






开个玩笑:我是萧炎,Redis就像萧薰儿,从刚接触修炼(java)的时候,就能感觉到Redis不简单,但是对其的了解始终不深,只能get到表象或者从各种外界传闻(面试宝典)知道Redis的强大。这一世,我重生归来,师从药老(诸葛老师),势必要从底层开始,狠狠深入了解Redis,将其拿下(桀桀桀)
Ok,开始新的专题:Redis
下载地址:http://redis.io/download
2 安装步骤:
3 # 安装gcc
4 yum install gcc
5
6 # 把下载好的redis‐5.0.3.tar.gz放在/usr/local文件夹下,并解压
7 wget http://download.redis.io/releases/redis‐5.0.3.tar.gz
8 tar xzf redis‐5.0.3.tar.gz
9 cd redis‐5.0.3
10
11 # 进入到解压好的redis‐5.0.3目录下,进行编译与安装
12 make
13
14 # 修改配置
15 daemonize yes #后台启动
16 protected‐mode no #关闭保护模式,开启的话,只有本机才可以访问redis
17 # 需要注释掉bind
18 #bind 127.0.0.1(bind绑定的是自己机器网卡的ip,如果有多块网卡可以配多个ip,代表允许客户
端通过机器的哪些网卡ip去访问,内网一般可以不配置bind,注释掉即可)
19
20 # 启动服务
21 src/redis‐server redis.conf
22
23 # 验证启动是否成功
24 ps ‐ef | grep redis
25
26 # 进入redis客户端
27 src/redis‐cli
28
29 # 退出客户端
30 quit
31
32 # 退出redis服务:
