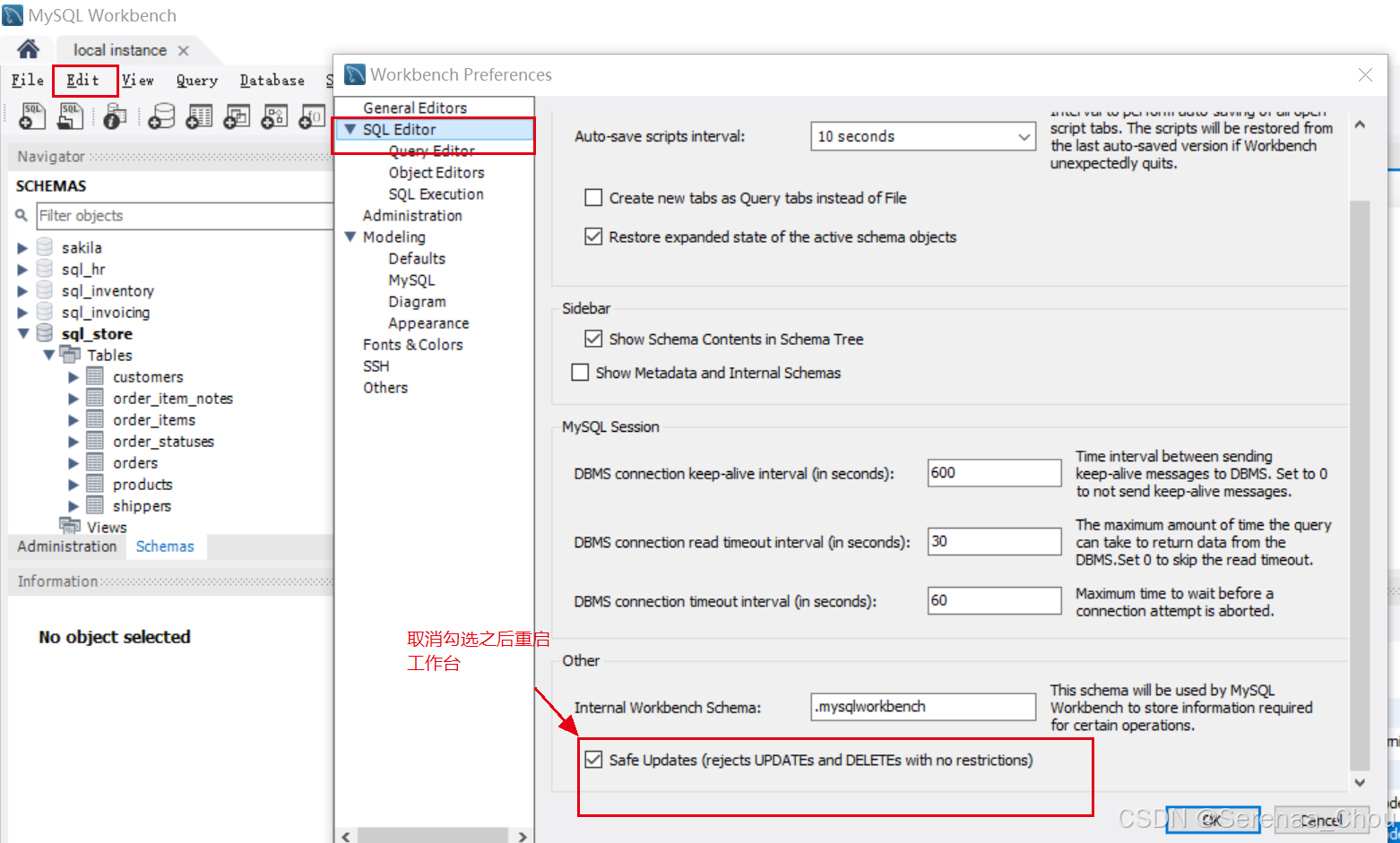
在插入新列之前,由于MySQL具有的原表格数据保护机制不能直接update,需要取消勾选之后才能进行增改:
-- 添加新列 discount_price 到 customers 表
ALTER TABLE sql_store.customers
ADD COLUMN discount_price DECIMAL(10,2);
-- 更新 discount_price 列的值
UPDATE sql_store.customers
SET discount_price = (points + 10) * 10;如果想要删除discount_price这列:
ALTER TABLE sql_store.customers
DROP COLUMN discount_price;2、WHERE子句:
字符串加上单引号,日期也需要加引号。
不等号可以用!=或<>表示。
练习题:
![]()
答:
AND子句,前后两个条件都需要正确;OR子句,两个条件只需正确一个。
AND逻辑会被先执行,可使用括号改变优先级。
NOT语句否定的是所有的,例如
![]()
等价于WHERE birth_date <= ‘1970-01-01’ AND points <= 1000
练习题

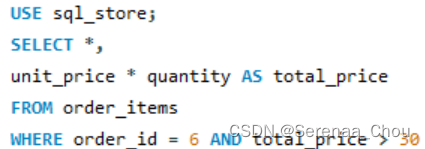 (有误,原因是:不能在 WHERE 子句中使用 SELECT 中的别名。因此,你无法在 WHERE 子句中使用 total_price 这个别名。你需要使用实际的列名或者重复计算总价来实现这一目的,改正:)
(有误,原因是:不能在 WHERE 子句中使用 SELECT 中的别名。因此,你无法在 WHERE 子句中使用 total_price 这个别名。你需要使用实际的列名或者重复计算总价来实现这一目的,改正:)
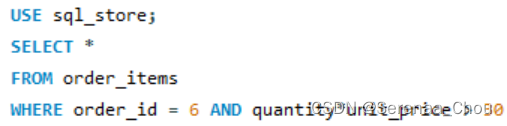
IN子句
多个条件可选择时,IN相当于建立一个集合,集合内为同属性
![]()
等价于![]()
不包括于这个集合里面时,用NOT IN
练习
![]()
答:

BETWEEN运算符
查询介于…与…之间的
练习
![]()
答:

LIKE运算符
查询以某一字母开头,%表示后面带有任意个数字符串![]()
‘%b%’表示b前后都可以有任意字符串。
要确定前面字符串个数时,用下划线表示,每个下划线代表一个字符串’_y’表示两个字符,而最后结尾是y。
练习


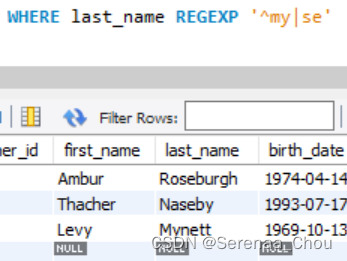
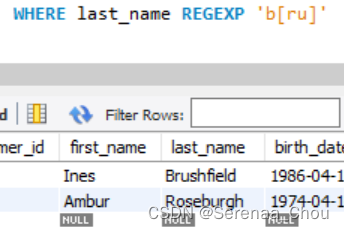
REGEXP子句(正则化表达)
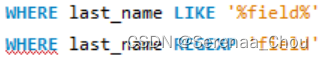 上下表达是等同的。
上下表达是等同的。
’^field’表示field打头;’field$’表示field结尾。
用|表示多个搜寻模式:
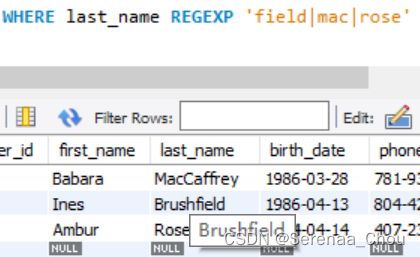
使用[ ]匹配任意括号里的单字符,例如[gi]e可以为ge、ie;[a-h]e表示a到h字母全都与e匹配一遍。
练习:

![]()
![]()
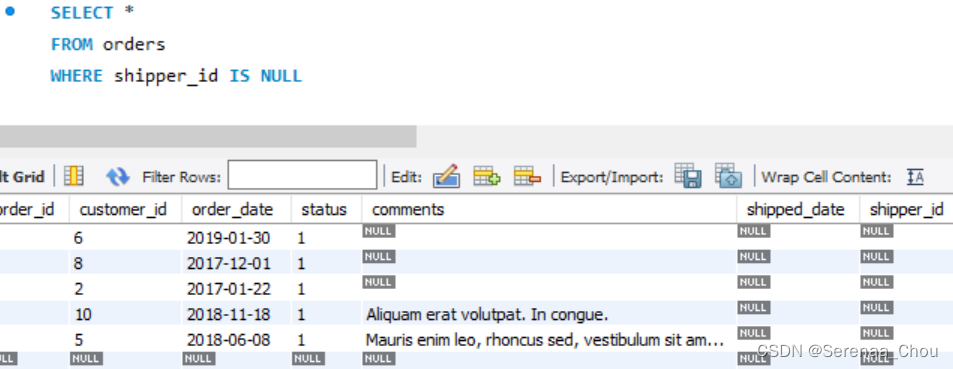
3、查询缺失值 IS NULL
用IS NOT NULL来查询非缺失值的样本。
练习:
![]()
Leetcode易错:


分析:在这里很容易想到这样的写法,然而这样是错误的,只能返回一个人,refree_id = null的人无法返回:
SELECT name
FROM Customer
WHERE referee_id != 2原因是,在传统的布尔逻辑中,只有TRUE和FALSE两种值。但在数据库中,特别是在处理NULL时,需要引入第三种逻辑值:UNKNOWN。这是因为与NULL进行比较时,我们无法确定其结果,因此结果被定义为UNKNOWN。例如,如果我们尝试比较一个NULL值和一个非NULL值,结果将是UNKNOWN,因为NULL没有一个明确的数值或状态。同样,如果我们尝试比较两个NULL值,结果也是UNKNOWN,因为我们无法确定它们之间的关系。
为了解决这个问题,MySQL提供了IS NULL和IS NOT NULL这两个操作符,它们专门用于检查字段是否为NULL。当我们使用IS NULL时,如果字段的值为NULL,查询将返回TRUE;如果字段的值不是NULL(包括字段中有值和字段为空),查询将返回FALSE。 同样地,IS NOT NULL用于检查字段值是否不是NULL。所以正确的写法应该是:
SELECT name
FROM Customer
WHERE referee_id != 2 OR referee_id IS NULL每张表都有一个主键列,由黄色标表示:id这一列为主键列
![]()
![]() 对first_name进行降序排列
对first_name进行降序排列
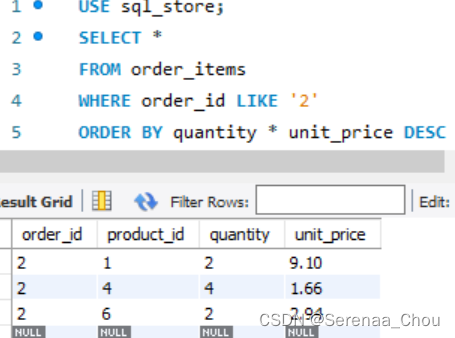
练习:
从一张表中选出id为2的,并把他们以总价排序
LIMIT子句(一般是放在最后的)
练习:
![]()
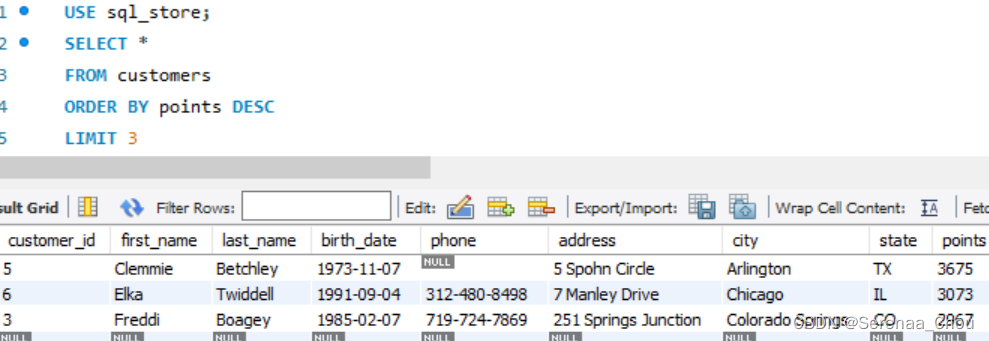
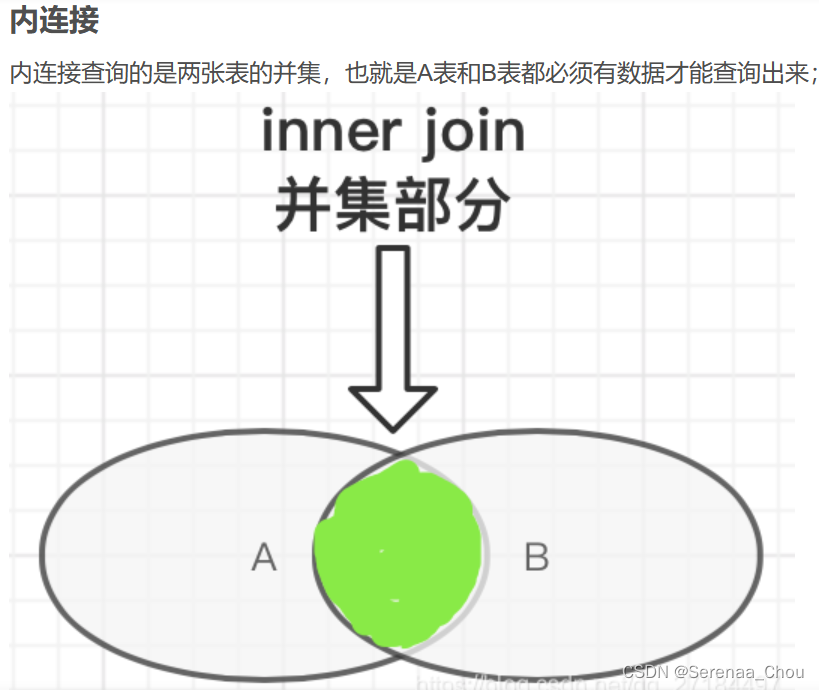
4、内连接 JOIN
各种JOIN见博客Mysql 多表连接查询 inner join 和 outer join 的使用 - 王默默 - 博客园 (cnblogs.com)
PS.MySQL不支持OUTER JOIN,但是我们可以对左连接和右连接的结果做 UNION 操作来实现。
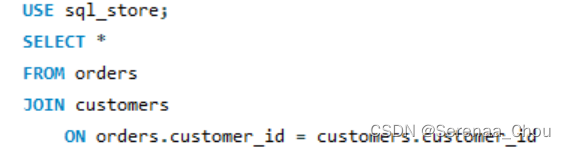
把两张表通过customer_id连在一起了,所有的列都还在,相当于通过customer_id匹配链接了两张表。而改成SELECT customer_id,first_name,last_name FROM orders,最终结果就只会显示这三列。
如果两张表有相同的列,就需要加上前缀来表明应该从哪张表中获取这一列。
简化表格名的写法:在FROM之后可以用上简化,前面的SELECT中表名也可以改成简化后的(注意:一旦用了简化,所有代码里该表都必须用简化后的来代指):
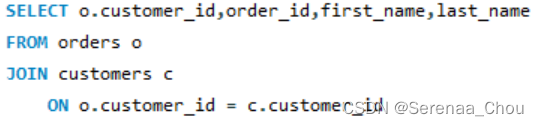
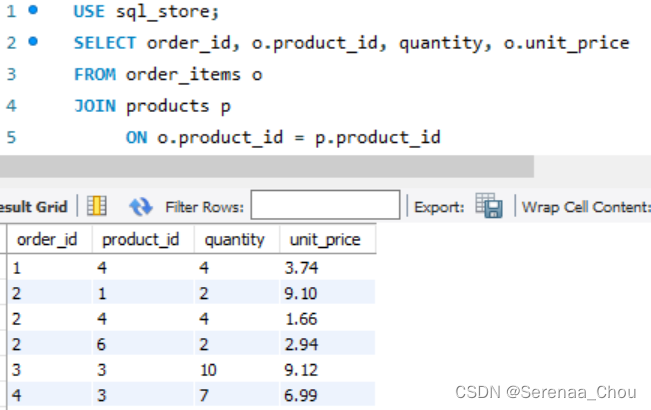
练习:
连接order_items和products表,结果应该如下:

