






一.Mysql数据库索引的数据结构。
索引:是帮助Mysql高效获取数据的排好序的数据结构。
由于数据的存放在磁盘上是随机分布的(同一个表的数据并不一定数据的存放位置是挨着一起的),数据的查找实际上是对磁盘做I/O交互,查找指定数据的过程,就是对磁盘不断进行I/O交互,查找数据进行比对。因此,可以理解为:索引的本质是为了减少I/O交互的消耗
索引的数据结构:
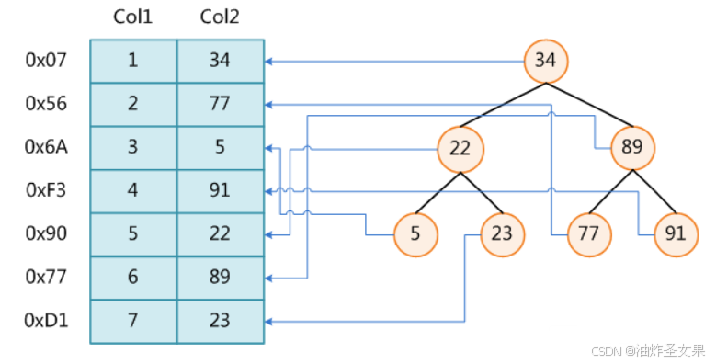
二叉树(数据量大的时候树的高度其实会持续增加,属于基础树形结构)
红黑树(同理,依然是受制于数的高度)
Hash树(在=条件查找时有优势)
B-Tree(常用的B+树的基础)
1。B-Tree
叶节点具有相同的深度,叶节点的指针为空
所有索引元素不重复
节点中的数据索引从左到右递增排列
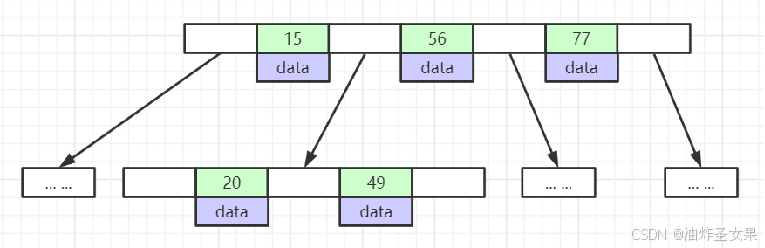
2.B+Tree
非叶子节点不存储data,只存储索引(冗余),可以放更多的索引(取每一页的第一个索引)
叶子节点包含所有索引字段