33 (1)pkill redis‐server
34 (2)kill 进程号
35 (3)src/redis‐cli shutdownRedis核心的五种数据结构
Redis的之所以强大,主要就归功于性能优秀和丰富的数据结构。见下图:
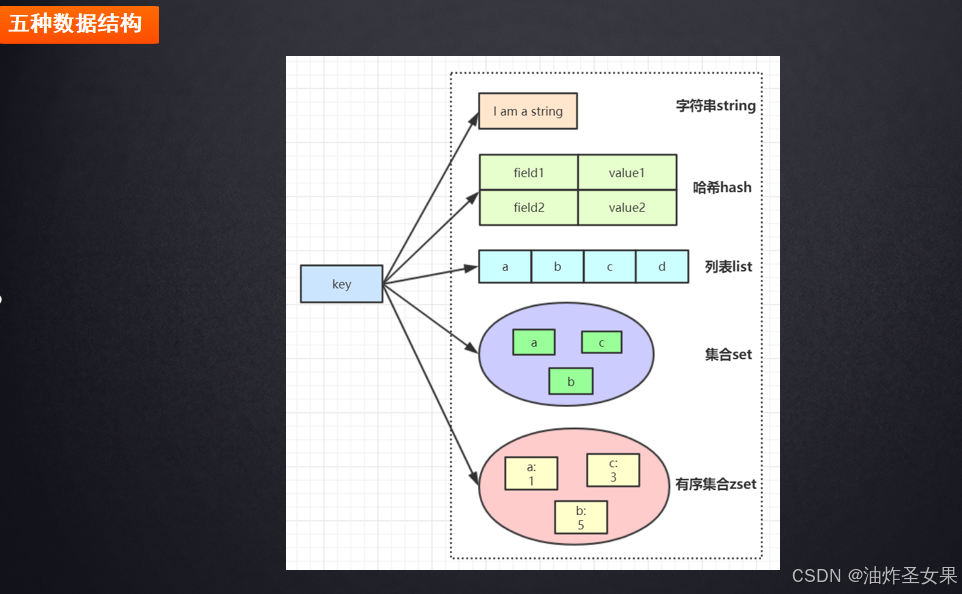
String结构
最常规的一个数据结构,常用的操作例举一下就行。

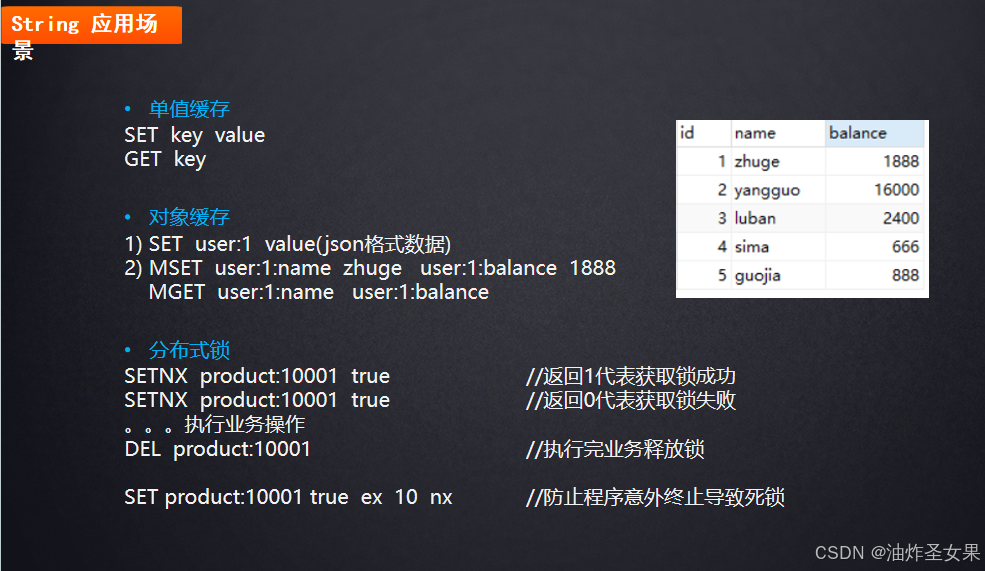
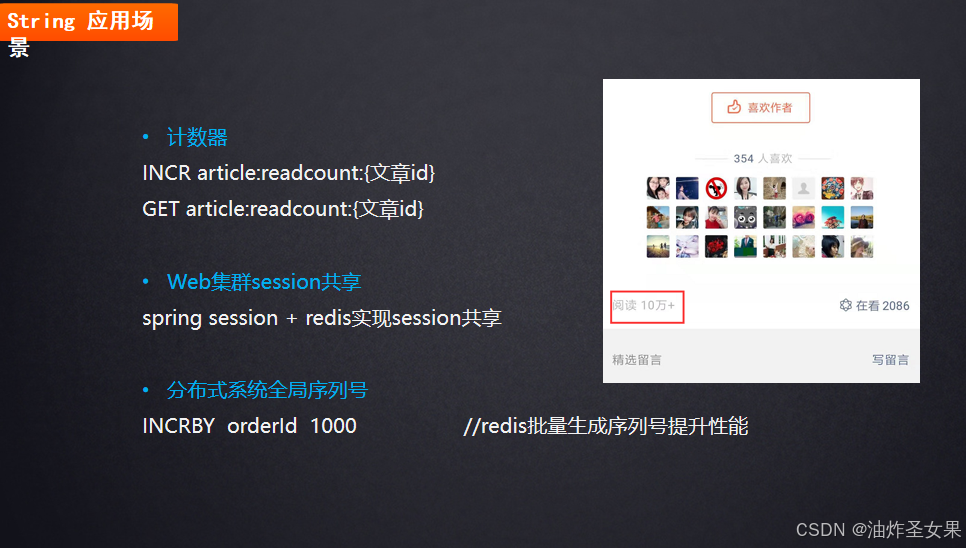
String的应用场景
这里指的分布式锁只是一种很简单的结构,做个举例,不用深究。
Hash结构
常用的操作命令都可以自己执行一下试试效果
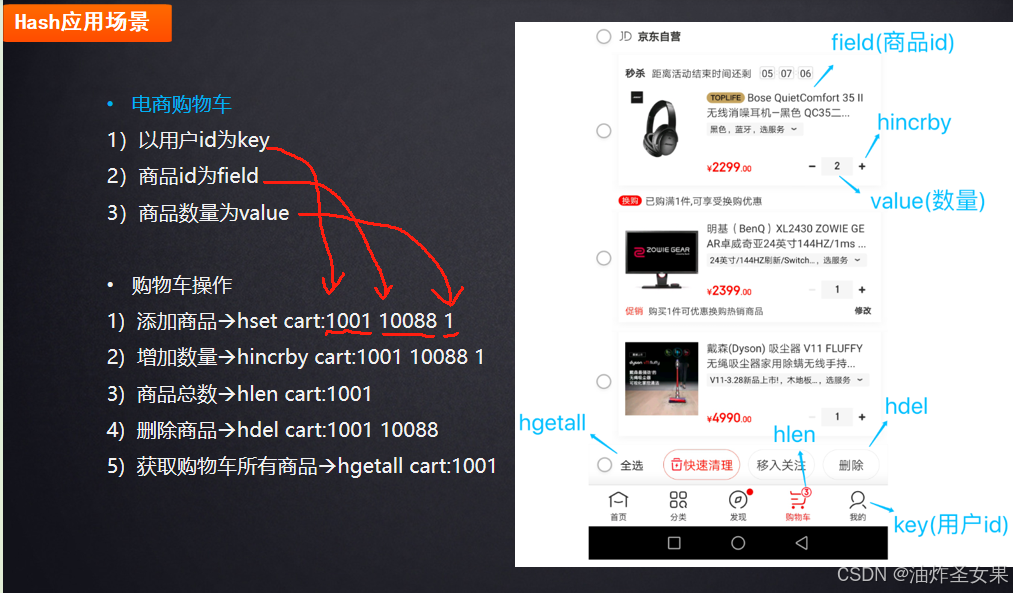
Hash的应用场景