答:
Leetcode易错:
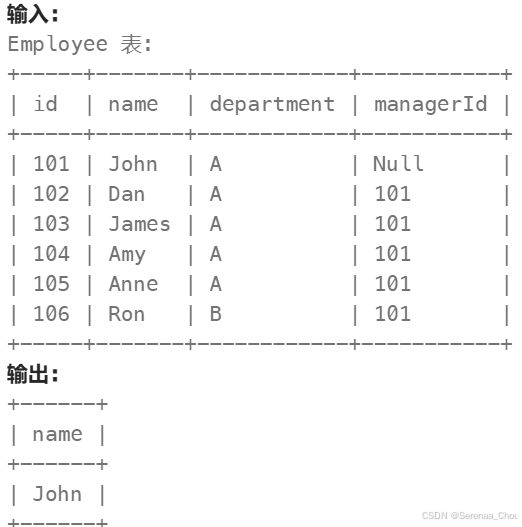
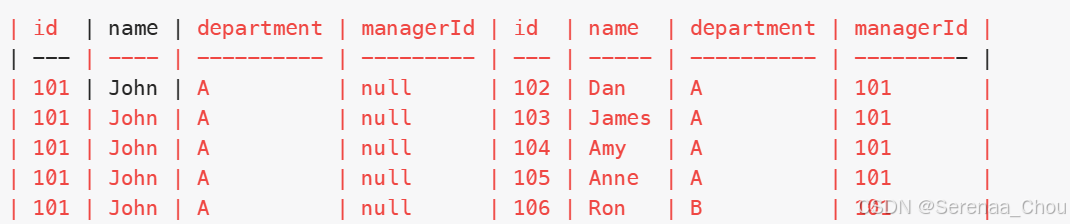
使用唯一标识码替换员工ID
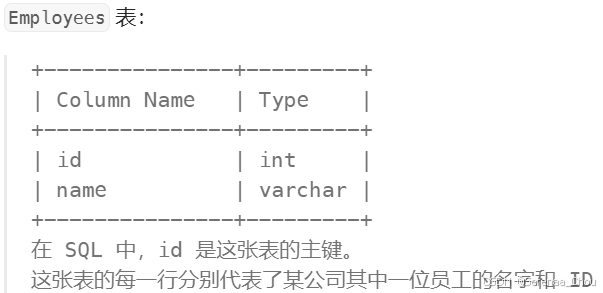


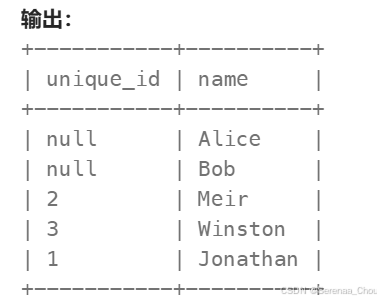

分析:看到输出结果是所有id都包含进去了的,所以这时就要区分左表和右表(由于MYSQL中没有FULL OUTER JOIN,所以以后就考虑(INNER)JOIN、LEFT JOIN、RIGHT JOIN就OK)。同时也要想着,有些表做了连接之后可能就已经达到想要的效果了,就不用再用额外的IF或者是CASE。
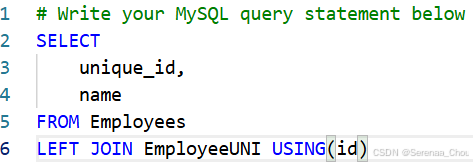
5、跨数据库连接
把数据库的名字放在前面作为前缀
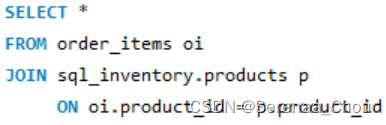
6、自连接
同一表内某列元素与另一列元素有关联
提取某几列:
Leetcode易错:

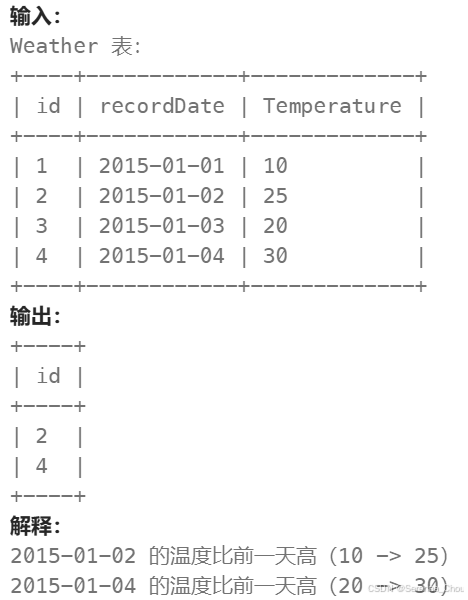
分析:这种表内数据与表内数据相比较的,想到了要用内连接。但是对于日期处理函数DATEDIFF不熟悉。
DATEDIFF: DATEDIFF(date1, date2) #date1-date2除了日期这里有一个条件之外,另外一个条件是温度的比较。所以可以一步步拆解来分析,首先引入日期条件,以原表为左表作为基准 SELECT *,之后再LEFT JOIN自己,这个时候得出的结果是左表为原表,加入的表是滞后一期的,到这一步之后就可以引入第二个条件比较温度了,需要注意的是temperature的前缀,即最终的结果是基于滞后一期的表上来看的。
SELECT
We.id AS id
FROM Weather W
LEFT JOIN Weather We ON
DATEDIFF(We.recordDate, W.recordDate) = 1
WHERE We.temperature > W.temperatureLeetcode易错:
计算每台机器的进程平均运行时间


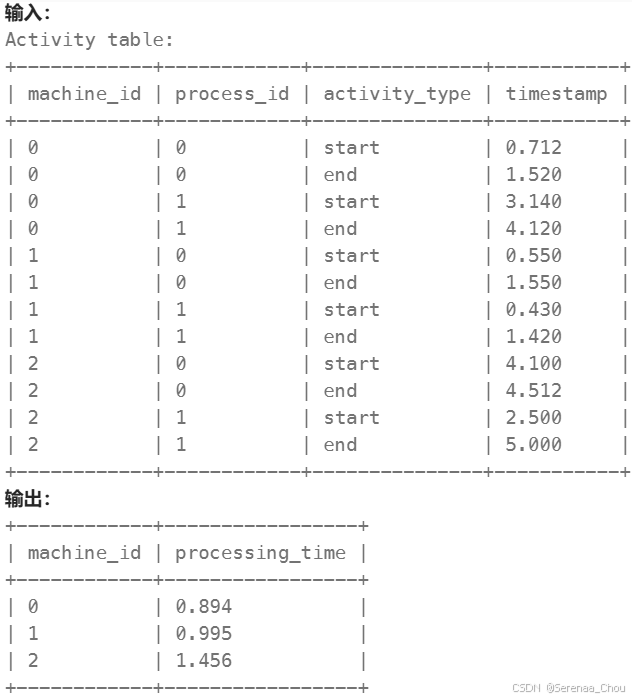
分析:大致方向是写对了,想到用自连接将start和end分离出来方便后面运算,但是要注意WHERE是要在JOIN之后的。而且在GROUP BY分组之后,计算每组均值可以直接用AVG了。
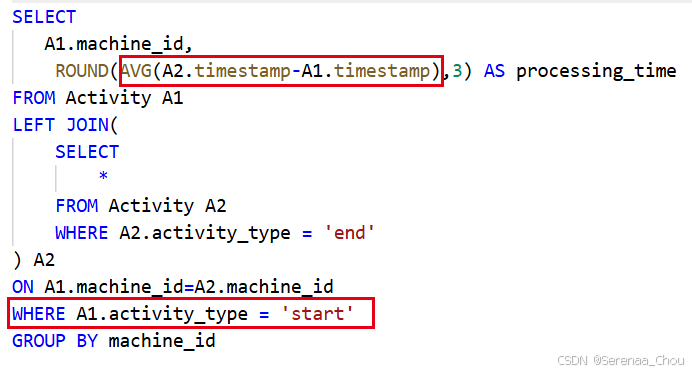
7、多表连接
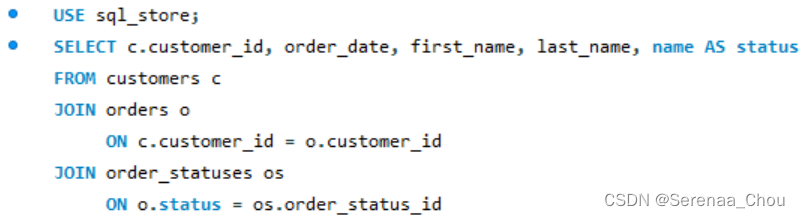
练习:
利用sql_invoicing里的三张表进行连接填充信息
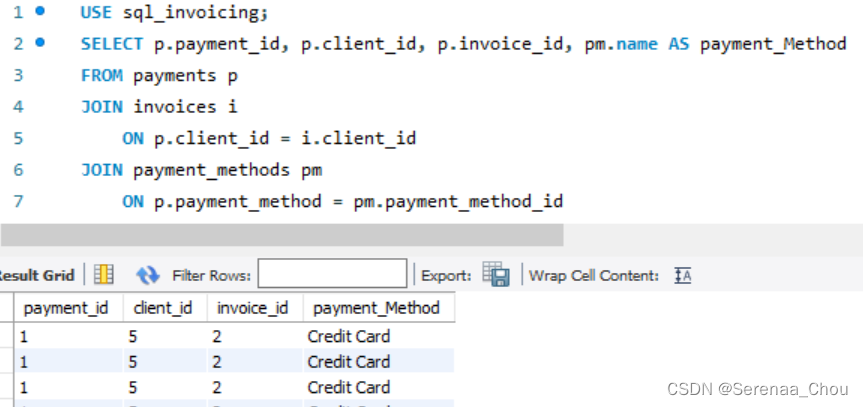
8、复合连接条件
JOIN后面除了ON还加个AND(具体为什么这样连接不太清楚)