叶子节点用指针连接,提高区间访问的性能(叶子节点的尾部和头部是存放了相邻节点的指针的)
每一层在节点内或者节点与节点之间,索引是从左到右递增的(排好序的)
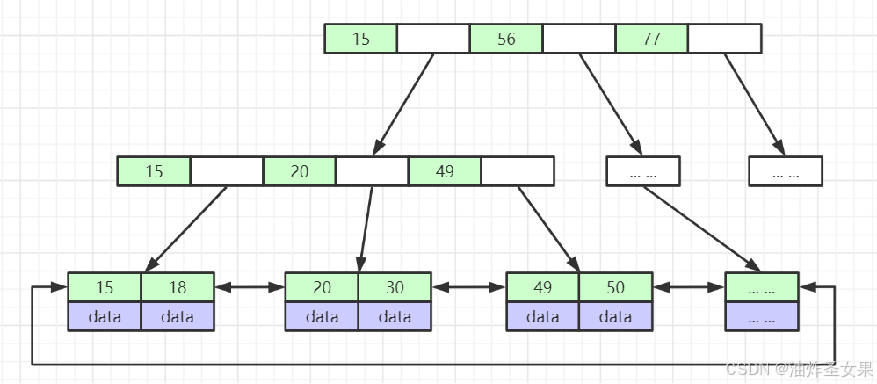
3.Hash
对索引的key进行一次hash计算就可以定位出数据存储的位置
很多时候Hash索引要比B+ 树索引更高效 仅能满足 “=”,“IN”,不支持范围查询
hash冲突问题
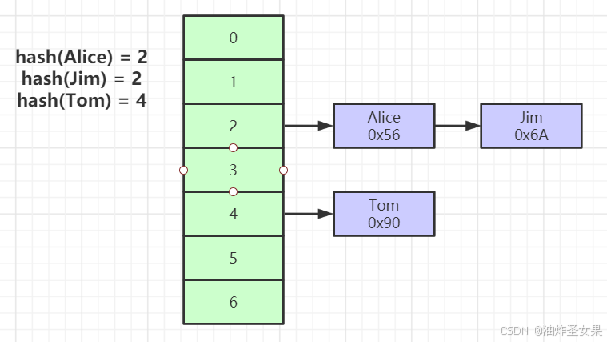
二。存储引擎索引实现
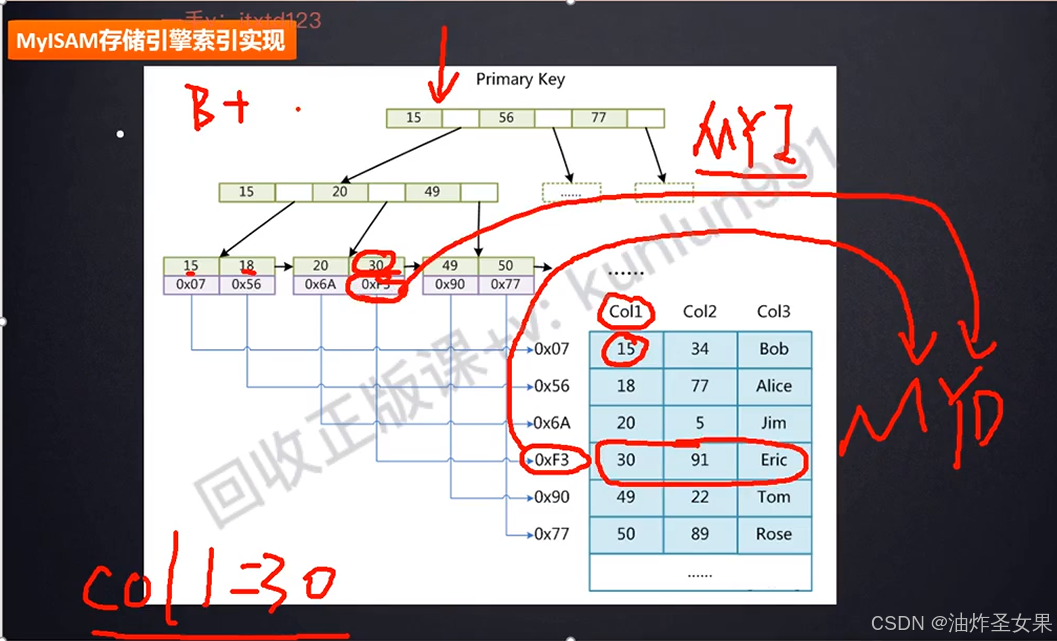
1。MyISAM索引实现(非聚集:即索引文件和数据文件时分开存储的)
先在MYI文件索引树中查找到指定的节点,该节点下存储了数据存放的地址,获取到地址后再到存放数据的MYD文件,根据地址比对找到这一条数据。
注:效率会比聚集索引低,因为会有一个跨文件查找的操作,相当于做了一个回表的操作。
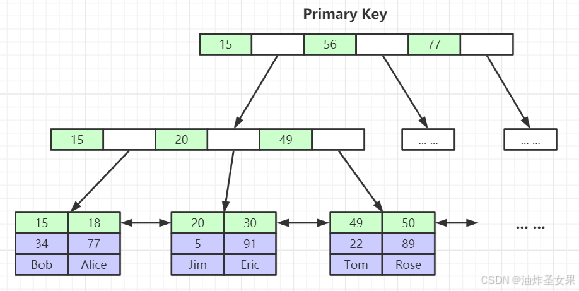