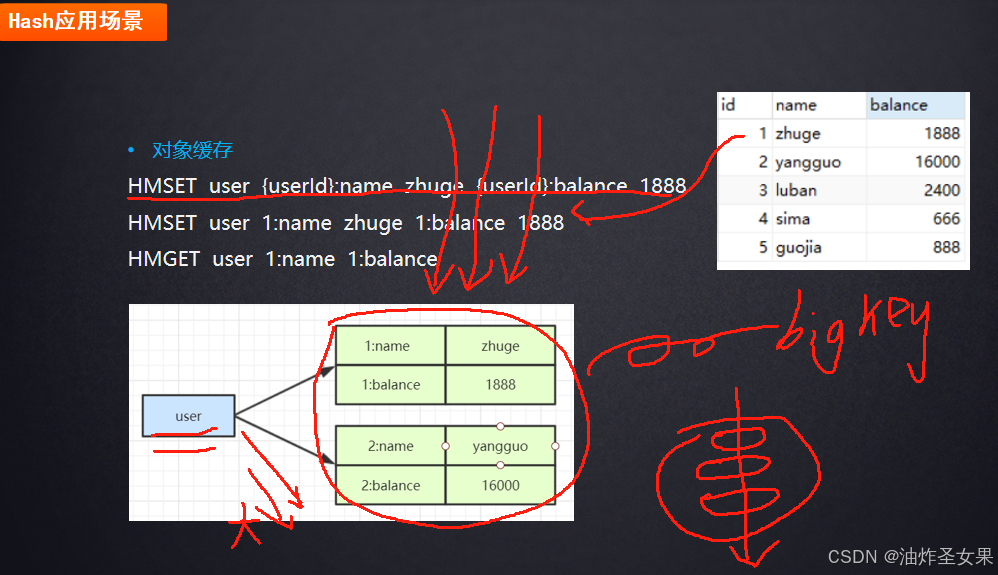
这里提一个Hash数据类型可能存在的问题:
bigkey问题:因为hash的结构是key value的形式,即如上图,如果我们给key为user缓存增加很多条数据,那么如果我们执行了一条HMGET ALL查询user的所有数据的话,这一个操作就会执行很长时间,那么问题就出现了:Redis是一个单线程模型(也不能说纯粹的单线程,后面会讲),各种命令进来会排个队,挨个执行,如果遇到这种bigkey的情况执行时间过长,其他的命令都会阻塞,那么就影响了redis的并发。
再举个应用场景例子,应用场景可以结合工作场景多思考
Hash结构优缺点:
优点
1)同类数据归类整合储存,方便数据管理
2)相比string操作消耗内存与cpu更小
3)相比string储存更节省空间
缺点
1)过期功能不能使用在field上,只能用在key上