Leetcode易错:
统计学生们参加各科测试的次数



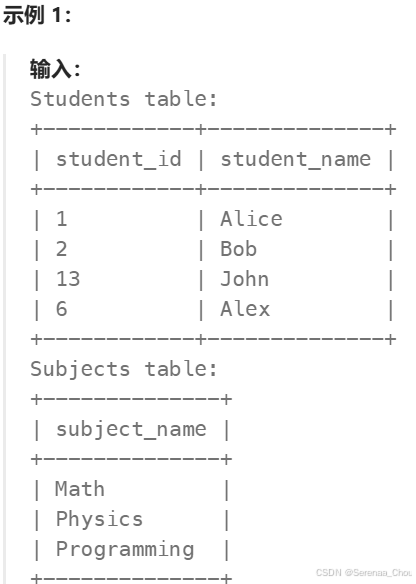
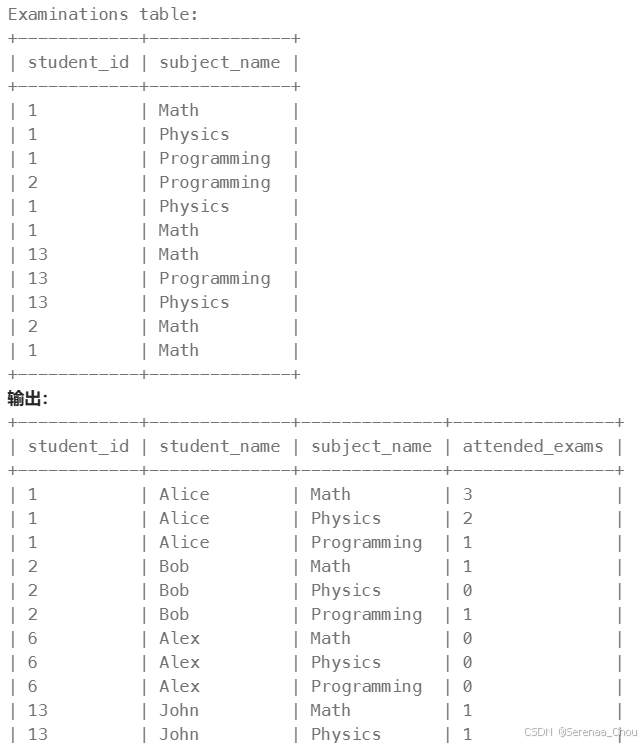
分析:这道题其实已经想到了利用CROSS JOIN,因为根据生成表的前三列,像是排列组合的呈现,而最后一列是利用COUNT函数求得次数,最后肯定要用到GROUP BY和ORDER BY,但问题就出现在【复合连接条件】上面,故将改题目归类至此。我是首先生成前三列,将其作为一个新表A,因为也要统计到attended_exams为0的情况,所以使用了LEFT JOIN连接Examinations表。这时可以打一个草稿,A表和Examinations表,如果只用student_id去连接的话,最后的出来的表格将会很长,因为Examinations表中的id会和A中每一个对应的id连接一边,生成的表很长,而我们最终要得到的数据是基于student_id和subject_name统计得到的,所以是复合条件。
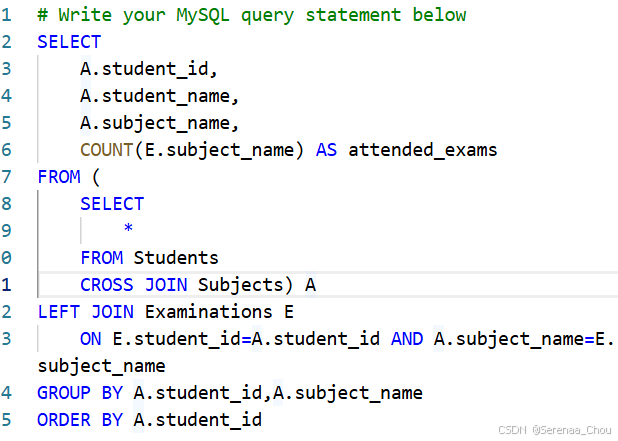
隐式连接语法
JOIN是显式链接,尽量用显式,隐式没有JOIN而是用的WHERE,容易出错。
9、外连接
之前的都是内连接,即(INNER)JOIN,内、外连接区别:
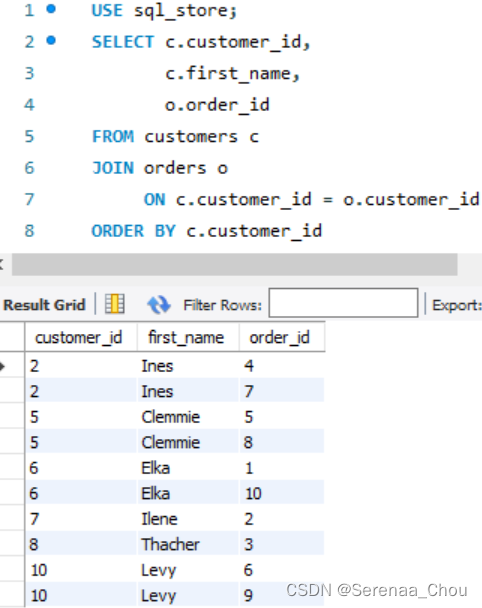
可见,内连接显示的是JOIN ON后面的条件,即没有下过单的顾客就没有出现在表格上。如果想把无论是否下单的所有顾客都列出,可以使用外连接(OUTER)JOIN。而首先需要区分一下左右连接的区别:
假如现在有两张表格
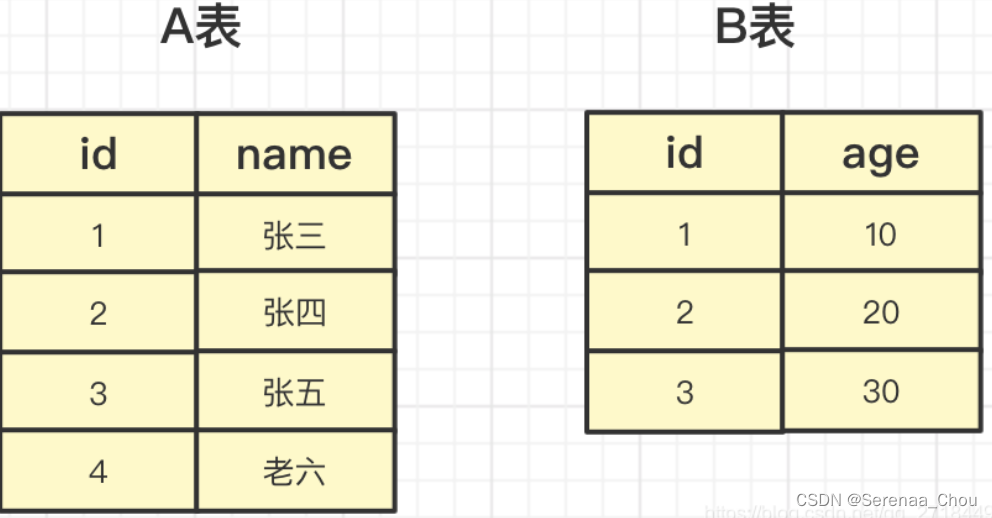
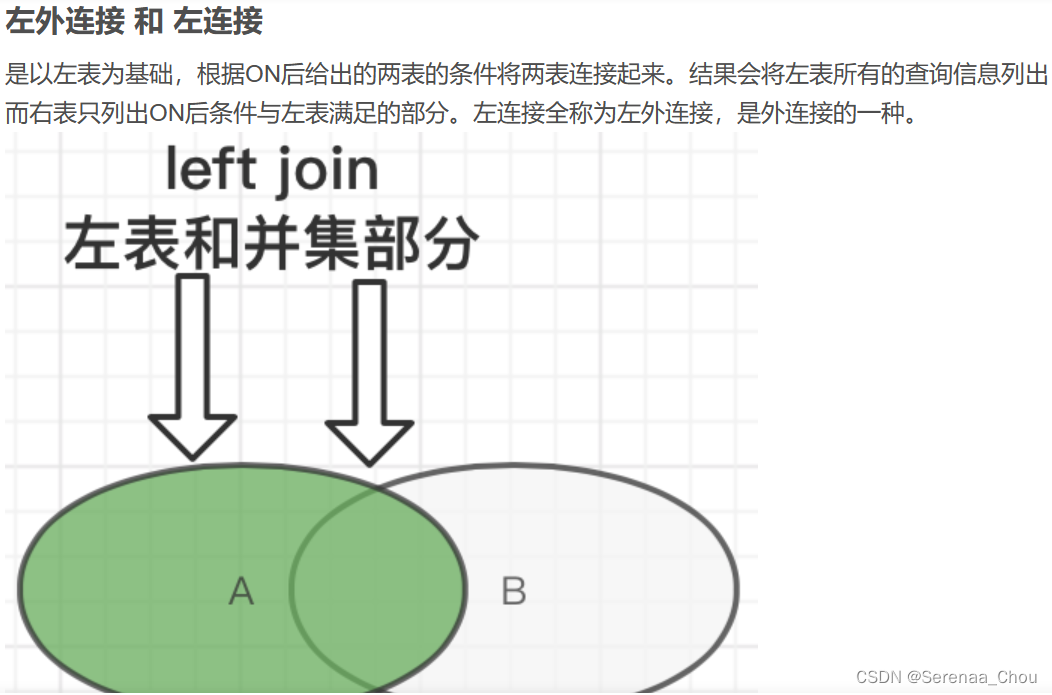
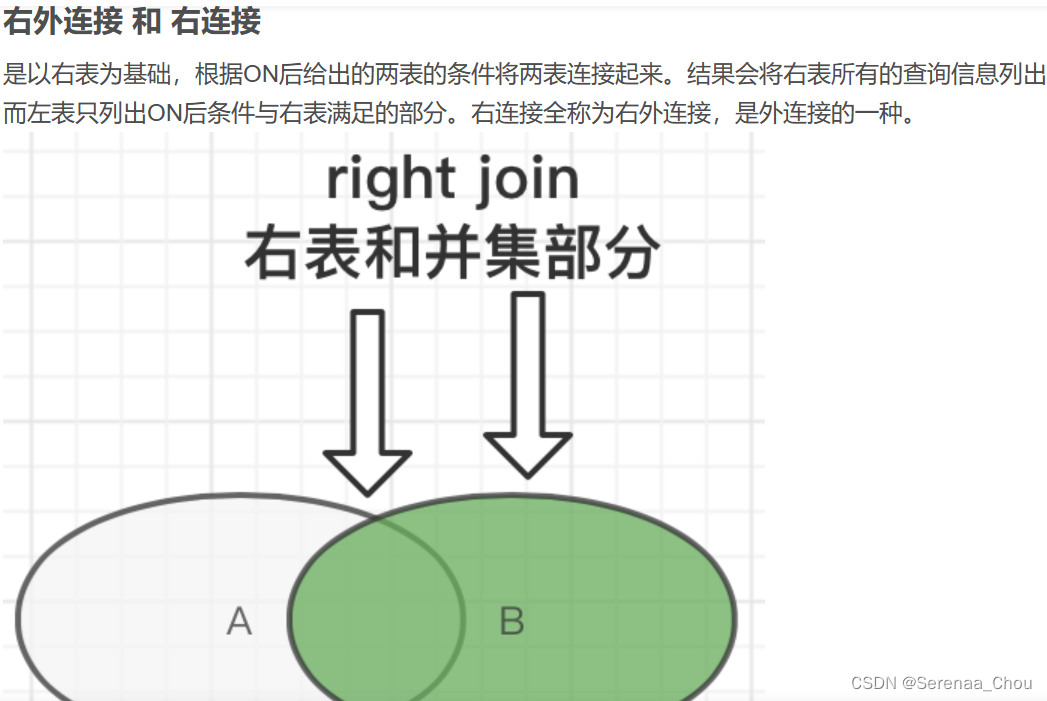
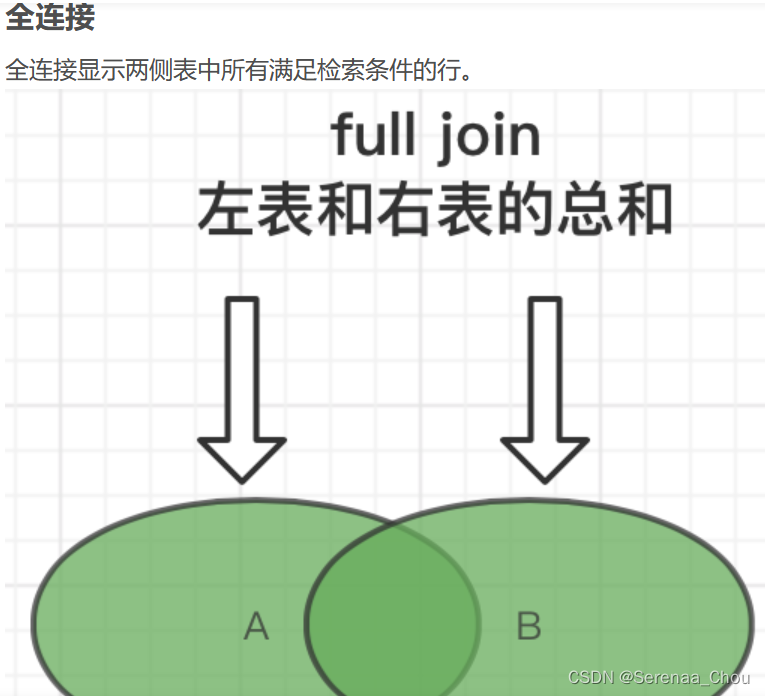
所以,如果是左连接,那么以左表customers为主表,所有顾客名字都会显示。
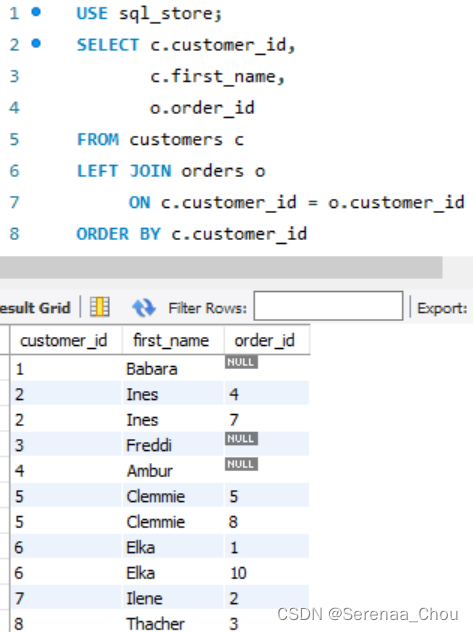
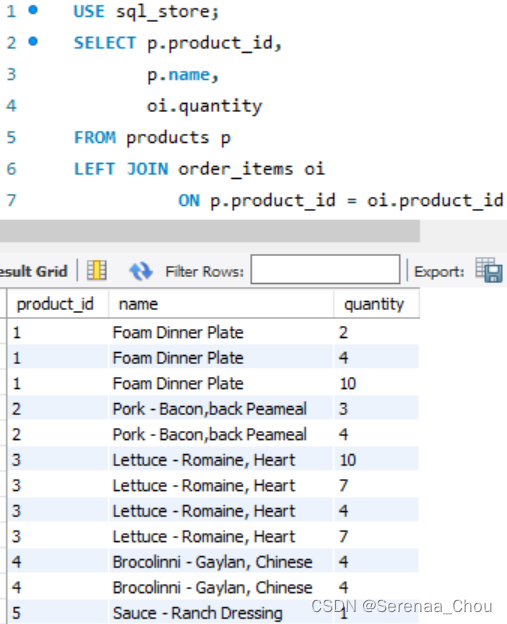
练习:找出所有货品的下单次数
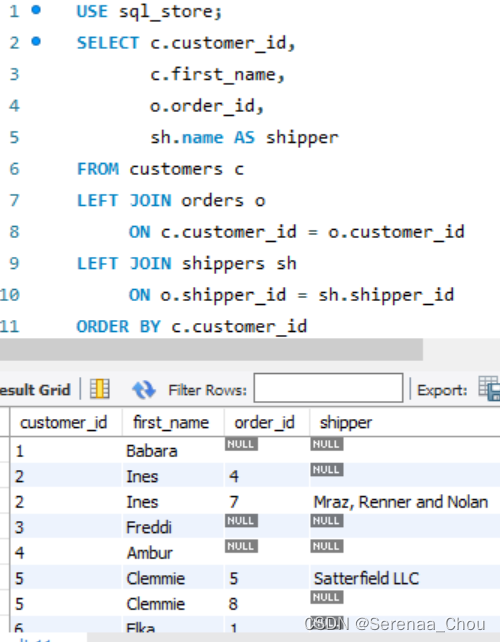
10、多表外连接
把发件人的名字填入上述例子的表格中作为补充。在连接的时候尽量都用左连接,不要一会儿左一会儿右。
练习:
写一段查询生成如下结果
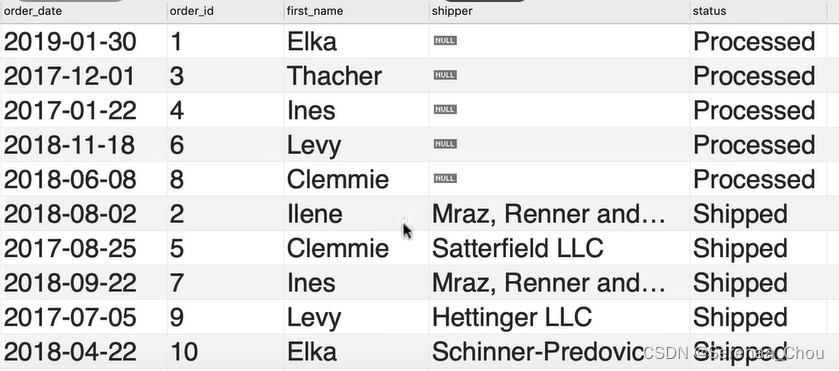
答:
USE sql_store;
SELECT o.order_date,
o.order_id,
c.first_name,
sh.name,
os.name AS status
FROM orders o
LEFT JOIN customers c
ON o.customer_id = c.customer_id
LEFT JOIN shippers sh
ON o.shipper_id = sh.shipper_id
LEFT JOIN order_statuses os
ON o.status = os.order_status_id
ORDER BY o.order_date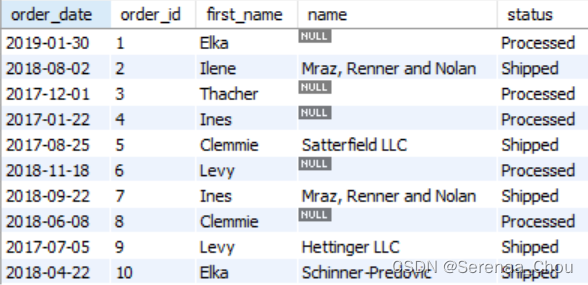
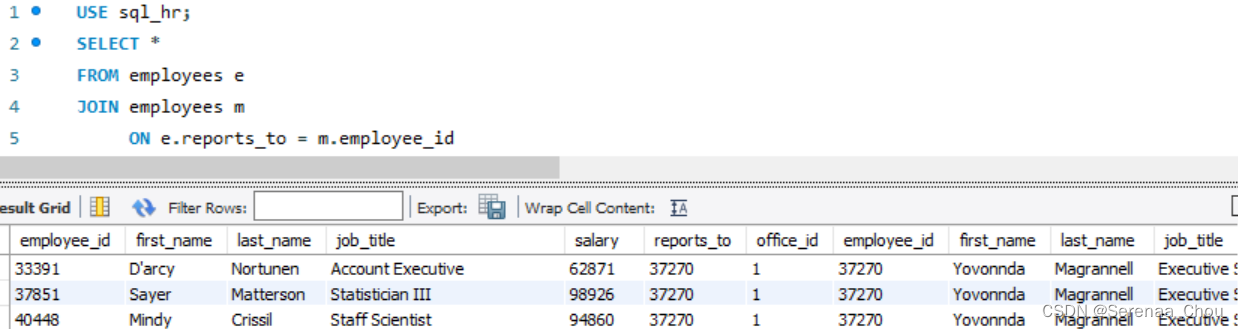
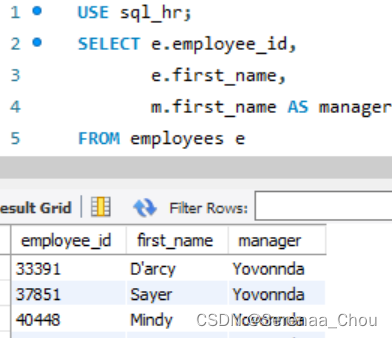
11、自外连接
以一个例子来说明:公司所有员工为一列,想要找出所有员工(包括CEO)的上司,可以利用自外连接
USE sql_hr;
SELECT e.employee_id,
e.first_name,
em.first_name AS manager
FROM employees e
LEFT JOIN employees em
ON e.reports_to = em.employee_id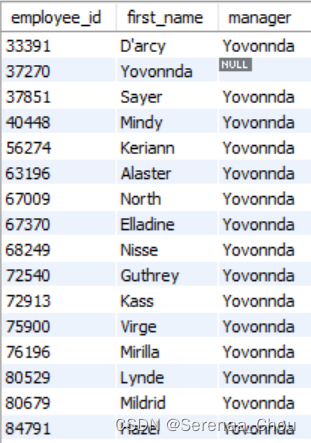
12、USING子句
利用USING子句,使得表与表之间的连接条件更加简洁(注意:只能用在不同表中列名一样的前提下)
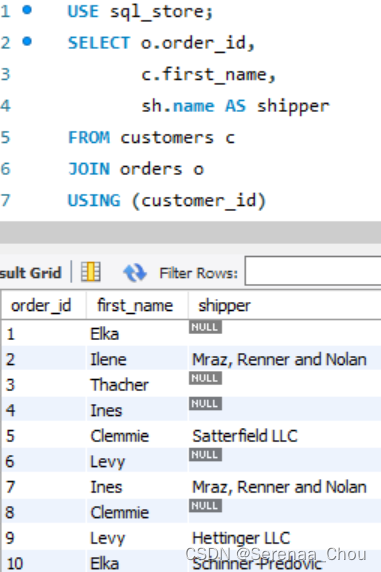
练习:
利用sql_invoicing生成以下结果
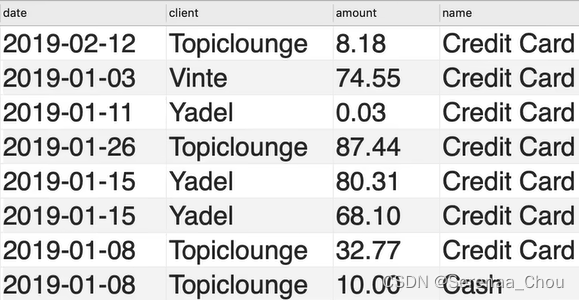
答:
USE sql_invoicing;
SELECT p.date,
c.name AS client,
p.amount,
pm.name
FROM payments p
JOIN clients c
USING (client_id)
JOIN payment_methods pm
ON p.payment_method = pm.payment_method_id13、自然连接
不太建议使用,因为NATUAL JOIN是根据它自己的逻辑去连接,找两张表相同的列名,这样易出错,因为我们不知道它是怎么连的。
14、交叉连接
个人感觉像是排列组合,例子中的CROSS JOIN仅仅是演示,没有意义,customer_id为4的顾客Ambur与10件商品配对,因为products一共是10,但表格customers和表格products之间在列名上没有联系。这种连接方式使用情节是:某一货品有s、m、l号,颜色有红、橙、黄,然后进行配对。
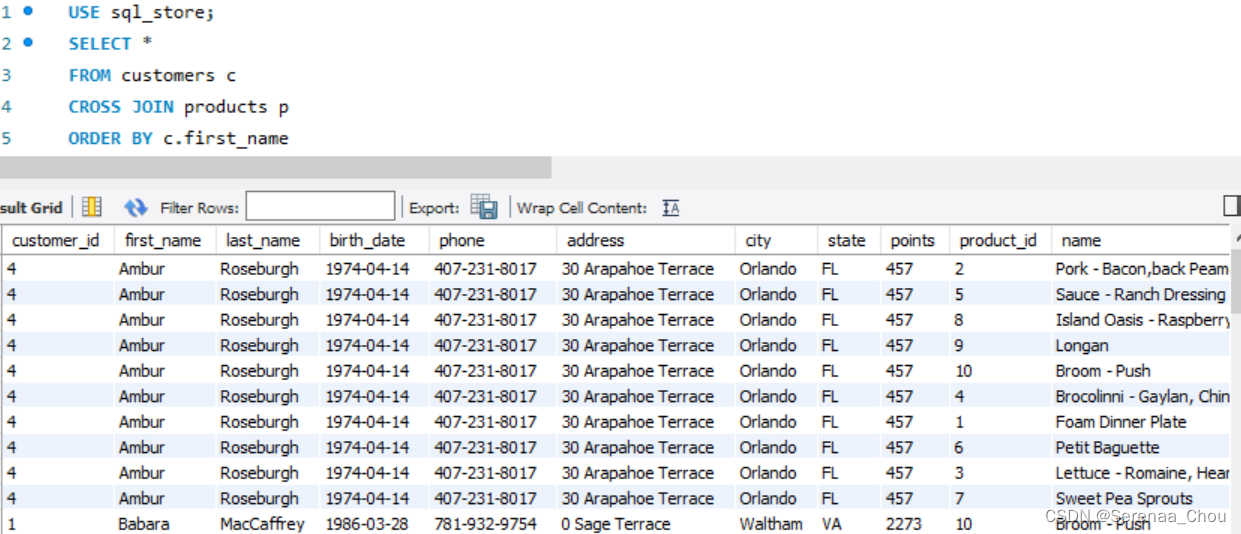
15、联合
上面介绍到的均是以“列”来进行操作的,UNION可以合并多段查询记录,即连接多张表的行,当然,它的前提是列数相同,而且,第一段查询写了啥,它就会被用作最后结果的列名。
举个例子:将2019年下单的记作“活跃”,将之前下单的记作“不活跃”,并将两个表连接起来。
USE sql_store;
SELECT order_id,
order_date,
'活跃' AS state
FROM orders
WHERE order_date >= '2019-01-01'得到:![]()
SELECT order_id,
order_date,
'不活跃' AS state
FROM orders
WHERE order_date < '2019-01-01'得到:
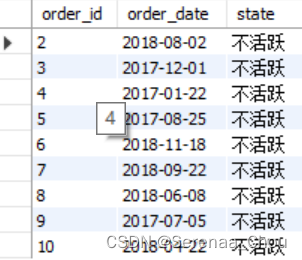
现在利用UNION将它们俩连接起来
USE sql_store;
SELECT order_id,
order_date,
'活跃' AS state
FROM orders
WHERE order_date >= '2019-01-01'
UNION
SELECT order_id,
order_date,
'不活跃' AS state
FROM orders
WHERE order_date < '2019-01-01'得到:
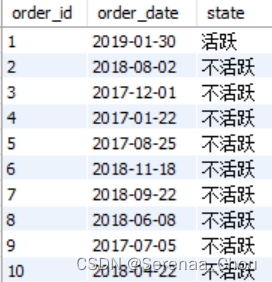
但如果是多个条件的话,每次赋值都要用UNION还是有点麻烦:
USE sql_store;
SELECT customer_id,
first_name,
points,
'青铜' AS type
FROM customers
WHERE points < 2000
UNION
SELECT customer_id,
first_name,
points,
'白银' AS type
FROM customers
WHERE points >= 2000 and points <3000
UNION
SELECT customer_id,
first_name,
points,
'黄金' AS type
FROM customers
WHERE points >= 3000
ORDER BY first_name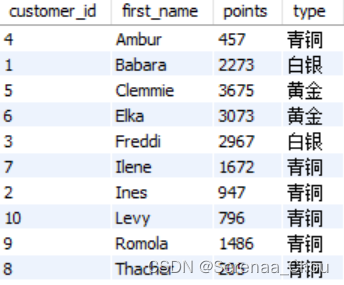
三、列、行属性
1、初识表格的列
以customers表格为例,点击中间的类似工具一样的图标,可以得到:
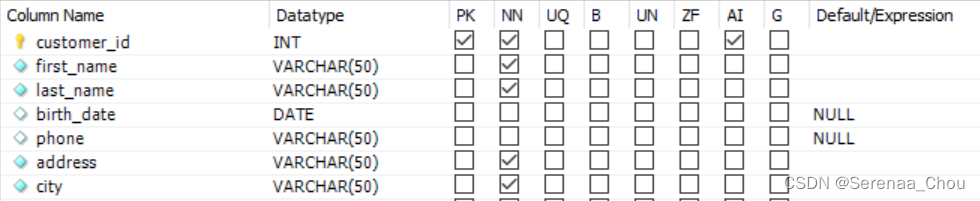
Column Name是各列的名字。
其中customer_id是主键列,它的数据属性是int整数型,并且在PK上面打了勾,表示Primary Key ,NN打勾表示不允许有缺失出现;在AI处打勾表示可以在最后对顾客(样本行)进行添加;
first_name列数据属性是“可变化的”字符型,与character不同的是,可变化的字符型设置为50,如果顾客名字只有5个字符,那么剩下的45空缺也不会占位,因为此时它已经变成了5,而character(50)的话,如果有空缺,MySQL会自己填补那剩下的45空位从而导致浪费;
最后Default/Expression表示缺失值用什么来替代。
2、插入单行
利用INSERT INTO子句。如果使用DEFAULT来填写,系统会分配默认值,比如在前一节提到的NULL之类的,如果在phone位置上填写的是DEFAULT,那么系统会分配为NULL
INSERT INTO customers
VALUES(DEFAULT, --这个是希望系统自动帮我们分配新增的样本编号,用default不容易出错
'John', --字符串、日期都需要引号
'Smith',
'1990-01-01',
NULL,
'adress',
'city',
'CA',
DEFAULT)3、插入多行
INSERT INTO shippers(name)
VALUES('Shipper1'),
('Shipper2'),
('Shipper3')只需要在VALUES后面加逗号添加就行。
练习:在products表格中插入三行
INSERT INTO products
VALUES(DEFAULT,'pp1',6,1.00),
(DEFAULT,'pp2',7,1.05),
(DEFAULT,'pp3',10,0.05)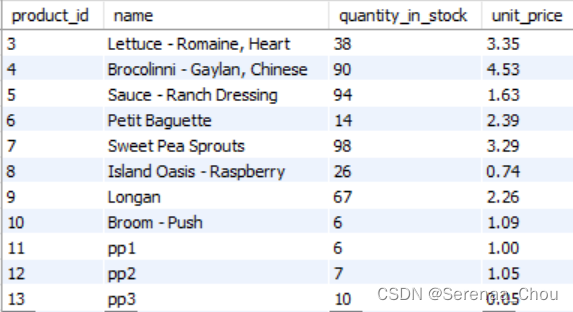
其实product_id是主键列也可以不用写DEFAULT,可以这样写:
INSERT INTO products(name,quantity_in_stock,unit_price)
VALUES('pp1',6,1.00),
('pp2',7,1.05),
('pp3',10,0.05)4、插入分层行
这一节相对于前面的来说就比较绕了,很能体现表格与表格之间的关联,所以首先要理解好其中的关联。
对于orders表格:有订单编号、顾客id、下单时间、发货状态列。同一个顾客可以在不同的时间下过单。
对于order_items表格:有订单编号、物品编号、数量、单价列。同一个订单编号可以下单过不同的物品。
所以,如果在orders表格中新增一行订单(为了简单一点,顾客id是出现过的有效顾客id),那么在order_items表格中也会有对应的新增。
首先在订单表格中产生一行新记录
INSERT INTO orders (customer_id,order_date,status)
VALUES (1,'2019-01-02',1);
SELECT LAST_INSERT_ID() -- 返回最近插入的一条记录的ID其实相当于嵌套了一个LAST_INSERT_ID()函数来为另外一张表格定位,以定向添加。
INSERT INTO orders (customer_id,order_date,status)
VALUES (1,'2019-01-02',1);
INSERT INTO order_items
VALUES(LAST_INSERT_ID(), 1, 4,0.20),
(LAST_INSERT_ID(), 2, 1,1.52)5、创建表复制
把一张表里的内容复制进另外一张新表里面
CREATE TABLE order_archived AS -- 首先创建新表“订单存档”
SELECT *
FROM orders -- 这里的SELECT..FROM..叫做子查询
-- 而这样创建的order_archived表格没有主键列,且不会自动递增如果只想截取一张表里满足条件的数据,并将其复制进新表里面,则基于上步骤再truncate该表格:
INSERT INTO order_archived
SELECT *
FROM orders
WHERE order_date < '2019-01-01'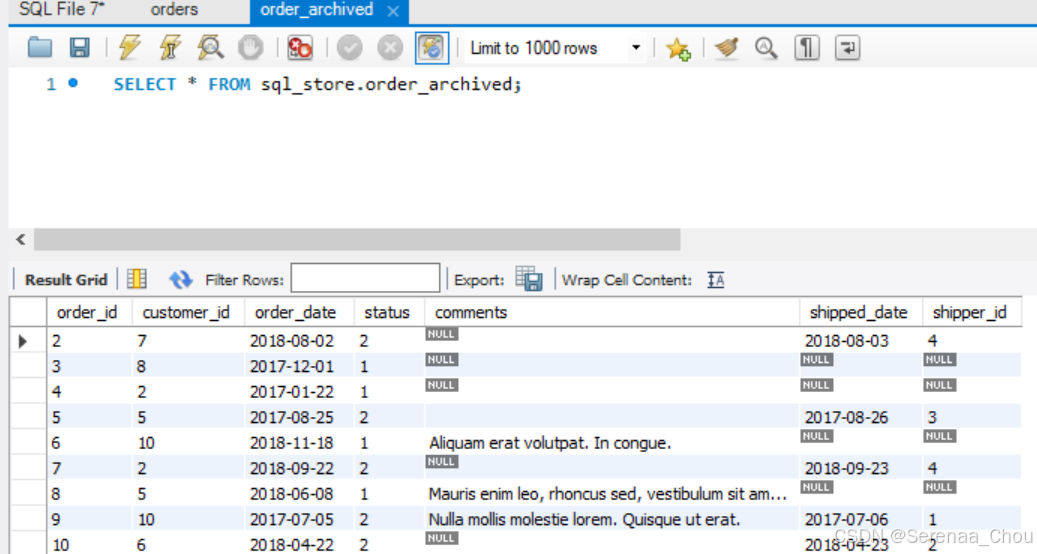
练习:利用sql_invoicing中的表格,将invoices中满足条件的复制进新表invoices archive中,要求:不要客户id列,而想要客户名列;只需要复制支付过的发票(即payment_date是有日期的)
CREATE TABLE invoices_archive AS
SELECT invoice_id, number, invoice_total, payment_total, invoice_date, due_date, payment_date, name
FROM invoices i
JOIN clients c
ON i.client_id = c.client_id
WHERE payment_date IS NOT NULL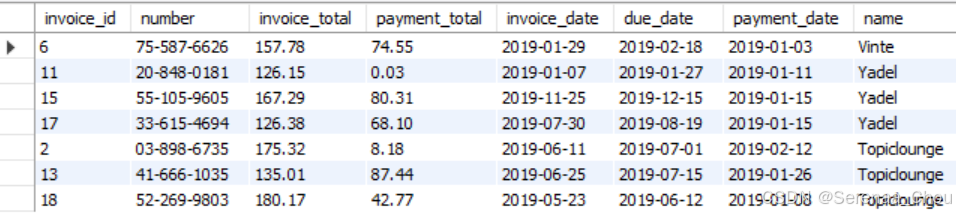
6、更新单行、多行
单行:
UPDATE invoices
SET invoice_total = invoice_total * 0.5,
payment_date = due_date
WHERE invoice_id = 3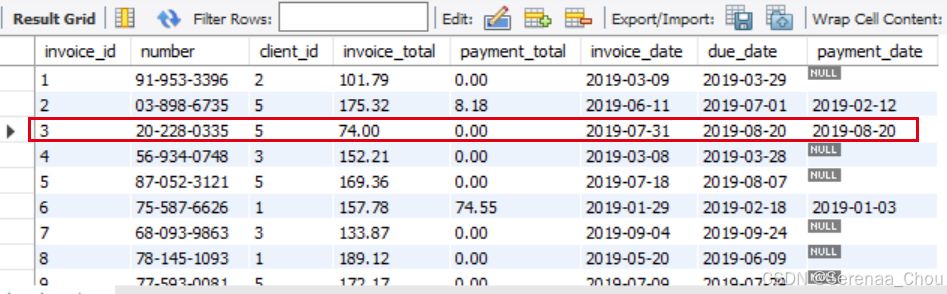
多行更新可能有错误提示,这是因为MySQL对于数据有保护,按前面的方法取消保护模式即可更新多行。
练习:利用sql_store中的表格,将1990年前出生的客户均添加50 points
(取消了保护模式之后)
UPDATE customers
SET points = points + 50
WHERE birth_date < '1990-01-01' 7、在UPDATE中用子查询
