







目录
爬取当当图书排行榜
一个课堂作业,使用re,BeautifulSoup等模板爬取当当图书排行榜(榜单自选),本篇重点在输出格式对齐那里,完整代码在结尾。
查看当当图书排行榜,分析其网址各部分代表的意义,选取特定分类和时间区间进行爬取
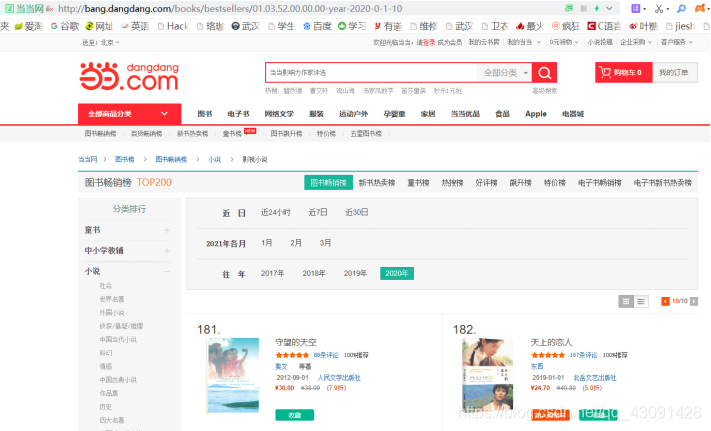
进入多个页面,仔细分析网址变化,可以发现网址最后的‘01.03.52.00.00.00’代表着书的类别,这个分类是影视小说排行榜;‘-year-’或者‘-month-’代表按照年份或者月份的排行榜;‘2020-0-1’是起始时间;最后的数字‘-10’代表当前页面,每页有20本图书。
我们用kind代表书的分类,time代表时间区间,depth代表共读取的页数,则” ‘http://bang.dangdang.com/books/bestsellers/’ + kind + time + ‘-’ + str(i+1) ”即是网址,循环爬取可以得到所有页面的数据。
在这里插入代码片
def main():
kind = '01.03.52.00.00.00'#排行榜书的类别,这个种类是影视小说
time = '-year-2020-0-1'#2020年整年的排行榜
depth = 10#页数
start_url = 'http://bang.dangdang.com/books/bestsellers/' + kind + time + '-'
infoList = []
for i in range(depth):
try:
url = start_url + str(i+1)
html = getHTMLText(url)
parsePage(infoList, html)
except:
continue
printGoodsList(infoList)
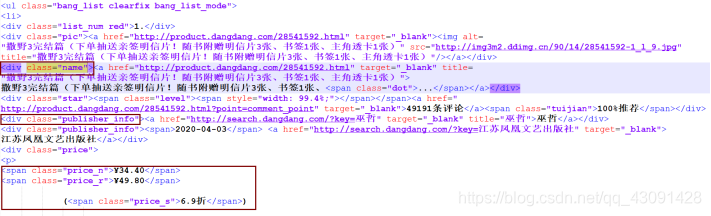
解析网页内容,查看所需信息(排名,书名,作者,出版社,价格)的位置;
爬取网页,使用 BeautifulSoup 进行解析,将代码写入到同目录下 “ceshi.txt”文件中
def getHTMLText(url):
try:
r = requests.get(url, timeout=100)
r.raise_for_status()
r.encoding = 'GBK'
#r.encoding = 'UTF-8'
return r.text
except:
return ""
def parsePage(ilt, html):
try:
soup = BeautifulSoup(html, 'html.parser')
'''
f = open("ceshi.txt", 'w', encoding="UTF-8")
f.write(str(soup))
f.close()
'''
查看网页代码,可以看出书名在
标签下;
作者和出版社在
作者和出版社在
标签下,我们只是想要作品数据,因此可以每次跳过出版社;当当价和定价分别在
和标签下。
分别爬取书名,作者,当当价和定价。由于书名中可能含有很多介绍性话语,如书名“希腊人左巴(三毛、村上春树生命中的过客,奥斯卡金像奖影片原著。“如果叫我在世界上选择一位导师的话,我肯定选择左巴,他教给了我热爱”我们使用split进行剔除,选择‘,’,‘空格’,‘(’依次进行分割,再选择第一段,我们就得到了书名。最后还要将‘——’替换为‘–’,因为python的print在打印中文破折号时距离不正确,会导致无法对其,因此我们将其更换为英文破折号。对齐问题后面会详细提到。
分别爬取书名,作者,当当价和定价。由于书名中可能含有很多介绍性话语,如书名“希腊人左巴(三毛、村上春树生命中的过客,奥斯卡金像奖影片原著。“如果叫我在世界上选择一位导师的话,我肯定选择左巴,他教给了我热爱”我们使用split进行剔除,选择‘,’,‘空格’,‘(’依次进行分割,再选择第一段,我们就得到了书名。最后还要将‘——’替换为‘–’,因为python的print在打印中文破折号时距离不正确,会导致无法对其,因此我们将其更换为英文破折号。对齐问题后面会详细提到。
看代码可以看到我设置了许多过滤条件,这实在是因为爬取到的书名后缀实在太多了,比如后来时间都与你有关(肖战李现同款书,韩寒 何炅 谢娜 吴昕 戚薇 阚清子等明星推荐),再比如请和我谈一场这样的恋爱吧!(一本甜到少女心炸裂、撩到大脑充血的恋爱书!随书附赠一套心灵糖分补充卡+恋爱大作战挑战卡),一个书名你搞那么长介绍干嘛啦,不过我还真有点想看的冲动(doge。
处理作者时,类似的先进行分割,去除介绍性话语,再将网页上错误显示的‘?’更改为’·’;
价格可以直接选择,然后将其加入到列表ilt中。

names = soup.find_all('div', attrs = {
'class': 'name'})
writers = soup.find_all('div', attrs={
'class': 'publisher_info'})
price_ns = soup.find_all('span', 'price_n')
price_rs = soup.</ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1415
1415

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