2)Redis集群架构下不适合大规模使用
List结构

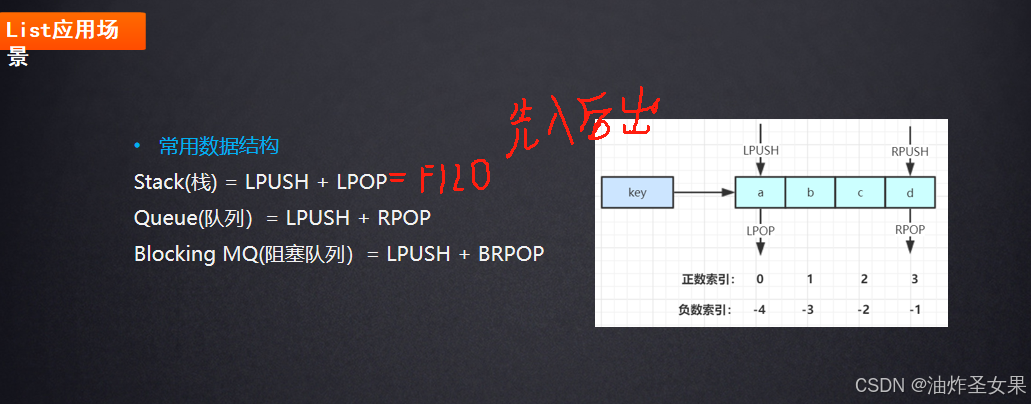
List应用场景
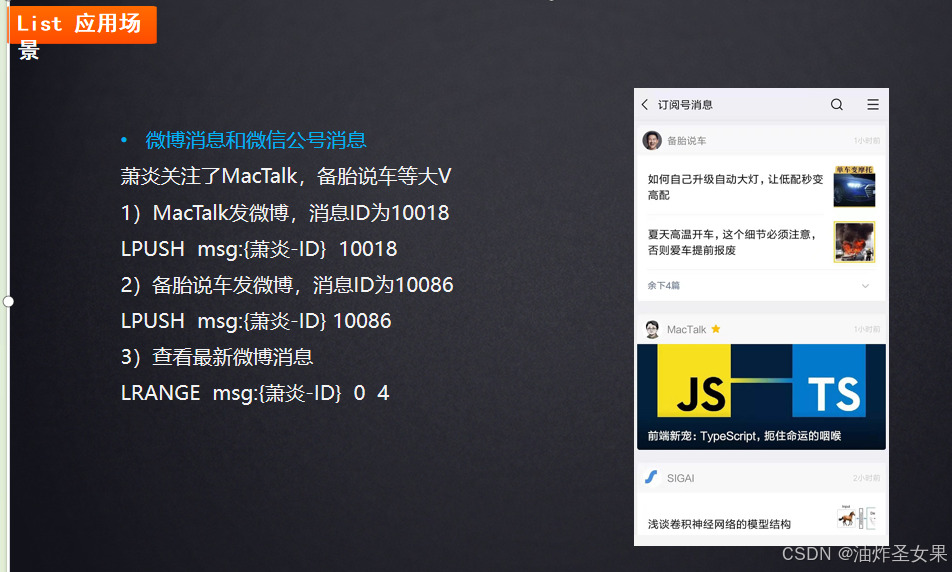
比如萧炎微博关注了几个博主(备胎说车和MacTalk),这样萧炎的关注消息就可以缓存为一个list,MacTalk发个微博,就往萧炎的消息list里LPUSH一条,备胎说车发微博,同样又缓存一条。这样我在查询的时候,先法消息的排序在后面,便是一种栈的形式。
Set结构(特点无序)

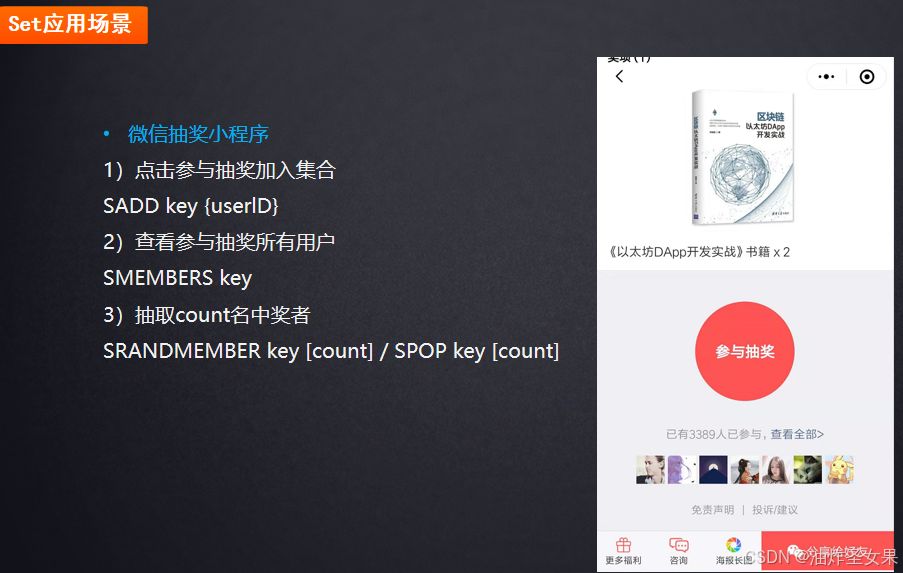
Set的应用场景
1.利用set的无序性用基础命令实现随机抽奖的效果。
2.集合操作:即交集、并集、差集
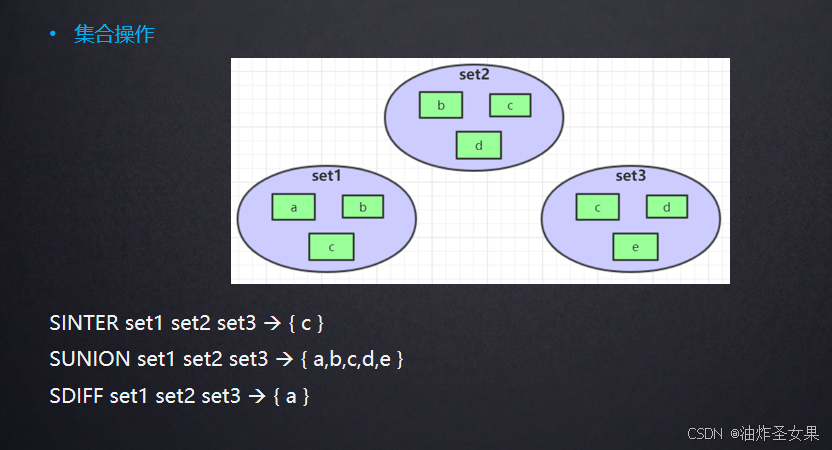