UPDATE invoices
SET payment_total = payment_total * 0.5,
payment_date = due_date
WHERE client_id IN
(SELECT client_id
FROM clients
WHERE state IN ('NY','CA'))练习:在comments表格中为points超过3000的顾客添加注释,将他们注释为golden customer
UPDATE orders
SET comments = 'golden customer'
WHERE customer_id IN
(SELECT customer_id
FROM customers
WHERE points > 3000)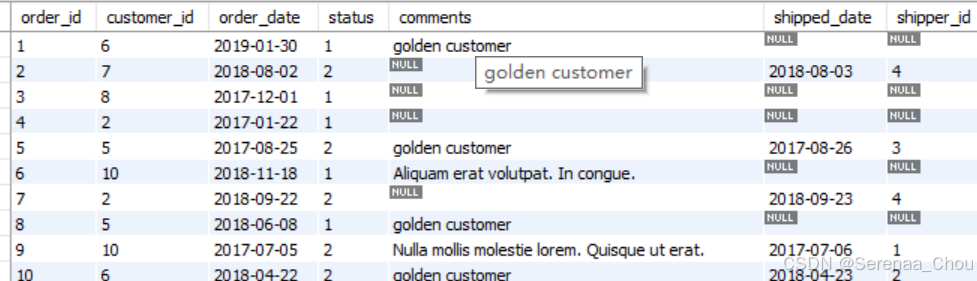
8、删除行
DELETE FROM invoices
WHERE client_id =
(SELECT client_id
FROM clients
WHERE name = 'Myworks')9、恢复数据库至初始状态
四、聚合函数
SELECT
MAX(invoice_total) AS highest,
MIN(invoice_date) AS lowest_of_date,
AVG(invoice_total) AS average,
COUNT(DISTINCT client_id) AS total_records
FROM invoices
WHERE invoice_date > '2019-07-01'练习:做出一张表格统计:
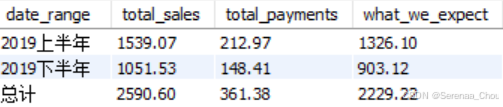
SELECT
'2019上半年' AS date_range,
SUM(invoice_total) AS total_sales,
SUM(payment_total) AS total_payments,
SUM(invoice_total - payment_total) AS what_we_expect
FROM invoices
WHERE invoice_date BETWEEN '2019-01-01' AND '2019-06-30'
UNION
SELECT
'2019下半年' AS date_range,
SUM(invoice_total) AS total_sales,
SUM(payment_total) AS total_payments,
SUM(invoice_total - payment_total) AS what_we_expect
FROM invoices
WHERE invoice_date BETWEEN '2019-07-01' AND '2019-12-31'
UNION
SELECT
'2019上半年' AS date_range,
SUM(invoice_total) AS total_sales,
SUM(payment_total) AS total_payments,
SUM(invoice_total - payment_total) AS what_we_expect
FROM invoices
WHERE invoice_date BETWEEN '2019-01-01' AND '2019-06-30'
UNION
SELECT
'总计' AS date_range,
SUM(invoice_total) AS total_sales,
SUM(payment_total) AS total_payments,
SUM(invoice_total - payment_total) AS what_we_expect
FROM invoices
WHERE invoice_date BETWEEN '2019-01-01' AND '2019-12-31'1、GROUP BY函数
主要是记住语句之间的顺序。其中的GROUP BY统计出每个client_id对应下的covince的汇总,即“单列分组”
SELECT
client_id,
SUM(invoice_total) AS total_sales
FROM invoices
WHERE invoice_date >= '2019-07-01'
GROUP BY client_id
ORDER BY total_sales DESC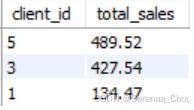
“多列分组”
SELECT
city,
state,
SUM(invoice_total) AS total_sales
FROM invoices
JOIN clients USING (client_id)
GROUP BY state,city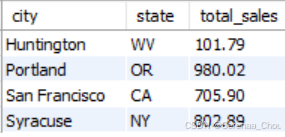
练习:利用payment表格做一个如下的汇总表:
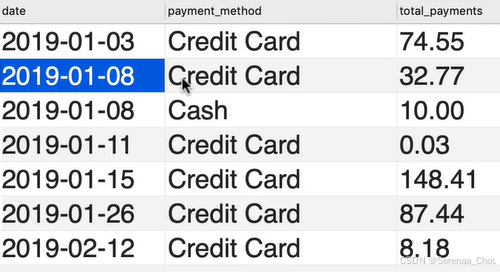
SELECT
date,
name,
SUM(amount) AS total_payment
FROM payments p
JOIN payment_methods pm
ON p.payment_method = pm.payment_method_id
GROUP BY date,payment_method
ORDER BY date ASC2、HAVING子句
筛选出total_sales超过500且数量超过5的client。自然联想到WHERE语句,而WHERE语句的出现顺序是在FROM invoices之后,而此时尚未分组,所以只有在GROUP BY分组完毕之后使用HAVING语句,这是二者最大的不同:
SELECT
client_id,
SUM(invoice_total) AS total_sales,
COUNT(*) AS number_of_invoices
FROM invoices
GROUP BY client_id
HAVING total_sales > 500 AND number_of_invoices > 5
练习:利用sql_store中的数据,筛选出坐标在Virginia的、且消费超过100美元的顾客。
SELECT
c.first_name,
c.last_name,
c.state,
SUM(oi.quantity * oi.unit_price) AS total_consume
FROM customers c
JOIN orders o
USING (customer_id)
JOIN order_items oi
USING(order_id)
GROUP BY customer_id,first_name
HAVING state = 'VA' AND total_consume > 100![]()
很重要的一点是GROUP BY以什么分组,需要想清楚!
Leecode易错:
这是道好题,有两种解法,其中方法二是一开始想到的自连接,但是对于连接条件以及该用什么GROUP BY非常混乱,所以做错了。
找出有5名直接下属的经理