2.InnoDB索引实现(聚集)
表数据文件本身就是按B+Tree组织的一个索引结构文件
聚集索引-叶节点包含了完整的数据记录(如下图)
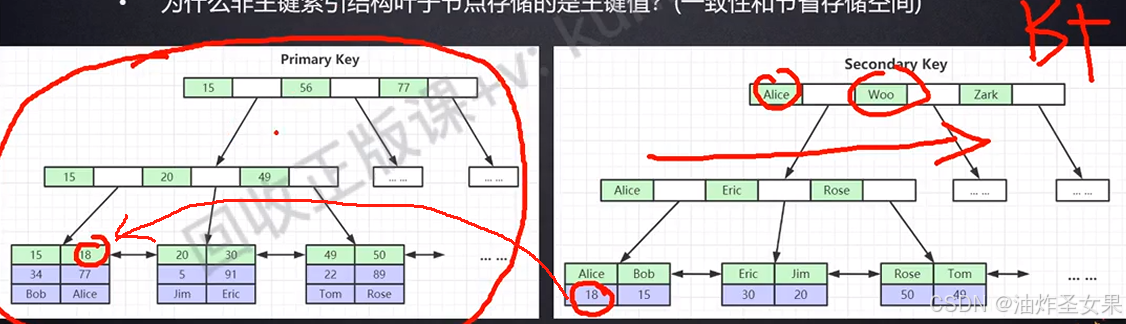
为什么建议InnoDB表必须建主键,并且推荐使用整型的自增主键?
因为在叶子节点数量不断增加时,自增的主键作为索引,只需要加载尾部的叶子节点后面,再根据B+树的构建规则,重新平衡其树的结构。如果不是自增的,会在所有的叶子节点中比较大小进行插入,然后再平衡树结构。
为什么非主键索引结构叶子节点存储的是主键值?(一致性和节省存储空间)
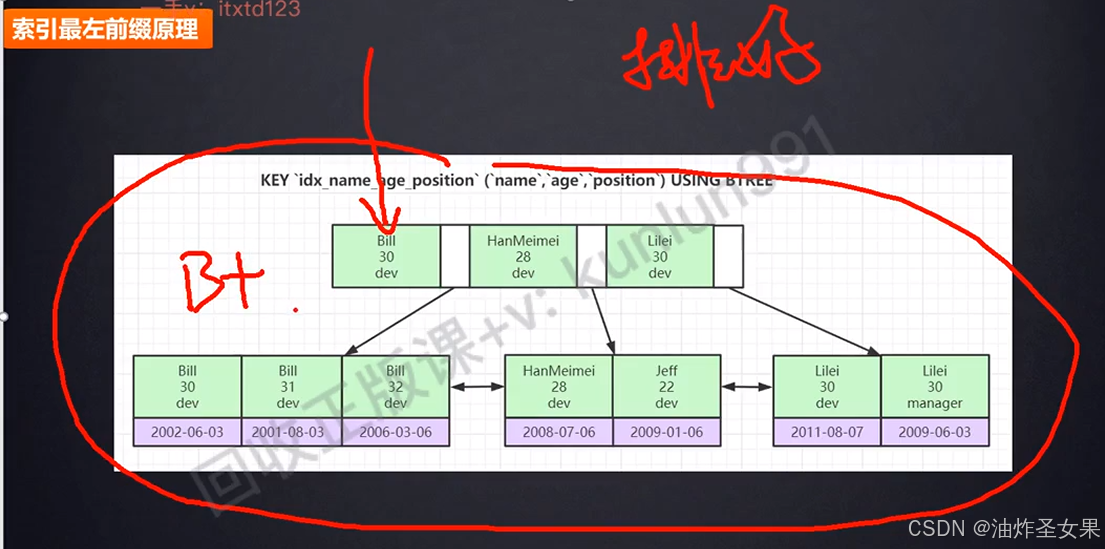
三。联合索引
比如name、age、position的联合索引,首先满足name的排序,其次age,再是position(即在name相同的叶子节点中,再看age是排好序的)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