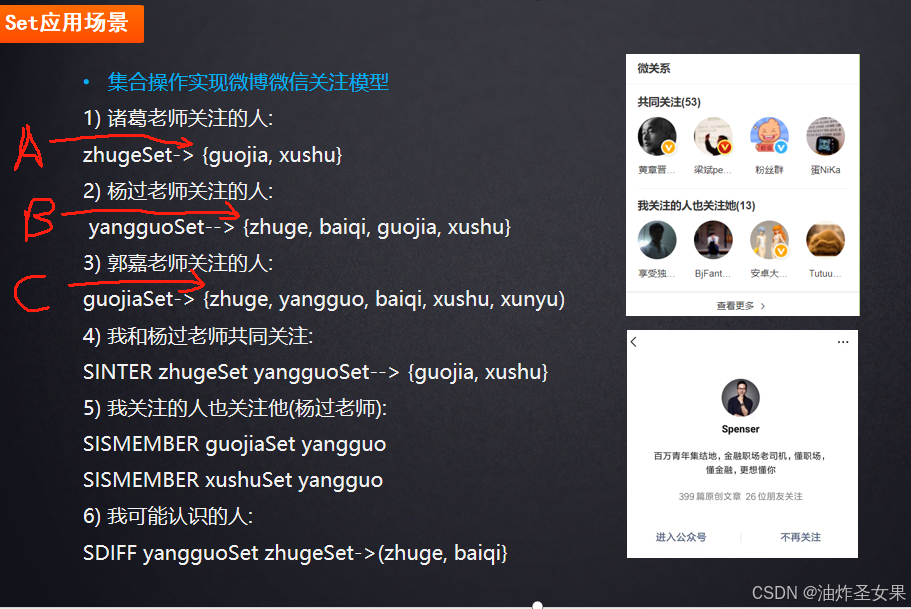
关注模型:
首先将每个用户关注的人作为一个用户的set缓存如集合A,B,C,那么诸葛老师和杨过老师的共同关注就是A和B集合的交集,那么就可以通过共同关注的人数或占比,系统可以推断出后你类似的人,就可以给你推送他关注的人给你或者判定你们可能共同认识的人(A和B的差集),或者和你喜好类似的人购买了某些商品,是不是可以推测你也感兴趣?那么系统就可以把商品推送给你。
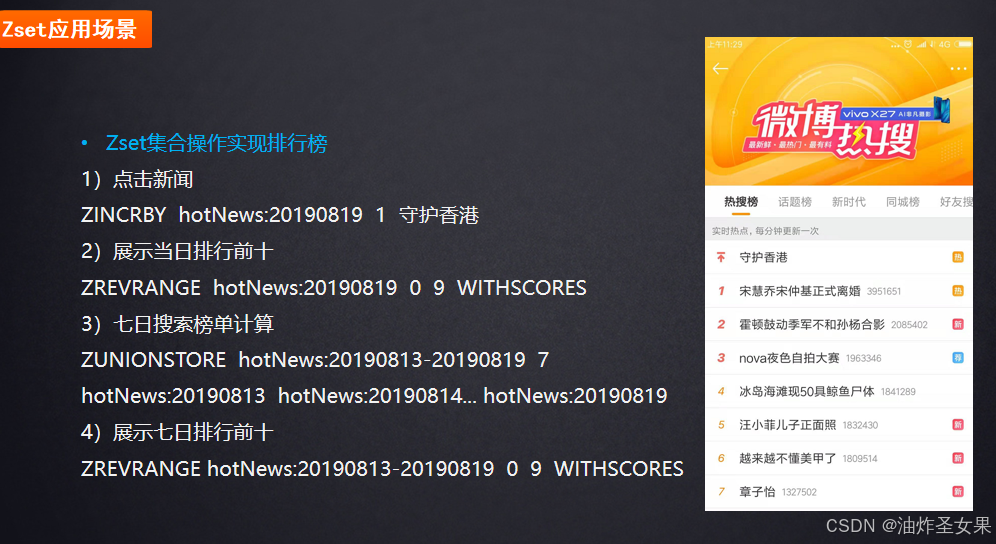
ZSet(有序集合结构)

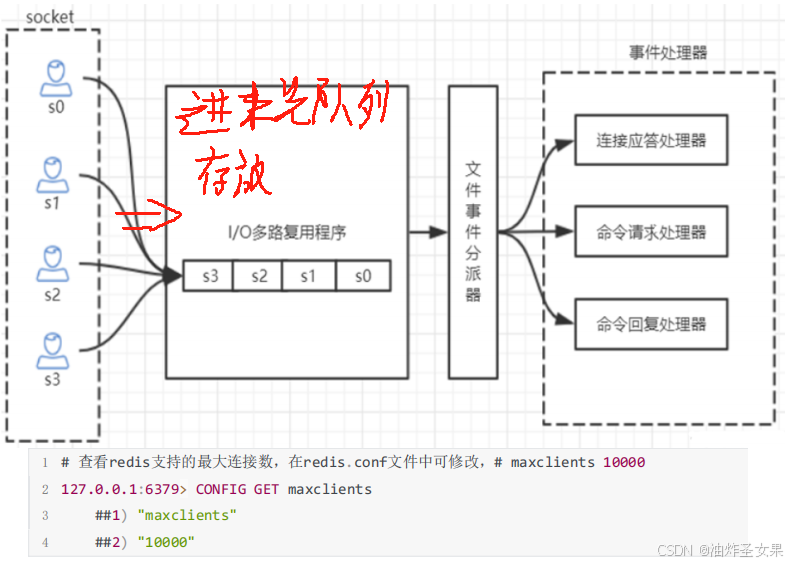
下一步通过几个问题了解Redis的性能层面


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