3、ROLLUP运算
类似于Excel中的数据透视表汇总功能,如果是单列分组,利用WITH ROLLUP可以得到最终一列的所有值汇总;如果是多分组,那么每一分组都会有一个汇总值,以及所有分组的汇总:
SELECT
state,
city,
SUM(invoice_total) AS total_sales
FROM invoices i
JOIN clients c USING (client_id)
GROUP BY state,city WITH ROLLUP 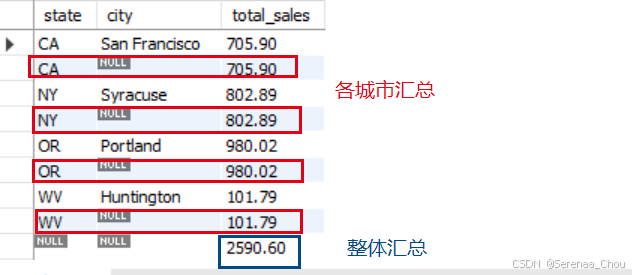
练习:利用payments表格得到下面的结果:


SELECT
pm.name AS payment_method,
SUM(p.amount) AS total
FROM payments p
JOIN payment_methods pm
ON p.payment_method = pm.payment_method_id
GROUP BY pm.name WITH ROLLUP五、复杂查询
1、子查询VS连接
利用子查询和连接两种方法对sql_store中购买过生菜(id=3)的顾客进行查找,列出他们的customer_id、first_name、last_name,之后比较两种方法的代码可读性:
-- 子查询
SELECT DISTINCT
customer_id,
first_name,
last_name
FROM customers
WHERE customer_id IN (
SELECT customer_id
FROM orders
WHERE order_id IN (
SELECT order_id
FROM order_items
WHERE product_id = 3
)
)
-- 连接
SELECT DISTINCT
c.customer_id,
c.first_name,
c.last_name
FROM customers c
JOIN orders o USING(customer_id)
JOIN order_items oi USING(order_id)
WHERE product_id = 3出来的结果均为:
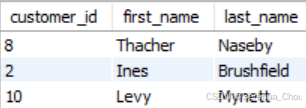
而由于这几张表之间天然有着某种联系,所以采用第二种方法,代码的可读性可能会好一点。
2、ALL关键字
它的逻辑是将符合的数值全部保留,并让前面需要比较的数值逐个与ALL之后保留的数值相比较。
选择大于客户3的所有发票额的发票:
-- 利用MAX函数
SELECT *
FROM invoices
WHERE invoice_total > (
SELECT
MAX(invoice_total)
FROM invoices
WHERE client_id = 3
)
-- 利用ALL关键字
SELECT *
FROM invoices
WHERE invoice_total > ALL (
SELECT
invoice_total
FROM invoices
WHERE client_id = 3
)
结果均为:

3、ANY关键字
=ANY等价于IN
选择至少有2张发票的客户:
-- 使用IN关键字
SELECT *
FROM clients
WHERE client_id IN (
SELECT
client_id
FROM invoices
GROUP BY client_id
HAVING COUNT(*) >= 2
)
-- 使用ANY关键字
SELECT *
FROM clients
WHERE client_id =ANY (
SELECT
client_id
FROM invoices
GROUP BY client_id
HAVING COUNT(*) >= 2
)看个人喜好使用,都是一样的。结果均为:

4、相关子查询
子查询和外查询存在相关性,需要引用外查询之后对子查询进行操作。上面所做的子查询都与外查询没有关联,是表与表之间的联系。
利用sql_hr数据选择工资超过部门平均值的员工。先看一下数据可知,工资平均值不再是一个数了,而是根据部门的不同而不同,所以应该根据不同部门找出各自部门中平均工资以上的员工。
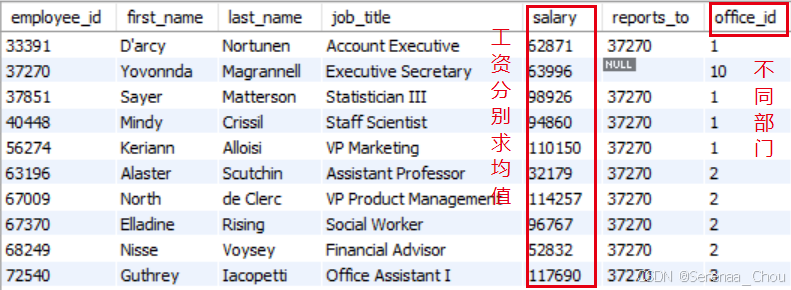
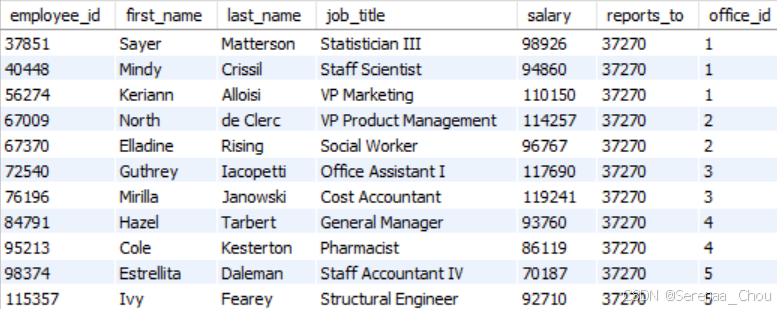
SELECT *
FROM employees e
WHERE salary > (
SELECT AVG(salary)
FROM employees
WHERE office_id = e.office_id
)
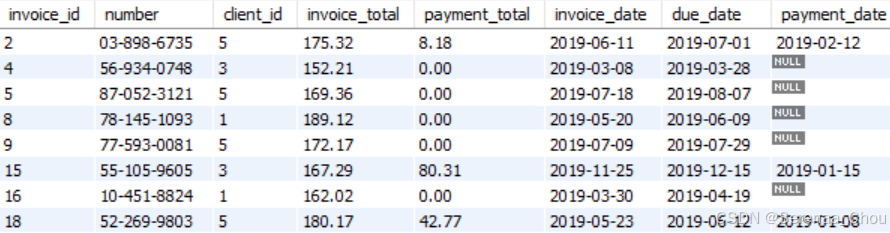
练习:利用sql_invoices数据,获取高于用户平均值的发票(每个用户不止一张发票,选出高于他们自己的平均值的发票)
SELECT *
FROM invoices i
WHERE invoice_total > (
SELECT AVG(invoice_total)
FROM invoices
WHERE client_id = i.client_id
)
5、EXISTS运算符
从invoices数据中找出有发票的客户。方法一是利用前面所学子查询可以得到想要;方法二利用的是EXISTS运算符,该运算符最大的好处是对于很大的查询他体系来说,方法一这种查询方式是子查询将结果传递给外面,即单独运行子查询都是行得通的,效率可能低下;而EXISTS运算符包含的查询不将结果传递给外面,效率可能高一点。
EXISTS <--> NOT EXISTS
-- 方法一
SELECT *
FROM clients c
WHERE client_id IN (
SELECT DISTINCT client_id
FROM invoices
)
-- 方法二
SELECT *
FROM clients c
WHERE EXISTS (
SELECT client_id
FROM invoices
WHERE client_id = c.client_id
)
练习:从sql_store数据中找到从来没有被订购过的产品。
SELECT *
FROM products p
WHERE NOT EXISTS (
SELECT DISTINCT product_id
FROM order_items oi
WHERE oi.product_id = p.product_id
)![]()
6、SELECT子句中的子查询
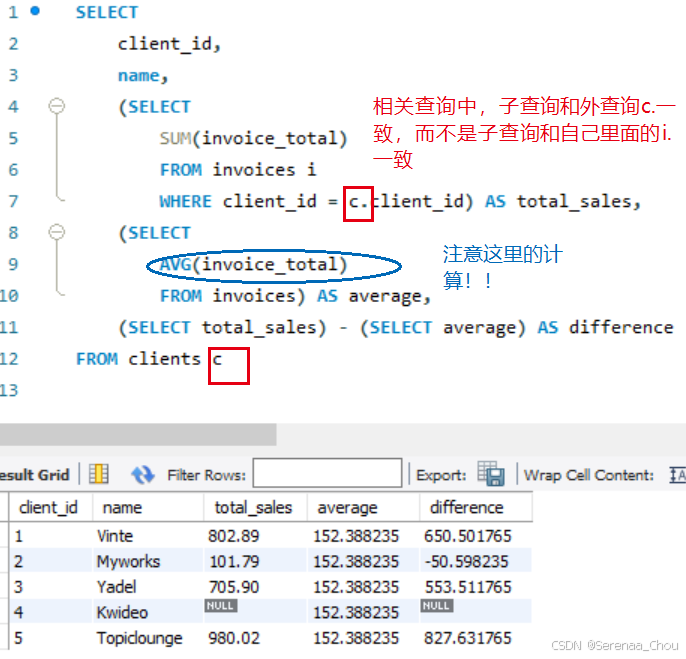
例子中的invoice_average是invoice_total这一列所有值的平均值,如果直接在SELECT后面写AVG(invoice_total)AS total_average的话就会报错,因为没有反映成一列,所以要在SELECT后面嵌套SELECT
SELECT
invoice_id,
invoice_total,
(SELECT AVG(invoice_total) FROM invoices) AS invoice_average,
invoice_total - (SELECT invoice_average) AS difference
FROM invoices
练习:写一段查询生成下表,其中total_sales为每位客户的成交总量,即每位客户开出发票的合计;

7、FROM子句中的子查询
FROM子句中的子查询仅用于简单的查询当中,因为这会使代码复杂可读性降低。为了改善这一点,后面会利用视图来优化。
SELECT *
FROM (
SELECT
client_id,
name,
(SELECT
SUM(invoice_total)
FROM invoices i
WHERE client_id = c.client_id) AS total_sales,
(SELECT
AVG(invoice_total)
FROM invoices) AS average,
(SELECT total_sales) - (SELECT average) AS difference
FROM clients c
) AS sales_summary
WHERE total_sales IS NOT NULL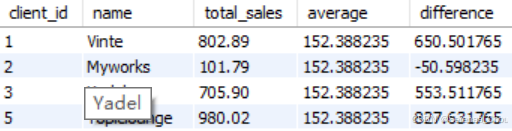
注意:必须为每个结果得出来的新表格创建一个别名,在本例中就是AS sales_summary
8、WITH...AS...查询
为一个查询结果或子查询结果创建一个临时表,这个临时表可以在后续的查询中被使用,通常在批量查询或者复杂查询里面会使用到
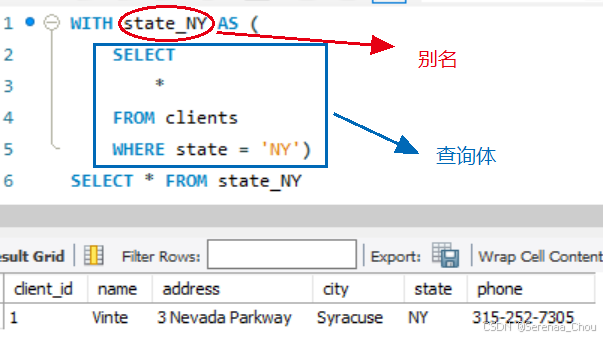
-- 同时定义多个临时表
WITH
tmp1 AS (SELECT * FROM tb_name1),
tmp2 AS (SELECT * FROM tb_name2)
SELECT * FROM tmp1 JOIN tmp2 ON tmp1.id = tmp2.foreign_id在业务中(此处做了脱敏处理,可能业务逻辑不容细细考究,目的仅为展现WITH...AS...的用法):
WITH
tyk AS(
SELECT
t.bhq_uid AS uid,
t.nickname AS nickname,
...
t1.second_category AS tyk_second_category
FROM hive.ddd_crm.micro_marketing_student t
INNER JOIN (
SELECT
buy_order_id,
...
goods_id
FROM hive.ddd_bhq.buy_order_detail
WHERE create_time < '${end_time}' AND create_time >='${start_time}'
) t1 --其中start_time和end_time需要手填
ON t.hq_uid = t1.uid AND t.good_id = t1.goods_id
WHERE t.good_name LIKE '%${good_name}%' --需要手填商品名称,所以前后加上%通配符,可填任意字符
),
zjk AS(
SELECT *
FROM (
SELECT
t.tyk_order_id AS 体验课订单id,
...
FROM tyk t
)
)
SELECT
t.uid AS '用户id',
...
t1.zjk_order_id AS '正价课订单id'
FROM tyk t
LEFT JOIN zjk t1 USING(tyk_order_id)
六、内置函数
数值函数:
有很多与其他语言中类似的函数,例如SELECT ROUND(5.73,1)结果为5.7,指的是四舍五入保留1位小数。SELECT RAND()随机生成0-1之间的浮点数。等等...不用记住,可以随用随查。
字符串函数:
针对字符串类型的数据。例如SELECT LTRIM('Sky')指的是移除字符串左边空白字符或其他预定字符;RTRIM同理移除字符串右边的。注意:字符串索引为正向索引,从1开始。随用随查。
日期函数:
SELECT NOW()返回当前日期时间,包括时分秒;SELECT CURDATE()返回当前年月日;SELECT CURTIME()返回当前时间,时分秒。
练习:![]() 利用内置函数返回当前年份的订单。
利用内置函数返回当前年份的订单。
SELECT *
FROM orders
WHERE YEAR(order_date) = YEAR(NOW()) 格式化日期和时间 SELECT DATE_FORMAT(NOW(),'%d %m %Y')
计算日期和时间 SELECT DATE_ADD(NOW(),INTERVAL 1 DAY)在当前日期上往后加一天,即明天的这个时候。
1、IFNULL和COALESCE函数
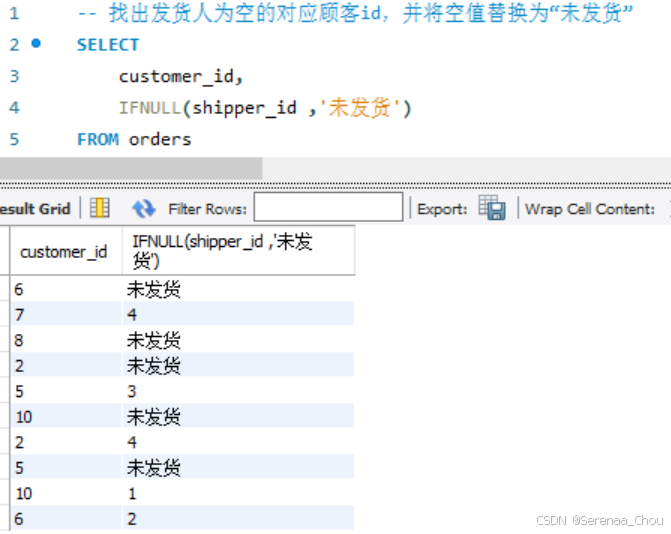
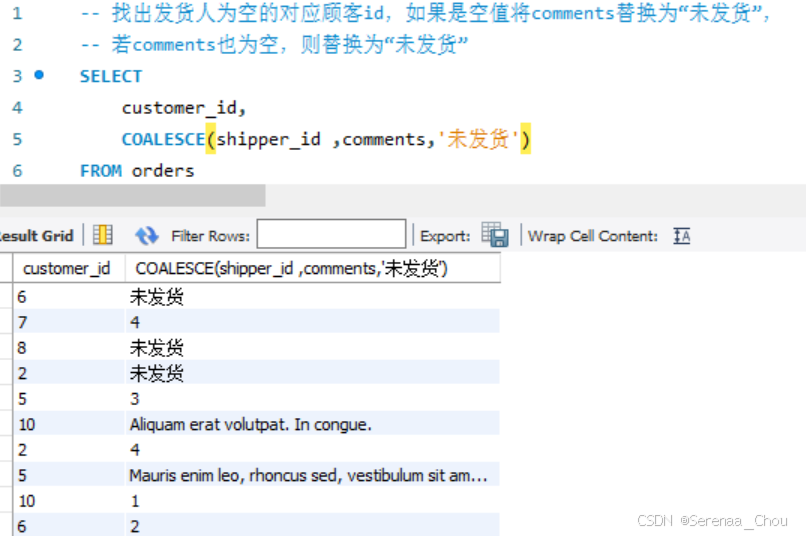
练习:写一段查询生成如下结果

SELECT
CONCAT(first_name,' ',last_name) AS full_name,
IFNULL(phone,'Unkown') AS phone_num
FROM customers2、IF语句/CASE语句
对于单分支结构而言,形式与excel形式类似,IF(判别式,返回值1,返回值2);而对于多分支结构则需要使用CASE语句。
对于单分支:
练习:利用product数据生成如下结果
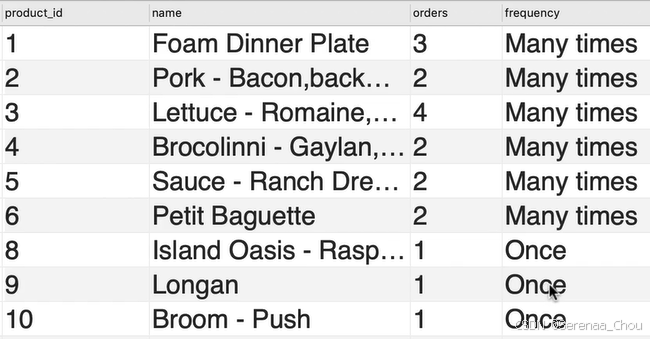
SELECT
product_id,
name,
COUNT(order_id) AS orders,
IF(COUNT(order_id) > 1,
'Many times',
'Onece') AS '频率'
FROM products
JOIN order_items USING(product_id)
GROUP BY product_id对于多分支:
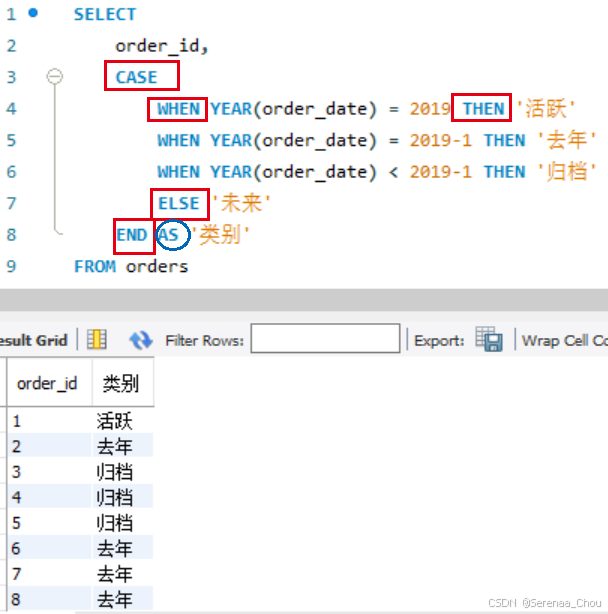
在业务中:
有一段按照转正时间查询后台订单的例子(比较简单,基本上就是取数)
SELECT
first_category_name AS '大类',
...
UID AS '用户UID',
channel_name AS '渠道',
agent_name AS '代理商'
CASE
WHEN CAST(card_source_id AS varchar )= '11' THEN 'WEB-付费搜索-百度'
--CAST是将一个数据类型转换成另一个数据类型的函数,即WEB-付费搜索-百度为11
--varchar是可变长字符串型,能节约存储空间
...
WHEN CAST(card_source_id AS varchar )= '1400' THEN 'QQ小程序-快题库pro'
ELSE '待解释来源'
END AS '流量来源',
CASE
WHEN CAST(first_visit_product AS varchar )= '1' THEN '频道页'
...
WHEN CAST(first_visit_product AS varchar )= '91' THEN '待解释页面'
END AS "首次访问产品",
CASE
WHEN CAST(last_visit_product AS varchar )= '1' THEN '频道页'
...
WHEN CAST(last_visit_product AS varchar )= '91' THEN '待解释页面'
END AS "末次访问产品",
CAST(card_source_id AS varchar ) AS '流量来源ID',
...
pay_money - balance_money AS '现金支付金额',
CASE
WHEN is_sales = 1 THEN '是' ELSE '否'
END AS "销售成单",
...
FROM dwd_hq.dwd_order_detail
WHERE formal_date BETWEEN '2024-05-13 00:00:00' AND '2024-05-16 23:59:59'
AND second_category_name = '数据分析师'
练习:写一段查询生成如下结果(这是以前的一个练习,用的是UNION来连接每一个部分,当时我的评价就是分支多了好复杂hhhh)
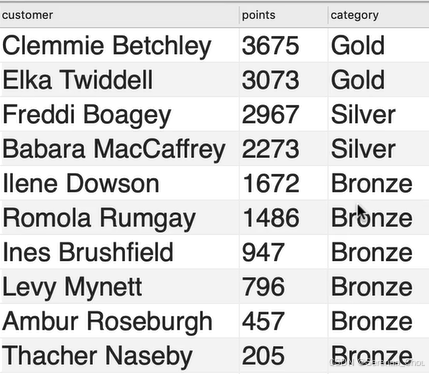
SELECT
CONCAT(first_name,' ',last_name) AS '顾客',
points,
CASE
WHEN points >= 3000 THEN '黄金'
WHEN points >= 2000 && points < 3000 THEN '白银'
ELSE '青铜'
END AS '类别'
FROM customers七、创建视图
当我们基于原有表格做了一些查询之后,会得到相应有用的查询结果,如果以后的查询想要基于这次的查询结果再做另外的查询,我们还要重新写一遍原来的查询,这很繁琐,所以可以将上次的查询保存为视图,以后的查询可以基于该视图来进行。
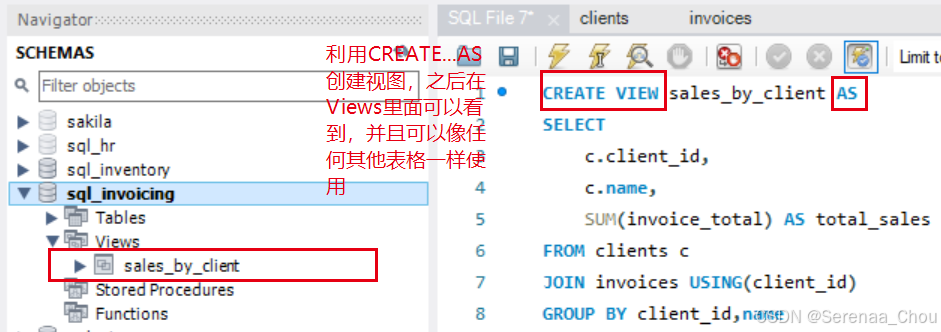
练习:创建一个视图显示客户结余balance(发票总额-支付总额)View名为Clients_balance,包含Client_id,name,balance
CREATE VIEW Clients_balance AS
SELECT
c.client_id,
c.name,
SUM(invoice_total)-SUM(payment_total) AS balance
FROM clients c
JOIN invoices i USING(client_id)
GROUP BY client_id,name将CREATE VIEW... AS改为CREATE OR REPLACE...AS可实现后面视图的删减更改,使用:DELETE FROM...或者是UPDATE...SET
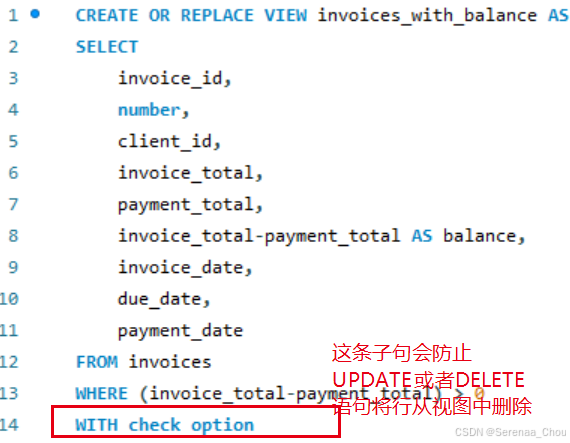
作用:1.数据一致性:确保通过试图插入或更新的数据满足视图的筛选条件,从而保持数据库中数据的一致性和完整性;2.数据验证:通过视图插入或更新的数据将自动经过视图定义的条件验证,如果不满足这些条件,操作将被拒绝。
八、创建/删除存储过程
有点像创建一个经常用到的函数,从而方便后面的调用 ...-.-...
1、使用代码创建
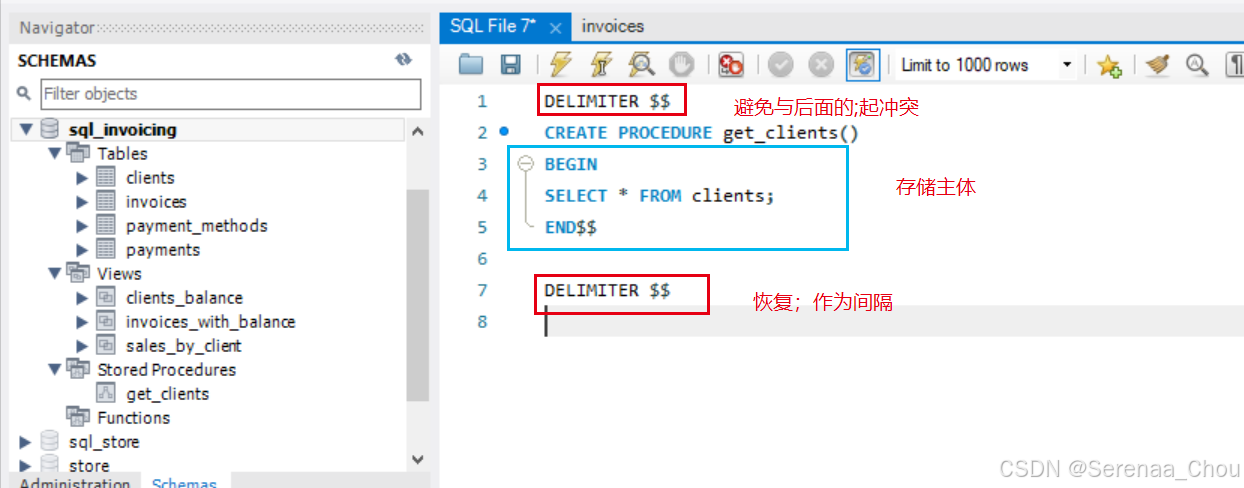
为什么前后都要加上(界定符)DELIMITER $$避免冲突:在定义存储过程时,SQL 语句内部可能包含多个分号 ; 用于分隔不同的语句。如果不更改分隔符,MySQL 会将第一个分号 ; 视为存储过程的结束标志,从而导致整个存储过程被提前结束。为避免这种冲突,使用 界定符来临时更改分隔符,使得存储过程中的分号不会干扰整个存储过程的定义。
之后利用CALL来调用存储过程 CALL get_clients()
练习:创建一个存储叫做get_invoices_with_balance,来返回所有结余大于0的发票(有视图)
DELIMITER $$
CREATE PROCEDURE get_invoices_with_balance()
BEGIN
SELECT
*
FROM invoices_with_balance
WHERE balance > 0;
END $$
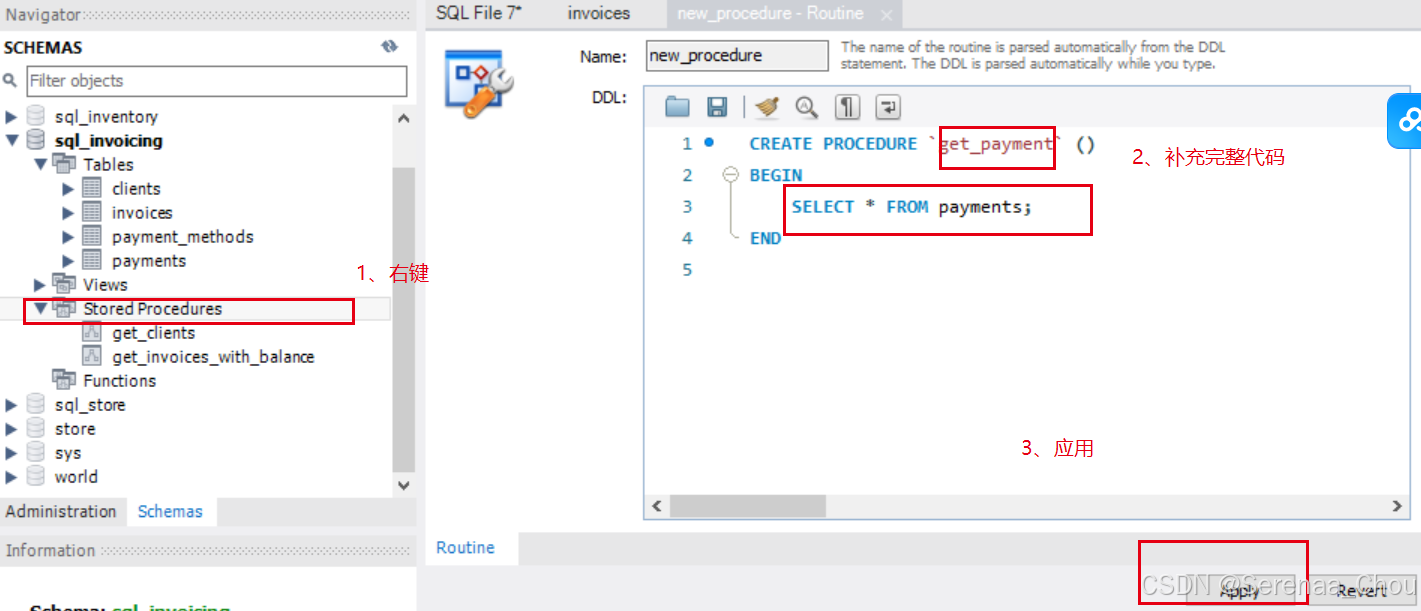
DELIMITER $$2、使用工作台创建
3、删除存储过程
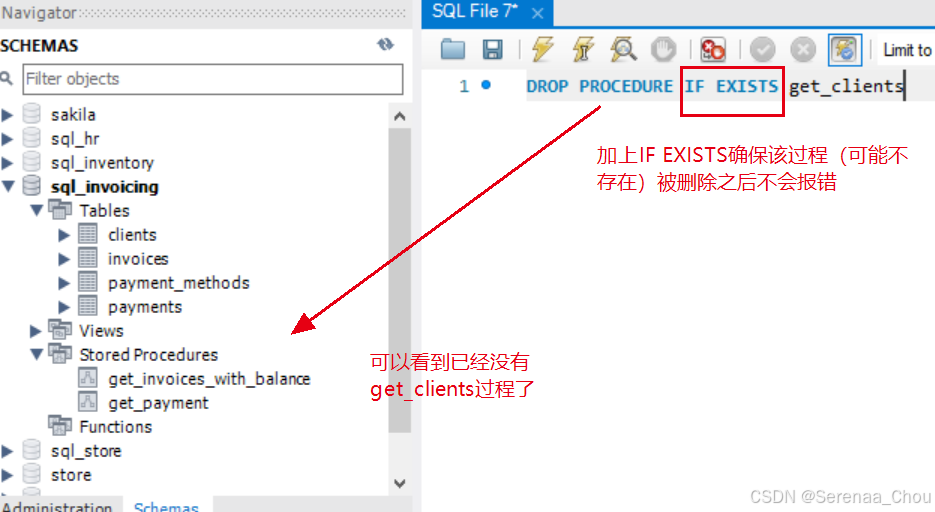
最好把删除和创建每一个存储过程的代码保存在不同的SQL文件中
4、参数
类似于函数中需要传入参数,这里用CALL调用包含特定参数的存储过程
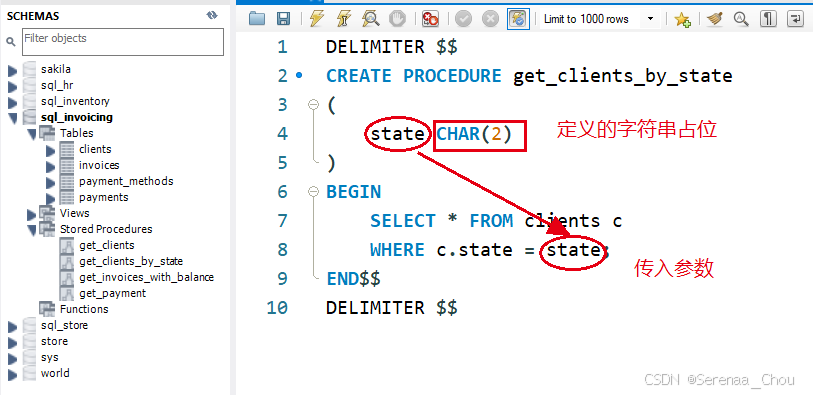
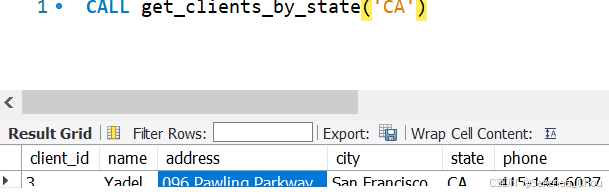
练习:设置一个存储过程get_invoices_by_clients返回给定客户的发票,其中参数为客户id
DROP PROCEDURE IF EXISTS get_invoices_by_client;
DELIMITER $$
CREATE PROCEDURE get_invoices_by_client(
client_id INT
)
BEGIN
SELECT * FROM invoices i
WHERE i.client_id = client_id;
END$$
DELIMITER $$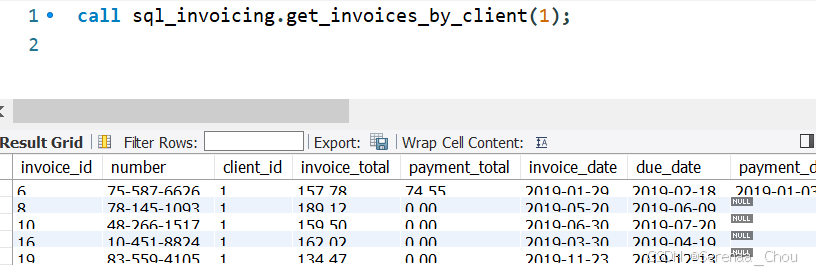
九、窗口函数
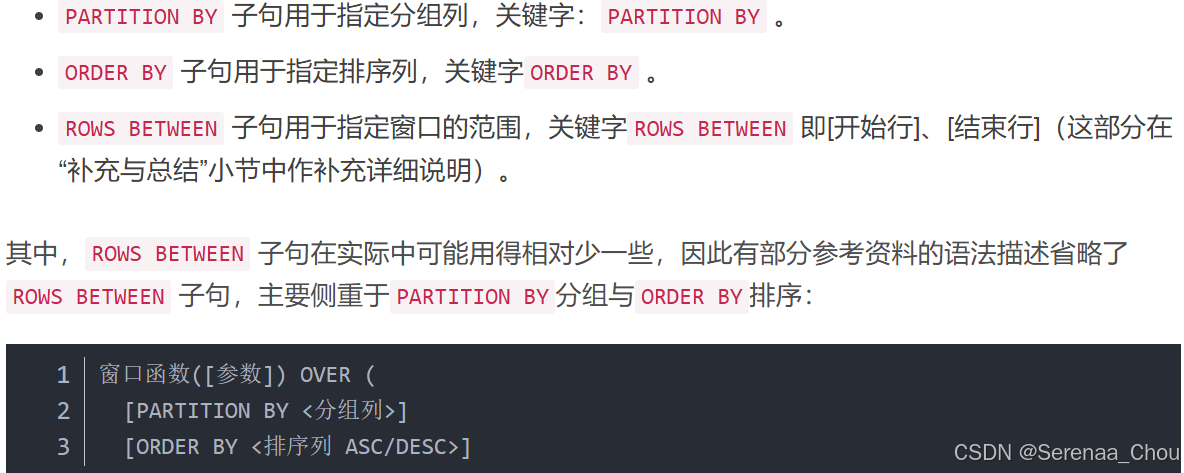
窗口函数,也叫OLAP函数(Online Anallytical Processing,联机分析处理),可以对数据库数据进行实时分析处理。语法如下:
窗口函数([参数]) OVER (
[PARTITION BY <分组列>]
[ORDER BY <排序列 ASC/DESC>]
[ROWS BETWEEN 开始行 AND 结束行]
)
(有点像VBA中的range属性hhh)
通常将常用的窗口函数分为两大类:聚合窗口函数 与 专用窗口函数
1、聚合窗口函数
聚合窗口函数的函数名与普通常用聚合函数(内置函数如SUM、MIN等等)一致,功能也一致。现在创建一个表sales
CREATE TABLE sales (
id INT PRIMARY KEY,
product VARCHAR(50),
category VARCHAR(50),
sale_date DATE,
quantity INT,
revenue DECIMAL(10, 2)
);
INSERT INTO sales (id, product, category, sale_date, quantity, revenue)
VALUES
(1, 'Product A', 'Category 1', '2022-01-01', 10, 100.00),
(2, 'Product B', 'Category 1', '2022-01-01', 5, 50.00),
(3, 'Product A', 'Category 2', '2022-01-02', 8, 80.00),
(4, 'Product B', 'Category 2', '2022-01-02', 3, 30.00),
(5, 'Product A', 'Category 1', '2022-01-03', 12, 120.00),
(6, 'Product B', 'Category 1', '2022-01-03', 7, 70.00),
(7, 'Product A', 'Category 2', '2022-01-04', 6, 60.00),
(8, 'Product B', 'Category 2', '2022-01-04', 4, 40.00);在sales表每行最后一列都加上这一行的产品类别category的平均销售收入revenue,并且以category顺序排序
按以前的办法:
SELECT
*
FROM sales
JOIN (
SELECT
category,
AVG(revenue) AS avg_revenue
FROM sales
GROUP BY category
) s
USING (category)
ORDER BY category
-- 用连接的原因是如果仅仅只AVG(revenue),只会出来两个值即两个类别分别的均值。这个时候GROUP BY不能将其他想要的列包裹,所以必须用连接,将对应的类别连接上分别的类别均值。利用聚合窗口函数:
SELECT
*,
AVG(revenue) OVER (PARTITION BY category) AS avg_revenue
FROM sales
ORDER BY category 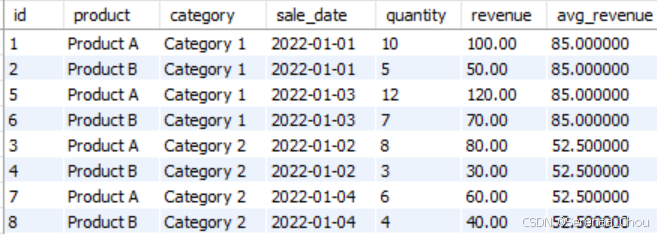
2、专用窗口函数
常见几种:

SELECT
*,
RANK() OVER(PARTITION BY category ORDER BY quantity DESC) AS quantity_rank,
DENSE_RANK() OVER(PARTITION BY category ORDER BY product DESC) AS product_dense_rank,
ROW_NUMBER() OVER(PARTITION BY category ORDER BY product DESC) AS product_row_number
FROM sales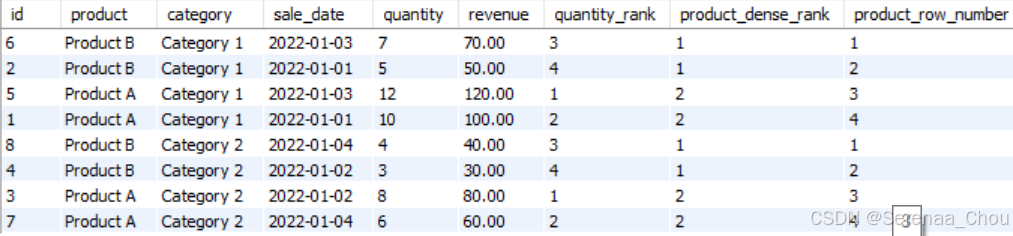
在业务中(已做脱敏处理,仅为展示用法):
WITH
zjk_tyk AS (
SELECT *
FROM(
SELECT
t.tyk_order_id AS tyk_order_id,
t1.zjk_order_id AS zjk_order_id,
row_number() OVER (PARTITION BY t1.zjk_order_id ORDER BY t.tyk_create_time DESC) AS raank
FROM tyk t -- raank为row_number()窗口函数生成的行值
LEFT JOIN zjk t1
ON t.uid=t1.uid AND t.tyk_second_category = t1.zjk_second_category
WHERE t.tyk_create_time < t1.zjk_create_time AND t1.zjk_order_id IS NOT NULL
) s
WHERE s.raank = 1 -- 保留了每个 zjk_order_id 分组中按时间排序后最新的那一条记录
)
SELECT
*
FROM tyk t
LEFT JOIN zjk_tyk t1
ON t.tyk_order_id = t1.tyk_order_id
















 1602
1602

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









